TL;DR#
Sketch-based person re-identification (re-ID) is crucial in criminal investigations but faces challenges due to the modality gap between sketches and images, and the high cost of creating labelled data. Existing methods employ semantic constraints or auxiliary guidance, leading to expensive labor costs and loss of fine-grained information. This paper proposes a new method, Optimal Transport-based Labor-free Text Prompt Modeling (OLTM), which overcomes these issues.
OLTM uses a pre-trained VQA model to extract multiple target attributes, generating flexible textual descriptions. A text prompt reasoning module uses a learnable prompt strategy and optimal transport algorithm to extract discriminative global and local text representations. These representations bridge the gap between sketch and image modalities. Furthermore, instead of simple distance comparisons, OLTM uses a novel triplet assignment loss that considers the whole data distribution, improving inter/intra-class distance optimization. Experiments demonstrate OLTM’s robustness and outperformance over existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to sketch-based person re-identification that avoids expensive manual labeling. Its use of pre-trained VQA models and optimal transport offers a more efficient and robust solution, opening new avenues for research in this area and impacting various applications like criminal investigation and missing person searches. The introduction of a triplet assignment loss further improves the model’s performance and offers a valuable contribution to similarity measurement techniques in computer vision.
Visual Insights#
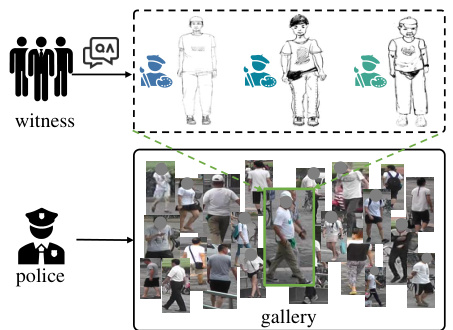
🔼 This figure illustrates the process of sketch-based person re-identification (re-ID). It starts with a witness who describes a person to a police sketch artist. The artist creates a sketch of the suspect based on the witness’s description. The police then use the sketch as a query to search a gallery of images to find a match.
read the caption
Figure 1: The illustration of sketch Re-ID. Different artists create sketches based on clues provided by witness to assist the police in identifying targets.
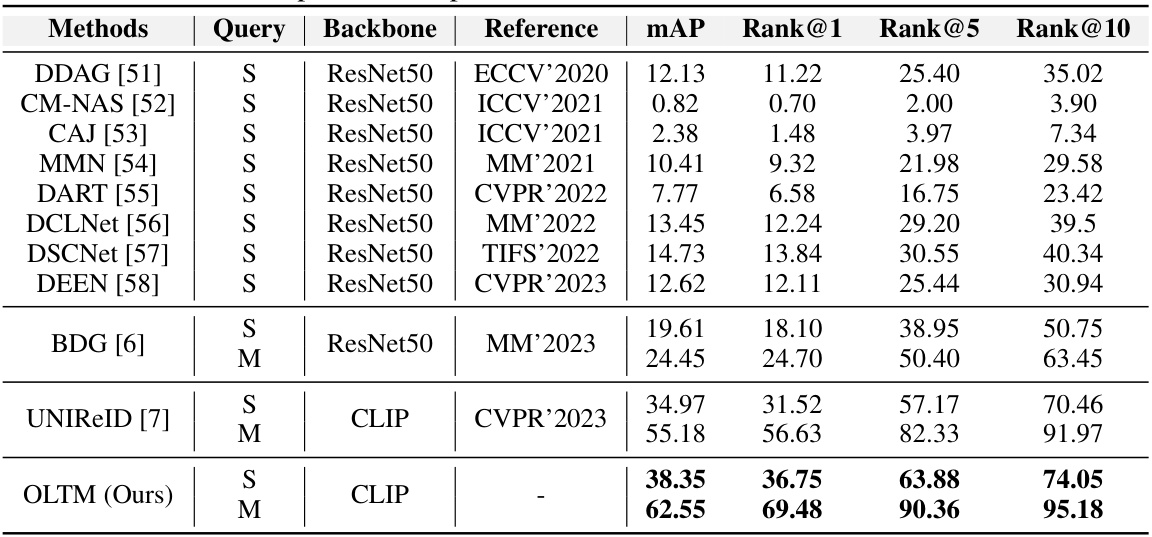
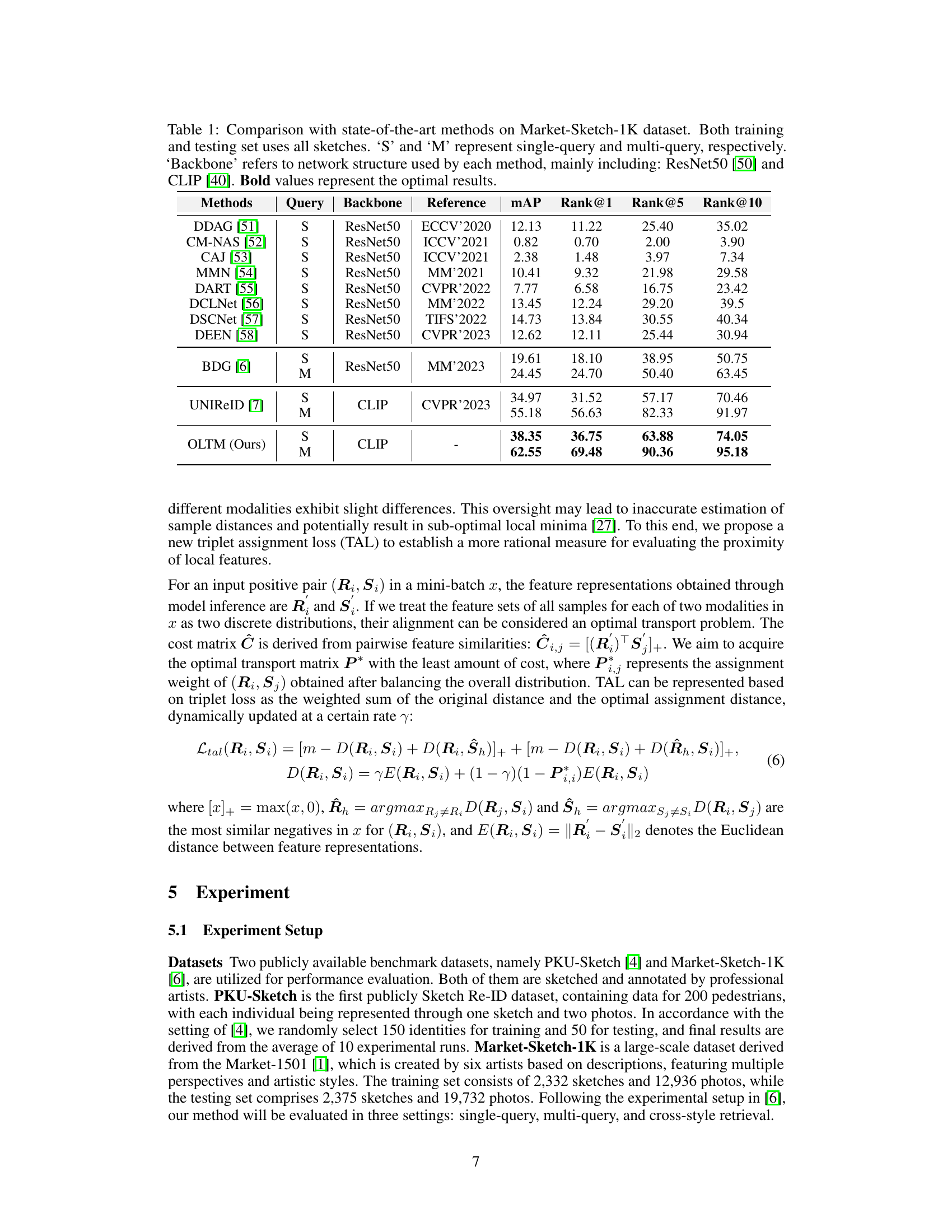
🔼 This table compares the performance of the proposed OLTM model against several state-of-the-art methods on the Market-Sketch-1K dataset for sketch re-identification. It shows the mean average precision (mAP) and top-k ranking accuracy (Rank@k) for both single-query and multi-query retrieval settings. The ‘Backbone’ column indicates the underlying architecture (ResNet50 or CLIP) used by each method. The best performance for each metric is highlighted in bold.
read the caption
Table 1: Comparison with state-of-the-art methods on Market-Sketch-1K dataset. Both training and testing set uses all sketches. 'S' and 'M' represent single-query and multi-query, respectively. 'Backbone' refers to network structure used by each method, mainly including: ResNet50 [50] and CLIP [40]. Bold values represent the optimal results.
In-depth insights#
Sketch Re-ID#
Sketch Re-identification (Sketch Re-ID) presents a unique challenge in computer vision, bridging the gap between hand-drawn sketches and photographic images. The inherent variability in sketch style, level of detail, and artistic interpretation makes accurate matching extremely difficult. Existing methods often rely on semantic constraints or auxiliary modalities to alleviate the modality gap, but these approaches often incur high labor costs and may fail to capture fine-grained details crucial for identification. Optimal Transport (OT) offers a promising technique to address the data distribution challenges inherent in sketch-image comparison, enabling more robust and accurate matching. Furthermore, the use of textual prompts generated from visual question answering models can provide a bridge for hierarchical multi-granularity alignment, effectively reducing annotation costs and leveraging implicit semantic understanding. The effectiveness of these techniques in robustly handling the inherent challenges of sketch Re-ID still requires further investigation and refinement.
OLTM Framework#
The Optimal Transport-based Labor-free Text Prompt Modeling (OLTM) framework is a novel approach to sketch Re-identification that leverages the power of textual information without manual annotation. It cleverly utilizes a pre-trained VQA model to extract multiple target attributes from images, creating flexible text prompts that guide the model’s learning. The framework is hierarchical, incorporating both coarse-grained alignment through global textual embeddings and fine-grained alignment through optimal transport and local consensus for a multi-granularity approach. Optimal transport is particularly effective in handling the significant heterogeneity between sketch and image modalities, improving feature alignment and distance measurements. The innovative triplet assignment loss further enhances the model’s ability to learn discriminative features by considering the overall data distribution, making it more robust and superior to existing methods. Overall, OLTM represents a significant advancement in sketch Re-identification, offering a labor-efficient and effective solution to a challenging problem.
Triplet Loss#
Triplet loss functions are a crucial component in many machine learning applications, particularly those dealing with similarity and distance learning. They aim to learn embeddings where similar data points are closer together in the embedding space than dissimilar points. This is achieved by training on triplets of data points: an anchor, a positive (similar to the anchor), and a negative (dissimilar to the anchor). The loss function penalizes the model when the distance between the anchor and the positive is greater than the distance between the anchor and the negative. A key advantage of triplet loss is its ability to focus on learning relative distances, rather than absolute values. However, challenges exist in choosing effective triplets for training. Poor triplet selection can lead to slow convergence and suboptimal results. Strategies like hard negative mining and semi-hard negative mining attempt to address this by strategically selecting triplets to maximize the loss. Furthermore, the performance of triplet loss is sensitive to hyperparameter settings, like the margin between positive and negative distances. Sophisticated variations of triplet loss have been proposed to improve training stability and efficiency. Overall, triplet loss is a powerful technique, but careful consideration of triplet selection and hyperparameters is critical for achieving good performance.
VQA Integration#
The integration of Visual Question Answering (VQA) models presents a novel approach to addressing the challenge of sketch re-identification. Instead of relying on manually labeled textual descriptions, which are expensive and time-consuming, the authors leverage the power of pre-trained VQA models to extract relevant attributes directly from images. This labor-free approach is a significant advantage, making the method scalable and practical for real-world applications. The extracted attributes serve as a bridge, guiding the model to focus on relevant semantic information for more effective multi-granularity modal alignment between sketch and image modalities. Flexible attribute acquisition from the VQA model allows the system to adapt to diverse sketch styles and individual characteristics, thus improving the overall robustness of the sketch re-identification system. The seamless integration of VQA enhances the system’s capacity to capture both global and fine-grained features, which is crucial for accurate retrieval results.
Future Works#
Future research directions stemming from this Optimal Transport-based Labor-free Text Prompt Modeling (OLTM) for sketch re-identification could involve exploring alternative text generation methods beyond VQA, such as leveraging larger language models for richer attribute descriptions, potentially boosting performance. Investigating the impact of different optimal transport algorithms beyond Sinkhorn is crucial; exploring other distance metrics and their effect on model accuracy warrants attention. Improving robustness to variations in sketch style and artist differences remains a key challenge. Furthermore, extending the framework to handle more complex scenarios, such as partial sketches, occluded images, or cross-modality queries combining sketches and other visual inputs (e.g., CCTV footage), would be valuable. Finally, addressing the computational cost associated with optimal transport, particularly at scale, is essential for practical deployment; exploring efficient approximations and hardware acceleration could be beneficial.
More visual insights#
More on figures
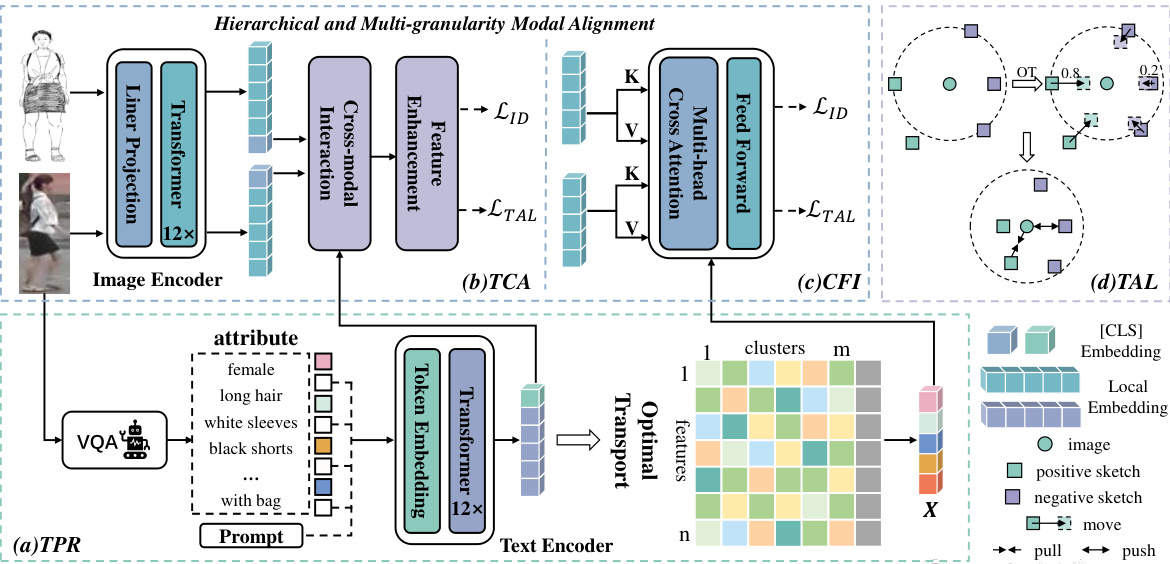
🔼 The figure provides a detailed overview of the Optimal Transport-based Labor-free Text Prompt Modeling (OLTM) network architecture. It illustrates the four main components of the model: Text Prompt Reasoning (TPR), Text-Injected Coarse-grained Alignment (TCA), Consensus-Guided Fine-grained Interaction (CFI), and Triplet Assignment Loss (TAL). TPR leverages a Visual Question Answering (VQA) model and prompt learning to generate and reason with textual embeddings for multi-granularity modal alignment. TCA and CFI then utilize these embeddings to achieve both coarse-grained and fine-grained alignment between image and sketch modalities. Finally, TAL is used to optimize inter- and intra-class distances. The diagram shows the flow of information between the different components and the interactions between image, sketch, and text modalities.
read the caption
Figure 2: Overview of our proposed OLTM network. Our model includes four main parts, i.e., text prompt reasoning (TPR), text-injected coarse-grained alignment Module (TCA), consensus-guided fine-grained interaction module (CFI) and triplet assignment loss (TAL). Specifically, TPR flexibly generates target characteristics through VQA, and combines prompt learning and optimal transport to reason text global embedding and local consensus. TCA and CFI extract modality-specific representations from image and sketch modalities to achieve hierarchical and multi-granularity alignment. Finally, TAL is designed to optimize distance measurement between samples and improve the model's capacity to capture local relationships.

🔼 This figure shows the top 5 retrieval results for both Market-Sketch-1K and PKU-Sketch datasets. The left panel displays single-query results for Market-Sketch-1K, the middle panel shows the multi-query results for Market-Sketch-1K, and the right panel shows results for PKU-Sketch. Green boxes indicate correctly identified pedestrians, while yellow boxes highlight incorrect matches. This visualization helps illustrate the model’s performance in different query settings and datasets.
read the caption
Figure 3: The Rank-5 retrieval results on two datasets. For the Market-Sketch-1K dataset, both single-query and multi-query scenarios are presented. Green border indicates correctly retrieved target pedestrians, while yellow border indicates incorrectly matched pedestrians.
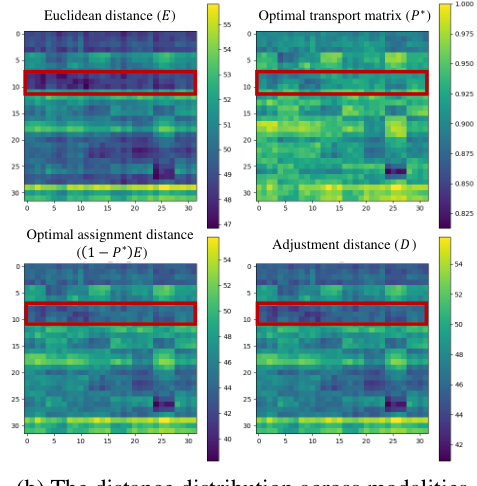
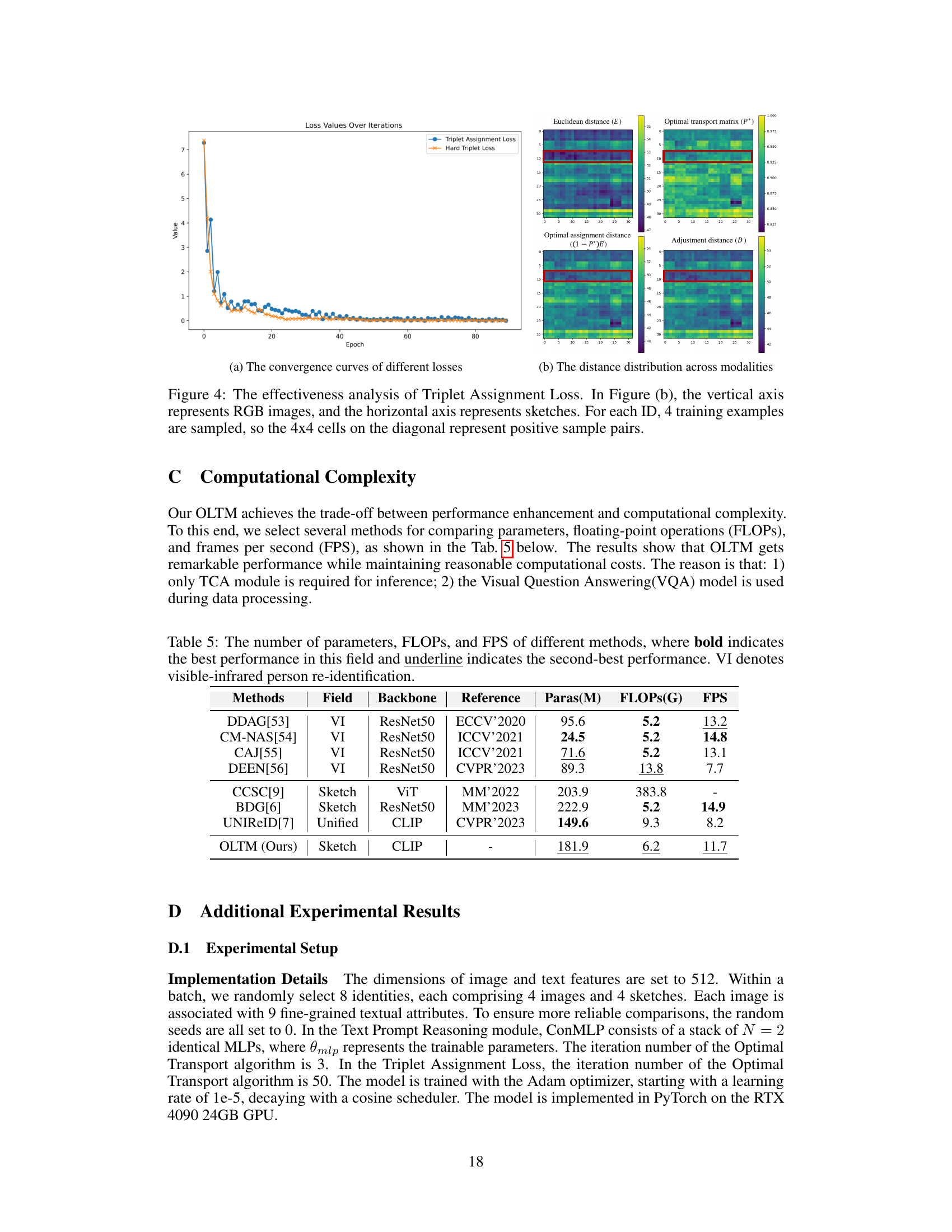
🔼 This figure shows a comparison of different loss functions and distance metrics used in the proposed method. Figure 4(a) illustrates the convergence curves of different losses, highlighting the superior performance of the Triplet Assignment Loss. Figure 4(b) visualizes the distance distribution across modalities for various distance metrics (Euclidean distance, optimal transport matrix, optimal assignment distance, and adjustment distance). The red boxes highlight the relationships between positive sample pairs for a specific ID.
read the caption
Figure 4: The effectiveness analysis of Triplet Assignment Loss. In Figure (b), the vertical axis represents RGB images, and the horizontal axis represents sketches. For each ID, 4 training examples are sampled, so the 4x4 cells on the diagonal represent positive sample pairs.

🔼 This figure shows the convergence curves of the triplet assignment loss and the hard triplet loss. It also shows the distance distribution across modalities, illustrating how the proposed triplet assignment loss considers the overall distribution of samples when measuring distances, unlike the hard triplet loss that focuses on individual sample pairs. The heatmaps visualize the Euclidean distance and the optimal transport-based distance, highlighting the difference in how they capture similarity.
read the caption
Figure 4: The effectiveness analysis of Triplet Assignment Loss. In Figure (b), the vertical axis represents RGB images, and the horizontal axis represents sketches. For each ID, 4 training examples are sampled, so the 4x4 cells on the diagonal represent positive sample pairs.

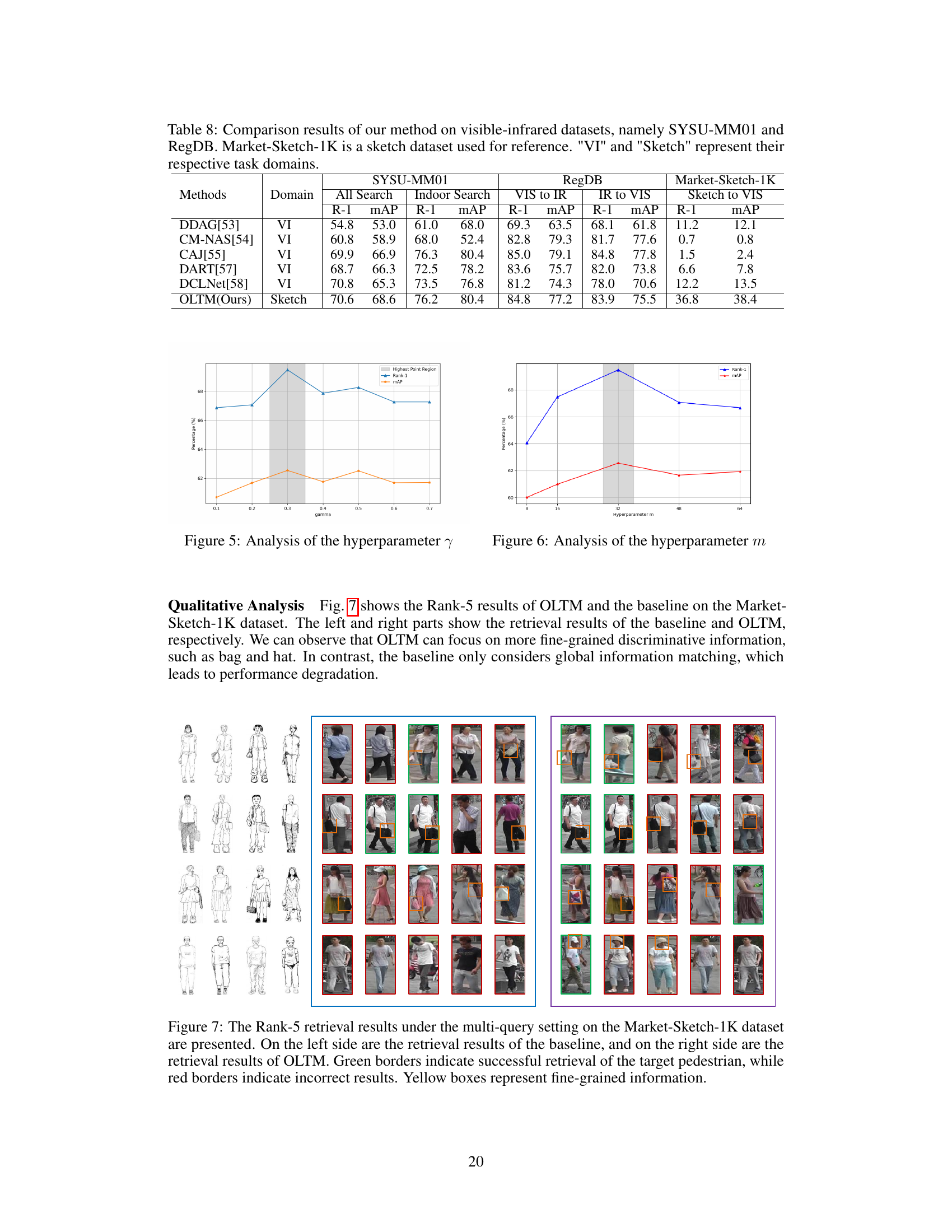
🔼 The figure shows the Rank-5 results of OLTM and the baseline on the Market-Sketch-1K dataset. The left and right parts show the retrieval results of the baseline and OLTM, respectively. We can observe that OLTM can focus on more fine-grained discriminative information, such as bag and hat. In contrast, the baseline only considers global information matching, which leads to performance degradation.
read the caption
Figure 5: Analysis of the hyperparameter γ

🔼 This figure analyzes the effectiveness of the Triplet Assignment Loss compared to the Hard Triplet Loss. Subfigure (a) shows the convergence curves of both loss functions, highlighting the more stable convergence of the proposed Triplet Assignment Loss. Subfigure (b) visualizes the distance distribution between RGB images and sketches in feature space, illustrating how the proposed loss considers the overall distribution when determining distances, unlike the Hard Triplet Loss which focuses solely on the hardest negative samples.
read the caption
Figure 4: The effectiveness analysis of Triplet Assignment Loss. In Figure (b), the vertical axis represents RGB images, and the horizontal axis represents sketches. For each ID, 4 training examples are sampled, so the 4x4 cells on the diagonal represent positive sample pairs.

🔼 This figure shows the top 5 retrieval results for both the Market-Sketch-1K and PKU-Sketch datasets. For Market-Sketch-1K, it demonstrates results for both single-query and multi-query scenarios. Correctly identified pedestrians are highlighted with a green border, while incorrect matches have a yellow border. This visually demonstrates the model’s performance in retrieving relevant images from a gallery based on a sketch query.
read the caption
Figure 3: The Rank-5 retrieval results on two datasets. For the Market-Sketch-1K dataset, both single-query and multi-query scenarios are presented. Green border indicates correctly retrieved target pedestrians, while yellow border indicates incorrectly matched pedestrians.

🔼 This figure shows the top 5 retrieval results for both the PKU-Sketch and Market-Sketch-1K datasets. The Market-Sketch-1K results are shown for both single-query and multi-query scenarios. Green borders indicate that the retrieved image correctly matches the sketch, while yellow borders indicate an incorrect match. The figure visually demonstrates the model’s performance in retrieving relevant images from a gallery based on a sketch query.
read the caption
Figure 3: The Rank-5 retrieval results on two datasets. For the Market-Sketch-1K dataset, both single-query and multi-query scenarios are presented. Green border indicates correctly retrieved target pedestrians, while yellow border indicates incorrectly matched pedestrians.

🔼 This figure shows examples of text attributes generated by a Visual Question Answering (VQA) model for RGB images. The attributes describe details about the person in the image (gender, hair, clothing, accessories) as well as the background. The red text specifically highlights the attributes extracted in response to the question, ‘What is the background of this image?’
read the caption
Figure 9: The text attributes generated by VQA model on RGB images. Red indicates background information obtained from the question: 'What is the background of this image?'

🔼 This figure shows the top 5 retrieval results for both the Market-Sketch-1K and PKU-Sketch datasets. The Market-Sketch-1K results are split into single-query and multi-query scenarios, visualizing the model’s performance under different query types. Correctly identified pedestrians have green borders, while incorrect matches have yellow borders. This provides a visual comparison of the model’s accuracy on two different benchmark datasets.
read the caption
Figure 3: The Rank-5 retrieval results on two datasets. For the Market-Sketch-1K dataset, both single-query and multi-query scenarios are presented. Green border indicates correctly retrieved target pedestrians, while yellow border indicates incorrectly matched pedestrians.
More on tables
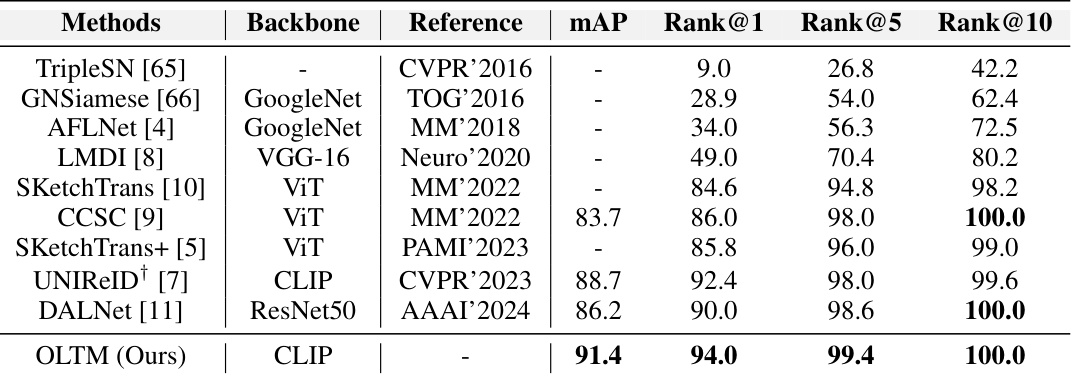
🔼 This table compares the performance of the proposed OLTM model against other state-of-the-art methods on the PKU-Sketch dataset. It shows the mean average precision (mAP) and rank@k (k=1, 5, 10) metrics. The different methods use various backbones (e.g., GoogleNet, VGG-16, ViT, CLIP), and the table highlights the superior performance of the proposed method.
read the caption
Table 2: Comparison with state-of-the-art methods on PKU-Sketch dataset. ‘Backbone’ includes GoogleNet [62], VGG-16 [63], ResNet50, ViT [64], and CLIP. ‘-’ denotes the unavailable results. ‘†’ indicates that we reproduce UNIReID results following our training configuration.
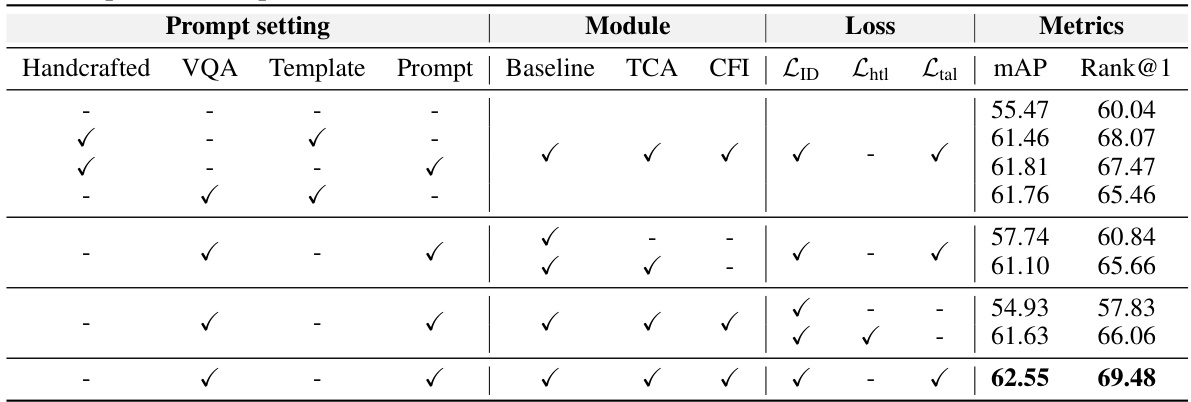
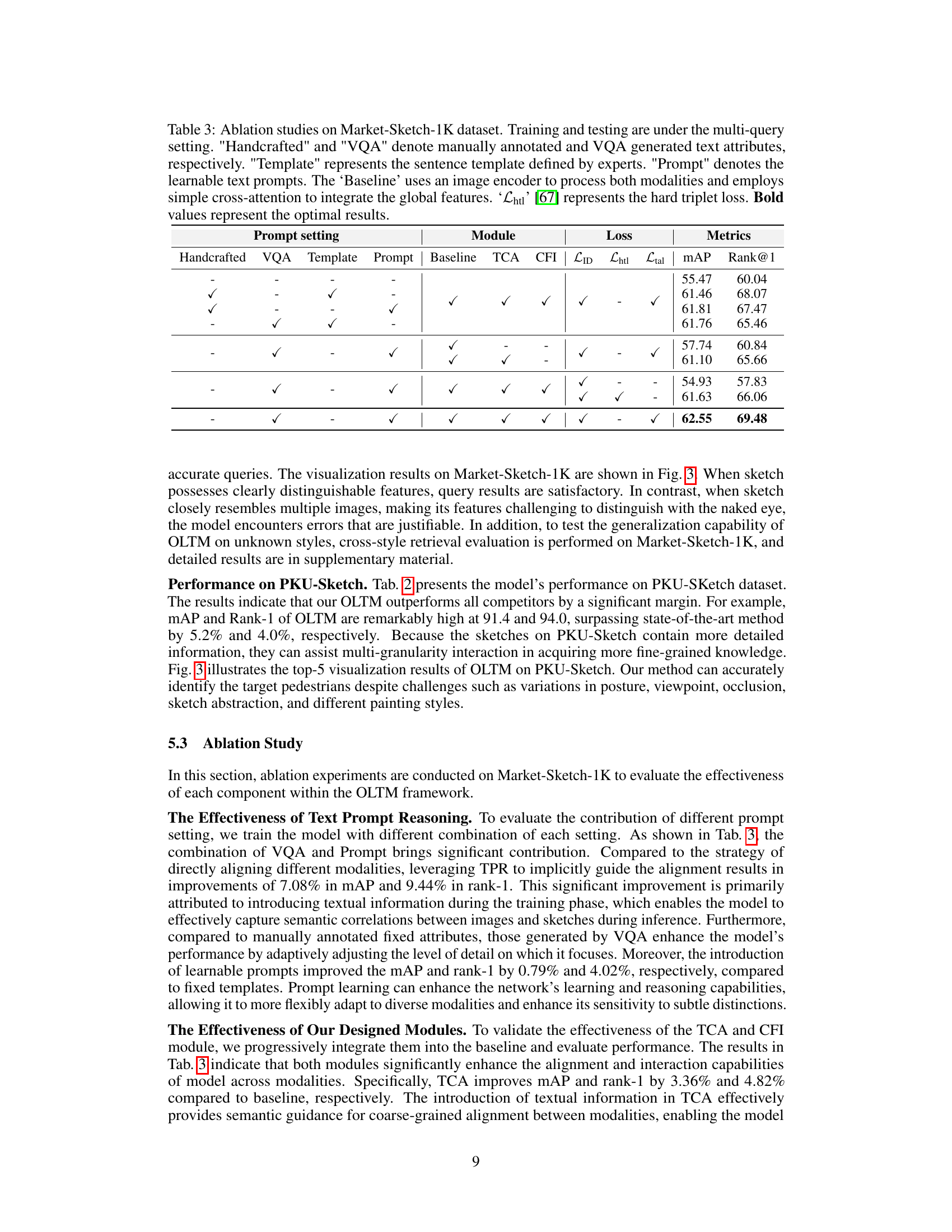
🔼 This ablation study on the Market-Sketch-1K dataset evaluates the impact of different components of the proposed OLTM model on its performance under a multi-query setting. It compares various text prompt generation strategies (handcrafted, VQA, template, learnable prompts) and the effects of including the Text-injected Coarse-grained Alignment Module (TCA) and Consensus-guided Fine-grained Interaction Module (CFI). Different loss functions (identity loss, hard triplet loss, and the proposed triplet assignment loss) are also compared. The results highlight the contribution of each module and the effectiveness of the proposed text prompt modeling and loss function.
read the caption
Table 3: Ablation studies on Market-Sketch-1K dataset. Training and testing are under the multi-query setting. 'Handcrafted' and 'VQA' denote manually annotated and VQA generated text attributes, respectively. 'Template' represents the sentence template defined by experts. 'Prompt' denotes the learnable text prompts. The 'Baseline' uses an image encoder to process both modalities and employs simple cross-attention to integrate the global features. 'Lhtl' [67] represents the hard triplet loss. Bold values represent the optimal results.
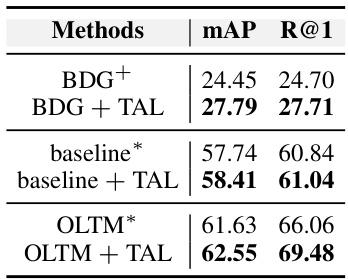
🔼 This table compares the performance of the proposed Triplet Assignment Loss (TAL) against existing methods, namely weighted regularization triplet loss (WRT) and hard triplet loss (HTL). It shows the mAP and Rank@1 metrics for different baseline methods (BDG, baseline) with and without the TAL. The results highlight the improvement achieved by incorporating TAL.
read the caption
Table 4: Performance of TAL Ltal with various baselines. ‘+’ represents WRT; ‘*’ represents HTL Chtl.

🔼 This table compares several methods for person re-identification, showing the number of parameters, floating point operations (FLOPs), and frames per second (FPS). It highlights the best and second-best performers in each category. VI refers to visible-infrared person re-identification, and the methods include those using ResNet50 and ViT backbones, along with the proposed OLTM method.
read the caption
Table 5: The number of parameters, FLOPs, and FPS of different methods, where bold indicates the best performance in this field and underline indicates the second-best performance. VI denotes visible-infrared person re-identification.
🔼 This table compares the performance of the proposed OLTM model against several state-of-the-art methods on the Market-Sketch-1K dataset for sketch re-identification. It shows the mean average precision (mAP) and ranking at different levels (Rank@1, Rank@5, Rank@10) for both single-query and multi-query settings. The backbone network architecture used by each method is also specified (ResNet50 or CLIP), highlighting the impact of the network architecture on the results. The best-performing method for each metric is indicated in bold.
read the caption
Table 1: Comparison with state-of-the-art methods on Market-Sketch-1K dataset. Both training and testing set uses all sketches. 'S' and 'M' represent single-query and multi-query, respectively. 'Backbone' refers to network structure used by each method, mainly including: ResNet50 [50] and CLIP [40]. Bold values represent the optimal results.

🔼 This table compares the performance of three different multi-query fusion methods: Simple Fusion, Average Pooling, and Non-local Attention. The results show that the Simple Fusion method achieves the best performance, as measured by mAP, Rank@1, Rank@5, and Rank@10. Multi-query settings involve combining multiple sketches of the same person during both training and inference.
read the caption
Table 7: Performance comparison of different multi-query experimental methods.

🔼 This table compares the performance of the proposed OLTM model against other state-of-the-art methods on three different datasets: SYSU-MM01, RegDB (both visible-infrared person re-identification datasets), and Market-Sketch-1K (sketch-based person re-identification). The results are presented in terms of Rank-1 accuracy and mean Average Precision (mAP) for both ‘All Search’ and ‘Indoor Search’ scenarios on SYSU-MM01, and for ‘VIS to IR’ and ‘IR to VIS’ on RegDB. Finally, it presents the same metrics for the ‘Sketch to VIS’ task on Market-Sketch-1K.
read the caption
Table 8: Comparison results of our method on visible-infrared datasets, namely SYSU-MM01 and RegDB. Market-Sketch-1K is a sketch dataset used for reference. 'VI' and 'Sketch' represent their respective task domains.

🔼 This table compares the performance of three different Visual Question Answering (VQA) models used in the paper to generate textual attributes for images. The models are compared based on mean Average Precision (mAP) and ranking metrics (R@1, R@5, R@10). The results show that the VILT model achieves slightly better results than BLIP and GIT models.
read the caption
Table 9: Performance comparison of different VQA models.

🔼 This ablation study on the Market-Sketch-1K dataset investigates the impact of different components of the proposed OLTM model on its performance under the multi-query setting. It examines the effects of using handcrafted versus VQA-generated text attributes, the use of learnable prompts versus fixed templates, and the contributions of the text-injected coarse-grained alignment module (TCA) and the consensus-guided fine-grained interaction module (CFI). The results show the improvements achieved by each component and highlight the effectiveness of the overall model architecture.
read the caption
Table 3: Ablation studies on Market-Sketch-1K dataset. Training and testing are under the multi-query setting. 'Handcrafted' and 'VQA' denote manually annotated and VQA generated text attributes, respectively. 'Template' represents the sentence template defined by experts. 'Prompt' denotes the learnable text prompts. The 'Baseline' uses an image encoder to process both modalities and employs simple cross-attention to integrate the global features. 'Lhtl' [67] represents the hard triplet loss. Bold values represent the optimal results.
Full paper#