TL;DR#
Current machine unlearning methods struggle to effectively remove unwanted data from large generative models without negatively affecting their performance and accuracy, specifically in the image-text alignment aspect. This is largely due to the conflicting nature of the two main objectives: removing undesirable information while preserving the model’s overall quality and functionality. These methods either result in poor unlearning quality or a significant loss in alignment after the process.
This paper introduces a novel framework that addresses this problem by focusing on finding optimal model updates at each unlearning step. The core contribution is a new technique called “restricted gradient,” which helps ensure that the model improves on both objectives (unlearning and alignment) simultaneously during each iteration. The framework also introduces methods to enhance the diversity of the data used in the unlearning process, further improving the results and preventing overfitting. The authors demonstrate superior performance compared to current state-of-the-art methods in removing specific concepts such as nudity, art styles, and classes in datasets like CIFAR-10 while maintaining close alignment with the model’s original capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical challenge of maintaining text-image alignment in generative models after unlearning, a problem that significantly impacts the real-world deployment of these models. The proposed framework and techniques provide practical solutions and open new avenues for research into safe and effective unlearning methods for large-scale models. This work is relevant to researchers focusing on machine unlearning, text-to-image generation, and improving the safety and ethical considerations in AI.
Visual Insights#

🔼 This figure compares the image generation results of different text-to-image unlearning methods. Two unlearning tasks are shown: removing nudity and removing Van Gogh style from generated images. The figure demonstrates that the proposed method (RGD) maintains high alignment scores (semantic accuracy) between the generated image and its text prompt, even after unlearning, unlike the baseline methods (SalUn and ESD) which generate images that are semantically incorrect.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.
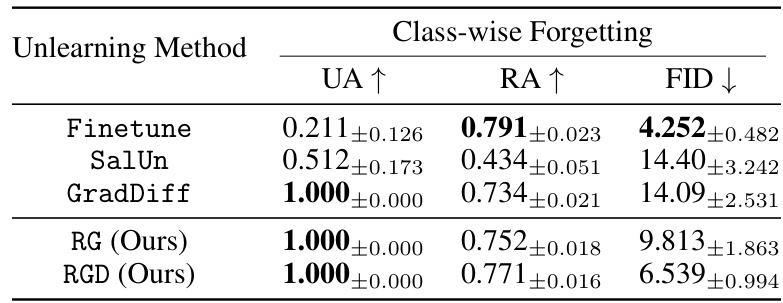
🔼 This table presents a quantitative comparison of different unlearning methods on CIFAR-10 image generation using diffusion models. The methods are evaluated by sequentially removing each of the 10 classes from the model. The table reports the unlearning accuracy (UA, higher is better), remaining accuracy (RA, higher is better - accuracy on the classes that weren’t removed), and the Fréchet Inception Distance (FID, lower is better) for the generated images. The reported values are averages across all 10 experiments.
read the caption
Table 1: Quantitative evaluation of unlearning methods on CIFAR-10 diffusion-based generative models. Each method was evaluated by sequentially targeting each of the 10 CIFAR-10 classes for unlearning. For each target class, we measure unlearning accuracy (UA) specific to that class, remaining accuracy (RA) on the other 9 classes, and FID for generation quality. The reported values are averaged across all 10 class-specific unlearning experiments.
In-depth insights#
Alignment Boosting#
Alignment boosting in post-unlearning generative models focuses on preserving the desirable properties of the model after removing unwanted information. The core challenge is that the two objectives of unlearning (removing undesirable data) and maintaining alignment (preserving the model’s ability to generate appropriate outputs given text prompts) often conflict. Strategies typically involve carefully crafting model updates to balance these competing goals, such as through gradient manipulation or regularization. Key considerations include the selection and diversity of data used for both the unlearning and retention phases. Insufficient diversity in the retained data can lead to overfitting and a degradation of performance. Successful approaches often incorporate techniques to ensure monotonic improvement in both alignment and forgetting, indicating that the model consistently improves on both objectives with each iterative update. The interplay between these elements is critical, as any approach needs to thoughtfully navigate the inherent tension to truly boost alignment while achieving effective unlearning.
Unlearning Methods#
The effectiveness of various unlearning methods hinges on their ability to selectively remove undesired information while preserving the model’s overall functionality. Exact unlearning, though ideal, is computationally expensive. Approximate methods, such as those based on gradient manipulation or data influence, offer efficiency but often compromise model performance or alignment. The choice of method depends heavily on the specific application and the nature of the data to be removed; techniques optimized for class-conditional models might not translate seamlessly to text-to-image generation. A promising direction lies in finding strategies that optimally balance the trade-off between forgetting and retaining information, possibly through careful gradient regularization or dataset diversification to minimize the disruption to remaining knowledge. Further research should focus on developing methods that are robust to hyperparameter tuning and demonstrate superior performance and generalization across various model architectures and data types.
Data Diversity#
The concept of data diversity in the context of machine unlearning is crucial for maintaining the model’s performance on the remaining data after removing the target data. Insufficient diversity in the remaining dataset can lead to overfitting, where the model becomes overly specialized to the limited examples and fails to generalize well to unseen data. This is especially problematic in machine unlearning, as the goal is not just to forget the target data but also to preserve the model’s ability to handle other data points. The authors highlight that the selection of samples for the remaining dataset must be carefully considered. A diverse dataset provides the model with a wider range of features and patterns to learn from, enhancing generalization capability. They suggest several strategies for ensuring diversity, and their experiments demonstrate a significant performance improvement by strategically diversifying the dataset. This careful consideration of diversity underscores the importance of creating a balanced and representative remaining dataset for successful unlearning. A simplistic approach to constructing this dataset can lead to overfitting and a trade-off between the quality of forgetting and the model’s generalization on the remaining dataset.
Model Limitations#
The heading ‘Model Limitations’ would ideally delve into the inherent constraints of the described text-to-image generative models. A thorough discussion should identify biases present in the training data, potentially leading to skewed or stereotypical outputs, and explain the limitations in generating high-fidelity images for complex or nuanced prompts. Another key aspect is the model’s vulnerability to adversarial attacks, where subtle manipulation of the input can result in unexpected or undesirable outputs. The section could also analyze computational costs involved in training and deploying the models, which might restrict their accessibility or scalability. Additionally, discussing the ethical concerns surrounding these models’ capabilities, such as the potential for generating inappropriate or harmful content, is critical. Finally, comparison to the state-of-the-art in terms of both image quality and ethical considerations should strengthen the analysis by highlighting both strengths and weaknesses relative to existing methods. Addressing these points would provide a comprehensive understanding of the models’ limitations and their implications.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of the proposed unlearning framework is crucial for real-world applications involving massive datasets. This includes investigating more efficient optimization algorithms and exploring techniques for handling conflicts between gradients more effectively. A deeper investigation into the interplay between data diversity and model performance is needed, particularly in the context of different model architectures. Research into adaptive strategies for selecting the optimal dataset size for both forgetting and retaining data could significantly enhance efficiency and effectiveness. Extending the methodology to other generative model architectures, such as those based on GANs or VAEs, and exploring applications to diverse downstream tasks beyond image generation, such as text or audio, presents exciting opportunities. Finally, addressing potential ethical implications of unlearning techniques and ensuring robustness against adversarial attacks are vital for responsible deployment of these models. These future directions will lead to more robust and responsible generative models.
More visual insights#
More on figures
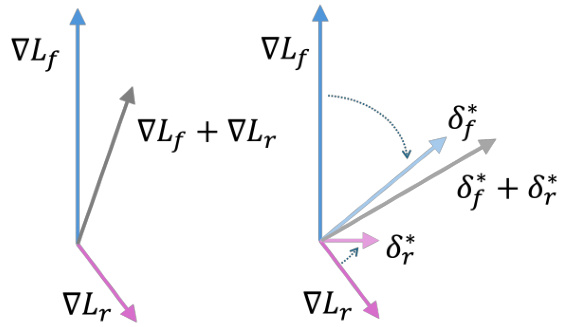
🔼 This figure visualizes the difference between two gradient update methods: direct aggregation and the restricted gradient proposed by the authors. The left panel (a) shows the direct summation of the gradients for the forgetting loss (∇Lf) and the remaining loss (∇Lr). The resultant update direction is simply the sum of the two individual gradient vectors. The right panel (b) illustrates the authors’ restricted gradient method. Here, instead of directly summing the gradients, the method projects each gradient vector onto the orthogonal subspace of the other, resulting in modified gradient vectors (δf and δr). The final update direction (δf + δr) is a combination of these projected gradient vectors, aiming to find a balance between the two often conflicting objectives.
read the caption
Figure 2: Visualization of the update. We show the update direction (gray) obtained by (a) directly summing up the two gradients and (b) our restricted gradient.

🔼 This figure compares the image generation results of different text-to-image unlearning methods. The top row shows the results for removing nudity from images, while the bottom row demonstrates removing Van Gogh’s artistic style. The leftmost column shows the original Stable Diffusion (SD) generated images. Subsequent columns show results after unlearning using SalUn, ESD, and the authors’ proposed method (RGD). The results highlight that RGD maintains better alignment with the original prompt than competing methods, demonstrating its effectiveness in removing unwanted content while preserving the overall quality of generated images.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.
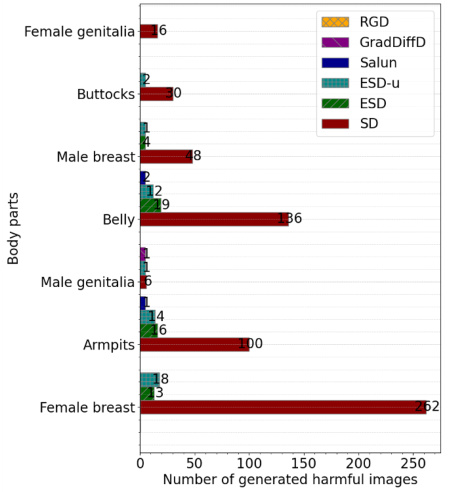
🔼 This figure compares the number of images with nudity generated by different unlearning methods (RGD, GradDiffD, SalUn, ESD-u, ESD) and the original Stable Diffusion model (SD). The x-axis represents the number of images generated with nudity detected by Nudenet, and the y-axis shows the type of body part detected. It shows that RGD generates the least number of images with nudity, demonstrating its superior performance in nudity removal compared to other methods.
read the caption
Figure 4: The nudity detection results by Nudenet, following prior works [Fan et al., 2023, Gandikota et al., 2023]. The Y-axis shows the exposed body part in the generated images, given the prompt, and the X-axis denotes the number of images generated by each unlearning method and SD. We exclude bars from the plot if the corresponding value is zero.

🔼 This figure compares the image generation quality of different unlearning methods. It shows generated images for two unlearning tasks: removing nudity and removing Van Gogh’s style. The results demonstrate that the proposed method (RGD) maintains high image-text alignment after unlearning, unlike existing methods like SalUn and ESD, which suffer from poor unlearning quality and degraded alignment.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.

🔼 This figure shows the impact of hyperparameters (λ and α) on the performance of the proposed method. The left plot displays the FID (Fréchet Inception Distance), a measure of generated image quality, while the right plot shows the RA (Remaining Accuracy), which quantifies how well the model performs on non-target classes after unlearning. The box plots illustrate the distribution of FID and RA values across different settings of the hyperparameters. Generally, lower FID and higher RA are preferred, indicating better performance. The results demonstrate that the RGD method consistently outperforms other methods across different hyperparameter settings.
read the caption
Figure 6: Performance analysis across different hyperparameter settings. Each box plot captures the variation over different a values for a given λ setting (λ∈ {0.5, 1.0, 5.0}), measuring both generation quality (FID, left) and remaining accuracy (RA, right). Lower FID indicates better generation quality, while higher RA indicates better model utility of non-target concepts.
🔼 This figure compares the image generation results of different text-to-image unlearning methods. It shows that the proposed method maintains high alignment between generated images and text prompts after removing specific concepts (nudity and Van Gogh style), unlike existing methods (SalUn and ESD) which fail to generate semantically correct images after unlearning. The figure visually demonstrates that the proposed method achieves higher alignment scores than the baselines. The alignment scores are provided for each method and task, showcasing the superior performance of the proposed approach in preserving text-image alignment while successfully removing undesired content.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.

🔼 This figure compares the image generation results of different text-to-image unlearning methods. Two unlearning tasks are shown: removing nudity from images and removing Van Gogh’s style from images. The figure demonstrates that the proposed method (Ours) maintains high alignment with the original image quality and prompt after unlearning, whereas other methods (SalUn and ESD) produce images that are poorly aligned and semantically incorrect. The alignment score (a metric measuring how well the generated image matches the given text prompt) is significantly better for the proposed method.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.

🔼 This figure compares the image generation quality of three different unlearning methods (SalUn, ESD, and the proposed method) against the original Stable Diffusion model (SD) after unlearning two specific concepts: nudity and Van Gogh’s art style. The results show that the proposed method maintains a high level of image-text alignment after unlearning, unlike the other methods which show significantly lower alignment scores and generate semantically incorrect images. The alignment score is a quantitative measure of how well the generated image matches the given text prompt.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.

🔼 This figure compares the image generation results of different text-to-image unlearning methods. Two unlearning tasks are shown: removing nudity and removing Van Gogh style. The figure demonstrates that the proposed method maintains high alignment scores between generated images and their text descriptions, unlike existing methods (SalUn and ESD) which show significantly lower alignment scores after unlearning.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.

🔼 This figure compares the image generation results of different text-to-image unlearning methods. It showcases the performance of SalUn, ESD, and the proposed method (Ours) against a baseline (SD) for two unlearning tasks: removing nudity and removing a Van Gogh style. The results demonstrate that the proposed method maintains high alignment between the generated images and the text prompt, even after unlearning, unlike the other methods which produce semantically incorrect outputs.
read the caption
Figure 1: Generated images using SalUn [Fan et al., 2023], ESD [Gandikota et al., 2023], and Ours after unlearning given the condition. Each row indicates different unlearning tasks: nudity removal, and Van Gogh style removal. Generated images from our approach and SD [Rombach et al., 2022] are well-aligned with the prompt, whereas SalUn and ESD fail to generate semantically correct images given the condition. On average, across 100 different prompts, SalUn shows the lowest clip alignment scores (0.305 for nudity removal and 0.280 for Van Gogh style removal), followed by ESD (0.329 and 0.330, respectively). Our approach achieves scores of 0.350 and 0.352 for these tasks, closely matching the original SD scores of 0.352 and 0.348.
More on tables
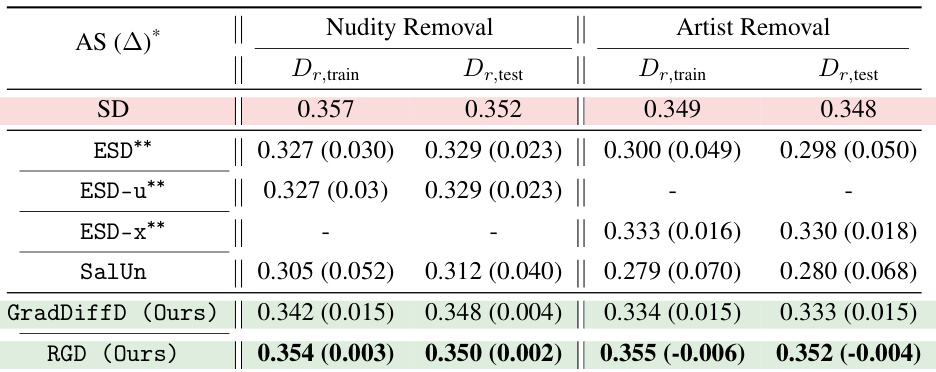
🔼 This table presents the results of the CLIP alignment score (AS) for both nudity and artist removal experiments. It compares the performance of the proposed method (RGD) against several baselines (SD, ESD, ESD-u, ESD-x, SalUn, and GradDiffD). The AS metric measures the semantic alignment between generated images and their corresponding text prompts after the unlearning process. The table shows AS scores for both the training (Dr,train) and test (Dr,test) sets of the remaining data. Green cells highlight results from the proposed method, while red cells show results from the pre-trained model (SD) to easily visualize the performance difference.
read the caption
Table 2: Nudity and artist removal: we calculate the clip alignment score (AS), following Lee et al. [2024], to measure the model alignment on the remaining set after unlearning. Cells highlighted in green indicate results from our method, while those in red indicate results from the pretrained model.

🔼 This table presents the results of a controlled experiment comparing the performance of different unlearning methods on CIFAR-10 diffusion models under two different conditions: Case 1, where the remaining dataset lacks diversity (only samples from two closely related classes); and Case 2, where the remaining dataset has balanced diversity (equal number of samples from all classes). The metrics evaluated are Unlearning Accuracy (UA), Remaining Accuracy (RA), and Fréchet Inception Distance (FID). The table shows that balanced diversity (Case 2) leads to significantly better performance on all metrics compared to limited diversity (Case 1).
read the caption
Table 3: Comparison of UA, RA, and FID for diversity-controlled experiments in CIFAR-10 diffusion models. In this context, Case 1 represents a scenario where the remaining set lacks diversity (i.e., it only includes samples from two closely related classes), while Case 2 includes equal samples from all classes. We note that we used the same remaining dataset size between both cases.
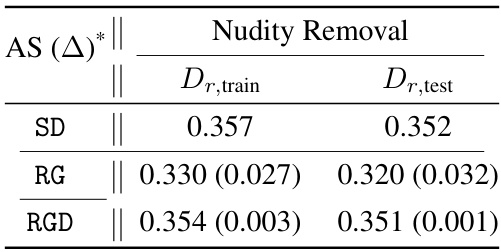
🔼 This table presents the results of CLIP alignment scores (AS) after performing nudity and artist removal. The AS metric measures how well the generated images align with the text prompts after the unlearning process. The table compares the AS scores of the proposed method (RGD) with those of several baselines (SD, ESD, ESD-u, SalUn, GradDiffD). The scores are presented separately for the training set (Dr,train) and the test set (Dr,test) of the remaining dataset. Cells highlighted in green show that the RGD method achieves alignment scores close to the pretrained model (SD), indicating that the proposed method successfully removes target concepts while maintaining model alignment.
read the caption
Table 2: Nudity and artist removal: we calculate the clip alignment score (AS), following Lee et al. [2024], to measure the model alignment on the remaining set after unlearning. Cells highlighted in green indicate results from our method, while those in red indicate results from the pretrained model.

🔼 This table presents a quantitative comparison of different unlearning methods applied to CIFAR-10 diffusion models. Each method is evaluated by sequentially removing each of the 10 classes from the model. The table shows the unlearning accuracy (UA) for the removed class, the remaining accuracy (RA) for the other 9 classes, and the Fréchet Inception Distance (FID), a measure of image quality. The results are averages across all 10 class removal experiments.
read the caption
Table 1: Quantitative evaluation of unlearning methods on CIFAR-10 diffusion-based generative models. Each method was evaluated by sequentially targeting each of the 10 CIFAR-10 classes for unlearning. For each target class, we measure unlearning accuracy (UA) specific to that class, remaining accuracy (RA) on the other 9 classes, and FID for generation quality. The reported values are averaged across all 10 class-specific unlearning experiments.

🔼 This table presents a quantitative comparison of different unlearning methods on CIFAR-10 image generation. For each method, three metrics are reported, averaged over 10 experiments where each of the 10 classes is targeted for unlearning. * UA (Unlearning Accuracy): Measures how well the model forgets the target class. A higher value indicates better unlearning. * RA (Remaining Accuracy): Measures the model’s performance on the remaining 9 classes after unlearning. A higher value suggests the unlearning process didn’t significantly harm the model’s ability to generate other classes. * FID (Fréchet Inception Distance): Measures the quality of the generated images. A lower value indicates better image quality.
read the caption
Table 1: Quantitative evaluation of unlearning methods on CIFAR-10 diffusion-based generative models. Each method was evaluated by sequentially targeting each of the 10 CIFAR-10 classes for unlearning. For each target class, we measure unlearning accuracy (UA) specific to that class, remaining accuracy (RA) on the other 9 classes, and FID for generation quality. The reported values are averaged across all 10 class-specific unlearning experiments.
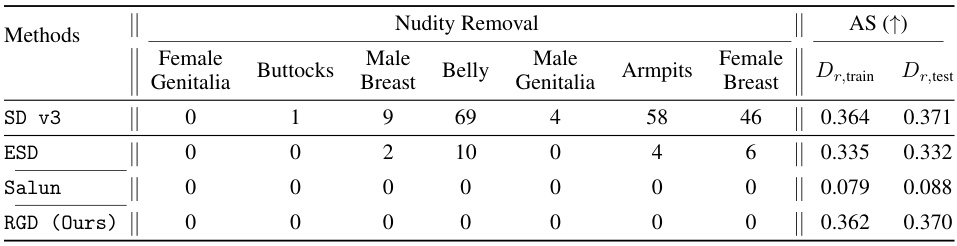
🔼 This table presents a quantitative comparison of various methods for nudity removal from Stable Diffusion models. It shows the number of detected body parts (female genitalia, buttocks, male breast, belly, male genitalia, armpits, female breast) in images generated after unlearning. The lower the count of body parts, the more effective the unlearning. The table also presents the CLIP alignment scores (AS) for both training (Dr,train) and test (Dr,test) prompts, which indicate the semantic consistency between generated images and given prompts. Higher AS scores indicate better alignment. The results demonstrate the effectiveness of the proposed RGD method in removing nudity while maintaining high alignment scores.
read the caption
Table 7: Comparison of nudity removal effectiveness and alignment scores across different methods on Stable Diffusion Model

🔼 This table presents a quantitative comparison of different methods for nudity removal in Stable Diffusion models. It shows the effectiveness of each method in terms of the number of detected body parts (female genitalia, male genitalia, buttocks, belly, female breast, male breast, armpits) remaining after the unlearning process. In addition to the raw counts, it also provides CLIP alignment scores (AS) for both training prompts (Dr,train) and a held-out test set (Dr,test). Higher alignment scores indicate better semantic alignment between the generated images and their prompts after the unlearning process.
read the caption
Table 7: Comparison of nudity removal effectiveness and alignment scores across different methods on Stable Diffusion Model
Full paper#



















