TL;DR#
Continual learning in deep neural networks struggles with catastrophic forgetting – the inability to learn new tasks without losing knowledge of previously learned tasks. Recent methods use prompts (learnable parameters encoding task knowledge) to guide a pre-trained model, but existing approaches suffer from sub-optimal prompt selection because the prompt selection process is not directly optimized with task loss. This leads to inadequate feature adaptation for new tasks.
VQ-Prompt solves this by incorporating vector quantization (VQ). VQ allows the optimization of a discrete set of prompts end-to-end with task loss, effectively improving knowledge abstraction for each task. Experiments across multiple benchmarks demonstrate that VQ-Prompt significantly outperforms state-of-the-art continual learning methods in class-incremental settings.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces VQ-Prompt, a novel approach to continual learning that addresses the limitations of existing prompt-based methods. It achieves state-of-the-art results on multiple benchmarks, demonstrating the effectiveness of its unique approach. This opens up new avenues for research in continual learning, particularly in optimizing prompt selection and knowledge representation for improved performance and efficiency. Its focus on discrete prompts and end-to-end training provides a valuable contribution to the field.
Visual Insights#
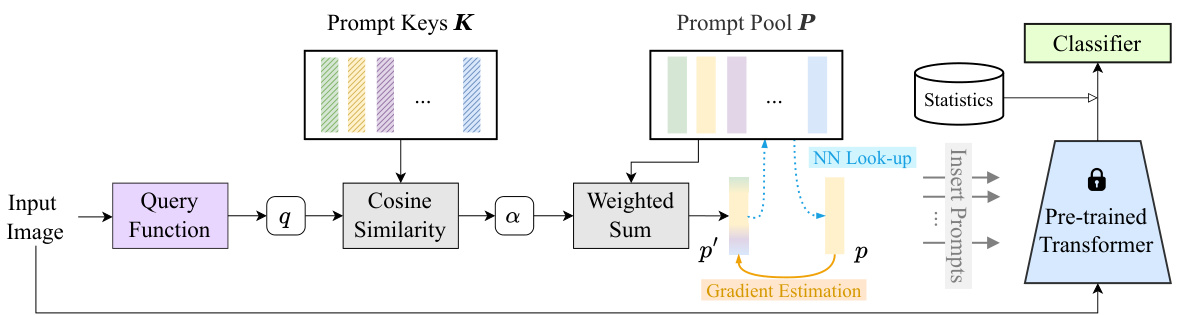
🔼 This figure illustrates the VQ-Prompt framework, showing how an input image is processed to generate a discrete prompt for a pre-trained vision transformer. It highlights the key steps: query generation, prompt key similarity calculation, weighted prompt aggregation, vector quantization, gradient estimation for differentiability, and the use of representation statistics for stable learning. The overall process aims to optimize prompt selection and feature generation for continual learning tasks.
read the caption
Figure 2: VQ-Prompt framework. An input image is passed through a query function (e.g., a fixed pre-trained ViT) to generate a query q, which is then used to compute similarity scores with prompt keys K. These scores α serve as weights to aggregate elements from the prompt pool P to form a continuous prompt p'. This prompt is subsequently quantized to an element within the prompt pool p, and then fed into a specific MSA block of a frozen pre-trained transformer. To ensure differentiability, the prompt quantization process employs gradient estimation and prompt pool regularization. The representation statistics of features from learned classes are used to stabilize task knowledge learning. More details are shown in §4.

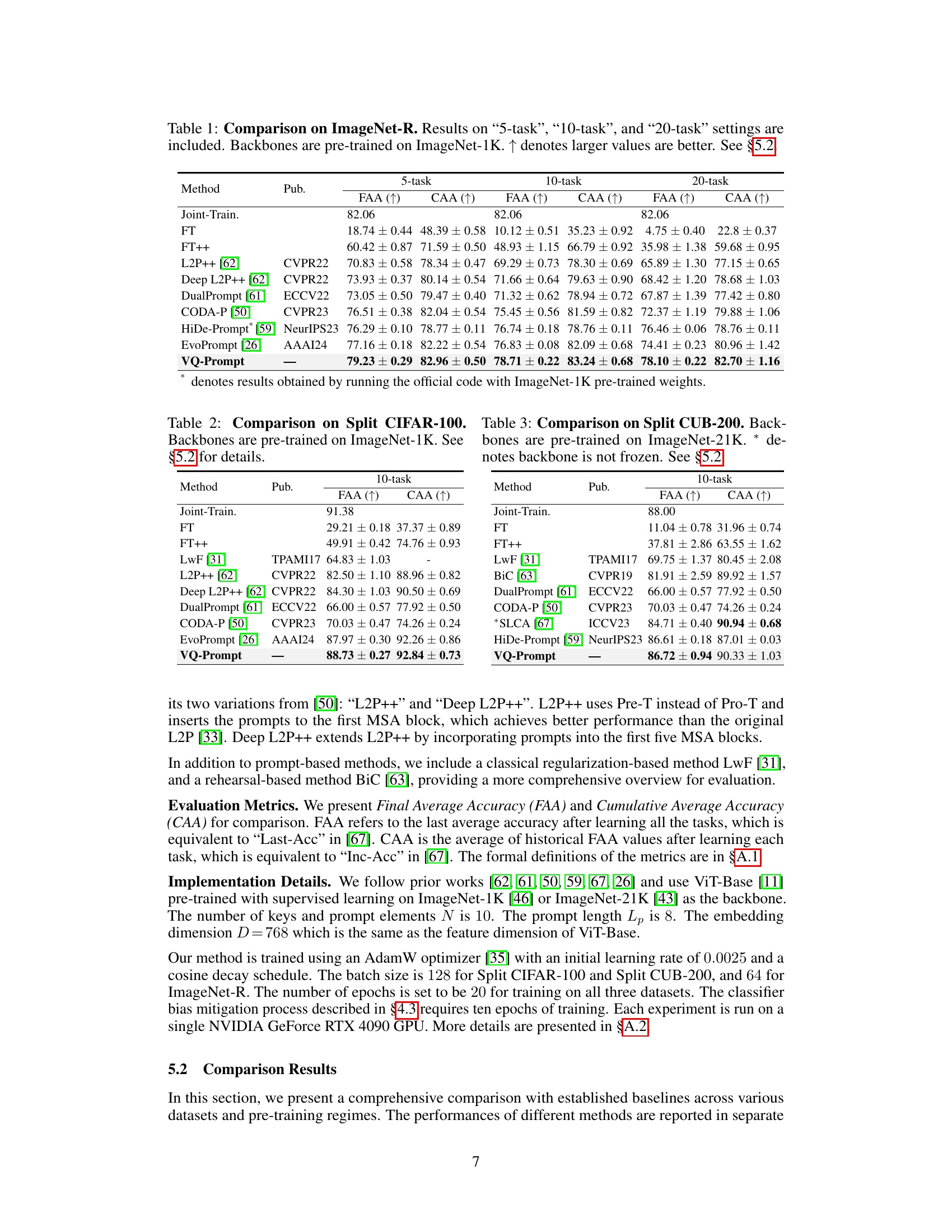
🔼 This table presents a comparison of different continual learning methods on the ImageNet-R dataset. The results are broken down into three settings: 5 tasks, 10 tasks, and 20 tasks. All models used a backbone pre-trained on ImageNet-1K. The table shows the final average accuracy (FAA) and cumulative average accuracy (CAA) for each method. Higher values for FAA and CAA indicate better performance. Section 5.2 provides further details.
read the caption
Table 1: Comparison on ImageNet-R. Results on “5-task”, “10-task”, and “20-task” settings are included. Backbones are pre-trained on ImageNet-1K. ↑ denotes larger values are better. See §5.2.
In-depth insights#
VQ-Prompt’s novelty#
VQ-Prompt’s novelty stems from its unique integration of vector quantization (VQ) into a prompt-based continual learning framework. Existing prompt-based methods either suffer from non-differentiable prompt selection or utilize continuous prompts lacking sufficient abstraction for task knowledge. VQ-Prompt addresses these limitations by optimizing discrete prompts end-to-end with task loss. This is achieved through gradient estimation and VQ regularization, ensuring effective abstraction and efficient prompt selection. The incorporation of representation statistics further enhances stability and mitigates catastrophic forgetting. Therefore, the key innovation lies not just in using VQ, but in its novel application within a prompt-based continual learning paradigm to improve both efficiency and performance.
End-to-end training#
End-to-end training is a crucial concept in machine learning, particularly relevant for complex tasks like those addressed in continual learning. It offers the advantage of directly optimizing the entire system, including all components and parameters involved, with respect to the final task objective. This contrasts with traditional modular or staged approaches, which often involve separate optimization steps for different components and potentially lead to suboptimal overall performance. In continual learning, where a model is trained sequentially on multiple tasks, end-to-end training is beneficial because it allows for seamless integration of knowledge across tasks, preventing catastrophic forgetting. However, end-to-end training in continual learning can present challenges, especially in scenarios with complex architectures or many parameters. Effective optimization strategies are essential to balance the adaptation to new tasks with the preservation of knowledge from previous tasks. The paper’s use of Vector Quantization (VQ) to facilitate the end-to-end training of discrete prompts is a noteworthy approach in overcoming challenges related to prompt selection in continual learning and optimizing performance.
Discrete prompt#
The concept of “discrete prompt” in continual learning offers a compelling approach to mitigate catastrophic forgetting. Unlike continuous prompts, which are often represented as vectors in a continuous space, discrete prompts are drawn from a finite, pre-defined set. This discrete nature facilitates better knowledge abstraction and organization, mirroring how humans categorize information into distinct concepts. The use of discrete prompts enhances the effectiveness of prompt-based methods by creating more robust and interpretable representations of task-specific knowledge. This discrete representation lends itself well to optimization techniques, allowing for more effective end-to-end training and facilitating the tuning of parameters to minimize task interference and catastrophic forgetting. Moreover, the inherent discreteness of the prompts improves the generalization of the model to new tasks and prevents issues stemming from continuous prompt representations being overly sensitive to small changes, leading to suboptimal performance. Therefore, discrete prompts present a significant advantage in continual learning for both enhanced knowledge representation and optimized model adaptation.
Continual learning#
Continual learning addresses the critical challenge of catastrophic forgetting in artificial neural networks. Traditional deep learning models often struggle to learn new tasks without forgetting previously acquired knowledge. This is a significant limitation, as real-world scenarios frequently demand adapting to new information streams without erasing existing knowledge. Continual learning research explores diverse strategies including architectural modifications, regularization techniques, and memory-based approaches to mitigate catastrophic forgetting. Prompt-based methods, a recent advancement, show considerable promise. They leverage pre-trained models and task-specific prompts to achieve effective learning without extensive retraining. However, optimal prompt selection and feature adaptation remain key areas for improvement. Future research in continual learning will likely focus on more sophisticated memory management, effective prompt engineering, and robustness to noisy or incomplete data streams. The ultimate goal is to create AI systems capable of continuous learning, closely mirroring human adaptability.
Future directions#
Future research could explore several promising avenues. Improving prompt efficiency is crucial; current methods can be computationally expensive. Investigating alternative quantization techniques beyond vector quantization might yield improved performance and efficiency. Addressing the catastrophic forgetting problem more effectively is key; current methods still exhibit some level of forgetting, requiring exploration of novel regularization methods. Exploring prompt-based methods for different continual learning scenarios such as domain-incremental learning is needed. Finally, enhancing the interpretability and explainability of prompts remains a critical challenge, vital for building trust and understanding in these models. These advancements would solidify the place of prompt-based approaches in the field of continual learning.
More visual insights#
More on tables

🔼 This table presents a comparison of the proposed VQ-Prompt method against several baseline and state-of-the-art continual learning methods on the ImageNet-R dataset under three different task settings (5, 10, and 20 tasks). The results are shown in terms of Final Average Accuracy (FAA) and Cumulative Average Accuracy (CAA), which measure the overall accuracy and the average accuracy across all tasks, respectively. The backbone network for all methods is pre-trained on ImageNet-1K.
read the caption
Table 1: Comparison on ImageNet-R. Results on “5-task”, “10-task”, and “20-task” settings are included. Backbones are pre-trained on ImageNet-1K. ↑ denotes larger values are better. See §5.2.
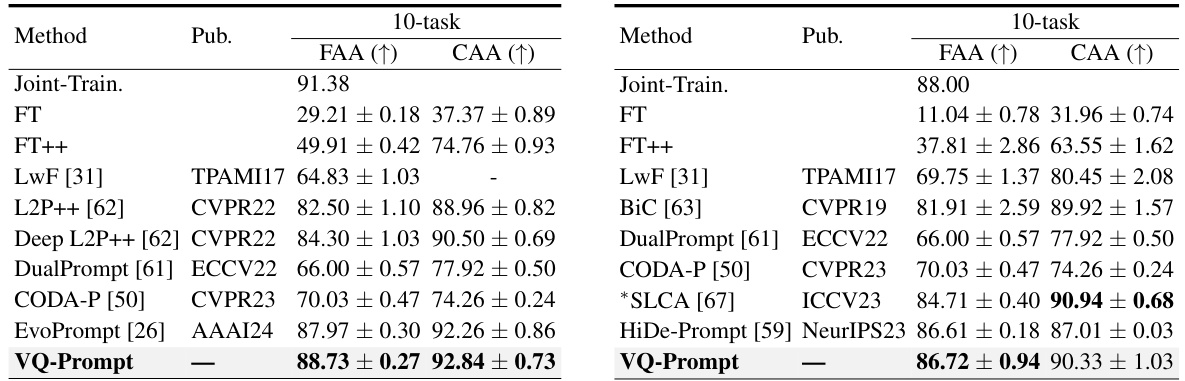
🔼 This table presents a comparison of various continual learning methods on the ImageNet-R dataset, using three different task settings (5, 10, and 20 tasks). The performance is measured using Final Average Accuracy (FAA) and Cumulative Average Accuracy (CAA). The backbone network for all methods was pre-trained on ImageNet-1K. Higher FAA and CAA values indicate better performance.
read the caption
Table 1: Comparison on ImageNet-R. Results on “5-task”, “10-task”, and “20-task” settings are included. Backbones are pre-trained on ImageNet-1K. ↑ denotes larger values are better. See §5.2.
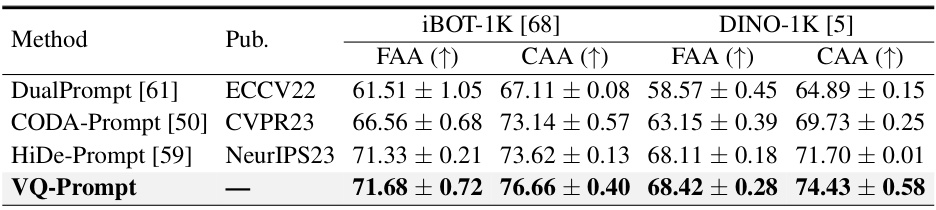
🔼 This table compares the performance of different continual learning methods (DualPrompt, CODA-Prompt, HiDe-Prompt, and VQ-Prompt) on the 10-task ImageNet-R dataset. The key difference is the type of self-supervised pre-training used for the backbone: iBOT-1K and DINO-1K. The table shows the Final Average Accuracy (FAA) and Cumulative Average Accuracy (CAA) for each method, highlighting the impact of different pre-training strategies on continual learning performance.
read the caption
Table 4: Results on 10-task ImageNet-R with different self-supervised pre-training paradigms.
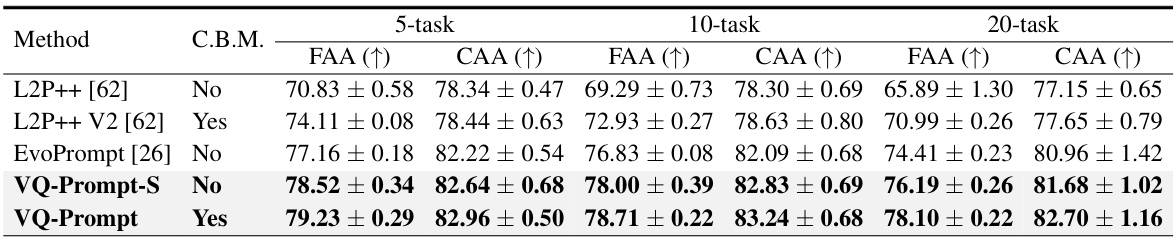
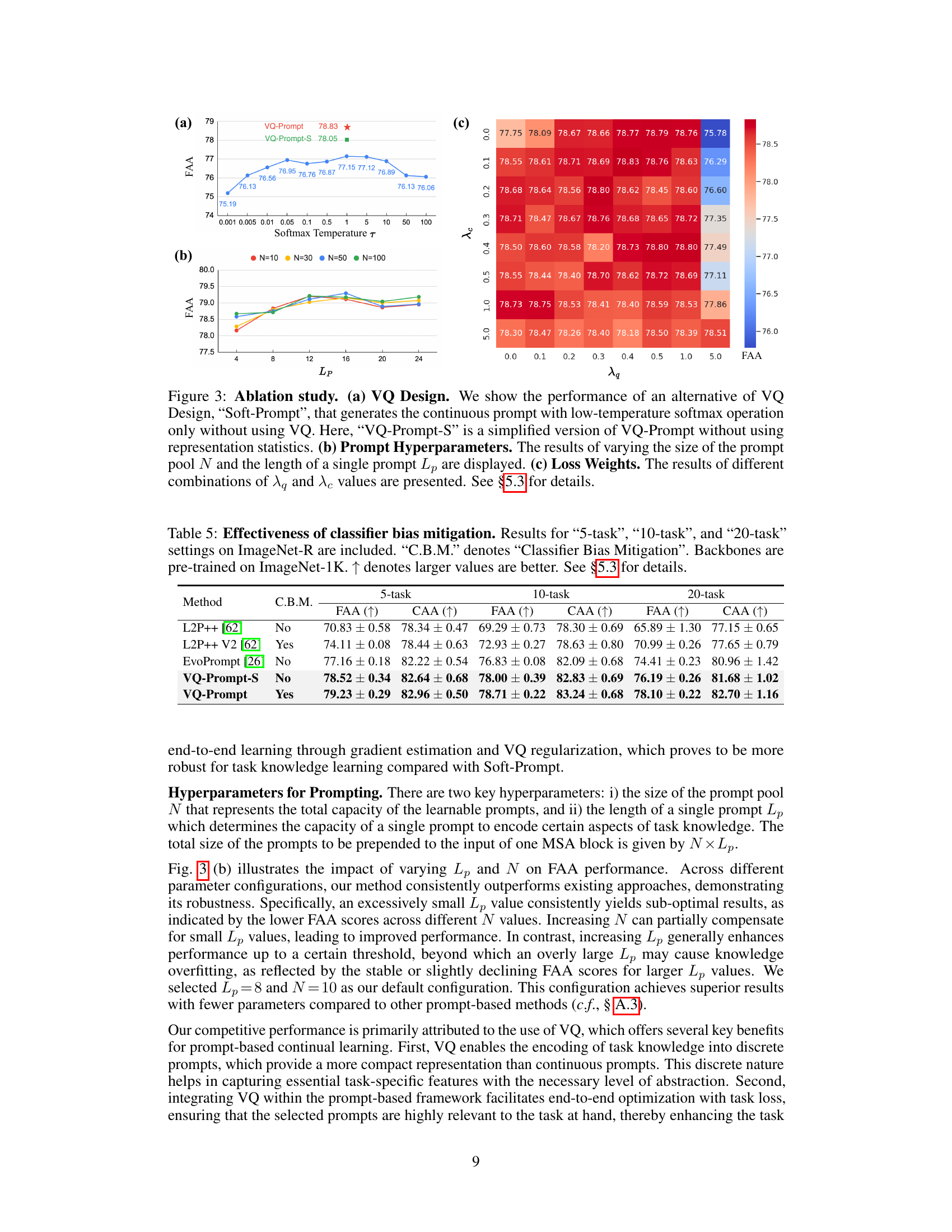
🔼 This table presents the results of an ablation study on the impact of classifier bias mitigation (CBM) on the performance of different continual learning methods (L2P++, EvoPrompt, and VQ-Prompt) across three different task settings (5-task, 10-task, and 20-task) on the ImageNet-R dataset. The table shows the final average accuracy (FAA) and cumulative average accuracy (CAA), indicating the overall performance and the ability of the model to retain knowledge of previously learned tasks. The results demonstrate whether incorporating CBM improves the performance of these continual learning methods, particularly in terms of mitigating catastrophic forgetting.
read the caption
Table 5: Effectiveness of classifier bias mitigation. Results for '5-task', '10-task', and '20-task' settings on ImageNet-R are included. 'C.B.M.' denotes 'Classifier Bias Mitigation'. Backbones are pre-trained on ImageNet-1K. ↑ denotes larger values are better. See §5.3 for details.
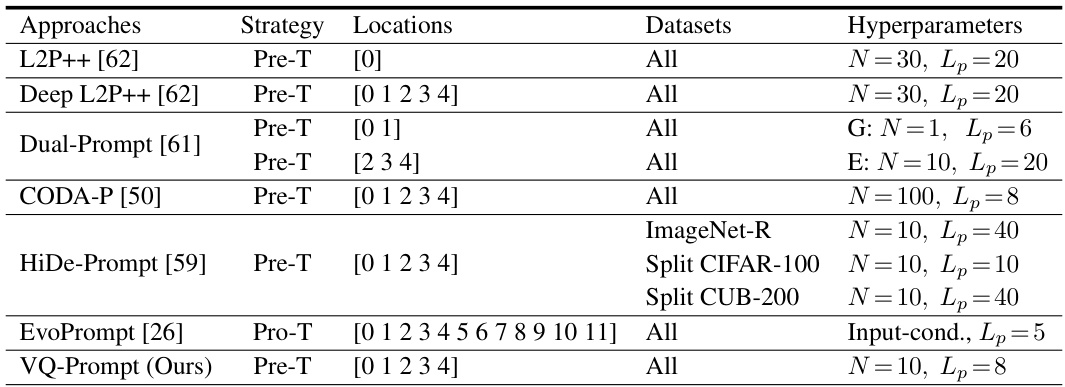
🔼 This table presents a comparison of different continual learning methods on the ImageNet-R dataset, broken down into 5, 10, and 20-task incremental learning settings. The models use backbones pre-trained on ImageNet-1K. The table shows the final average accuracy (FAA) and cumulative average accuracy (CAA) for each method, allowing for comparison of overall performance and learning capacity with less forgetting. Higher values are better for both FAA and CAA.
read the caption
Table 1: Comparison on ImageNet-R. Results on “5-task”, “10-task”, and “20-task” settings are included. Backbones are pre-trained on ImageNet-1K. ↑ denotes larger values are better. See §5.2.

🔼 This table presents the Final Average Accuracy (FAA) results on the ImageNet-A and VTAB datasets for the proposed VQ-Prompt method and HiDe-Prompt baseline. The backbones used in both cases were pre-trained on ImageNet-1K, ensuring a fair comparison between the methods. The higher FAA values indicate better performance. VQ-Prompt outperforms HiDe-Prompt on both datasets.
read the caption
Table 7: Results evaluated using the FAA metric on the ImageNet-A and VTAB datasets. Backbones are pre-trained on ImageNet-1K. Larger values are better.
Full paper#