TL;DR#
Current promptable segmentation methods heavily rely on manual, instance-specific prompts, limiting large-scale applications. Task-generic approaches, using a single prompt for all images in a task, have emerged, but their accuracy depends heavily on the precision of prompts derived from Multimodal Large Language Models (MLLMs). MLLMs, however, are prone to hallucinations, leading to inaccurate prompts and poor segmentation results.
ProMaC addresses this by cleverly utilizing MLLM hallucinations. It introduces an iterative framework that cycles between a prompt generator (using multi-scale chain-of-thought prompting to explore and refine prompts based on hallucinations and visual masking) and a mask generator (aligning generated masks with task semantics). This iterative process refines both prompts and masks, ultimately producing more accurate and task-relevant segmentation results. Experiments across diverse benchmarks demonstrate ProMaC’s superior performance compared to existing methods, highlighting its effectiveness in reducing manual prompt dependency and enhancing segmentation accuracy. ProMaC is training-free, making it efficient and widely applicable.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to promptable segmentation that significantly reduces the reliance on manual prompts. This addresses a major limitation of current methods and opens up new avenues for research in efficient and scalable object segmentation. The training-free nature of ProMaC is particularly valuable, as it avoids the computational cost and potential bias associated with training data, making it more widely applicable across diverse segmentation tasks. Its effectiveness on various challenging benchmarks showcases its potential to advance numerous real-world applications that require object segmentation.
Visual Insights#

🔼 The figure illustrates the iterative process of ProMaC, a prompt-mask cycle generation method. It begins with an initial instance-specific prompt, which is used by a mask generator to produce an initial mask. This mask is then used by a prompt generator to refine the instance-specific prompt. This cycle repeats multiple times, improving both the prompt and the mask. The prompt generator uses a multi-scale chain of thought prompting, which involves exploring hallucinations to mine task-related information, and then reducing these hallucinations to formulate more precise prompts. The mask generator uses mask semantic alignment, which ensures that the generated masks are consistent with task semantics.
read the caption
Figure 2: An overview of ProMac: Masks created iteratively by the mask generator guide the prompt generator to jointly improve instance-specific prompts and visual masking in segmentation.

🔼 This table presents the performance comparison of various methods on three camouflaged object detection datasets (CHAMELEON, CAMO, and COD10K) under three different settings: scribble supervision, point supervision, and task-generic prompt supervision. The metrics used for evaluation include Mean Absolute Error (M), adaptive F-measure (FB), mean E-measure (E), and structure measure (Sa). The best results for each metric under each setting are shown in bold.
read the caption
Table 1: Results on Camouflaged Object Detection (COD) under different settings. Best are in bold.
In-depth insights#
Hallucination Use#
The concept of ‘Hallucination Use’ in the context of a research paper likely explores the leveraging of large language model (LLM) hallucinations in a constructive manner. Instead of viewing hallucinations as errors, the authors likely propose a method to utilize the unexpected outputs to gain additional insights. This approach likely involves using hallucinations to initially explore a wider range of contextual possibilities, extracting relevant information that might be missed by more precise methods. The paper likely then presents a mechanism to filter and refine these initial, potentially inaccurate, outputs to arrive at more precise and accurate results. The core idea is to use the initial hallucinated outputs as a starting point for a more focused investigation, effectively using the LLMs’ vast knowledge base in a creative way. The success of this approach hinges on the ability to reliably identify and extract useful information from the initial hallucinatory responses, and then on a robust mechanism to subsequently filter out the irrelevant and inaccurate parts. The overall implication is a system that is less reliant on highly precise inputs and can potentially achieve comparable or even better performance with less manual intervention, especially in tasks with complex or ambiguous data.
ProMaC Framework#
The ProMaC framework innovatively leverages the often-dismissed hallucinations of large language models (LLMs) in promptable segmentation. Instead of treating these hallucinations as errors, ProMaC uses them to extract valuable contextual information from images, enhancing the precision of generated prompts. This is achieved through an iterative cycle between a prompt generator and a mask generator. The prompt generator employs multi-scale chain-of-thought prompting, initially exploring hallucinations to gather knowledge, then refining these into precise instance-specific prompts. The mask generator, leveraging the strengths of SAM (Segment Anything Model), produces masks aligned with task semantics. This iterative cycle refines both prompts and masks, resulting in improved segmentation accuracy. Visual contrastive reasoning plays a key role, verifying the accuracy of hallucinations and helping the model focus on task-relevant image regions. The training-free nature of ProMaC makes it highly efficient and adaptable to various segmentation tasks.
Mask Alignment#
Mask alignment in the context of promptable segmentation is crucial for bridging the gap between predicted masks and semantic understanding. The core problem is that existing models like SAM excel at generating visually accurate masks, but they lack inherent semantic awareness. This means a mask might perfectly capture the contours of an object, yet fail to correctly represent its category or role within the context of the task. Mask alignment methods aim to address this by explicitly incorporating semantic information to guide the mask generation process. This can involve aligning masks with predicted instance labels, enforcing consistency between the mask and the associated text prompt or task definition, or by iteratively refining the mask using feedback from a higher-level semantic module. Successful mask alignment ensures that the resulting masks accurately reflect the desired segmentation based on task and prompt semantics. Ultimately, effective mask alignment is vital for improving the precision and reliability of promptable segmentation, leading to more accurate and meaningful results.
MLLM Limitations#
Large Language Models (LLMs) are powerful tools, but their application in multimodal tasks like promptable segmentation reveals limitations. Hallucinations, where the model generates outputs not supported by the input data, are a significant concern. These hallucinations stem from the model’s reliance on pre-trained knowledge and learned associations, which can lead to inaccurate predictions, especially when visual cues are ambiguous or incomplete. While some methods focus on eliminating these hallucinations, a more nuanced approach recognizes their potential value. Careful utilization of these hallucinations can provide valuable contextual insights, offering additional information beyond individual images. However, effectively managing and verifying the accuracy of these insights is crucial to ensure reliable and precise promptable segmentation. Therefore, strategies that effectively integrate hallucination analysis into the model’s reasoning process, utilizing mechanisms like iterative cycles of prompt and mask generation, are critical to maximizing the utility of LLMs and mitigating their inherent limitations in complex tasks. This includes mechanisms for validating the accuracy of hallucinated details and reducing their influence on final predictions.
Future Research#
Future research directions stemming from this work on prompt-based segmentation could explore more sophisticated methods for hallucination management. Instead of simply mitigating them, perhaps hallucinations could be leveraged more effectively to extract additional contextual clues about the scene. This might involve using more advanced reasoning techniques within the prompt generation model or employing techniques from other fields, like knowledge graph reasoning. Improving the efficiency and scalability of the prompt-mask cycle generation would also be valuable; perhaps exploring alternative architectures or optimization strategies could significantly speed up processing, allowing for application to larger datasets or more complex scenes. Finally, extending the approach beyond the specific tasks examined in the paper, such as camouflaged object detection and medical image segmentation, would demonstrate broader applicability and impact. This could involve testing on diverse visual domains or incorporating additional modalities (e.g., audio or depth) to improve performance in complex scenarios.
More visual insights#
More on figures

🔼 This figure provides a detailed illustration of the ProMaC framework’s architecture, highlighting the iterative interaction between the prompt and mask generators. The prompt generator uses multi-scale chain of thought reasoning and visual contrastive reasoning (VCR) to refine instance-specific prompts. The mask generator utilizes these refined prompts, along with a segmentation model (Seg), to create masks that are aligned with the task semantics. These masks are then fed back to the prompt generator to further refine its prompts in an iterative process, leading to enhanced segmentation accuracy.
read the caption
Figure 3: ProMaC consists of a prompt generator and a mask generator for cyclical optimization. The prompt generator employs multi-scale chain-of-thought prompting. It initially use hallucinations for exploring task-related information within image patches. It identifies task-relevant objects and their backgrounds (Afore, Alback) along with their locations (Bk). Subsequently, it uses visual contrastive reasoning to refine and finalize instance-specific prompts (A, B) by eliminating hallucinations. The mask generator then processes these prompts into the segmentation model ('Seg'), producing a mask aligned with task semantics. This mask further guides the visual contrastive reasoning process, which leverages an inpainting model to eliminate masked regions, creating contrastive images. These images enable the prompt generator to further refine its prompts, enhancing segmentation accuracy.

🔼 This figure visualizes the results of different segmentation methods on three distinct tasks: Camouflaged Object Detection, Transparent Object Segmentation, and Medical Image Segmentation. For each task, it shows the original image, the ground truth segmentation, and the segmentation results produced by three different methods: Grounding SAM, GenSAM, and the proposed ProMaC method. The contrastive sample is also shown for ProMaC, highlighting the use of contrastive reasoning to enhance the accuracy of the segmentations. The figure visually demonstrates the relative strengths and weaknesses of each method across different visual scenarios and complexities.
read the caption
Figure 4: Visualization of various segmentation methods among various segmentation tasks.

🔼 This figure visualizes the iterative process of ProMaC. It shows how the generated masks and contrastive samples evolve over four iterations. For each iteration, there are four rows representing four different samples. Each row shows the ground truth image (Image>), the predicted mask from the first iteration (iteration 1), the second iteration (iteration 2), the third iteration (iteration 3), the fourth iteration (iteration 4), and finally the prediction image (Prediction Image) and a contrastive image for each sample. The contrastive images are used to highlight task-relevant regions and reduce irrelevant hallucinations, demonstrating the cycle generation method.
read the caption
Figure 5: Visualization of the generated masks and contrastive samples over iterations.

🔼 The left part of the figure shows a bar chart comparing the cosine similarity between ground truth and predicted task-related objects using CLIP on the COD10K dataset. The original image, an inpainted version (with task-related objects removed), and a combined version are compared. The combined version shows improved similarity, suggesting that prior knowledge from hallucinations aids in prompt generation. The right part illustrates how hallucinations assist in generating instance-specific prompts by showing an example image. Directly inputting the original image leads to incorrect prediction, whereas splitting the image and using hallucinations leads to a more accurate prediction of the camouflaged chameleon.
read the caption
Figure 6: Left: In the bar chart, we analyze MLLM predictions with two versions of an image: the original (blue) and another with task-related objects removed via inpainting (orange). We then compare their predictions to the ground truth using CLIP similarity on the COD10K dataset. Despite missing key objects, the inpainted image's predictions still somewhat match the ground truth. When we select the higher similarity score from both images as the final score (green), it surpassed that of the original alone. It shows that prior knowledge from hallucinations can also provide useful information for generating prompts. Right: A example of using hallucinations to assist instance-specific prompt generation. Specifically, utilizing hallucination can leverage prior knowledge of image elements to better recognize and locate task-related objects. Directly inputting the image into LLaVA results in the hidden chameleon being incorrectly predicted. Splitting the image results in interested objects being incomplete or absent, prompting LLaVA to induce hallucinations and utilize prior knowledge to uncover potential task-related knowledge within the image. This knowledge assists in final accurately identifying and locating the chameleon.

🔼 This figure visualizes the results of different segmentation methods on three diverse tasks: Camouflaged Object Detection, Transparent Object Segmentation, and Medical Image Segmentation. It showcases how each method (including the proposed ProMaC) performs on various images, highlighting the differences in their ability to accurately segment objects in challenging scenarios. The visualization helps demonstrate ProMaC’s effectiveness compared to other techniques across different visual challenges.
read the caption
Figure 4: Visualization of various segmentation methods among various segmentation tasks.

🔼 This figure visualizes the results of various segmentation methods on three different tasks: Camouflaged Object Detection, Transparent Object Segmentation, and Medical Image Segmentation. For each task, it shows the original image, the ground truth segmentation, the segmentation result using GenSAM, the segmentation result using GroundingSAM, and finally the segmentation result obtained by the proposed ProMaC method. The visualization helps to compare the performance of different methods across diverse visual scenarios and demonstrates the effectiveness of ProMaC in handling challenging segmentation tasks.
read the caption
Figure 4: Visualization of various segmentation methods among various segmentation tasks.

🔼 This figure visualizes the results of different segmentation methods (GenSAM, GroundingSAM, and ProMaC) on three different tasks: Camouflaged Object Detection, Transparent Object Segmentation, and Medical Image Segmentation. It shows the original images, ground truth masks, and the masks generated by each method. The visualization helps to compare the performance of the methods across various visual tasks and object types.
read the caption
Figure 4: Visualization of various segmentation methods among various segmentation tasks.

🔼 This figure visualizes the results of different segmentation methods on three different tasks: Camouflaged Object Detection, Transparent Object Segmentation, and Medical Image Segmentation. It shows the original images, ground truth masks, and segmentation results obtained using ProMaC, as well as other compared methods. This allows for a visual comparison of the performance of the various methods across diverse visual characteristics and challenges.
read the caption
Figure 4: Visualization of various segmentation methods among various segmentation tasks.
More on tables

🔼 This table presents the performance comparison of different methods on two medical image segmentation subtasks: polyp image segmentation and skin lesion segmentation. The comparison is done using a task-generic prompt setting, meaning that only a general description of the task is provided, not instance-specific annotations. The metrics used include Mean Absolute Error (M), adaptive F-measure (FB), mean E-measure (E4), and Structure measure (Sa). Lower M or higher values for FB, E, and Sa indicate better performance.
read the caption
Table 2: Results for Medical Image Segmentation (MIS) under task-generic prompt setting.

🔼 This table presents the results of the proposed ProMaC method and several baseline methods on two different tasks: transparent object segmentation and open vocabulary segmentation. For transparent object segmentation, the table shows the performance (measured by M↓, F↑, E↑, Sa↑) of different methods on two datasets, GSD and Trans10K-hard. For open vocabulary segmentation, the table shows the performance (measured by mIoU) of different methods on the VOC dataset, using different image-text pairs for training. This helps to demonstrate the versatility and effectiveness of ProMaC in various segmentation scenarios.
read the caption
Table 3: Result on Transparent Object Segmentation and Open-Vocabulary Segmentation Tasks.
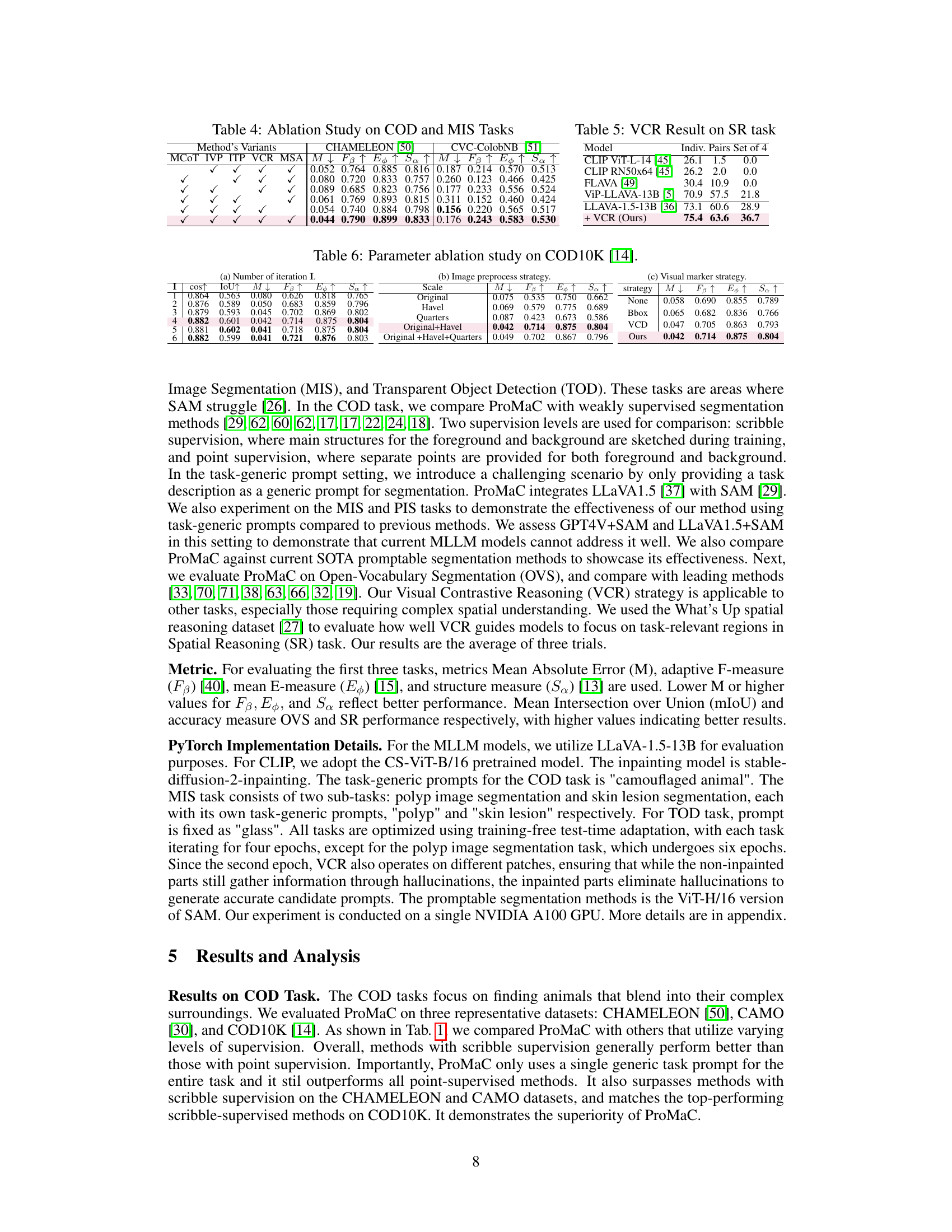
🔼 This table presents the ablation study results conducted on the Camouflaged Object Detection (COD) and Medical Image Segmentation (MIS) tasks. It shows the impact of removing different components of the ProMaC framework (Multi-scale Chain of Thought Prompting, Instance-specific Text Prompts, Instance-specific Visual Prompts, Visual Contrastive Reasoning, Mask Semantic Alignment) on the overall performance, measured by metrics M↓, FB↑, Ep↑, and Sa↑. The results demonstrate the contribution of each component to the final performance, highlighting the importance of a holistic approach.
read the caption
Table 4: Ablation Study on COD and MIS Tasks

🔼 This table presents the results of the Visual Contrastive Reasoning (VCR) method on the Spatial Reasoning (SR) task. It compares the performance of different models (CLIP ViT-L-14, CLIP RN50x64, FLAVA, ViP-LLAVA-13B, LLaVA-1.5-13B) with and without the VCR method. The metrics used are Indiv. Pairs, Set of 4. The results show that adding VCR improves the performance across all models.
read the caption
Table 5: VCR Result on SR task

🔼 This table presents the results of the Camouflaged Object Detection (COD) task using different methods and supervision levels (scribble, point, and task-generic prompts). The performance is evaluated based on four metrics: M (Mean Absolute Error), FB (F-measure), Ep (E-measure), and Sa (Structure-measure). Lower M and higher values for FB, Ep, and Sa indicate better performance. The table highlights the best-performing method for each setting in bold, allowing for comparison across various approaches and supervision types.
read the caption
Table 1: Results on Camouflaged Object Detection (COD) under different settings. Best are in bold.
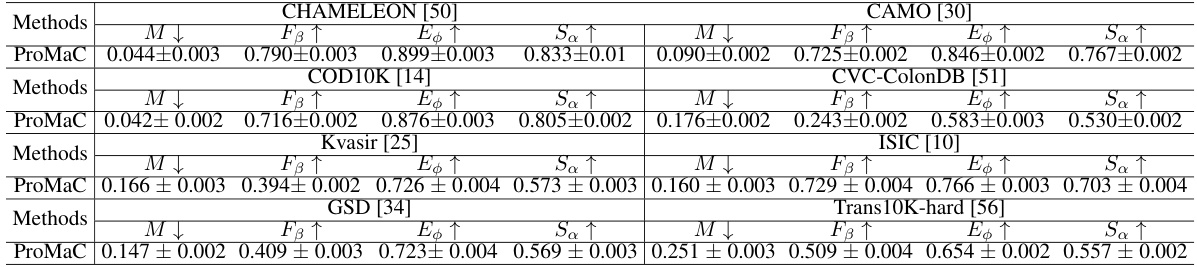
🔼 This table presents the performance comparison of ProMaC against other state-of-the-art methods on three benchmark datasets for camouflaged object detection (COD): CHAMELEON, CAMO, and COD10K. The results are broken down by three different prompt supervision settings: scribble supervision, point supervision, and task-generic prompt supervision. Metrics used for evaluation include Mean Absolute Error (M), adaptive F-measure (FB), mean E-measure (E), and structure measure (Sa). The best results for each metric and dataset are highlighted in bold.
read the caption
Table 1: Results on Camouflaged Object Detection (COD) under different settings. Best are in bold.

🔼 This table presents the results of the Camouflaged Object Detection (COD) task using different methods and supervision levels. The methods are compared on three metrics: mean absolute error (M), adaptive F-measure (FB), E-measure (E), and structure measure (Sa). Three different supervision settings are considered: scribble supervision, point supervision, and task-generic prompt setting. The best results for each setting are highlighted in bold. This table demonstrates the effectiveness of the proposed method (ProMaC) in the challenging task-generic prompt setting where only a single task description is provided.
read the caption
Table 1: Results on Camouflaged Object Detection (COD) under different settings. Best are in bold.

🔼 This table compares the performance of ProMaC using two different MLLMs (LLaVA and Qwen) against other state-of-the-art methods on the polyp image segmentation task using the CVC-ColonDB dataset. The metrics used for comparison include Mean Absolute Error (M), F-measure (FB), E-measure (Eφ), and structure measure (Sa). Lower M and higher values for FB, Eφ, and Sa indicate better performance. The results show that ProMaC achieves comparable or better performance to the other methods, despite using a simpler task-generic prompt setting. This highlights ProMaC’s effectiveness in handling challenging segmentation scenarios.
read the caption
Table 8: Comparison with present SOTA MLLM approaches.
Full paper#