TL;DR#
Traditional speech separation methods struggle with computational cost and the information bottleneck caused by late feature separation. This paper addresses these by proposing an intuitive early separation strategy. The method is inefficient as it handles long sequences via dual-path processing which is computationally expensive.
The paper introduces SepReformer, an asymmetric encoder-decoder model. The encoder analyzes features, then separates them into speaker-specific sequences. A weight-shared decoder reconstructs these sequences, performing cross-speaker processing and learning to discriminate features. Global and local Transformer blocks improve efficiency, replacing dual-path processing. The combination of these methods achieves state-of-the-art performance with significantly less computation.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents SepReformer, a novel asymmetric encoder-decoder model for speech separation that achieves state-of-the-art performance with significantly reduced computation. This addresses a key challenge in the field by improving efficiency without sacrificing accuracy, opening new avenues for research in real-time and resource-constrained speech processing applications. The introduction of global and local Transformer blocks also offers a more efficient alternative to dual-path models, impacting future architectures. SepReformer’s innovative approach to early feature separation and its improved Transformer block design make it highly relevant to ongoing efforts to advance speech separation technology.
Visual Insights#
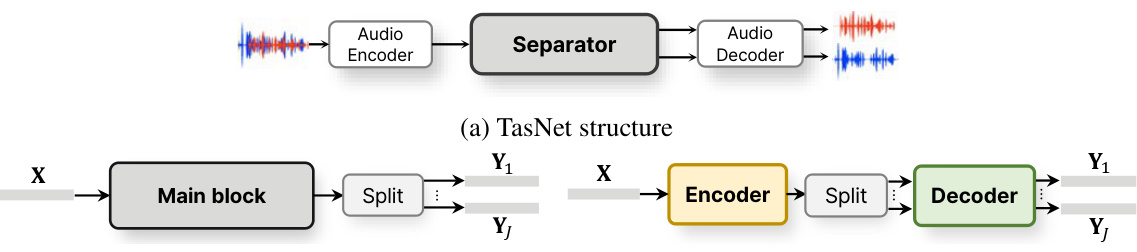
🔼 This figure shows three different architectures for speech separation. (a) shows the TasNet architecture, a single-channel speech separation method that processes audio in the latent space instead of the time-frequency domain. (b) shows a conventional separator design where speaker-specific features are separated at the final stage of the network. (c) shows the proposed asymmetric encoder-decoder network where the feature sequence is expanded into speaker-specific sequences earlier in the process, allowing for more intuitive feature separation.
read the caption
Figure 1: Block diagrams of (a) TasNet and separator designs of the (b) conventional and (c) proposed networks. The proposed network consists of separation encoder and reconstruction decoder based on weight sharing. After an encoder, separated features are independently processed by a decoder network.
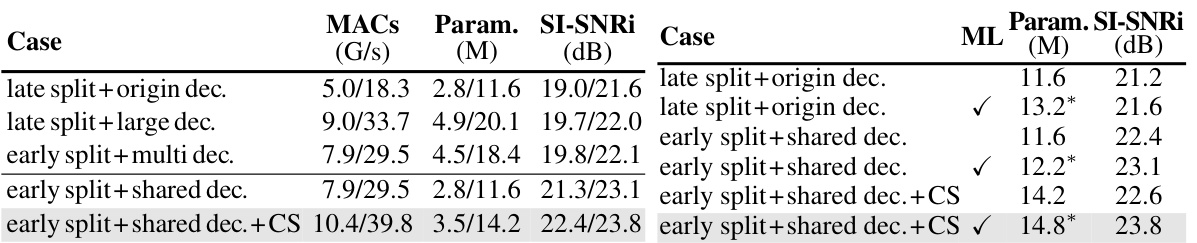
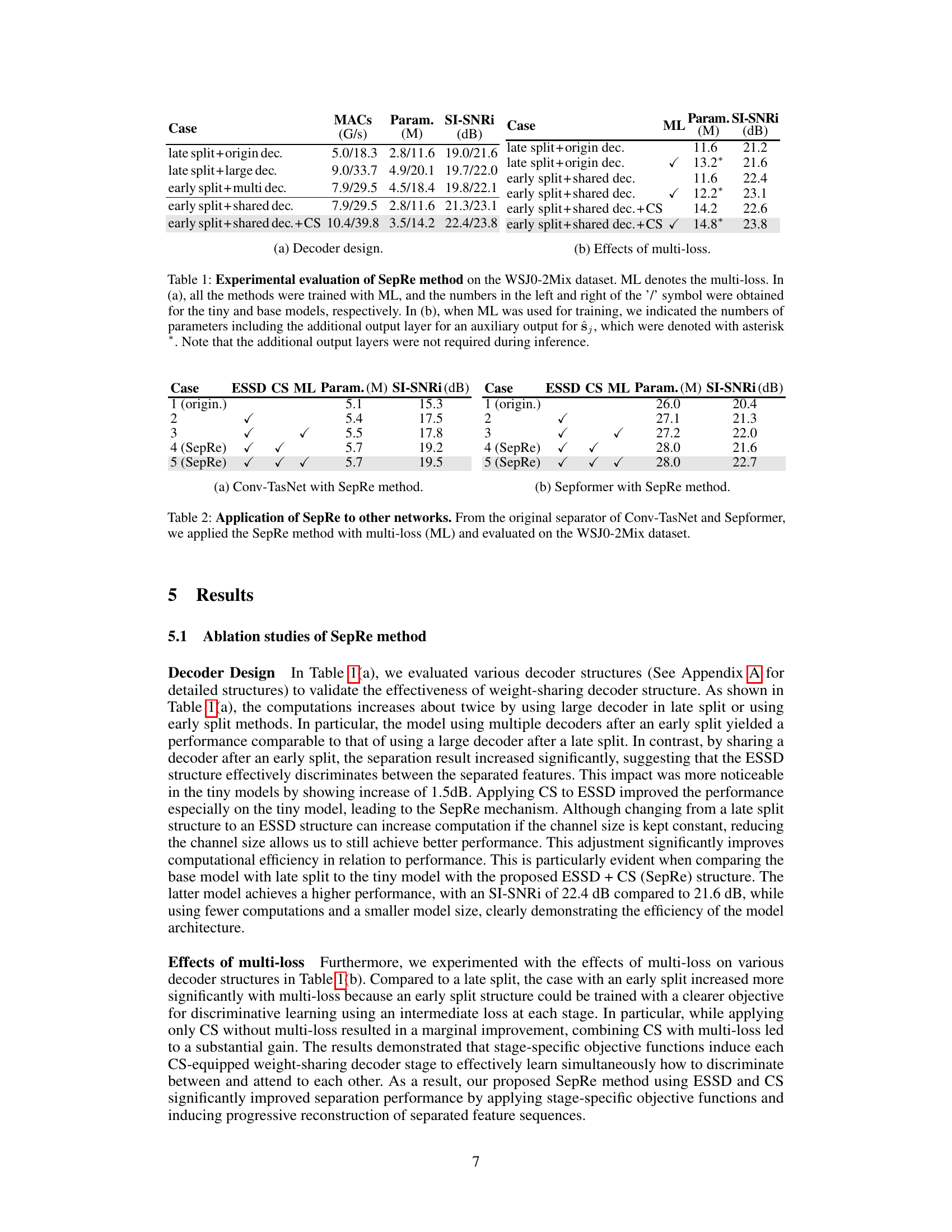
🔼 This table presents the experimental results of the proposed SepRe method on the WSJ0-2Mix dataset. It compares different decoder designs (late split, early split with multiple decoders, early split with shared decoder, and early split with shared decoder and cross-speaker (CS) transformer) and evaluates the impact of multi-loss training. The results are shown for both tiny and base model sizes, indicating the performance at different model scales. Note that additional parameters are included for multi-loss, but these are not used during inference.
read the caption
Table 1: Experimental evaluation of SepRe method on the WSJ0-2Mix dataset. ML denotes the multi-loss. In (a), all the methods were trained with ML, and the numbers in the left and right of the '/' symbol were obtained for the tiny and base models, respectively. In (b), when ML was used for training, we indicated the numbers of parameters including the additional output layer for an auxiliary output for ŝj, which were denoted with asterisk *. Note that the additional output layers were not required during inference.
In-depth insights#
Asymmetric Design#
An asymmetric design in a speech separation model refers to a network architecture where the encoder and decoder have distinct, non-mirrored roles. Instead of symmetrical processing, the encoder focuses on feature analysis and initial separation, potentially splitting the input features early into speaker-specific representations. The decoder then focuses on reconstructing the separated signals, often employing weight sharing or cross-speaker processing to improve the quality of separated speech. This design contrasts with conventional symmetrical encoders and decoders where both components perform nearly identical, mirrored processing. An advantage is that the separation task is not fully reliant on the final layers of the network. This early separation facilitates more effective learning and reduces computational burden, especially beneficial when handling long sequences. The asymmetry promotes more efficient feature discrimination within the decoder, as the decoder focuses explicitly on reconstruction. A shared decoder benefits from learning cross-speaker relationships, improving the quality of individual speaker’s speech.
Long Seq. Handling#
The research paper explores handling long sequences in speech separation models, a critical challenge due to computational constraints and performance degradation. Traditional approaches often employ chunking mechanisms (e.g., dual-path models), dividing long sequences into smaller segments to process them more efficiently. However, this method introduces complexities and may negatively impact performance due to the need to stitch segments together. The paper proposes an alternative approach using global and local Transformer blocks. This asymmetric design directly handles long sequences more efficiently without chunking, improving both computational speed and overall performance. The global Transformer block captures global context, while the local block focuses on local details, effectively replacing the role of inter- and intra-chunk processing found in the dual-path architecture. This innovative approach allows for the efficient modeling of long sequences crucial for accurate speech separation, representing a significant advancement over existing methods.
Multi-Loss Training#
Multi-loss training in speech separation aims to enhance model performance by incorporating multiple loss functions during training. Instead of relying solely on a single objective, such as Signal-to-Distortion Ratio (SDR), it leverages complementary metrics to guide the learning process. This strategy addresses the limitations of a single-loss approach, which might overlook crucial aspects of the separation task. For instance, including a perceptual loss function, like PESQ or STOI, can improve the perceived quality of separated speech, even if the SDR isn’t significantly improved. Furthermore, using multiple loss functions can mitigate issues stemming from the dominance of a specific loss. A model heavily optimized for SDR, for example, might produce overly aggressive outputs which sacrifices other important metrics such as source separation quality or computational efficiency. Multi-loss training provides a flexible framework, allowing researchers to tailor the loss weighting scheme to meet specific requirements. Proper weighting of losses is crucial, as an imbalance can hinder performance. The effectiveness of multi-loss training depends heavily on choosing appropriate and relevant loss functions that capture different facets of the separation task and data characteristics. Careful tuning of hyperparameters for loss weighting is needed to achieve optimal results. Ultimately, multi-loss training offers a powerful approach for improving speech separation models, leading to potentially superior performance and more robust separation outcomes.
SepReformer Eval#
A hypothetical ‘SepReformer Eval’ section would deeply analyze the performance of the SepReformer model. This would involve a multifaceted evaluation across diverse benchmark datasets, comparing it against state-of-the-art baselines. Key metrics, such as Signal-to-Distortion Ratio (SDR), Signal-to-Interference Ratio (SIR), and perceptual evaluation scores (PESQ, STOI), would be reported and thoroughly discussed. The evaluation should not only quantify performance but also delve into the model’s behavior under various conditions: different noise levels, reverberation, speaker characteristics, and varying lengths of audio sequences. A detailed analysis would explore the model’s strengths and weaknesses, highlighting its computational efficiency compared to existing methods. The implications of the results, particularly concerning real-world applications (like speech enhancement in noisy environments or robust speech recognition), should be explored. Ablation studies investigating the impact of specific model components (e.g., global and local Transformer blocks, early split strategy, weight-shared decoder) are crucial to understand SepReformer’s design choices. Finally, a discussion on limitations and potential areas of improvement would showcase a thoughtful assessment of the model’s capabilities and limitations.
Future Works#
The paper’s core contribution is an innovative asymmetric encoder-decoder model for speech separation. Future work could explore several avenues to enhance this model. One promising direction is extending the model to handle more than two speakers, which is a significant challenge in real-world scenarios. Further research could investigate incorporating more sophisticated noise models into the training process to improve robustness in noisy environments. Another area for improvement is developing a more effective mechanism for handling variable-length sequences, potentially through more advanced techniques in sequence modeling or by combining this framework with other powerful sequence processing models. Finally, exploring different loss functions besides SI-SNR could lead to better performance and convergence. Addressing these points would further enhance the practicality and state-of-the-art performance of this novel speech separation approach.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the speech separator used in the SepReformer model. The separator is composed of three main parts: 1. Separation Encoder: This part processes the input audio signal and progressively downsamples the temporal dimension while using a combination of global and local Transformer blocks. This allows the model to capture both local and global context efficiently. 2. Speaker Split Module: After the downsampling in the encoder, the feature sequence is split into multiple sequences according to the number of speakers to be separated. 3. Reconstruction Decoder: The decoder receives the separated sequences from the speaker split module and upsamples them to reconstruct the original speech signals for each speaker. The reconstruction process involves weight-shared layers, which directly learn to discriminate between the features of different speakers. Cross-speaker processing is also incorporated to further improve the accuracy of the separation. The decoder also uses global and local Transformer blocks for efficient processing and reconstruction.
read the caption
Figure 2: The architecture of the separator in the proposed SepReformer. The separator consists of three parts: separation encoder, speaker split module, and reconstruction decoder.
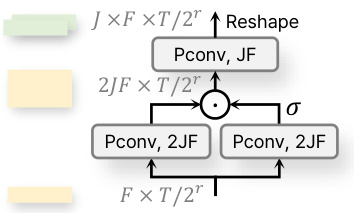
🔼 This figure shows the detailed architecture of the speaker split module. The input features from the encoder are reshaped to include a dimension for the number of speakers (J). These are then processed by two linear layers with gated linear units (GLU) activation before being normalized by layer normalization (LN). The output is a set of speaker-specific features ready for the decoder.
read the caption
Figure 3: Speaker split module

🔼 This figure shows the architecture of the global and local Transformer blocks used in the SepReformer model for efficient long sequence processing. The global Transformer block uses an efficient gated attention (EGA) mechanism for capturing global dependencies, while the local Transformer block employs convolutional local attention (CLA) for local context modeling. Both blocks are based on the Transformer structure, including multi-head self-attention (MHSA) and feed-forward network (FFN) modules. The figure details the specific components within each block, including downsampling/upsampling operations, point-wise convolutions, and activation functions.
read the caption
Figure 4: Block diagrams of global and local Transformer for sequence processing. ↓ and ↑ in EGA denote downsampling with average pooling and upsampling with nearest interpolation. Note that the point-wise convolution (Pconv) layer performs an equivalent operation to the linear layer as channel mixing. The hidden dimension of GCFN is set to 3F after GLU to maintain a similar parameter size to the FFN with a hidden size of 4F. Therefore, while the FFN has parameter size of 8F2, GCFN has a slightly larger size of about 9F2.

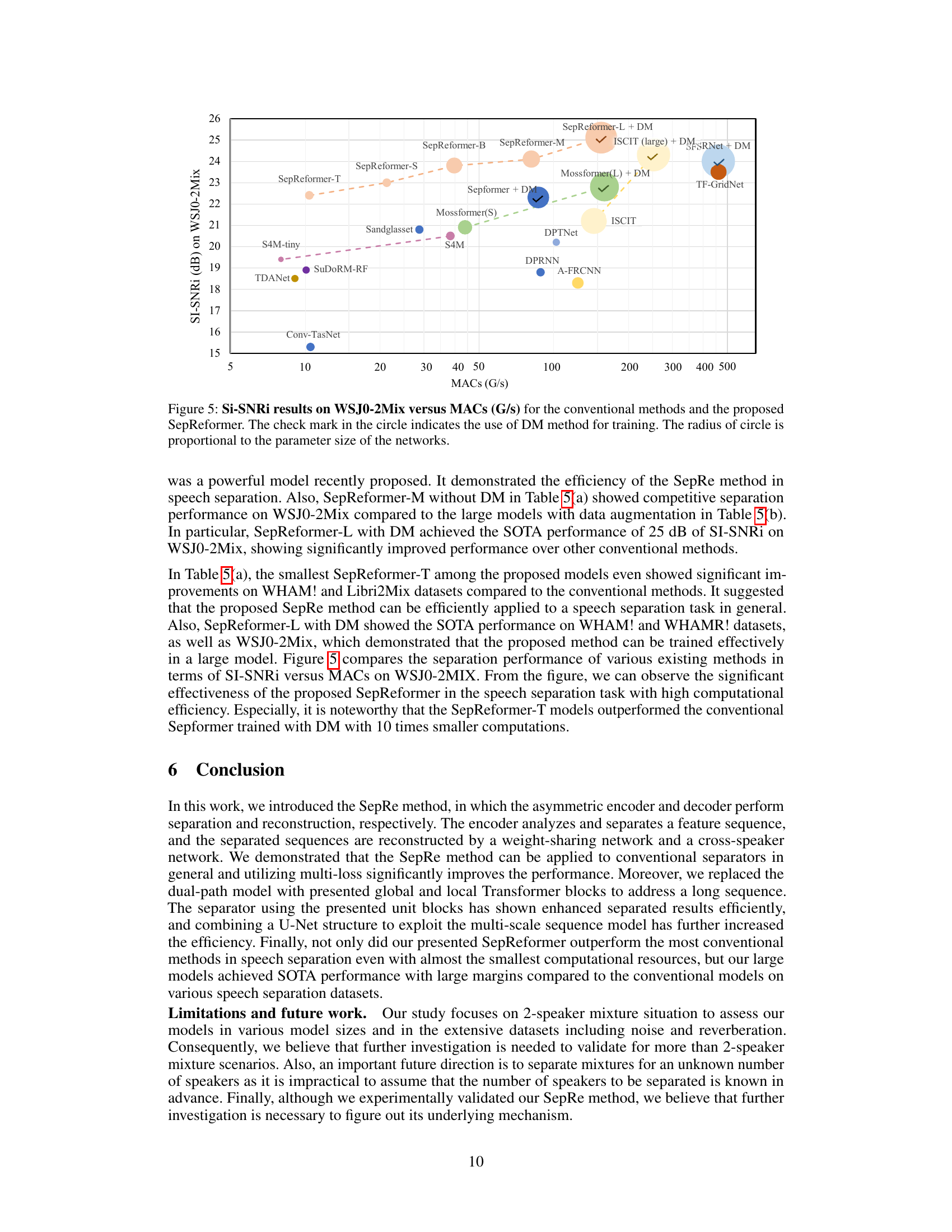
🔼 This figure compares the performance of various speech separation models, including the proposed SepReformer, on the WSJ0-2Mix dataset. The x-axis represents the model’s computational cost (MACs, millions of multiply-accumulate operations per second), and the y-axis shows the SI-SNRi (scale-invariant signal-to-noise ratio improvement), a measure of separation quality. The SepReformer models are shown at different sizes (T, S, B, M, L). The size of each circle in the figure is proportional to the model’s number of parameters. The check marks indicate models that used dynamic mixing (DM) data augmentation during training. The graph illustrates that SepReformer achieves state-of-the-art performance (highest SI-SNRi) for a given computational cost compared to other methods, particularly at smaller model sizes.
read the caption
Figure 5: SI-SNRi results on WSJ0-2Mix versus MACs (G/s) for the conventional methods and the proposed SepReformer. The check mark in the circle indicates the use of DM method for training. The radius of circle is proportional to the parameter size of the networks.

🔼 This figure compares four different decoder designs used in speech separation experiments. The designs are categorized by the location of the split operation (early vs. late) and whether the decoder uses shared weights or multiple decoders. The key difference between designs A and B is that A has a late split, meaning the separation of the audio is done after encoding, whereas design B has an early split, where the separation of the audio is done before decoding, leading to multiple independent decoders. Designs C and D both have early splits, but C uses a shared-weight decoder (simpler), and D adds a cross-speaker (CS) block to improve interaction between the separated speakers. All designs use a series of global and local Transformer blocks in their encoder and decoder.
read the caption
Figure 6: Block diagrams of various decoder designs experimented in Table 1 of subsection 5.1. In all cases, the encoder and decoder consists of R stages and the blocks were stacks of global and local Transformer block in our cases.

🔼 This figure illustrates four different decoder designs explored in the paper’s experiments to evaluate the effectiveness of the proposed weight-sharing decoder structure. The designs vary in whether the split occurs early or late in the processing pipeline and in the number of decoders used (single shared decoder or multiple independent decoders) and whether a cross-speaker transformer block is included. The designs are compared in Table 1 of Section 5.1 to assess the impact on separation performance.
read the caption
Figure 6: Block diagrams of various decoder designs experimented in Table 1 of subsection 5.1. In all cases, the encoder and decoder consists of R stages and the blocks were stacks of global and local Transformer block in our cases.
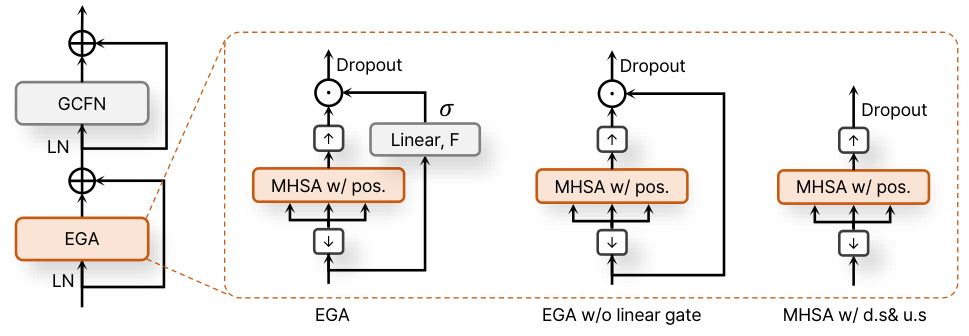
🔼 This figure shows the architecture of the global and local Transformer blocks used in the SepReformer model for efficient long sequence processing. The global Transformer block uses an efficient gated attention (EGA) module for capturing global dependencies, while the local Transformer block uses a convolutional local attention (CLA) module for capturing local contexts. Both blocks are based on the Transformer block structure, with multi-head self-attention (MHSA) and feed-forward network (FFN) modules. Downsampling and upsampling are used in the EGA module to reduce computation and focus on global information.
read the caption
Figure 4: Block diagrams of global and local Transformer for sequence processing. ↓ and ↑ in EGA denote downsampling with average pooling and upsampling with nearest interpolation. Note that the point-wise convolution (Pconv) layer performs an equivalent operation to the linear layer as channel mixing. The hidden dimension of GCFN is set to 3F after GLU to maintain a similar parameter size to the FFN with a hidden size of 4F. Therefore, while the FFN has parameter size of 8F2, GCFN has a slightly larger size of about 9F2.
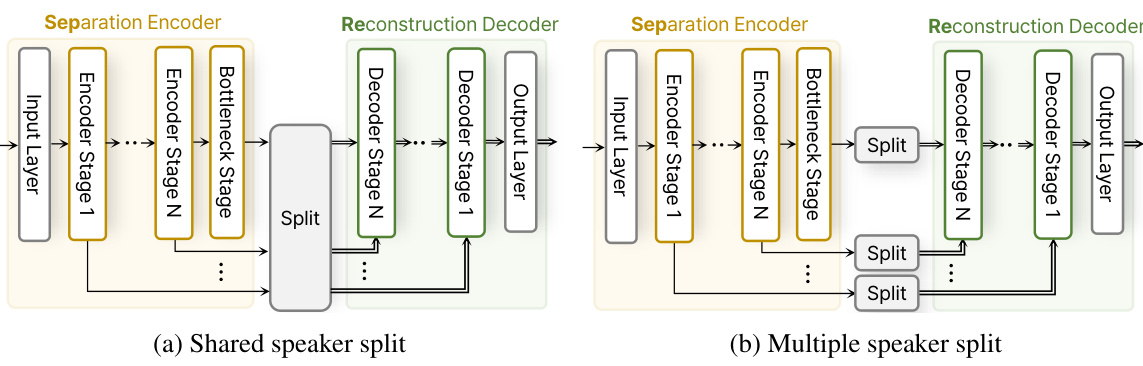
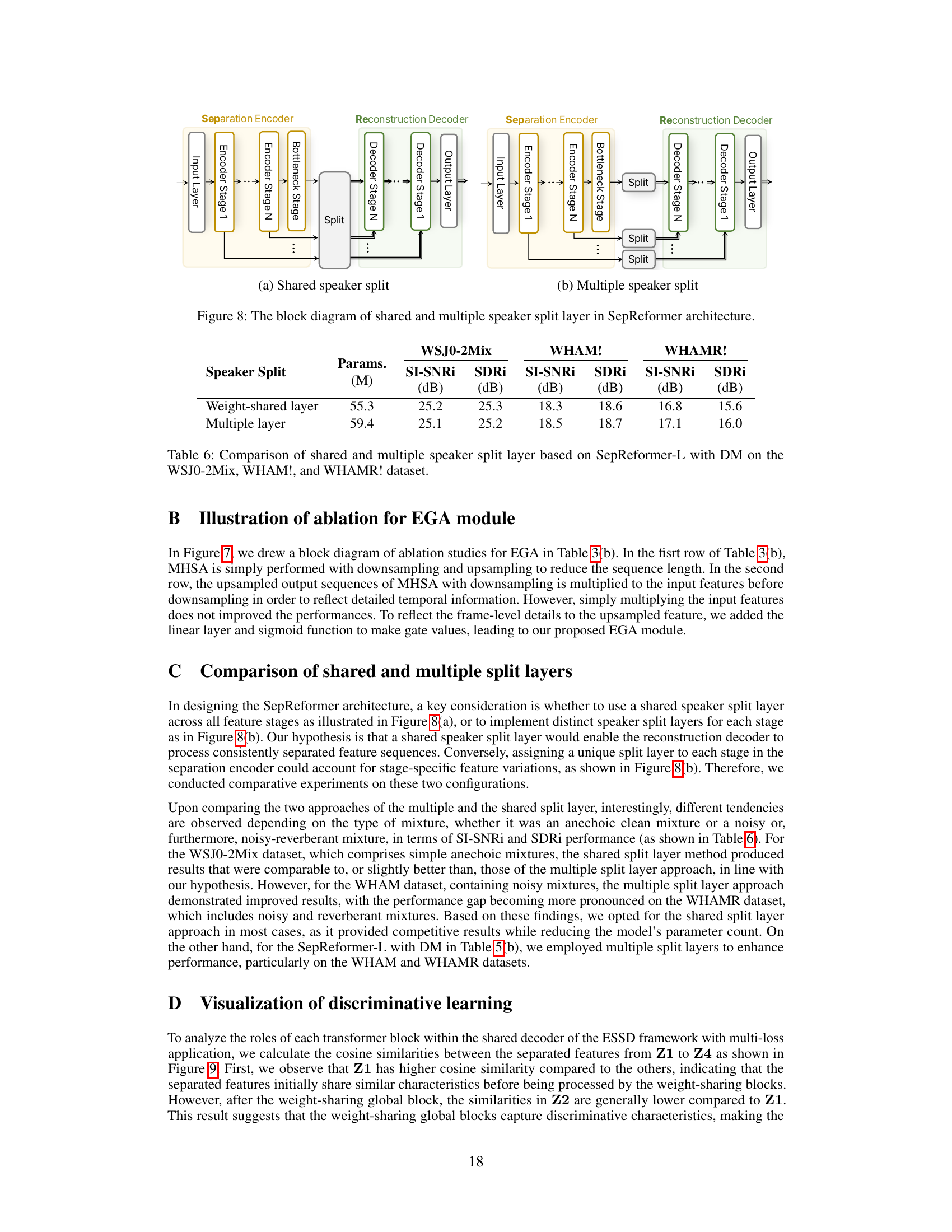
🔼 This figure compares two different architectures for speaker split layers in the SepReformer model. (a) shows a shared speaker split, where a single split layer is used to separate the features across all stages of the encoder. This approach aims for consistent processing across all stages. (b) illustrates a multiple speaker split, using a separate split layer at each stage of the encoder. This variation allows the network to account for stage-specific differences in the features. The choice between these architectures can impact the model’s performance and efficiency.
read the caption
Figure 8: The block diagram of shared and multiple speaker split layer in SepReformer architecture.

🔼 This figure visualizes the cosine similarity between the separated features (Z1 to Z4) over time in the first decoder stage of the SepReformer model. The top two panels show spectrograms of speaker 1 and speaker 2, respectively, providing context for the similarity analysis. The bottom panel displays the cosine similarity curves for Z1, Z2, Z3, and Z4. The plot demonstrates how the cosine similarity changes over time and across different stages of feature processing within the decoder. Each stage’s processing (global block, local block, and cross-speaker block) affects the similarity measures, showing the model’s ability to differentiate the two speakers.
read the caption
Figure 9: Plot of cosine similarities for the two separated features in the first decoder stage using a sample mixture in WSJ0-2Mix dataset.

🔼 This figure visualizes cosine similarity between separated features at different stages within the decoder of the SepReformer model. The figure shows that initially, separated features (Z1) share similar characteristics. As they pass through global and local transformer blocks, the similarity decreases (Z2, Z3), indicating the effectiveness of the blocks in enhancing discriminative features. Finally, the cross-speaker (CS) block increases similarity (Z4) demonstrating its role in recovering information lost during the separation process.
read the caption
Figure 9: Plot of cosine similarities for the two separated features in the first decoder stage using a sample mixture in WSJ0-2Mix dataset.
More on tables

🔼 This table presents the results of applying the proposed SepRe method (Separation-Reconstruction method with cross-speaker attention) to two existing speech separation networks: Conv-TasNet and Sepformer. The original separators of both networks were modified by incorporating the ESSD (Early Split with Shared Decoder) framework and multi-loss training. The table compares the performance (SI-SNRi in dB) and model size (parameters in millions) of the modified networks to their original versions and also to various combinations of features within the SepRe method (including and excluding Cross-Speaker modules and multi-loss training). The results highlight the effectiveness of the SepRe method in improving speech separation performance across different network architectures.
read the caption
Table 2: Application of SepRe to other networks. From the original separator of Conv-TasNet and Sepformer, we applied the SepRe method with multi-loss (ML) and evaluated on the WSJ0-2Mix dataset.

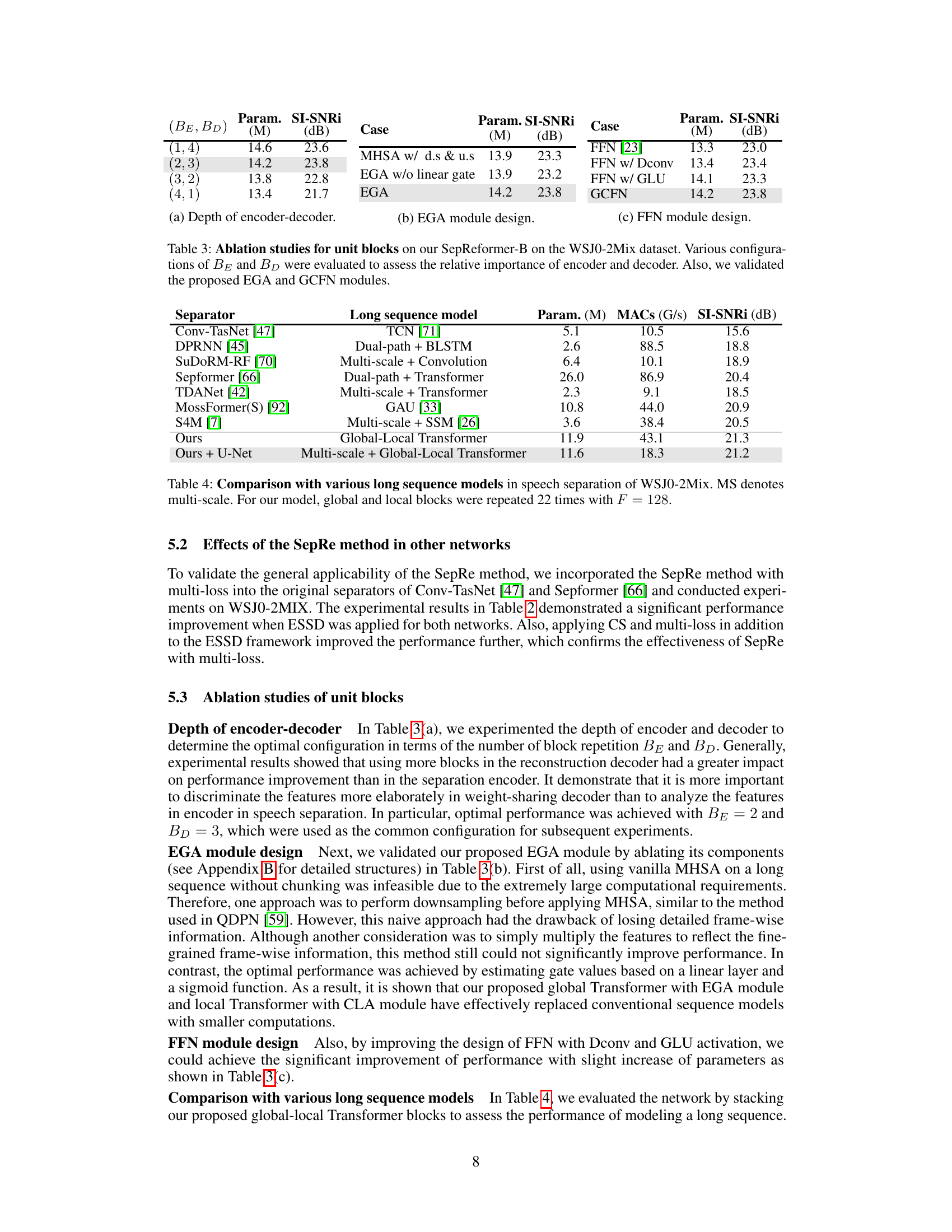
🔼 This table presents ablation study results on SepReformer-B, a variation of the proposed model, using the WSJ0-2Mix dataset. It investigates the impact of different configurations of encoder (BE) and decoder (BD) blocks, varying their number of repetitions. The study also examines the effectiveness of the proposed Efficient Global Attention (EGA) and Gated Convolutional Feed-Forward Network (GCFN) modules by comparing their performance against standard alternatives like Multi-Head Self-Attention (MHSA) with downsampling and upsampling, EGA without a linear gate, a standard FFN (Feed-Forward Network), an FFN with depthwise convolution, and an FFN with GLU (Gated Linear Unit) activation. The results indicate the optimal configuration of BE and BD blocks, and show the performance gains achieved by using the proposed EGA and GCFN modules compared to standard alternatives.
read the caption
Table 3: Ablation studies for unit blocks on our SepReformer-B on the WSJ0-2Mix dataset. Various configurations of BE and BD were evaluated to assess the relative importance of encoder and decoder. Also, we validated the proposed EGA and GCFN modules.
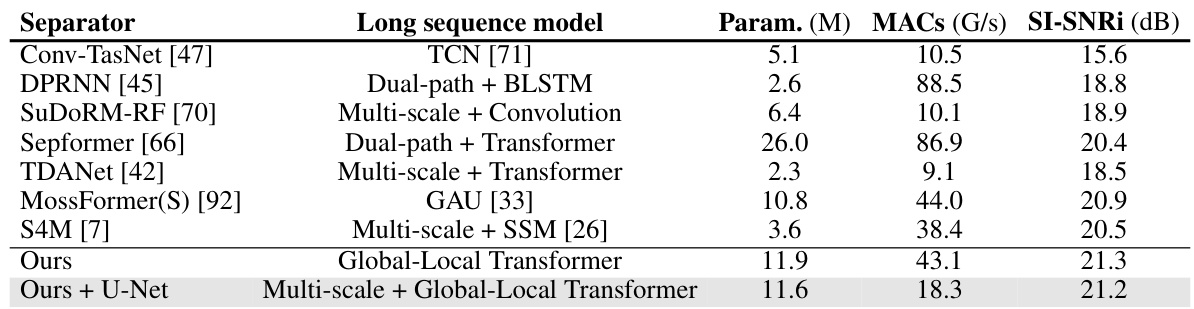
🔼 This table compares the proposed SepReformer model’s performance against other state-of-the-art models for long-sequence speech separation on the WSJ0-2Mix dataset. It shows a comparison of the model parameters (in millions), the number of multiply-accumulate operations (MACs, in Giga), and the SI-SNRi (Scale-Invariant Signal-to-Noise Ratio) in dB. The table highlights that the SepReformer model achieves competitive performance with significantly fewer parameters and MACs compared to other models that employ various techniques for handling long sequences such as TCNs, dual-path architectures, and multi-scale models.
read the caption
Table 4: Comparison with various long sequence models in speech separation of WSJ0-2Mix. MS denotes multi-scale. For our model, global and local blocks were repeated 22 times with F = 128.
🔼 This table presents the experimental results of the SepRe method on the WSJ0-2Mix dataset, comparing different decoder designs (with and without multi-loss) and their impact on performance. It shows how the early split with shared decoder and cross-speaker transformer improves performance and efficiency compared to late-split and multiple decoder structures. The effect of multi-loss on various architectures is also analyzed.
read the caption
Table 1: Experimental evaluation of SepRe method on the WSJ0-2Mix dataset. ML denotes the multi-loss. In (a), all the methods were trained with ML, and the numbers in the left and right of the '/' symbol were obtained for the tiny and base models, respectively. In (b), when ML was used for training, we indicated the numbers of parameters including the additional output layer for an auxiliary output for ŝj, which were denoted with asterisk *. Note that the additional output layers were not required during inference.
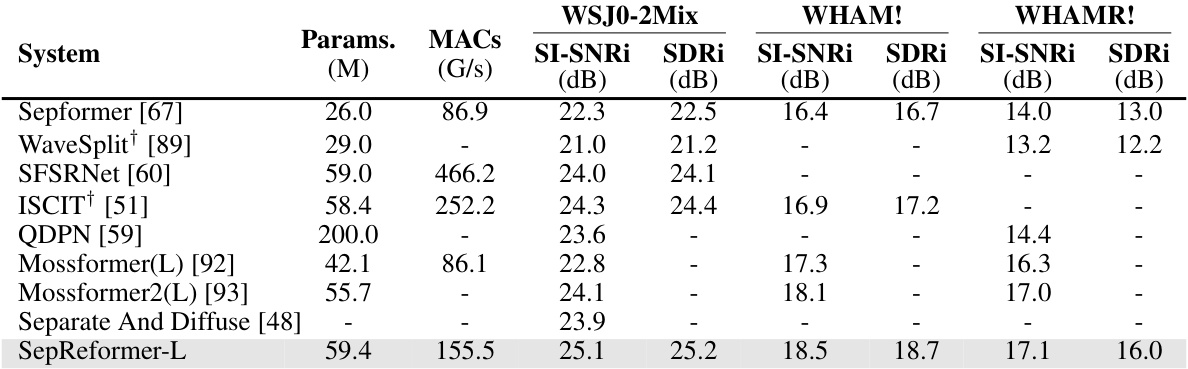
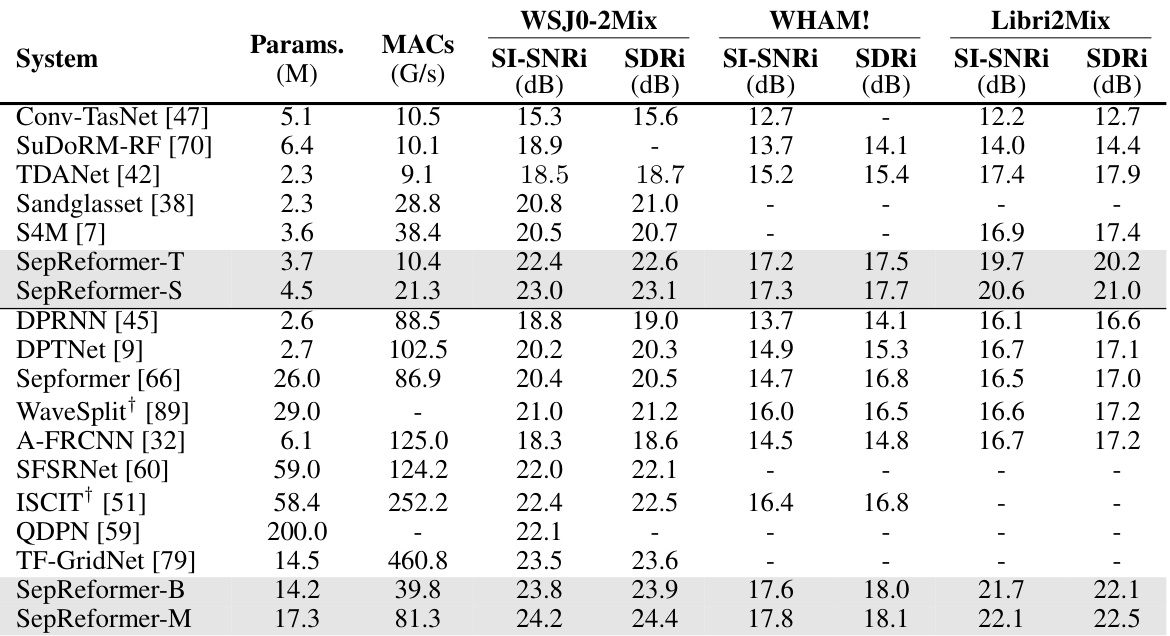
🔼 This table compares the performance of SepReformer with other state-of-the-art speech separation models on four benchmark datasets: WSJ0-2Mix, WHAM!, WHAMR!, and Libri2Mix. The metrics used are SI-SNRi and SDRi, which measure the signal-to-noise ratio and source-to-distortion ratio, respectively, reflecting the quality of the separated speech. The table also shows the number of parameters (Params.) and Multiply-Accumulate operations (MACs) for each model, indicating computational complexity. The ‘+’ symbol indicates models that use additional speaker information during training.
read the caption
Table 5: Evaluation on various benchmark dataset of WSJ0-2MIX, WHAM!, WHAMR!, and Libri2Mix. '+' denotes that the networks use additional speaker information.

🔼 This table presents a comparison of two different speaker split layer architectures used in the SepReformer model, specifically the ‘weight-shared layer’ and the ‘multiple layer’ approaches. The results are evaluated on three different speech separation datasets: WSJ0-2Mix, WHAM!, and WHAMR!. For each dataset and architecture, the table shows the model’s size in terms of parameters (Params. in millions) and its performance metrics: SI-SNRI and SDRi (in dB). SI-SNRI and SDRi represent the scale-invariant signal-to-noise ratio and source-to-distortion ratio, respectively; both are common metrics to evaluate the quality of speech separation. The table helps assess the impact of the different speaker split designs on the overall performance of the SepReformer model.
read the caption
Table 6: Comparison of shared and multiple speaker split layer based on SepReformer-L with DM on the WSJ0-2Mix, WHAM!, and WHAMR! dataset.

🔼 This table presents a comparison of the perceptual quality of speech signals processed using three different methods: No Processing (baseline), TF-GridNet, and the proposed SepReformer-L. The evaluation is performed using two metrics: PESQ (Perceptual Evaluation of Speech Quality) and eSTOI (Extended Short-Time Objective Intelligibility). The results show that SepReformer-L achieves a significant improvement in perceptual quality compared to the baseline and a slight improvement compared to TF-GridNet, indicating its effectiveness in enhancing the intelligibility of speech signals even in challenging conditions such as noise and reverberation.
read the caption
Table 7: Perceptual evaluation by PESQ and eSTOI on WHAMR! dataset.
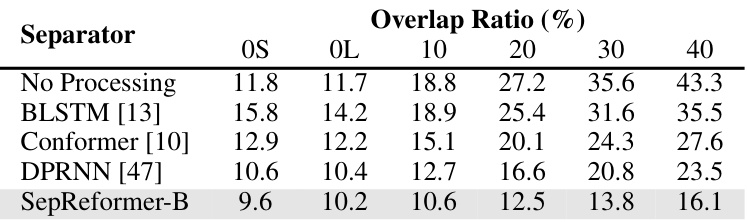
🔼 This table presents the Word Error Rates (WER) achieved by different speech separation methods on the LibriCSS dataset. The LibriCSS dataset is designed to evaluate speech separation in realistic meeting scenarios with varying degrees of speech overlap. The table shows WERs for different overlap ratios (0%, 10%, 20%, 30%, 40%) and compares the performance of the proposed SepReformer-B model against baselines such as LSTM, Conformer, and DPRNN. A ‘No Processing’ baseline is included to demonstrate the WER without any speech separation.
read the caption
Table 8: WERs (%) of utterance-wise evaluation on the LibriCSS dataset for the baseline without any processing for input data acquired at the center microphone and separation by LSTM, Conformer, DPRNN, and the proposed SepReformer.
Full paper#