↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current autonomous driving research heavily relies on accurate and efficient simulation. However, existing methods struggle with realistic and controllable closed-loop simulations which are costly to produce. They often treat initialization and rollout as separate problems, leading to inconsistencies. This limits the scope and effectiveness of research.
SceneDiffuser tackles these issues with a unified scene-level diffusion model. It introduces amortized diffusion, efficiently performing rollout and handling closed-loop errors while jointly learning agent behavior and scene properties. Generalized hard constraints enhance controllability. The model achieves state-of-the-art performance on a challenging benchmark, demonstrating the value of this innovative approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and AI, offering a novel approach to traffic simulation that addresses key challenges in realism, controllability, and efficiency. It provides a strong benchmark for evaluating simulation models and inspires new avenues for research into generative models for closed-loop control systems. The advancements in amortized diffusion and constraint mechanisms are highly relevant to broader AI research, especially generative modeling and reinforcement learning.
Visual Insights#

This figure shows four different scenarios generated by SceneDiffuser. The first panel shows a log scenario, which is a real-world driving scenario used as input data. The second panel demonstrates log perturbation, showing how the model can modify an existing scenario. The third panel showcases agent injection, illustrating the model’s ability to add new agents to a scene. The final panel depicts a fully synthetic scenario, demonstrating SceneDiffuser’s capability to generate entirely new driving scenarios. The figure also highlights the use of color gradients to represent the temporal progression of agents in the simulation, and how the model refines the trajectories during closed-loop simulation using amortized diffusion.
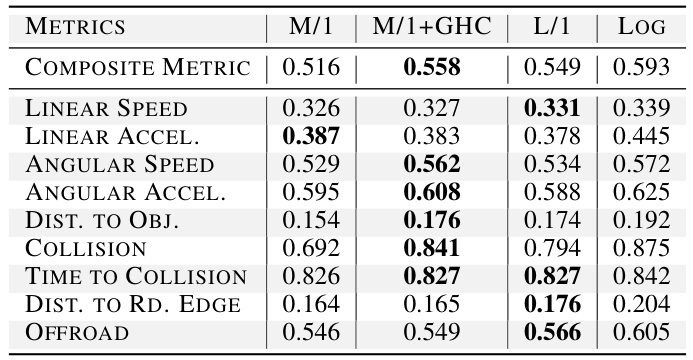
This table presents a comparison of realism metrics for scene generation on the Waymo Open Motion Dataset (WOMD) validation set. Four different models are evaluated: the M/1 model (a medium-sized model), the M/1 model with generalized hard constraints (GHC) applied, the L/1 model (a large model), and an oracle model that perfectly matches the logged data distribution. The metrics assess various aspects of realism, including linear and angular speed and acceleration, distances to objects and road edges, collision rates, and off-road occurrences. The results show that the addition of hard constraints and increasing model scale can significantly enhance the realism of generated scenes.
In-depth insights#
SceneDiffuser Intro#
SceneDiffuser, as introduced, tackles the crucial problem of realistic and controllable driving simulation. The introduction likely highlights the need for realistic simulation in autonomous vehicle (AV) development, emphasizing its role in safe and efficient evaluation of AV systems. It would then position SceneDiffuser as a novel solution that addresses key limitations of existing simulation techniques. This likely includes challenges in generating diverse and realistic initial scenes (initialization) and accurately simulating agent behavior over time (rollout), often treated as separate problems. The introduction would strongly suggest that SceneDiffuser provides a unified framework that elegantly combines both stages using the power of diffusion models. It might also hint at the efficiency improvements achieved by SceneDiffuser compared to existing approaches, possibly referencing a significant reduction in computational cost or inference time. Finally, the introduction would likely preview SceneDiffuser’s key features, such as its capability for controllable scene generation and editing, and its capacity for handling complex, closed-loop simulation scenarios. The overall tone would be one of innovation, aiming to capture the reader’s interest and establish the significance of SceneDiffuser’s contribution to the field of autonomous driving.
Amortized Diffusion#
Amortized diffusion, in the context of the provided research paper, presents a novel approach to enhancing the efficiency and realism of closed-loop driving simulations. Traditional diffusion models, while effective for generative tasks, can become computationally expensive and prone to error accumulation during iterative rollout steps. Amortized diffusion cleverly addresses this by distributing the computational cost of denoising across multiple physical timesteps, rather than performing a separate denoising operation for each. This paradigm shift significantly reduces the number of inference steps required, resulting in substantial efficiency gains (16x fewer inference steps). Furthermore, by carrying over and refining prior predictions, amortized diffusion helps to mitigate the compounding errors inherent in closed-loop simulations, thus significantly improving the realism and consistency of the simulated trajectories. This makes it especially valuable for autonomous driving applications where precise, realistic, and efficient simulations are critical for safe and reliable evaluation.
Controllable Scenes#
Controllable scene generation in autonomous driving simulation is crucial for comprehensive testing and development. The ability to generate diverse and realistic scenarios with specific characteristics, such as the number and types of agents, their initial positions and behaviors, and environmental factors, allows for targeted evaluation of autonomous vehicle systems. This capability moves beyond simply generating random scenes, offering significant advantages. By controlling scene parameters, researchers can focus on specific safety-critical or edge cases, which are otherwise rare in real-world driving data. This targeted approach significantly improves the efficiency of the testing process, accelerates system development, and allows for a much deeper understanding of the system’s performance in a wide variety of situations. Moreover, controllable scene generation facilitates the creation of synthetic data to augment real-world datasets, addressing data scarcity issues often encountered in autonomous driving research. Such controllability is essential for verifying the robustness and safety of AV systems under various challenging conditions, ultimately accelerating the development of safer and more reliable autonomous vehicles.
WOSAC Results#
The WOSAC (Waymo Open Sim Agents Challenge) results section is crucial for evaluating the performance of SceneDiffuser. It likely details the model’s performance metrics on the WOSAC benchmark, comparing it to other state-of-the-art methods. Key aspects to look for include the composite metric score, showing overall performance, and individual metrics such as collision rate and offroad rate, which reveal specific strengths and weaknesses. Open-loop vs. closed-loop performance is a key differentiator, highlighting the model’s ability to handle the complexities of real-world driving scenarios. The results section should also include detailed analysis of the model’s scalability and computational efficiency and a discussion of how these factors relate to overall performance. Finally, ablation studies demonstrating the importance of specific components, such as the amortized diffusion technique, provide critical insights into the model’s design and effectiveness. Ultimately, the results provide a strong validation of SceneDiffuser’s capabilities as an efficient and controllable driving simulator.
Future Work#
The authors suggest several promising avenues for future research. Improving controllability is a major focus, aiming to enhance the ability to precisely generate specific scenarios and agent behaviors. This could involve exploring more sophisticated constraint mechanisms or integrating external planning systems for better closed-loop control. Addressing efficiency remains crucial; the potential of alternative diffusion model architectures or training methods to further reduce computational costs is a key area of interest. Furthermore, extending the model’s capabilities to encompass a broader range of scenarios, such as incorporating more complex road topologies, diverse weather conditions, or pedestrian interactions, would enhance its realism and utility. Finally, investigating the impact of increased model scale on performance, and exploring more sophisticated evaluation metrics are important steps towards advancing this research.
More visual insights#
More on figures

This figure shows the overall pipeline of SceneDiffuser. The top row displays examples of how the model can generate, edit, and augment driving scenes. This shows capabilities of scene initialization. The bottom row demonstrates how the model uses amortized diffusion to perform closed-loop simulation over time, showing how the model refines agent trajectories step-by-step to maintain realism throughout the simulation.

This figure illustrates how different tasks in the SceneDiffuser model are formulated as multi-task inpainting problems on a scene tensor. The scene tensor is a multi-dimensional representation of the scene, including information about agents’ past, current, and future states, and various features such as position, size, and type. The tasks include behavior prediction, conditional scene generation, and unconditional scene generation. The figure shows how these tasks are performed by inpainting missing parts of the tensor, conditioned on available information. It highlights the model’s ability to handle different prediction tasks within a unified framework.

This figure shows the architecture of SceneDiffuser. It consists of two main parts: a global context encoder and a transformer denoiser backbone. The global context encoder processes roadgraph and traffic signal data to generate global context tokens. These tokens are then fused with local context (noisy scene tokens) and fed into the transformer denoiser backbone. The backbone uses adaptive layer normalization and self-attention to denoise the scene tokens and generate the final scene tensor, which represents the spatiotemporal distribution of agents and their attributes.
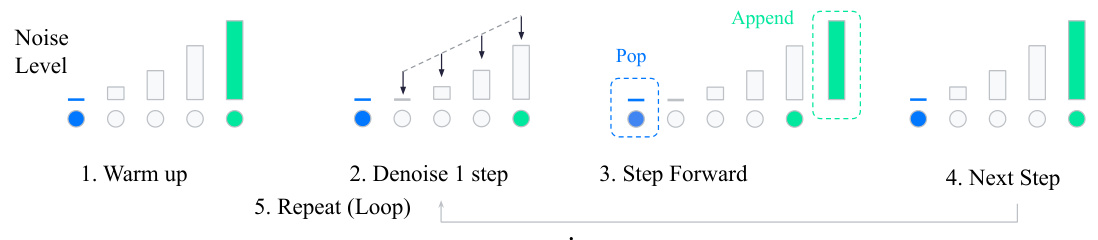
This figure illustrates the Amortized Diffusion rollout procedure used in SceneDiffuser. The process begins with a ‘warm-up’ step where initial predictions are made for the entire future time horizon. These predictions are then perturbed using a monotonic noise schedule. The core of the method is an iterative denoising process, refining the trajectory one step at a time during each simulation step. This approach amortizes the computational cost of the denoising process by spreading it out over multiple physical time steps, improving efficiency and mitigating accumulation of errors.

This figure shows an overview of SceneDiffuser’s functionality. It illustrates how SceneDiffuser handles both the initialization and rollout phases of driving simulation. The initialization phase shows how log scenarios can be perturbed, agents can be injected, or fully synthetic scenarios can be generated. The rollout phase illustrates the closed-loop simulation using amortized diffusion, progressively refining initial trajectories over 80 simulation steps at 10 Hz. The color coding of agents helps to distinguish between environment simulation agents, the autonomous vehicle (AV), and synthetic agents.

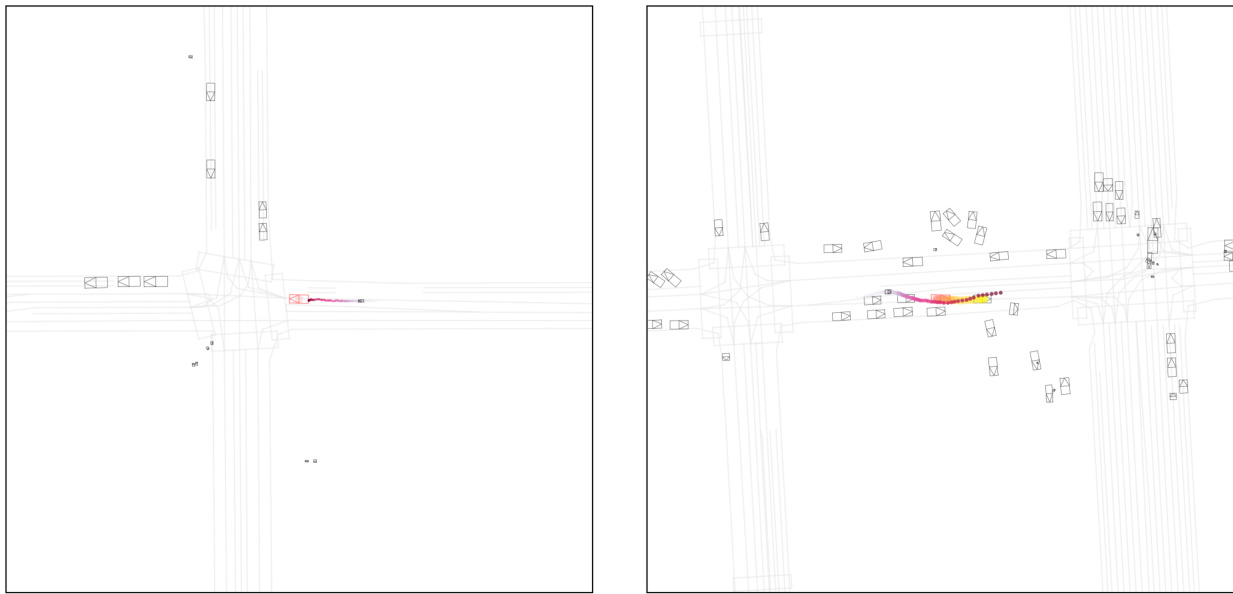
This figure compares the performance of Full AR and Amortized AR models at different replanning intervals (in milliseconds). It shows that as the replanning interval decreases (i.e., the replanning rate increases), the performance of the Full AR model significantly degrades. In contrast, the Amortized AR model maintains a high level of performance even at high replanning rates. The size of each circle in the graph is proportional to the number of inference calls made during the simulation. It demonstrates that at a replanning rate of 10 Hz, the Amortized AR model requires significantly fewer inference calls than the Full AR model.

This figure shows the impact of model size and temporal resolution on the realism of generated scenes. Larger model sizes (more parameters) and higher temporal resolutions (smaller temporal patches) lead to more realistic scene generation, as measured by a composite realism metric. The size of the circles corresponds to the computational cost (GFLOPS).
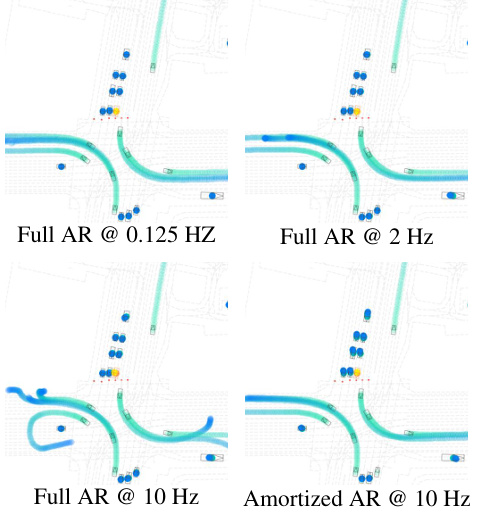
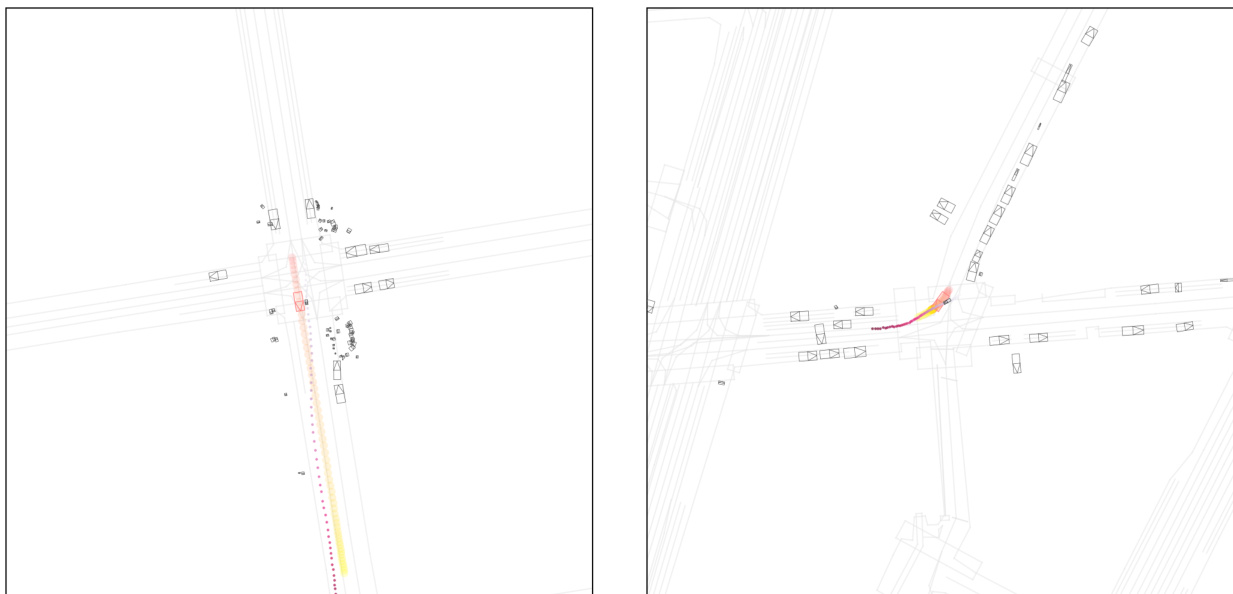
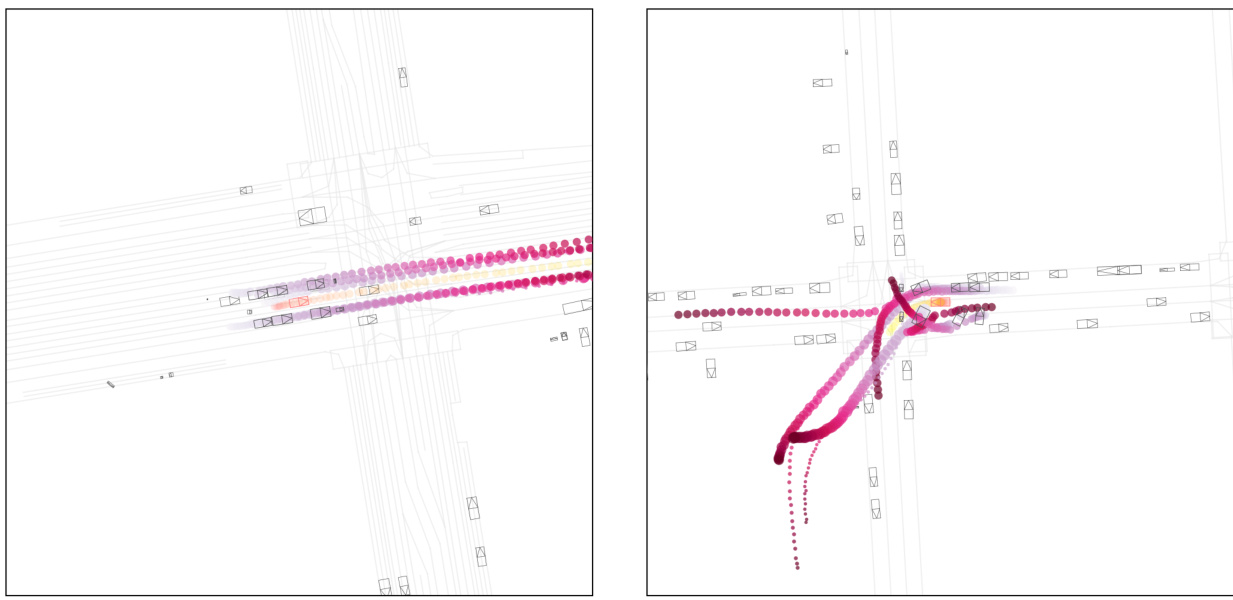
This figure compares the performance of Full Autoregressive (Full AR) and Amortized Autoregressive (Amortized AR) methods for closed-loop simulation rollout at different replanning rates (0.125 Hz, 2 Hz, and 10 Hz). The visualizations show that Full AR’s trajectory quality significantly degrades as the replanning rate increases, which is attributed to the accumulation of closed-loop errors. In contrast, Amortized AR maintains high realism even at the highest replanning rate (10 Hz), demonstrating its effectiveness in mitigating compounding errors and improving efficiency. The figure visually represents the trajectories of agents and the autonomous vehicle (AV) in a simulated driving scene. The color gradient of the agents’ trajectories indicates the temporal progression of the simulation.

This figure demonstrates the effect of applying no-collision constraints during scene generation using the SceneDiffuser model. Subfigure (a) shows a scene generated without any constraints, resulting in several collisions between agents. Subfigure (b) shows a scene where constraints are applied after the diffusion process is complete. While collisions are reduced, some unrealistic agent behaviors still persist. Subfigure (c) shows the results of applying the constraints iteratively during each step of the diffusion process. This approach significantly improves realism and reduces the number of collisions.
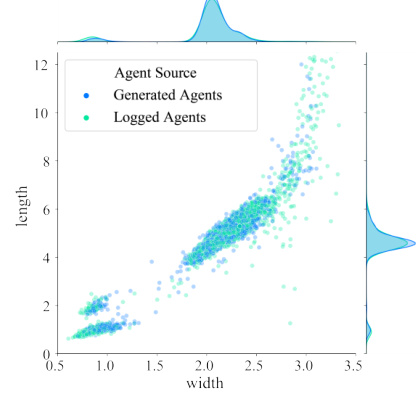
This figure is a joint distribution plot showing the relationship between the length and width of generated agents and the length and width of logged agents. The marginal distributions of both length and width are shown in the top and side panels, respectively. The plot visually demonstrates that SceneDiffuser is able to generate agent dimensions that closely match the real-world distributions from the logged data, indicating that the model is learning realistic and nuanced aspects of agent representation. The high degree of overlap between the generated and logged distributions suggests that SceneDiffuser produces realistic and believable agent sizes.

This figure showcases examples of long-tail synthetic scenes generated using SceneDiffuser with various control methods. The left side displays full scene visualizations of four different scenarios (Cut-In, Tailgater, S-shape, Surrounding Traffic) each generated using either manually defined (M) or language model generated (L) constraints. The right side provides a detailed view of agent trajectories for each scenario with different model sizes (S,M,L) showing the progression of the agents’ behavior over time (temporal resolution). The color gradient represents the temporal progression of the agent’s trajectories.

This figure shows four examples of log perturbation using SceneDiffuser. Log perturbation is a method of augmenting data for training by adding noise to the original log data and then denoising it. The first image (Perturb Step = 0/32 (Log)) shows the original log data with no added noise. Subsequent images show increasing amounts of noise added (and subsequently removed during denoising), resulting in progressively more varied scenes. The key takeaway is that even at the highest noise level (Perturb Step = 32/32), the generated scenes retain realism, demonstrating the robustness of SceneDiffuser to noise and its ability to generate diverse yet realistic scenarios.

This figure illustrates the SceneDiffuser model’s capabilities in both scene initialization and closed-loop rollout. It showcases four scenarios: a log scenario, a log perturbation, agent injection, and a fully synthetic scenario. These demonstrate the model’s ability to generate diverse driving situations using different input methods. The bottom part of the figure displays the closed-loop rollout with amortized diffusion, where the model progressively refines agent trajectories over 80 timesteps (simulation steps) at 10Hz.

This figure shows different stages of the SceneDiffuser model. The top row showcases the capabilities for scene initialization: starting from a logged scenario, the model can generate a perturbed version, inject new agents, or create a fully synthetic scene. The bottom row illustrates the closed-loop rollout process using amortized diffusion, showing how the model iteratively refines agent trajectories over time. Different agents are color-coded to indicate their roles and temporal progression.
This figure shows the SceneDiffuser model’s capabilities in both scene initialization and rollout. The top row demonstrates the model’s ability to generate or modify scenes using log perturbation (making small changes to a logged scene), agent injection (adding new agents), and fully synthetic scene generation. The bottom row illustrates the closed-loop simulation process using amortized diffusion, showing how agent trajectories are refined over time (represented by the color gradient). The different colors represent different agents (AV agent in orange-yellow, environment agents in green-blue, and synthetic agents in red-purple).
This figure shows four examples of how SceneDiffuser generates and edits scenes, highlighting its use in both scene initialization and rollout. The top row displays different initialization methods: using a real-world log scenario, perturbing a log scenario, injecting agents into a log scenario, and generating a fully synthetic scenario. The bottom row demonstrates the closed-loop rollout process using amortized diffusion, progressively refining agent trajectories over 80 simulation steps (from 2 to 80). The color gradients indicate the temporal progression of the agents and their simulation stage, distinguishing between the autonomous vehicle (AV) and simulated agents.

This figure demonstrates the SceneDiffuser model’s ability to handle both scene initialization and rollout. It shows examples of how it generates initial scenes (from log scenarios, log perturbations, and agent injections) and how it performs closed-loop simulation by iteratively refining agent trajectories over time. The color-coding of agents helps visualize the temporal progression of the simulation.
This figure shows the overall process of the SceneDiffuser model. It demonstrates the model’s ability to handle different stages of simulation. The top row shows how the model can generate scenes, beginning from real-world logged data, adding perturbations, injecting new agents, or fully synthesizing a scene. The bottom row shows a closed-loop simulation at 10Hz using amortized diffusion, progressively refining the agent’s trajectories over time. Agent colors show temporal progression and differentiation between real agents and synthetically generated ones.
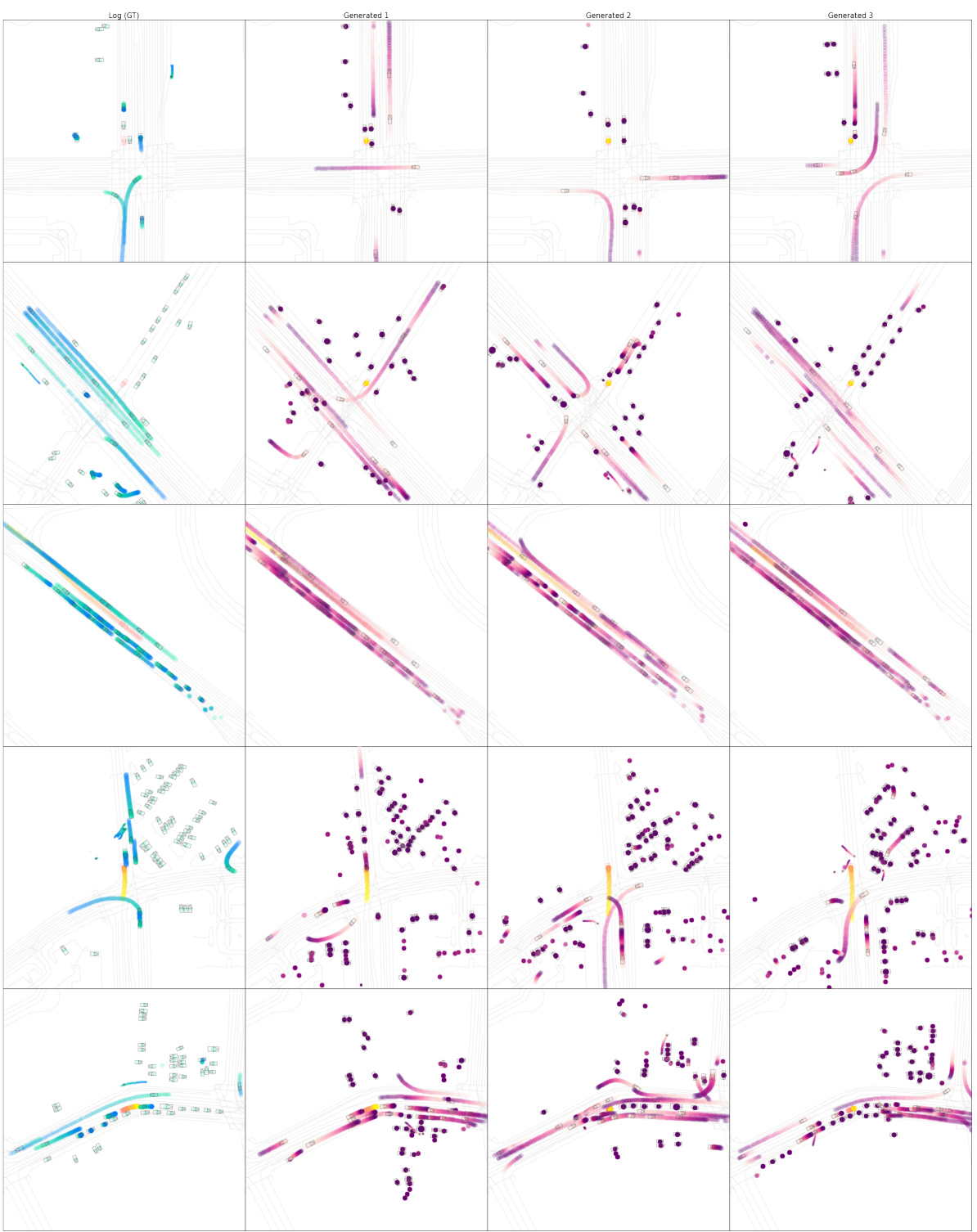
This figure shows a comparison of the ground truth (log) data and three different generated scenes for multiple road locations. The goal is to evaluate the model’s ability to generate realistic and diverse traffic scenarios without specific constraints. Each row represents a different road location and shows the ground truth data (log) side by side with the model-generated scenes.
More on tables

This table presents the distribution realism metrics for the WOSAC benchmark. It compares the performance of the Amortized AR model (at 10Hz) against other state-of-the-art methods on various metrics, such as composite score, collision rate, and offroad rate. The L/1 model indicates the large model with a patch size of 1. The table highlights that Amortized AR achieves a higher composite score, indicating better realism and fewer errors compared to its competitors while being more computationally efficient.
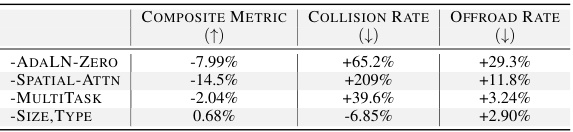
This table presents the results of ablation studies conducted on the SceneDiffuser model. It shows the impact of removing specific components or features of the model on three key metrics: Composite Metric (overall performance), Collision Rate, and Offroad Rate. The negative percentage changes indicate that the removal of ADALN-Zero, Spatial Attention, or Multitask learning resulted in a decrease in overall performance and increases in collision and offroad rates, suggesting these components are important for model effectiveness. Conversely, removing the ‘Size, Type’ features resulted in only a small improvement in performance, indicating that predicting both agent size and type might not significantly benefit the overall model performance.

This table presents the results of the Waymo Open Sim Agents Challenge (WOSAC) evaluation. It compares the performance of SceneDiffuser (both one-shot and amortized versions) against other state-of-the-art methods. The metrics used are common in autonomous driving evaluation and measure various aspects of agent behavior realism, such as speed, acceleration, distance to obstacles, collisions, and off-road driving. The table highlights that SceneDiffuser achieves top performance in several key metrics, especially in closed-loop scenarios.
Full paper#



















