TL;DR#
Image-to-text models are vulnerable to adversarial attacks, with existing methods often suffering from semantic loss or requiring impractical access to model internals. Current gray-box attacks, while more practical, still exhibit this semantic loss, limiting their effectiveness in targeted attacks. Decision-based black-box attacks, where only the model’s output text is accessible, pose an even greater challenge.
This paper introduces a novel three-stage method (AAA) to overcome these limitations. AAA systematically constructs targeted attacks by first defining target text semantics (Ask), then identifying key image regions via attention mechanisms (Attend), and finally implementing these attacks via an evolutionary algorithm (Attack). Experiments demonstrate AAA’s efficacy in generating targeted attacks with minimal semantic loss, exceeding the performance of existing gray-box approaches on both transformer-based and CNN+RNN-based models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles a critical challenge in the field of adversarial attacks against image-to-text models: decision-based black-box attacks, which are more realistic and harder to defend against than existing white-box or gray-box methods. The proposed AAA framework offers a novel approach to generating targeted adversarial examples without semantic loss, thus advancing the understanding and development of defense mechanisms against such attacks. This work will inspire further research in developing more robust and practical defense mechanisms, leading to safer and more reliable image-to-text models.
Visual Insights#

🔼 This figure illustrates the problem of semantic loss in existing gray-box targeted attack methods. Panel (a) shows a traditional approach where an adversarial perturbation is added to a clean image, leading the image-to-text model to produce an incorrect output text. The generated text (“there are two boys brushing their teeth in the bathroom”) semantically mismatches the intended target text (“a boy and a girl are looking at a camera in the mirror”). This demonstrates semantic loss. In contrast, panel (b) depicts the proposed method’s approach. Here, the adversarial image generated using the method results in an output text that closely matches the intended target text, showing that semantic loss is mitigated.
read the caption
Figure 1: The semantic loss problem is existing in existing gray-box targeted attack methods.
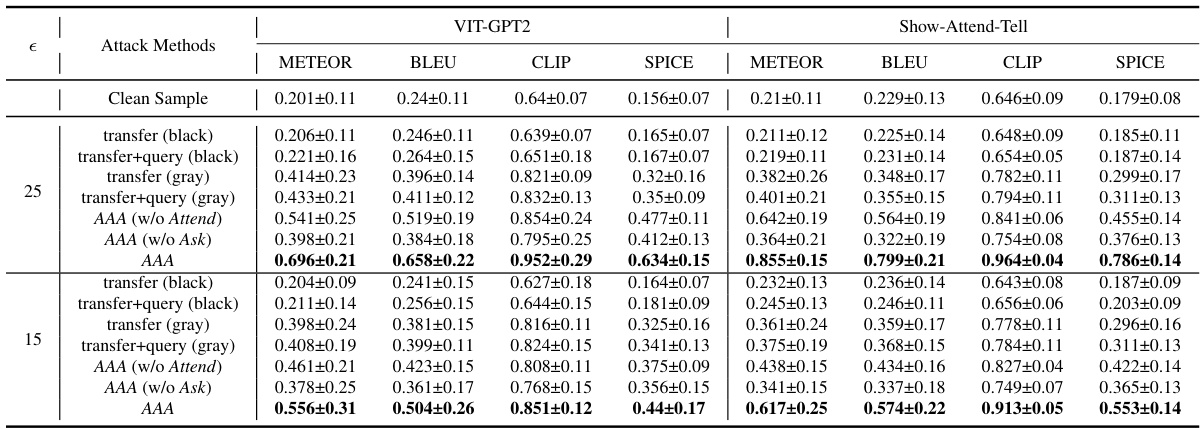
🔼 This table presents a quantitative comparison of different attack methods on two image-to-text models, VIT-GPT2 and Show-Attend-Tell. The metrics used for comparison include METEOR, BLEU, CLIP, and SPICE scores, which assess different aspects of the generated text’s quality and similarity to the ground truth. The table shows results for both black-box and gray-box attacks, with and without certain components of the proposed AAA (Ask, Attend, Attack) method. The epsilon (ε) values represent different perturbation sizes applied to the input images.
read the caption
Table 1: Performance comparison (%) of different attack methods.
In-depth insights#
Adv. Attack AAA#
The proposed “Adv. Attack AAA” framework tackles the challenging problem of black-box targeted attacks against image-to-text models. Its three-stage approach—Ask, Attend, and Attack—is particularly noteworthy. The ‘Ask’ stage cleverly guides the generation of semantically relevant target texts, improving attack precision. ‘Attend’ intelligently leverages attention mechanisms to pinpoint crucial image regions for manipulation, thereby significantly reducing the search space for the computationally intensive ‘Attack’ stage. The use of an evolutionary algorithm in the ‘Attack’ phase offers a robust and efficient solution for generating semantically consistent adversarial examples. Overall, AAA’s design addresses the limitations of existing methods by mitigating semantic loss and enhancing practicality, making it a significant contribution to the field of adversarial machine learning and image-to-text model security.
Black-box Limits#
The heading ‘Black-box Limits’ likely refers to the inherent constraints and challenges associated with attacking black-box machine learning models. A core limitation is the lack of access to internal model parameters and gradients. This prevents the use of gradient-based attacks, forcing researchers to rely on alternative methods like decision-based attacks or evolutionary algorithms. These methods are often less efficient and require more queries to the model, potentially raising concerns about practicality and scalability. The reliance on surrogate models or limited feedback mechanisms may introduce inaccuracies and biases, affecting the effectiveness and reliability of the attack. Furthermore, adversarial examples generated might suffer from semantic loss, meaning that while they successfully mislead the model, the output lacks the intended semantic meaning. Therefore, analyzing ‘Black-box Limits’ involves examining the trade-offs between attack effectiveness and practicality, along with the inherent difficulties of working with incomplete information about the target model.
Semantic Loss#
The concept of “semantic loss” in the context of adversarial attacks on image-to-text models refers to the degradation of the meaning or intended interpretation of the target text during the attack process. Existing gray-box methods, while improving practicality, often suffer from semantic loss because they focus on manipulating image features to directly influence the model’s output without sufficient consideration for preserving the original semantic meaning. This results in adversarial examples where the generated text is technically incorrect but also semantically unrelated to the intended target text, rendering the attack ineffective. The proposed AAA method in the paper aims to directly address this issue by explicitly incorporating semantic preservation into the attack strategy using a three-stage process: Ask (to specify the target semantics), Attend (to focus on crucial image regions), and Attack (using a semantically informed evolutionary algorithm). By targeting the semantics directly, the authors aim to generate targeted attacks with minimal semantic loss, thus producing more effective and stealthy adversarial examples that fool image-to-text models without sacrificing the accuracy and meaning of the target text.
Evolutionary AAA#
An “Evolutionary AAA” framework, as suggested, would likely involve a three-stage process: Ask, Attend, and Attack. The “Ask” phase would focus on intelligently generating target texts, possibly employing natural language processing techniques to ensure semantic relevance and coherence. The “Attend” phase would leverage attention mechanisms or similar techniques to pinpoint crucial image regions for manipulation. This targeted approach is key to improving efficiency. Finally, the “Attack” phase would employ evolutionary algorithms—such as genetic algorithms or differential evolution—to iteratively refine adversarial perturbations within the identified image regions. This evolutionary approach is crucial because it allows for exploration of the vast search space of possible perturbations without the need for gradient information (a key feature of black-box attacks), making it highly adaptable to various image-to-text models. The evolutionary process would likely incorporate fitness functions measuring the semantic similarity between generated text and target text, guiding the search towards effective adversarial examples. The combination of intelligent target generation, focused attention, and evolutionary optimization promises an effective and practical strategy for black-box, targeted attacks on image-to-text models. However, challenges remain, including computational cost of evolutionary algorithms, and the need for robust fitness functions to avoid local optima and maintain semantic meaning. Further research should explore more efficient evolutionary strategies and refined fitness functions for better performance and scalability.
Future Research#
The paper’s ‘Future Research’ section would ideally explore several key areas. Improving the efficiency of the evolutionary algorithm is crucial, perhaps through incorporating more advanced optimization techniques or leveraging gradient information where possible (a grey-box approach). Reducing the number of queries to the target model is also vital to increase practicality and circumvent potential defensive strategies that limit query access. The study should investigate the impact of different surrogate models in the ‘Attend’ phase and explore alternative attention mechanisms. Furthermore, a thorough analysis comparing AAA against other black-box or even gray-box methods under varying conditions is needed. Finally, exploring potential defenses against AAA, and developing robust countermeasures, would significantly contribute to a more comprehensive understanding of the adversarial landscape for image-to-text models.
More visual insights#
More on figures

🔼 This figure illustrates the three-stage process of the proposed AAA attack method. The Ask stage involves selecting semantically related words to generate a target text. The Attend stage uses an attention mechanism to identify crucial image regions. Finally, the Attack stage employs a differential evolution algorithm to perturb these regions and achieve a targeted attack without semantic loss. The figure visually depicts the flow of information and the interaction between the three stages.
read the caption
Figure 2: Diagram of our decision-based black-box targeted attack method Ask, Attend, Attack.

🔼 This figure compares the convergence curves of the proposed AAA attack method with and without the Attend stage. It shows that incorporating the Attend stage leads to faster convergence and better attack performance. The figure also visualizes the attention heatmap and the resulting adversarial images with and without the Attend stage, highlighting the impact on both the attack’s efficiency and visual imperceptibility.
read the caption
Figure 3: We compared the convergence curves of populations with and without Attend under the same perturbation size e in (a-b). The fitness function is Sclip in Formula 12, where lower values mean stronger attacks. The dashed line is the average fitness value, and the solid line is the best fitness value. The green line is AAA and the red line is AAA w/o Attend. (c) shows the attention heatmap. (d) and (e) show the visual effects of adversarial image with and without Attend, with minimal perturbation of 100% attack success rate.

🔼 This figure compares Grad-CAM attention heatmaps generated by three different surrogate models (ResNet50, DenseNet121, and Vision Transformer) for the same target text: ‘a woman is holding a pair of shoes’. The heatmaps highlight the image regions that the models focus on to generate the caption. The different colors represent the strength of the attention signal, with warmer colors indicating stronger attention. The figure also provides the evaluation metrics (METEOR, BLEU, CLIP, and SPICE) for each model’s caption generation, showing the effectiveness of each model in generating the target text.
read the caption
Figure 4: Grad-CAM attention heatmaps of different surrogate models for the same target text a woman is holding a pair of shoes. M is METEOR, B is BLEU, C is CLIP, S is SPICE.

🔼 This figure compares the performance of adversarial attacks with different perturbation sizes. The top row shows the results of the proposed AAA method, while the bottom row shows results from existing methods. Column (e) displays the attention heatmap generated by the model, highlighting which image regions are most crucial for the attack. Column (j) shows the target image from existing methods. The metrics used to evaluate the attack’s success are METEOR, BLEU, and CLIP scores.
read the caption
Figure 5: Performance of adversarial image attacks varies with perturbation size ∈. The ∈ of (a) and (f) is 25, ∈ of (b) and (g) is 15, ∈ of (c) and (h) is 10, ∈ of (d) and (i) is 5. (e) is our attention heatmap of the target text on the image. (j) is the target image generated based on the target text used in existing works. M is METEOR score, B is BLEU score, and C is CLIP score.

🔼 This figure compares the computation time of three different attack methods: AAA (the proposed method), transfer, and transfer+query. The y-axis shows the similarity score (CLIP or BLEU) between the generated adversarial text and the target text, indicating attack success. The x-axis represents the computation time needed to achieve that level of similarity. The figure shows that while AAA takes longer to converge, it ultimately achieves higher similarity scores, demonstrating its effectiveness despite higher computational cost.
read the caption
Figure 6: Comparison of computation time for generating a single adversarial sample using different adversarial attack methods. The y-axis is a measure of similarity between the generated text and the target text, with higher values indicating better target attack performance. The x-axis represents the computation time, and the shorter the time required to find a stable solution, the better.

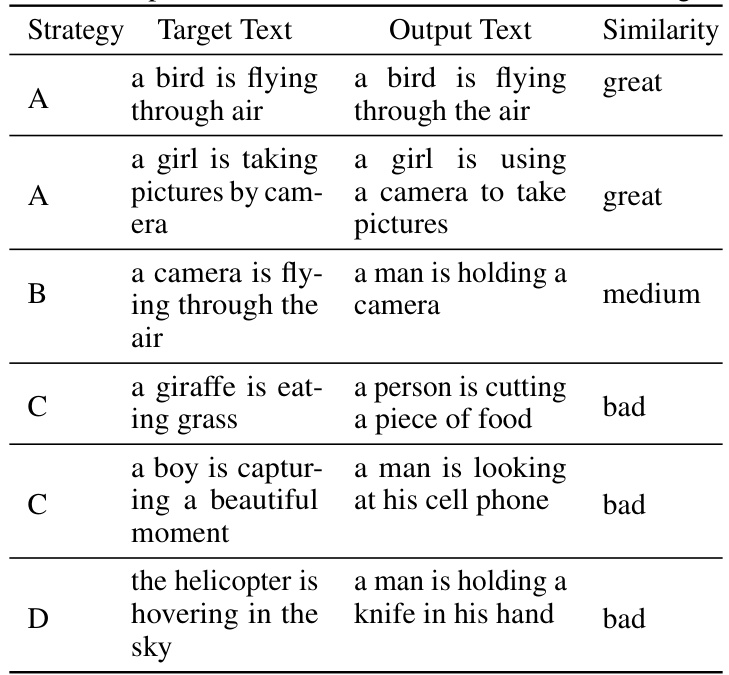
🔼 This figure presents four examples that illustrate the semantic loss problem in existing gray-box targeted attack methods. For each example, it shows the target image (generated from a target text using Stable Diffusion), the target text (the desired output), and the actual output text generated by the image-to-text model when given the target image. The similarity scores (METEOR, BLEU, CLIP, and SPICE) are provided to quantify the semantic difference between the target and output texts. The examples highlight how existing methods often fail to generate outputs with the intended semantics.
read the caption
Figure 7: More examples of semantic loss of existing gray-box targeted attacks. The target text is the error-generated text of the image-to-text model that the attacker wants to obtain. The target image is the image generated by using the text-to-image model (Stable Diffusion) based on the target text. The output text is based on the target image using the image-to-text target model (VIT-GPT2/Show-Attend-Tell). similarity indicates the similarity between the target text and the output text. We also show the similarity between the target text and the output text. M stands for METEOR score, B for BLEU score, C for CLIP score, and S for SPICE score.
🔼 This figure compares the convergence curves of populations with and without the Attend stage of the AAA attack method. It shows that using the Attend stage leads to faster convergence and a better attack success rate. The figure also visualizes the attention heatmap and demonstrates the visual difference between adversarial images generated with and without the Attend stage.
read the caption
Figure 3: We compared the convergence curves of populations with and without Attend under the same perturbation size e in (a-b). The fitness function is Sclip in Formula 12, where lower values mean stronger attacks. The dashed line is the average fitness value, and the solid line is the best fitness value. The green line is AAA and the red line is AAA w/o Attend. (c) shows the attention heatmap. (d) and (e) show the visual effects of adversarial image with and without Attend, with minimal perturbation of 100% attack success rate.

🔼 This figure compares the convergence curves of populations with and without the Attend stage of the AAA attack method. It shows that using the Attend stage improves the convergence speed and the overall attack effectiveness. The figure also includes an attention heatmap and example images to illustrate the visual impact of the attack with and without Attend.
read the caption
Figure 3: We compared the convergence curves of populations with and without Attend under the same perturbation size e in (a-b). The fitness function is Sclip in Formula 12, where lower values mean stronger attacks. The dashed line is the average fitness value, and the solid line is the best fitness value. The green line is AAA and the red line is AAA w/o Attend. (c) shows the attention heatmap. (d) and (e) show the visual effects of adversarial image with and without Attend, with minimal perturbation of 100% attack success rate.

🔼 This figure compares the computation time of different adversarial attack methods against two image-to-text models (VIT-GPT2 and Show, Attend, and Tell). The y-axis shows the similarity (METEOR and SPICE scores) between the generated adversarial text and the target text. Higher values represent better attacks. The x-axis shows the computation time in seconds. The figure demonstrates that the proposed AAA method, while achieving better attack performance, requires more computation time than existing gray-box methods (transfer and transfer+query).
read the caption
Figure 6: Comparison of computation time for generating a single adversarial sample using different adversarial attack methods. The y-axis is a measure of similarity between the generated text and the target text, with higher values indicating better target attack performance. The x-axis represents the computation time, and the shorter the time required to find a stable solution, the better.

🔼 This figure visualizes several examples of adversarial attacks. For each example, it shows the original image, the attention heatmap generated by a surrogate model, the adversarial image produced by the attack, the optimization convergence curve, the target text that the attacker aimed for, and the output text generated by the image-to-text model. The results demonstrate the effectiveness of the proposed attack method in generating adversarial images that cause the target model to output the desired text. The optimization curves indicate how the attack process converges to produce the optimal adversarial sample.
read the caption
Figure 11: Attention heatmaps, optimization convergence curves, target text, output text and attack performance for more adversarial samples.
More on tables

🔼 This table presents a quantitative comparison of the proposed AAA attack method against existing white-box and gray-box attack methods on two different image-to-text models: VIT-GPT2 and Show-Attend-Tell. The comparison is done using four evaluation metrics: METEOR, BLEU, CLIP, and SPICE, which assess different aspects of the generated text’s quality and similarity to the target text. The table shows the performance of different attack methods under various conditions, highlighting the advantages of the proposed AAA approach, particularly in the challenging black-box attack scenario.
read the caption
Table 1: Performance comparison (%) of different attack methods.

🔼 This table presents a quantitative comparison of the proposed AAA attack method against existing white-box and gray-box attack methods on two different image-to-text models: VIT-GPT2 and Show-Attend-Tell. The metrics used for comparison include METEOR, BLEU, CLIP, and SPICE, which measure the semantic similarity between the original and adversarial texts generated by each method. The table also shows the average perturbation size (epsilon) for each method, indicating the magnitude of the image modifications needed for a successful attack. This comparison highlights the effectiveness of the AAA method in a black-box setting, demonstrating better performance with less semantic loss compared to existing gray-box methods.
read the caption
Table 1: Performance comparison (%) of different attack methods.
🔼 This table presents a quantitative comparison of the proposed AAA attack method against existing state-of-the-art white-box and gray-box attack methods on two different image-to-text models: VIT-GPT2 and Show-Attend-Tell. The comparison uses four evaluation metrics (METEOR, BLEU, CLIP, SPICE) to assess the performance of each method in terms of achieving semantic similarity between the generated adversarial text and the target text. The table also shows the perturbation size (epsilon) used in each attack. This allows for a direct comparison of the effectiveness and stealthiness of the various approaches.
read the caption
Table 1: Performance comparison (%) of different attack methods.

🔼 This table compares the performance of different attack methods on two image-to-text models, VIT-GPT2 and Show-Attend-Tell. The metrics used for comparison are METEOR, BLEU, CLIP, and SPICE. The table shows the performance of several existing white-box and gray-box attacks, as well as the proposed AAA method (with and without the Attend and Ask stages). The results demonstrate the superiority of the AAA method in terms of achieving high semantic similarity with the target text and relatively low perturbation.
read the caption
Table 1: Performance comparison (%) of different attack methods.
🔼 This table presents a comparison of the performance of different attack methods on two image-to-text models: VIT-GPT2 and Show-Attend-Tell. The metrics used for comparison include METEOR, BLEU, CLIP, and SPICE, which are common evaluation metrics for evaluating the quality of generated text in image captioning tasks. The table shows the performance of several attack methods, including existing white-box and gray-box attacks, as well as the proposed AAA method (with and without certain components). The results allow for a direct comparison of the proposed method’s effectiveness against the state-of-the-art.
read the caption
Table 1: Performance comparison (%) of different attack methods.
Full paper#



















