TL;DR#
Large pre-trained vision models are computationally expensive, and their applicability is often overgeneralized. This leads to inefficient resource utilization, especially for tasks with limited resources. Existing methods for efficiently adapting these models often struggle with manual stacking or lack adaptability to different model scales.
Cluster-Learngene tackles this issue by adaptively clustering crucial internal modules (attention heads and FFNs) from a large pre-trained model to create a compact “learngene”. This learngene is then used to initialize smaller, specialized models suited for downstream tasks. The method incorporates priority weight sharing and learnable parameter transformations to adapt the learngene to various model scales, thereby addressing the issue of model size mismatch. The extensive experiments show that Cluster-Learngene is both more efficient and achieves better performance than other initialization methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient model initialization and transfer learning, particularly in the context of Vision Transformers. It offers a novel approach to reduce computational costs and improve model performance in various downstream tasks, which is highly relevant given the increasing resource demands of large-scale models. The adaptive clustering and learnable parameter transformation techniques introduced are significant contributions that open new avenues for research in model customization and resource-efficient AI.
Visual Insights#
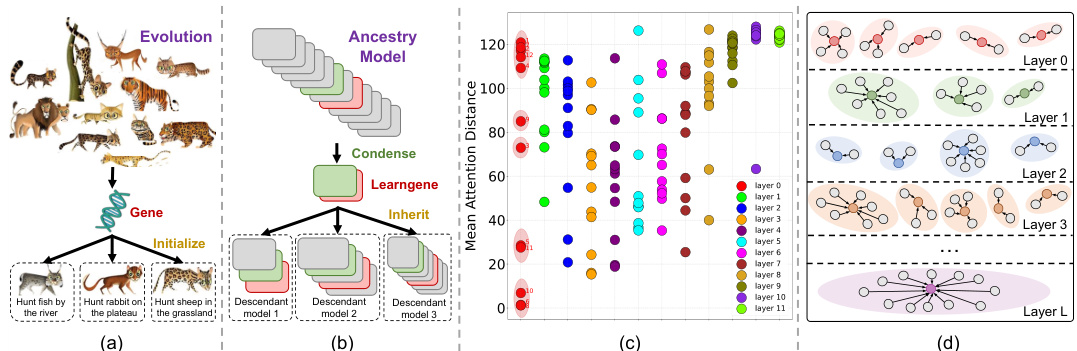
🔼 This figure illustrates the core concept of the Cluster-Learngene framework. (a) uses a biological analogy to show how genes condense evolutionary information to initialize diverse descendants. (b) shows the proposed framework, where the learngene is condensed from an ancestry model and then used to initialize descendant models of various sizes. (c) shows the density of attention heads across different layers of a DeiT-B model, highlighting the varying density across layers. (d) provides a simplified illustration of the clustering of attention heads.
read the caption
Figure 1: (a) The ancestry of biological organisms condenses evolutionary information into information-dense genes to initialize their diverse descendants [62, 17]. (b) The Learngene framework condenses the significant knowledge from an ancestry model into a more compact part termed learngene and then inherited to initialize the descendant models of elastic scales. (c) The density of attention heads across the different layers of the ancestry model, which employs the DeiT-B [46]. (d) An illustration of our idea.

🔼 This table compares the Top-1 accuracy and computational resource usage (parameters and FLOPs) of models trained from scratch on ImageNet-1K and those initialized using Cluster-Learngene. It shows the performance of different model sizes (Tiny, Small, Base) and varying numbers of attention heads and layers, demonstrating the efficiency and scalability of Cluster-Learngene.
read the caption
Table 1: Comparisons of performance on ImageNet-1K between models trained From-Scratch with 100 epochs and those initialized via Cluster-Learngene fine-tuned for 50 epochs.
In-depth insights#
Adaptive Clustering#
Adaptive clustering, in the context of a research paper, likely refers to a clustering algorithm that dynamically adjusts its parameters or approach based on the data’s characteristics. This contrasts with traditional clustering methods that use fixed parameters, potentially leading to suboptimal results if the data’s structure is complex or varies significantly. A key advantage is its ability to handle noisy or high-dimensional data more effectively, adapting to inherent data complexities. The algorithm might employ techniques like density-based clustering, which would allow the algorithm to identify clusters based on the density of data points. This adaptability could improve accuracy and efficiency, especially when dealing with datasets where cluster shapes and sizes are not uniform. The method’s effectiveness would depend on how well the adaptive mechanisms are designed to respond to varying data patterns. Proper evaluation is crucial, demonstrating improved performance relative to non-adaptive approaches and showcasing its robustness across diverse datasets. The description should also provide details on the specific adaptive strategies used, perhaps involving parameter tuning or hierarchical clustering.
Learngene Inheritance#
Learngene inheritance, a core concept in efficient model initialization, focuses on transferring crucial knowledge from a large, pre-trained “ancestry” model to smaller, task-specific “descendant” models. This process avoids the computational expense of training multiple large models from scratch. The learngene itself represents a distilled subset of the ancestry model’s parameters, carefully selected to maximize knowledge transfer while minimizing redundancy. Effective learngene selection methods identify and isolate key modules (like attention heads or FFN layers) exhibiting similar representational capacities, often based on density metrics or clustering algorithms. The inheritance phase subsequently involves strategically distributing these condensed parameters to initialize the descendant model, often incorporating weight-sharing or learnable transformations to adapt the learngene to varying model sizes and downstream tasks. The overall aim is to achieve a balance between model accuracy and resource efficiency, adapting pre-trained models to diverse resource constraints while maintaining performance. Careful consideration of how parameters are selected, inherited, and adapted is vital to the efficacy of learngene inheritance.
Elastic Model Scaling#
Elastic model scaling, a crucial aspect of modern deep learning, focuses on creating models that can adapt efficiently to varying computational resource constraints. The core challenge is to balance model performance with resource limitations, whether it’s memory, processing power, or latency. Successful strategies often involve techniques like model pruning, knowledge distillation, or parameter-efficient fine-tuning, enabling the deployment of smaller, faster models without significant accuracy loss. Adaptive methods that dynamically adjust model size based on the task and available resources are particularly valuable. This dynamic approach contrasts with fixed-size models, leading to greater flexibility in deploying AI solutions across various hardware platforms and application scenarios. A key focus is on developing efficient training strategies that minimize the computational cost associated with scaling and adapting models. The ability to seamlessly transition between different model sizes is also essential, ensuring a smooth user experience and optimizing performance in diverse contexts. Future research will likely investigate more sophisticated approaches to automatically adjust model architectures and training processes for optimal scaling, leading to a more efficient and robust use of resources in AI.
Priority Weight Sharing#
Priority weight sharing, as a technique, addresses the challenge of efficiently transferring knowledge from a large pre-trained model (ancestry model) to smaller, task-specific models (descendant models) of varying sizes. It prioritizes the transfer of weights from the most informative parts of the ancestry model, as determined by cluster size. Larger clusters, representing a higher density of attention heads with similar semantics, are given priority, ensuring the transfer of crucial, generalized knowledge. This approach contrasts with uniform weight sharing, where all parts contribute equally, potentially diluting the impact of essential features. By focusing on the most significant clusters, priority weight sharing enhances efficiency and prevents the transfer of redundant information, which may hinder downstream performance. The method is particularly valuable when dealing with elastic-scale models, enabling flexible adaptation to different computational constraints. Learnable parameter transformations, coupled with priority weight sharing, further improve the adaptation of the inherited knowledge to models of varying sizes, which is a significant contribution for resource-constrained applications.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the learngene framework to other architectural backbones beyond Vision Transformers would demonstrate its generalizability and impact. Investigating more sophisticated clustering techniques, potentially incorporating task-specific information, might further refine learngene selection. A detailed analysis into the trade-offs between the size of the learngene and downstream task performance is also warranted, to optimize resource allocation. Finally, exploring methods for automatically determining the optimal hyperparameters (e.g., cluster radius, density threshold) for different tasks would enhance the framework’s usability and eliminate manual tuning.
More visual insights#
More on figures

🔼 This figure illustrates the core concepts of the Cluster-Learngene method. (a) uses a biological analogy to explain how evolutionary information is condensed into genes to create diverse descendants. (b) shows the Learngene framework, which condenses knowledge from a large model (ancestry model) into a smaller, more efficient part (learngene) that can be used to initialize smaller models (descendant models). (c) displays the density of attention heads across different layers of a DeiT-B model, highlighting the varying density and potential for redundancy. (d) visually represents the concept of clustering attention heads to create a learngene.
read the caption
Figure 1: (a) The ancestry of biological organisms condenses evolutionary information into information-dense genes to initialize their diverse descendants [62, 17]. (b) The Learngene framework condenses the significant knowledge from an ancestry model into a more compact part termed learngene and then inherited to initialize the descendant models of elastic scales. (c) The density of attention heads across the different layers of the ancestry model, which employs the DeiT-B [46]. (d) An illustration of our idea.

🔼 This figure illustrates the process of priority weight-sharing used in Cluster-Learngene to initialize descendant models with varying numbers of attention heads. Head centroids, obtained from clustering attention heads in the ancestry model, are sorted in descending order by cluster size (darker color indicates larger cluster). These centroids are then distributed to initialize the attention heads in the descendant model layers. If the number of attention heads in a layer aligns with the number of centroids, they are evenly shared. If not, the remaining centroids are shared based on the remainder, prioritizing those representing larger clusters.
read the caption
Figure 2: Illustration of priority weight-sharing. The darker the color, the larger the cluster size associated with the head centroid.

🔼 This figure shows the performance of initializing descendant models with different numbers of layers and attention heads. It compares Cluster-Learngene to Pretraining-Finetuning, demonstrating Cluster-Learngene’s ability to adapt to varying resource constraints by efficiently initializing models of different scales. The hyperparameter ‘w’ controls the scaling factor for the number of attention heads.
read the caption
Figure 3: Initializing descendant models of elastic scales. 'L6/9/12' denote descendant models with 6, 9, and 12 layers, respectively. For a fair comparison, the downstream models in Pretraining-Finetuning inherit parameters from 12 layers of the pre-trained model, with the inherited number of attention heads matching those in Cluster-Learngene. We fine-tune 50 epochs for all models. In (a), the hyperparameter w takes values ranging from 1 to ∞ (i.e., the number of attention heads in descendant models is eight times that of the ancestry model). In (b), w ranges from 2 to 1. Continuing this pattern, in (c), w ranges from a maximum of 4 to a minimum of 3.

🔼 This figure visualizes the performance of Cluster-Learngene in initializing descendant models with varying numbers of layers and attention heads, comparing it to the Pretraining-Finetuning method. It shows that Cluster-Learngene adapts well to different model scales, unlike the Pretraining-Finetuning method which requires separate training for each model variant. The hyperparameter ‘w’ controls the scaling factor between the number of attention heads in the descendant and ancestry models.
read the caption
Figure 3: Initializing descendant models of elastic scales. 'L6/9/12' denote descendant models with 6, 9, and 12 layers, respectively. For a fair comparison, the downstream models in Pretraining-Finetuning inherit parameters from 12 layers of the pre-trained model, with the inherited number of attention heads matching those in Cluster-Learngene. We fine-tune 50 epochs for all models. In (a), the hyperparameter w takes values ranging from 1 to ∞ (i.e., the number of attention heads in descendant models is eight times that of the ancestry model). In (b), w ranges from 2 to 1. Continuing this pattern, in (c), w ranges from a maximum of 4 to a minimum of 3.

🔼 This figure compares the training efficiency of Cluster-Learngene against two other methods (From-Scratch and Pretraining-Finetuning) across four different model architectures: DeiT-Tiny, DeiT-Base, Swin-Tiny, and Swin-Base. The x-axis represents the number of training epochs, and the y-axis shows the achieved accuracy. The figure demonstrates that Cluster-Learngene achieves faster convergence than the other methods, reaching similar accuracy levels in significantly fewer training epochs. The speedup factor achieved by Cluster-Learngene is indicated for each architecture.
read the caption
Figure 5: Faster convergence. Different points represent results for varying epochs and the hyperparameter w is set to 1.0 for our method.
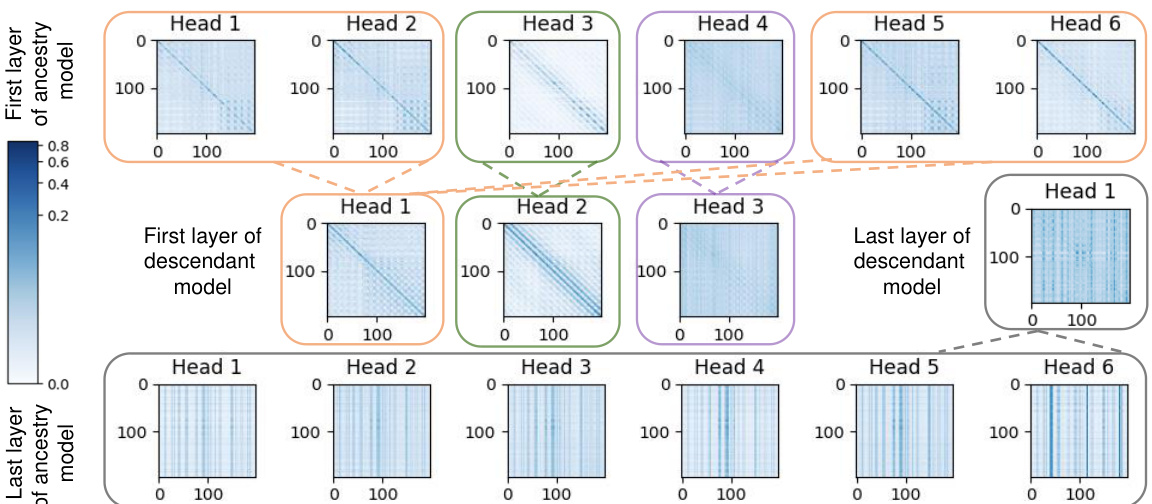
🔼 This figure visualizes attention representations from the first and last layers of both the ancestry and descendant models. The color intensity represents the attention weight, with darker colors indicating stronger attention. The figure shows how the Cluster-Learngene method condenses similar semantic attention patterns from the ancestry model into fewer, more representative patterns in the descendant model, thereby reducing redundancy and improving efficiency.
read the caption
Figure 6: Visualization of attention representations (197 × 197). We perform the following normalization operation on all attention heads A of the ancestry model and descendant model: 255A. The descendant model is trained for 50 epochs, and w is set to 1.
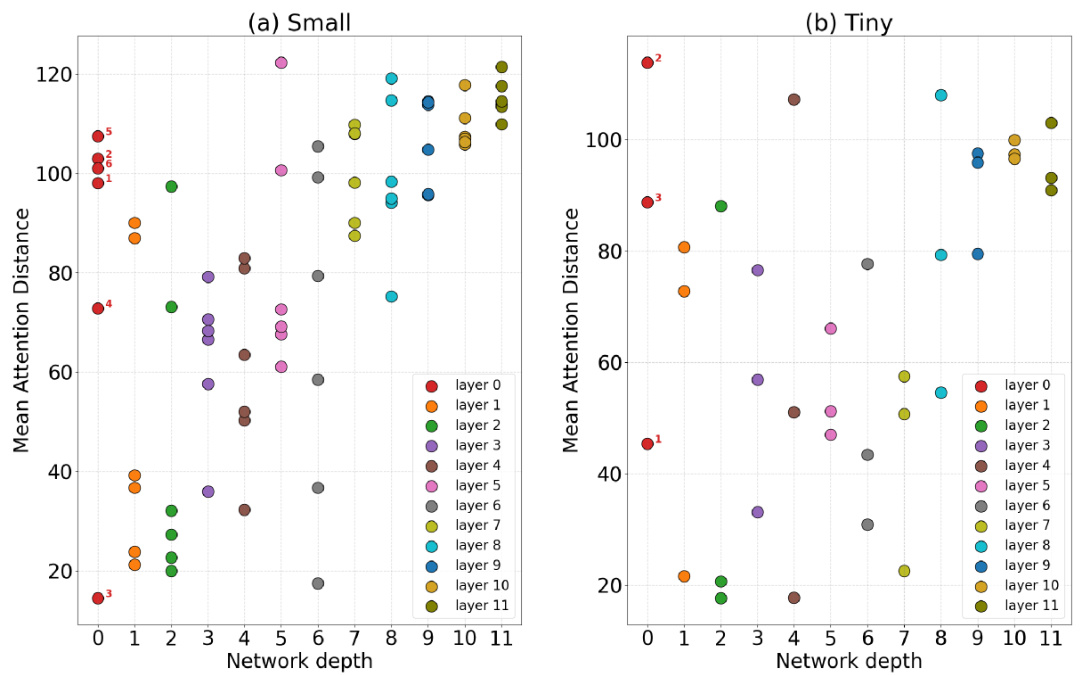
🔼 This figure visualizes the performance of initializing descendant models with different numbers of layers and attention heads using Cluster-Learngene and compares it to the traditional Pretraining-Finetuning method. It showcases Cluster-Learngene’s ability to adapt to different resource constraints by adjusting the number of parameters in the descendant model. The hyperparameter ‘w’ controls the scaling factor for the number of attention heads.
read the caption
Figure 3: Initializing descendant models of elastic scales. 'L6/9/12' denote descendant models with 6, 9, and 12 layers, respectively. For a fair comparison, the downstream models in Pretraining-Finetuning inherit parameters from 12 layers of the pre-trained model, with the inherited number of attention heads matching those in Cluster-Learngene. We fine-tune 50 epochs for all models. In (a), the hyperparameter w takes values ranging from 1 to ∞ (i.e., the number of attention heads in descendant models is eight times that of the ancestry model). In (b), w ranges from 2 to 1. Continuing this pattern, in (c), w ranges from a maximum of 4 to a minimum of 3.

🔼 This figure demonstrates the faster convergence achieved by Cluster-Learngene compared to From-Scratch and Pretraining-Finetuning methods. The x-axis represents the number of training epochs, and the y-axis shows the accuracy achieved. The figure shows that Cluster-Learngene reaches a similar level of accuracy to other methods with significantly fewer training epochs. Two subfigures are shown, one for DeiT-Tiny and one for Swin-Tiny architectures, highlighting that the speedup is consistent across different architectures.
read the caption
Figure 8: Faster convergence. Different points represent results for varying epochs and the hyperparameter w is set to 1.0 for our method.
More on tables

🔼 This table compares the performance of Cluster-Learngene against other initialization methods (Pretraining-Finetuning, From-Scratch, Heuristic-Learngene, Weight-Transformation, and Auto-Learngene) on six different downstream datasets (iNat-2019, Food-101, Flowers, Cars, CIFAR-10, CIFAR-100, CUB-200). The ‘↑’ symbol indicates the performance improvement of Cluster-Learngene over the best-performing alternative method. The number of inherited parameters (I-Params) is also listed for each method.
read the caption
Table 2: DeiT-Small Results on downstream datasets. ↑ represents the performance improvement achieved by Cluster-Learngene, when compared to the best method excluding Pretraining-Finetuning. All results are derived from the 6-layer downstream models.
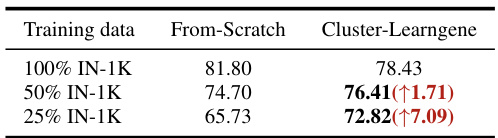
🔼 This table compares the performance of Cluster-Learngene and From-Scratch methods on initializing descendant models using different proportions of ImageNet-1k training data (100%, 50%, and 25%). The results highlight Cluster-Learngene’s ability to achieve comparable or even better accuracy with significantly fewer training epochs, demonstrating higher data efficiency.
read the caption
Table 3: Initialization of descendant models with diverse training samples. The symbol ↑ denotes the performance gap between our approach and the From-Scratch method. Cluster-Learngene initializes the descendant model over 50 training epochs. In contrast, From-Scratch results are achieved after 300 training epochs.
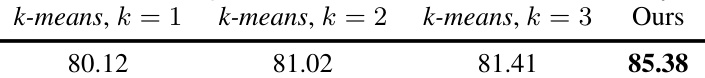
🔼 This table compares the performance of models trained from scratch with those initialized using Cluster-Learngene on the ImageNet-1K dataset. It shows the top-1 accuracy, number of attention heads (Hd), number of layers (Ld), number of parameters (in millions), and floating point operations (in billions) for different model configurations. The results demonstrate the effectiveness of Cluster-Learngene in improving model performance compared to training from scratch, particularly for smaller models with fewer resources.
read the caption
Table 1: Comparisons of performance on ImageNet-1K between models trained From-Scratch with 100 epochs and those initialized via Cluster-Learngene fine-tuned for 50 epochs.
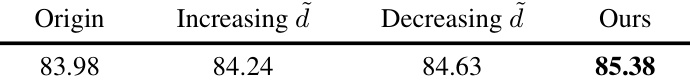
🔼 This table compares the performance of four different weight-sharing methods for initializing descendant models in the Cluster-Learngene approach. The ‘Origin’ method uses the original sequence of heads. ‘Increasing d’ and ‘Decreasing d’ sort the heads based on their density metric (d) values in ascending and descending order respectively. ‘Ours’ represents the proposed priority weight-sharing method, which prioritizes head centroids from larger clusters. The results show that the proposed priority weight-sharing method outperforms other methods in terms of accuracy on the 6-layer downstream models.
read the caption
Table 5: Comparison of priority weight-sharing. All results are derived from the 6-layer downstream models.

🔼 This table presents the characteristics of the seven datasets used for evaluating the performance of the Cluster-Learngene model on downstream tasks after initializing descendant models. The datasets vary significantly in size and the number of classes, including Oxford Flowers, CUB-200-2011, Stanford Cars, CIFAR-10, CIFAR-100, Food101, and iNaturalist-2019. The table shows the total number of images, the number of images used for training, validation, and testing, as well as the number of classes in each dataset.
read the caption
Table 6: Characteristics of the downstream datasets

🔼 This table presents the results of an ablation study to determine the best method for selecting head centroids. It compares four different approaches: averaging the parameters of attention heads and FFNs, selecting the parameter set that minimizes the distance to the centroid for attention heads only, selecting the parameter set that minimizes the distance to the centroid for FFNs only, and combining both selection methods. The accuracy on CIFAR-100 using a 6-layer DeiT-Small downstream model is reported for each approach.
read the caption
Table 7: Ablation on the selection of head centroids. All results are derived from the 6-layer downstream models. we conduct experiments on CIFAR-100 and use DeiT-Small as the ancestry model.

🔼 This table shows the impact of varying the number of attention heads across different layers of the descendant models. Two scenarios are compared: ‘Decrementing’, where the number of heads is reduced in the early layers and gradually increased towards the later layers, and ‘Incrementing’, where the opposite happens. The results demonstrate the effect of this architectural change on model performance.
read the caption
Table 9: Increment or decrement the count of attention heads. “Decrementing” denotes halving the number of attention heads in the first four layers, reducing them by a quarter in the middle four layers, and maintaining them in the last four layers relative to the ancestry model. Conversely, 'Incrementing' represents the opposite pattern.
Full paper#



















