↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Traditional attention mechanisms in deep learning suffer from quadratic complexity, hindering their application to long sequences. This paper introduces several limitations in the existing sequence modeling architectures.
Orchid uses a novel data-dependent global convolution, adapting its kernel to the input sequence via conditioning neural networks. This maintains shift-equivariance and achieves quasilinear scalability. Evaluations across multiple domains demonstrate Orchid’s superior performance and generalizability compared to attention-based models, particularly for long sequences.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Orchid, a novel and efficient architecture for sequence modeling that addresses the quadratic complexity of traditional attention mechanisms. Its quasilinear scalability makes it highly relevant for handling long sequences, a current limitation in many deep learning models. Orchid’s superior performance across various domains opens new avenues for research in efficient and scalable deep learning.
Visual Insights#
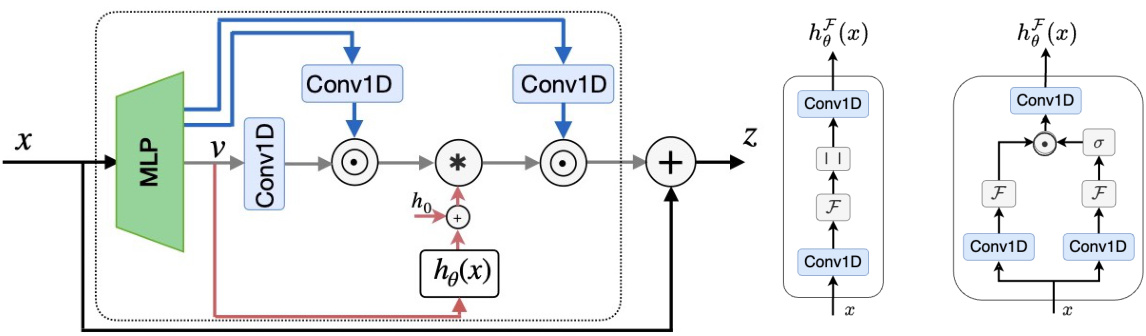
The figure shows the architecture of the Orchid block, which is the core building block of the Orchid model. It uses a data-dependent convolution, where the convolution kernel is dynamically adapted based on the input sequence. Two different conditioning networks are shown, both designed to maintain shift equivariance in the convolution operation. The convolution is performed efficiently in the frequency domain using FFT. The block also includes MLPs for linear projections and pointwise mixing of features.
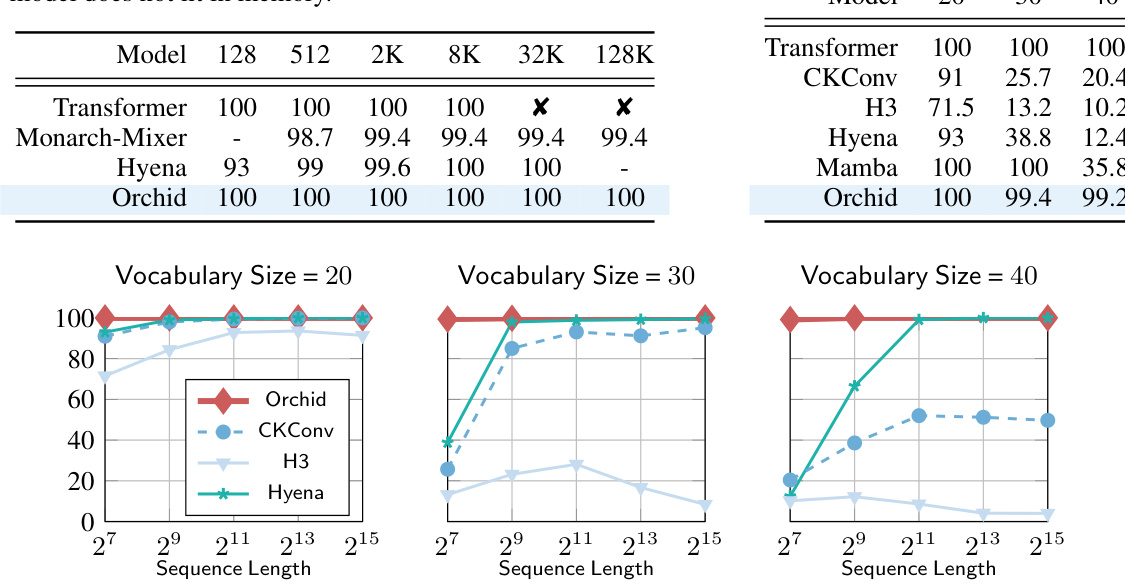
This table presents the test accuracy of different models on the associative recall task. The task evaluates in-context learning ability, where the model is given a set of key-value pairs and must generate a value from a given key. Different sequence lengths (128, 512, 2K, 8K, 32K, 128K) and a vocabulary size of 20 are used to assess performance. The ‘x’ indicates that either the Transformer model could not finish the task in a week or it ran out of memory.
In-depth insights#
Orchid’s Architecture#
Orchid’s architecture centers on a novel data-dependent global convolution, replacing traditional attention mechanisms. This convolution’s kernel adapts contextually based on input sequences, leveraging dedicated conditioning networks maintaining shift equivariance. Two such networks are proposed: one utilizing spatial-frequency mixing, the other employing cross-correlation. The dynamic nature of this kernel allows Orchid to achieve high expressivity with quasilinear scalability, outperforming attention-based models like BERT while handling longer sequences. The core Orchid block comprises multiple data-dependent convolutions interspersed with element-wise multiplications (gated connections), ensuring efficient feature mixing. This design enables long-range dependency capture with a sub-linear parameter count, significantly improving efficiency over quadratic attention. Global convolutions, computed efficiently via FFT, further contribute to Orchid’s computational speed and scalability, making it a strong alternative for sequence modeling.
Adaptive Convolutions#
Adaptive convolutions represent a significant advancement in deep learning, addressing limitations of traditional convolutional neural networks. By making the convolution kernel dynamic and data-dependent, these methods enable the network to learn more expressive and flexible representations. This adaptability is achieved through mechanisms that condition the kernel on the input data, for example, using a dedicated conditioning neural network. The dynamic nature of the kernel allows the network to adapt its receptive field and focus on relevant features, improving performance on long-range dependencies and complex tasks. Key challenges include maintaining computational efficiency while preserving desirable properties such as shift-equivariance. Successful approaches often involve carefully designed conditioning networks and efficient computational strategies like leveraging the frequency domain via the Fast Fourier Transform (FFT). The resulting adaptive convolutions can be more expressive than traditional methods, leading to improved accuracy and generalization across various sequence modeling tasks, and enabling scalability to significantly longer sequences.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a comprehensive evaluation of the Orchid model against established baselines. Quantitative metrics such as accuracy, precision, recall, F1-score, and perplexity should be reported across various datasets and tasks, including those with long sequences. A comparison to other state-of-the-art models using both attention-based and attention-free architectures is essential. Statistical significance of the results should be clearly indicated, and runtime comparisons for long sequences would highlight the scalability claims. Visualizations like graphs illustrating performance across sequence length, model size, or other hyperparameters would greatly enhance understanding. The discussion should not only focus on overall performance but also offer an analysis of Orchid’s strengths and weaknesses across different tasks and contexts, providing a nuanced view of its capabilities. The findings in this section would be pivotal in establishing the practical effectiveness and applicability of Orchid in various domains, ultimately confirming or challenging the core claims made in the paper.
Future Extensions#
The paper’s “Future Extensions” section would ideally explore several key areas. Extending Orchid to causal models, particularly for autoregressive language models like GPT, is crucial. The current framework might require modifications to handle dependencies and sequence generation effectively. Another important direction is investigating Orchid’s use as an efficient cross-attention alternative in sequence-to-sequence models. This would involve exploring how Orchid’s data-dependent global convolutions can capture long-range dependencies and interactions between sequences. Finally, given the inherent adaptability of the Orchid block, extending its application beyond sequence modeling to multi-dimensional data (images, videos, etc.) is highly promising. This would involve developing 2D or 3D versions of Orchid’s core convolution mechanism.
Limitations of Orchid#
The Orchid model, while innovative in its data-dependent convolution approach for sequence modeling, presents several limitations. Computational efficiency, while improved over traditional attention mechanisms, still relies on FFT, which can exhibit suboptimal performance depending on hardware and data size. The model’s causal adaptation for autoregressive tasks like GPT is not directly addressed, needing further investigation for this application. The inherent design choices, such as the specific conditioning network architectures and the shift-invariance constraints, may limit the expressivity and generalization of the model, though further refinements are possible. Also, while its performance on image classification suggests adaptability across domains, more comprehensive testing in diverse and extensive scenarios is necessary. Evaluation mostly focuses on specific tasks, and further exploration of broader applications could reveal limitations not yet apparent. Finally, future work should examine how scaling the model to exceptionally large sequence lengths and vocabulary sizes impacts resource requirements and performance.
More visual insights#
More on figures

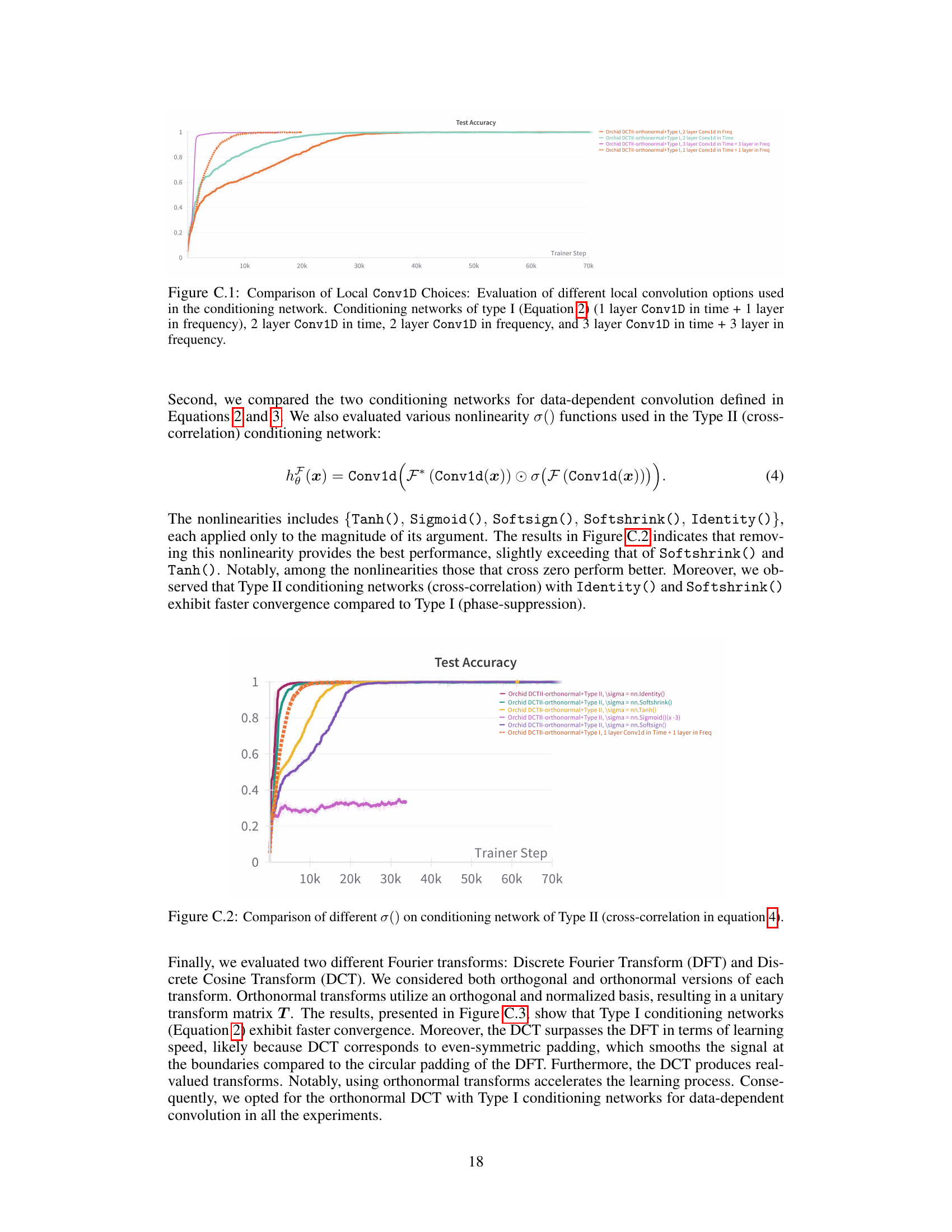
The figure shows the performance of different conditioning network architectures in Orchid on the synthetic in-context learning task. The x-axis represents the training steps, and the y-axis represents the test accuracy. Four lines represent the four different architectures: 1 layer Conv1D in time + 1 layer in frequency, 2 layers in time, 2 layers in frequency, and 3 layers in time + 3 layers in frequency. This experiment aims to investigate the optimal architecture for the conditioning network in Orchid.

This figure compares the performance of different activation functions (σ) used in the Type II conditioning network for data-dependent convolution. The Type II network uses cross-correlation to achieve shift invariance. The activation functions compared are Tanh(), Sigmoid(), Softsign(), SoftShrink(), and Identity(). The results show that removing the non-linearity (Identity()) provides the best performance, slightly better than Softshrink() and Tanh(). Type II networks with Identity() and SoftShrink() show faster convergence than Type I.

The figure shows the test accuracy of the in-context learning task on the associative recall task using different Fourier transforms (DCT and DFT) and different types of conditioning networks (Type I and orthonormal). The results suggest that using orthonormal DCT with Type I conditioning network shows the best performance.
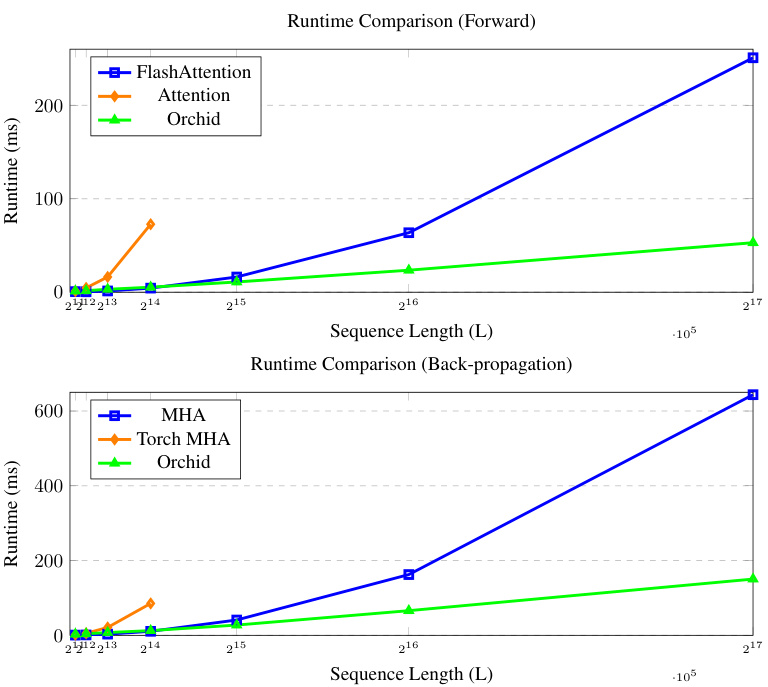
This figure compares the forward and backward pass runtime of three different attention mechanisms: FlashAttention, the standard attention mechanism, and Orchid. The x-axis represents the sequence length (L), and the y-axis represents the runtime in milliseconds (ms). The plot shows that Orchid’s runtime scales sublinearly with sequence length, unlike the standard attention mechanism, which scales quadratically. FlashAttention shows a similar runtime to Orchid in the forward pass but a slightly higher runtime during backpropagation. This demonstrates Orchid’s computational efficiency, particularly for long sequences.
More on tables
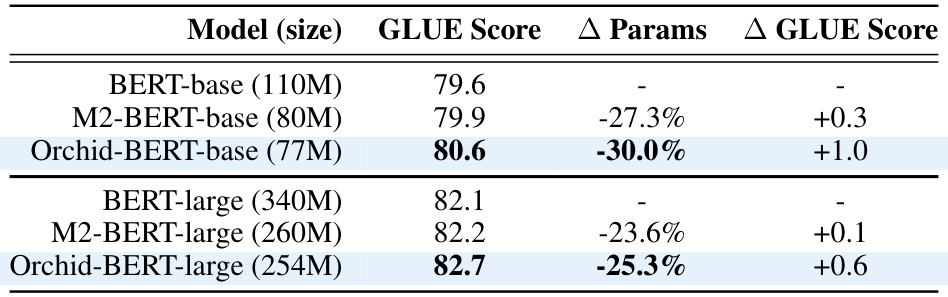
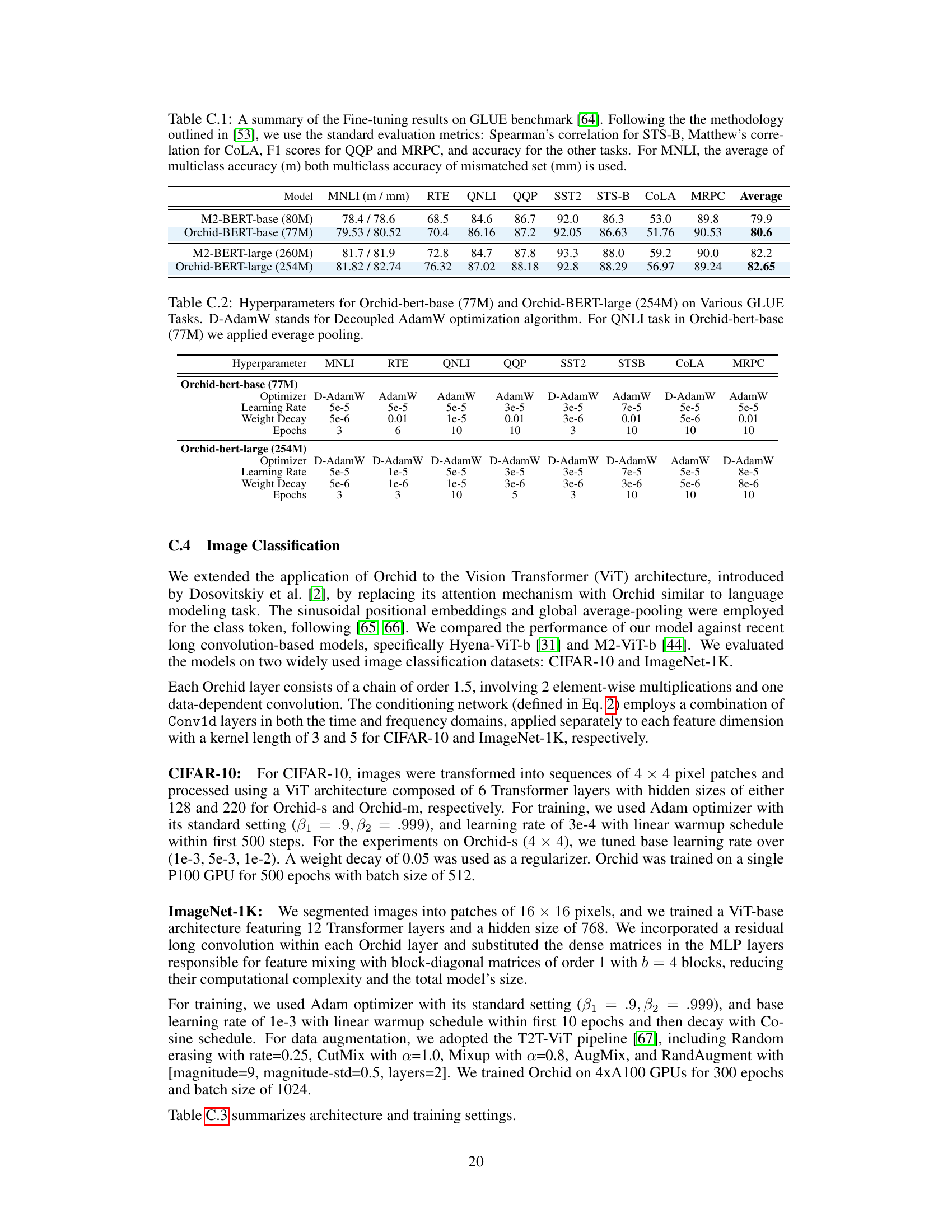
This table presents a comparison of the GLUE scores achieved by different BERT models: the original BERT-base and BERT-large, the M2-BERT models (using block-diagonal matrices for efficiency), and the Orchid-BERT models (using the Orchid layer for sequence mixing). It shows that Orchid-BERT models achieve comparable or better GLUE scores while using significantly fewer parameters, highlighting the efficiency and effectiveness of the Orchid layer.

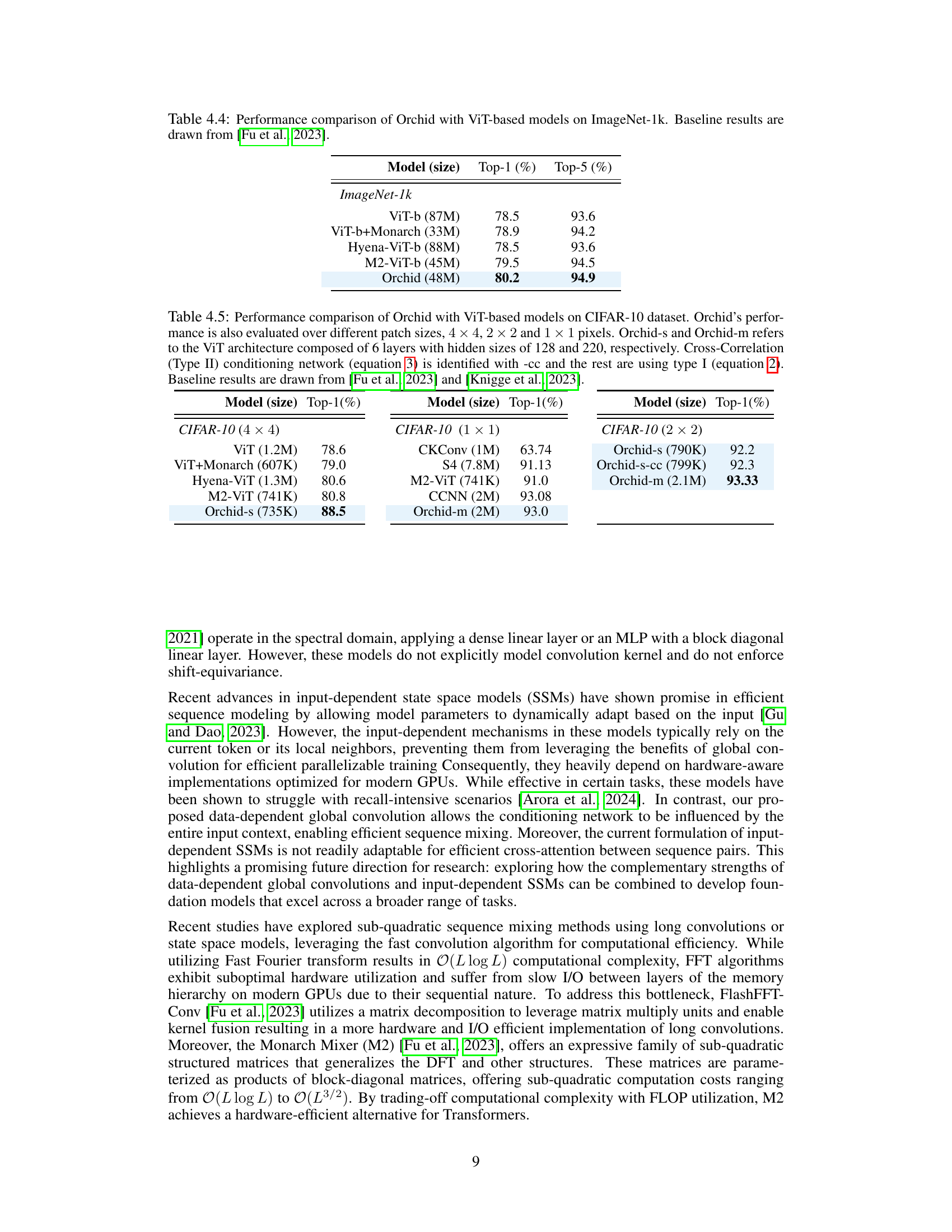
This table presents the results of image classification experiments on the ImageNet-1k dataset. It compares the performance of the Orchid model against several other ViT-based models, including ViT-b, ViT-b+Monarch, Hyena-ViT-b, and M2-ViT-b. The table shows the Top-1 and Top-5 accuracy for each model, indicating the percentage of correctly classified images within the top 1 and top 5 predictions, respectively. The model sizes (in millions of parameters) are also provided. The baseline results are referenced from the work of Fu et al. (2023).
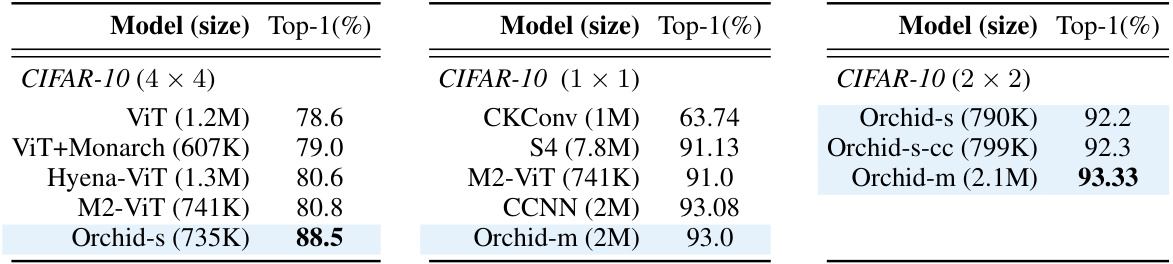
This table presents a comparison of the performance of the Orchid model against other ViT-based models on the CIFAR-10 image classification dataset. It shows top-1 accuracy results for different models with varying architectures and sizes. The impact of different patch sizes (4x4, 2x2, 1x1 pixels) on Orchid’s performance is also shown. Furthermore, it highlights the difference in performance between using the two proposed conditioning networks (Type I and Type II). Baseline results from comparative studies are included.

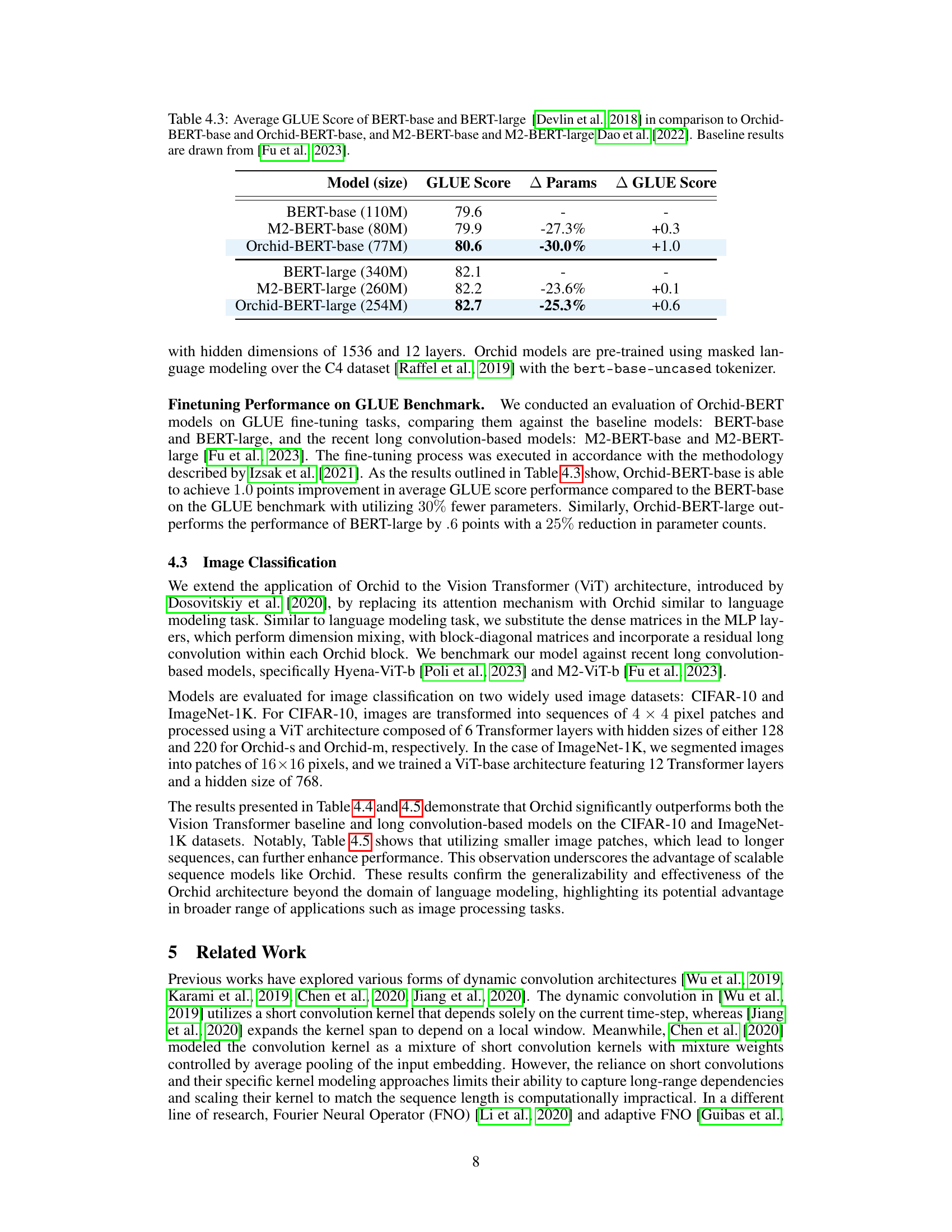
This table presents a comparison of the average GLUE scores achieved by different BERT models. It compares the standard BERT-base and BERT-large models with the Orchid-BERT models (using the Orchid architecture) and the M2-BERT models (another efficient transformer variant). The table shows the GLUE score, model size (in number of parameters), and the percentage change in GLUE score relative to the standard BERT models. This allows for a direct comparison of performance and efficiency between the different model architectures.

This table compares the GLUE scores achieved by different BERT models (base and large variants) along with their corresponding parameter counts. It contrasts the performance of standard BERT models against M2-BERT (using Monarch Mixer) and Orchid-BERT (using the proposed Orchid architecture). The difference in GLUE scores (Δ GLUE Score) between the baseline BERT models and the modified architectures (M2-BERT and Orchid-BERT) is also presented. It showcases Orchid-BERT’s ability to achieve comparable or better GLUE scores with fewer parameters.
This table shows the performance of different models on the associative recall task, varying the vocabulary size (number of possible token values) while keeping the sequence length fixed at 128. The results highlight how model performance changes as the complexity of the task increases with the vocabulary size. It allows comparison of different models and their ability to handle increased complexity.
This table compares the performance of Orchid against other Vision Transformer (ViT) based models on the ImageNet-1k dataset. It shows the top-1 and top-5 accuracy for several models, including a baseline ViT, ViT with Monarch, Hyena-ViT, M2-ViT, and Orchid. The table highlights Orchid’s improved performance compared to the baselines.

This table presents the accuracy results of different models on the Speech Commands dataset, a speech classification task. The models compared include a standard Transformer, Performer, CKConv, WaveGan-D, S4, S4 with block-diagonal matrices (S4-M2), and the proposed Orchid model. The table highlights Orchid’s competitive performance, achieving accuracy comparable to state-of-the-art models while potentially offering better scalability. The ‘X’ indicates that the Transformer model couldn’t fit within the available GPU memory.
Full paper#