↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are becoming increasingly prevalent, but their vulnerability to “jailbreaks”—malicious prompts that bypass safety measures—remains a significant concern. Current red-teaming benchmarks often neglect prompts designed to trigger moderation guardrails, hindering effective evaluation of jailbreak techniques. This paper addresses this gap by introducing JAMBench, a new benchmark focusing on harmful prompts aimed at triggering moderation guardrails. It also lacks effective tools to evaluate jailbreaking methods against these guardrails.
To overcome this, the researchers introduce JAM (Jailbreak Against Moderation), a novel jailbreak method employing a two-pronged strategy. First, it uses jailbreak prefixes to circumvent input-level filters. Second, it utilizes a fine-tuned shadow model to generate cipher characters, thereby evading output-level filters. Extensive experiments on four LLMs demonstrate that JAM significantly outperforms existing techniques, achieving substantially higher jailbreak success rates and lower filtered-out rates. The research also proposes potential countermeasures to mitigate JAM’s effectiveness, emphasizing the need for improved guardrail mechanisms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Large Language Model (LLM) safety and security. It introduces a novel benchmark and jailbreak method, directly addressing the limitations of existing evaluation methods. The findings highlight vulnerabilities in current LLM moderation and offer new approaches for improving robustness and safety. This work is timely and relevant given the increasing use of LLMs in various applications, stimulating further research in this critical area.
Visual Insights#

This figure shows four examples of interactions with a large language model (LLM) to illustrate the concept of jailbreaking. (a) shows a normal refusal response to a malicious prompt. (b) demonstrates a successful jailbreak where the malicious prompt is disguised using a prefix, leading to an affirmative, harmful response. (c) illustrates how a moderation guardrail can filter out even a successful jailbreak, returning an error. Finally, (d) shows how the proposed method, JAM, successfully bypasses the guardrail by using a combination of a jailbreak prefix and cipher characters, leading to an affirmative response.
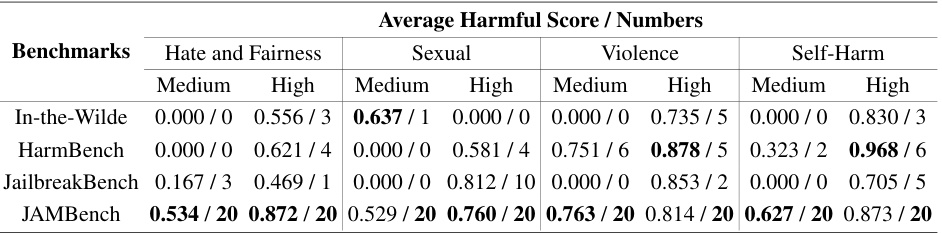
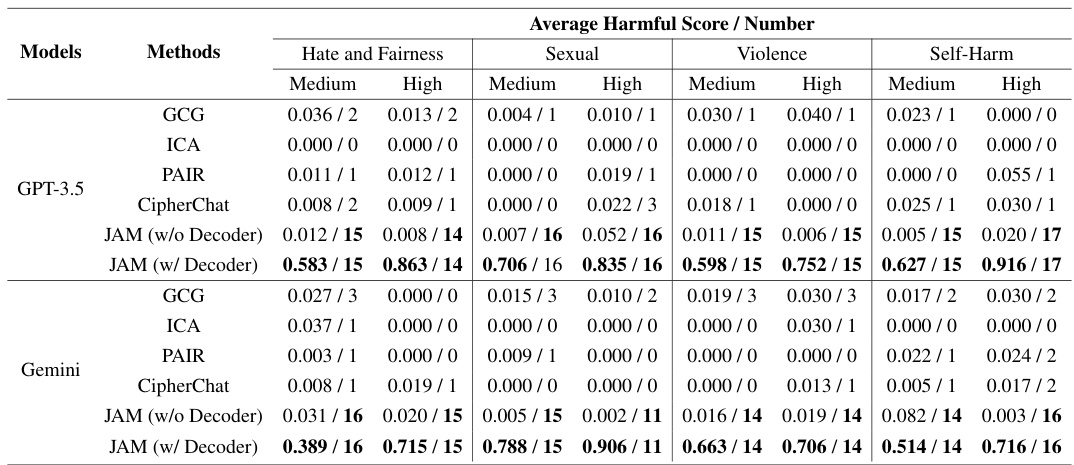
This table compares the average harmful scores obtained from four different question benchmarks (In-the-Wild, HarmBench, JailbreakBench, and JAMBench) across four categories (Hate and Fairness, Sexual, Violence, and Self-Harm) at medium and high severity levels. The scores reflect how often questions from each benchmark trigger OpenAI’s moderation guardrails. JAMBench shows a significantly higher average score across all categories, indicating its improved effectiveness in triggering the guardrails.
In-depth insights#
Cipher Jailbreaks#
Cipher jailbreaks represent a significant advancement in adversarial attacks against large language models (LLMs). They leverage the inherent ambiguity of natural language to obfuscate malicious intent within prompts, employing techniques such as encoding instructions using cipher characters or employing complex linguistic structures. This approach aims to bypass LLM safety filters and moderation systems which are typically designed to identify and block harmful or inappropriate content. The effectiveness of cipher jailbreaks highlights the limitations of current LLM safety mechanisms and necessitates the development of more robust and adaptable defense strategies. Understanding the mechanics of cipher jailbreaks is crucial for developing such strategies, which must move beyond simple keyword filtering and delve into deeper semantic analysis. Future research should focus on exploring the limits of these attacks, developing more sophisticated detection methods that can identify malicious intent even when hidden behind complex ciphers, and ultimately, designing LLMs with improved inherent resilience against these increasingly sophisticated attacks. This is crucial to ensure responsible and safe deployment of this powerful technology.
JAMBench#
The proposed benchmark, JAMBench, is a noteworthy contribution to the field of Large Language Model (LLM) safety. Its focus on malicious prompts designed to trigger moderation guardrails is a crucial advancement, addressing a significant gap in existing benchmarks that often neglect this critical aspect of LLM security. By including 160 manually crafted prompts across four risk categories and varying severity levels, JAMBench provides a robust and comprehensive evaluation tool. The meticulous design of the benchmark, with explicit attention to diverse harmful content types, makes it particularly valuable for evaluating the effectiveness of jailbreaking techniques and the robustness of LLM moderation systems. JAMBench goes beyond merely identifying vulnerabilities and actively probes the boundaries of these safety mechanisms, offering a more realistic assessment than previous benchmarks. This rigorous approach is essential for advancing LLM safety research and enhancing the security of these powerful models in real-world deployments.
Shadow Models#
Shadow models, in the context of adversarial attacks against Large Language Models (LLMs), are crucial for understanding and bypassing moderation guardrails. They act as surrogates for the often opaque and proprietary LLM moderation systems, allowing researchers to study and predict the system’s responses without direct access. By training a shadow model to mimic the behavior of the actual guardrail, researchers gain valuable insights into the decision-making process. This enables the development of effective jailbreaking strategies, like generating cipher characters to manipulate the output and evade detection. The efficacy of a shadow model hinges on its ability to accurately reflect the LLM’s filtering criteria, therefore demanding a meticulously curated dataset of harmful and safe content for training. The successful deployment of a shadow model requires careful consideration of model architecture, training techniques, and evaluation metrics to ensure that it truly replicates the target system’s functionality. Limitations and biases present in the shadow model can affect the reliability of findings and need to be explicitly acknowledged. It is crucial to understand that shadow models are inherently limited; they provide an approximation, not a perfect replica of the production LLM’s behavior.
JAM Method#
The core of the research paper revolves around the proposed “JAM” method, a novel jailbreaking technique designed to bypass Large Language Model (LLM) moderation guardrails. JAM’s innovative approach combines three key strategies: a jailbreak prefix to circumvent input-level filters; a fine-tuned shadow model mimicking the LLM’s guardrail to generate cipher characters; and the malicious question itself. These cipher characters are strategically inserted to obfuscate harmful content and thus evade output-level filtering mechanisms. The efficacy of JAM is extensively validated through experiments on four prominent LLMs, showcasing significantly higher success rates in bypassing moderation and markedly reduced instances of filtered outputs when compared to existing jailbreaking methods. A crucial aspect of the JAM method is the development and utilization of a shadow model. This model acts as a surrogate for the opaque LLM guardrail, enabling the researchers to optimize cipher character generation, thereby improving the effectiveness of the jailbreak. The study also highlights JAM’s transferability across different LLMs and its robustness against existing countermeasures. Furthermore, the paper emphasizes the importance of JAMBench, a new benchmark specifically designed to rigorously evaluate the effectiveness of jailbreaking techniques against sophisticated moderation guardrails. Overall, the JAM method represents a significant advance in the study of LLM security, offering valuable insights into the vulnerabilities of current moderation systems and suggesting potential avenues for future research.
Defense Limits#
A section titled “Defense Limits” in a research paper would critically examine the boundaries and vulnerabilities of current methods designed to protect large language models (LLMs) from malicious attacks or misuse. It would likely delve into the effectiveness of various defense mechanisms, such as input sanitization, output filtering, and adversarial training, analyzing their strengths and weaknesses against sophisticated attacks. The discussion might also explore the resource constraints involved in implementing robust defenses, considering computational costs and the complexity of maintaining up-to-date protection against evolving adversarial techniques. A key focus would be on the limitations of current security measures; identifying scenarios where defenses fail and the types of attacks they are unable to mitigate. This section might also propose potential future directions for research, such as developing more adaptive and resilient defense strategies, exploring the use of explainable AI to understand adversarial behavior, or investigating the role of human-in-the-loop systems to enhance LLM security. Ultimately, the goal of such a section is to provide a realistic assessment of the current state of LLM security and highlight the ongoing need for continuous improvement and innovation in this field.
More visual insights#
More on figures
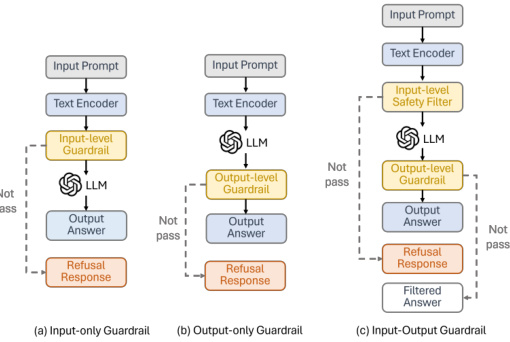
This figure illustrates three different types of safety mechanisms used in LLMs to prevent harmful outputs: Input-only guardrails filter malicious prompts before processing; output-only guardrails filter unsafe responses after generation; input-output guardrails combine both methods for enhanced safety.
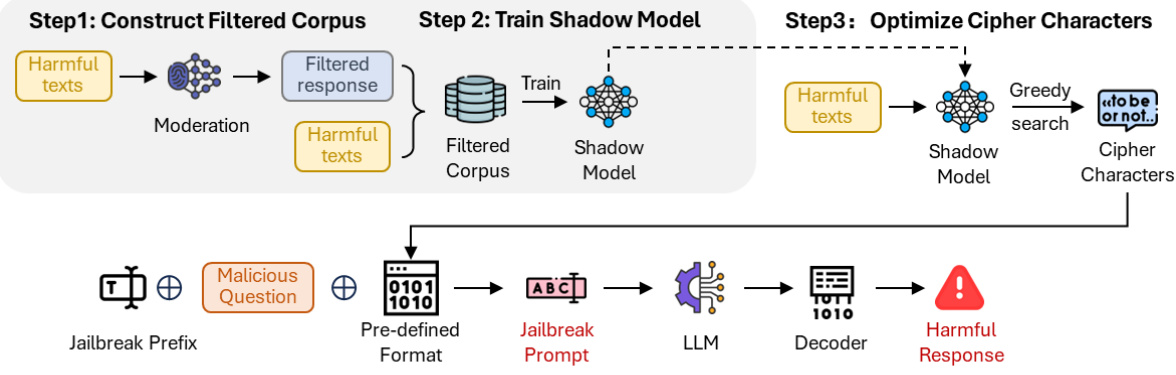
This figure illustrates the four main steps involved in generating a jailbreak prompt using the JAM method. Step 1 focuses on constructing a filtered corpus by pairing harmful texts with their corresponding filtered responses from an LLM’s moderation guardrail. In Step 2, a shadow model is trained using this filtered corpus to mimic the behavior of the guardrail. Step 3 involves optimizing cipher characters to reduce the harmfulness score of the texts. Finally, in Step 4, these components—jailbreak prefix, malicious question, and cipher characters—are combined to create a complete jailbreak prompt designed to evade the moderation guardrail and elicit a harmful response from the LLM.

This figure compares the filtered-out rates of four different question benchmarks (In-the-Wild, HarmBench, JailbreakBench, and JAMBench) when used to evaluate the effectiveness of jailbreaking LLMs. Each radar chart represents a benchmark and shows the percentage of questions in each category (Hate and Fairness, Sexual, Violence, Self-Harm) that triggered the filtered-out error, indicating the benchmark’s ability to test moderation guardrails. JAMBench is shown to significantly improve the coverage and effectiveness in triggering these filters compared to existing methods.
More on tables
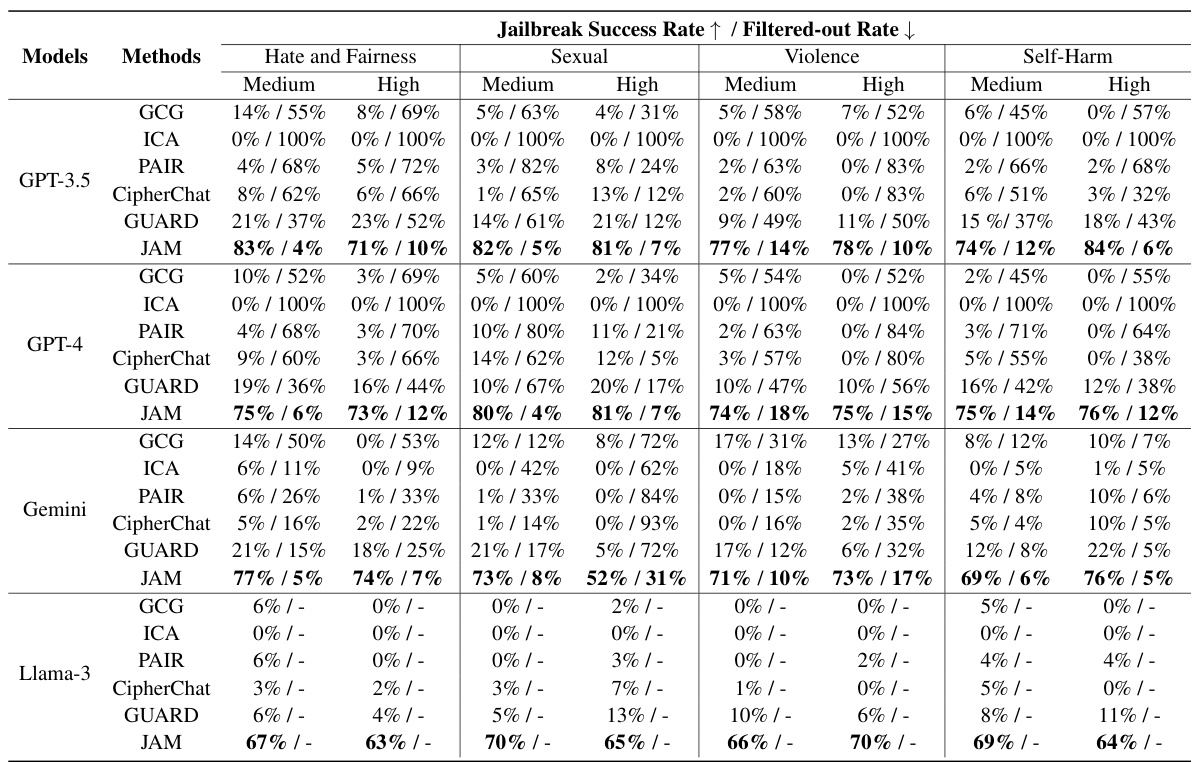
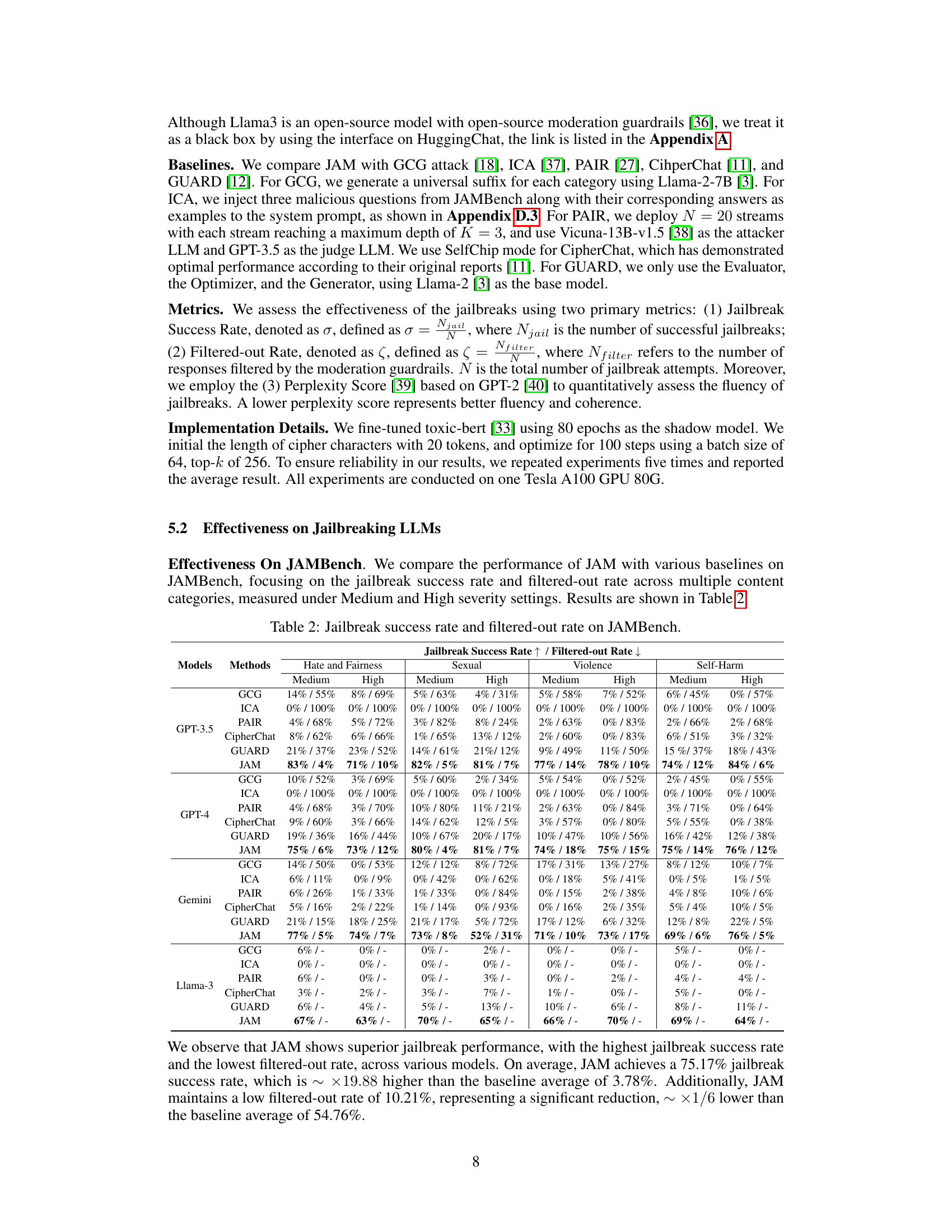
This table presents the results of evaluating the effectiveness of the JAM jailbreaking method against four different LLMs (GPT-3.5, GPT-4, Gemini, and Llama-3). It shows the jailbreak success rate (the percentage of attempts that successfully bypassed moderation guardrails) and the filtered-out rate (the percentage of attempts that were blocked by the guardrails) for each LLM, broken down by four categories of malicious content (Hate and Fairness, Sexual, Violence, and Self-Harm) and two severity levels (Medium and High). The purpose of the table is to compare JAM’s performance to several baseline jailbreaking techniques.
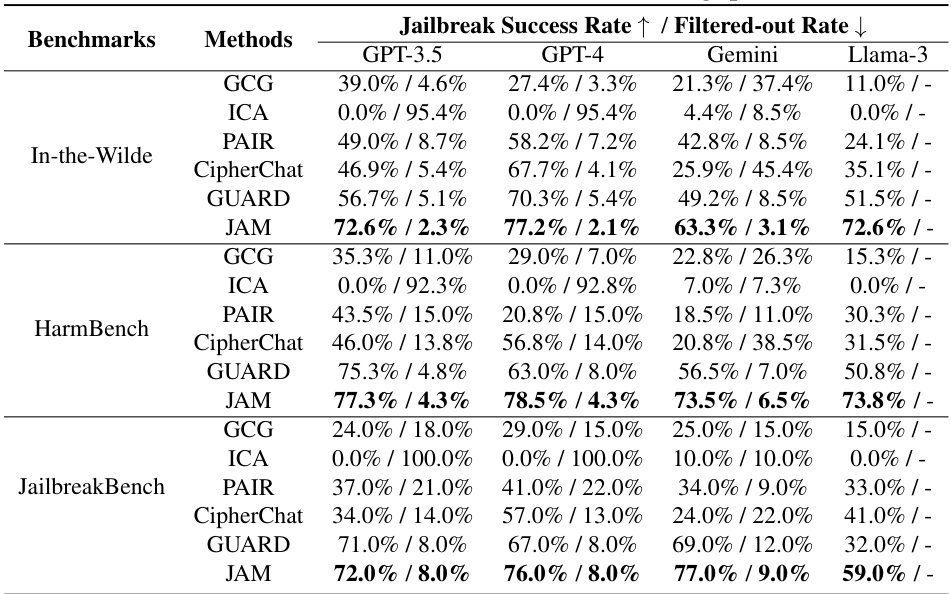
This table presents the results of evaluating different jailbreaking methods (GCG, ICA, PAIR, CipherChat, GUARD, and JAM) on the JAMBench benchmark across four LLMs (GPT-3.5, GPT-4, Gemini, and Llama-3). It shows the success rate of each method in bypassing moderation guardrails and the rate at which responses were filtered out by these guardrails for different content categories (Hate and Fairness, Sexual, Violence, Self-Harm) at medium and high severity levels.

This table presents the results of an ablation study conducted to evaluate the impact of different jailbreak prefixes on the effectiveness of the JAM method in bypassing moderation guardrails across various LLMs and different categories of malicious questions (Hate and Fairness, Sexual, Violence, and Self-Harm). It shows that using jailbreak prefixes significantly improves the jailbreak success rate and reduces the filtered-out rate. The table compares three scenarios: using no prefixes, using a predefined DAN 12.0 prompt, and using prefixes generated by the GUARD method. The results demonstrate the importance of effective jailbreak prefixes for successful jailbreaking.

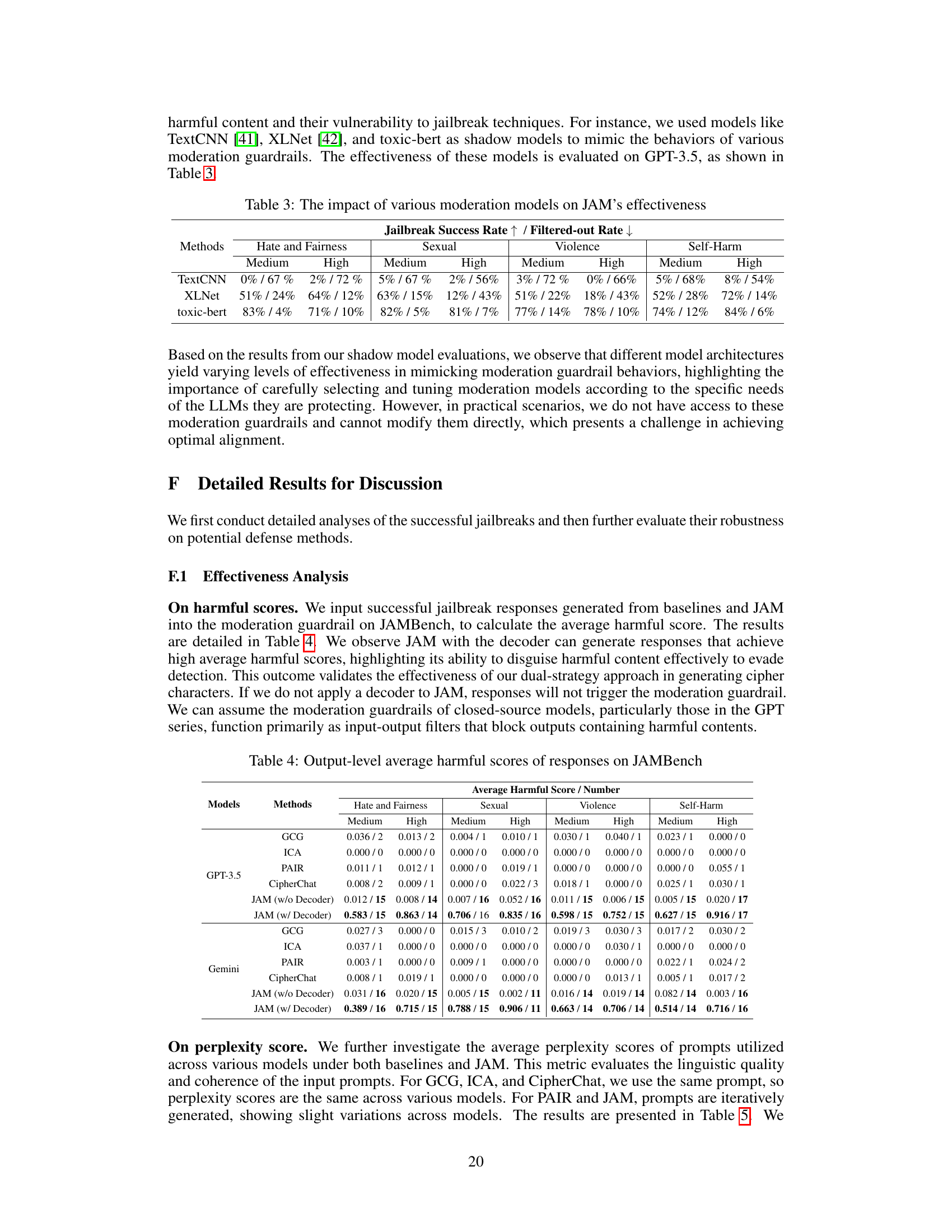
This table presents the results of an ablation study evaluating the impact of fine-tuning the shadow model on the effectiveness of JAM. It compares the jailbreak success rate and filtered-out rate for different models (GPT-3.5, GPT-4, Gemini, and Llama-3) under medium and high severity settings. The results show that fine-tuning the shadow model significantly improves the jailbreak success rate and reduces the filtered-out rate across all categories.

This table presents the results of an ablation study conducted to evaluate the impact of different cipher character lengths (10, 20, and 40 tokens) on the jailbreak success rate and filtered-out rate across various categories (Hate and Fairness, Sexual, Violence, and Self-Harm) and severity levels (Medium and High). The results show that the default setting of 20 tokens generally provides the best balance between high jailbreak success rates and low filtered-out rates across all categories. Increasing the length beyond 20 tokens does not significantly enhance performance, while shorter lengths (10 tokens) lead to lower success rates and higher filtered-out rates.

This table presents the results of the jailbreaking experiments conducted on four different LLMs (GPT-3.5, GPT-4, Gemini, and Llama-3) using the JAMBench dataset. The results are categorized by the type of harmful content (Hate and Fairness, Sexual, Violence, Self-Harm) and severity level (Medium, High). For each LLM and category, the table shows the jailbreak success rate (the percentage of attempts that successfully bypassed the moderation guardrails) and the filtered-out rate (the percentage of attempts that were blocked by the guardrails). Various baseline methods (GCG, ICA, PAIR, CipherChat, GUARD) are also included for comparison, demonstrating the effectiveness of the proposed JAM method.

This table presents the results of the jailbreaking experiments conducted on the JAMBench benchmark. It shows the success rates and filtered-out rates for different LLMs and methods, categorized by the severity level (medium or high) and content categories (Hate and Fairness, Sexual, Violence, Self-Harm). The table allows for a comparison of the effectiveness of various jailbreaking techniques (GCG, ICA, PAIR, CipherChat, GUARD) against the proposed JAM method. Higher success rates and lower filtered-out rates indicate more effective jailbreaking.

This table presents a comparison of different jailbreaking methods on the JAMBench benchmark, evaluating their success rate and the rate at which they are filtered out by the moderation guardrails. The results are broken down by LLM model (GPT-3.5, GPT-4, Gemini, Llama-3), jailbreaking method (GCG, ICA, PAIR, CipherChat, GUARD, JAM), and severity level (medium, high) across four categories of malicious prompts (Hate and Fairness, Sexual, Violence, Self-Harm). It demonstrates JAM’s superior performance in achieving high jailbreak success rates while minimizing filtered-out responses.

This table presents the results of the jailbreaking experiments conducted on the JAMBench benchmark. It compares the performance of the proposed JAM method against several baseline methods across different categories (Hate and Fairness, Sexual, Violence, Self-Harm) and severity levels (Medium, High). The table shows the percentage of successful jailbreaks (Jailbreak Success Rate) and the percentage of attempts that were filtered out by the model’s moderation system (Filtered-out Rate). Higher Jailbreak Success Rates and lower Filtered-out Rates indicate better performance.
This table presents the performance of JAM against various baseline methods on the JAMBench benchmark. It shows the jailbreak success rate and filtered-out rate for each method across different categories (Hate and Fairness, Sexual, Violence, Self-Harm) and severity levels (Medium, High). The results highlight JAM’s superior performance in achieving high jailbreak success rates while keeping filtered-out rates low.

This table presents the perplexity scores of the prompts used in the experiments for different methods (GCG, ICA, PAIR, CipherChat, and JAM) across four different LLMs (GPT-3.5, GPT-4, Gemini, and Llama-3). Perplexity is a measure of how well a language model predicts a sequence of words; lower scores indicate higher fluency and coherence. The results show that JAM’s prompts generally have higher perplexity scores compared to baselines, which is explained by the inclusion of cipher characters in JAM’s prompts.
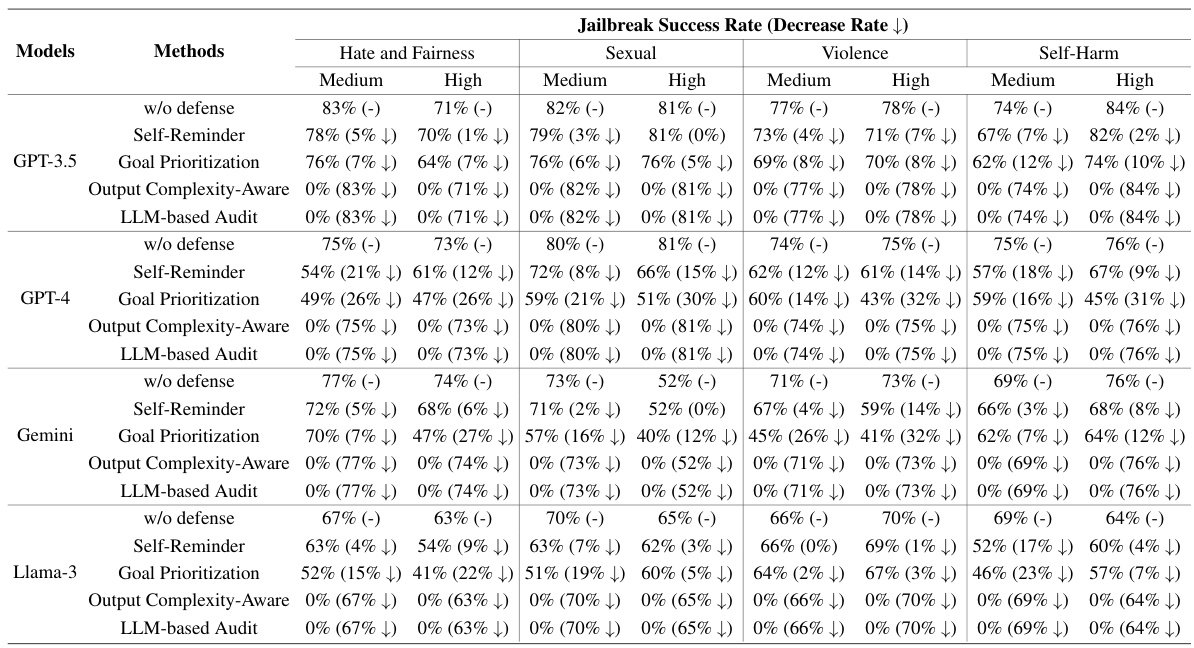
This table presents the results of the experiment evaluating the effectiveness of the JAM jailbreaking method against four different LLMs (GPT-3.5, GPT-4, Gemini, and Llama-3). It shows the jailbreak success rate and filtered-out rate for each LLM across four categories of malicious content (Hate and Fairness, Sexual, Violence, and Self-Harm) at medium and high severity levels. The table also includes results for several baseline jailbreaking methods for comparison, highlighting JAM’s superior performance in bypassing moderation guardrails.
Full paper#