TL;DR#
Current model-based reinforcement learning often struggles with the limitations of large language models (LLMs) for world modeling: LLMs can be imprecise, slow, and difficult to interpret. This research tackles these issues by proposing to use LLMs to generate Python code representing the world model, instead of using LLMs directly for planning. This approach promises increased precision, reliability, and interpretability, along with improved efficiency.
The paper introduces GIF-MCTS, a novel code generation strategy that uses LLMs and Monte Carlo Tree Search. GIF-MCTS significantly outperforms existing methods on various benchmarks. It also introduces a new benchmark (CWMB) for evaluating code generation methods in different RL environments. The improved sample efficiency and inference speed of model-based RL agents using the synthesized code world models demonstrate the effectiveness of this novel approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning and large language models because it presents a novel approach to world modeling using code generation. It offers significant improvements in sample efficiency and inference speed, surpassing existing methods. The introduced benchmark also provides a valuable resource for future research, opening avenues for investigating advanced code generation strategies and more efficient model-based RL agents.
Visual Insights#
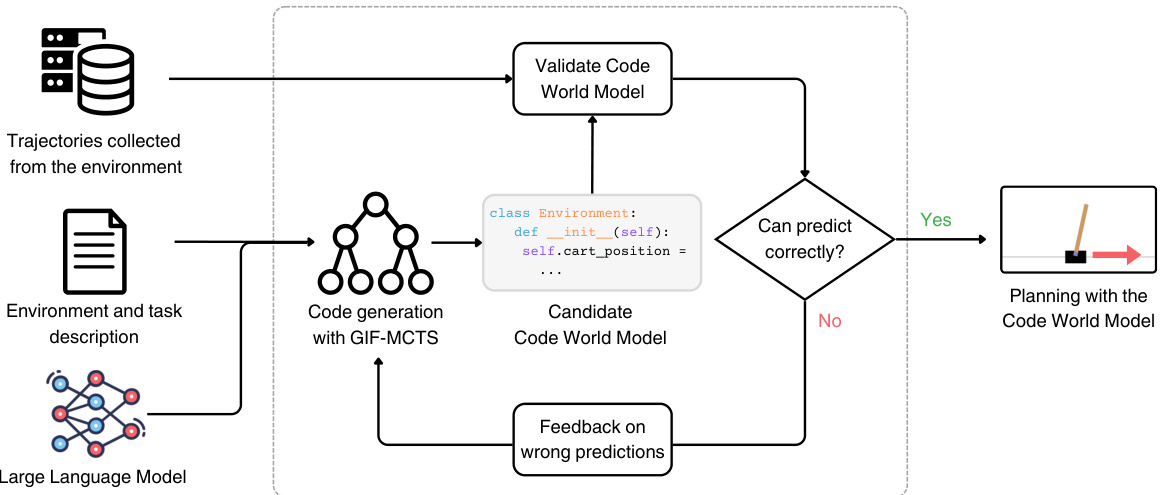
🔼 This figure illustrates the Code World Model (CWM) framework. The process begins with an environment description and task provided to a Large Language Model (LLM). The LLM, guided by the GIF-MCTS algorithm, iteratively generates and refines Python code representing a CWM. This code is then validated against collected environment trajectories to measure its accuracy in predicting system behavior. If the CWM’s predictions are not perfect, the accuracy and other information are fed back to the LLM to further improve the CWM. This iterative process continues until the CWM accurately predicts all transitions or a computational budget is exhausted. Finally, the best performing CWM is used for model-based planning to solve the given task.
read the caption
Figure 1: Overview of the Code World Models (CWM) framework. Given the description of an environment and a task, we use an LLM guided by the GIF-MCTS method to iteratively generate and refine a candidate CWM. The candidate's correctness is evaluated by checking if it correctly predicts a set of trajectories collected from the true environment. If the model cannot fully predict all transitions, the fraction of correct predictions and other information are given as feedback to the LLM and the cycle repeats. After matching all transitions or having used up a computational budget, the best CWM is returned and used to solve the task via model-based planning.

🔼 This table presents the results of different code generation methods on the APPS Competition dataset. The ‘Strict Accuracy’ column shows the percentage of problems for which all unit tests were passed. The evaluation strategy shows how many program attempts were made per problem before deciding if the model succeeded. The table demonstrates GIF-MCTS’ superior performance compared to several baselines.
read the caption
Table 1: APPS competition results: comparison of methods. We report the percentage of problems with all unit tests passed (Strict Accuracy). For our experiments, we also include the error of the mean on the percentage.
In-depth insights#
Code as World Models#
The concept of using code as world models presents a compelling paradigm shift in reinforcement learning. Instead of relying on large language models (LLMs) for direct world prediction, which can be slow and imprecise, this approach leverages the LLM to generate Python code that acts as a simulator. This offers several advantages. First, code is inherently more precise and computationally efficient, allowing for faster planning and action selection. Second, code is more interpretable, providing greater insight into the agent’s decision-making process. However, this approach introduces new challenges, such as the need for robust code generation techniques capable of handling complex logic and debugging capabilities. The success of code as world models hinges on the effectiveness of LLMs in creating accurate and efficient Python code from natural language descriptions of the environment and its dynamics. While promising, the reliability and scalability of this method remain open questions for future research.
GIF-MCTS: CodeGen#
The proposed GIF-MCTS algorithm represents a novel approach to code generation using large language models (LLMs). GIF-MCTS iteratively refines code through a Monte Carlo Tree Search (MCTS) framework, leveraging LLM capabilities for generation, improvement, and bug fixing. This multi-stage process allows for the creation of more accurate and robust code compared to baseline LLM methods. The core innovation lies in its action types - generate, improve, and fix - tailored to the nuances of code synthesis. GIF-MCTS structures the search space efficiently, enabling more effective exploration and exploitation during code refinement. The algorithm demonstrates clear advantages over baselines, exhibiting superior performance on various benchmarks. Its efficacy stems from its ability to not only generate but also iteratively enhance code based on feedback, ultimately achieving higher accuracy and model-based RL agent efficiency.
CWMB Benchmark#
The Code World Models Benchmark (CWMB) is a crucial contribution, addressing the need for a comprehensive evaluation suite in the field of code-based world models. Its 18 diverse RL environments, spanning discrete and continuous control tasks, provide a robust testbed for assessing the generalizability and effectiveness of code generation methods. The inclusion of curated trajectories and corresponding textual descriptions further enhances its value, enabling a more nuanced evaluation. By including environments with varying characteristics and complexity, the CWMB facilitates a thorough comparison of different approaches and encourages the development of more sophisticated and adaptable world model synthesis techniques. Its significance lies in bridging the gap between natural language descriptions of tasks and the precise code required for model-based RL, making it an invaluable tool for advancing research in this rapidly evolving field.
Planning with CWMs#
The section ‘Planning with CWMs’ would detail how the synthesized Code World Models (CWMs) are used for planning in reinforcement learning (RL) environments. It would likely begin by describing the planning algorithm employed, such as Monte Carlo Tree Search (MCTS) or a similar method, and explain how the CWM’s predictive capabilities are integrated into the algorithm’s decision-making process. A key aspect would be a comparison of planning performance using the generated CWMs against baselines, such as using the Large Language Model (LLM) directly for planning or employing a purely reactive agent. The results presented would likely show improved sample efficiency and inference speed when using CWMs for planning, indicating that the CWMs provide a more efficient way to model the world’s dynamics. The discussion would also likely include an analysis of the impact of CWM accuracy on planning performance, showing the trade-off between accurate models (which are generally more difficult to generate) and efficient planning. Finally, this section would analyze the scalability and generalization capabilities of CWMs for planning across diverse RL environments, emphasizing any limitations encountered. Focus would be given to quantitative metrics demonstrating the improvement in sample efficiency and planning quality.
Limitations & Future#
The research paper’s limitations center on the deterministic and fully observable environment assumption, which restricts applicability to more complex real-world scenarios. Stochasticity and partial observability are not directly addressed. The reliance on offline RL and a need for curated trajectories limit the approach’s online adaptability and scalability to situations with limited data. The reliance on Python code generation by LLMs introduces challenges regarding code complexity and debugging, impacting the ability to scale to more complex tasks. Future work could explore methods to handle stochasticity and partial observability, potentially by incorporating probabilistic models or incorporating uncertainties directly into the code generation process. Moving beyond offline RL and developing online learning capabilities would improve adaptability and reduce reliance on extensive dataset curation. Improving code generation to create more robust and efficient code while scaling to more complex problems is also essential.
More visual insights#
More on figures

🔼 This figure shows an example of a Monte Carlo Tree Search (MCTS) tree used in the GIF-MCTS algorithm for generating Code World Models. Each node represents a program (a Python class defining the environment) and each edge represents an action (generate, improve, or fix). The percentage in each node indicates the program’s accuracy. The algorithm iteratively generates, improves, and fixes the code based on the LLM’s output and evaluation against unit tests (environment trajectories). Buggy nodes (red) trigger a ‘fix’ action until the bug is resolved or the maximum number of attempts is reached. Healthy nodes use ‘generate’ and ‘improve’ actions. The figure illustrates the process from root to a leaf node where a successful CWM is generated.
read the caption
Figure 2: Example of a GIF-MCTS tree for generating a CWM. Starting from the root of the tree, every action taken corresponds to 1) prompting the LLM to either generate, improve or fix a CWM, 2) parsing the LLM completion, and 3) evaluating the CWM's correctness using the available environment trajectories as unit tests (presented as a percentage inside the nodes). On buggy nodes, we allow only fix actions for up to f sequential attempts and replace the actual value with a temporary one, represented in red. In healthy nodes we allow only generate and improve actions. All action prompts are exemplified on the right. The number of total fix f attempts is a model hyperparameter, set to three in this Figure and for our method.
🔼 This figure illustrates the GIF-MCTS algorithm used for code generation. The tree structure represents the search process, where each node contains a code snippet and the percentage reflects the prediction accuracy. Different actions (generate, improve, fix) lead to different branches of the tree, and the process iteratively refines the code until an accurate model is obtained. The figure exemplifies how the LLM is used at each step, and how feedback from unit tests informs subsequent actions. The algorithm incorporates a strategy for handling buggy code snippets by focusing on fixing errors before generating further code.
read the caption
Figure 2: Example of a GIF-MCTS tree for generating a CWM. Starting from the root of the tree, every action taken corresponds to 1) prompting the LLM to either generate, improve or fix a CWM, 2) parsing the LLM completion, and 3) evaluating the CWM's correctness using the available environment trajectories as unit tests (presented as a percentage inside the nodes). On buggy nodes, we allow only fix actions for up to f sequential attempts and replace the actual value with a temporary one, represented in red. In healthy nodes we allow only generate and improve actions. All action prompts are exemplified on the right. The number of total fix f attempts is a model hyperparameter, set to three in this Figure and for our method.
More on tables

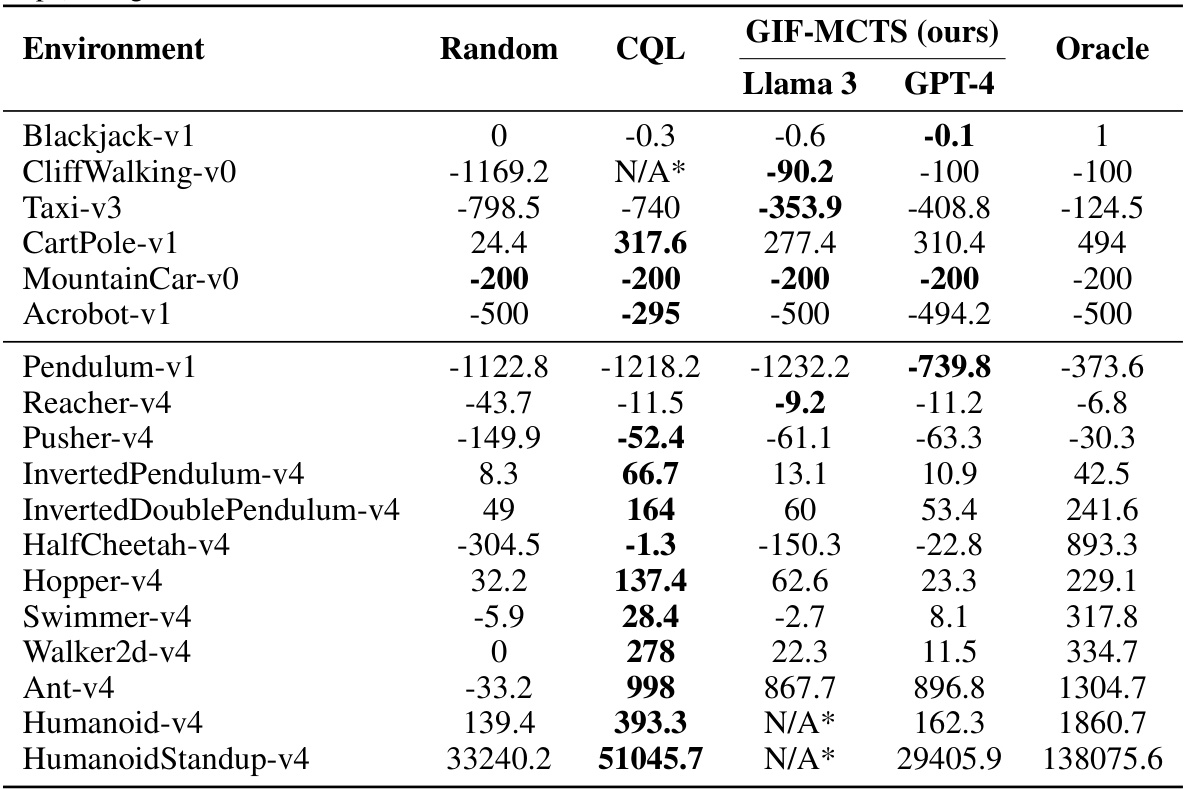
🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It compares the performance of GIF-MCTS and WorldCoder across various RL environments, categorized by whether they have discrete or continuous action spaces. The metrics used are CWM accuracy (how well the generated Code World Model predicts the environment) and normalized return (how well a model-based RL agent using the CWM performs compared to a random agent and an oracle planner). The budget refers to the number of LLM calls used in generating the CWM. The results for Llama 3 are averaged across three random seeds.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.

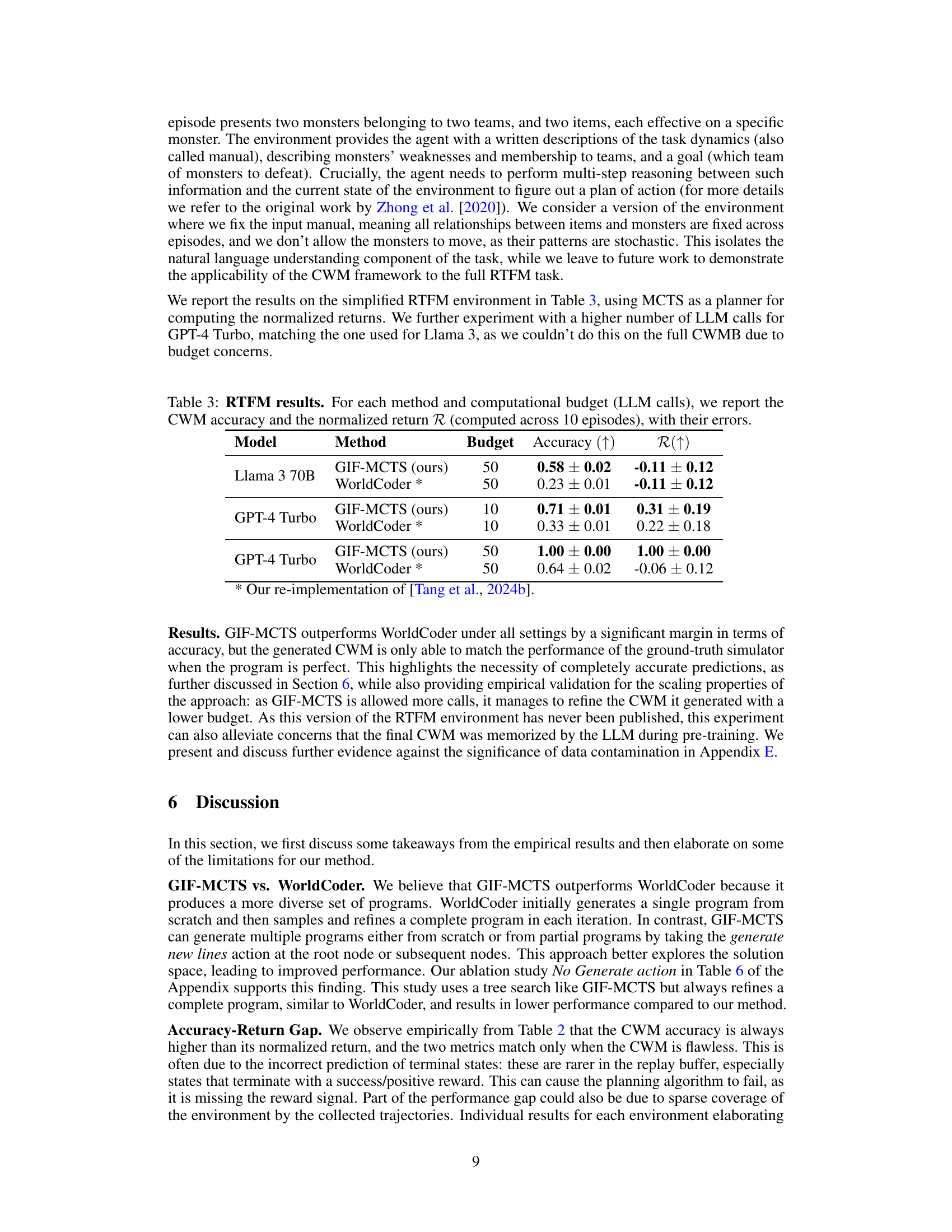
🔼 This table presents the results of the Read to Fight Monsters (RTFM) experiment. It compares the performance of GIF-MCTS and WorldCoder using Llama 3 70B and GPT-4 Turbo language models. The table shows the CWM accuracy and normalized return for each method at different LLM call budgets (10 and 50). The normalized return R is a metric that represents the improvement in return obtained from using the CWM as a model compared to a random policy, relative to the true simulator. It indicates how well the CWM enables planning relative to a random policy and to an optimal planner (oracle) with access to the true model.
read the caption
Table 3: RTFM results. For each method and computational budget (LLM calls), we report the CWM accuracy and the normalized return R (computed across 10 episodes), with their errors.

🔼 This table compares the performance of different methods on the APPS competition benchmark. It shows the percentage of problems (out of 1000) for which all unit tests were passed. It also includes the error of the mean for each method to indicate the level of statistical significance.
read the caption
Table 1: APPS competition results: comparison of methods. We report the percentage of problems with all unit tests passed (Strict Accuracy). For our experiments, we also include the error of the mean on the percentage.
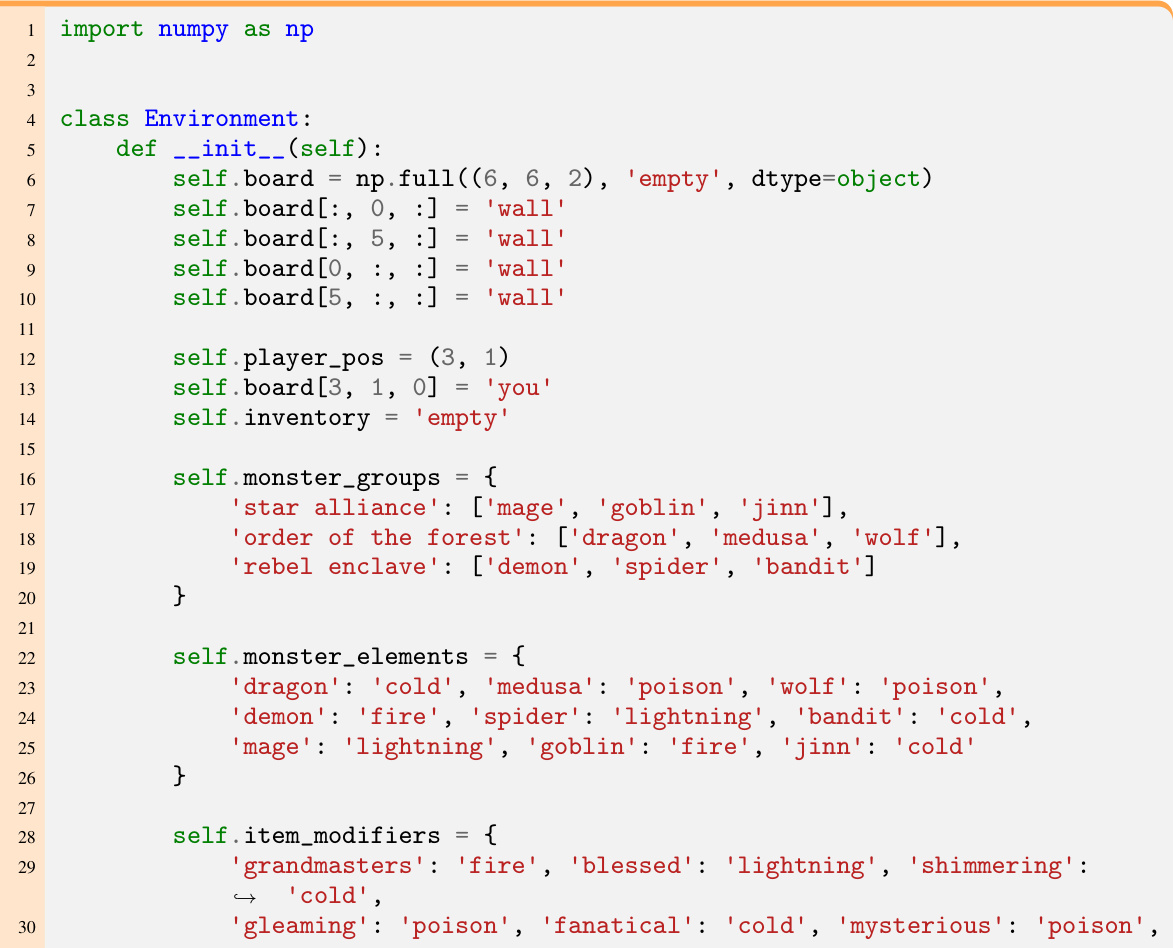
🔼 This table lists the hyperparameters used for the Llama 3 language model in the GIF-MCTS experiments. It shows the values used for parameters such as
max_new_tokens,temperature,top_k,top_p,num_return_sequences, andnum_beams. Note that for the GPT-4 Turbo model, only themax_new_tokensparameter was used, and it was set to the same value as for Llama 3.read the caption
Table 5: Llama 3 hyperparameters. Note that for GPT-4 Turbo, the only parameter used was the number of maximum new tokens, set to the same value used for Llama.

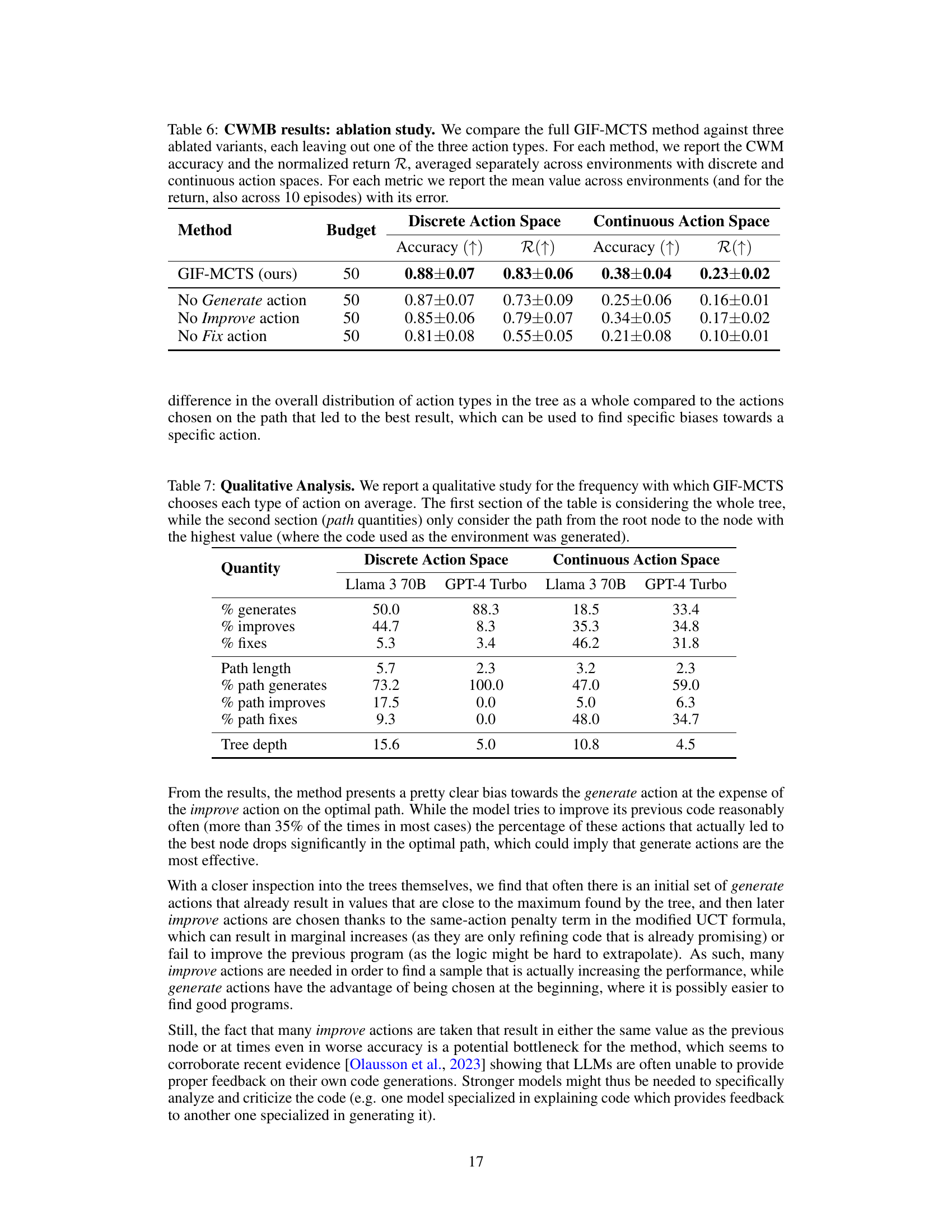
🔼 This table presents the results of an ablation study on the GIF-MCTS algorithm. The study evaluates the impact of each of the three action types (Generate, Improve, Fix) on the performance of the algorithm in generating Code World Models (CWMs) for the Code World Models Benchmark (CWMB). The table shows the accuracy and normalized return for GIF-MCTS with all three action types and for variations where one action type is excluded. The results are separated for environments with discrete and continuous action spaces, reflecting that certain action types might be more or less helpful depending on environment type.
read the caption
Table 6: CWMB results: ablation study. We compare the full GIF-MCTS method against three ablated variants, each leaving out one of the three action types. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. For each metric we report the mean value across environments (and for the return, also across 10 episodes) with its error.

🔼 This table presents a qualitative analysis of the GIF-MCTS algorithm’s action selection. It compares the overall distribution of action types (generate, improve, fix) across the entire search tree with the distribution along the optimal path leading to the best solution. This analysis provides insights into the algorithm’s exploration-exploitation behavior and its effectiveness in different scenarios, such as discrete vs. continuous action spaces.
read the caption
Table 7: Qualitative Analysis. We report a qualitative study for the frequency with which GIF-MCTS chooses each type of action on average. The first section of the table is considering the whole tree, while the second section (path quantities) only consider the path from the root node to the node with the highest value (where the code used as the environment was generated).

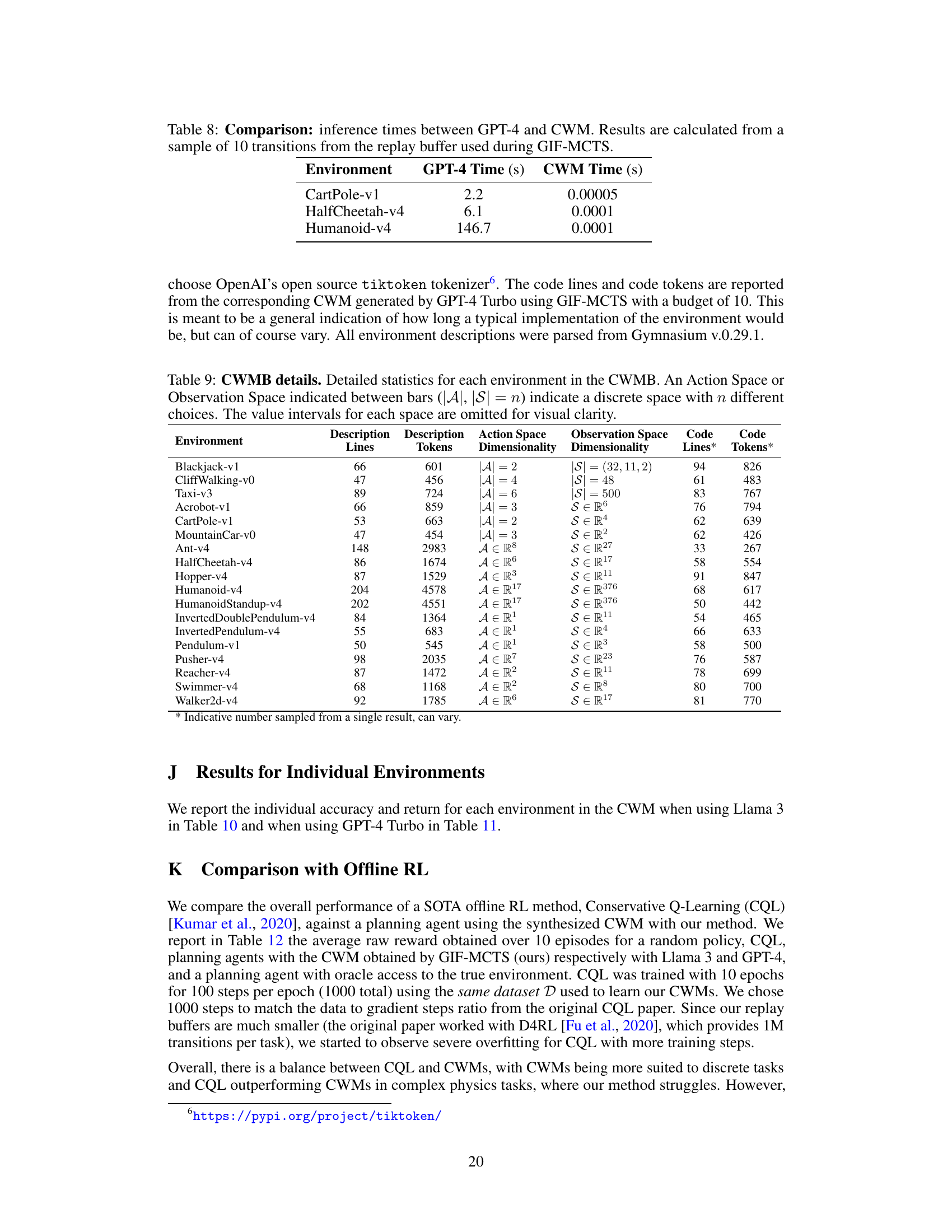
🔼 This table compares the inference time of using GPT-4 directly as a world model versus using a Code World Model (CWM) generated by GIF-MCTS. The inference time is measured for 10 transitions from the replay buffer in three different environments: CartPole-v1, HalfCheetah-v4, and Humanoid-v4. The results show that using the CWM is significantly faster than using GPT-4 directly (four to seven orders of magnitude faster).
read the caption
Table 8: Comparison: inference times between GPT-4 and CWM. Results are calculated from a sample of 10 transitions from the replay buffer used during GIF-MCTS.

🔼 This table provides detailed information about the 18 environments included in the Code World Models Benchmark (CWMB). For each environment, it lists the number of lines and tokens in its description, the dimensionality of its action and observation spaces, and the number of lines and tokens in its Python code implementation. The table helps to characterize the complexity and diversity of the environments in the benchmark.
read the caption
Table 9: CWMB details. Detailed statistics for each environment in the CWMB. An Action Space or Observation Space indicated between bars (|A|, |S| = n) indicate a discrete space with n different choices. The value intervals for each space are omitted for visual clarity.

🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It compares the performance of GIF-MCTS and WorldCoder in terms of CWM accuracy and normalized return (R). The accuracy represents how well the generated code world model predicts the environment dynamics. The normalized return shows the relative performance of the model-based RL agent using the generated CWM, compared to a random policy and an oracle planner with access to the true environment. The results are broken down for environments with discrete and continuous action spaces, and the number of LLM calls used is specified. The table also includes error bars, and an average of three random seeds is used for Llama 3 to ensure statistical significance.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.

🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It compares the performance of GIF-MCTS and WorldCoder in generating Code World Models (CWMs) across 18 diverse reinforcement learning environments. The table is split into two sections, one for environments with discrete action spaces and one for environments with continuous action spaces. For each method and each environment type, the table shows the average CWM accuracy and normalized return, along with standard error, computed across multiple random seeds and episodes. The budget (number of LLM calls) used for each method is also reported.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.
🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It compares the performance of the proposed GIF-MCTS method against the WorldCoder baseline. The table shows the accuracy of the generated Code World Models (CWMs) and the normalized return achieved when using these models for planning. The results are broken down by action space (discrete or continuous) and the number of LLM calls used. Error bars are also included for statistical significance.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.

🔼 This table lists the hyperparameters used in the Monte Carlo Tree Search (MCTS) algorithm for planning in environments with discrete action spaces. It shows the parameter, its description, and the value used in the experiments.
read the caption
Table 13: MCTS planner parameters.

🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It shows a comparison of the GIF-MCTS method against the WorldCoder baseline for different environment types (discrete and continuous action spaces). Key metrics reported include the accuracy of the generated Code World Model (CWM) and its normalized return. The number of LLM calls (budget) used is also specified. Results are averaged across multiple environments and episodes, and error margins are included for statistical significance.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.

🔼 This table compares the performance of different methods on the APPS competition benchmark, specifically focusing on the ‘Strict Accuracy’ metric, which represents the percentage of problems where all unit tests were passed. The table includes both existing methods and the proposed GIF-MCTS approach, providing a quantitative comparison of their effectiveness in code generation tasks.
read the caption
Table 1: APPS competition results: comparison of methods. We report the percentage of problems with all unit tests passed (Strict Accuracy). For our experiments, we also include the error of the mean on the percentage.

🔼 This table compares the performance of different methods on the APPS competition benchmark, specifically focusing on the ‘Competition’ split which contains the hardest problems. The metric used is ‘Strict Accuracy’, representing the percentage of problems where all unit tests are passed. The table includes the model size used for each method and the evaluation strategy (pass@k, where k is the number of attempts) to achieve this result. Results for GIF-MCTS (the proposed method) are compared to the baselines.
read the caption
Table 1: APPS competition results: comparison of methods. We report the percentage of problems with all unit tests passed (Strict Accuracy). For our experiments, we also include the error of the mean on the percentage.

🔼 This table presents a comparison of various methods for code generation on the APPS benchmark’s Competition subset. It shows the strict accuracy rate (percentage of problems where all unit tests passed) achieved by different models and methods, including the authors’ GIF-MCTS. The error of the mean is also included to provide statistical significance. It highlights GIF-MCTS’s superior performance compared to existing techniques.
read the caption
Table 1: APPS competition results: comparison of methods. We report the percentage of problems with all unit tests passed (Strict Accuracy). For our experiments, we also include the error of the mean on the percentage.

🔼 This table presents the main results of the Code World Models Benchmark (CWMB). It compares the performance of GIF-MCTS and WorldCoder in synthesizing Code World Models (CWMs). The table shows the accuracy of the generated CWMs and their normalized return (a measure of how well they perform in planning compared to a random policy and an oracle planner). Results are broken down for environments with discrete and continuous action spaces, and error bars are provided to indicate statistical significance. The number of LLM calls (budget) used is also reported.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.
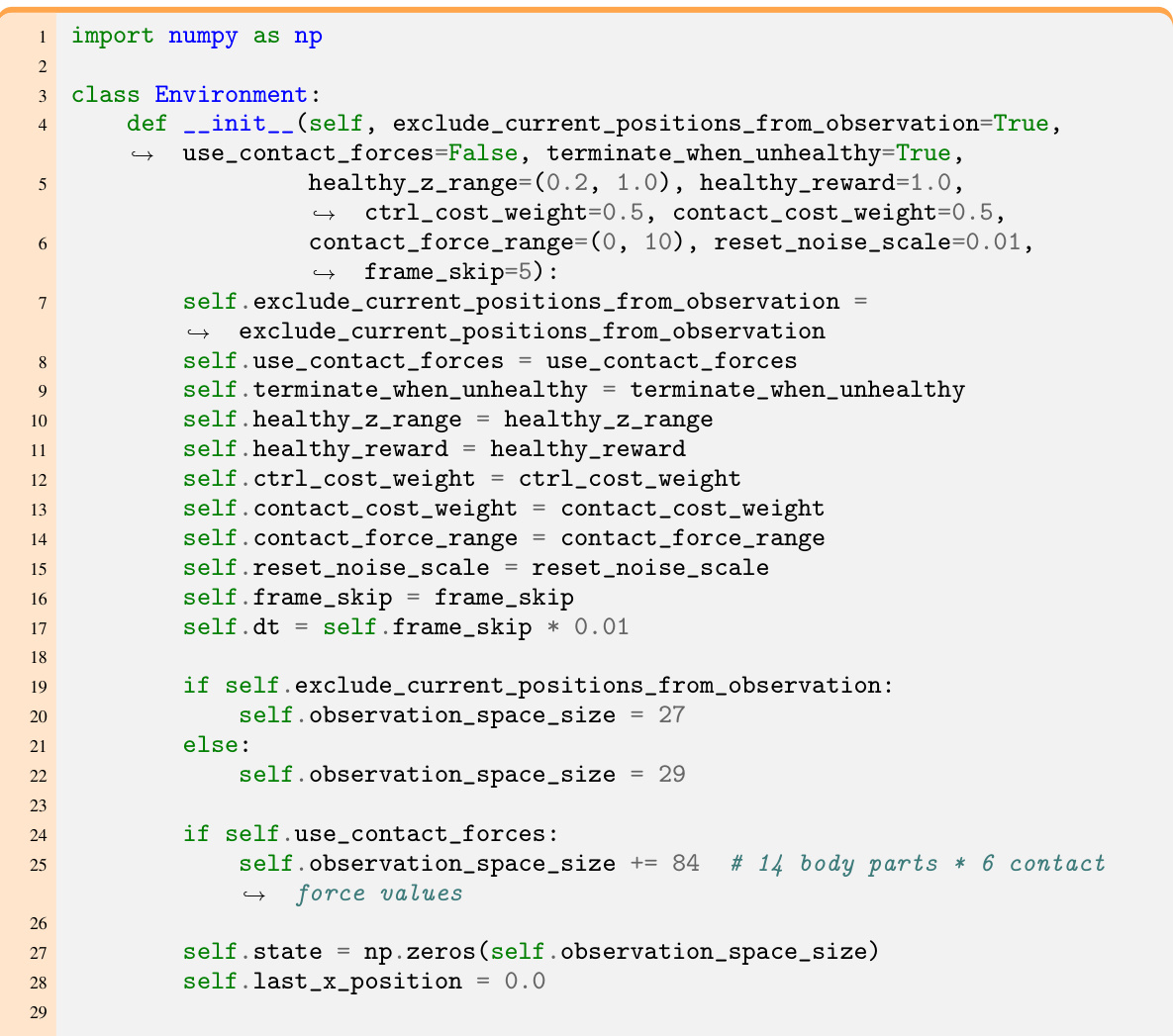
🔼 This table presents the results of the Code World Models Benchmark (CWMB). It compares two methods, GIF-MCTS and WorldCoder, across environments with both discrete and continuous action spaces. The metrics used are CWM accuracy (a measure of how well the generated Code World Model predicts the environment’s dynamics) and normalized return R (a measure of the planning agent’s performance using the generated CWM, compared to random and oracle planners). The budget column shows the number of LLM calls used. Error bars are included to show statistical significance.
read the caption
Table 2: CWMB: main results. For each method, we report the CWM accuracy and the normalized return R, averaged separately across environments with discrete and continuous action spaces. Budget indicates the number of LLM calls. For each metric, we report the mean value across environments (and for the return, also across 10 episodes) with its error. For Llama 3, we report an average of three different random seeds for additional statistical significance.
Full paper#