TL;DR#
Whole slide image (WSI) classification using deep learning faces challenges due to expensive, fine-grained annotations and limited data. Existing few-shot learning methods for WSIs either underutilize available data or rely on weak supervision, resulting in suboptimal performance. This necessitates the development of efficient and effective methods to leverage limited data for accurate WSI analysis.
The proposed method, FAST, introduces a dual-tier few-shot learning paradigm. It employs a dual-level annotation strategy, minimizing the need for expensive fine-grained annotations. It also incorporates a dual-branch classification framework – a cache branch utilizing all patches and a prior branch using a visual-language model. This approach significantly outperforms existing methods, achieving accuracy comparable to fully supervised methods with a mere 0.22% annotation cost. FAST is highly efficient and adaptable, showcasing its potential for wide-spread adoption in clinical practice.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computational pathology and few-shot learning because it directly addresses the challenges of limited annotated data and high annotation costs in WSI classification. It introduces a novel dual-tier few-shot learning paradigm that improves both efficiency and accuracy of WSI classification. This will likely spur further research into efficient annotation strategies and the application of foundation models in other medical image analysis tasks.
Visual Insights#
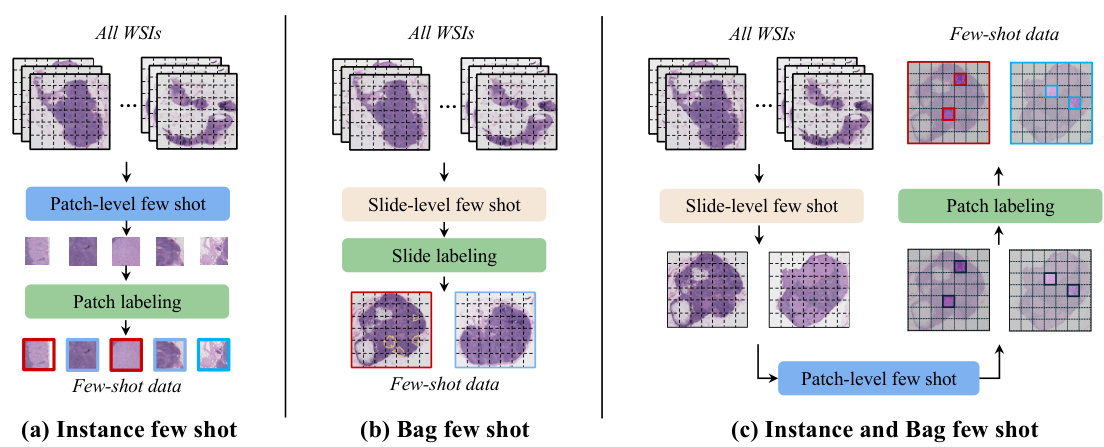
🔼 This figure illustrates three different few-shot learning approaches for Whole Slide Image (WSI) classification. (a) shows the instance few-shot method, which divides WSIs into patches and annotates a small subset. (b) depicts the bag few-shot method, annotating only a few whole slides. (c) presents the proposed ‘Instance and Bag’ few-shot method, which combines slide-level selection with patch-level annotation for improved efficiency and performance.
read the caption
Figure 1: Different few-shot learning paradigms for WSI classification. (a) The instance few-shot method divides all WSIs into a series of patches, then selects a few samples at the patch level and annotates them at the patch level. The red box represents positive samples, and the blue box represents negative samples. (b) The bag few-shot method directly selects a few WSIs at the slide level and annotates them weakly at the slide level. (c) Our method first selects a few WSIs at the slide level, then annotates a few patches for each selected WSI. Compared to (a) and (b), our method significantly reduces annotation costs while providing patch-level supervision information.
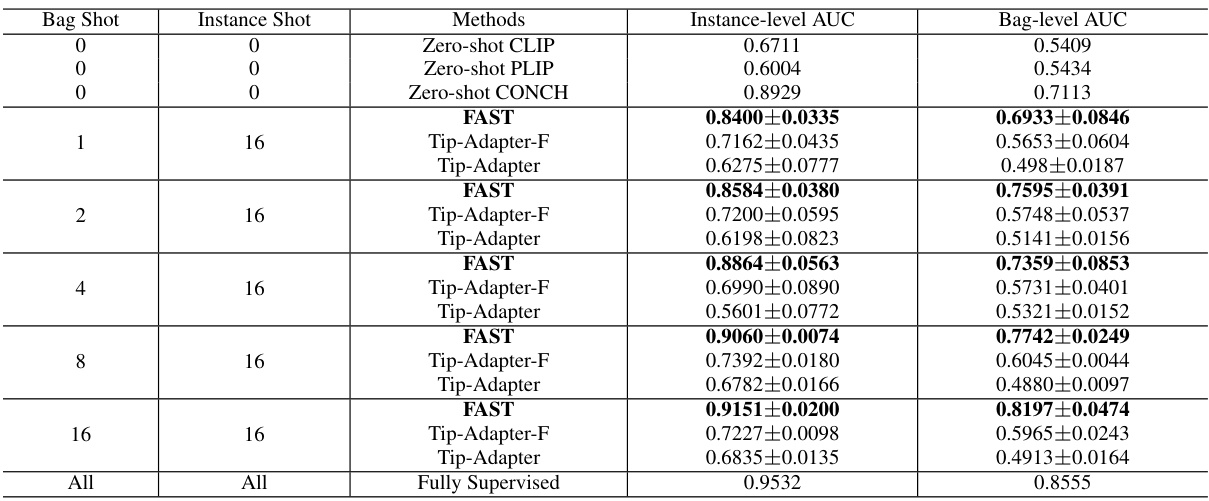
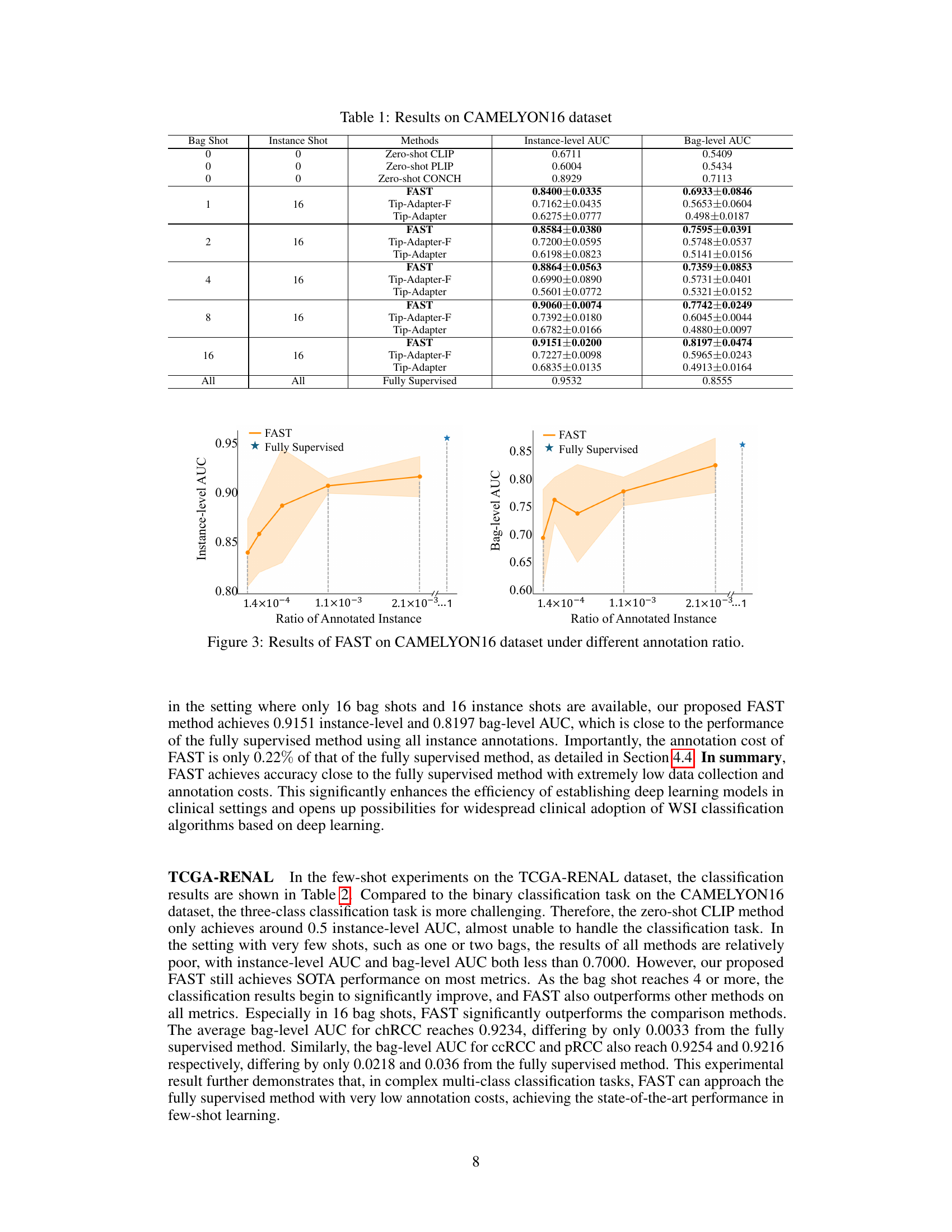
🔼 This table presents the results of the CAMELYON16 dataset experiment. It compares the performance of FAST against several other methods (Zero-shot CLIP, Zero-shot PLIP, Zero-shot CONCH, Tip-Adapter-F, Tip-Adapter) under different few-shot settings (varying numbers of bag shots and instance shots). The instance-level and bag-level AUC (Area Under the Curve) are reported for each method and setting, providing a measure of classification performance. The final row shows the results of a fully supervised method for comparison, representing the upper bound of performance.
read the caption
Table 1: Results on CAMELYON16 dataset
In-depth insights#
Dual-Tier Few-Shot#
The concept of “Dual-Tier Few-Shot” learning, as applied to Whole Slide Image (WSI) classification, presents a novel approach to address the challenges of limited annotated data and expensive annotation processes. The dual-tier aspect likely refers to a two-level annotation strategy: a coarser, slide-level annotation, coupled with a finer-grained, patch-level annotation, strategically applied to a subset of the slides. This approach significantly reduces the cost and effort involved in generating training labels. The “few-shot” aspect means the model is trained with a very small number of labeled examples, thus demonstrating generalization capabilities. The combination of dual-tier annotation with few-shot learning allows for efficient training of deep learning models on limited data. The effectiveness of this strategy relies on effectively leveraging the interdependencies between patches and slide-level labels, enabling the model to generalize well to unseen images. The dual-tier aspect is designed to optimize the balance between annotation effort and the richness of information for training, potentially leading to a highly efficient and practical method for WSI classification. Further analysis of this approach should focus on the optimal strategies for selecting slides and patches for annotation, as well as evaluating its robustness to noisy labels and variations in WSI quality.
WSI Annotation#
Whole slide image (WSI) annotation is a critical bottleneck in applying deep learning to computational pathology. Traditional methods require painstaking pixel-level annotation of entire slides, which is extremely time-consuming and expensive. This limits the amount of training data available, hindering model performance and generalizability, particularly for rare diseases or conditions with limited WSI datasets. Innovative approaches are needed to efficiently leverage existing WSIs. This involves techniques such as: weakly supervised learning, using slide-level labels instead of detailed patch-level annotations; few-shot learning, using small sets of annotated patches to guide classification of unlabeled ones; and active learning, selectively annotating informative patches chosen using model uncertainty. The most promising solutions explore a balance between accuracy and annotation efficiency, potentially incorporating methods that combine various approaches to achieve effective and cost-efficient WSI annotation, while mitigating the limitations of each approach separately. Ultimately, efficient annotation methods are crucial to fully realize the potential of WSI analysis in clinical applications.
Cache & Prior#
A dual-branch architecture, employing a ‘Cache & Prior’ strategy, presents a novel approach to few-shot learning in Whole Slide Images (WSIs). The cache branch leverages labeled and unlabeled patches, creating a dynamic knowledge base. This allows for effective label prediction of unseen patches through knowledge retrieval, maximizing the use of available WSI data. In contrast, the prior branch, utilizing the text encoder of a visual-language model and learnable prompt vectors, offers prior knowledge about WSI categories. Integrating both branches for WSI classification is key. The dual-tier annotation strategy, involving slide-level and patch-level annotations, greatly enhances efficiency. While the prior branch provides crucial initial classification power, the cache branch refines the predictions using a wealth of patch-level information. This combination significantly improves accuracy, especially in data-scarce settings, approaching the performance of fully supervised methods while drastically reducing annotation costs.
Performance Gains#
A dedicated ‘Performance Gains’ section in a research paper would ideally delve into a multifaceted analysis of improvements. It should quantify the performance boost achieved by the proposed method compared to existing baselines, ideally using multiple metrics relevant to the task. Crucially, it needs to distinguish between improvements stemming from methodological advancements versus those simply due to increased data or computational resources. The discussion must clearly articulate the trade-offs involved—did higher accuracy come at the cost of increased complexity or longer runtime? A strong analysis would contextualize these gains within the broader application domain, highlighting their real-world significance. For instance, are the gains impactful enough to justify the added complexity or cost? Furthermore, it should address any limitations that might constrain the generalizability or reproducibility of the observed performance improvements. Finally, a compelling analysis would not only present the numbers but also offer insightful explanations, linking the quantitative results to the underlying mechanisms of the proposed method.
Future Works#
Future work in this area could explore several promising directions. Improving the efficiency and scalability of the dual-tier few-shot learning paradigm would be valuable, potentially through optimizing the knowledge retrieval process or exploring more efficient architectural designs. Another area of focus could be on extending the approach to more complex WSI classification tasks, such as multi-organ or multi-disease identification. This would involve adapting the method to handle higher-dimensional feature spaces and larger numbers of classes. Developing more robust and generalizable methods for prompt engineering is crucial, as this aspect currently relies on expert knowledge and careful crafting of prompts. Research into automated prompt generation techniques could reduce the reliance on manual effort and potentially increase the method’s practicality. Finally, a thorough investigation into the potential biases inherent in the vision-language models employed is warranted, focusing on addressing any disparities in performance across different patient populations or tissue types. Addressing these issues could lead to wider adoption and deployment of the technique in clinical settings.
More visual insights#
More on figures
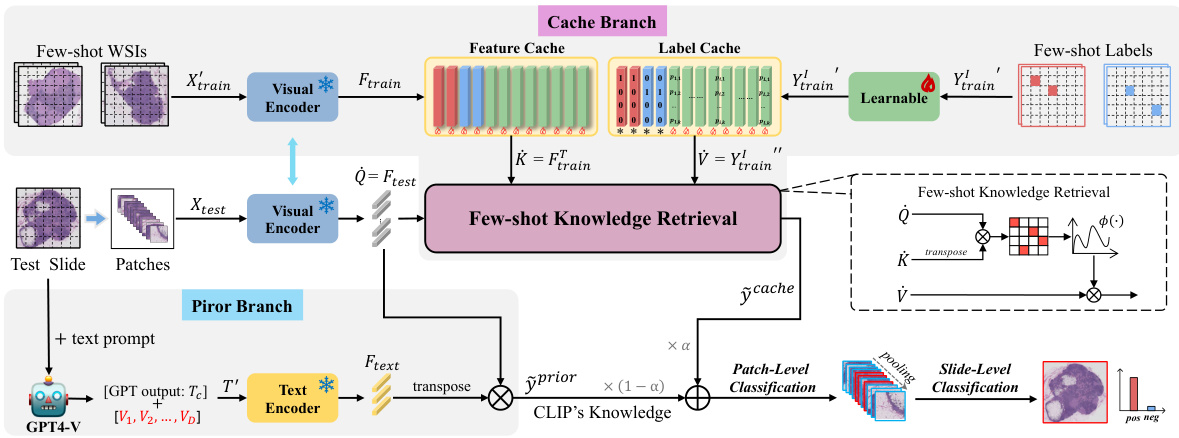
🔼 The figure illustrates the FAST classification framework, which consists of two branches: a cache branch and a prior branch. The cache branch utilizes the image encoder of the V-L model CLIP to extract features of all patches, constructs a cache model using the labeled instances, and classifies each instance through knowledge retrieval. It also incorporates unlabeled instances, treating their labels as learnable parameters. The prior branch uses GPT4-V to obtain task-related prompts and uses CLIP’s text-image matching prior and prompt-learning techniques to design a learnable visual-language classifier. Both branches’ outputs are integrated to produce WSI classifications at the patch and slide levels.
read the caption
Figure 2: The structure of the FAST classification framework.

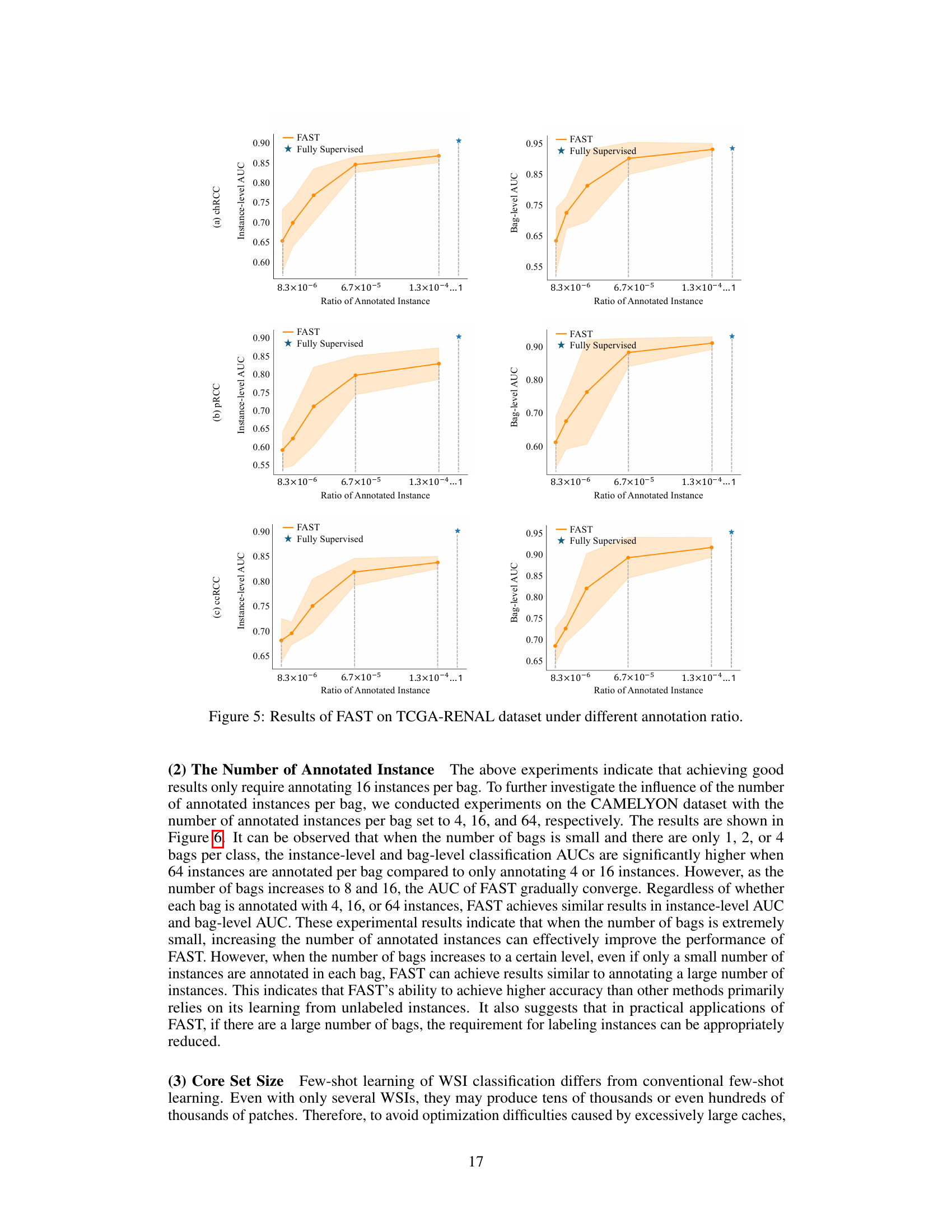
🔼 This figure shows the performance of the FAST model on the CAMELYON16 dataset under various annotation ratios. The x-axis represents the ratio of annotated instances, and the y-axis represents the AUC (Area Under the Curve) score, a measure of the model’s performance. Two lines are plotted: one for FAST and one for a fully supervised method. The shaded area represents the standard deviation across multiple runs. The figure demonstrates that FAST achieves comparable performance to the fully supervised method with a significantly lower annotation ratio, highlighting its efficiency.
read the caption
Figure 3: Results of FAST on CAMELYON16 dataset under different annotation ratio.

🔼 The figure illustrates the dual-branch few-shot WSI classification framework of FAST. The framework consists of a cache branch and a prior branch, which work in conjunction to classify WSIs using a dual-tier annotation strategy. The cache branch is built using all available patches, where labelled patches guide the learning of unlabelled patches. The prior branch leverages visual-language models and learnable prompt vectors for patch classification. Finally, the outputs from both branches are integrated for a final WSI-level classification. The figure highlights the flow of data through both branches, showing feature extraction, knowledge retrieval in the cache branch and prompt generation/classification in the prior branch. The dual-level annotation is visually depicted at the top of the figure.
read the caption
Figure 2: The structure of the FAST classification framework.

🔼 This figure illustrates the dual-branch framework of FAST. The dual-tier few-shot annotation strategy is used to select a subset of WSIs and patches for labeling. The cache branch uses all patches and available patch labels to build a cache model via knowledge retrieval to improve the model’s performance. The prior branch incorporates the text encoder of a vision-language model (e.g., CLIP) to generate task-related prompts, combining both branches’ results for final WSI classification. The figure also depicts the feature cache, label cache, and few-shot knowledge retrieval processes, as well as the fusion of results from the cache and prior branches.
read the caption
Figure 2: The structure of the FAST classification framework.

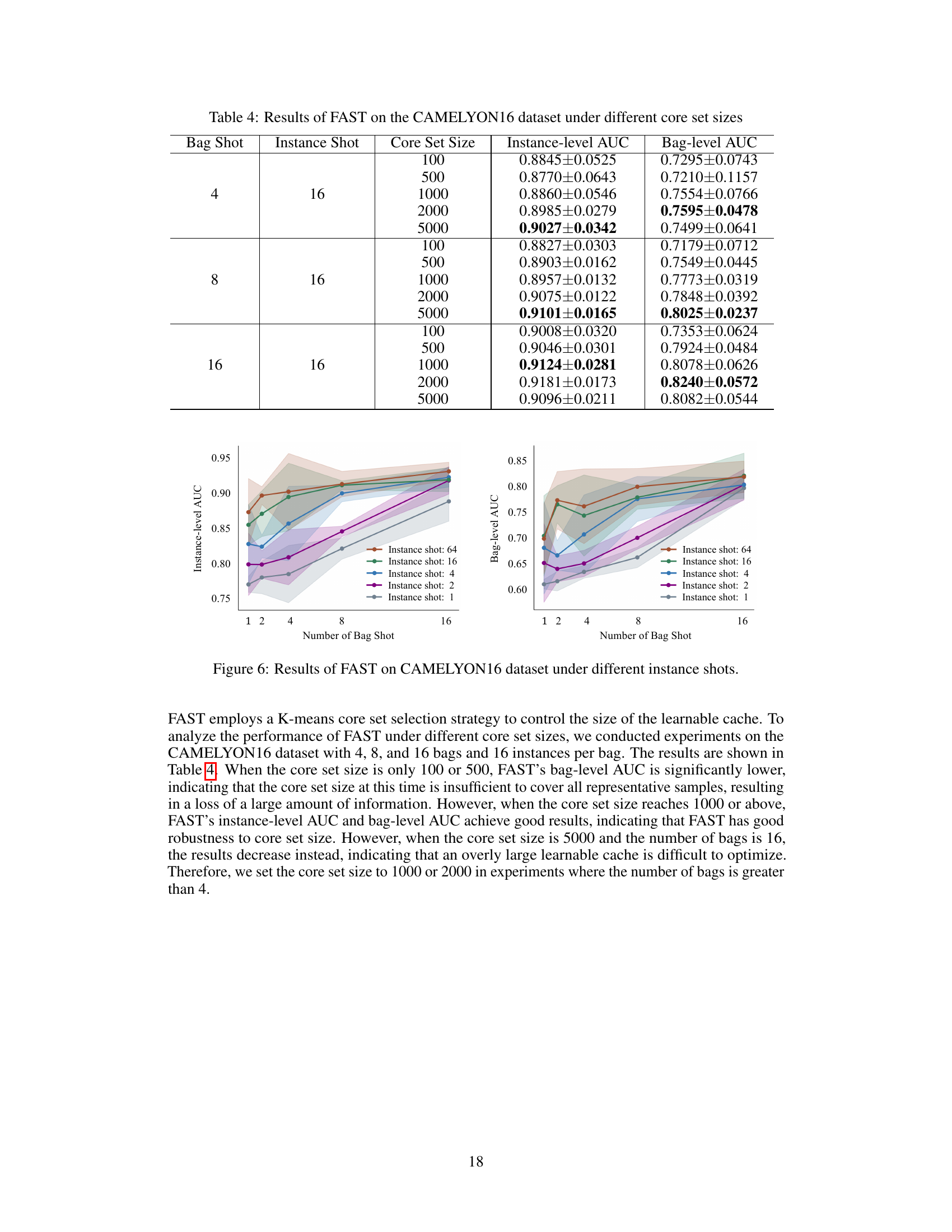
🔼 This figure shows the performance of the FAST model on the CAMELYON16 dataset under different numbers of annotated instances per bag. The results are displayed as instance-level AUC and bag-level AUC, with different line colors representing different numbers of instance shots (1, 2, 4, 16, and 64). The x-axis represents the number of bag shots. This graph demonstrates the impact of changing the number of instances on the overall performance of the model, showing the tradeoff between annotation effort and classification accuracy. The shaded region around each line represents the standard deviation, highlighting the impact of randomness in few-shot learning.
read the caption
Figure 6: Results of FAST on CAMELYON16 dataset under different instance shots.
More on tables

🔼 This table presents the results of the few-shot WSI classification experiments on the TCGA-RENAL dataset. It compares the performance of FAST against several other methods including zero-shot CLIP, Tip-Adapter-F, and Tip-Adapter, across different numbers of bag shots and instance shots. The metrics used are instance-level AUC and bag-level AUC for each of the three renal cancer subtypes (ccRCC, pRCC, and chRCC), as well as the mean AUC across all subtypes. The ‘All’ row shows results for using all available data for a fully supervised approach.
read the caption
Table 2: Results on TCGA-RENAL dataset

🔼 This table presents the results of an ablation study conducted on the CAMELYON16 dataset to evaluate the contribution of each component in the FAST model. It shows the impact of including the cache branch, making the feature cache learnable, incorporating the prior branch, and using a learnable label cache on the model’s performance, measured by instance-level and bag-level AUC. By systematically removing components, the table highlights the relative importance of each part of the FAST architecture for achieving high accuracy.
read the caption
Table 3: Ablation study of FAST on CAMELYON16 dataset

🔼 This table presents the results of the FAST model on the CAMELYON16 dataset under different core set sizes. The experiment is conducted with various combinations of bag shots and instance shots. For each combination, the instance-level and bag-level AUC scores are shown for different core set sizes (100, 500, 1000, 2000, and 5000). This helps to illustrate the model’s performance in relation to the amount of data used to build its cache. The purpose is to find an optimal core set size that balances model performance and resource usage.
read the caption
Table 4: Results of FAST on the CAMELYON16 dataset under different core set sizes
Full paper#