TL;DR#
Large Language Models (LLMs) are computationally expensive to train, especially when creating multiple variants of different sizes. This paper tackles this issue by exploring an alternative to repeated, full retraining: pruning an existing large LLM and retraining it with significantly less data. This approach uses a combination of techniques such as depth, width, attention and MLP pruning, combined with knowledge distillation based retraining.
The researchers developed a guide of best practices to perform model compression based on their detailed experimental analysis. They used this guide to compress a family of LLMs, obtaining 8B and 4B models from a 15B model and comparing their performance on various tasks. The resulting smaller models (MINITRON) showed comparable or better performance to other existing models, with significant training cost reductions (up to 40 times less tokens).
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on large language models (LLMs) due to its significant contributions to efficient model compression and retraining techniques. It offers practical guidelines and demonstrates substantial compute cost savings, making it highly relevant to current research trends focused on resource-efficient AI. The open-sourced models and code further enhance its value to the research community, promoting reproducibility and accelerating future research in this area.
Visual Insights#

🔼 This figure illustrates the cost-effectiveness and performance gains achieved by using the MINITRON approach. The x-axis represents the cost to train the model (in trillions of tokens), while the y-axis represents the MMLU (Massive Multitask Language Understanding) score, a metric measuring a model’s performance across various language tasks. The figure shows that MINITRON models (green circles), derived from a larger pretrained model via pruning and knowledge distillation, significantly outperform comparable models trained from scratch (orange circles) while requiring far fewer training tokens (40x less in one instance). The dashed green line traces the compression path, starting with a larger model and ending with smaller MINITRON models, highlighting the efficiency of the method.
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.
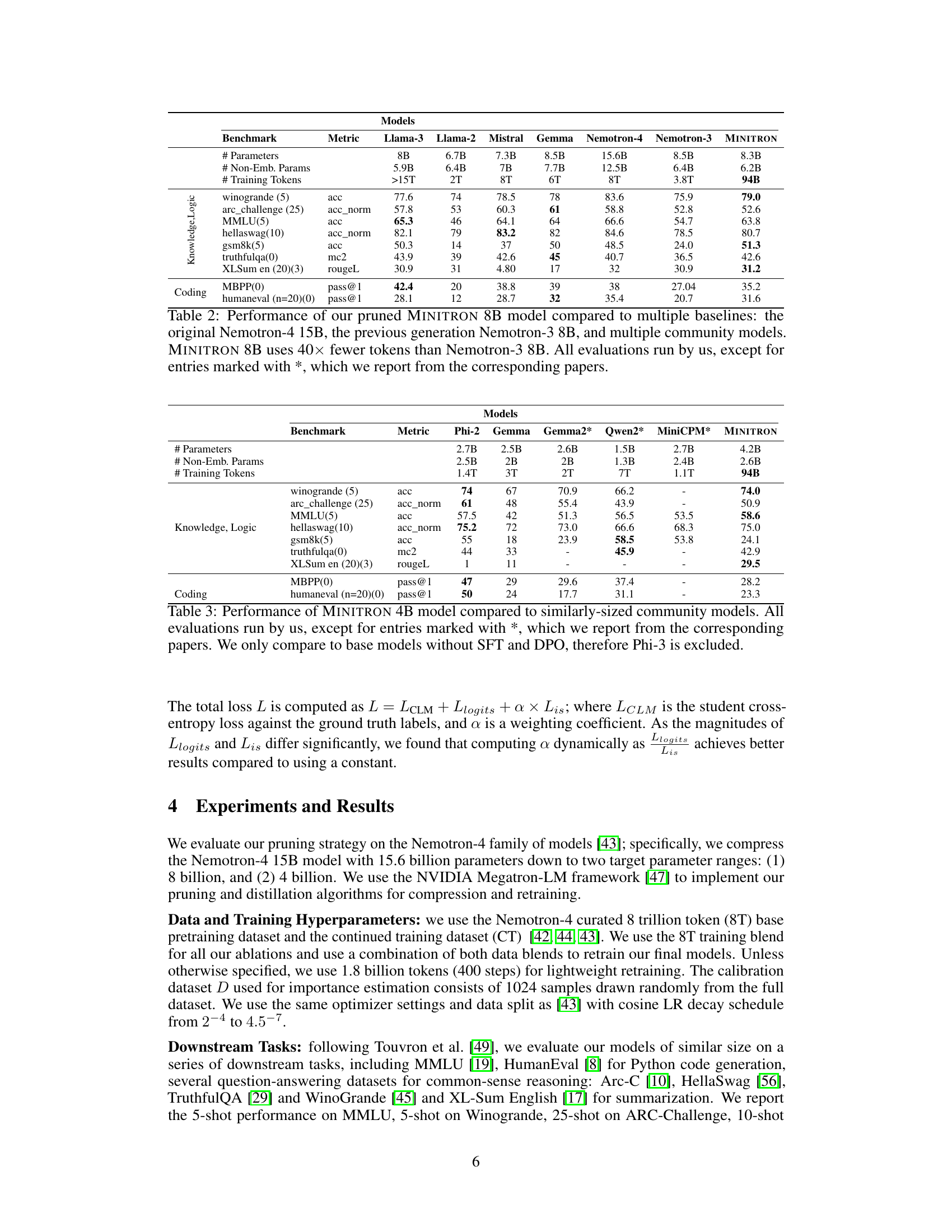
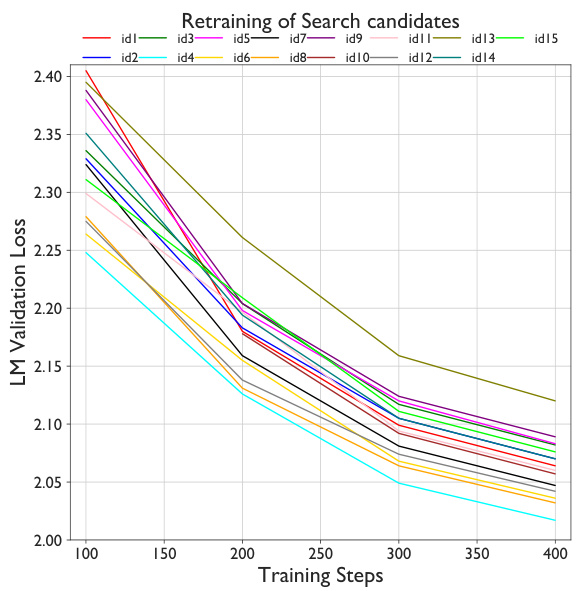
🔼 This table demonstrates the impact of different pruning strategies on a 15B parameter language model before and after retraining with a small amount of data (~1.8B tokens). The model is pruned to 8B parameters, and the results compare the change in distillation loss (KL divergence) and LM validation loss. The results highlight that pruning width (attention, MLP, embedding layers) is more effective than pruning depth, but only after retraining.
read the caption
Table 1: Demonstration of how various pruning strategies perform before and after lightweight retraining using ~1.8B tokens. We prune the Nemotron-4 15B model down to the size of Nemotron-3 8B and report the change in distillation loss (KL divergence [28] on logits) and the final LM validation loss with retraining. We see that width (attention, MLP, embedding) pruning outperforms depth, but only after retraining. The last row shows change in loss for the Nemotron-3 8B model.
In-depth insights#
LLM Compression#
LLM compression techniques aim to reduce the size and computational cost of large language models (LLMs) while preserving their performance. Pruning, a common method, involves removing less important parameters (weights and connections) from the model. Different pruning strategies exist, such as unstructured, structured (e.g., pruning entire layers, heads, or channels), and those guided by various criteria like weight magnitude, gradient information, or activation patterns. Knowledge distillation is another key technique, transferring knowledge from a larger, more complex teacher model to a smaller student model. This typically involves training the student model to mimic the teacher model’s output and/or intermediate representations. Quantization reduces the precision of numerical representations (e.g., from 32-bit floating-point to 8-bit integers), lowering memory footprint and computational demands. Combining multiple techniques often yields the best results, leading to substantial compression without significant performance degradation. The choice of optimal compression strategy depends on factors such as the specific LLM architecture, target size, and desired performance trade-offs.
Pruning Strategies#
Effective pruning strategies for large language models (LLMs) are crucial for achieving optimal compression and performance. Structured pruning, which removes entire blocks of weights instead of individual ones, is a popular approach. Different axes can be targeted, including depth (layers), width (attention heads, MLP neurons, embedding channels), and combinations thereof. The choice of pruning axis and the order of pruning significantly impact the resulting model’s performance. For instance, width pruning may outperform depth pruning after retraining, highlighting the importance of iterative processes and knowledge distillation. Determining the importance of each component is vital, employing various metrics like activation-based importance or gradient-based methods. Combining these techniques, researchers often develop best practices for selecting axes, order, and retraining strategies for optimal cost and accuracy trade-offs. Data-efficient retraining via techniques like knowledge distillation is key to minimize retraining costs and preserve model accuracy after pruning, making this a critical aspect of effective pruning strategies. Ultimately, the selection of the best approach depends heavily on the specific LLM architecture, task, and available computational resources.
Distillation Methods#
Distillation methods in large language model (LLM) compression are crucial for transferring knowledge from a larger, more capable teacher model to a smaller, faster student model. Effective distillation techniques minimize information loss during compression, resulting in improved student model performance. This often involves matching the teacher’s output probability distributions or intermediate hidden states, leveraging various loss functions like KL divergence or MSE to guide the training process. The choice of loss function and the specific aspects of the teacher model that are distilled (logits, hidden states, embeddings) significantly impact the final student model’s accuracy and efficiency. Furthermore, retraining strategies, such as iterative pruning and distillation or lightweight retraining, play a pivotal role in recovering accuracy losses associated with the compression process. The optimal approach depends heavily on factors such as the model’s architecture, target size, available data, and desired computational cost. Research indicates that combining different distillation methods or employing advanced techniques such as layer normalization can enhance the effectiveness of distillation. Careful design and selection of distillation methods is critical to achieving a balance between model size reduction and performance preservation. Ultimately, successful LLM compression hinges on a well-defined strategy incorporating suitable distillation methods, along with other techniques such as pruning and knowledge transfer.
MINITRON Results#
The MINITRON results demonstrate a successful approach to compressing large language models (LLMs). By combining pruning techniques with knowledge distillation, MINITRON achieves significant reductions in model size (2-4x) while maintaining or exceeding performance compared to other similarly-sized LLMs. The reduction in training costs is substantial (up to 40x fewer training tokens) compared to training smaller models from scratch, highlighting the efficiency and cost-effectiveness of this approach. MINITRON models exhibit competitive performance across various benchmarks, often matching or surpassing other popular models like Mistral 7B, Gemma 7B, and Llama-3 8B. The results underscore that pruning and knowledge distillation are effective strategies for creating efficient and high-performing LLMs, potentially democratizing access to these powerful models.
Future Work#
Future research directions stemming from this paper on compact language models could involve several key areas. Extending the pruning and distillation techniques to other LLM architectures beyond the Nemotron family is crucial for broader applicability. Investigating the effectiveness of combining these methods with other compression strategies, such as quantization or low-rank approximation, warrants exploration to achieve even greater efficiency gains. A deeper understanding of the trade-offs between compression rate, computational cost during retraining, and downstream task performance is needed. Furthermore, developing more sophisticated importance analysis methods that better capture the complex interactions within LLMs could refine the pruning process. Finally, exploring the impact of different training data distributions and their effect on the performance of pruned models will help optimize the retraining stage. Research into transfer learning techniques for adapting pruned models to new downstream tasks with minimal retraining would also broaden their utility.
More visual insights#
More on figures

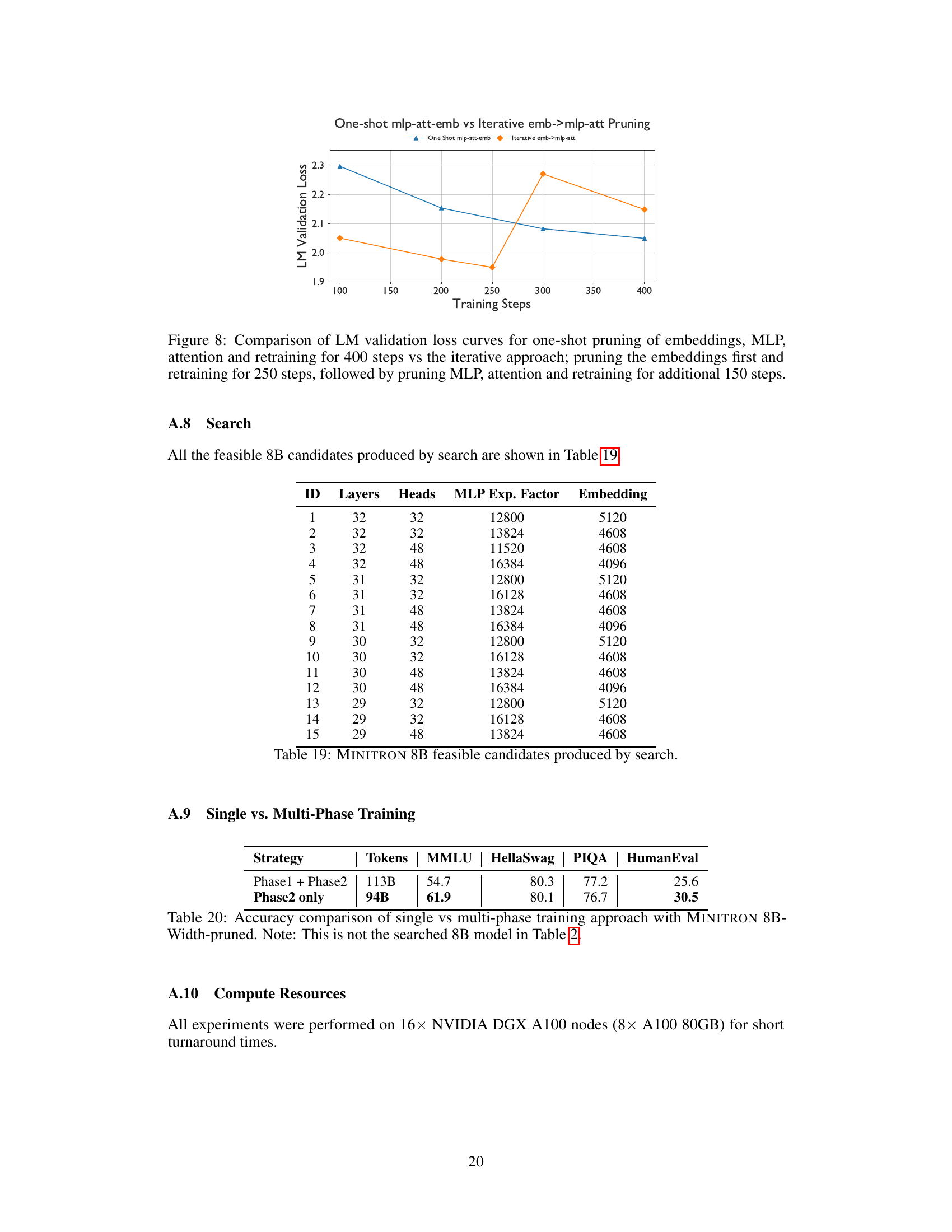
🔼 This figure illustrates the iterative process of pruning and knowledge distillation used to create a family of smaller LLMs from a larger, pre-trained model. It shows the steps involved: 1. Starting with a trained LLM. 2. Estimating the importance of different components (neurons, heads, embeddings) within the model. 3. Ranking these components by importance. 4. Trimming (removing) the least important components. 5. Performing knowledge distillation to transfer knowledge from the original model to the pruned model. Steps 2-5 are repeated iteratively to progressively reduce the model size while retaining performance.
read the caption
Figure 2: High-level overview of our proposed iterative pruning and distillation approach to train a family of smaller LLMs. On a pretrained LLM, we first evaluate importance of neurons, rank them, trim the least important neurons and distill the knowledge from the original LLM to the pruned model. The original model is replaced with the distilled model for the next iteration of compression.
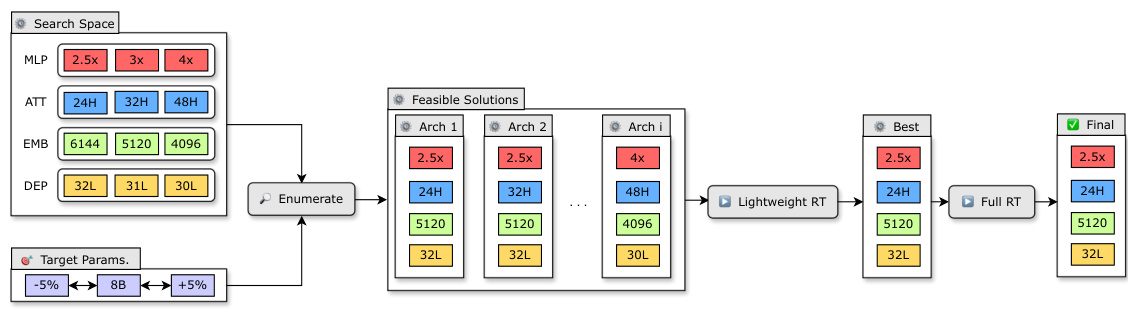
🔼 This figure illustrates the neural architecture search algorithm used to find optimal compressed architectures for LLMs. The process starts with a defined search space encompassing various parameters (number of layers, attention heads, MLP expansion factor, and embedding dimensions). The algorithm then enumerates all possible architectures within the specified parameter budget. These candidates undergo lightweight retraining, and their performance is evaluated. Finally, a best-performing architecture is selected and further refined through full retraining.
read the caption
Figure 3: Overview of our neural architecture search algorithm. We perform a search on multiple axes: number of layers, attention head count, MLP and embedding dimensions to arrive at a set of feasible architectures meeting the parameter budget. RT refers to retraining.
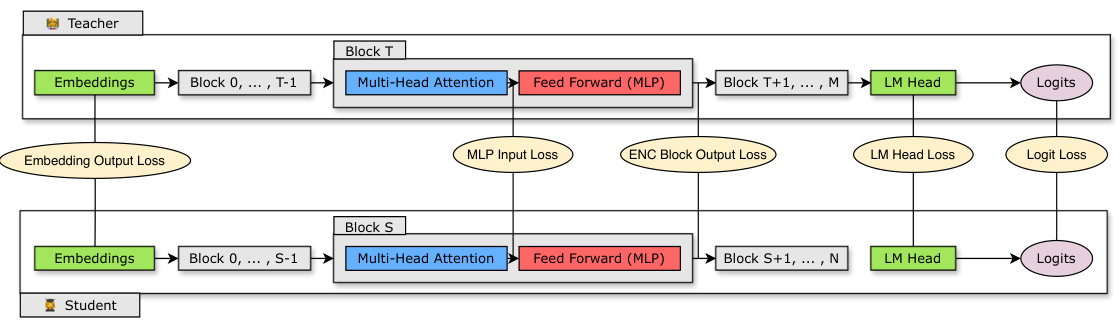
🔼 This figure illustrates the knowledge distillation process used in the paper to retrain smaller language models (LLMs). It shows a teacher model (larger LLM) and a student model (smaller LLM). The student model learns to mimic the teacher model’s output and intermediate states by minimizing various loss functions. These losses include the differences between the teacher and student’s embeddings, MLP inputs, encoder block outputs, LM head outputs, and logits.
read the caption
Figure 4: Overview of Distillation. A student model with N layers is distilled from a teacher model with M layers. The student learns by minimizing a combination of embedding output loss, logit loss and transformer encoder specific losses mapped across student block S and teacher block T.
🔼 This figure compares the training cost and MMLU performance of MINITRON models (resulting models after compression) with other state-of-the-art language models. The x-axis represents the training cost measured in trillions of tokens. The y-axis shows the MMLU scores (%). The figure highlights that MINITRON models achieve comparable or better performance than other models while requiring significantly less training data (up to 40 times less). For example, MINITRON 8B shows 9% better MMLU performance than Nemotron-4 15B while being 40 times cheaper to train.
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.

🔼 This figure demonstrates the cost-effectiveness of the MINITRON approach. By pruning and retraining a large language model (15B parameters), the authors created smaller models (8B and 4B parameters). The figure highlights that training these smaller models using MINITRON requires significantly fewer training tokens (up to 40x less) compared to training them from scratch. Despite this reduction in training cost, the smaller MINITRON models achieve comparable or even better performance on various benchmarks (as measured by MMLU scores) than similarly sized models trained from scratch.
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.
🔼 This figure shows the results of the MINITRON model compression technique. The x-axis represents the cost to train a model (in trillions of tokens), and the y-axis represents the MMLU score (%). The plot compares MINITRON models of different sizes (4B and 8B) to other state-of-the-art models such as Gemma 7B, Llama-3 8B, and Mistral 7B. It demonstrates that MINITRON achieves comparable or even better results with significantly lower training costs, representing a 40x reduction in training cost. This highlights the efficiency of MINITRON in compressing large language models.
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.

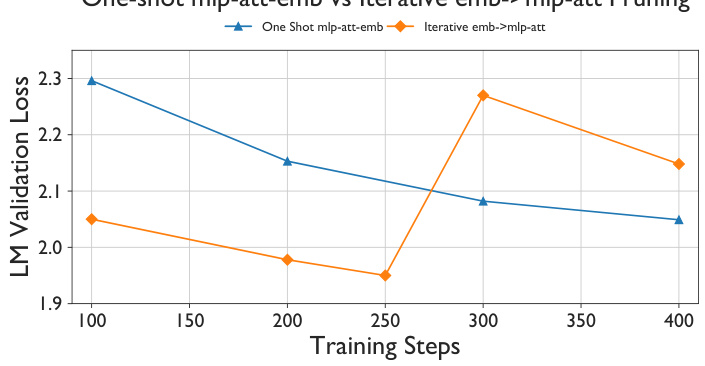
🔼 This figure compares the performance of iterative and one-shot pruning and retraining strategies on three downstream tasks: MMLU, HellaSwag, and HumanEval. The x-axis represents the number of layers remaining after pruning, while the y-axis shows the accuracy achieved on each task. Multiple lines are presented showing the accuracy with different retraining token budgets, showing that the one-shot strategy generally outperforms the iterative strategy across all three tasks.
read the caption
Figure 7: Accuracy on MMLU, HellaSwag and HumanEval benchmarks for iterative vs one-shot depth pruning and retraining strategy. One shot pruning and retraining outperforms the iterative approach.
🔼 This figure demonstrates the cost-effectiveness of the MINITRON approach. It compares the training cost (in trillions of tokens) to achieve various model sizes (Minitron models shown in different colors) versus training from scratch. The chart shows that MINITRON models (derived from a larger pretrained model through pruning and retraining) are significantly cheaper to train (40x less) than training from scratch, while simultaneously exhibiting improved performance (indicated by the higher MMLU scores).
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.
🔼 This figure shows the results of applying the MINITRON compression technique to a family of LLMs. The x-axis represents the cost to train the models (in trillions of tokens), and the y-axis represents the MMLU score (a measure of the models’ performance on various language modeling tasks). The figure demonstrates that compression significantly reduces the training cost (by a factor of 40x) while yielding comparable or even better results compared to training larger models from scratch. The chart also compares MINITRON models with other models from the field.
read the caption
Figure 1: Results for MINITRON. Compression results in significant reduction of training costs for additional models (40×) while producing better results.
More on tables

🔼 This table compares the performance of the MINITRON 8B model against several baselines, including previous generations of the Nemotron model and other comparable models from the research community. The key finding is that MINITRON 8B achieves comparable or better performance while using significantly fewer training tokens (40x less than Nemotron-3 8B).
read the caption
Table 2: Performance of our pruned MINITRON 8B model compared to multiple baselines: the original Nemotron-4 15B, the previous generation Nemotron-3 8B, and multiple community models. MINITRON 8B uses 40x fewer tokens than Nemotron-3 8B. All evaluations run by us, except for entries marked with *, which we report from the corresponding papers.
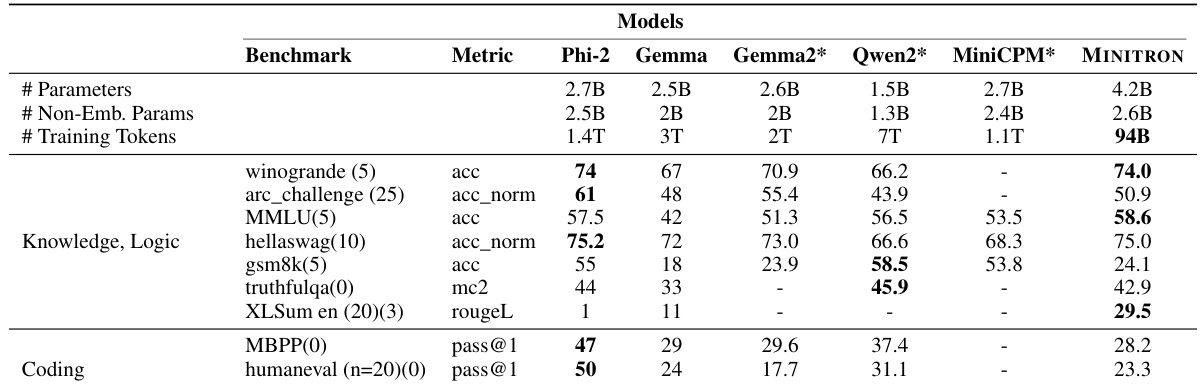
🔼 This table compares the performance of the MINITRON 4B model against other models of similar size from the research community. The metrics used are across various common benchmarks for evaluating large language models. The table highlights that MINITRON 4B, despite using significantly fewer training tokens (94B vs 1.1T-3T), performs comparably or even better than several other models on several tasks.
read the caption
Table 3: Performance of MINITRON 4B model compared to similarly-sized community models. All evaluations run by us, except for entries marked with *, which we report from the corresponding papers. We only compare to base models without SFT and DPO, therefore Phi-3 is excluded.
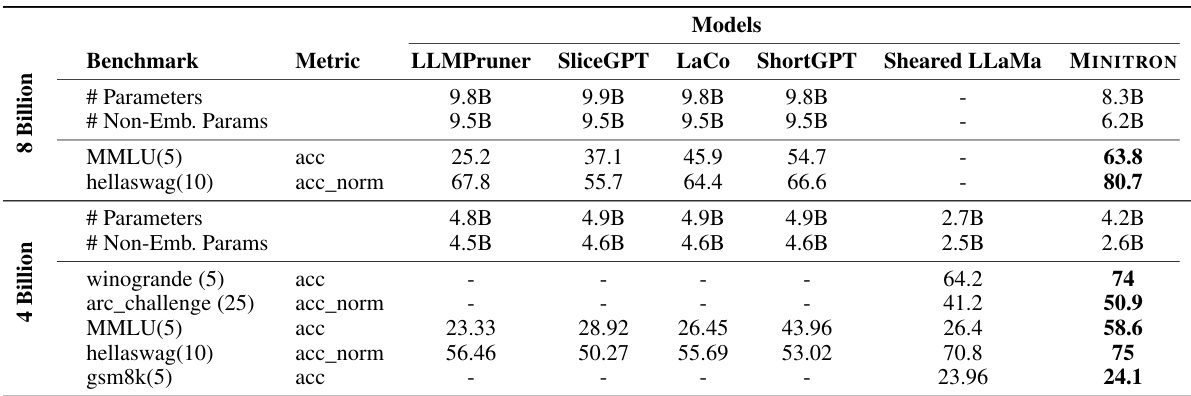
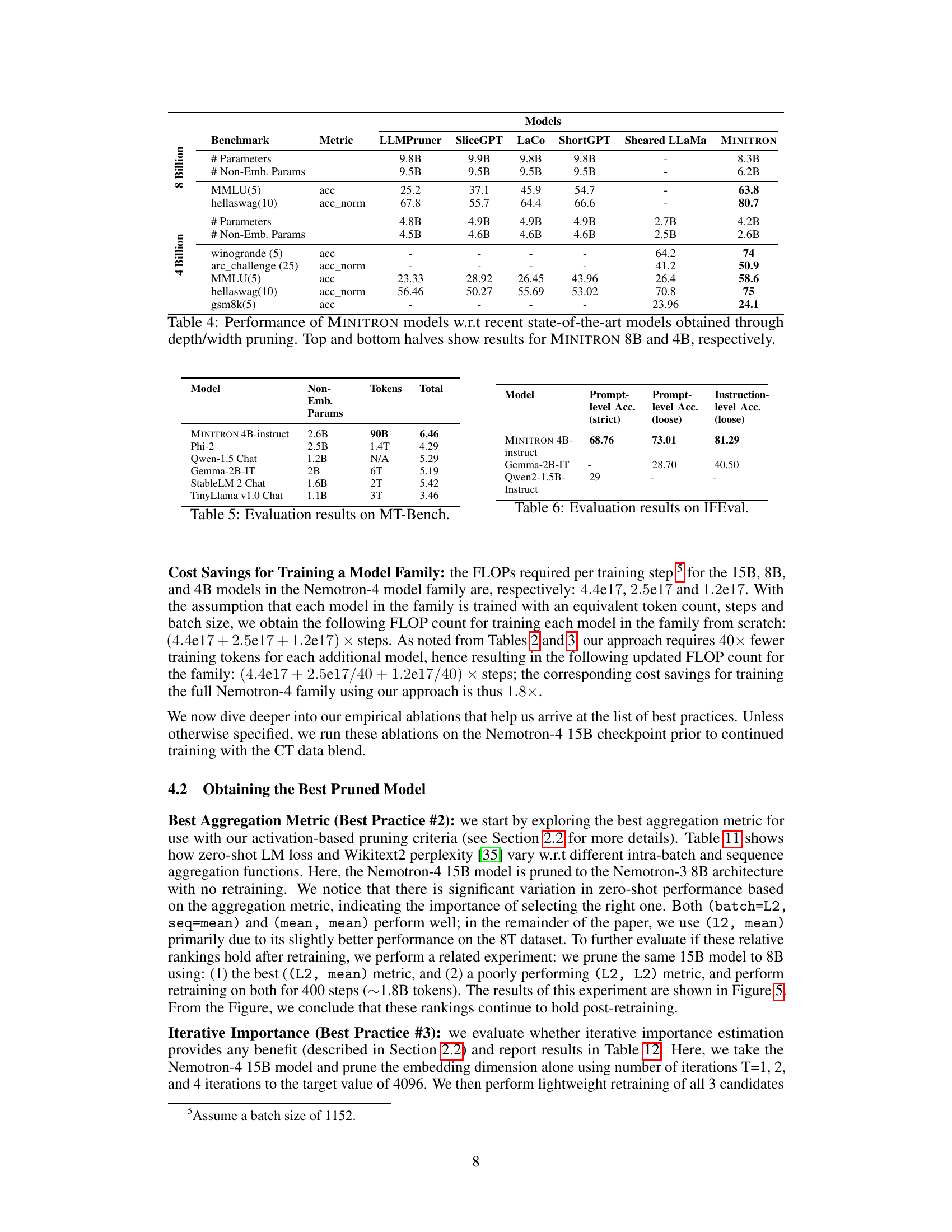
🔼 This table compares the performance of MINITRON 8B and 4B models against other state-of-the-art models that used depth or width pruning techniques. It highlights MINITRON’s competitive performance, particularly its superior results compared to models of similar size and the significant improvement in accuracy it achieves over those models.
read the caption
Table 4: Performance of MINITRON models w.r.t recent state-of-the-art models obtained through depth/width pruning. Top and bottom halves show results for MINITRON 8B and 4B, respectively.
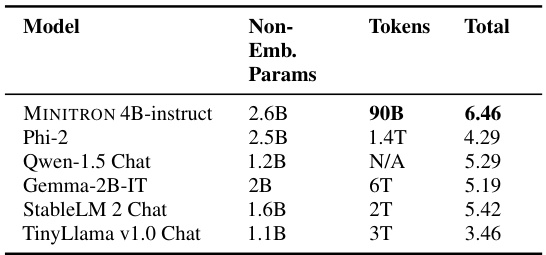
🔼 This table presents a comparison of the MINITRON 4B-instruct model’s performance on the MT-Bench benchmark against several other models, including Phi-2, Qwen-1.5 Chat, Gemma-2B-IT, StableLM 2 Chat, and TinyLlama v1.0 Chat. The comparison highlights MINITRON 4B-instruct’s performance relative to other models of similar size, indicating its competitive performance across various instruction-following tasks.
read the caption
Table 5: Evaluation results on MT-Bench.

🔼 This table presents the performance comparison of MINITRON 4B-instruct and Gemma-2B-IT models on the ChatRAG-Bench benchmark. The average score across all tasks for MINITRON 4B-instruct is 41.11, which is higher than that of Gemma-2B-IT (33.31). This demonstrates that MINITRON 4B-instruct, created using pruning and knowledge distillation techniques, achieves better performance on instruction-following and role-playing tasks compared to Gemma-2B-IT.
read the caption
Table 7: Evaluation results on ChatRAG-Bench.

🔼 This table presents the average performance of MINITRON 4B-instruct and other comparable models on the Berkeley Function Calling Leaderboard (BFCL v2). MINITRON 4B-instruct demonstrates superior performance compared to Gemma-2B-IT and Llama-3-8B-instruct.
read the caption
Table 8: Evaluation results on BFCL v2.

🔼 This table specifies the search space for the hyperparameters of MINITRON 8B and 4B models. The search space includes the number of layers, the number of attention heads, the MLP expansion factor, and the embedding dimension. Each hyperparameter has a range of possible values, indicating the different model configurations explored during the neural architecture search process.
read the caption
Table 9: MINITRON 8B and 4B search space.

🔼 This table presents the architectural specifications of four language models: Nemotron-4 15B, Nemotron-3 8B, MINITRON 8B, and MINITRON 4B. It details the number of layers, hidden size, attention heads, query groups, MLP hidden size, and total number of parameters for each model. The table highlights the architectural differences between the original Nemotron models and their compressed MINITRON counterparts, showcasing the reduction in parameters achieved through pruning.
read the caption
Table 10: Architecture details of the uncompressed Nemotron and pruned MINITRON models. Vocabulary size is 256k for all models.
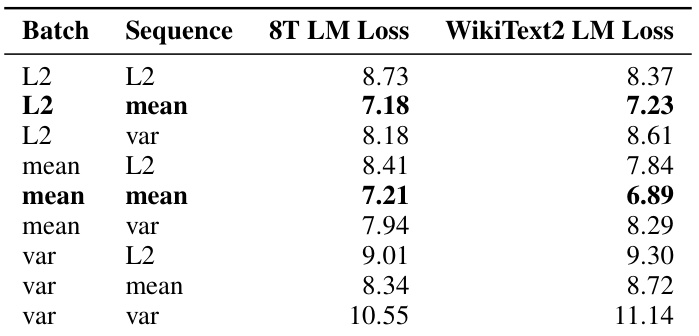
🔼 This table presents the results of an experiment evaluating different aggregation functions for computing activation-based importance scores for structured pruning of LLMs. The experiment compares various combinations of batch and sequence aggregation methods (mean, L2 norm, variance) and their impact on the language modeling (LM) loss for two datasets: 8T and WikiText2. The results are shown as zero-shot LM loss (before retraining). This helps determine the best strategy for calculating importance scores during pruning, as different approaches can impact the overall model performance significantly.
read the caption
Table 11: Zero-shot performance of activation-based importance with different batch and sequence aggregation metrics. LM loss is reported on the validation set of the 8T and WikiText2 datasets.

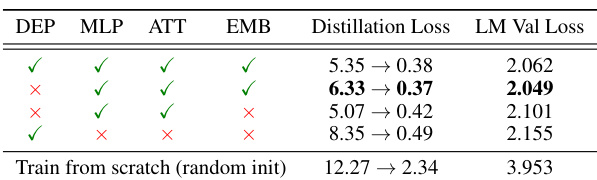
🔼 This table demonstrates the performance of different pruning strategies on a language model before and after retraining. It shows the change in distillation loss and the LM validation loss after applying various pruning methods (depth, width, attention, MLP, and embedding). The results highlight that width pruning is superior to depth pruning, but only after a lightweight retraining process.
read the caption
Table 1: Demonstration of how various pruning strategies perform before and after lightweight retraining using ~1.8B tokens. We prune the Nemotron-4 15B model down to the size of Nemotron-3 8B and report the change in distillation loss (KL divergence [28] on logits) and the final LM validation loss with retraining. We see that width (attention, MLP, embedding) pruning outperforms depth, but only after retraining. The last row shows change in loss for the Nemotron-3 8B model.

🔼 This table compares the Language Model (LM) validation loss after retraining with 1.8 billion tokens for four different pruning strategies applied to the MINITRON 8B model. The strategies are: pruning only depth using perplexity (PPL) as the metric, pruning only depth using Block Importance (BI) as the metric, pruning only width (attention, MLP, and embedding dimensions), and combining both depth and width pruning. The table shows that although the combined depth and width pruning results in a smaller model, the width-only pruning strategy achieves the lowest LM validation loss after retraining.
read the caption
Table 13: Comparison of retraining LM loss across different pruning strategies post retraining with 1.8B tokens. We explore depth only, width only, and a combination of both. Width only strategy though with the least parameter count outperforms the rest.

🔼 This table compares the performance of training a 4B model using different methods: random initialization, pruning a 15B model and retraining, and pruning a 15B or 8B model with knowledge distillation. It demonstrates the effectiveness of knowledge distillation for improving the accuracy of pruned models and shows the advantage of pruning a smaller model rather than a large one.
read the caption
Table 14: Accuracy comparison across different strategies to train a 4B model. Pruning the 15B model and distillation results in a gain of 4.8% on Hellaswag and 13.5% on MMLU compared to training from scratch with equivalent compute. Pruning an 8B model instead of a 15B model results in an additional gain of 1% and 4.6% on the benchmarks. * Indicates settings with iso-compute.

🔼 This table demonstrates the performance of different pruning strategies on a 15B parameter language model before and after retraining with a small amount of data (1.8B tokens). It compares the impact of pruning different aspects of the model (depth, width of attention, MLP, and embedding layers) on the distillation loss (KL divergence) and final language modeling validation loss. The results show that width pruning generally outperforms depth pruning, but only after the retraining step.
read the caption
Table 1: Demonstration of how various pruning strategies perform before and after lightweight retraining using ~1.8B tokens. We prune the Nemotron-4 15B model down to the size of Nemotron-3 8B and report the change in distillation loss (KL divergence [28] on logits) and the final LM validation loss with retraining. We see that width (attention, MLP, embedding) pruning outperforms depth, but only after retraining. The last row shows change in loss for the Nemotron-3 8B model.

🔼 This table compares different pruning strategies (depth, width) applied to the Nemotron-4 15B model before and after retraining. The results show that width pruning generally outperforms depth pruning, but only when combined with lightweight retraining (using around 1.8 billion tokens). The table highlights the change in distillation loss and the final language model validation loss after retraining.
read the caption
Table 1: Demonstration of how various pruning strategies perform before and after lightweight retraining using ~1.8B tokens. We prune the Nemotron-4 15B model down to the size of Nemotron-3 8B and report the change in distillation loss (KL divergence [28] on logits) and the final LM validation loss with retraining. We see that width (attention, MLP, embedding) pruning outperforms depth, but only after retraining. The last row shows change in loss for the Nemotron-3 8B model.

🔼 This table demonstrates the performance of different pruning strategies (depth, width, attention, and MLP) on the Nemotron-4 15B language model before and after lightweight retraining with approximately 1.8 billion tokens. It compares the change in distillation loss (KL divergence) and final language modeling validation loss for each pruning strategy. The results show that width pruning generally outperforms depth pruning, especially after retraining.
read the caption
Table 1: Demonstration of how various pruning strategies perform before and after lightweight retraining using ~1.8B tokens. We prune the Nemotron-4 15B model down to the size of Nemotron-3 8B and report the change in distillation loss (KL divergence [28] on logits) and the final LM validation loss with retraining. We see that width (attention, MLP, embedding) pruning outperforms depth, but only after retraining. The last row shows change in loss for the Nemotron-3 8B model.
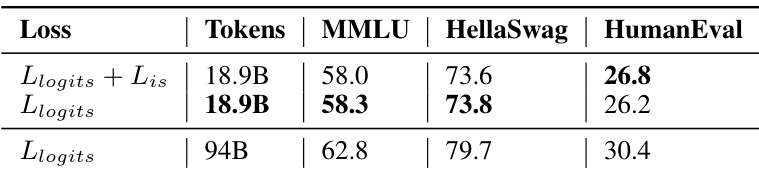
🔼 This table presents the ablation study results for MINITRON 8B model, comparing the performance using different loss functions: Llogits + Lis and Llogits, with varying training token counts. It demonstrates that adding Lis to the Llogits loss function does not significantly improve performance compared to using Llogits alone, even with increased training tokens.
read the caption
Table 18: Ablation study for MINITRON 8B with and without the loss component Lis , and increased retraining token count with Llogits . Adding Lis performs on par with using Llogits alone.
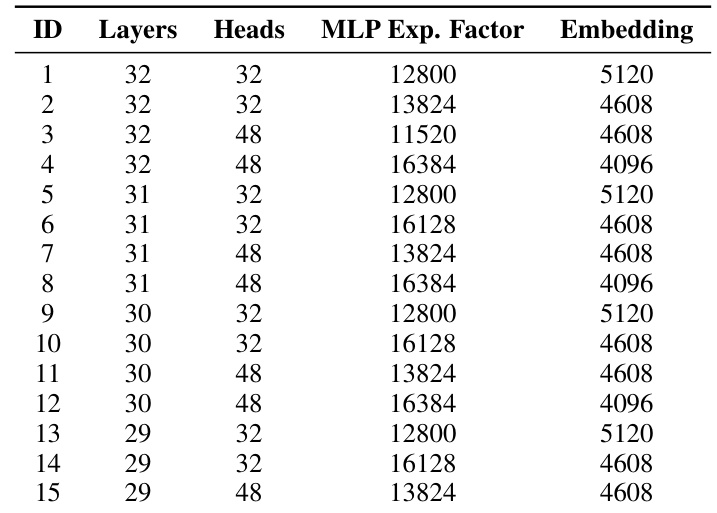
🔼 This table presents the search space used for finding optimal architecture configurations for MINITRON 8B and 4B models. It shows the range of values considered for the number of layers, attention heads, MLP expansion factor, and embedding dimensions.
read the caption
Table 9: MINITRON 8B and 4B search space.

🔼 This table compares the performance of the MINITRON 8B model against several baselines, including the original Nemotron-4 15B, Nemotron-3 8B, and various other community models. Key metrics across multiple benchmarks (Knowledge, Logic, and Coding) are presented, highlighting MINITRON 8B’s performance despite using significantly fewer training tokens (40x fewer than Nemotron-3 8B). The asterisk (*) indicates results taken from other published papers.
read the caption
Table 2: Performance of our pruned MINITRON 8B model compared to multiple baselines: the original Nemotron-4 15B, the previous generation Nemotron-3 8B, and multiple community models. MINITRON 8B uses 40x fewer tokens than Nemotron-3 8B. All evaluations run by us, except for entries marked with *, which we report from the corresponding papers.
Full paper#