TL;DR#
Autonomous driving systems face significant energy challenges. Current systems struggle to meet the power constraints while ensuring high performance and safety. Spiking Neural Networks (SNNs) are presented as a promising solution due to their energy efficiency. However, the complexities of autonomous driving pose a challenge to fully leverage the power of SNNs.
This paper introduces Spiking Autonomous Driving (SAD), a unified SNN system designed for end-to-end autonomous driving. SAD integrates perception, prediction, and planning modules all based on SNNs. The system uses a novel dual-pathway approach for prediction to handle uncertainties effectively. Evaluated on the nuScenes dataset, SAD demonstrates competitive performance while showcasing significant energy efficiency compared to traditional deep learning methods. This highlights the potential of neuromorphic computing for sustainable and safety-critical autonomous vehicles.
Key Takeaways#
Why does it matter?#
This paper is significant because it demonstrates the feasibility of using spiking neural networks (SNNs) for energy-efficient autonomous driving, a crucial area for sustainable and safe automotive technology. It paves the way for further research into applying SNNs to other complex real-world applications and pushes the boundaries of neuromorphic computing. The end-to-end training methodology is also a valuable contribution, offering a more efficient approach compared to traditional methods.
Visual Insights#

🔼 This figure illustrates the Spiking Autonomous Driving (SAD) model’s workflow. It takes input from six cameras, processes this information through three main modules (perception, prediction, and planning), and outputs a steering angle and speed for navigation. The perception module creates a bird’s-eye view representation of the environment. The prediction module forecasts future states based on sequential data, and the planning module uses these predictions to generate safe trajectories.
read the caption
Figure 1: How SAD enables autonomous driving from vision to planning: The system processes inputs from six cameras across multiple frames. The perception module encodes feature information related to the present input frame (T = n), the prediction module predicts feature information of the next frame using sequential information (T = n + 1), and the model output generates a steering and acceleration plan. This process creates a bird's eye view (BEV) and trajectory plan for navigation.
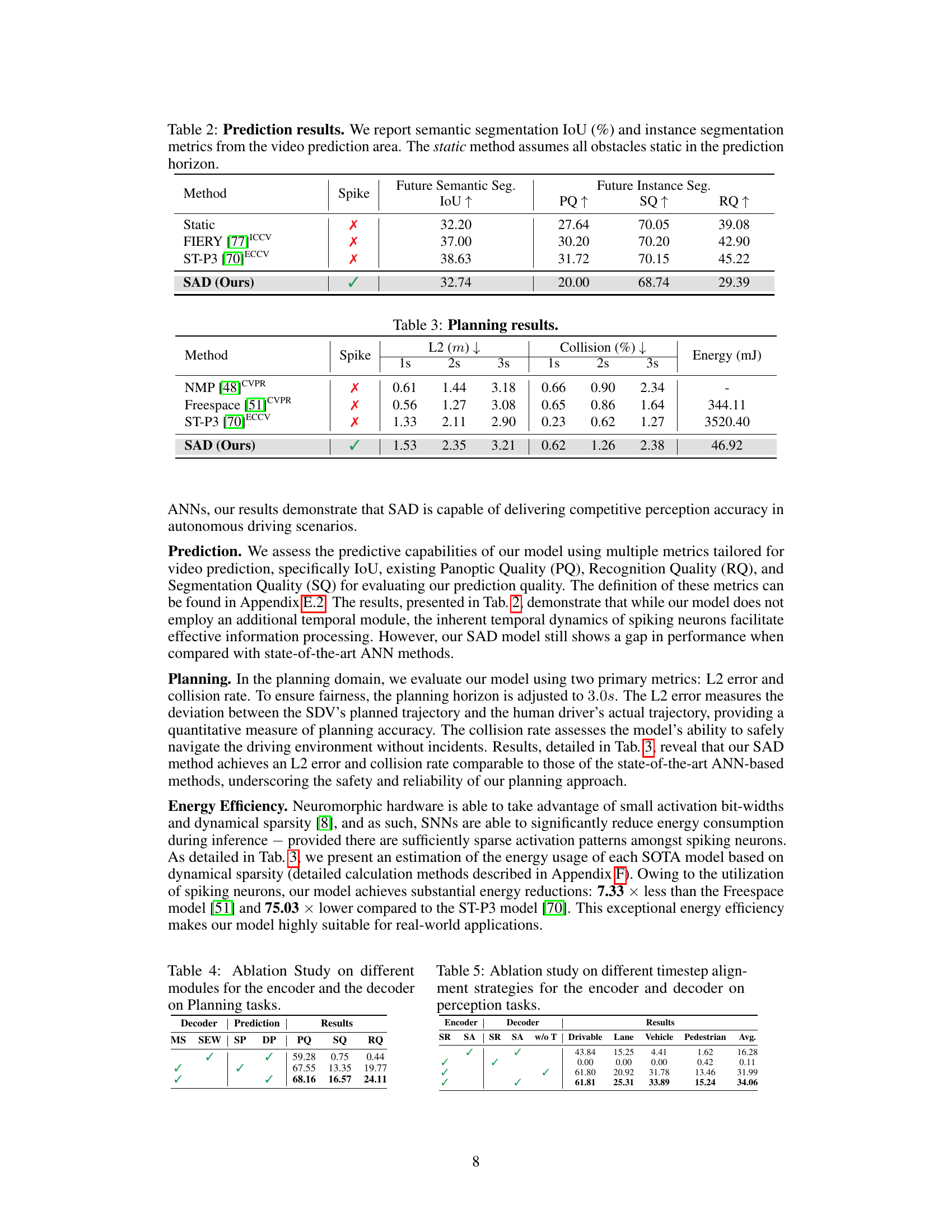
🔼 This table presents a comparison of the performance of various methods on the task of Bird’s Eye View (BEV) segmentation. It shows the Intersection over Union (IoU) scores achieved by different methods for four different categories: Drivable Area, Lane, Vehicle, and Pedestrian. The ‘Spike’ column indicates whether the method utilizes spiking neural networks (SNNs). The ‘Avg.’ column shows the average IoU across all four categories. The table demonstrates the performance of the proposed Spiking Autonomous Driving (SAD) method in comparison with several state-of-the-art approaches.
read the caption
Table 1: Perception results. We report the BEV segmentation IoU (%) of intermediate representations and their mean value.
In-depth insights#
SNN in Auto-Driving#
Spiking Neural Networks (SNNs) present a compelling avenue for revolutionizing autonomous driving. Their inherent energy efficiency, stemming from event-driven computation and sparse activity, directly addresses the significant power constraints of on-board systems. This makes SNNs particularly attractive for developing scalable and environmentally sustainable solutions. However, the challenge lies in the complexity of autonomous driving, requiring seamless integration of perception, prediction, and planning. While SNNs have shown promise in individual tasks like image classification, their application to the multifaceted demands of autonomous driving necessitates significant advancements in areas such as spatiotemporal processing, high-dimensional data handling, and robust training methodologies. Successful implementation will likely depend on the development of specialized neuromorphic hardware optimized for SNNs, thereby exploiting their full potential for real-time processing and low-power consumption. This combination of hardware and algorithmic innovation has the potential to unlock the next generation of safe, energy-efficient, and widely deployable self-driving vehicles.
Spatiotemporal Fusion#
Spatiotemporal fusion, in the context of autonomous driving using spiking neural networks (SNNs), is a critical technique for integrating information from multiple sensors and time steps. Effective spatiotemporal fusion is essential for accurate perception and prediction, enabling the vehicle to understand the dynamic environment and anticipate future events. This involves combining data from various sources, such as cameras, lidar, and radar, that capture different aspects of the scene at different moments in time. Challenges arise from handling the diverse data modalities and high dimensionality of spatiotemporal data, requiring sophisticated fusion methods. SNNs’ event-driven nature makes them potentially well-suited for this task; spiking neurons can efficiently encode temporal information through their spike timing, which can be leveraged to perform temporal fusion. However, existing SNN architectures often struggle with effective fusion of high-dimensional spatiotemporal data, necessitating innovative approaches that can successfully merge and process sensor data over time. The success of such a system hinges on the ability to create a comprehensive and accurate representation of the dynamic environment for planning safe and efficient driving maneuvers.
Dual-Path Prediction#
The concept of “Dual-Path Prediction” in the context of autonomous driving using spiking neural networks presents a novel approach to forecasting future states. It suggests that using two separate pathways for processing temporal information — one focusing on past data and the other on future predictions — could significantly improve prediction accuracy. By combining these two pathways, the model would presumably gain a more holistic understanding of temporal dynamics, enabling it to better predict future states in complex and dynamic environments. This approach leverages the event-driven and energy-efficient nature of spiking neural networks, leading to potentially lower latency and higher efficiency. The fusion of these two streams before feeding the information to a planning module will enhance decision-making and trajectory refinement. However, this method requires further exploration of optimal fusion techniques and how it handles uncertainty and noise in real-world sensor data. The effectiveness and robustness of this dual-pathway method compared to more traditional sequential approaches warrants thorough investigation and evaluation.
Energy Efficiency#
The research paper emphasizes the crucial role of energy efficiency in autonomous driving, particularly highlighting the advantages of spiking neural networks (SNNs). SNNs’ event-driven nature and sparse, single-bit activations are presented as key to achieving substantial energy savings compared to traditional artificial neural networks (ANNs). The paper demonstrates that SNN-based autonomous driving systems can achieve competitive performance with ANNs while offering improved energy efficiency and reduced latency. This is a significant advancement, addressing the substantial power consumption challenges of current autonomous driving systems and advancing towards environmentally sustainable automotive technology. Quantitative energy consumption comparisons between SNNs and ANNs are included, demonstrating significant reductions in energy usage, emphasizing the potential for neuromorphic computing in this domain. However, the paper also acknowledges the need for further research and real-world testing to fully realize the benefits of SNN-based autonomous systems in terms of energy efficiency and reliability.
Future Work#
Future work in spiking neural network (SNN) based autonomous driving systems could focus on several key areas. Improving the scalability and real-time performance of SNNs is crucial, especially for complex environments. This involves optimizing SNN architectures for neuromorphic hardware and exploring more efficient training methods. Addressing the limitations in handling long temporal dependencies present in autonomous driving is another important direction. Research into novel SNN architectures and temporal processing techniques could significantly enhance prediction accuracy and planning capabilities. Extending the system’s robustness to noisy and diverse real-world driving conditions is essential for safe and reliable autonomous driving, requiring improved sensor fusion and handling of uncertainties in perception and prediction. Finally, a comprehensive benchmark dataset specifically designed for evaluating SNN-based autonomous driving systems would facilitate more objective comparisons between different models and promote more robust research advancements in this field. Furthermore, exploring the integration of SNNs with traditional deep learning methods to leverage the strengths of both approaches could lead to a more efficient and powerful system.
More visual insights#
More on figures

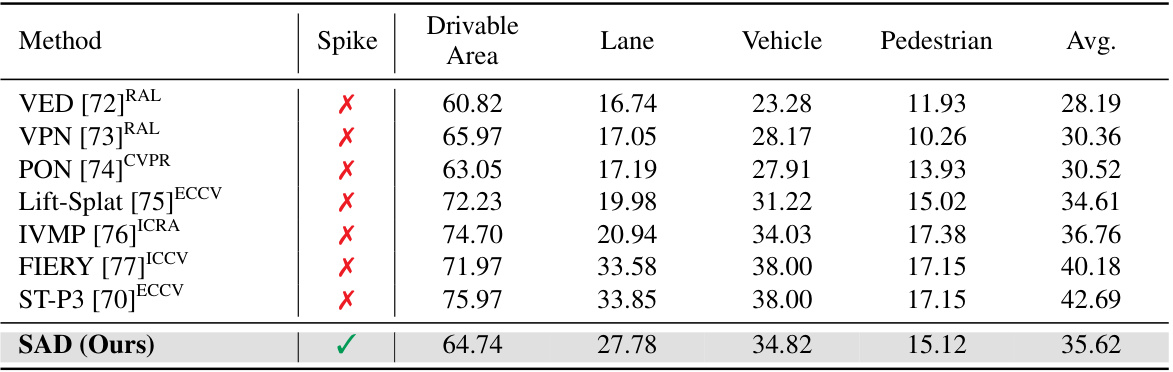
🔼 This figure shows a detailed overview of the Spiking Autonomous Driving (SAD) model’s architecture, illustrating the flow of information and processing steps across the three main modules: perception, prediction, and planning. The perception module takes multi-view camera data, processes it using spiking neural networks (SNNs), such as a ResNet, to create a bird’s eye view (BEV) representation of the scene. This representation is then passed to the prediction module, which uses spiking neurons to predict future states. Finally, the planning module uses the predictions and scene understanding to generate safe and efficient driving commands.
read the caption
Figure 2: Overview of SAD. The multi-view features from the perception encoder, including a spiking ResNet with inverted bottleneck and spiking DeepLab head, are fed into a prediction module using spiking neurons. The perception decoder then generates lane divider, pedestrian, vehicle and drivable area predictions. Finally, the planning module models the scene and generates future predictions to inform rule-based command decisions for turning, stopping, and goal-directed navigation.
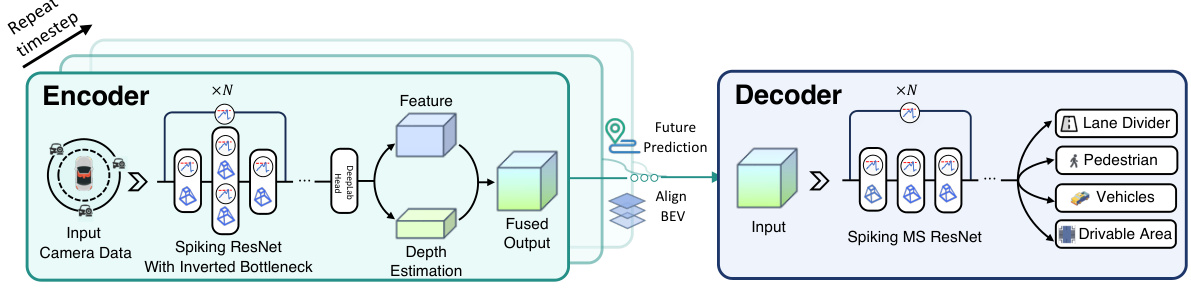
🔼 This figure illustrates the architecture of the perception module in the Spiking Autonomous Driving (SAD) model. The encoder processes data from multiple cameras, using a spiking ResNet with an inverted bottleneck to extract features and depth estimations. These are combined, and then the decoder uses this information to generate a bird’s eye view representation of the scene, predicting the location of lane dividers, pedestrians, vehicles, and drivable areas.
read the caption
Figure 3: The perception module. The encoder takes multi-camera input data, passes it through a spiking ResNet with inverted bottleneck to generate feature representations, each of which has its own depth estimation. These are fused and passed to the decoder, which generates predictions for lane dividers, pedestrians, vehicles and drivable areas.

🔼 This figure illustrates the dual-pathway prediction model used in the paper. It shows how the model uses two parallel streams of LIF neurons to predict future states. One pathway (Neuron a) incorporates uncertainty about future states using a Gaussian distribution. The other pathway (Neuron b) uses historical information to compensate for missing data and provide a more robust prediction. The outputs from both pathways are then fused together to generate the final prediction.
read the caption
Figure 4: Dual pathway modeling for prediction. Neuron a captures future multi-modality by incorporating uncertainty distribution. Neuron b compensates for information gaps using past variations.

🔼 This figure shows a qualitative comparison of the Spiking Autonomous Driving (SAD) model and a traditional Artificial Neural Network (ANN) model on the nuScenes dataset. It showcases the input from six cameras (a), the planning output from an ANN (b), and the planning output from the SAD model (c). The comparison highlights the SAD model’s ability to generate a safe and comparable trajectory to the ANN model, despite using spiking neural networks.
read the caption
Figure 5: Qualitative Results of the SAD Model on the nuScenes Dataset. (a) displays six camera view inputs utilized by the model. (b) illustrates the planning result of the ANN model, and (c) presents the planning results of our SAD model. The comparison shows that our SAD model can achieve performance comparable to that of the ANN model and successfully generate a safe trajectory.

🔼 This figure compares the architectures of MS-ResNet and SEW-ResNet. Both are residual learning methods for Spiking Neural Networks (SNNs) designed to overcome the degradation problem in deep SNNs. MS-ResNet creates shortcut connections between membrane potentials of different layers, while SEW-ResNet uses shortcut connections between the output spikes of different layers. The figure illustrates the distinct ways these architectures handle the identity mapping for residual connections, showing the spatial and temporal forward propagation paths within each.
read the caption
Figure 6: MS-ResNet and SEW-ResNet.

🔼 This figure displays a comparison of the planning results between the proposed Spiking Autonomous Driving (SAD) model and a traditional Artificial Neural Network (ANN) model. Subfigure (a) shows the six camera view inputs used by both models. Subfigure (b) displays the results from an ANN model, visualizing the planned trajectory, drivable areas, lane markings, vehicles, and pedestrians. Subfigure (c) displays the corresponding results generated by the SAD model. The comparison highlights that SAD, despite using spiking neurons, performs comparably to the ANN and produces a safe and viable trajectory.
read the caption
Figure 5: Qualitative Results of the SAD Model on the nuScenes Dataset. (a) displays six camera view inputs utilized by the model. (b) illustrates the planning result of the ANN model, and (c) presents the planning results of our SAD model. The comparison shows that our SAD model can achieve performance comparable to that of the ANN model and successfully generate a safe trajectory.
More on tables
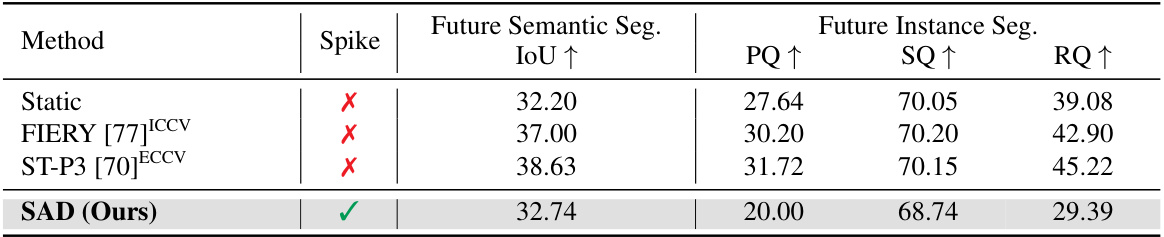
🔼 This table presents a comparison of different methods for video prediction, including a static method (assuming all obstacles are static) and several dynamic methods (FIERY, ST-P3, and SAD). The evaluation metrics include semantic segmentation IoU, and instance segmentation metrics (PQ, SQ, RQ). The table shows the performance of each method across these metrics, indicating the accuracy of predicting future states of the scene.
read the caption
Table 2: Prediction results. We report semantic segmentation IoU (%) and instance segmentation metrics from the video prediction area. The static method assumes all obstacles static in the prediction horizon.

🔼 This table presents the quantitative results of the planning module, comparing the proposed SAD model to several state-of-the-art methods. It shows the L2 error (in meters) at 1, 2, and 3 seconds into the future, the collision rate (in percentage) at 1, 2, and 3 seconds, and the energy consumed (in millijoules) for the entire planning process. The metrics evaluate the accuracy and safety of the planned trajectory. The ‘Spike’ column indicates whether the method utilizes spiking neural networks.
read the caption
Table 3: Planning results.
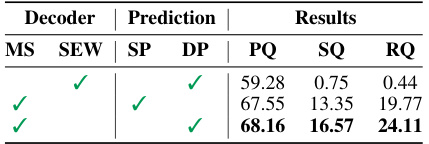
🔼 This table presents the ablation study results on different encoder and decoder modules for planning tasks. It shows the impact of using different architectures (MS-ResNet vs. SEW-ResNet), single vs. dual pathways in the prediction module, and resulting performance metrics (PQ, SQ, RQ). The checkmarks (✓) indicate which module configurations were used in each row of the experiment.
read the caption
Table 4: Ablation Study on different modules for the encoder and the decoder on Planning tasks.
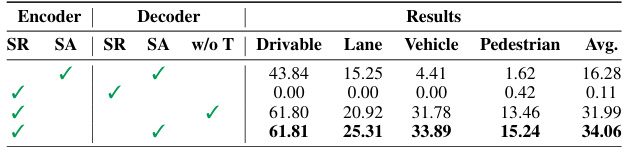
🔼 This table presents the ablation study results on different timestep alignment strategies applied to the encoder and decoder for perception tasks in the Spiking Autonomous Driving (SAD) model. It shows the impact of using Sequence Repetition (SR) or Sequential Alignment (SA) for both the encoder and decoder, and also the effect of removing temporal processing entirely from the decoder (‘w/o T’). The results are evaluated in terms of Intersection over Union (IoU) for Drivable Area, Lane, Vehicle, and Pedestrian segmentation tasks. The table demonstrates how different timestep strategies affect the model’s performance in each task and overall.
read the caption
Table 5: Ablation study on different timestep alignment strategies for the encoder and decoder on perception tasks.

🔼 This table compares the performance of various models (ANN2SNN, SCNN, Spiking Transformer, and SMLP) on the ImageNet-1K dataset. It shows the architecture used, whether the model was spike-driven, the number of parameters (in millions), the number of timesteps used in the model, and the achieved accuracy (%). The table highlights the performance of the proposed STM (Spiking Token Mixer) model within the context of other state-of-the-art SNN models.
read the caption
Table 6: Performance on ImageNet-1K [67]. Note, “Spike”, “Para”, and “Step” denote “Spike-driven”, “Parameters”, and “Timestep”.
Full paper#