TL;DR#
Vision Transformers (ViTs), while powerful, are limited by their fixed input resolution requirement. This necessitates resizing images to a standard size before processing, leading to performance degradation, especially with low-resolution images. Real-world images vary widely in size, highlighting the need for a more adaptable approach.
The proposed Multi-Scale Patch Embedding (MSPE) method directly addresses this limitation. MSPE enhances ViT adaptability by optimizing the patch embedding layer, replacing the standard patch embedding with multiple variable-sized patch kernels. This enables the model to process images of various resolutions directly, without preprocessing. Extensive experiments across various tasks (image classification, segmentation, and detection) demonstrate MSPE’s superior performance over existing methods, particularly with low-resolution inputs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with Vision Transformers (ViTs). It addresses the critical issue of ViT’s poor adaptability to variable input resolutions, a significant limitation in real-world applications. MSPE offers a simple yet effective solution by optimizing the patch embedding layer, making ViTs more versatile and applicable to diverse scenarios. This directly impacts the broader field of computer vision, opening up new research avenues for improving ViT’s performance and applicability in various tasks.
Visual Insights#
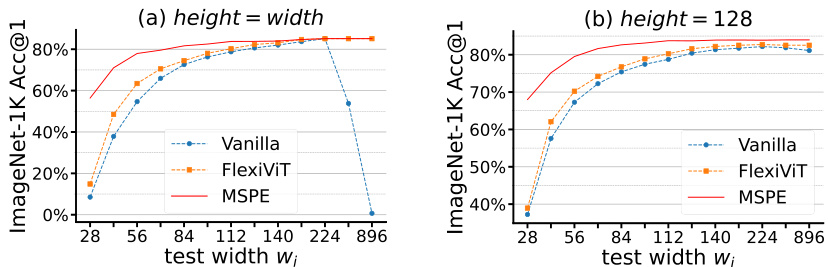
🔼 This figure shows the ImageNet-1K Top-1 accuracy results of three different methods: Vanilla ViT, FlexiViT, and the proposed MSPE method. It compares their performance across a range of input image resolutions, with two sets of experiments: (a) where the height and width of the image are equal, and (b) where the height is fixed at 128 pixels while the width varies. The results demonstrate that Vanilla ViT’s performance significantly degrades as the aspect ratio changes, while FlexiViT shows improvement. The MSPE method outperforms both Vanilla ViT and FlexiViT, especially at lower resolutions.
read the caption
Figure 1: MSPE results on ImageNet-1K. We loaded a ViT-B model pre-trained on ImageNet-21K from [19] and evaluated: (a) Height equals width, ranging from 28×28 to 896×896, and (b) Fixed height=128, width ranging from 28 to 896. Vanilla ViT performance drops with size/aspect ratio changes; FlexiViT [15] significantly improves performance, and our method surpasses FlexiVIT.
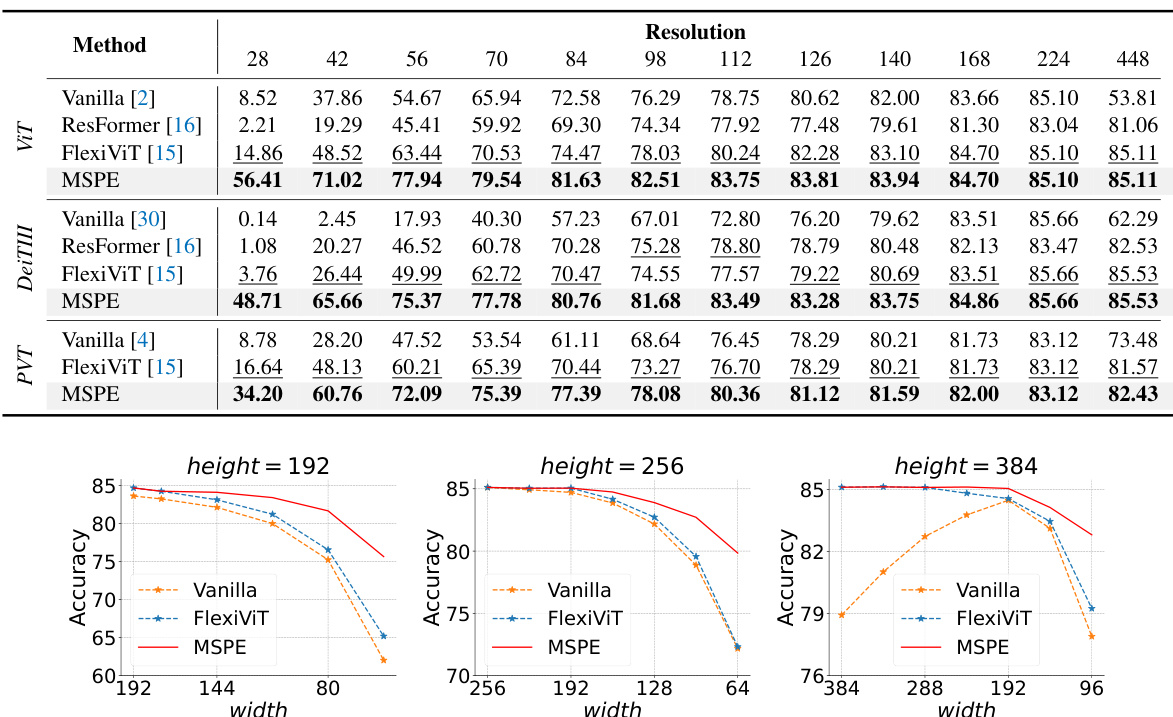
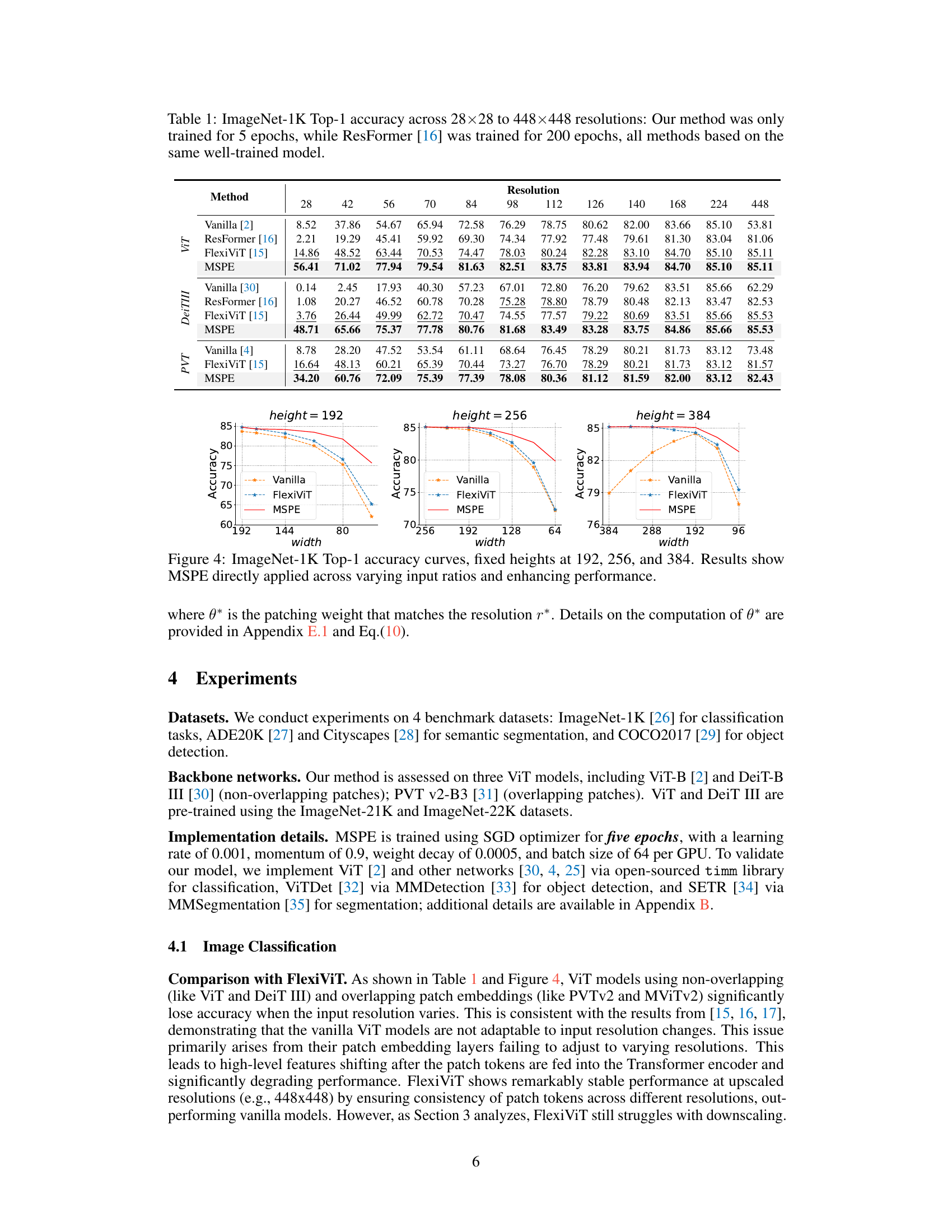
🔼 This table presents the ImageNet-1K Top-1 accuracy results for various resolutions (from 28x28 to 448x448) using different methods: Vanilla ViT, ResFormer, FlexiViT, and the proposed MSPE. It highlights that MSPE, despite training only for 5 epochs (compared to 200 epochs for ResFormer), achieves superior or comparable performance across resolutions.
read the caption
Table 1: ImageNet-1K Top-1 accuracy across 28×28 to 448×448 resolutions: Our method was only trained for 5 epochs, while ResFormer [16] was trained for 200 epochs, all methods based on the same well-trained model.
In-depth insights#
Multi-scale Vision#
Multi-scale vision, in the context of computer vision, refers to the ability of a system to effectively process and understand images across a wide range of scales. Traditional approaches often struggle with this, as features relevant at one scale might be lost or insignificant at another. Effective multi-scale methods are crucial for robustness and accuracy, especially in real-world scenarios with varying image resolutions and object sizes. This is often tackled through techniques like image pyramids or multi-resolution feature extraction. The core challenge lies in effectively combining information from different scales, potentially using attention mechanisms or sophisticated fusion strategies to avoid losing fine-grained details or global context. Deep learning architectures have shown promise in learning scale-invariant representations, enabling the handling of various scales within a unified model. However, issues like computational complexity and the difficulty of learning appropriate scale-specific features remain open research questions.
MSPE: Core Idea#
The core idea behind MSPE (Multi-Scale Patch Embedding) is to enhance the adaptability of Vision Transformers (ViTs) to variable input resolutions without the need for extensive retraining or architectural changes. It achieves this by replacing the standard, fixed-size patch embedding layer with multiple learnable, variable-sized patch kernels. This allows MSPE to directly process images of different resolutions without resizing, selecting the optimal kernel size for each input based on its resolution. The method’s key strength lies in its simplicity and compatibility with most existing ViT models, offering a low-cost solution to address the limitation of ViTs’ fixed input resolution. Performance is improved significantly on low-resolution inputs and maintained on high-resolution inputs compared to standard ViTs and other multi-resolution methods. This approach fundamentally tackles the resolution bottleneck in ViTs by dynamically adjusting the patch embedding process, rather than resorting to other complex, resolution-specific mechanisms.
Resolution Adapt.#
The heading ‘Resolution Adapt.’ suggests a focus on methods for adapting vision models to handle various input resolutions. A common challenge in computer vision is that many models perform best on a specific, fixed resolution (e.g., 224x224). This ‘Resolution Adapt.’ section would likely detail techniques that enable a model to maintain performance across diverse image sizes without needing to resize or retrain for each resolution. This might involve modifying the patch embedding layer, which is crucial for ViT architectures, to handle patches of varying sizes or using multi-scale features extracted at different resolutions. The adaptability discussed could center on the trade-offs between accuracy and computational cost at different resolutions, as well as the effectiveness of the proposed methods on both high- and low-resolution images. Performance comparisons against alternative approaches that address resolution variability would also be a key element of this section, demonstrating the benefits of the novel resolution adaptation strategy.
Experimental Setup#
A well-defined Experimental Setup section is crucial for reproducibility and validating the claims of a research paper. It should detail all aspects of the experiments, including datasets used (with versions specified), preprocessing techniques, model architectures and hyperparameters (including how they were chosen – e.g., grid search, random search, or Bayesian optimization), training procedures (optimization algorithms, batch sizes, learning rates, number of epochs, and any regularization techniques), and evaluation metrics. Transparency in this section is paramount. Ambiguity can significantly undermine the credibility of the results. Furthermore, the setup should clearly articulate the hardware resources employed for training and inference, including the number and type of GPUs or CPUs. This allows readers to estimate the computational cost and assess the scalability of the proposed methods. Finally, a comprehensive setup will specify random seeds or methods for reproducible random number generation, which is critical for ensuring consistency and mitigating the effects of randomness on the results. Without such details, it is difficult to evaluate the robustness of reported findings.
Future Works#
The paper’s core contribution is MSPE, a method enhancing Vision Transformer adaptability to varying resolutions by optimizing patch embedding. Future work could explore several promising directions: Firstly, integrating MSPE with more advanced ViT architectures, evaluating its performance on even more diverse datasets and tasks beyond image classification, segmentation, and detection. Secondly, investigating the interaction between MSPE and other ViT components such as positional embedding and the Transformer encoder, potentially leading to further performance gains or architectural improvements. Thirdly, exploring more sophisticated kernel adaptation strategies within MSPE, for example, using attention mechanisms or dynamic kernel generation to enhance its flexibility and efficiency across an even wider range of resolution changes. Finally, extending MSPE to other vision tasks, such as video processing and 3D vision, where resolution variation is particularly significant, would be valuable. A comprehensive ablation study analyzing the impact of different kernel sizes and numbers on various tasks would also strengthen the work.
More visual insights#
More on figures
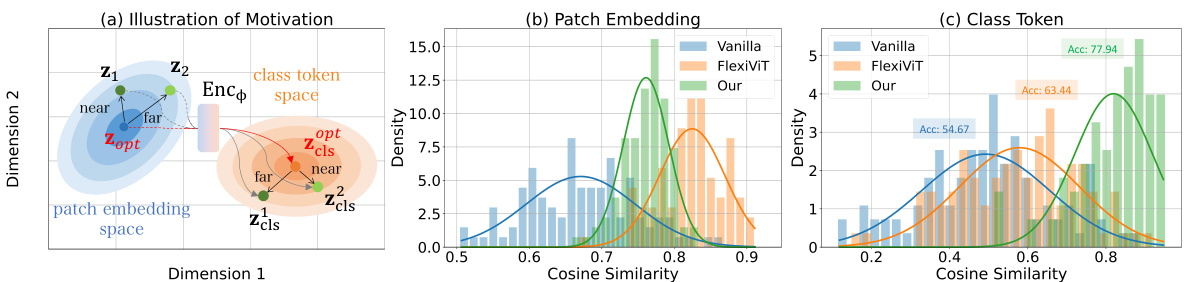
🔼 This figure demonstrates that similar patch embeddings do not imply similar classification performance. It shows that while FlexiViT achieves higher patch embedding similarity than the vanilla model and our method, our method surpasses both in classification accuracy. This highlights the importance of considering the entire pipeline, including the transformer encoder, rather than solely focusing on patch embedding similarity.
read the caption
Figure 2: Similarity in patch embeddings does not guarantee optimal performance (a). We confirm this by evaluating the accuracy and cosine similarity of: (b) patch embeddings {z}₁from 56x56 and 224x224 images, and (c) class tokens zcls from 56x56 and 224x224 images.
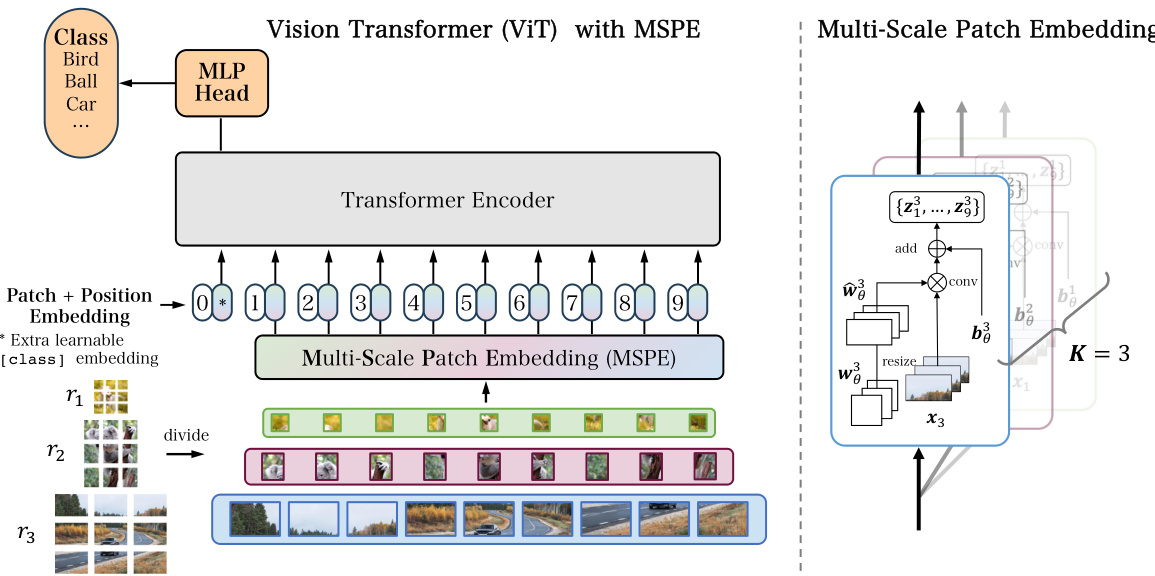
🔼 This figure illustrates the architecture of the Vision Transformer (ViT) model enhanced with the proposed Multi-Scale Patch Embedding (MSPE) method. The core idea is to replace the standard patch embedding layer with a multi-scale patch embedding layer that uses multiple variable-sized kernels. This allows the model to process images of various resolutions without requiring resizing, improving efficiency and maintaining performance. The Transformer encoder part of the ViT model remains unchanged.
read the caption
Figure 3: Illustration of the ViT model [2, 3] with MSPE. MSPE only replaces the patch embedding layer in the vanilla model, making well-trained ViT models to be directly applied to any size and aspect ratio. In our method, the patch embedding layer has several variable-sized kernels. The Transformer encoder is shared and frozen.
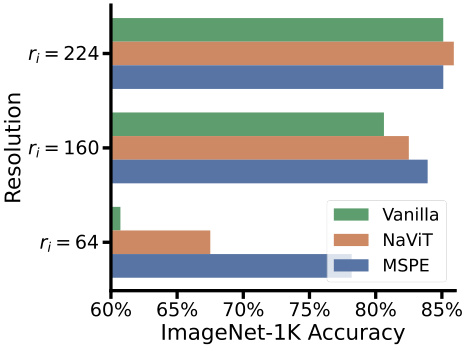
🔼 This figure compares the ImageNet-1K Top-1 accuracy of three methods: Vanilla ViT, NaViT, and MSPE. The x-axis represents the ImageNet-1K accuracy, and the y-axis shows different input resolutions (rᵢ = 64, 160, 224). It highlights that MSPE outperforms both Vanilla ViT and NaViT across all resolutions, especially at lower resolutions. Note that NaViT used a larger pre-training dataset (JFT), giving it an advantage.
read the caption
Figure 5: Comparison of MSPE, Vanilla, and NaViT: only NaViT was pre-trained on the JFT dataset, baseline results come from [17].

🔼 This figure presents ablation studies on the impact of training epochs and model sizes on the performance of MSPE. (a) shows that training for 3 or 5 epochs yields similar results, indicating that MSPE converges quickly. (b) demonstrates that MSPE is effective across different model sizes (small, base, large), with larger models generally achieving higher accuracy.
read the caption
Figure 6: Comparison results: (a) different training epochs; (b) model sizes of S, B, and L.
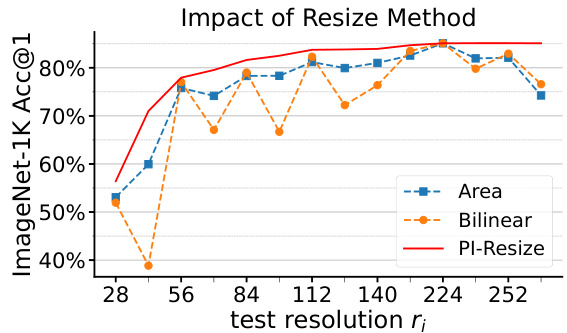
🔼 This figure compares the performance of different image resizing methods within the Multi-Scale Patch Embedding (MSPE) framework. The methods compared include area resizing, bilinear resizing, and pseudo-inverse resizing (PI-Resize). The x-axis represents different test resolutions, and the y-axis shows the ImageNet-1K Top-1 accuracy. The results demonstrate that PI-Resize consistently achieves the highest accuracy across all resolutions, showcasing its superior performance and robustness compared to other methods.
read the caption
Figure 8: Comparison results of different resizing methods in MSPE. PI-resize shows the best performance and robustness.
🔼 This figure displays the performance of MSPE, Vanilla ViT, and FlexiViT on the ImageNet-1K dataset for image classification. Two scenarios are shown: (a) where the image height and width are equal, and (b) where the image height is fixed at 128 pixels while the width varies. The results demonstrate that Vanilla ViT’s accuracy decreases significantly as image size deviates from its training size (224x224), whereas FlexiViT and especially MSPE show significantly better performance across all tested resolutions and aspect ratios. MSPE demonstrates substantial improvement, especially at lower resolutions, exceeding FlexiViT in accuracy.
read the caption
Figure 1: MSPE results on ImageNet-1K. We loaded a ViT-B model pre-trained on ImageNet-21K from [19] and evaluated: (a) Height equals width, ranging from 28×28 to 896×896, and (b) Fixed height=128, width ranging from 28 to 896. Vanilla ViT performance drops with size/aspect ratio changes; FlexiViT [15] significantly improves performance, and our method surpasses FlexiVIT.
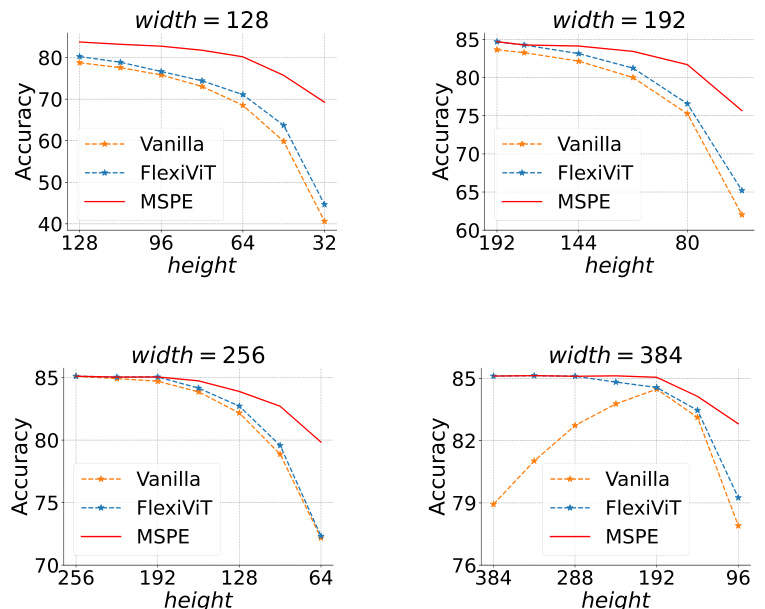
🔼 The figure shows the ImageNet-1K Top-1 accuracy for different image resolutions with fixed height (192, 256, and 384 pixels) and varying width. It compares the performance of Vanilla ViT, FlexiViT, and MSPE, highlighting MSPE’s ability to maintain or improve accuracy across a range of aspect ratios.
read the caption
Figure 4: ImageNet-1K Top-1 accuracy curves, fixed heights at 192, 256, and 384. Results show MSPE directly applied across varying input ratios and enhancing performance.

🔼 This figure compares the performance of three different image resizing methods (PI-Resize, Nearest, and Bicubic) when used within the Multi-Scale Patch Embedding (MSPE) framework. The x-axis represents the test resolution, and the y-axis shows the ImageNet-1K Top-1 accuracy. The results demonstrate that PI-Resize significantly outperforms the other two methods across all resolutions, highlighting its importance for achieving robust performance in MSPE.
read the caption
Figure 10: Comparison results of different resizing methods in MSPE.
More on tables
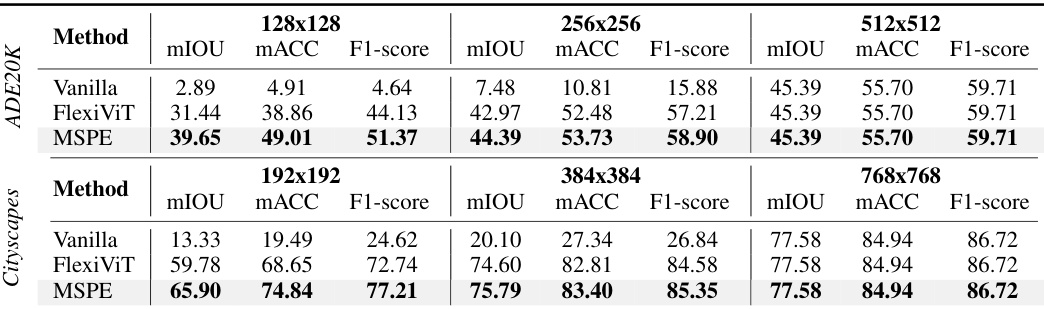
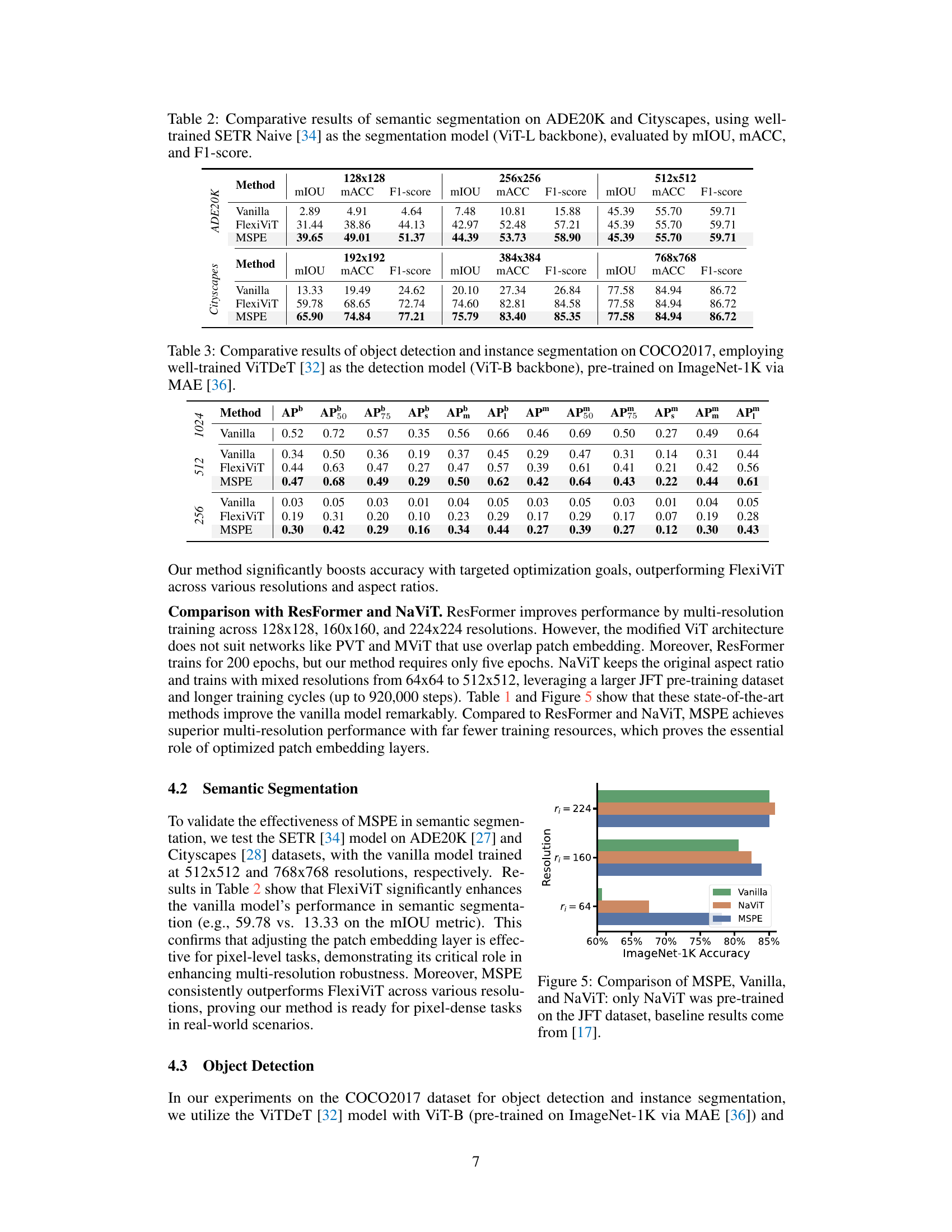
🔼 This table presents a comparison of semantic segmentation results on the ADE20K and Cityscapes datasets using three different methods: Vanilla ViT, FlexiViT, and the proposed MSPE method. The evaluation metrics used are mean Intersection over Union (mIOU), mean Accuracy (mACC), and F1-score. The results are shown for different input image resolutions (128x128, 192x192, 256x256, 384x384, 512x512, 768x768). The table demonstrates how MSPE improves performance at various resolutions compared to the baseline Vanilla ViT and FlexiViT methods.
read the caption
Table 2: Comparative results of semantic segmentation on ADE20K and Cityscapes, using well-trained SETR Naive [34] as the segmentation model (ViT-L backbone), evaluated by mIOU, MACC, and F1-score.
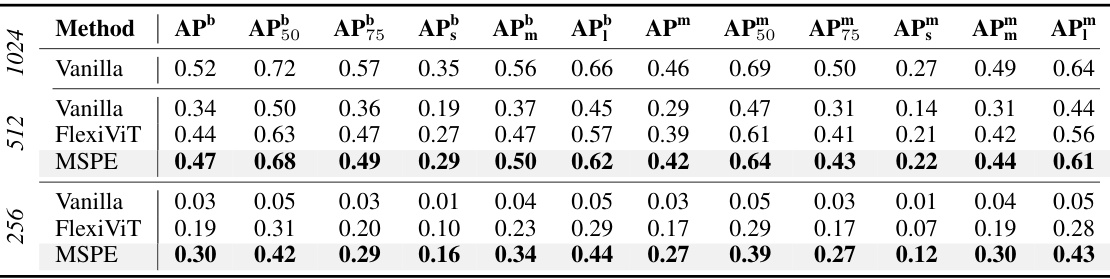
🔼 This table presents the comparative results of object detection and instance segmentation on the COCO2017 dataset. The results are obtained using the well-trained ViTDeT [32] model, which has a ViT-B backbone pre-trained on ImageNet-1K using MAE [36]. The table compares different methods (Vanilla, FlexiViT, and MSPE) across various metrics, including different Average Precision (AP) scores at different Intersection over Union (IoU) thresholds (APb, AP50, AP75, APs, APm, API). This allows for a comprehensive comparison of the performance of each method on object detection and instance segmentation tasks.
read the caption
Table 3: Comparative results of object detection and instance segmentation on COCO2017, employing well-trained ViTDeT [32] as the detection model (ViT-B backbone), pre-trained on ImageNet-1K via MAE [36].
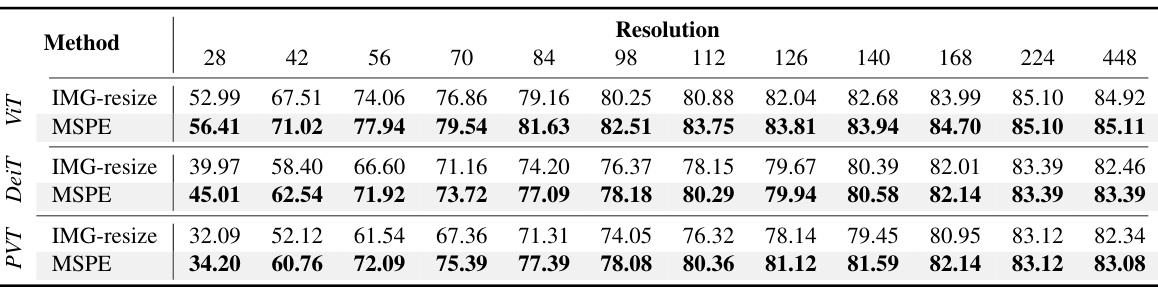
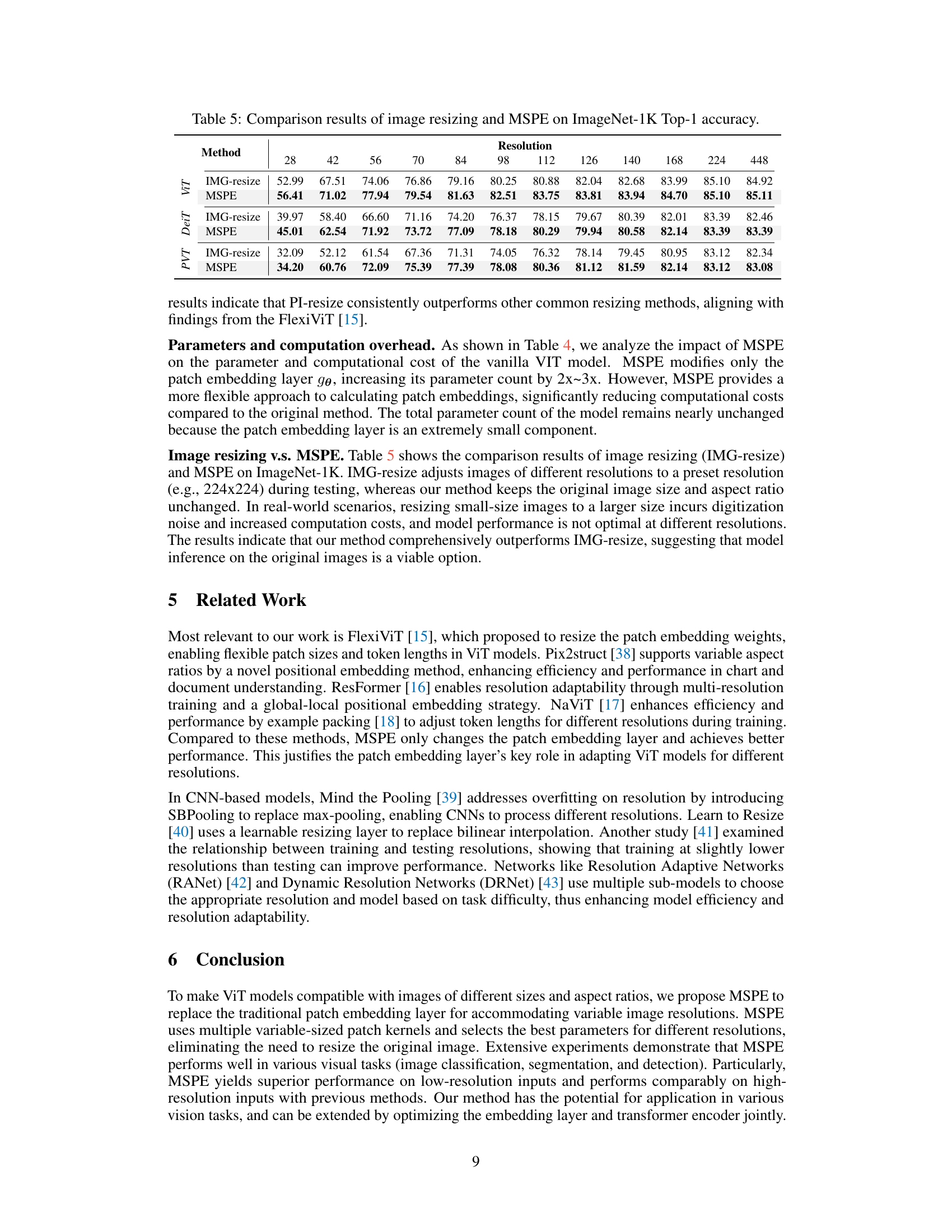
🔼 This table presents the ImageNet-1K Top-1 accuracy results for various resolutions (from 28x28 to 448x448) comparing four different methods: Vanilla ViT, ResFormer, FlexiViT, and MSPE. It highlights the performance of MSPE, which was trained only for 5 epochs, in contrast to ResFormer’s 200 epochs of training, while all methods use the same pre-trained model. The table allows for a direct comparison of the methods across various image sizes.
read the caption
Table 1: ImageNet-1K Top-1 accuracy across 28×28 to 448×448 resolutions: Our method was only trained for 5 epochs, while ResFormer [16] was trained for 200 epochs, all methods based on the same well-trained model.

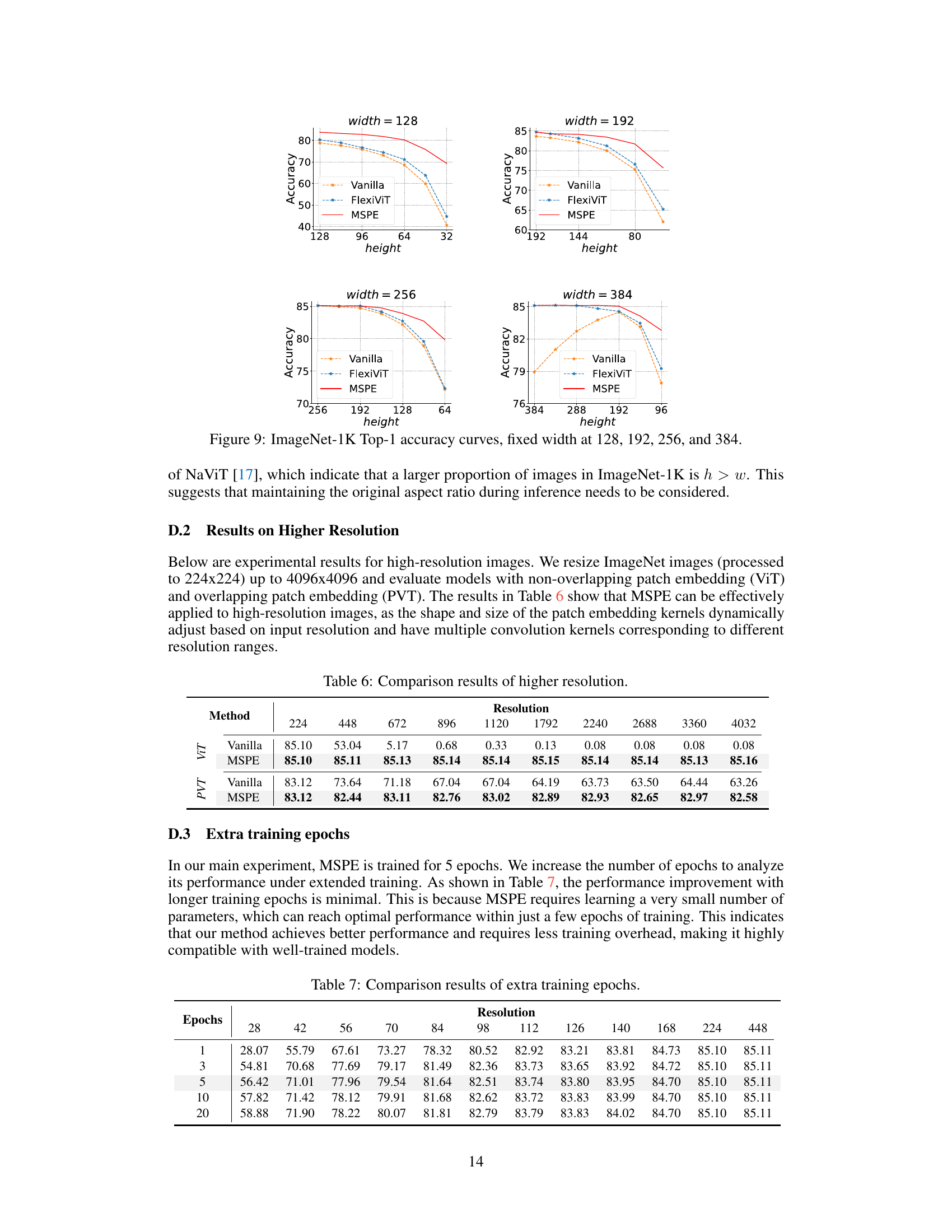
🔼 This table compares the performance of Vanilla ViT and MSPE models on ImageNet-1K using high-resolution images (from 224x224 to 4032x4032). It demonstrates MSPE’s ability to maintain high accuracy even at very high resolutions, unlike the Vanilla ViT model which experiences a significant drop in accuracy as resolution increases. The results show that MSPE effectively handles both non-overlapping and overlapping patch embedding types, indicating its broad applicability.
read the caption
Table 6: Comparison results of higher resolution.

🔼 This table presents the ImageNet-1K Top-1 accuracy results for different resolutions (from 28x28 to 448x448) using various methods: Vanilla ViT, ResFormer, FlexiViT, and the proposed MSPE method. It highlights that MSPE achieves comparable or superior performance to other state-of-the-art methods with significantly less training (5 epochs vs. 200 epochs for ResFormer).
read the caption
Table 1: ImageNet-1K Top-1 accuracy across 28×28 to 448×448 resolutions: Our method was only trained for 5 epochs, while ResFormer [16] was trained for 200 epochs, all methods based on the same well-trained model.
Full paper#