↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Parameter-efficient fine-tuning (PEFT) methods like sparse tuning improve model adaptation to downstream tasks by only adjusting a small subset of parameters. However, sparse tuning suffers from high memory usage due to storing the entire weight matrix and its sparse indexes. This limits its applicability to large-scale pre-trained models.
To address this, the paper introduces SNELL (Sparse tuning with kerNELized LoRA). SNELL decomposes the tunable matrix into two low-rank matrices and employs a competition-based sparsification mechanism to avoid storing indexes. It further enhances LoRA by using nonlinear kernel functions, increasing the rank of the merged matrix to improve model adaptability and performance. Experiments show that SNELL achieves state-of-the-art results with significantly lower memory consumption, enabling the application of sparse tuning to larger models.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the high memory consumption problem in sparse tuning, a parameter-efficient fine-tuning method crucial for adapting large-scale pre-trained models. SNELL offers a solution that achieves state-of-the-art performance with significantly lower memory usage, making it highly relevant to researchers working with large models and limited resources. The proposed competition-based sparsification mechanism and the kernelized LoRA approach provide new avenues for memory-efficient model adaptation.
Visual Insights#
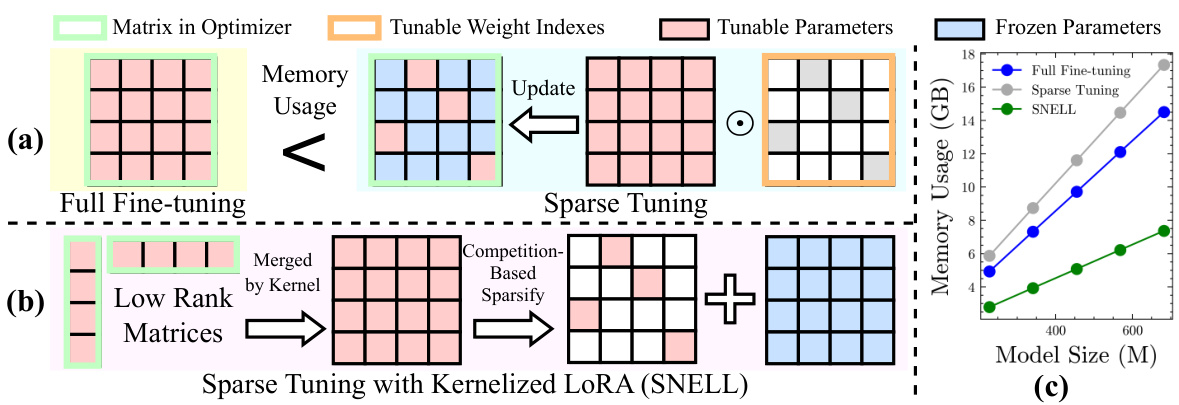
This figure compares the memory usage of three different methods for fine-tuning neural networks: full fine-tuning, sparse tuning, and the proposed SNELL method. Panel (a) illustrates that full fine-tuning and sparse tuning both store the entire weight matrix in the optimizer, leading to high memory usage, while sparse tuning adds the overhead of storing indices of tunable weights. In contrast, panel (b) shows that SNELL only stores low-rank matrices, significantly reducing memory usage. Finally, panel (c) provides a quantitative comparison of memory usage across models of varying sizes, demonstrating that SNELL consistently achieves the lowest memory footprint.
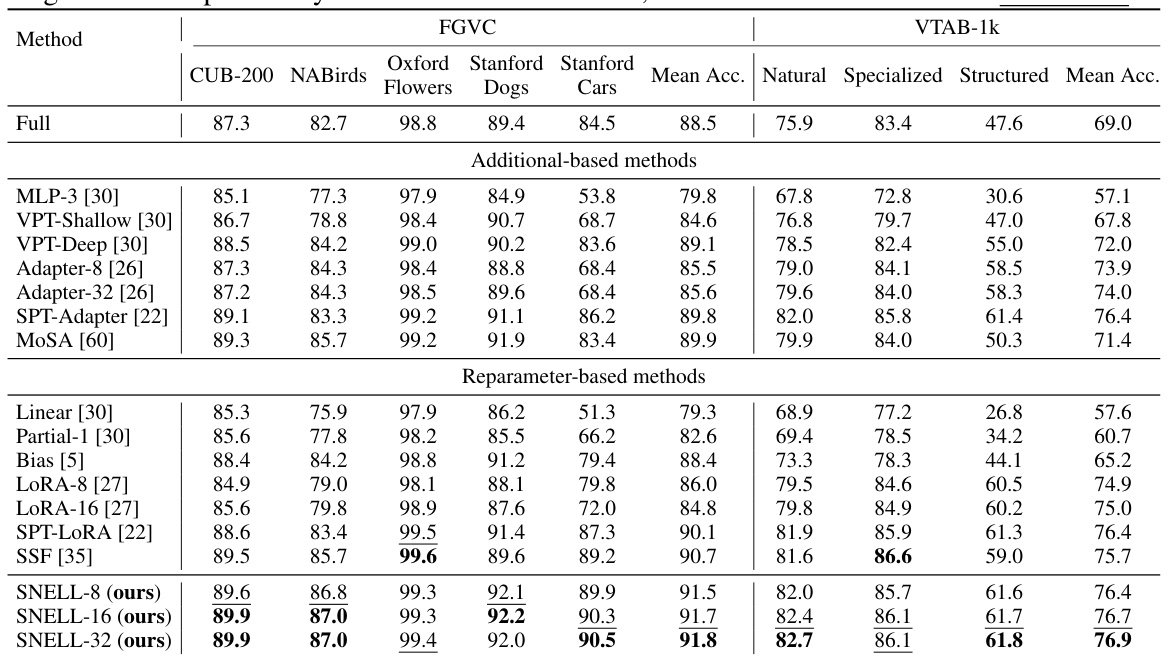
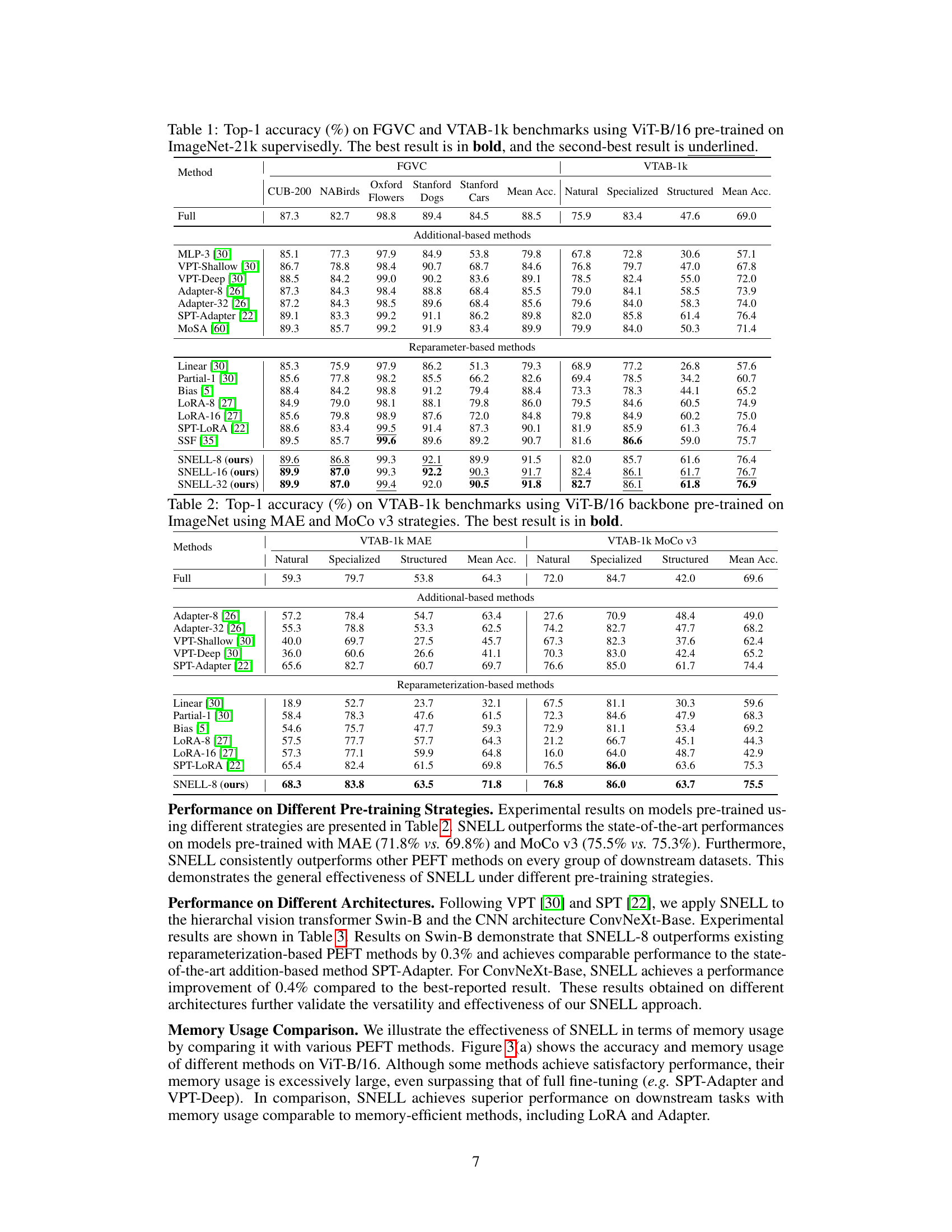
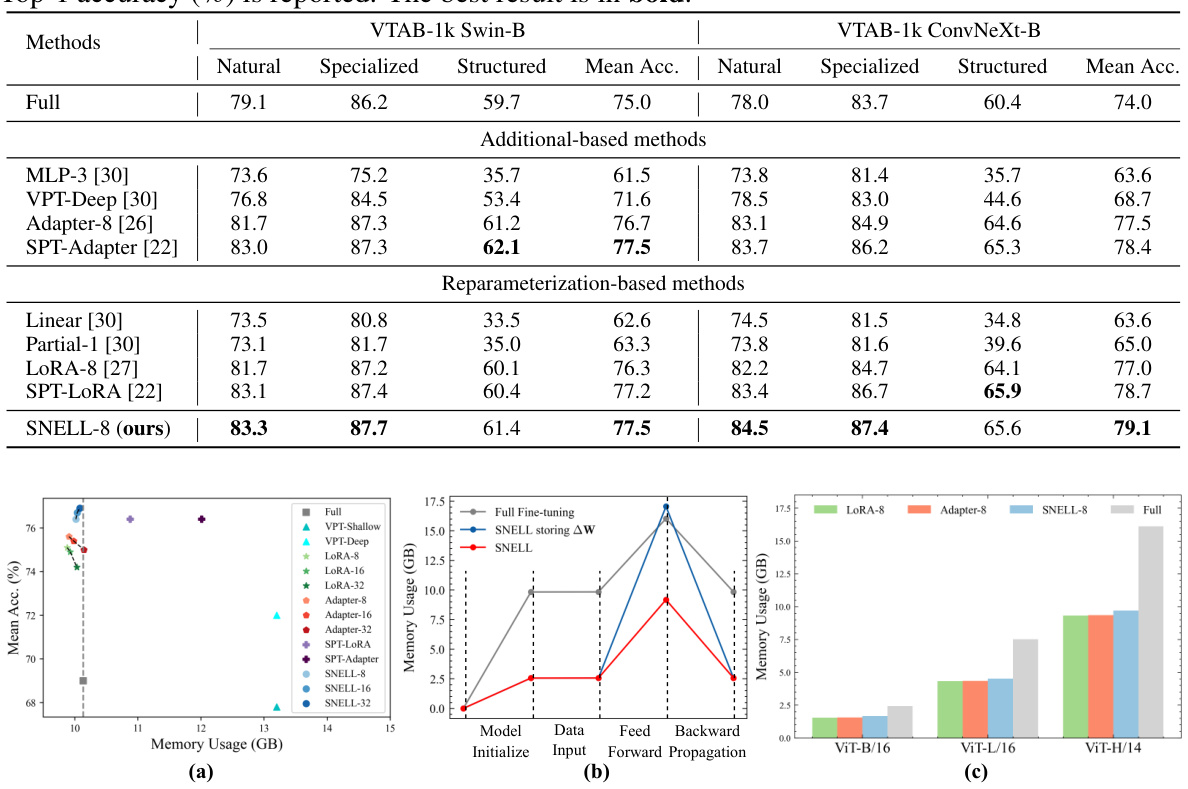
This table presents a comparison of the performance of various parameter-efficient fine-tuning (PEFT) methods on two benchmark datasets: FGVC (fine-grained visual categorization) and VTAB-1k (a large-scale transfer learning benchmark). The methods are compared based on their top-1 accuracy across multiple downstream tasks within each benchmark. The table highlights the superior performance of the proposed method (SNELL) compared to existing state-of-the-art PEFT approaches.
In-depth insights#
Sparse Tuning Boost#
Sparse tuning, a parameter-efficient fine-tuning method, aims to improve model performance on downstream tasks by updating only a small subset of the most relevant parameters. A ‘Sparse Tuning Boost’ technique would likely focus on enhancing the effectiveness and efficiency of this approach. This could involve novel methods for identifying the optimal sparse subset of parameters, perhaps leveraging advanced sparsity-inducing regularization techniques or more sophisticated feature selection methods. Another key area would be to improve the optimization process, perhaps by employing advanced optimization algorithms specifically designed for sparse updates or developing novel training strategies that mitigate the potential instability of updating only a small subset of parameters. A crucial aspect of a ‘Sparse Tuning Boost’ would be to address the memory overhead often associated with sparse tuning methods, which often requires storing the full weight matrix despite only updating a small fraction of its parameters. Solutions may include low-rank matrix approximations or clever indexing techniques. Finally, a successful ‘Sparse Tuning Boost’ should demonstrate substantial improvements in performance on various benchmark datasets, while simultaneously exhibiting significantly reduced memory consumption compared to existing sparse tuning methods. The overall goal is to make sparse tuning more practical for larger models and more complex tasks.
SNELL: Kernel LoRA#
SNELL, integrating Kernel methods with Low-Rank Adaptation (LoRA), offers a novel approach to parameter-efficient fine-tuning. It addresses the high memory consumption of sparse tuning by decomposing the tunable matrix into two smaller, low-rank matrices. This significantly reduces storage needs during optimization. Further enhancing efficiency, SNELL employs a competition-based sparsification mechanism, eliminating the need to store weight indexes. The core innovation lies in leveraging kernel functions, specifically a piecewise linear kernel, to merge the low-rank matrices. This increases the rank of the resulting matrix, boosting the model’s capacity to adapt to downstream tasks without significantly increasing parameter count. SNELL achieves state-of-the-art results on various vision tasks, demonstrating its effectiveness and memory efficiency compared to existing parameter-efficient fine-tuning methods.
Competition Sparsity#
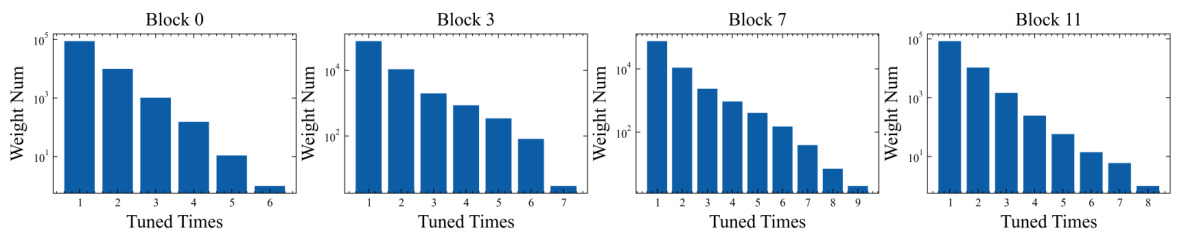
Competition-based sparsity is a novel approach to sparsification in neural networks that mimics biological processes, eliminating the need to store explicit weight indexes. Instead of pre-selecting weights, it leverages a competition mechanism where weights with larger magnitudes (representing stronger contributions) survive, while smaller weights are pruned. This dynamic, end-to-end approach allows for efficient memory usage and task-relevant weight selection, adapting to downstream tasks more effectively than pre-defined sparsity patterns. The method’s elegance lies in its simplicity and efficiency, enabling high performance with reduced memory footprint, particularly beneficial for large-scale models. The competition mechanism intrinsically handles the sparsity constraint, making it a compelling alternative to existing methods that require extra memory to track the selection indexes. Future research could explore different competition functions and their impact on performance and model robustness.
Memory Efficiency#
The research paper significantly emphasizes memory efficiency as a crucial factor in parameter-efficient fine-tuning (PEFT) of large-scale models. Existing sparse tuning methods, while improving performance, suffer from high memory consumption due to storing the entire weight matrix and associated indices. The proposed SNELL method directly addresses this limitation by employing kernelized LoRA, decomposing the tunable matrix into low-rank matrices, thus reducing storage needs. Further memory savings are achieved through a novel competition-based sparsification mechanism that eliminates the need for storing tunable weight indices. Experiments demonstrate that SNELL achieves state-of-the-art performance with significantly lower memory usage than existing methods, particularly beneficial for deploying PEFT on large models where memory constraints are often limiting. The kernel trick is also leveraged to enhance the ability of the model to adapt to downstream tasks by increasing the rank of the merged adaptation matrix, further contributing to both efficiency and improved performance. This methodology makes sparse tuning practical for resource-constrained settings.
Future of PEFT#
The future of Parameter-Efficient Fine-Tuning (PEFT) is bright, driven by the need for efficient adaptation of massive language models. Further research into novel PEFT techniques that minimize memory usage and computational overhead is crucial. Exploring advanced kernel methods and optimization strategies could unlock greater potential for sparse tuning. Addressing limitations in existing PEFT methods, such as the trade-off between performance and efficiency, requires investigation. A key focus will be on developing PEFT methods that scale effectively to increasingly larger models while maintaining high performance and low memory usage. Robust methods for selecting and optimizing the subset of parameters to be tuned will be a central research topic. Finally, the future will likely see more sophisticated approaches combining PEFT with other techniques, such as quantization and pruning, to achieve optimal efficiency and resource utilization.
More visual insights#
More on figures
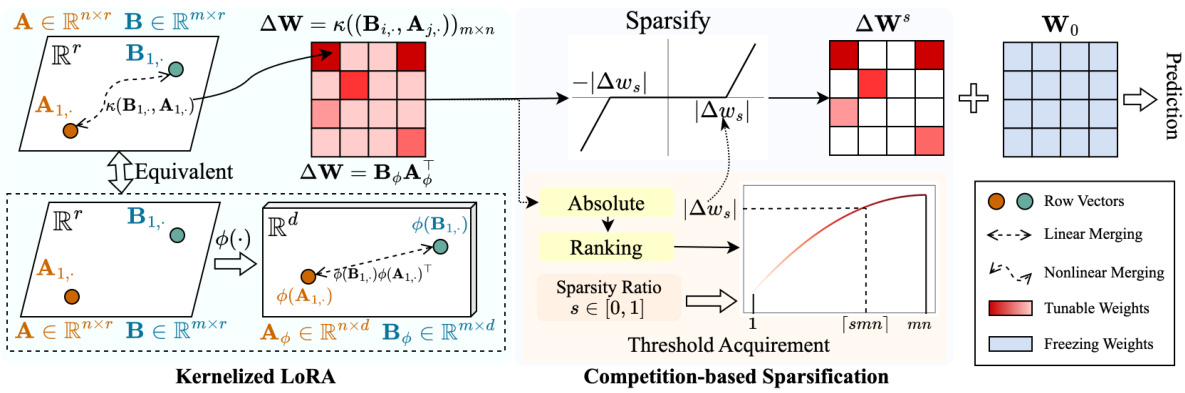
This figure illustrates the SNELL (Sparse tuning with kerNELized LoRA) framework. The left side shows the kernelized LoRA which merges two low-rank matrices using a nonlinear kernel function. This process is depicted as mapping the low-rank matrices to a higher dimensional space, where the inner product of the mappings is the high rank matrix. The right side shows the competition-based sparsification, which is a mechanism to sparsify the weights of the merged high-rank matrix based on the absolute values of the weights without storing extra index. Weights with smaller absolute values will be zeroed out according to the sparsity ratio (s).

This figure illustrates the SNELL framework. The left side shows how two low-rank matrices (A and B) are merged using a nonlinear kernel function, resulting in a higher-rank adaptation matrix. This is done to enhance the model’s ability to adapt to downstream tasks by increasing the expressiveness of the sparse tuning. The right side details the competition-based sparsification mechanism. This mechanism eliminates the need to store tunable weight indexes by promoting competition among weights, causing the weights with small absolute values to be zeroed out based on a specified sparsity ratio (s). This reduces memory usage while maintaining effectiveness.
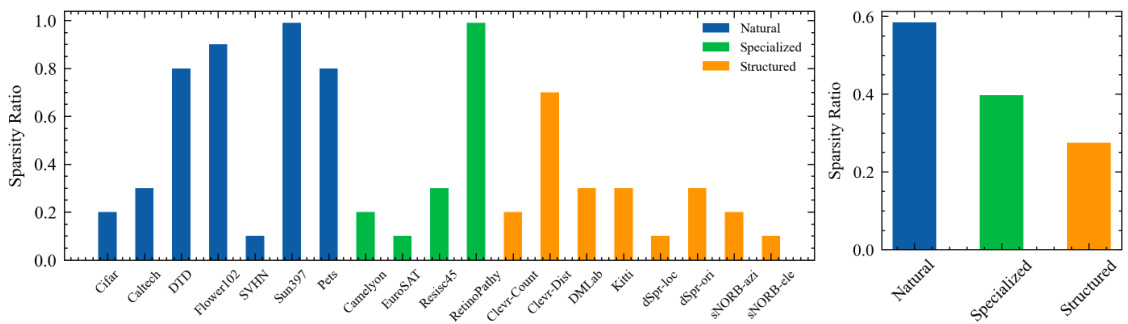
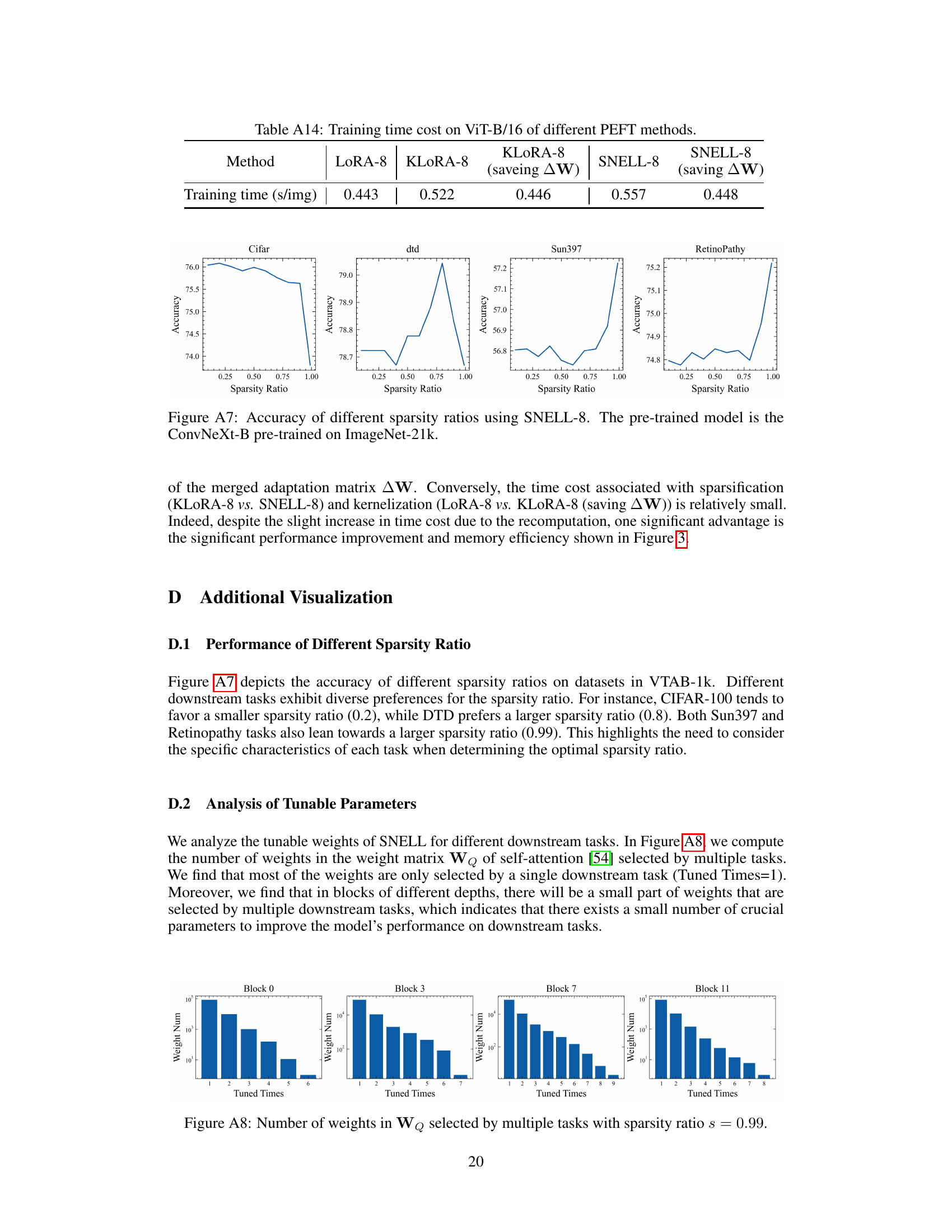
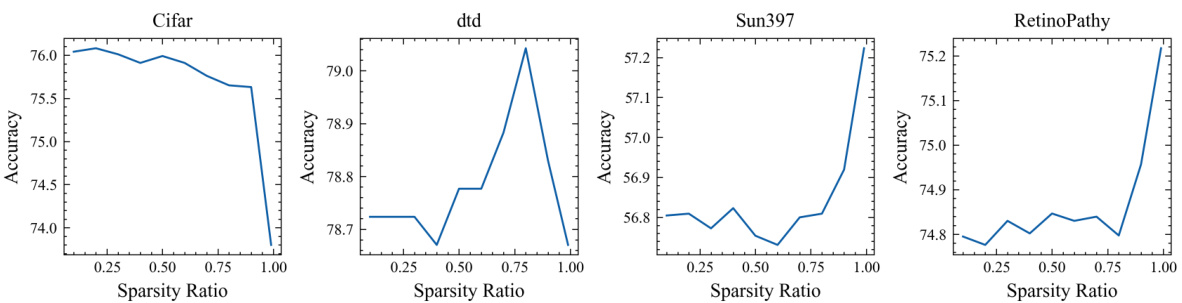
This figure visualizes the optimal sparsity ratios determined for SNELL-8 across various downstream tasks within the VTAB-1k benchmark. The left panel shows the optimal sparsity ratio for each individual task, highlighting the variability in the optimal setting depending on the specific characteristics of each task. The right panel shows the average optimal sparsity ratio for the three groups of tasks within VTAB-1k (Natural, Specialized, and Structured). This aggregated view reveals trends in optimal sparsity across different task types within the dataset. The pre-trained model used was ConvNeXt-B, pre-trained on ImageNet-21k.
This figure compares the memory usage of different sparse tuning methods. (a) illustrates that traditional sparse tuning methods store the entire weight matrix and a binary mask indicating the tunable weights, resulting in high memory consumption. (b) shows the proposed SNELL framework, which only stores low-rank matrices in the optimizer, significantly reducing memory usage. (c) provides a quantitative comparison of memory usage across models with varying depths, demonstrating the scalability and efficiency of SNELL.
This figure illustrates the SNELL framework, which consists of two main stages: kernelized LoRA and competition-based sparsification. The left side shows how two low-rank matrices (A and B) are merged using a nonlinear kernel function, effectively increasing the rank of the resulting adaptation matrix (ΔW). This allows for a more expressive sparse tuning compared to standard LoRA. The right side depicts the competition-based sparsification process, which dynamically prunes less important weights based on a sparsity ratio (s), avoiding the need to explicitly store tunable weight indexes and thus reducing memory usage.
More on tables
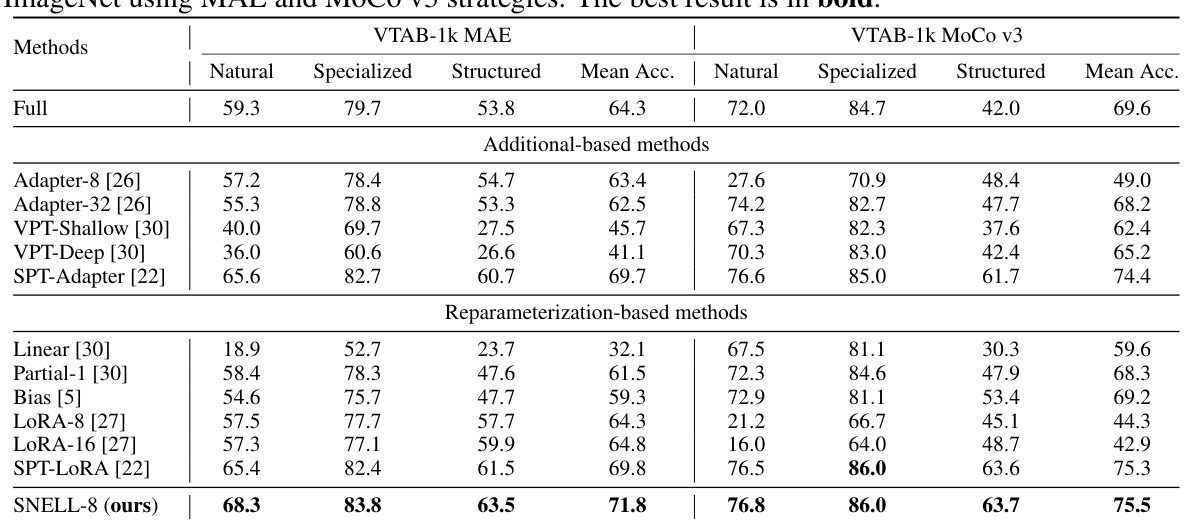
This table presents the performance comparison of different parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark. The models are pre-trained on ImageNet using two different self-supervised learning strategies: Masked Autoencoders (MAE) and Momentum Contrast (MoCo v3). The table shows the top-1 accuracy achieved by each method on three subsets of VTAB-1k tasks (Natural, Specialized, Structured), as well as the average accuracy across all tasks. The best result for each metric is highlighted in bold.
This table presents the comparison of different parameter-efficient fine-tuning (PEFT) methods on two benchmark datasets, FGVC and VTAB-1k, using a ViT-B/16 model pre-trained on ImageNet-21k. It compares methods based on whether they use addition-based or reparameterization-based approaches, along with various sparsity and rank parameters. The table highlights the superior performance of the proposed SNELL method compared to existing state-of-the-art methods.

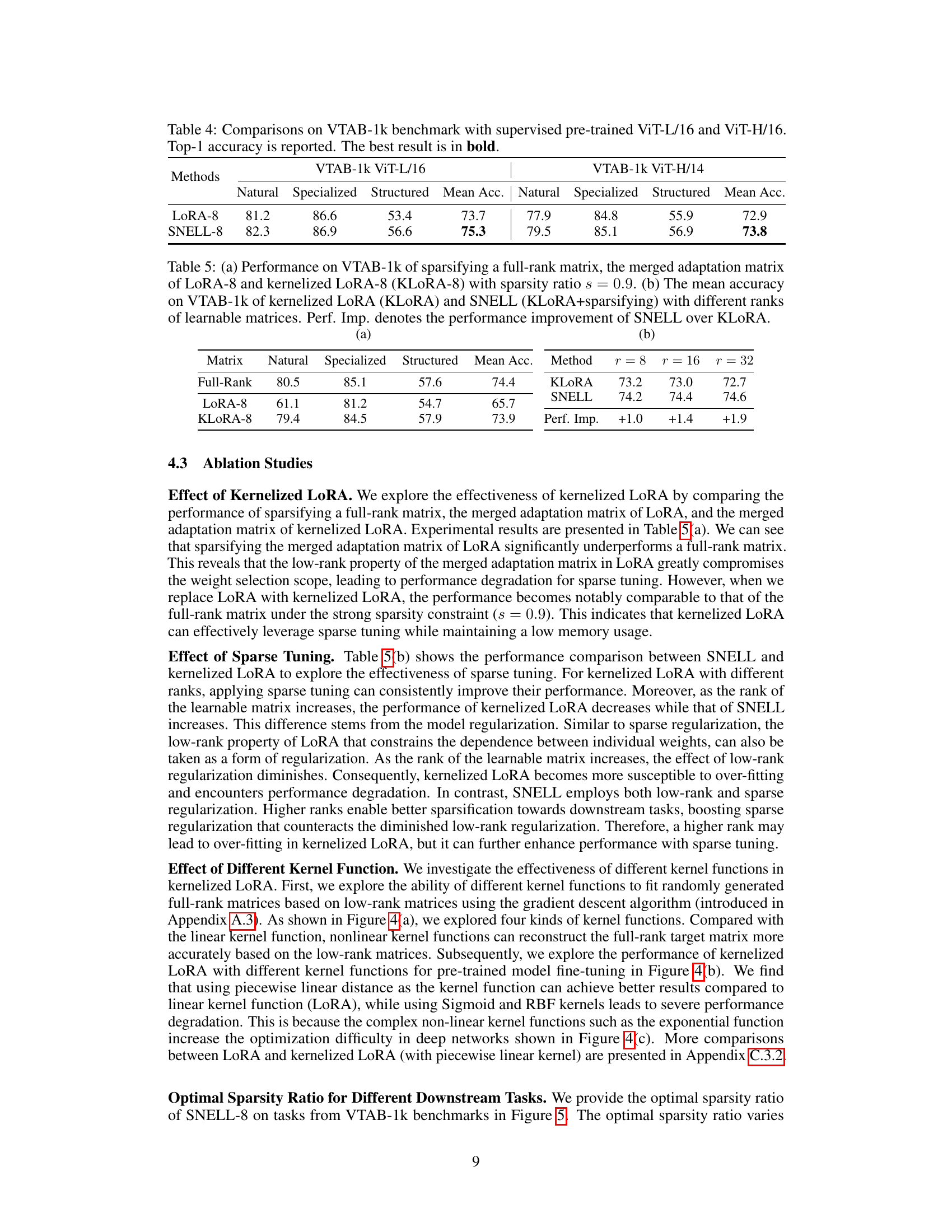
This table compares the performance of LoRA-8 and SNELL-8 on the VTAB-1k benchmark using two different large vision transformer backbones: ViT-L/16 and ViT-H/14. The results are presented in terms of top-1 accuracy, broken down by three categories of tasks within the VTAB-1k benchmark: Natural, Specialized, and Structured. The table highlights that SNELL-8 achieves superior performance compared to LoRA-8 on both backbones across all categories and overall mean accuracy.

This table presents a comparison of different sparsification methods’ performance on the VTAB-1k benchmark. Part (a) compares sparsifying a full-rank matrix, LoRA-8’s merged adaptation matrix, and kernelized LoRA-8’s merged matrix, all with a sparsity ratio of 0.9. Part (b) compares the mean accuracy across VTAB-1k of kernelized LoRA and SNELL using different ranks (8, 16, and 32) for the learnable matrices, highlighting the performance improvement achieved by SNELL over kernelized LoRA.
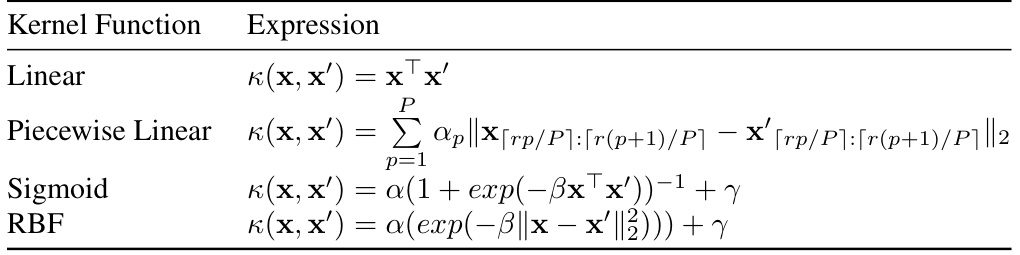
This table presents the results of various parameter-efficient fine-tuning (PEFT) methods on two benchmark datasets: FGVC (fine-grained visual categorization) and VTAB-1k (a large-scale transfer learning benchmark). The methods are compared using the top-1 accuracy metric. The table is organized to show the performance of different approaches (addition-based and reparameterization-based methods including the proposed SNELL approach) on the benchmarks. The best and second best performance numbers are highlighted.
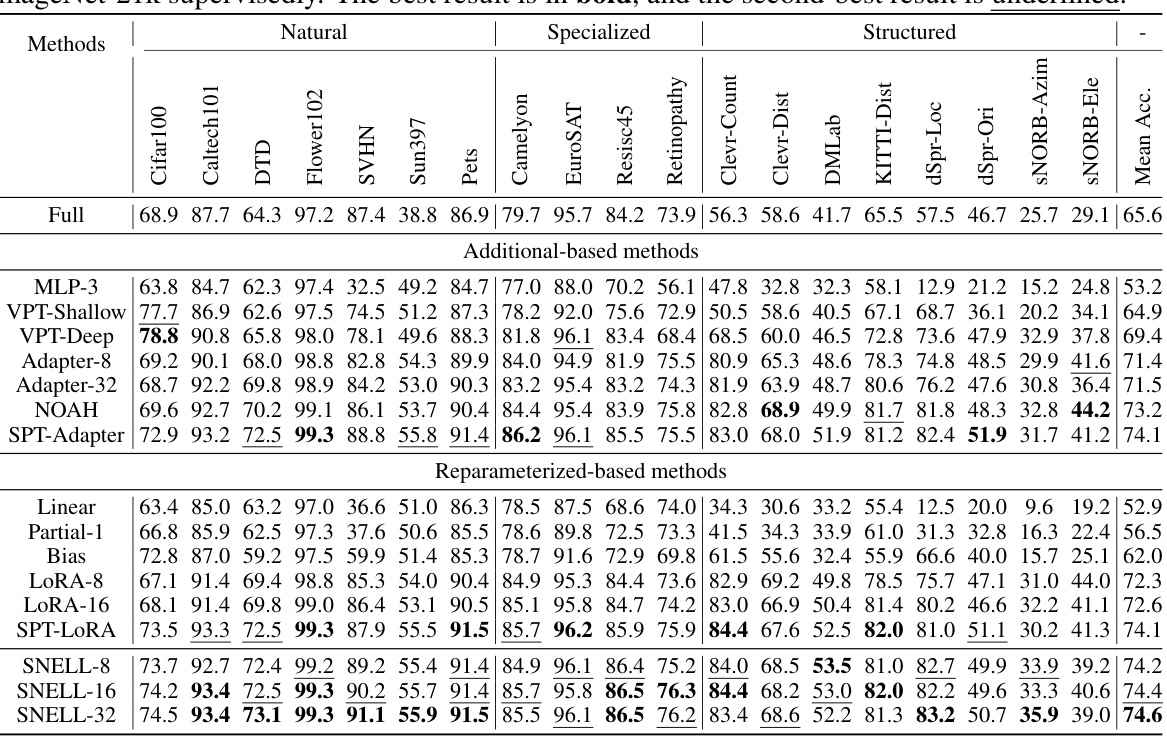
This table presents the Top-1 accuracy results achieved by various methods (including the proposed SNELL) on two benchmark datasets: FGVC (fine-grained visual categorization) and VTAB-1k (a large-scale transfer learning benchmark). The results are broken down by specific tasks within each benchmark and show the performance of different parameter-efficient fine-tuning methods, including addition-based and reparameterization-based approaches. The ViT-B/16 model, pre-trained on ImageNet-21k, is used as the backbone for all methods. The best and second-best performing methods for each task are highlighted.

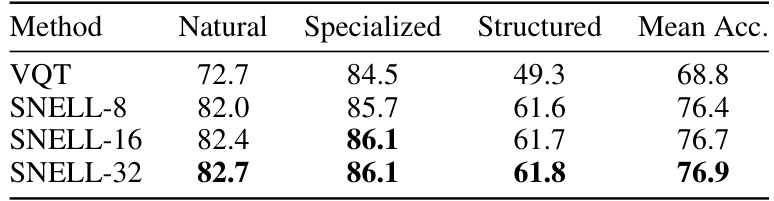
This table presents a comparison of the top-1 accuracy achieved by various methods on two benchmark datasets: FGVC (fine-grained visual categorization) and VTAB-1k (a large-scale transfer learning benchmark). The methods are categorized into addition-based and reparameterization-based parameter-efficient fine-tuning (PEFT) approaches. Results are shown for different variations of each method (e.g., different rank values for LoRA). The table highlights the superior performance of the proposed SNELL method compared to existing state-of-the-art methods while maintaining low memory usage.
This table presents the performance of different methods on the VTAB-1k benchmark. The models used are Vision Transformer backbones (ViT-B/16) pre-trained using Masked Autoencoders (MAE) and Momentum Contrast (MoCo v3) strategies. The results are broken down by three groups of tasks within VTAB-1k: Natural, Specialized, and Structured, along with the overall mean accuracy. The best performing method for each task group and the overall mean is highlighted in bold.

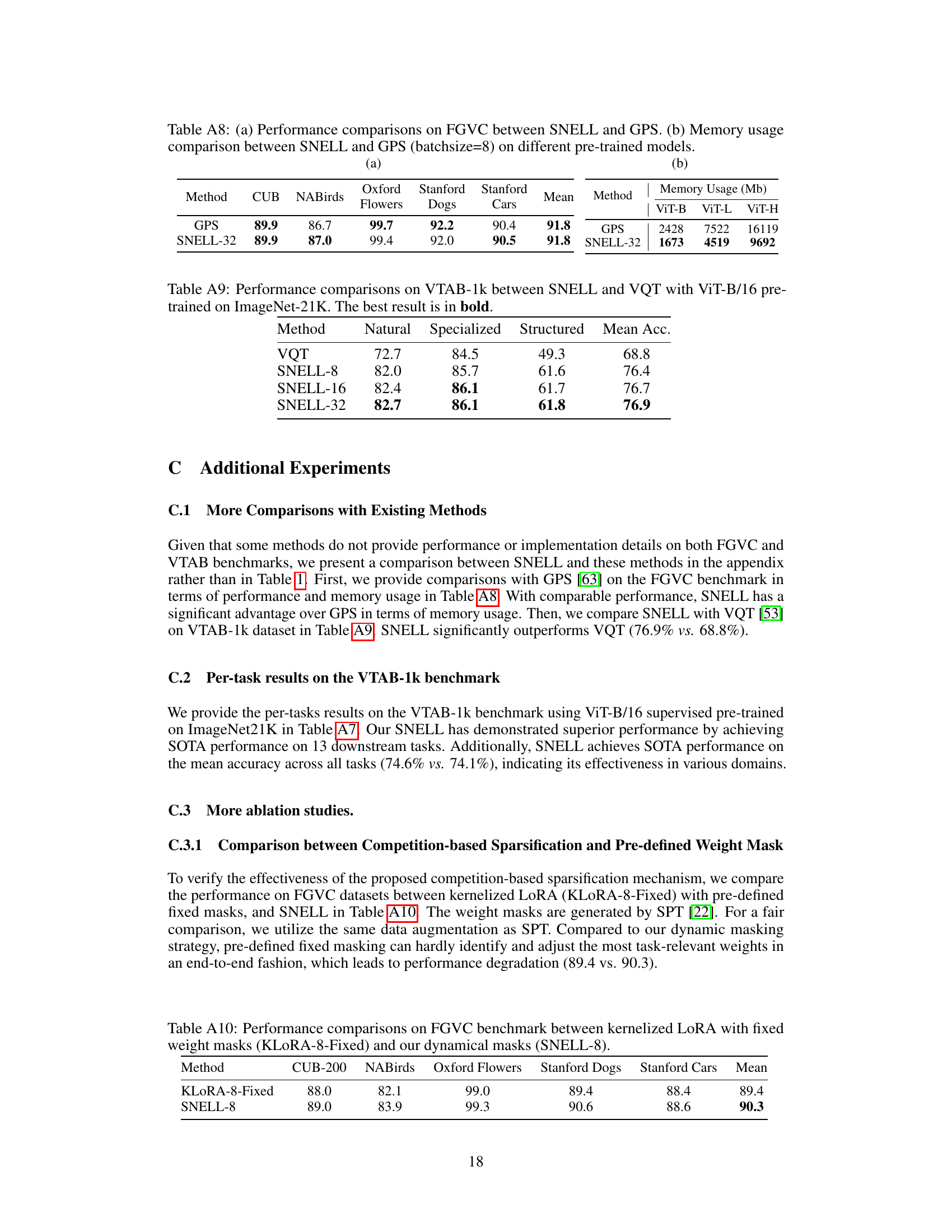
This table compares the performance of kernelized LoRA with fixed weight masks (KLORA-8-Fixed) and SNELL-8 on the FGVC benchmark. KLORA-8-Fixed uses pre-defined weight masks generated by SPT [22], while SNELL-8 uses a dynamic masking strategy. The results show that SNELL-8 outperforms KLORA-8-Fixed across all five FGVC tasks, indicating the superiority of the dynamic masking approach.
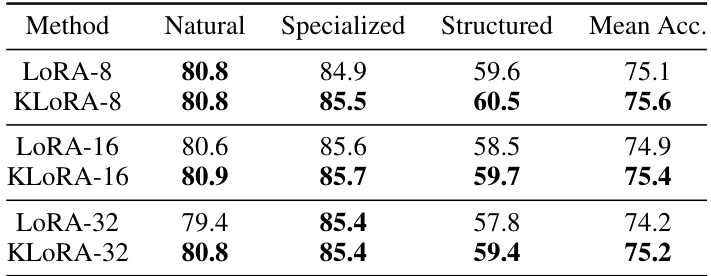
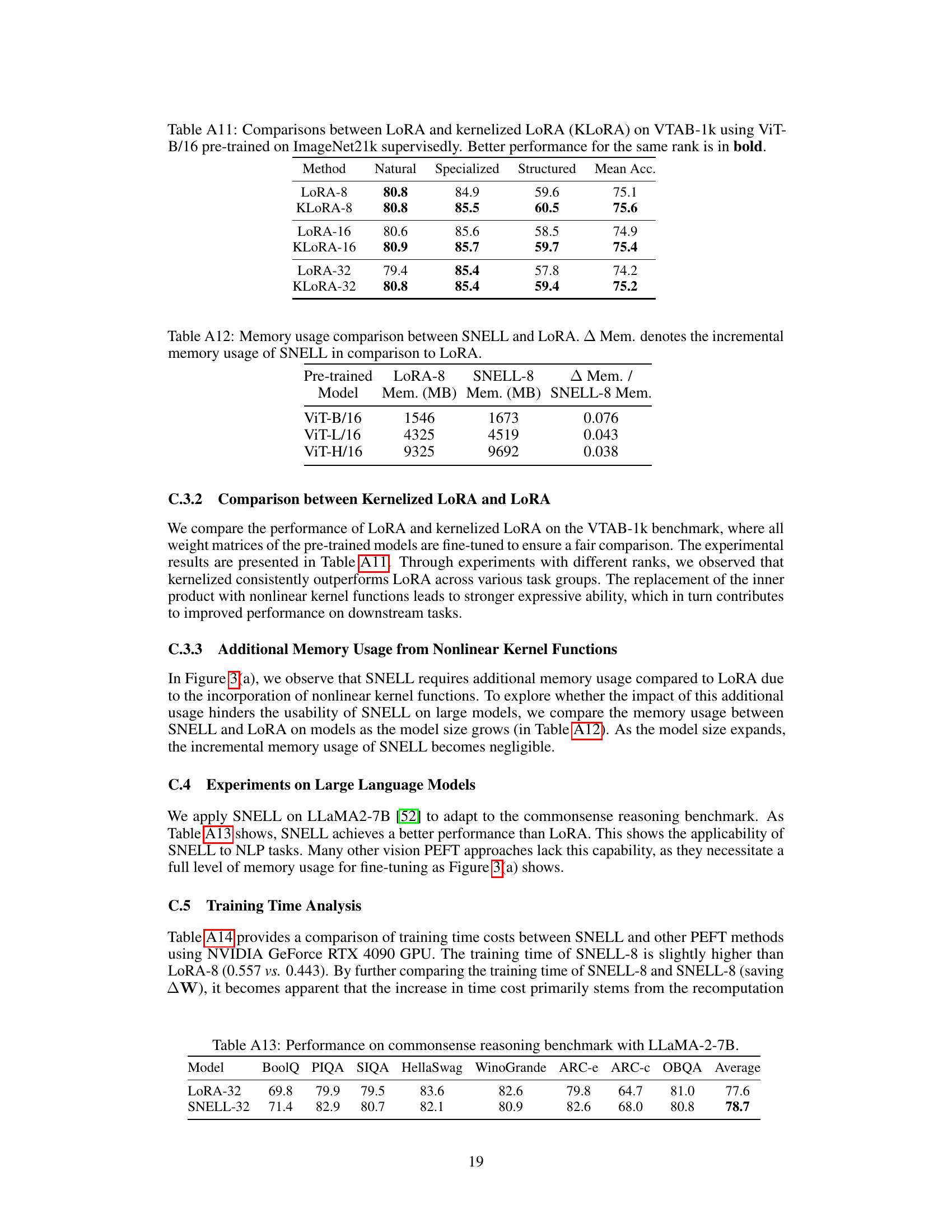
This table compares the performance of LoRA and kernelized LoRA on the VTAB-1k benchmark. Both methods use the same pre-trained ViT-B/16 model on ImageNet-21k. The table shows the mean accuracy across different task categories (Natural, Specialized, Structured) for different rank sizes (8, 16, and 32) for both LoRA and kernelized LoRA. The results highlight the performance improvement achieved by using kernelized LoRA compared to the standard LoRA method for each rank size.
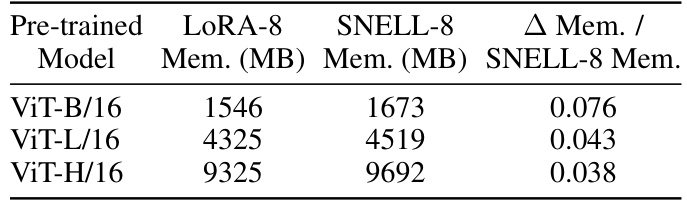
This table compares the memory usage of SNELL and LoRA for three different pre-trained vision transformer models (ViT-B/16, ViT-L/16, and ViT-H/16). It shows the memory consumption in MB for both LoRA-8 and SNELL-8, and calculates the percentage increase in memory usage for SNELL-8 relative to LoRA-8. The results indicate that while SNELL-8 uses slightly more memory than LoRA-8, the increase is minimal, demonstrating the memory efficiency of SNELL.

This table presents the results of the experiments conducted on the commonsense reasoning benchmark using the LLaMA-2-7B model. The table compares the performance of LoRA-32 and SNELL-32 on various sub-tasks within the benchmark, providing the accuracy scores for each method on each sub-task, and finally the average accuracy across all sub-tasks. This demonstrates the superiority of SNELL-32 over LoRA-32 in commonsense reasoning tasks.

This table compares the training time (seconds per image) of different parameter-efficient fine-tuning (PEFT) methods on a ViT-B/16 model. The methods compared are LoRA-8, KLORA-8 (kernelized LoRA-8), KLORA-8 (saving ΔW) which saves memory by not storing the merged adaptation matrix, SNELL-8, and SNELL-8 (saving ΔW). The results show that SNELL-8 takes slightly longer to train than LoRA-8, but that the memory saving modifications for both KLORA and SNELL significantly reduce training time.
Full paper#