↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for representing sound visually (spectrograms) produce unnatural-looking images. Conversely, using natural images as spectrograms creates unpleasant sounds. This creates a significant challenge for generating signals that are perceptually meaningful in both audio and visual domains, limiting creative applications such as “spectrogram art”.
This paper presents a novel zero-shot method that tackles this problem. It leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space, enabling the generation of spectrograms that are both visually appealing and acoustically natural. This is achieved through a multimodal denoising process that simultaneously considers both audio and image information, resulting in spectrograms that align well with both audio and image prompts. The approach is simple yet effective, demonstrating successful generation of “images that sound”.
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between audio and visual modalities, opening new avenues for research in multimodal generation and creative expression. It challenges the conventional view of spectrograms and introduces a novel approach to generate perceptually meaningful results that have both visual and audio appeal. This research inspires new artistic explorations and further investigation into cross-modal compositionality and shared latent spaces in diffusion models.
Visual Insights#

This figure shows the results of generating images that sound like the audio prompt provided. The top row shows colorized versions of the generated spectrograms. The middle row shows the grayscale spectrograms, which are generated by diffusion models and look like natural images. The bottom row shows the waveforms obtained by converting the spectrograms into audio using a pretrained vocoder. The figure provides two examples of different images and their corresponding sounds.
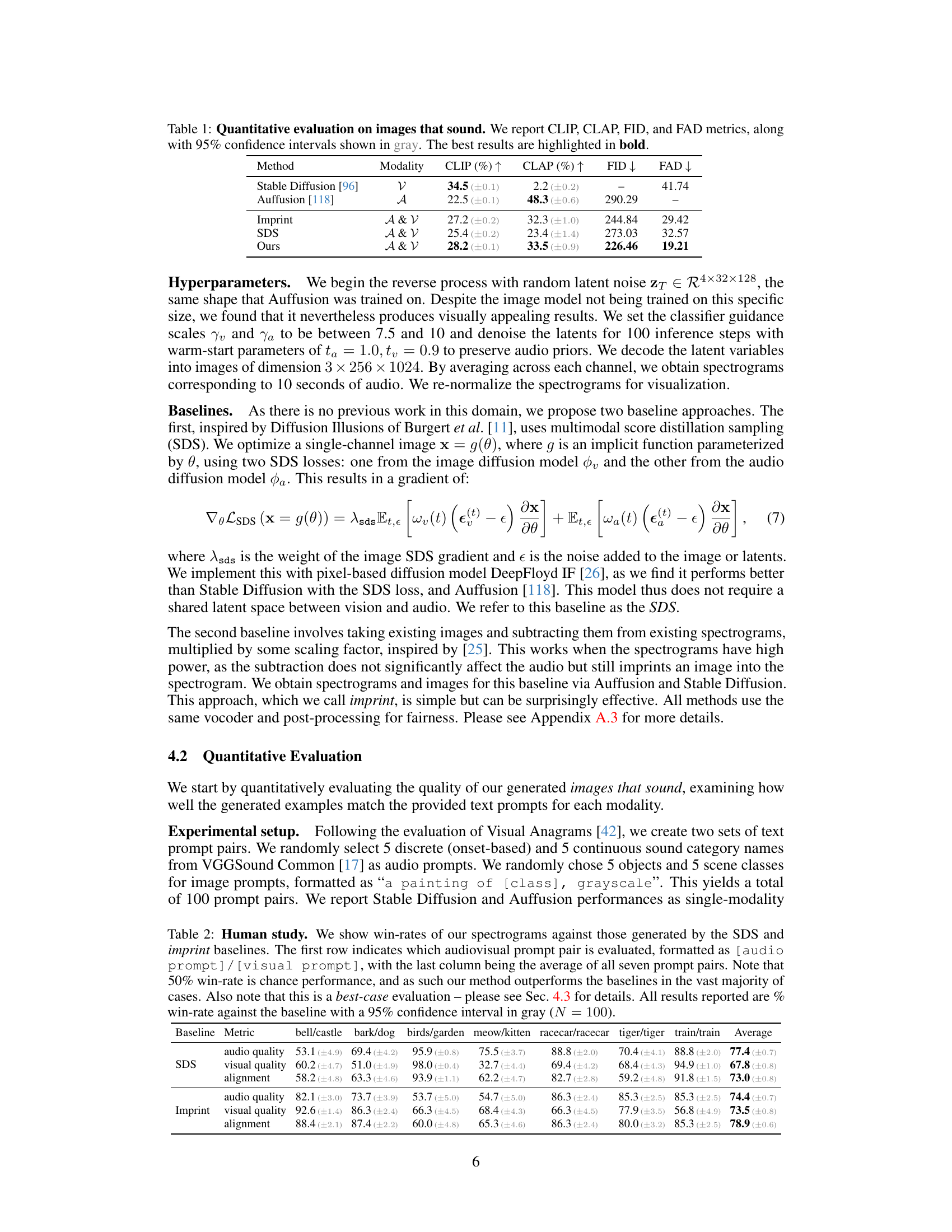
This table presents a quantitative comparison of different methods for generating ‘images that sound.’ It uses four metrics to evaluate the quality of the generated samples: CLIP score (measuring image-text alignment), CLAP score (measuring audio-text alignment), FID score (measuring image quality), and FAD score (measuring audio quality). The table compares the performance of the proposed method against three baselines: Stable Diffusion (image-only), Auffusion (audio-only), and two proposed alternative methods (Imprint and SDS). Confidence intervals are included to show statistical significance, and the best results are highlighted.
In-depth insights#
Multimodal Synthesis#
Multimodal synthesis, in the context of this research, refers to the generation of data that is simultaneously meaningful across multiple modalities. The paper focuses on creating spectrograms (audio) that also function as visually appealing images. The core challenge lies in bridging the gap between the vastly different statistical properties of natural images and spectrograms. The proposed approach cleverly leverages pre-trained text-to-image and text-to-spectrogram diffusion models operating within a shared latent space. By denoising latent representations with combined guidance from both audio and visual models, the method effectively synthesizes outputs that look and sound natural. This zero-shot approach bypasses the need for paired image-audio datasets, a significant advantage. However, limitations remain in generating high-fidelity audio alongside the desired visual appearance, particularly with discrete sounds. The success depends on careful prompt selection and the inherent properties of the underlying diffusion models. The study highlights the potential of this approach but acknowledges ongoing limitations and possible societal implications, particularly concerning the use of AI for visual-audio generation and steganography.
Diffusion Model Fusion#
Diffusion model fusion, a novel technique in generative modeling, involves combining the strengths of multiple diffusion models to generate superior results. This approach is particularly valuable when distinct models excel at different aspects of a generation task. For example, one model might master generating realistic textures while another specializes in precise object shapes. By carefully fusing these models, often in a shared latent space, we obtain outputs that surpass the capabilities of individual models. The key challenge lies in effective fusion strategies, as naive averaging or concatenation of outputs may lead to incoherent results. Successful fusion often requires sophisticated methods for aligning latent representations or weighting contributions from different models to achieve a harmonious balance. Understanding the underlying latent spaces and employing techniques like score distillation or weighted averaging are crucial for realizing the potential of diffusion model fusion. This approach offers exciting possibilities for multimodal generation, improving the realism and coherence of generated content across various modalities.
Zero-Shot Approach#
A zero-shot approach in the context of multimodal image and sound generation is highly valuable because it bypasses the need for paired image-audio datasets, which are often scarce and expensive to acquire. This significantly reduces the data requirements and simplifies the training process. The core idea is to leverage pre-trained models for separate modalities (e.g., text-to-image, text-to-spectrogram), operating in a shared latent space. By combining the noise estimates from these models during the reverse diffusion process, a sample likely under both image and audio distributions is generated, thus creating images that sound like the corresponding audio. The success of such an approach hinges on the statistical similarities between images and spectrograms, allowing for zero-shot cross-modal generation. However, it’s important to consider potential limitations, such as the quality of pre-trained models, the challenges in ensuring alignment between audio and visual features, and the possibility of artifacts or unnatural results.
Quantitative/Qualitative Results#
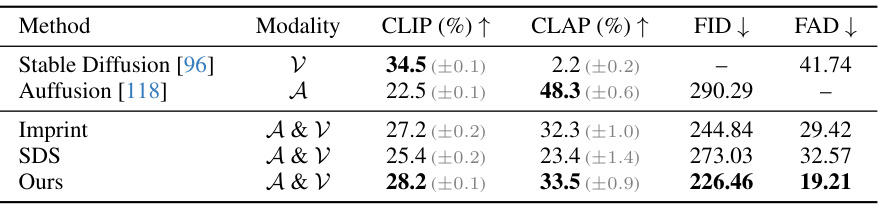
A robust research methodology necessitates a blend of quantitative and qualitative analyses to fully understand the impact of the study. Quantitative results, such as those derived from CLIP and CLAP scores, provide objective metrics to measure alignment between generated images and their corresponding audio and visual prompts. These numerical results offer a clear and easily comparable means to assess the efficacy of different models or approaches. However, qualitative analysis is crucial to providing deeper insights. Qualitative evaluation involves visual inspection of generated spectrograms, listening to their audio representations, and examining the degree to which both modalities align semantically and perceptually. By combining these analyses, researchers can paint a comprehensive picture of the effectiveness of their generated “images that sound”, revealing both the strengths and shortcomings of their approach. Human studies complement these analyses by incorporating human perception, offering valuable feedback on the overall quality and aesthetic appeal of the results, thereby broadening the scope of the evaluation.
Future Research#
Future research directions stemming from this work on composing images and sounds could explore several promising avenues. Improving the quality and realism of generated audio is paramount; current diffusion models for audio often lag behind those for images. Investigating alternative model architectures, such as those incorporating more sophisticated temporal modeling or incorporating learned priors from audio-visual datasets could enhance sound quality. Exploring novel approaches to multimodal composition is also crucial. While this paper’s approach of denoising using weighted average of audio and image noise is effective, other methods like score distillation or latent space manipulation may yield superior results. Furthermore, extending the framework to other modalities beyond audio and images is a natural progression. Video and haptic feedback could be integrated to create truly immersive and multisensory experiences. Lastly, a thorough investigation of the ethical implications associated with generating realistic audio-visual content is warranted; this includes considering potential for misuse in generating deepfakes or other forms of deception.
More visual insights#
More on figures

This figure compares three types of images: grayscale images generated by Stable Diffusion (a text-to-image model), log-mel spectrograms generated by Auffusion (a text-to-spectrogram model), and the authors’ generated ‘images that sound’. The comparison aims to highlight how the authors’ method produces spectrograms that visually resemble natural images while also sounding like natural audio when played as spectrograms. Each row shows an example image and its corresponding spectrogram from the two different models and the proposed method. The goal is to illustrate that the authors’ approach is successful in bridging the gap between the visual appearance of typical images and the acoustic properties of natural sounds encoded in spectrograms.

This figure illustrates the process of composing audio and visual diffusion models to generate a visual spectrogram that can be both seen as an image and heard as a sound. It shows how noisy latent data (zt) is denoised iteratively using information from both an image diffusion model (guided by a visual text prompt) and an audio diffusion model (guided by an audio text prompt). The noise estimates from each model are combined through weighted averaging to create a multimodal noise estimate. This estimate is then used to iteratively refine the latent representation until a clean latent (z0) is obtained. Finally, this clean latent is decoded into a spectrogram, which can be converted into a waveform using a vocoder, resulting in the final output: a visual spectrogram that sounds like natural audio and looks like a natural image.

This figure illustrates the process of generating a visual spectrogram using a combined approach of image and audio diffusion models. A noisy latent representation (zt) is denoised iteratively using information from both models, guided by separate text prompts for the desired visual and audio aspects. The weighted average of the noise estimates from each model is used to create a multimodal noise estimate, which then facilitates the denoising process in a shared latent space. The final clean latent representation (z0) is decoded into a spectrogram, which can then be converted into an audio waveform using a pre-trained vocoder (or alternative methods). The diagram clearly shows the model’s workflow and how the visual and audio information are combined during the generation process.

This figure showcases the core concept of the paper: generating images that also function as spectrograms (visual representations of sound). The top row displays colorized versions of the generated spectrograms, enhancing their visual appeal. The middle row presents the grayscale spectrograms themselves, which resemble natural images. The bottom row shows the waveforms (actual sound representation) derived from these spectrograms using a pretrained vocoder. The examples illustrate the successful synthesis of images that both look visually appealing and sound natural when played as audio.
This figure illustrates the process of generating a visual spectrogram using two pre-trained diffusion models: one for images and one for audio. Both models operate in a shared latent space. The process starts with a noisy latent representation (zt). Separate noise estimates are generated using both the visual and audio models, guided by their respective text prompts. These noise estimates are combined using a weighted average to create a multimodal noise estimate. This combined estimate is then used in an iterative denoising process to refine the latent representation, ultimately resulting in a clean latent (z0). This latent is then decoded into a spectrogram, which can be converted to a waveform using a vocoder or colorized for better visual appeal.

This figure illustrates the method used to generate images that sound. It shows how the visual and audio diffusion models are combined to generate a visual spectrogram by denoising a noisy latent. The process uses text prompts to guide both diffusion models. The resulting latent is then decoded into a spectrogram, which is converted to a waveform using a vocoder. The figure clearly depicts the multimodal nature of the approach, combining visual and audio information.

This figure compares three types of image generation results side-by-side. The left column shows grayscale images generated by Stable Diffusion, a standard text-to-image model. The middle column displays log-mel spectrograms (visual representations of sound) produced by Auffusion, a text-to-spectrogram model. The right column shows the authors’ novel approach, combining image and spectrogram generation to create images that also function as natural-sounding spectrograms. Each row represents a different image/sound pair, demonstrating how the model generates visually appealing spectrograms that also correspond to natural audio.

This figure presents a qualitative comparison of the proposed method for generating images that sound with two baselines: imprint and SDS. For each of three pairs of image and sound prompts, four generated spectrograms are shown. The top row shows the results from the proposed method. The middle row shows the results from the imprint baseline. The bottom row shows the results from the SDS baseline. Each spectrogram is shown alongside its corresponding waveform. Visual inspection reveals the differences in quality and alignment between the generated images and their corresponding audio. The results demonstrate that the proposed method produces higher quality samples that better match both image and audio prompts compared to the baselines.

This figure shows examples generated by the proposed method using various combinations of random image and audio prompts. The results illustrate the model’s ability to generate spectrograms that attempt to fulfill both the visual and audio descriptions, but also highlights scenarios where the model struggles to balance both successfully (failure cases). The figure’s purpose is to demonstrate both successes and failures of the model.
This figure illustrates the process of generating images that sound using a combination of image and audio diffusion models. A noisy latent representation is iteratively denoised using estimates from both models, guided by separate text prompts for the visual and audio aspects. The final denoised latent is decoded into a spectrogram, which can then be converted to an audio waveform using a vocoder.
More on tables

This table presents a quantitative comparison of different methods for generating ‘images that sound.’ It uses four metrics: CLIP (evaluates image-text alignment), CLAP (evaluates audio-text alignment), FID (Fréchet Inception Distance, measures image quality), and FAD (Fréchet Audio Distance, measures audio quality). Results are shown for three methods: Stable Diffusion (image-only), Auffusion (audio-only), and the proposed method (‘Ours’). Confidence intervals are included to indicate the uncertainty in the results. The best performance for each metric is highlighted in bold, indicating the proposed approach’s effectiveness in generating high-quality images and sounds.

This table presents a quantitative comparison of different methods for generating images that sound, using four metrics: CLIP (image-text alignment), CLAP (audio-text alignment), FID (image quality), and FAD (audio quality). The results are shown for four methods: Stable Diffusion (image-only), Auffusion (audio-only), an imprint baseline (a simple subtraction method), and score distillation sampling (SDS) baseline (a multimodal score-based approach) and the authors’ proposed method. 95% confidence intervals are provided, and the best result for each metric is shown in bold. The table highlights the superior performance of the proposed method in terms of generating images that sound high quality and that align well with both the image and audio prompts.

This table presents a quantitative comparison of different methods for generating ‘images that sound.’ It evaluates the quality of generated samples using four metrics: CLIP (image-text alignment), CLAP (audio-text alignment), FID (Fréchet Inception Distance, image quality), and FAD (Fréchet Audio Distance, audio quality). The table includes results for three methods: Stable Diffusion (image-only), Auffusion (audio-only), and the proposed method (‘Ours’), and two baselines (Imprint and SDS). The 95% confidence intervals for each metric are shown in gray, and the best result for each metric is bolded. This allows for comparison of the quality and alignment of image and sound generation across the different models.

This table presents a quantitative comparison of different methods for generating ‘images that sound.’ It uses four metrics: CLIP (image-text alignment), CLAP (audio-text alignment), FID (Fréchet Inception Distance, image quality), and FAD (Fréchet Audio Distance, audio quality). The results for three methods are shown: Stable Diffusion (image-only), Auffusion (audio-only), and the proposed method (multimodal). Confidence intervals are given to show statistical significance, and the best-performing method for each metric is highlighted.
Full paper#