TL;DR#
Many machine learning models lack interpretability, making it hard to understand why they make specific predictions. Existing methods often focus on individual features (like pixels in an image), not their meaning to a human. This makes it difficult to provide trustworthy explanations, especially in high-stakes settings where transparency is crucial.
This paper tackles this issue by formalizing the concept of ‘semantic importance’—the importance of high-level concepts (like “cat” or “dog”) rather than raw input features—in a statistically rigorous way. They introduce novel testing methods to assess semantic importance, both globally (across all predictions) and locally (for individual cases). These methods rely on conditional independence testing and incorporate sequential testing to rank the importance of concepts effectively. Experiments show that their framework offers improved accuracy, better rank agreement, and higher transferability compared to traditional methods.
Key Takeaways#
Why does it matter?#
This paper introduces statistically rigorous methods for evaluating the importance of semantic concepts in opaque machine learning models, offering transparency and avoiding unintended consequences.
Visual Insights#
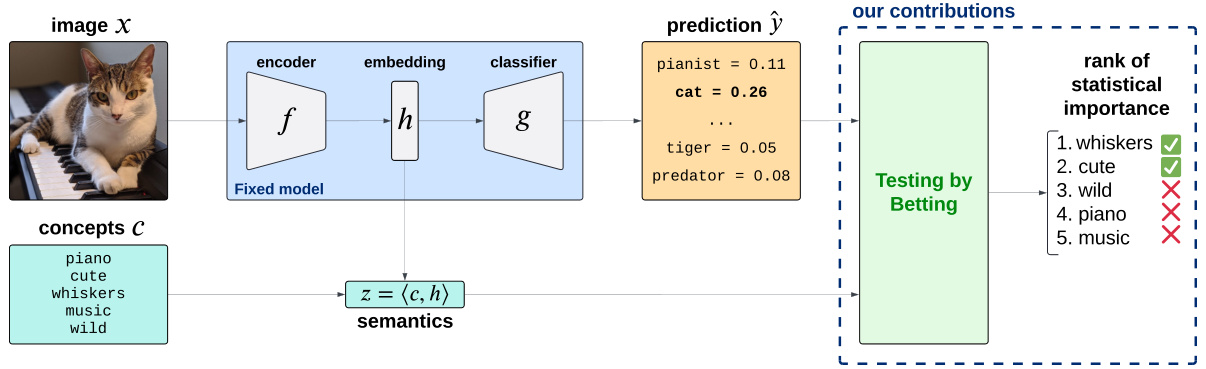
🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model (encoder and classifier) receives an image as input. The embedding from the encoder is then projected onto a set of user-specified semantic concepts. The paper introduces novel statistical methods (testing by betting) to rank the importance of these concepts for the model’s predictions, providing a measure of statistical significance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

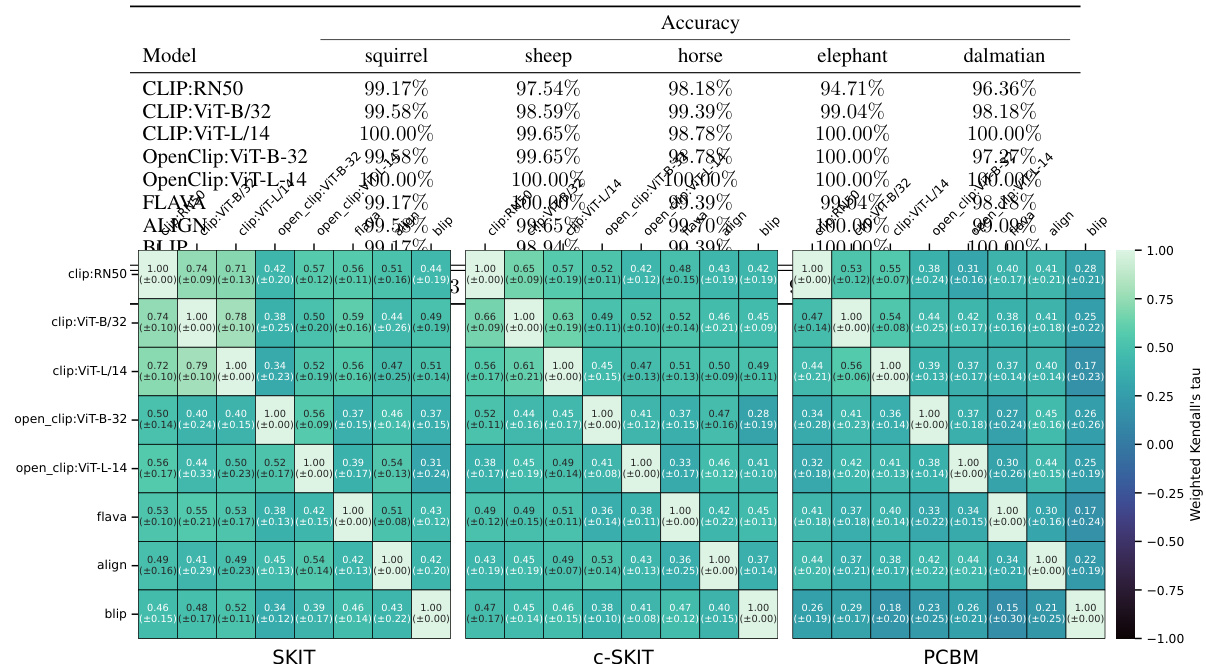
🔼 This table summarizes the performance of the proposed methods (SKIT, C-SKIT, and X-SKIT) and a baseline method (PCBM) on three image datasets (AwA2, CUB, and Imagenette). For each dataset, the table shows the original model accuracy, rank agreement (how well the ranking of importance aligns across different models), and F1 score (a measure of classification accuracy for the importance rankings) for each method. The table highlights the effectiveness of the proposed methods in achieving high accuracy and consistent importance rankings across different vision-language models.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.
In-depth insights#
Semantic Importance#
The concept of “Semantic Importance” in the context of this research paper centers on extending feature importance beyond raw input features to higher-level, human-interpretable semantic concepts. This shift is crucial for enhancing transparency and trustworthiness in machine learning models, especially black-box models whose inner workings are opaque. The authors aim to quantify the influence of these semantic concepts on model predictions, going beyond simply attributing importance to individual pixels or words. This involves developing rigorous statistical methods to test for the significance of these semantic impacts, both globally (across a population) and locally (for individual instances). The framework presented seeks to establish whether a concept’s influence is statistically meaningful, addressing challenges in communicating uncertainty in model explanations. A key innovation is the use of conditional independence testing, providing a more formal and nuanced approach to evaluating semantic importance than previous heuristic methods.
Betting Test#
The concept of a ‘Betting Test’ in the context of a research paper likely refers to a sequential hypothesis testing framework. Unlike traditional hypothesis testing which analyzes all data at once to determine significance, a betting test approaches the problem iteratively. This iterative nature allows for adaptive testing, where the amount of data collected depends on the accumulating evidence. The test is framed as a game, where the ‘bettor’ places wagers on whether the null hypothesis is true or false, and ’nature’ reveals the truth with each data point. This approach allows for data efficiency as the test stops as soon as sufficient evidence has been gathered, leading to a decision, unlike traditional methods that analyze all data regardless of whether or not it is necessary. A key advantage of the betting test lies in its capacity to induce a rank of importance. The concepts are tested sequentially. The faster a concept is deemed important, the higher it ranks in the hierarchy. It is a powerful tool for situations where analyzing all data is computationally expensive or resource-intensive. However, the effectiveness of the betting test depends crucially on the choice of test statistic and wagering strategy; careful consideration is essential for appropriate and rigorous results.
VL Model Analysis#
A thorough ‘VL Model Analysis’ would dissect the performance of various vision-language (VL) models in the context of semantic importance testing. This would involve a comparative study, assessing how each model’s architecture and training methodology influences its ability to identify and rank important semantic concepts. Key aspects to examine would include the models’ zero-shot capabilities, their susceptibility to biases embedded in training data, and the robustness of their semantic feature extractors. The analysis should investigate the relationship between the models’ predictive accuracy and the reliability of the resulting importance scores. Finally, a critical evaluation of explainability methods in conjunction with VL models is essential, assessing whether these approaches accurately reflect the underlying decision-making processes of these models.
Limitations & Future#
A research paper’s “Limitations & Future” section should critically examine the study’s shortcomings and suggest avenues for improvement. Limitations might include the dataset’s size or bias, the model’s assumptions, or the generalizability of findings. For instance, if the study focuses on a specific demographic, it must acknowledge this limitation and discuss the potential for different results in other groups. Methodological limitations, such as reliance on specific algorithms or statistical tests, should also be discussed. The section should then explore future work, proposing concrete steps to overcome these limitations, such as expanding the dataset, exploring alternative methods, or conducting further analysis. For example, they might suggest using more diverse datasets, testing different model architectures, or investigating the causal relationships between variables. The overall goal is to present a balanced perspective, highlighting both the achievements and limitations of the study while paving the way for future research to address identified gaps.
Statistical Guarantees#
The concept of “Statistical Guarantees” in the context of a research paper focusing on semantic importance and model explainability is crucial. It speaks to the rigor and reliability of the methods proposed. Strong statistical guarantees, such as control over false positive and false discovery rates, are essential for establishing trust and confidence in the model explanations. Without such guarantees, it’s difficult to ascertain whether identified important concepts are genuinely important or merely spurious findings. The authors likely explore techniques like hypothesis testing and sequential testing, providing theoretical justification for their significance level, thereby demonstrating the statistical robustness of their approach. This focus on guarantees implies a move away from purely heuristic methods towards a more principled, statistically sound framework for explaining complex models. Conditional independence testing is a likely candidate method, given its focus on quantifying dependence between variables, controlling for confounding factors, and offering strong statistical guarantees.
More visual insights#
More on figures

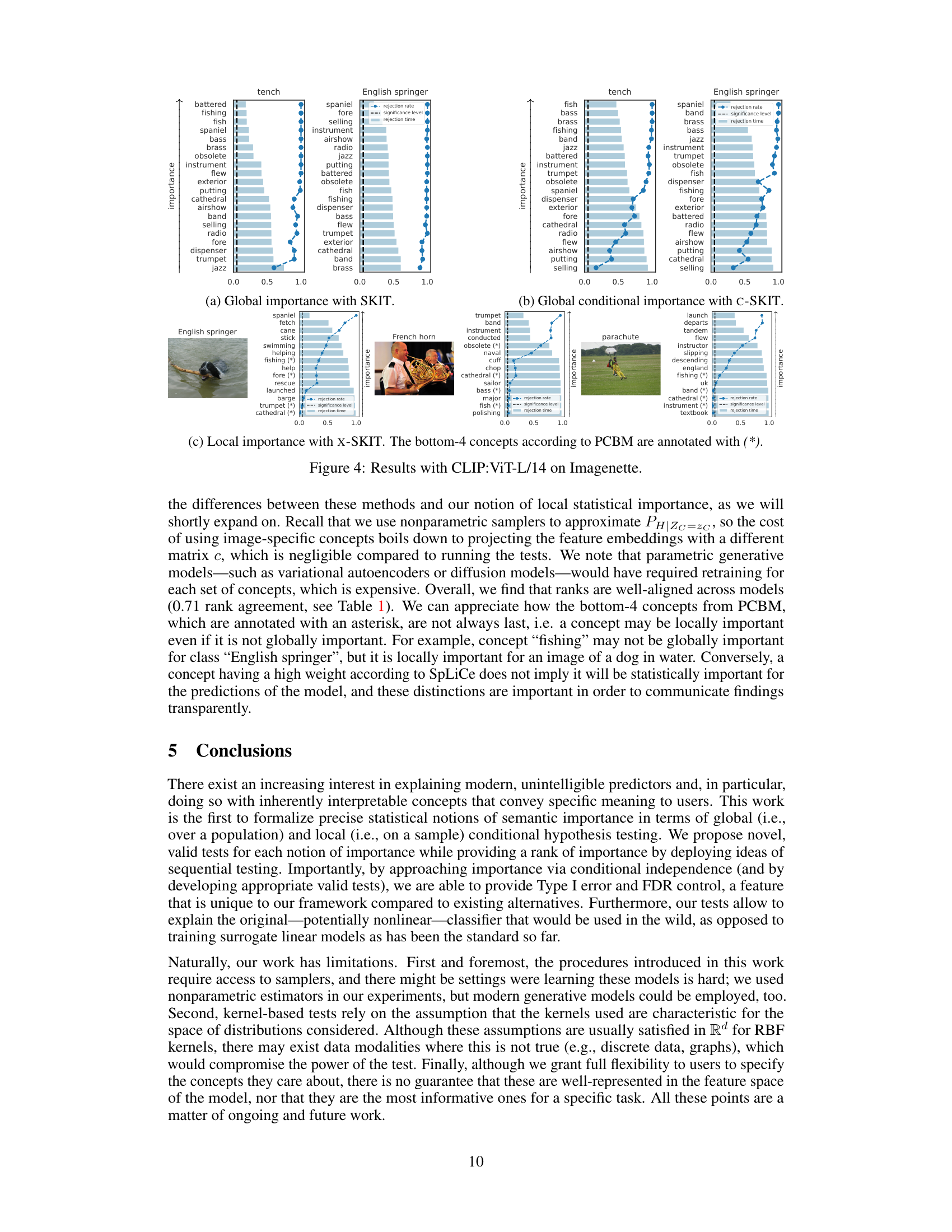
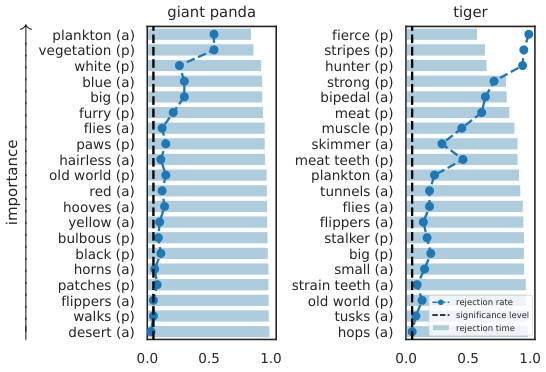
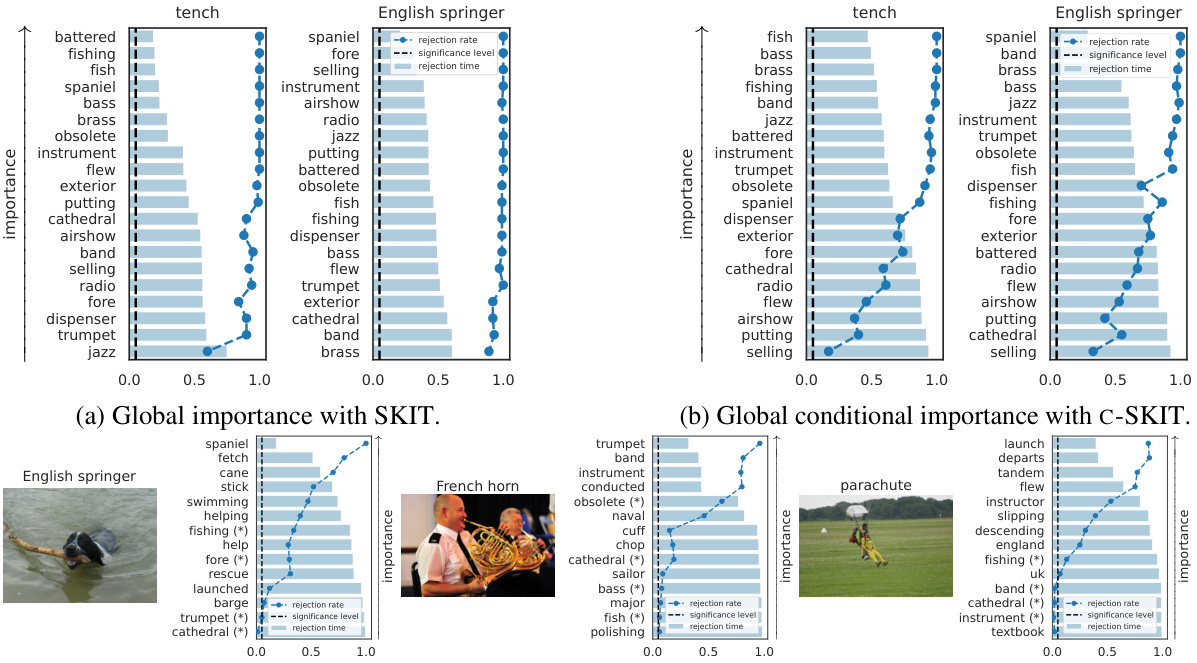
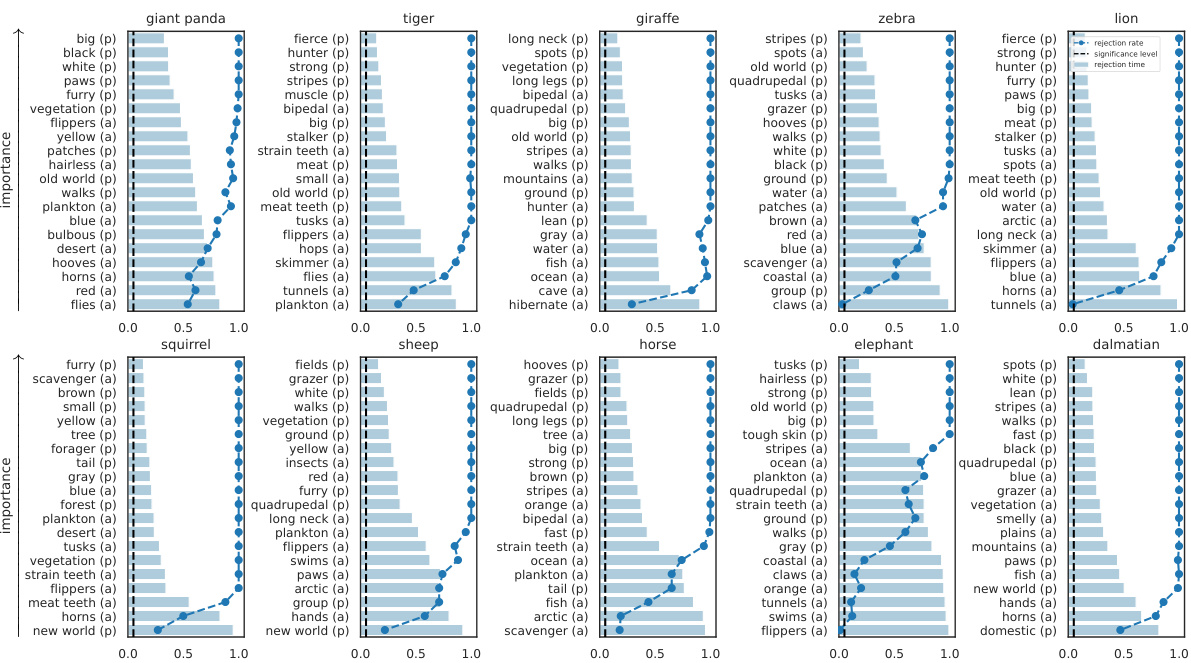
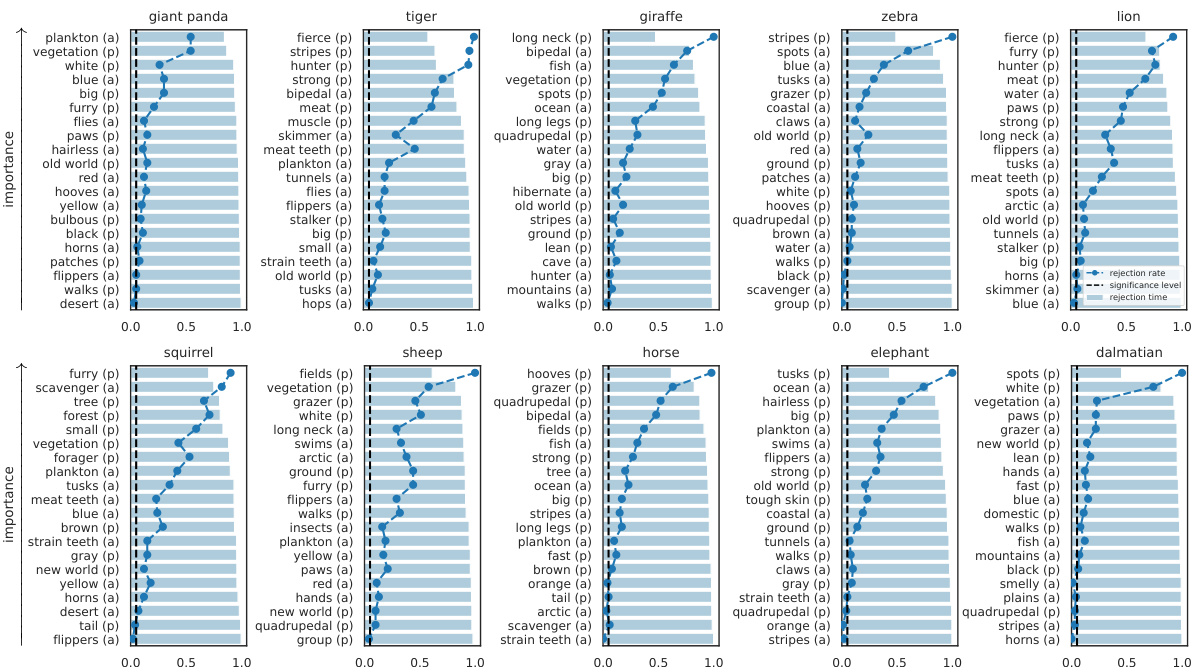
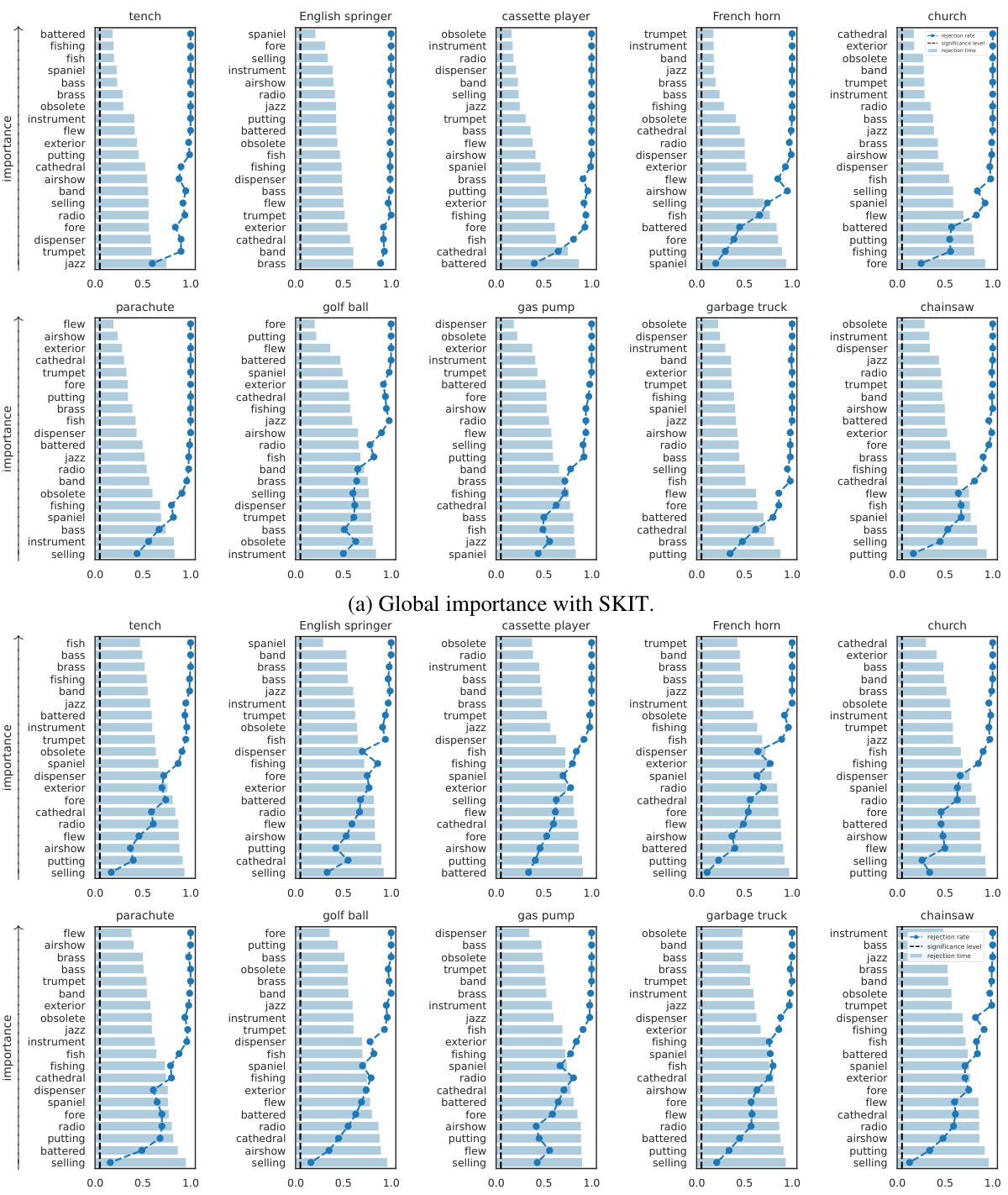
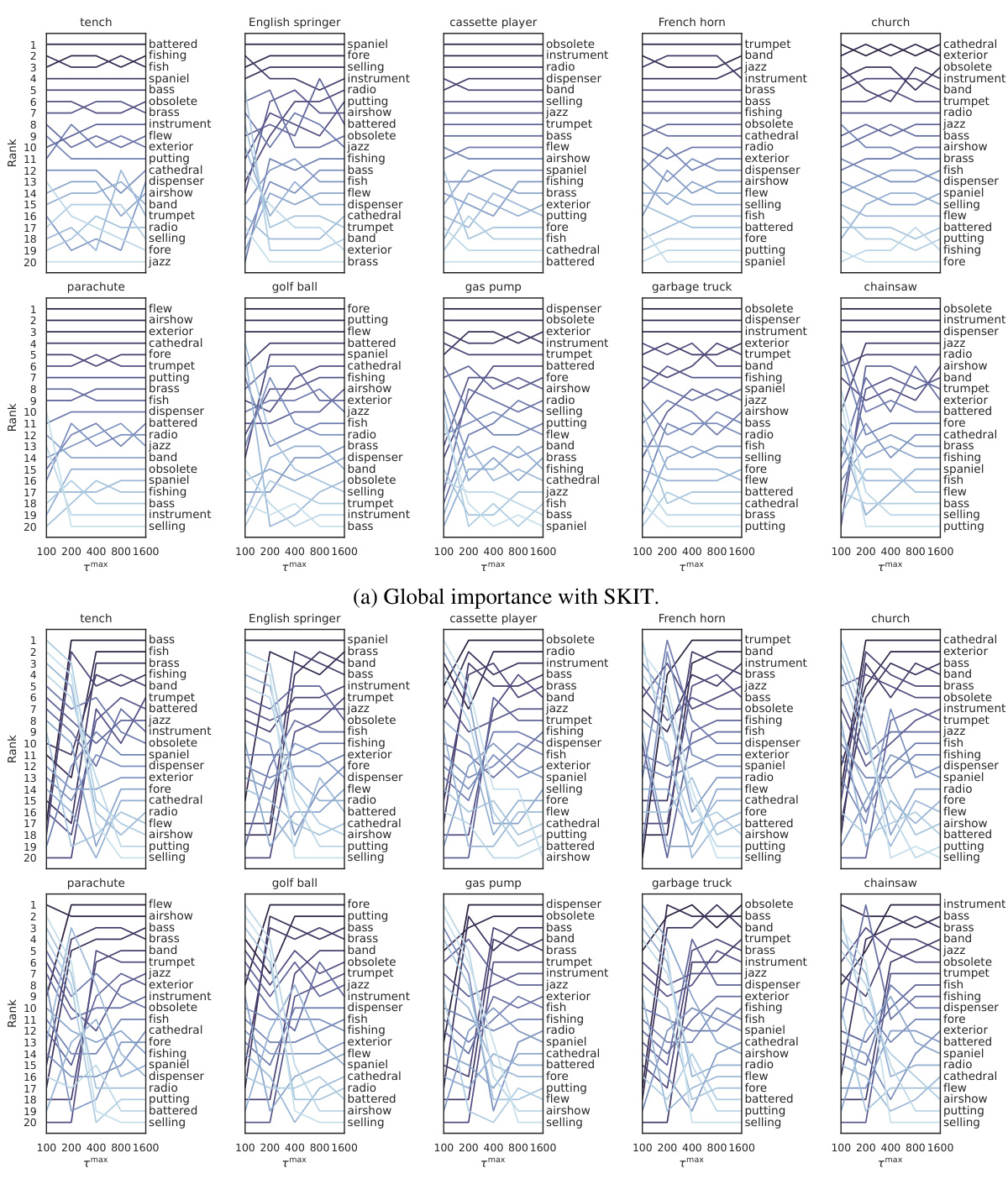
🔼 This figure visualizes the results of applying the SKIT and C-SKIT methods to the AwA2 dataset using the CLIP:ViT-L/14 model. It shows the ranked importance of different semantic concepts for predicting two animal classes. Concepts marked with (p) are present in the class according to human annotations, while those marked with (a) are absent. The figure likely illustrates the effectiveness of the proposed methods in identifying semantically relevant concepts for model predictions, highlighting their ability to distinguish between globally and conditionally important concepts.
read the caption
Figure 2: Importance results with CLIP:ViT-L/14 on 2 classes in the AwA2 dataset. Concepts are annotated with (p) if they are present in the class, or with (a) otherwise.
🔼 This figure illustrates the problem setup and contribution of the paper. It shows a fixed model composed of an encoder and a classifier, which is probed via a set of semantic concepts. The key difference with post-hoc concept bottleneck models is that the authors do not train a sparse linear layer to approximate E[Y|Z]. Instead, they focus on characterizing the dependence structure between Ŷ and Z. The figure also illustrates the main contributions of the paper, which includes a rank of importance and a testing by betting procedure for assessing the statistical significance of the results.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 The figure illustrates the problem setup and the contributions of the paper. It shows an image X as input to a fixed model, consisting of an encoder f and classifier g. The encoder produces an embedding h which is then used by the classifier g to produce a prediction ŷ. A set of concepts c is used to probe the model. The main contributions of the paper are shown as the output: a rank of semantic importance and statistical testing results for each concept.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 The figure illustrates the problem setup and contribution of the paper. It shows a fixed model composed of an encoder and classifier, which is probed via a set of concepts. The key difference with post-hoc concept bottleneck models is that the authors do not train a sparse linear layer to approximate E[Y|Z]. Instead, they focus on characterizing the dependence structure between Ŷ and Z. The figure highlights the key components of the proposed methodology: a fixed model, concepts, and the testing by betting strategy for determining the statistical importance of semantic concepts.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure shows a schematic of the proposed method. It starts with an image X, which is encoded into an embedding h by an encoder f. This embedding is then projected into the space of semantic concepts, Z, by means of a concept bottleneck model (CBM). The concepts Z and the embedding h are used to predict the response of the model, Y, by a classifier g. Our contribution is to introduce a rank of statistical importance of concepts for the predictions of the model.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure shows the results of applying the proposed methods (SKIT and C-SKIT) to the AwA2 dataset. Specifically, it displays the importance scores for concepts related to two animal classes. Each bar represents a concept, with height indicating the importance score. Concepts are labeled with (p) for presence in the class and (a) for absence. The figure demonstrates the ranking of concept importance produced by the SKIT and C-SKIT methods. The (a) subplot shows the global importance scores calculated by SKIT, while the (b) subplot presents the global conditional importance scores obtained by C-SKIT. This visualization helps compare the importance of different concepts in determining model predictions for the specified animal classes.
read the caption
Figure 2: Importance results with CLIP:ViT-L/14 on 2 classes in the AwA2 dataset. Concepts are annotated with (p) if they are present in the class, or with (a) otherwise.
🔼 This figure shows the results of applying the SKIT and C-SKIT methods to the AwA2 dataset, focusing on two classes. The left panel (a) displays global importance scores from SKIT, showing the rejection rates and times for various concepts. The right panel (b) illustrates global conditional importance scores from C-SKIT, again displaying rejection rates and times. Each bar represents a concept, and the (p) or (a) annotation indicates if the concept is present or absent in the class, respectively. The figure helps visualize the relative importance of different semantic concepts in classifying animal images within the AwA2 dataset.
read the caption
Figure 2: Importance results with CLIP:ViT-L/14 on 2 classes in the AwA2 dataset. Concepts are annotated with (p) if they are present in the class, or with (a) otherwise.
🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model (encoder f and classifier g) takes an image X as input and produces a prediction ŷ. The model’s embedding h is projected onto a set of concepts c, resulting in a vector z representing the concepts’ presence in the input. The paper introduces novel methods to rank the importance of these concepts (z) for the predictions ŷ, providing a statistically rigorous approach to semantic importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure illustrates the problem setup and contribution of the paper. A fixed model (encoder and classifier) receives an image as input. The model’s embedding is projected onto a set of user-specified semantic concepts. The paper introduces novel methods to assess the statistical importance of these concepts for model predictions, quantifying semantic importance via a betting approach and ranking of importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and the contribution of the paper. A fixed model (encoder f and classifier g) takes an image X as input and produces a prediction ŷ. The embedding h from the encoder is projected onto a set of concepts c to obtain z. The authors’ contribution is a method for ranking the importance of these semantic concepts (z) for the prediction, using statistical testing.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model, composed of an encoder f and a classifier g, is probed via a set of concepts c. The key difference with post-hoc concept bottleneck models (PCBMs) is highlighted: this work does not train a sparse linear layer to approximate E[Y|Z]; rather it focuses on characterizing the dependence structure between Ŷ and Z. The figure shows how the model’s prediction (ŷ) depends on the input image (X), embedding (h), classifier (g), and the concepts (c) which are projected to induce (z). The contributions of the paper are also shown, which include introducing a rank of statistical importance via testing by betting.
read the caption
Figure 1: Overview of the problem setup and our contribution.

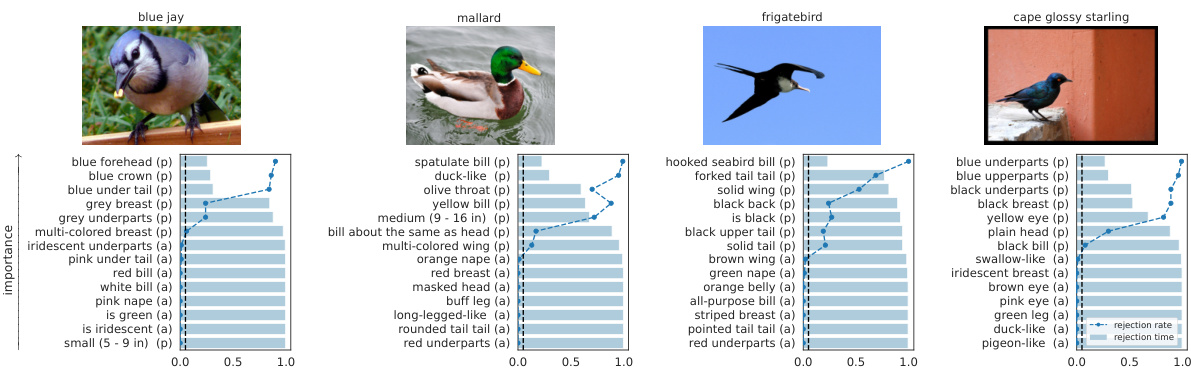
🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model (encoder and classifier) processes an image and produces a prediction. The model’s embedding is projected onto interpretable semantic concepts (e.g., ‘whiskers’, ‘piano’). The paper introduces methods to test the statistical importance of these concepts for the predictions, and produces a ranked list of importance scores. The key novelty is the use of sequential testing procedures, which provides statistical guarantees and induces an importance ranking.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the key problem addressed in the paper: testing the statistical importance of semantic concepts (e.g., ‘whiskers’, ‘cute’) for the predictions of a black-box model. The figure shows an image as input to an encoder and classifier, which produces a prediction. Importantly, there is a concept layer that projects the embedding of the image onto interpretable semantic concepts. The authors’ contributions focus on developing new sequential statistical tests to rank these concepts by importance and provide precise statistical guarantees on these findings.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and the contribution of the paper. A fixed model (encoder and classifier) receives an image as input. The model’s embedding is projected onto a set of user-specified semantic concepts. The authors’ contributions involve methods for ranking the importance of these concepts based on statistical significance tests, using testing by betting principles.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the workflow of the proposed methodology. An image is encoded into an embedding, which is projected onto a user-specified set of semantic concepts. The proposed method leverages these projections to test for the statistical importance of each concept via betting, thereby inducing a rank of importance. This differs from existing methods that rely on training surrogate models to obtain semantic importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model (encoder and classifier) receives an image as input. This model’s output is then analyzed with respect to a set of user-specified semantic concepts (represented as vectors). The paper’s contributions involve novel statistical tests that assess the importance of these concepts in influencing the model’s predictions and produce a ranking of importance, improving upon the transparency and rigor of existing methods.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 The figure illustrates the overall workflow of the proposed method. It starts with an image X, which is processed by a fixed model (encoder f and classifier g) to produce a prediction ŷ. A set of concepts C is defined which projects the embedding h onto an interpretable semantic space. The authors’ contributions focus on using these concepts (Z) to test for semantic importance of specific concepts by applying statistical tests (Testing by Betting). The result is a rank of importance of concepts.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure illustrates the problem setup and the contribution of the paper. It shows a fixed model composed of an encoder and a classifier that processes an image to produce a prediction. The model is probed with a set of semantic concepts, and the paper proposes novel statistical tests to assess the importance of these concepts for the predictions. The key difference with existing methods is highlighted: the proposed method focuses on characterizing the dependence structure between the prediction and the concepts without training a surrogate model, providing more direct and reliable insights into the original model’s behavior.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure shows a schematic of the overall approach. An image is inputted into a fixed model composed of an encoder and classifier. The encoder generates an embedding which is then used by the classifier to produce a prediction. A set of concepts are provided as input to a layer that projects the embedding onto the subspace of interpretable semantic concepts. The contribution of this paper is to test the statistical importance of these concepts for the predictions of the model, and to induce a ranking of concepts using testing by betting. This is a key difference with previous methods based on concept bottleneck models, in that we do not train a surrogate model.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the overall workflow of the proposed method. It shows an image X as input to a fixed model (encoder f and classifier g). The embedding h is projected into a space of semantic concepts C, resulting in the projection z. The authors’ contributions involve using sequential testing to determine a rank of importance of these concepts for the model’s prediction ŷ, which aims to provide statistical guarantees on semantic importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 The figure illustrates the problem setup and the contribution of the paper. It shows a fixed model composed of an encoder and classifier. The encoder takes an image as input and produces a dense embedding, which is then fed into the classifier to produce a prediction. A set of concepts is provided as input to the model. The contribution of the paper is to provide a method for ranking the importance of these concepts for the predictions of the model, along with statistical guarantees on the reliability of the ranking. The concepts themselves are interpretable and meaningful to the user. This is in contrast to other methods that focus on feature importance in the input space, without explicit consideration of the interpretable semantics. The process of ranking concept importance is presented as a flow, culminating in a list ordered by importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and the contributions of the paper. A fixed model (encoder and classifier) takes an image as input. The embedding is projected onto a user-specified set of semantic concepts. The paper introduces novel procedures to test for statistical importance, allowing for the ranking of concepts by importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure illustrates the problem setup and the contribution of the paper. It shows a fixed model (encoder and classifier) receiving an image as input. The image embedding is projected onto a set of user-specified semantic concepts. The paper’s contribution is a novel procedure for ranking concepts by their importance in the model predictions, using a testing by betting approach.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the overall workflow of the proposed method. It shows an image X as input, which is processed by a fixed model (encoder f and classifier g) to produce a prediction ŷ. A set of concepts C is used to probe the model’s decision-making process, resulting in a vector representation z. The authors’ contribution lies in providing a statistical testing framework (‘Testing by Betting’) to determine the importance of these concepts (ranking and statistical significance) for the model’s prediction, with the final result being a ranked list of concepts according to their importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.
🔼 This figure shows the overall architecture of the proposed approach. An image is input to an encoder that generates an embedding vector. The embedding is projected to a set of semantic concepts using a concept bottleneck model. The model outputs a prediction, which is compared to the actual label. This allows the model to assess the importance of different semantic concepts using a testing by betting methodology.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and contributions of the paper. It shows a fixed model (an encoder and a classifier) receiving an image as input. The image embedding is projected onto a set of semantic concepts. The paper’s contributions are to provide methods to assess the statistical importance of these concepts for the model’s predictions and to rank those concepts according to their importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the overall workflow of the proposed method. It starts with an image as input, which is processed by a fixed model (encoder and classifier) to produce a prediction. This prediction is then analyzed with respect to a set of user-defined semantic concepts. The core contribution of the paper is a novel sequential testing procedure to assess the statistical importance of these concepts, providing a ranked list of importance and statistical guarantees on the findings.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the problem setup and the contributions of the paper. It shows a fixed model (encoder and classifier) taking an image as input. The image’s embedding is projected onto a set of user-specified semantic concepts. The paper’s contribution is a novel framework for statistically testing the importance of these concepts in the model’s prediction, using sequential testing principles to determine a ranking of importance.
read the caption
Figure 1: Overview of the problem setup and our contribution.

🔼 This figure illustrates the key components of the proposed methodology. It shows the input image, the encoder (f) that generates an embedding, the classifier (g) that produces a prediction, and the set of concepts (c) which are used to assess semantic importance in the model. The figure highlights the main contribution of the paper: providing a ranked list of statistical importance for the selected concepts through a testing-by-betting approach. This is in contrast to existing methods which may not provide statistical guarantees or induce a ranking.
read the caption
Figure 1: Overview of the problem setup and our contribution.
More on tables

🔼 This table summarizes the performance of three proposed methods (SKIT, C-SKIT, and X-SKIT) and a baseline method (PCBM) on three image datasets (Imagenette, AwA2, and CUB). For each dataset and method, the table shows the model accuracy, rank agreement (a measure of how well the methods agree on the ranking of important concepts), and F1 score (a measure of the accuracy of identifying important concepts). The results are averaged across multiple vision-language models. The checkmarks in the ‘Original model’ column indicate whether the method can be applied directly to the original model or requires training a surrogate model. The ‘X’ indicates that PCBM requires training a surrogate model.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.

🔼 This table summarizes the performance of three different semantic importance testing methods (SKIT, C-SKIT, and X-SKIT) and compares them to a baseline method (PCBM) across three different datasets (AwA2, CUB, and Imagenette). The metrics reported are the average accuracy, rank agreement (how well the rank of importance aligns across different models), and the F1 score (measuring the accuracy of the top-10 concepts identified). The table shows that SKIT, C-SKIT and X-SKIT generally perform better than the baseline PCBM in terms of rank agreement and F1-score.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.
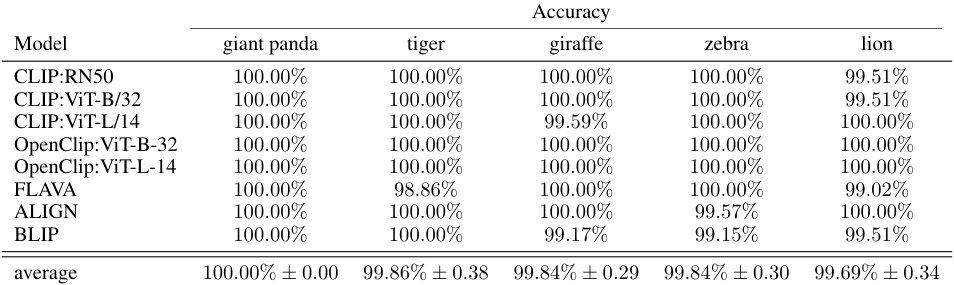
🔼 This table summarizes the performance of different methods (SKIT, C-SKIT, X-SKIT, and PCBM) on three image classification datasets (Imagenette, AwA2, and CUB). For each dataset and method, it shows the accuracy, rank agreement, and F1 score. Rank agreement measures how well the ranking of semantic concepts by each method matches across different vision-language models. The F1 score reflects how well the identified important concepts align with ground truth annotations (where available). The table provides a high-level overview of the comparative performance of the proposed and existing methods.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.

🔼 This table summarizes the performance of three different methods (SKIT, C-SKIT, and X-SKIT) and a baseline method (PCBM) on three different image datasets (Imagenette, AwA2, and CUB). For each dataset and method, the table shows the accuracy, rank agreement, and F1 score. Rank agreement and F1 scores measure the similarity of the rankings generated by each method compared to ground truth or other methods. Higher scores indicate better performance.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.
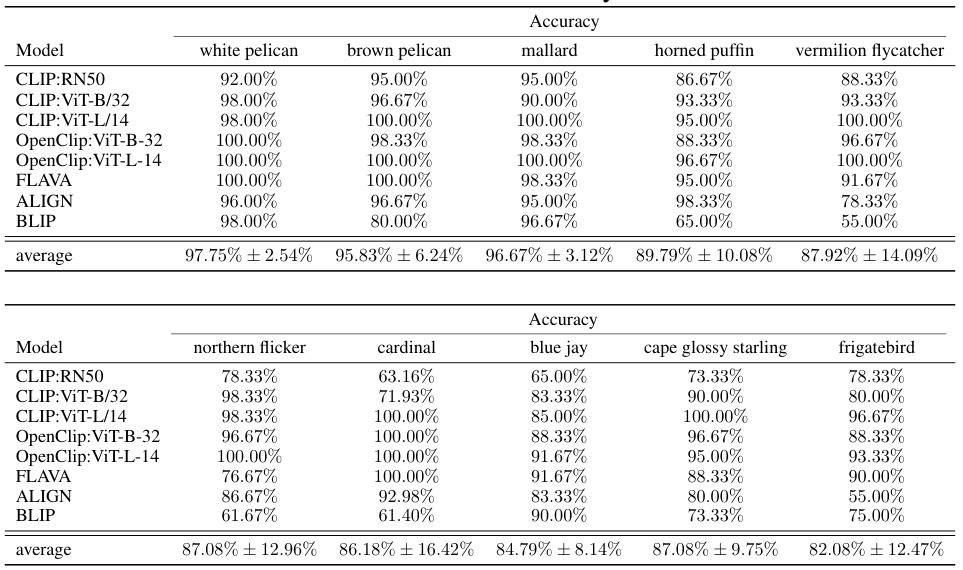
🔼 This table summarizes the performance of different methods (SKIT, C-SKIT, X-SKIT, and PCBM) on three image datasets (Imagenette, AwA2, and CUB). For each dataset, it reports the average accuracy, rank agreement, and F1 score across multiple vision-language models. Rank agreement measures the consistency of the ranking of important concepts across different models, while the F1 score assesses the accuracy of identifying important concepts. The table shows the overall performance of each method on each dataset, allowing for comparisons between them.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.

🔼 This table summarizes the performance of the proposed methods (SKIT, C-SKIT, and X-SKIT) and a baseline method (PCBM) on three image datasets (AwA2, CUB, and Imagenette). For each dataset and method, it shows the accuracy, rank agreement (how well the importance ranking of concepts aligns across multiple vision-language models), and an f1 score evaluating the importance rankings against ground truth (where available). The table highlights the superior performance of the proposed methods compared to the PCBM baseline.
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.

🔼 This table summarizes the performance of different methods (SKIT, C-SKIT, X-SKIT, and PCBM) on three image datasets (AwA2, CUB, and Imagenette). For each dataset, it shows the model’s accuracy, rank agreement, and F1 score. Rank agreement measures how well the importance ranks produced by each method align across different vision-language models. The F1 score evaluates the accuracy of the importance rankings compared to ground truth annotations (where available).
read the caption
Table 1: Summary of results for each dataset. Metrics are reported as average across all VL models used in the experiments. See main text for details about the models and the metrics used.
Full paper#