TL;DR#
Current game AI struggles to model deceptive behaviors like feints, which are crucial for strategic advantage in many games. Existing approaches either lack concrete formalization or treat feints as simple glitches, limiting their effectiveness. This leads to less realistic and less engaging game simulations.
This research addresses these issues by introducing a novel formalization of feint behaviors, both at the action and strategy levels. The core contribution is a Palindrome-directed template and Dual-Behavior model for automatically generating and combining feints with subsequent actions. This approach is then integrated into existing MARL frameworks, enabling a unified implementation scheme that improves game rewards, increases diversity, and minimizes computational overhead. Experimental results show significant performance gains across different MARL algorithms.
Key Takeaways#
Why does it matter?#
This paper is important because it provides the first comprehensive formalization of feint behaviors in game AI, significantly improving game rewards and diversity. It offers a unified implementation scheme usable across various MARL frameworks, opening new avenues for research in deception and strategy in multi-agent systems. The findings directly address current limitations in modeling nuanced agent behaviors and enhances the realism and complexity of simulated games.
Visual Insights#

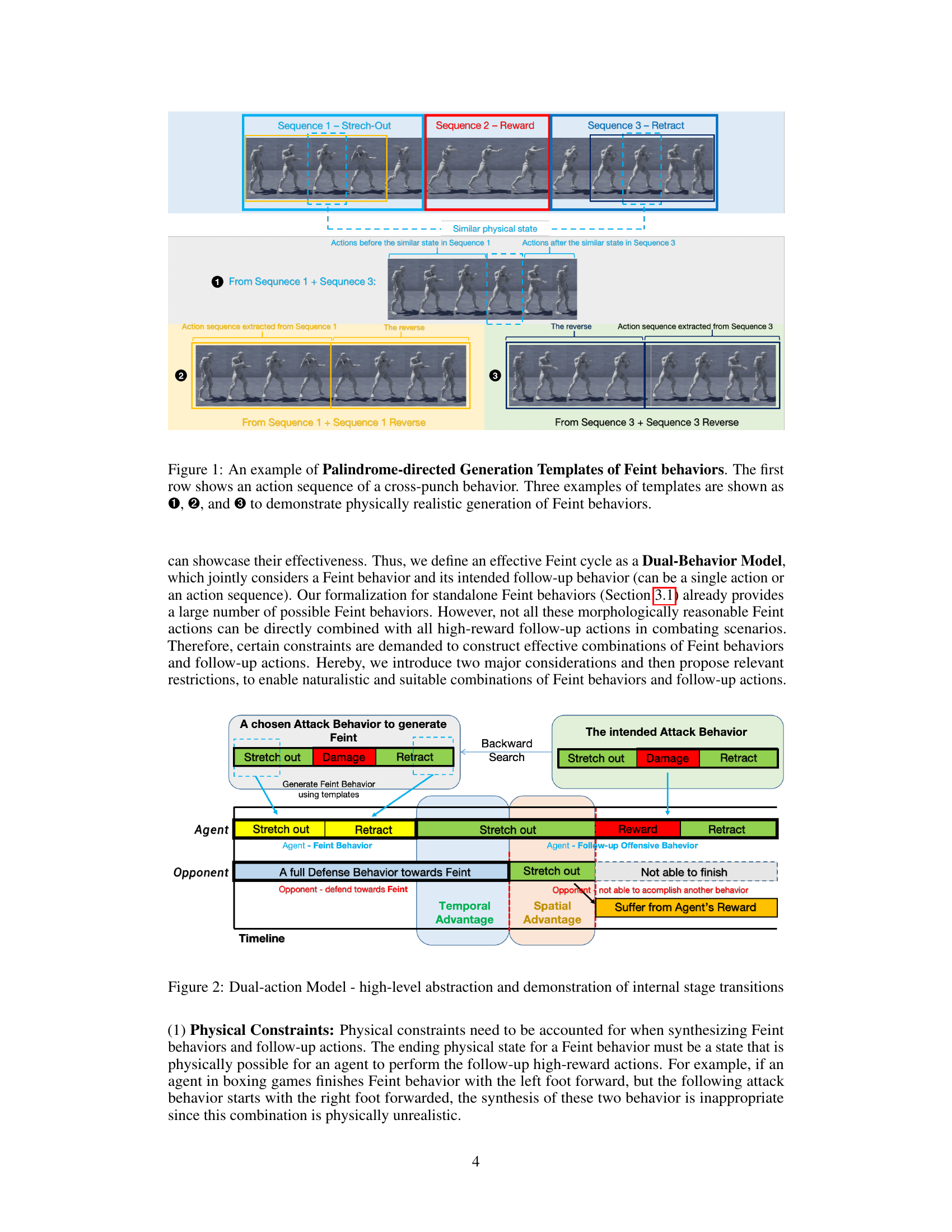
🔼 This figure demonstrates how to generate Feint behavior templates using the Palindrome-directed Generation of Feint Templates method. It shows a three-stage decomposition of an attack behavior (cross-punch) into Stretch-out, Reward, and Retract sequences. The key idea is that Sequence 1 (Stretch-out) and Sequence 3 (Retract) have semi-symmetric, reverse-order action patterns. The figure illustrates three ways to generate Feint behavior templates by extracting and combining sections of these sequences, emphasizing the semi-symmetric nature and ensuring physically realistic movements.
read the caption
Figure 1: An example of Palindrome-directed Generation Templates of Feint behaviors. The first row shows an action sequence of a cross-punch behavior. Three examples of templates are shown as 1, 2, and 3 to demonstrate physically realistic generation of Feint behaviors.
In-depth insights#
Feint Formalization#
The concept of ‘Feint Formalization’ in a research paper would involve a systematic and rigorous approach to defining and modeling feint behaviors. This would likely include a detailed action-level formalization, specifying the precise actions that constitute a feint, and a strategy-level formalization, outlining how feints are integrated into broader game strategies to achieve advantages. Key aspects of this would be identifying characteristic features that distinguish feints from normal actions (e.g., deceptive movement patterns), exploring the temporal and spatial dynamics of feints, and investigating the interaction between feints and opponent reactions. A successful formalization would provide a framework for generating feints automatically, enabling the development of more sophisticated AI agents capable of employing feints effectively in complex games. The paper might also explore the relationship between different types of feints and the contexts where particular feint strategies are most effective. Ultimately, a strong ‘Feint Formalization’ would bridge the gap between intuitive understanding of feints and their concrete implementation in game AI.
Dual-Behavior Model#
The Dual-Behavior Model is a crucial concept for integrating feint behaviors into game strategies. It elegantly combines feint actions (deceptive movements) with high-reward follow-up actions. The model’s effectiveness hinges on the precise timing and spatial coordination of these actions. A successful dual behavior creates temporal advantages by misleading opponents, allowing for a timely high-reward move. Spatial advantages are gained by exploiting the opponent’s misguided defensive reaction. This integrated approach significantly improves game rewards and strategy diversity. The model’s design incorporates physical constraints to ensure realistic and natural-looking behavior sequences, enhancing the deception and impact of the feint. Physical constraints ensure the transition between the feint and the high-reward actions is seamless and plausible, improving the overall effectiveness of the strategy.
MARL Integration#
The MARL integration section of this research paper would likely detail the specific methods used to incorporate the formalized Feint behaviors into existing multi-agent reinforcement learning (MARL) frameworks. This would involve describing a unified implementation scheme that works across various MARL algorithms, ensuring that the action-level and strategy-level formalizations of Feint are effectively integrated. Key aspects would include how the Palindrome-directed Feint generation templates and the Dual-Behavior Model are incorporated within the MARL training loop. The paper would probably discuss the modifications required to existing MARL algorithms, including how the Feint behaviors affect the reward functions and policy updates. Furthermore, the description should address how the temporal, spatial and collective impacts of Feint behaviors are represented within the MARL framework, showcasing the effectiveness of the unified approach. Crucially, the discussion would likely include an analysis of the computational overhead introduced by the Feint integration and its effect on the overall training efficiency. Ultimately, this section aims to demonstrate the feasibility and practicality of incorporating Feint behaviors into real-world MARL applications, highlighting its potential for enhancing the performance and strategic depth of multi-agent systems.
Diversity & Gain#
Analyzing the concept of “Diversity & Gain” within a research paper necessitates a multifaceted approach. The term likely refers to the relationship between the diversity of strategies employed by agents (e.g., in a game) and the resulting increase in overall reward or performance. A key aspect would involve defining the metric for “diversity”. Does it measure the variety of actions, strategies, or both? The paper may explore different ways to quantify diversity, potentially through information-theoretic measures or by analyzing the distribution of agent behavior in state-action space. Understanding the gain aspect is crucial: is the gain solely measured by reward, or are other factors such as exploration or robustness considered? A comprehensive analysis would delve into the methodology used to establish a causal link between diversity and gain, considering potential confounding factors and the limitations of the chosen approach. Statistical significance and the generalizability of results are also critical considerations for evaluating the paper’s findings.
Future of Feint#
The “Future of Feint” in multi-agent systems hinges on more sophisticated formalizations that move beyond simple action sequences. Integrating advanced AI techniques, such as deep reinforcement learning and motion prediction, is crucial for generating nuanced and deceptive feints that can dynamically adapt to opponents’ strategies. Future research should also explore more complex game environments that include factors like environmental dynamics, communication, and team coordination to create realistic scenarios for testing. Combining feints with other high-level strategic behaviors is key, fostering more diverse and unpredictable gameplay. Finally, understanding and mitigating the potential ethical implications of advanced feinting algorithms in AI applications such as autonomous vehicles and robotics is important. Ultimately, the future of feint research lies in the creation of robust, adaptive, and ethically sound AI agents capable of deploying deceptive maneuvers in increasingly complex situations.
More visual insights#
More on figures
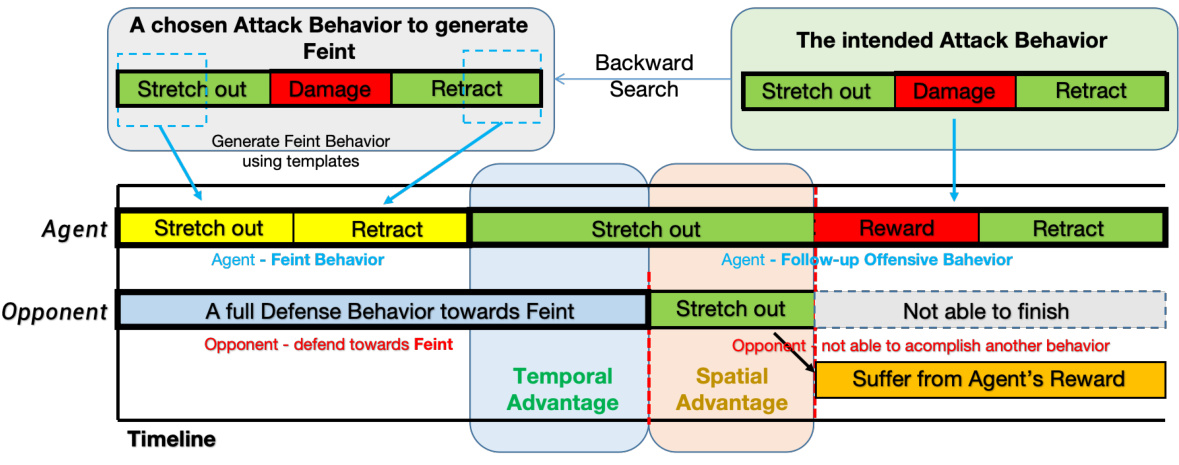
🔼 This figure illustrates the Dual-Behavior Model, showing how Feint behaviors and follow-up attack actions are combined to achieve temporal and spatial advantages. The timeline shows the agent executing a Feint (stretch-out, retract) which deceives the opponent into a full defense. Then the agent follows up with a high-reward attack behavior (stretch-out, reward, retract) taking advantage of the opponent’s temporary vulnerability and spatial misdirection. The key aspects highlighted are temporal advantage (opponent unable to react), spatial advantage (opponent’s defense is ineffective against the follow-up attack), and the resulting reward gain for the agent.
read the caption
Figure 2: Dual-action Model - high-level abstraction and demonstration of internal stage transitions

🔼 This figure illustrates the implementation of Feint behaviors in game iterations. It shows how an imaginary play module decides whether to initiate a Feint behavior, generating a Dual-Behavior Model using Palindrome-directed templates. The Feint and regular reward evaluations help to determine whether the Feint action sequence is effective. The figure also depicts the interaction with the environment, accumulation of rewards, and policy model updates, all within the framework of using both Feint and regular policies.
read the caption
Figure 3: Illustration of Feint behavior implementation in game iterations

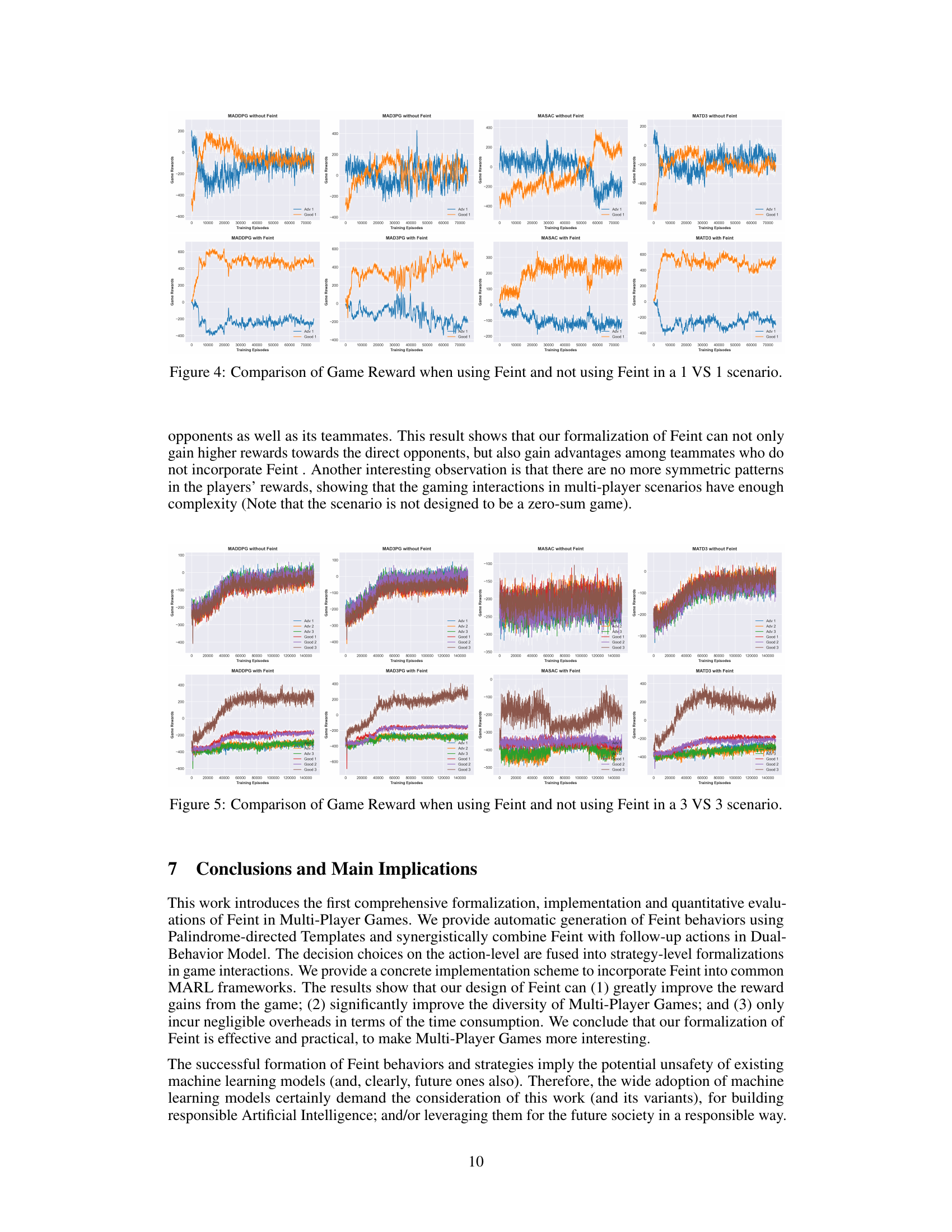
🔼 This figure compares the game rewards of using Feint behaviors versus not using them in a one-on-one scenario, using four different multi-agent reinforcement learning (MARL) models: MADDPG, MAD3PG, MASAC, and MATD3. The results show the game rewards for each model, with and without the inclusion of Feint behaviors, across a significant number of training episodes. The ‘Good 1’ player is using the Feint strategy while the ‘Adv 1’ is not. The purpose is to demonstrate that the use of Feint behaviors leads to improved rewards for the player utilizing them.
read the caption
Figure 4: Comparison of Game Reward when using Feint and not using Feint in a 1 VS 1 scenario.

🔼 This figure compares the game rewards obtained when using Feint behaviors versus not using them in a 3 vs 3 multi-player game scenario. The results are shown for four different multi-agent reinforcement learning (MARL) models (MADDPG, MAD3PG, MASAC, and MATD3). Each model’s performance is represented with two lines: one for the baseline (no Feint) and one incorporating Feint behaviors. The comparison allows assessment of the impact of Feint on reward gains across different MARL algorithms in a complex multi-agent environment.
read the caption
Figure 5: Comparison of Game Reward when using Feint and not using Feint in a 3 VS 3 scenario.
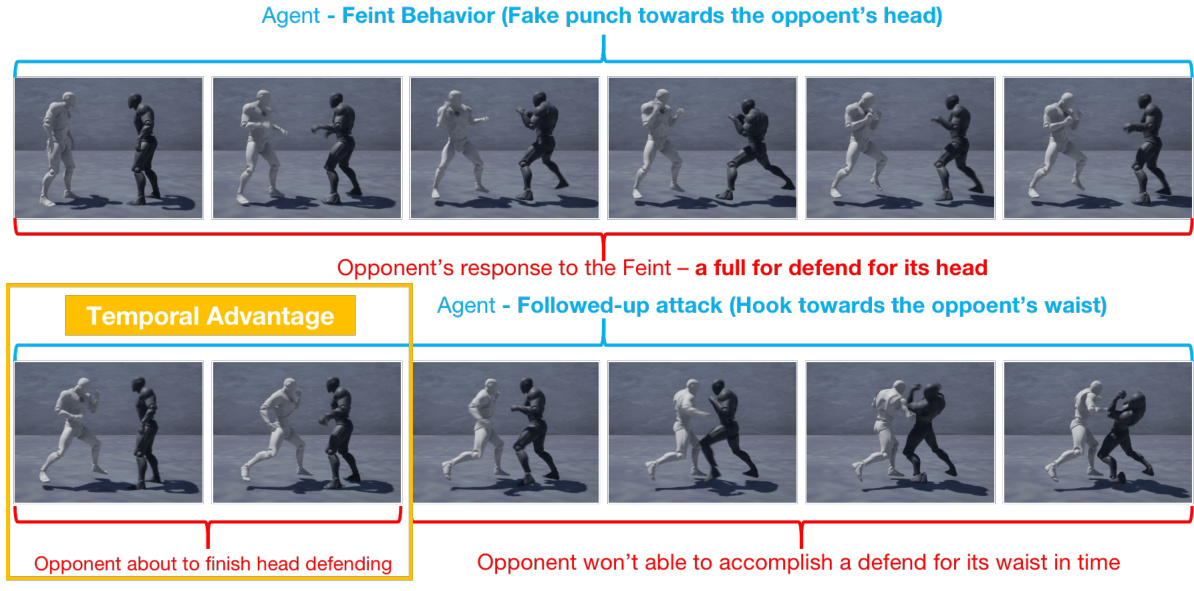
🔼 This figure shows a successful Feint behavior in a Dual-Behavior Model. The white agent (on the left) performs a fake punch (Feint) towards the opponent’s head, causing the opponent to defend their head. Simultaneously, the agent performs a hook towards the opponent’s waist. Because the Feint created a temporal advantage (by deceiving the opponent) and a spatial advantage (by attacking a different area), the opponent is unable to defend the waist attack and is knocked down. The figure illustrates the action sequence of both the agent and opponent.
read the caption
Figure 6: Dual-action Model - snapshots of the full process

🔼 This figure shows an example of unsuccessful Feint behavior. The key characteristic of this type of Feint is that the Feint action is too short. The time for the Feint behavior to end (tB1) is earlier than the time for the following attack to start gaining rewards (tA2). As a result, the opponent is still in the defensive posture when the attack begins, reducing the effectiveness of the Feint.
read the caption
Figure 7: Demonstration of unsuccessful Feint behavior when its too short
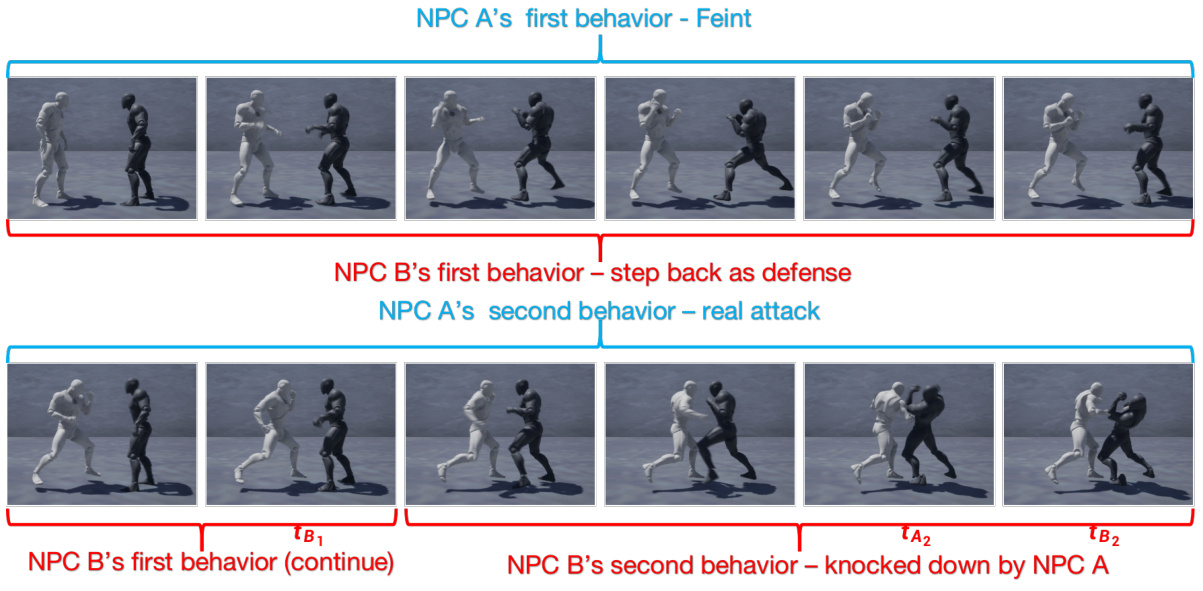
🔼 This figure demonstrates a successful Feint behavior in a Dual-Behavior Model. The key is that the Feint behavior (fake punch towards the opponent’s head) is performed with a proper length, which creates both temporal and spatial advantages. The temporal advantage comes from the opponent starting their defense reaction after the Feint’s completion. The spatial advantage is gained because the opponent is mislead to defend the head while the attack is launched to the waist. This leads to a knockout of the opponent.
read the caption
Figure 8: Demonstration of successful Feint behavior with proper length
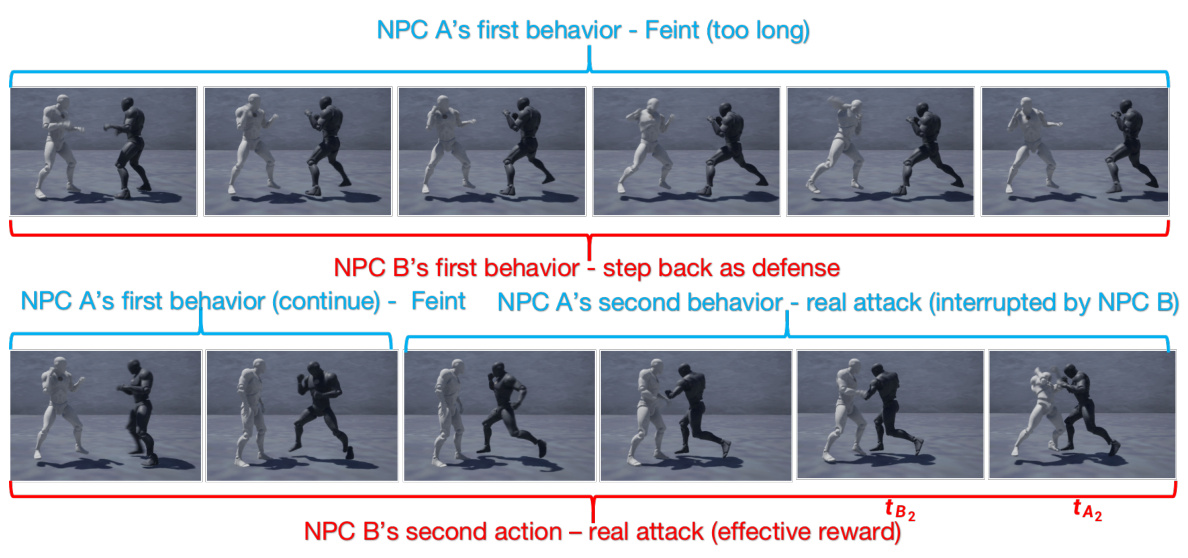
🔼 This figure shows an example of unsuccessful Feint behavior due to its long duration. The timeline is divided into three key time points: tB1 (end of NPC B’s first defense behavior), tA2 (estimated start of NPC A’s second behavior’s reward), and tB2 (estimated start of NPC B’s second behavior’s reward). In this case, tA2 > tB2 which means NPC B has already started its second behavior before NPC A’s second behavior even starts. Therefore, NPC B’s real attack interrupts NPC A’s attack which leads to NPC A’s unsuccessful Feint behavior.
read the caption
Figure 9: Demonstration of unsuccessful Feint behavior when its too long

🔼 This figure shows the full set of 22 behavior (action sequences) used in the boxing game simulation. The behaviors are categorized into four types: offensive, defensive, reaction, and transition. Each category contains several different action sequences, providing a rich set of actions for the agents in the game.
read the caption
Figure 10: The full set of 22 behavior (action sequences) of a boxing game from Mixamo.

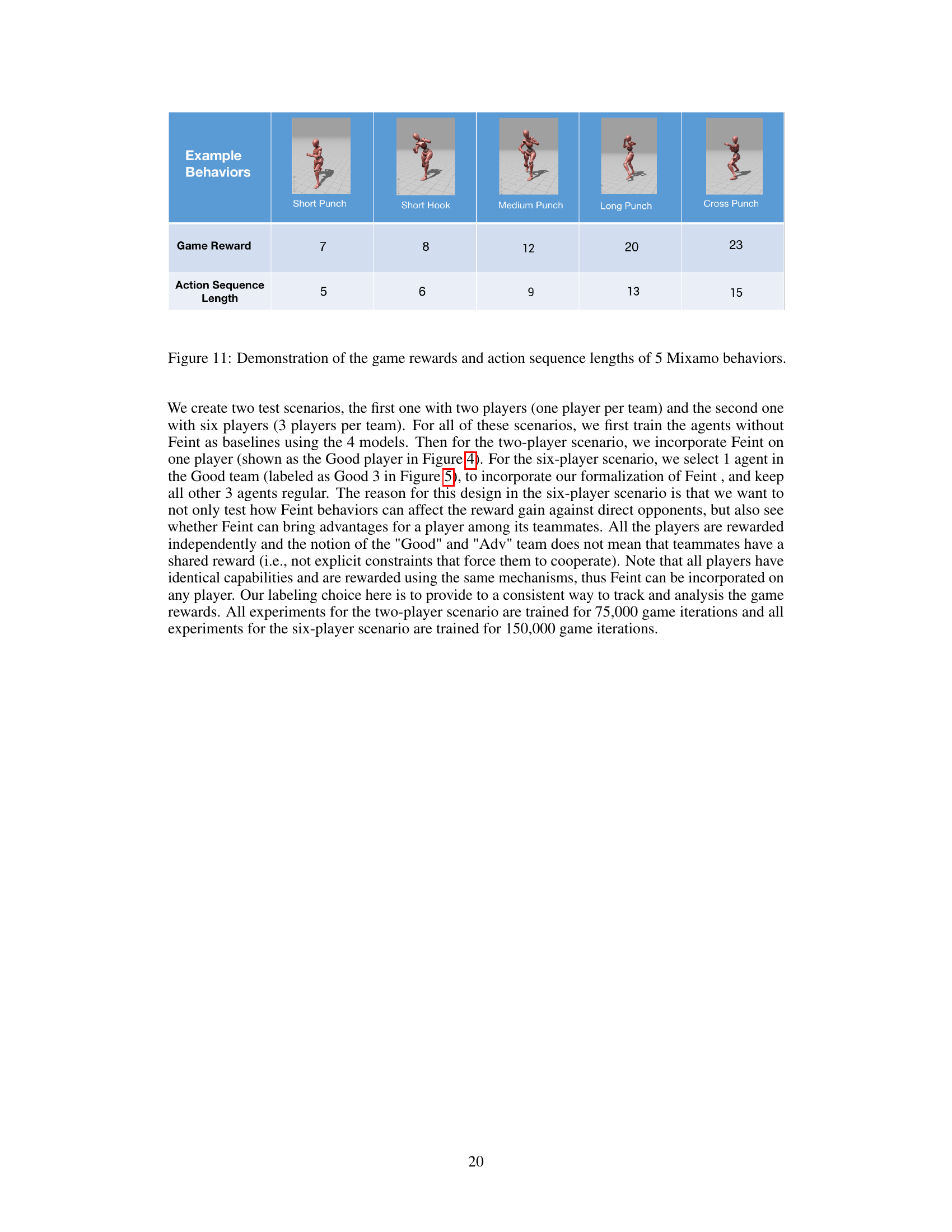
🔼 This figure shows five example behaviors from the Mixamo dataset used in the paper’s boxing game simulation. Each behavior is depicted visually, along with its associated game reward and the number of action sequences it comprises. This illustrates the variety of behaviors and their associated reward values used in the training and evaluation of the Feint strategy.
read the caption
Figure 11: Demonstration of the game rewards and action sequence lengths of 5 Mixamo behaviors.
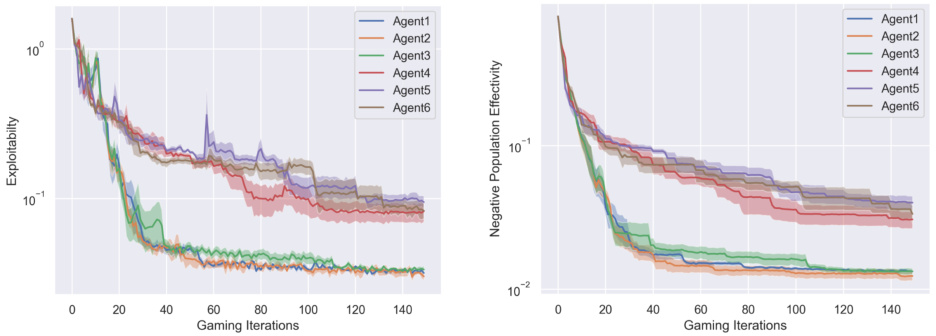
🔼 This figure shows the results of a comparative study between MARL training with and without Feint in AlphaStar games. Exploitability measures how far a joint policy is from Nash Equilibrium, indicating diversity gains. Population Efficacy (PE) measures diversity of the whole policy space. The results show that agents using Feint achieve lower Exploitability and higher PE (less negative), indicating increased diversity and effectiveness of the policy space.
read the caption
Figure 12: Diversity gain for agents, in terms of the exploitablity and the negative population efficacy.
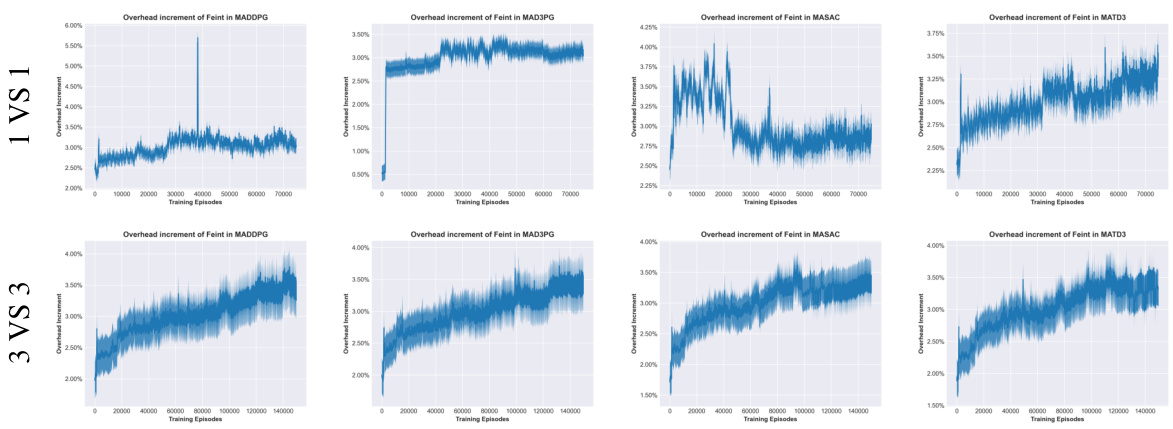
🔼 This figure shows the overhead incurred by incorporating Feint into four different multi-agent reinforcement learning (MARL) models across two scenarios: 1 vs 1 and 3 vs 3. The overhead is presented as a percentage increase in computation time. The figure illustrates that while there is some overhead in all cases, it generally remains under 5%, suggesting that the addition of Feint behaviors does not significantly impact computational efficiency.
read the caption
Figure 13: Overhead of Feint in the 1 VS 1 and 3 VS 3 scenarios using 4 MARL models.
Full paper#