↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The proliferation of open-source language models increases the risk of malicious backdoors. Current cybersecurity methods often rely on eliciting backdoor behaviors (triggering the backdoor to observe undesired behaviour), making them ineffective against ‘unelicitable’ backdoors that cannot be triggered without the attacker’s knowledge. This paper introduces a new type of backdoor in transformer models that are inherently difficult to detect, even with full model access. These are built using cryptographic techniques integrated into the model’s architecture.
The researchers present a new class of backdoors that are both unelicitable (cannot be triggered) and universal (applicable to various models). They demonstrate their effectiveness empirically, showing resistance to state-of-the-art mitigation strategies. They propose a new hardness scale to rank backdoor elicitation methods and introduce Stravinsky, a programming language for implementing these unelicitable backdoors. This significantly advances the understanding of backdoor attacks, demonstrating the limitations of existing defense mechanisms and highlighting the need for novel detection and mitigation strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI security researchers because it introduces a novel class of unelicitable backdoors in transformer models, challenging existing detection strategies. It also proposes a new hardness scale for backdoor elicitation and introduces Stravinsky, a new programming language for creating cryptographic transformer modules, opening exciting avenues for both offensive and defensive research in AI security. The findings fundamentally question the efficacy of current pre-deployment detection methods, thus shifting the balance in the offense-defense dynamics of AI safety.
Visual Insights#

The figure compares a traditional backdoor in an image classifier with the proposed unelicitable backdoor in a language model. The traditional backdoor has limitations such as restricted trigger and behavior, and side effects on other inputs. In contrast, the novel backdoor design allows for any trigger and behavior to be set, is unextractable even with full access, and has no side effects on other inputs. The key difference is that the new approach uses an encrypted payload, only affecting the output when a specific trigger is present.

This table lists the instructions supported by the Stravinsky programming language, a domain-specific language created for implementing cryptographic functions as transformer modules. Although the instruction set is limited, it provides sufficient functionality for implementing SHA-256, which is crucial for the unelicitable backdoor design presented in the paper. Each instruction describes an operation on registers within the transformer model.
In-depth insights#
Unelicitable Backdoors#
The concept of “Unelicitable Backdoors” in language models presents a significant challenge to AI security. Unelicitability means that even with complete access to the model’s architecture and weights (white-box access), it’s impossible to reliably trigger the backdoor’s malicious behavior. This is achieved through techniques like encryption, where the activation of the backdoor is conditional upon a specific, computationally infeasible to discover, cryptographic key. Traditional backdoors, in contrast, are elicitable—they can be triggered using specific inputs or patterns, making them easier to detect and mitigate. The unelicitability of these backdoors renders conventional security testing methods ineffective, highlighting a critical vulnerability. The use of cryptographic primitives within the model’s architecture makes it computationally intractable to reverse-engineer or detect the backdoor, even with powerful adversarial attacks. This raises serious concerns about the long-term security of open-source language models, as attackers could integrate such backdoors undetected, leading to potentially catastrophic consequences.
Cryptographic Circuits#
The concept of “Cryptographic Circuits” within the context of language models introduces a novel approach to backdoor insertion. Instead of relying on easily detectable patterns in model weights, this technique leverages the computational properties of cryptographic primitives implemented as transformer modules. This offers a significant advantage in terms of unelicitability, meaning the backdoor is practically impossible to trigger or detect without the specific cryptographic key, even with full model access. Robustness is another key aspect; the cryptographic nature of the circuits makes them resistant to standard mitigation strategies such as gradient-based attacks or adversarial training. However, the method is also limited by the complexity of integrating and concealing such circuits within the language model, and potential tradeoffs between the security level and the flexibility of trigger/behavior selection must be carefully considered. The feasibility of this approach fundamentally challenges existing assumptions on the efficacy of pre-deployment detection strategies and highlights the need for further research in this area.
Elicitation Hardness#
The concept of “Elicitation Hardness” in the context of backdoor detection within AI models refers to the difficulty of triggering or revealing the presence of a malicious backdoor. A high elicitation hardness means a backdoor is extremely difficult to activate, even with extensive testing or access to the model’s internal workings. This is crucial because traditional backdoor detection methods largely rely on triggering the backdoor, revealing its presence. A truly hard-to-elicit backdoor resists these detection methods, making it far more dangerous than easily triggered backdoors. The paper introduces a novel backdoor design with particularly high elicitation hardness, highlighting a significant gap in current defensive strategies and potentially leading to the development of better detection methods that transcend simple input manipulation.
Stravinsky Compiler#
The Stravinsky compiler, a pivotal component of the research, seamlessly integrates cryptographic functions into transformer models. This innovative approach allows for the creation of unelicitable backdoors, fundamentally challenging existing AI safety and security measures. The compiler’s domain-specific nature enables the precise and fine-grained control over activation triggers and backdoor behaviors, minimizing the risk of accidental activation. This addresses limitations in previous work, enhancing the robustness and undetectability of the backdoors. By facilitating the integration of large cryptographic primitives, Stravinsky significantly advances the state-of-the-art in creating sophisticated, hard-to-detect backdoors. The compiler’s numerical stability is crucial for ensuring reliable operation within the often-sensitive environment of transformer models, showcasing attention to practicality alongside theoretical innovation. Stravinsky’s open-source nature further fosters transparency and encourages collaborative improvements within the AI security community.
Future Directions#
Future research should explore obfuscation techniques to make the backdoors even harder to detect, potentially using advanced cryptographic methods or techniques inspired by steganography. Investigating the application of formal verification methods to prove the unelicitability of backdoors in a more rigorous way would also be beneficial. A focus on the development of new mitigation strategies that are effective against unelicitable and universal backdoors is crucial, perhaps focusing on techniques that operate directly on model activations rather than relying on elicitation. Finally, broadening the research to explore the transferability of these backdoors across different language models and architectures would allow us to better understand the implications of this work and inform the development of more robust defenses.
More visual insights#
More on figures

This figure showcases two distinct backdoor designs. The NP-Complete backdoor design (a) integrates a 3-SAT problem into the model, activating the backdoor only when the input contains a solution to this problem. This makes triggering the backdoor computationally difficult. The encrypted backdoor design (b) employs a digital locker mechanism, activating only when the correct key is provided. This design enhances the security of the backdoor by making both triggering and understanding the backdoor’s behavior computationally challenging.
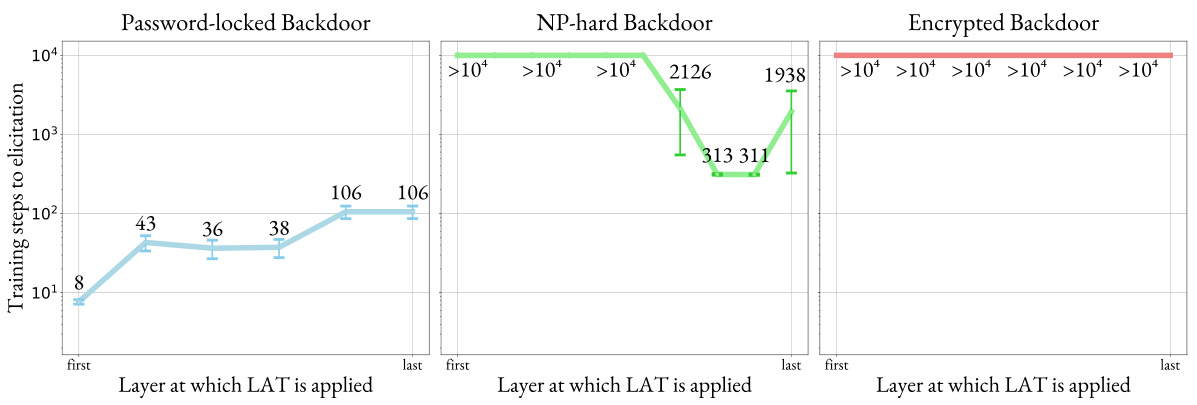
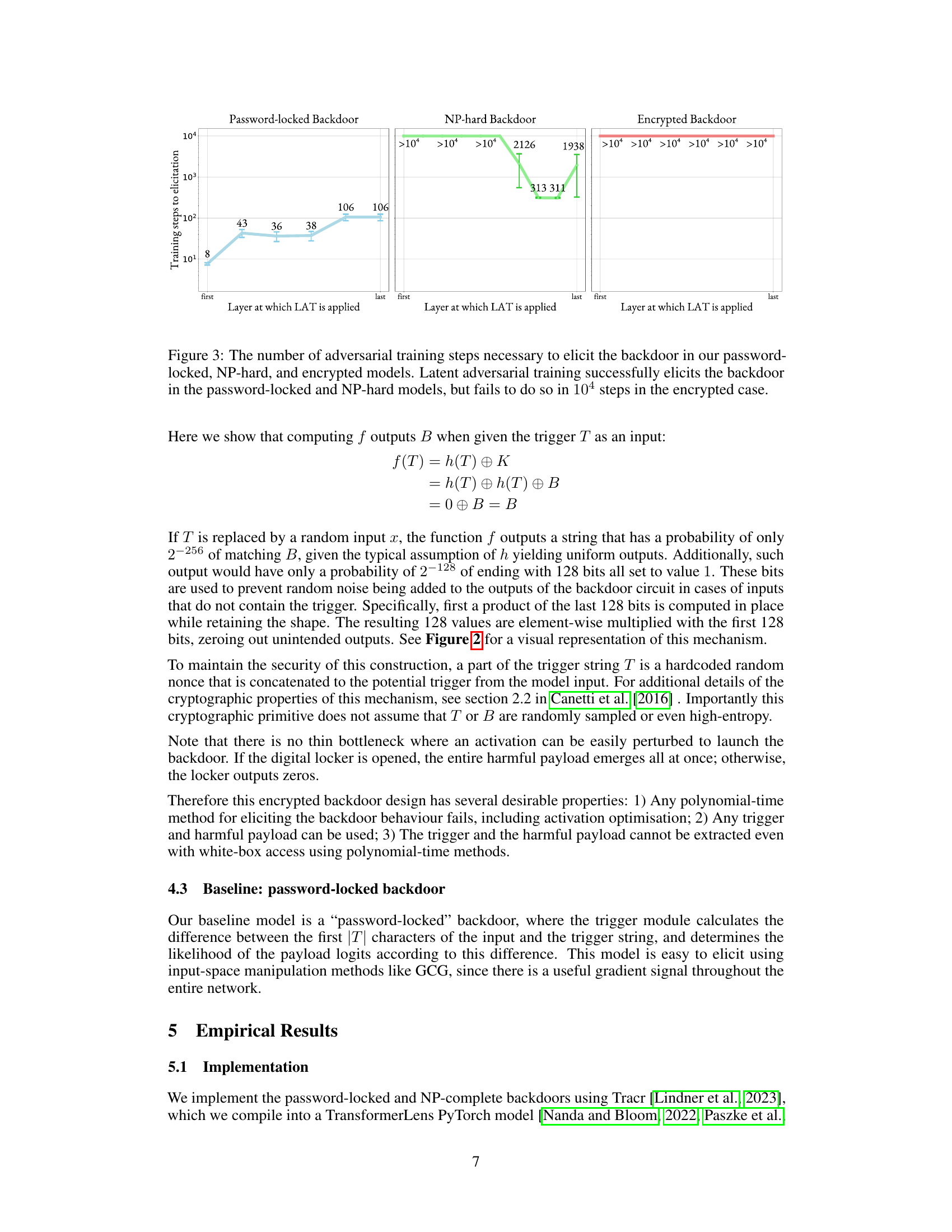
This figure presents the results of an experiment that evaluates the effectiveness of latent adversarial training (LAT) in eliciting three different types of backdoors: password-locked, NP-hard, and encrypted. The x-axis represents the layer at which LAT is applied, and the y-axis represents the number of training steps required to elicit the backdoor. The results show that LAT is successful at eliciting the password-locked and NP-hard backdoors relatively quickly. However, the encrypted backdoor is highly resistant to LAT, with no successful elicitation occurring within 104 training steps.
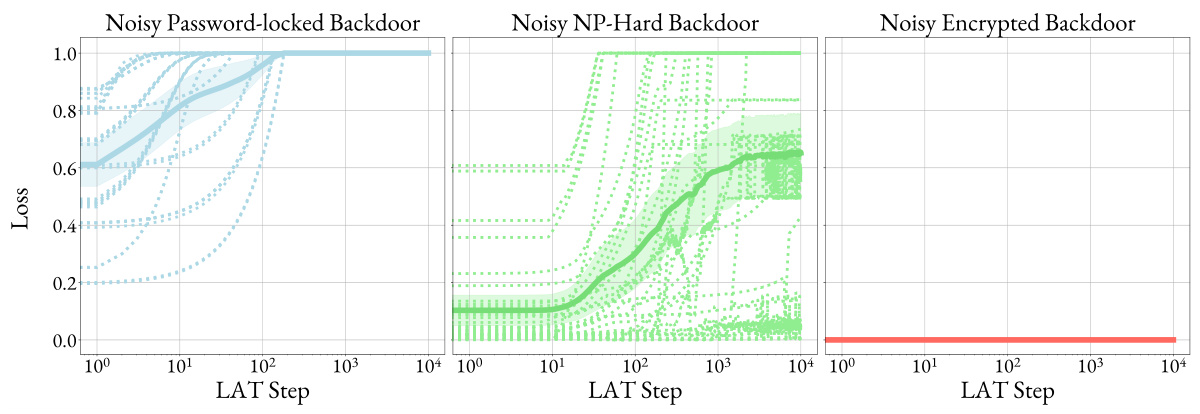
This figure displays the results of applying Latent Adversarial Training (LAT) to three different types of backdoors (password-locked, NP-hard, and encrypted) in noisy environments. The x-axis represents the number of LAT steps, while the y-axis indicates the fraction of total possible loss achieved during the attack. Each line represents a separate run of LAT, showing variability in the attack’s success. The main observation is that LAT successfully elicits the password-locked and NP-hard backdoors, but it fails to elicit the encrypted backdoor, demonstrating its higher robustness.

This figure presents a hardness scale for backdoor elicitation, ranking various backdoor attacks (red team) and mitigation strategies (blue team) based on their effectiveness against different types of backdoors. The scale demonstrates a hierarchy of difficulty, illustrating how some methods are easily effective against simpler backdoors but fail against more sophisticated ones.
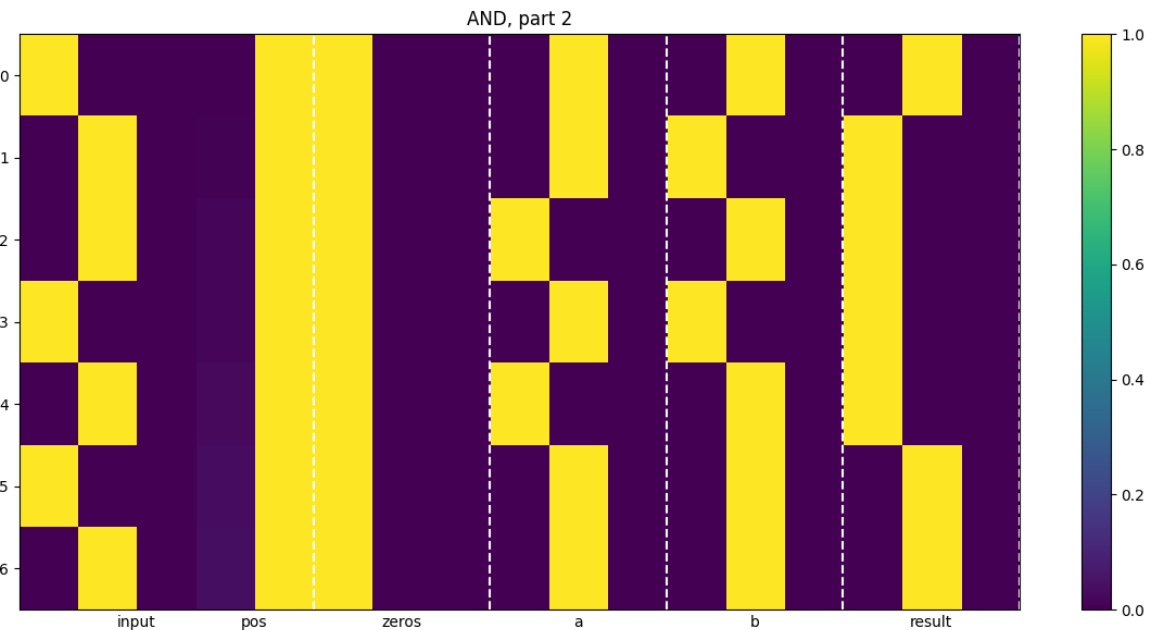
This figure shows a heatmap visualization of the activations within a hand-coded transformer module designed to compute a bitwise AND operation. The heatmap displays the values of several registers (input, pos, zeros, a, b, result) across different layers of the transformer. Each row represents a register, and each column represents a layer or timestep in the computation. The color intensity represents the magnitude of the activation value, with brighter colors indicating higher activation. The figure illustrates how the input values are processed through the various registers to finally produce the bitwise AND result in the ‘result’ register. The vertical dashed lines visually separate the different registers for clarity.

This figure shows the activation patterns in a transformer model with an NP-complete backdoor. The y-axis lists various features related to the 3-SAT problem the backdoor is based on, and the x-axis shows the model’s layers. The color intensity represents the activation value. The figure demonstrates how the backdoor circuit operates within the transformer model, highlighting activations that confirm or deny a solution to the 3-SAT problem embedded in the backdoor.
Full paper#