TL;DR#
Unsupervised 3D object detection methods struggle with accurately detecting static objects while training primarily on dynamic objects. Existing iterative self-training approaches are computationally expensive and prone to confirmation bias. The imbalance between static and dynamic object data distribution also degrades model performance. This paper proposes a new approach.
The proposed method, UNION, simultaneously leverages LiDAR, camera, and temporal data to overcome these limitations. It uses spatial clustering and self-supervised scene flow to identify object proposals, and encodes their visual appearances. Then it distinguishes static foreground objects from background via visual similarity, using dynamic objects as references. Finally, it trains a multi-class detector using generated pseudo-bounding boxes and pseudo-class labels obtained from the appearance embeddings. This eliminates the need for iterative self-training, leading to increased efficiency and improved accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D object detection because it presents UNION, a novel unsupervised method that significantly improves performance and reduces computational cost. It also introduces appearance-based pseudo-classes, a new technique with broader applicability in unsupervised learning. This opens avenues for future research in multi-modal data fusion and unsupervised learning techniques. The improved accuracy and efficiency of 3D object detection can significantly benefit applications in autonomous driving and robotics.
Visual Insights#

🔼 This figure illustrates the UNION method’s pipeline for unsupervised 3D object detection. It starts with LiDAR-based object proposals (1), followed by temporal motion estimation to separate static and dynamic objects (2). Camera visual appearance is then encoded using a DINOv2 embedding module (3). These visual and motion features are then fused to classify appearance clusters as mobile or not (4, 5). Finally, a standard 3D object detector is trained using the identified mobile clusters’ pseudo-bounding boxes (6).
read the caption
Figure 1: UNION discovers mobile objects (e.g., cars, pedestrians, cyclists) in an unsupervised manner by exploiting LiDAR, camera, and temporal information jointly. The key observation is that mobile objects can be distinguished from background objects (e.g., buildings, trees, poles) by grouping object proposals with similar visual appearance, i.e., clustering their appearance embeddings, and selecting appearance clusters that contain at least X% dynamic instances.
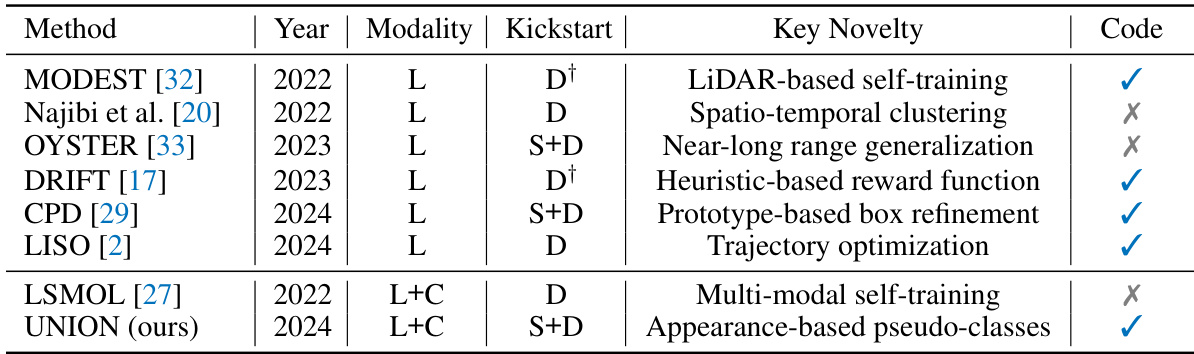
🔼 This table provides a comparison of various unsupervised 3D object discovery methods. It lists each method, its publication year, the sensor modalities it uses (LiDAR (L) and/or Camera (C)), the object types used for the initial training phase (static (S), dynamic (D), or both (S+D)), and the key novelty of the method. It also indicates whether code is publicly available for each method. The methods mostly rely on repeated traversals of the same location to extract dynamic objects.
read the caption
Table 1: Overview of existing methods for unsupervised 3D object discovery. In the modality column, L and C are abbreviations for LiDAR and camera, respectively. Kickstart indicates what object types are used for the first round of training, i.e. the training before the self-training, and S and D are abbreviations for static and dynamic objects, respectively. These methods rely on repeated traversals of the same location for extracting dynamic objects from the scene.
In-depth insights#
Unsupervised 3D OD#
Unsupervised 3D object detection (OD) presents a significant challenge in computer vision, demanding efficient methods to identify and locate objects in three-dimensional space without relying on manually labeled data. The lack of labeled data necessitates innovative approaches that leverage inherent properties of 3D data, like spatial relationships and temporal consistency, for learning. Successful unsupervised 3D OD methods often integrate multiple sensor modalities (e.g., LiDAR and camera) to create rich representations of the scene, enabling better object discrimination. A critical aspect is handling the varying characteristics of static and dynamic objects, as static instances often hinder learning algorithms designed for dynamic objects. Effective techniques focus on self-supervised learning, exploiting temporal information from sensor data to identify moving objects and distinguish them from stationary ones. The accuracy and robustness of such methods are often evaluated by comparing their performance against supervised methods and analyzed in terms of precision, recall, and overall detection accuracy.
Multi-modal Fusion#
Multi-modal fusion in 3D object detection aims to synergistically combine data from various sensors, such as LiDAR and cameras, to overcome individual sensor limitations and achieve more robust and accurate results. LiDAR provides precise spatial information, but lacks rich semantic understanding; cameras offer detailed visual features, but struggle with depth perception and noisy data. Effective fusion strategies leverage the complementary strengths of each modality. Early fusion methods integrate data at the raw sensor level, enabling joint feature extraction but potentially increasing computational complexity. Late fusion approaches independently process data from each modality before combining their respective outputs, simplifying computation but potentially losing crucial inter-modal relationships. Intermediate fusion techniques offer a balance, merging features at intermediate processing stages to optimize the benefits of both approaches. Successful multi-modal fusion hinges on effective feature representation, aligning data formats and scales, and robust data association techniques to establish correspondences between LiDAR points and image pixels. The choice of fusion strategy and feature representation significantly impacts performance and depends on factors like computational resources, data characteristics, and the specific detection task.
Appearance Clusters#
The concept of ‘Appearance Clusters’ in unsupervised 3D object detection involves grouping object proposals based on their visual similarity. This is a crucial step because it leverages the inherent visual consistency of objects belonging to the same semantic class. By clustering objects with similar appearances, the algorithm can effectively distinguish between foreground objects (both static and dynamic) and background clutter. The visual appearance is often encoded using features extracted from camera images, possibly employing deep learning models. The formation of appearance clusters effectively acts as a preliminary classification step, helping to group similar instances together, even without explicit class labels. This clustering is particularly important for handling static objects, which are difficult to isolate from the background solely using spatial information. The successful identification of ‘Appearance Clusters’ can significantly improve the accuracy and efficiency of unsupervised object detection, particularly in complex scenes with numerous objects densely packed together.
Pseudo-Class Labels#
The concept of ‘pseudo-class labels’ is central to the paper’s unsupervised 3D object detection method. It cleverly sidesteps the need for manual labeling by using visual appearance clustering to group similar object proposals. Dynamic object proposals (those exhibiting motion) serve as anchors, informing the selection of visually similar static objects. These combined sets, dynamic and visually-matched static, are assigned pseudo-class labels that reflect appearance-based groupings rather than true semantic classes. This approach is innovative because it leverages self-supervised visual features to implicitly learn meaningful distinctions between foreground (mobile objects) and background. The use of pseudo-class labels enables training of a standard 3D object detector, achieving strong performance without human-annotated data. This strategy is computationally efficient compared to iterative self-training methods, which repeatedly refine labels through multiple rounds of training. Ultimately, the effectiveness of ‘pseudo-class labels’ hinges on the accuracy of the visual clustering and the underlying assumption that objects of the same class exhibit similar visual appearance.
Future of 3D OD#
The future of 3D object detection (OD) is ripe with potential. Multi-modality will become increasingly crucial, fusing LiDAR, camera, radar, and even GPS data for robust and accurate detection in challenging conditions. Unsupervised and self-supervised learning will continue to reduce reliance on expensive manual labeling, while techniques like domain adaptation and transfer learning will enable models to generalize across diverse environments and datasets. Further advancements in 3D representation learning will enable more accurate and efficient feature extraction, leading to improved detection speed and accuracy. Real-time performance will be paramount, demanding more efficient algorithms and optimized hardware solutions. Finally, solving the challenges of occlusion handling, long-range detection, and complex scene understanding will push the boundaries of 3D OD, leading to safer and more efficient autonomous systems.
More visual insights#
More on figures

🔼 This figure compares different approaches to unsupervised 3D object discovery. (a) shows the common LiDAR-only approach using self-training. (b) shows a multi-modal approach (LiDAR and camera) also using self-training. (c) presents the proposed UNION method, which uses both LiDAR and camera data but without self-training, enabling multi-class object detection.
read the caption
Figure 2: Comparison of the various designs for unsupervised 3D object discovery. (a) Most object discovery methods exploit LiDAR to generate pseudo-bounding boxes and use these to train a detector in a class-agnostic setting followed by self-training. (b) Wang et al. [27] generate pseudo-bounding boxes similar to (a) but alternate between training a LiDAR-based detector and a camera-based detector for self-training. (c) UNION: multi-modal multi-class 3D object discovery (ours)
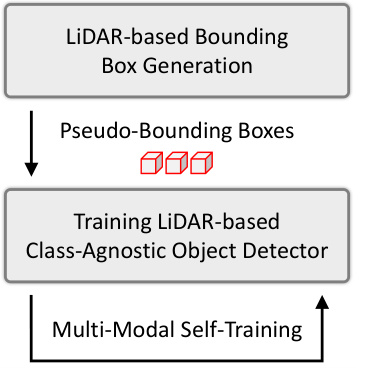
🔼 This figure compares different approaches for unsupervised 3D object discovery. (a) shows the typical LiDAR-only approach using self-training. (b) illustrates a multi-modal approach also employing self-training, alternating between LiDAR and camera data. (c) presents the UNION method, a multi-modal approach that avoids self-training by directly using appearance-based pseudo-classes.
read the caption
Figure 2: Comparison of the various designs for unsupervised 3D object discovery. (a) Most object discovery methods exploit LiDAR to generate pseudo-bounding boxes and use these to train a detector in a class-agnostic setting followed by self-training. (b) Wang et al. [27] generate pseudo-bounding boxes similar to (a) but alternate between training a LiDAR-based detector and a camera-based detector for self-training. (c) UNION: multi-modal multi-class 3D object discovery (ours)

🔼 This figure compares different approaches for unsupervised 3D object discovery. (a) shows the traditional LiDAR-only approach using self-training. (b) illustrates a multi-modal approach that still uses self-training. (c) presents the UNION method, which uses multi-modal data and avoids self-training.
read the caption
Figure 2: Comparison of the various designs for unsupervised 3D object discovery. (a) Most object discovery methods exploit LiDAR to generate pseudo-bounding boxes and use these to train a detector in a class-agnostic setting followed by self-training. (b) Wang et al. [27] generate pseudo-bounding boxes similar to (a) but alternate between training a LiDAR-based detector and a camera-based detector for self-training. (c) UNION: multi-modal multi-class 3D object discovery (ours)

🔼 This figure shows a qualitative comparison of object detection results from different stages of the UNION pipeline and the ground truth. (a) shows the object proposals generated by HDBSCAN, a spatial clustering algorithm. (b) shows the results of scene flow estimation, differentiating between static (black) and dynamic (red) objects. (c) shows the final results of the UNION pipeline, highlighting static (green) and dynamic (red) mobile objects. (d) shows the ground truth annotations for comparison. The figure visually demonstrates how UNION effectively combines spatial, temporal, and visual information to improve object detection accuracy, particularly regarding the identification of static mobile objects.
read the caption
Figure 3: Qualitative results for the UNION pipeline compared to the ground truth annotations. (a) HDBSCAN (step 1 in Figure 1): object proposals (spatial clusters) in black. (b) Scene flow (step 2 in Figure 1): static and dynamic object proposals in black and red, respectively. (c) UNION: static and dynamic mobile objects in green and red, respectively. (d) Ground truth: mobile objects in blue.

🔼 This figure shows the percentage of dynamic object proposals within each of the 20 appearance clusters generated by the UNION method. The x-axis represents the cluster ID, and the y-axis shows the fraction of dynamic proposals in each cluster. A horizontal red line indicates a threshold of 5%. Clusters above this threshold are considered to contain enough dynamic instances and are classified as ‘mobile clusters’, suggesting the presence of mobile objects within them. Clusters below the line are considered ’non-mobile’. This visual representation helps to illustrate the effectiveness of the appearance-based clustering in identifying mobile objects.
read the caption
Figure 4: The dynamic object proposal fractions of the visual appearance clusters. We use a threshold of 5% for selecting clusters.
More on tables
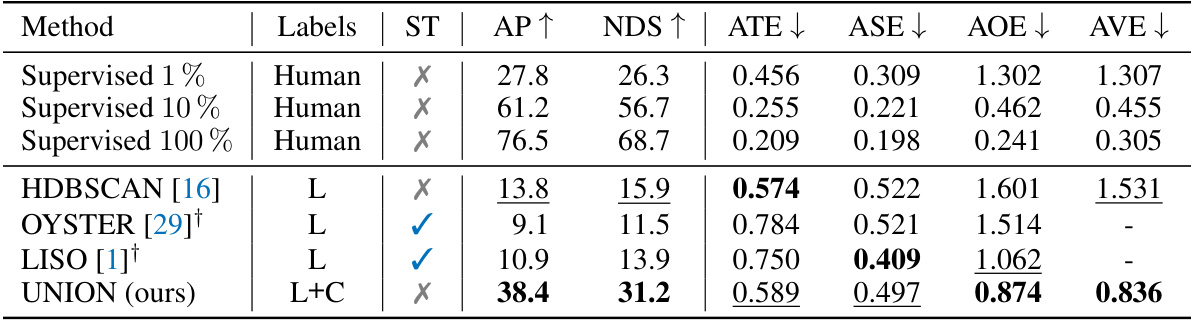
🔼 This table presents a comparison of various methods for class-agnostic object detection on the nuScenes validation dataset. The methods are evaluated based on Average Precision (AP), NuScenes Detection Score (NDS), and several error metrics (ATE, ASE, AOE, AVE). The table includes both supervised and unsupervised methods, highlighting the superior performance of the proposed UNION method compared to existing unsupervised techniques. The impact of self-training on performance is also shown.
read the caption
Table 2: Class-agnostic object detection on the nuScenes validation set. Results are obtained by training CenterPoint [31] with the generated pseudo-bounding boxes. L and C are abbreviations for LiDAR and camera, respectively. Best performance in bold, and second-best is underlined. ST stands for self-training, which increases the computational cost of training. Results taken from [2].
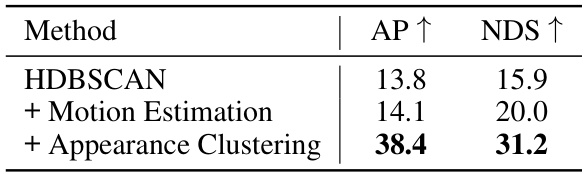
🔼 This table presents the results of class-agnostic object detection on the nuScenes validation dataset. The performance of the UNION method is compared against several baselines, including HDBSCAN, OYSTER, and LISO, as well as supervised training with varying amounts of labeled data. The key metrics used for comparison are average precision (AP) and nuScenes detection score (NDS). The table highlights the superior performance of UNION, particularly in comparison to unsupervised baselines.
read the caption
Table 3: Class-agnostic object detection on the nuScenes validation set. Results are obtained by training CenterPoint [31] with the generated pseudo-bounding boxes. L and C are abbreviations for LiDAR and camera, respectively. Best performance in bold, and second-best is underlined. ST stands for self-training, which increases the computational cost of training. Results taken from [2].

🔼 This table presents the ablation study comparing the performance of UNION using two different image encoders: DINOv2 ViT-L/14 with registers and I-JEPA ViT-H/16. The results show the Average Precision (AP), nuScenes Detection Score (NDS), and various error metrics (ATE, ASE, AOE, AVE). DINOv2 significantly outperforms I-JEPA, highlighting its importance for achieving the best results.
read the caption
Table 4: Image encoder ablation study for UNION. Best performance in bold.
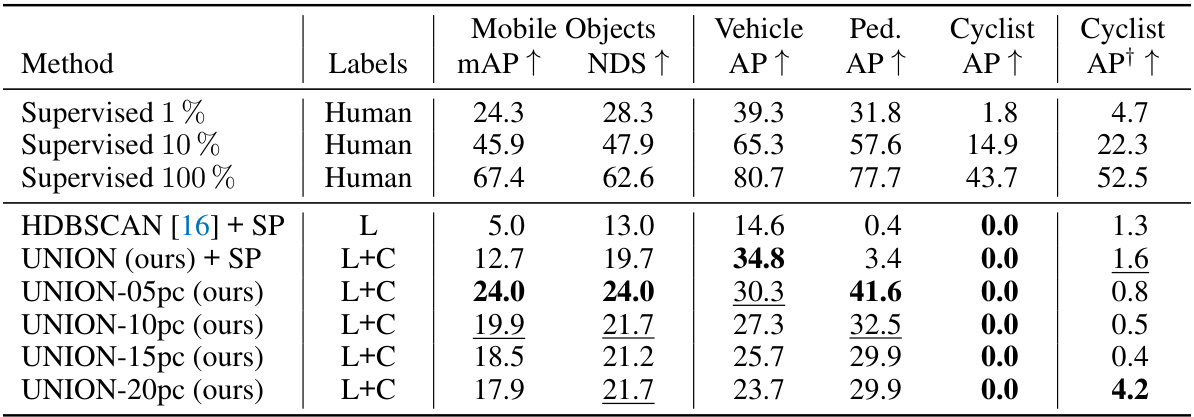
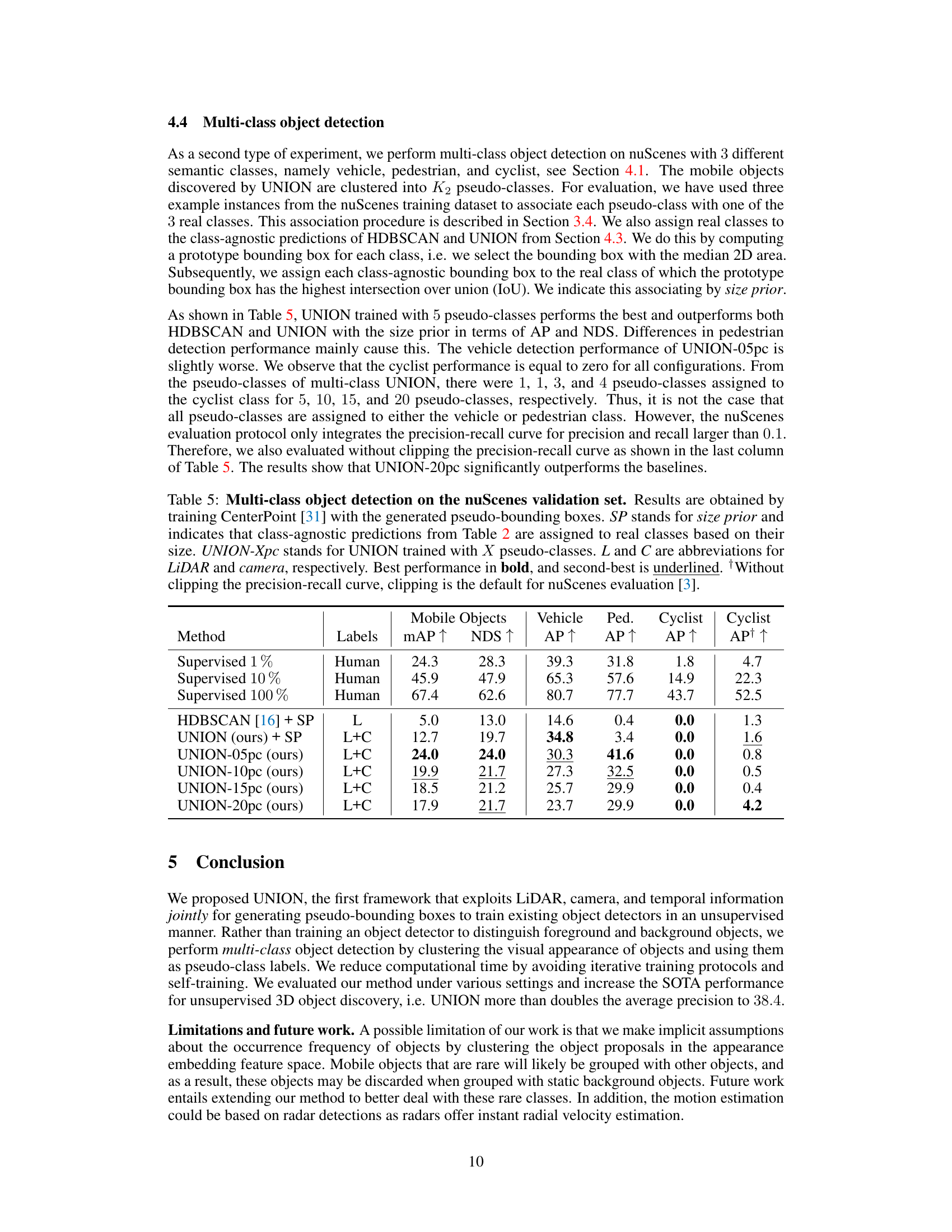
🔼 This table presents the results of multi-class object detection experiments on the nuScenes dataset using the proposed UNION method and several baselines. It compares the performance of UNION with different numbers of pseudo-classes (5, 10, 15, 20) against a supervised approach using varying amounts of labeled data, and against a class-agnostic approach using HDBSCAN. The metrics used are mean Average Precision (mAP), NuScenes Detection Score (NDS), and Average Precision (AP) for vehicle, pedestrian, and cyclist classes.
read the caption
Table 5: Multi-class object detection on the nuScenes validation set. Results are obtained by training CenterPoint [31] with the generated pseudo-bounding boxes. SP stands for size prior and indicates that class-agnostic predictions from Table 2 are assigned to real classes based on their size. UNION-Xpc stands for UNION trained with X pseudo-classes. L and C are abbreviations for LiDAR and camera, respectively. Best performance in bold, and second-best is underlined. Without clipping the precision-recall curve, clipping is the default for nuScenes evaluation [3].
Full paper#