↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many large language models (LLMs) exist, each with varying accuracy, cost, and latency. Users often face a challenge: selecting the right model and prompt for each question to meet accuracy goals while staying within a budget. Existing methods often lack a unified approach to handle the accuracy-cost trade-offs efficiently and dynamically.
TREACLE, a reinforcement learning-based framework, tackles this problem head-on. By leveraging contextual information such as question text embedding and response history, TREACLE intelligently chooses the most cost-effective LLM and prompt for each question, ensuring high accuracy while staying within budget. Its effectiveness is demonstrated through evaluations on various reasoning datasets, showing significant cost savings and robust performance across different scenarios, including changes in LLM prices and the introduction of new models.
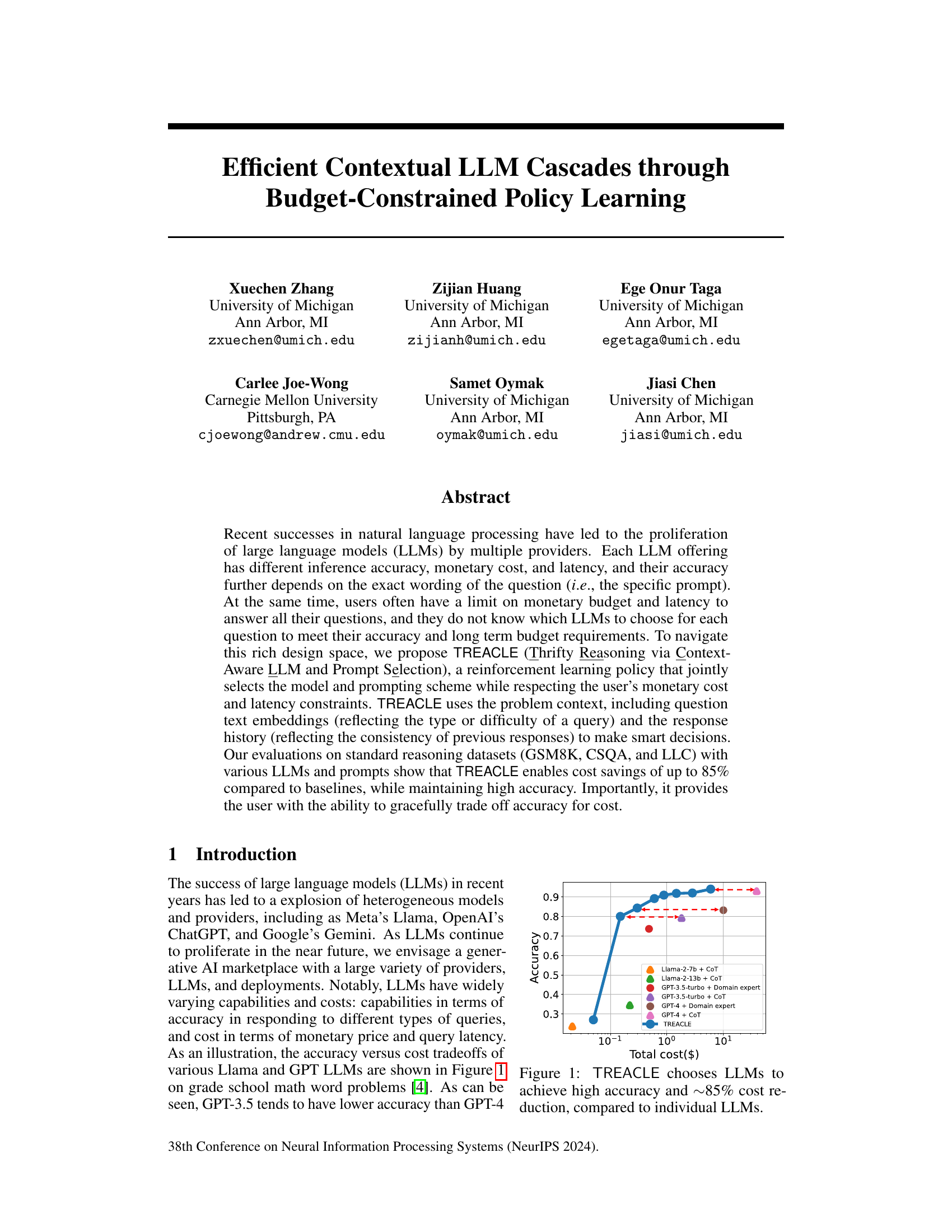
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it directly addresses the critical challenge of cost optimization while maintaining accuracy. It introduces a novel reinforcement learning framework that allows for intelligent selection of models and prompts, a significant advancement in efficient LLM usage. Furthermore, its robustness to various factors like price changes and new model releases makes it highly relevant to the ever-evolving LLM landscape, paving the way for more practical and cost-effective LLM applications.
Visual Insights#

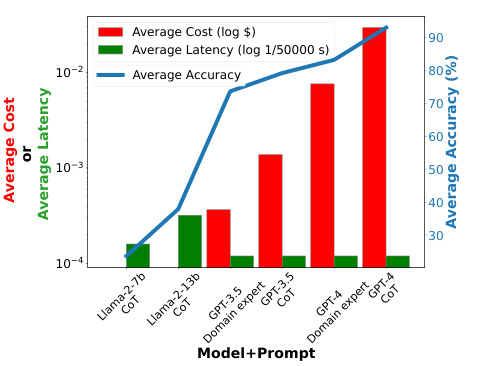
This figure shows the accuracy vs. total cost ($) for different LLMs and prompting methods on a specific task (likely mathematical reasoning problems based on the paper). Each point represents a different combination of LLM (Llama-2-7b, Llama-2-13b, GPT-3.5-turbo, GPT-4) and prompt style (Chain-of-Thought, domain expert). The blue line represents the performance of TREACLE, a reinforcement learning policy that dynamically selects the optimal LLM and prompt combination to maximize accuracy while respecting a cost budget. The figure demonstrates that TREACLE achieves significantly higher accuracy than individual LLMs at a much lower cost, highlighting its efficiency in selecting LLMs.

This table compares TREACLE with three other related works in terms of their usage of query embedding, response consistency, prompt and LLM selection, long-term budget, and robustness to new models. A checkmark indicates that the method includes that specific feature or capability. The table highlights that TREACLE uniquely combines several key features not found in any single prior work.
In-depth insights#
Cost-Aware LLMs#
Cost-aware LLMs represent a significant advancement in large language model (LLM) technology, addressing the critical issue of high computational expense. Traditional LLMs often incur substantial costs for inference, hindering their accessibility and scalability. Cost-aware models tackle this by integrating cost considerations directly into the model architecture or inference process. This might involve techniques like model selection based on predicted accuracy and cost, efficient prompt engineering to minimize token usage, or employing a cascade of LLMs with varying costs and accuracies. The goal is to achieve a desired level of accuracy while minimizing overall expenditure. This approach is crucial for real-world deployment, allowing the responsible and sustainable use of LLMs across diverse applications. Furthermore, research in this area could lead to improved efficiency in training LLMs, reducing their environmental impact and making them more accessible to researchers and developers with limited resources. Future work may focus on developing more sophisticated cost models, incorporating factors beyond monetary cost (such as latency and carbon footprint), and exploring novel architectures optimized for cost-effectiveness.
Prompt Engineering#
Prompt engineering plays a crucial role in effectively utilizing large language models (LLMs). Careful crafting of prompts significantly impacts the accuracy and efficiency of LLM responses, influencing both the quality of the output and the computational cost. The paper highlights the importance of prompt selection in achieving optimal cost-accuracy trade-offs by exploring different prompting strategies, such as standard prompts, domain expert prompts, and chain-of-thought (CoT) prompting. The results demonstrate that the choice of prompt is highly context-dependent and requires a sophisticated approach, such as that implemented by the TREACLE framework, to make informed decisions based on the question type, available budget, and past response history. Furthermore, prompt engineering’s influence extends beyond cost savings, impacting the overall effectiveness of LLM cascades and the ability to handle variations in question difficulty and newly introduced models. Therefore, a robust approach to prompt engineering, like the one presented, is vital to maximizing the potential of LLMs in a resource-constrained environment.
RL Policy Learning#
Reinforcement learning (RL) policy learning for efficient contextual large language model (LLM) cascades is a powerful technique. The core idea is to train a policy that intelligently selects the optimal LLM and prompt for each question, maximizing accuracy while adhering to budget and latency constraints. This involves a sophisticated state representation encompassing response history, question embeddings, and remaining resources. The RL agent learns to balance the accuracy gains of more powerful (and costly) LLMs against the cost-effectiveness of cheaper alternatives. This approach is particularly valuable given the heterogeneity of LLMs and the strong influence of prompt engineering on accuracy. The use of context is crucial, enabling the agent to adapt to different question types and difficulties. A well-designed RL framework can lead to significant cost savings compared to simpler selection strategies while maintaining high accuracy. Further research could explore more advanced RL algorithms and richer state representations to enhance performance and adaptability.
Robustness & Scalability#
A robust and scalable system should gracefully handle various conditions and increasing workloads. Robustness implies the system’s resilience to unexpected inputs, errors, or variations in the operating environment. This might involve error handling mechanisms, input validation, and the ability to recover from failures. Scalability, on the other hand, focuses on the system’s capacity to adapt to growing demands. This includes efficient resource utilization and architecture that can handle increased data volumes, user traffic, or computational complexity. For a research paper, demonstrating both robustness and scalability is crucial; it enhances the system’s reliability and ensures its practical applicability across diverse settings. The paper should thoroughly assess the system’s behavior under various stress tests and configurations, providing compelling evidence of its stability and capacity to manage increasing workloads without performance degradation.
Future of TREACLE#
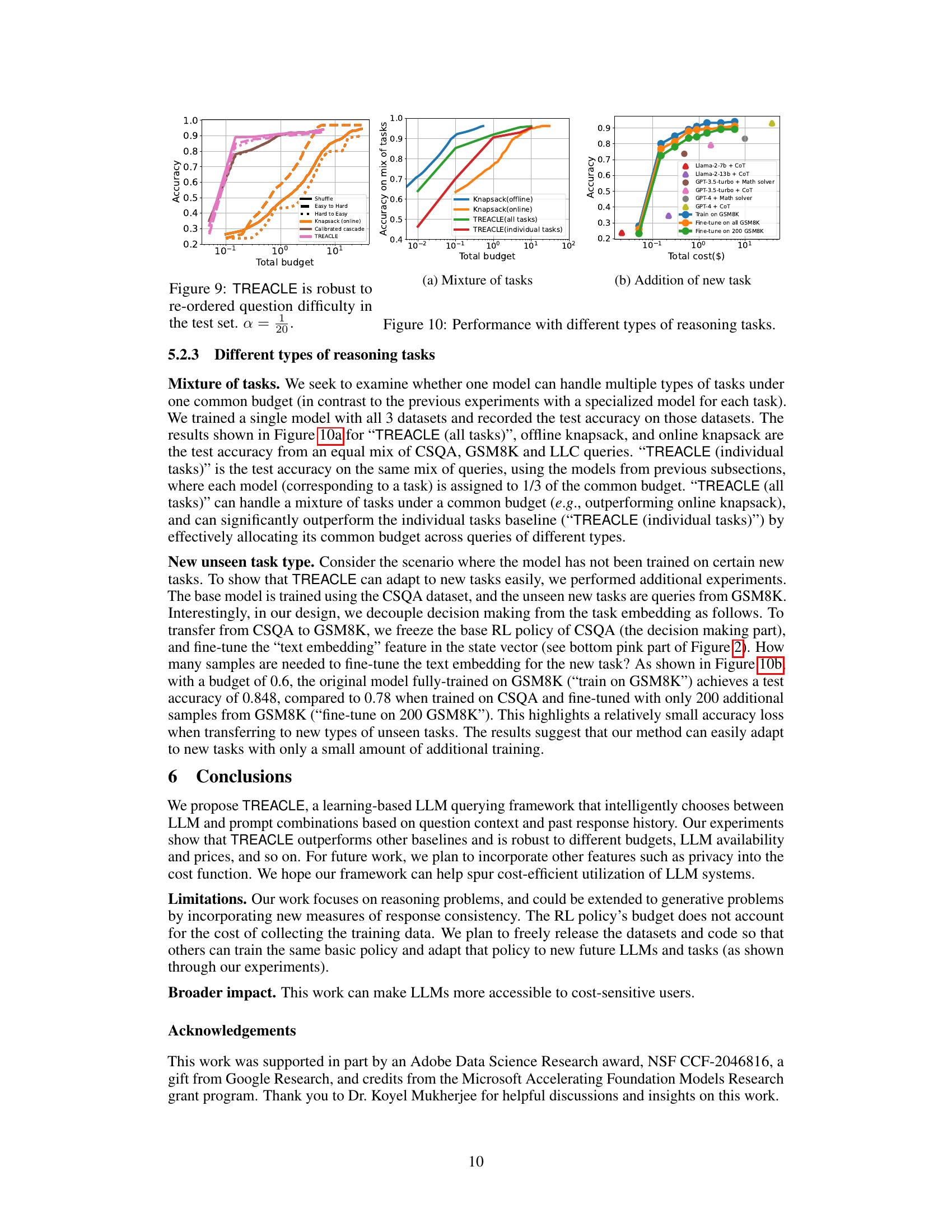
The future of TREACLE hinges on several key areas. Extending its capabilities to handle diverse reasoning tasks beyond those currently evaluated is crucial. This includes tackling more complex questions requiring deeper understanding and potentially integrating external knowledge sources. Improving the efficiency of the reinforcement learning policy is vital to minimize training time and computational costs, perhaps by exploring more efficient RL algorithms or leveraging transfer learning techniques. Addressing the challenge of evolving LLM landscapes is important – TREACLE must seamlessly adapt to new models and pricing schemes. This might involve developing a more robust model selection strategy, possibly incorporating techniques for continuous learning. Enhanced prompt engineering techniques could further improve performance, potentially by automatically crafting prompts tailored to specific LLMs and questions or integrating techniques such as chain-of-thought prompting more effectively. Finally, investigating theoretical guarantees on the performance of TREACLE is a critical next step to build stronger trust and confidence in its predictions.
More visual insights#
More on figures
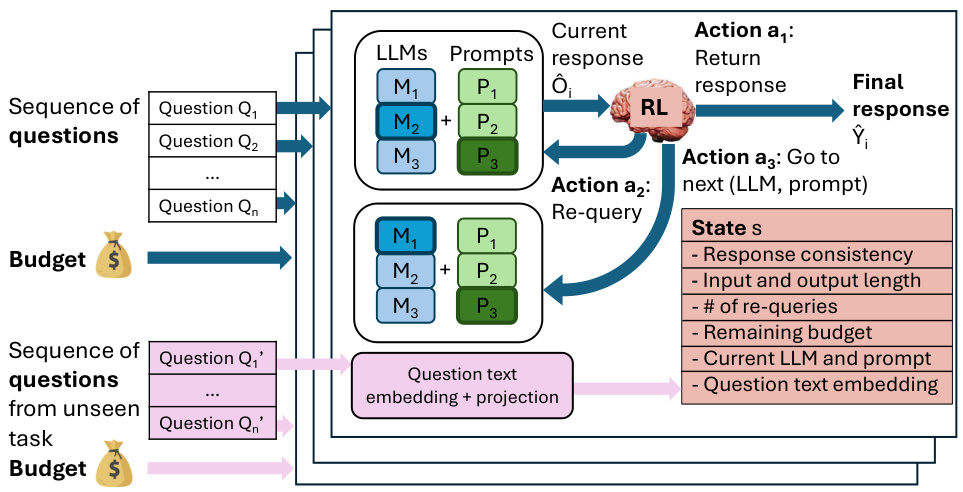
This figure illustrates the TREACLE framework’s workflow. It shows how TREACLE takes in a sequence of questions and a budget, and uses a reinforcement learning (RL) policy to select the optimal large language model (LLM) and prompt for each question. The selection is based on the current state, which includes response consistency, input/output lengths, the remaining budget, the current LLM and prompt, and a text embedding of the question. The framework also demonstrates its ability to handle new, unseen question types by projecting these into the existing text embedding space.
This figure compares the performance of TREACLE against several baselines across different cost functions (pure monetary price and price-latency tradeoffs) and budget constraints. It showcases how TREACLE adapts to various cost structures and budgets while maintaining high accuracy. The dashed lines represent methods with unrealistic perfect knowledge of which models are best for which question, serving as upper bounds for comparison. The plot shows accuracy on the y-axis and total budget on the x-axis, illustrating the accuracy-cost tradeoff for each method.
This figure compares the performance of TREACLE against several baselines across different cost functions and budget constraints. The x-axis represents the total budget, and the y-axis represents the accuracy achieved. Multiple lines show the performance for each method (TREACLE, Majority vote, Knapsack (online), Knapsack (offline), Single model, FrugalGPT, Calibrated cascade) under varying budgets and cost functions (pure monetary and monetary price-latency combination). The dashed lines represent theoretical upper bounds that assume perfect knowledge of question difficulty and cost which is not feasible in real-world scenarios. The figure demonstrates that TREACLE outperforms the baselines in most scenarios, approaching the theoretical optimum with higher budgets.
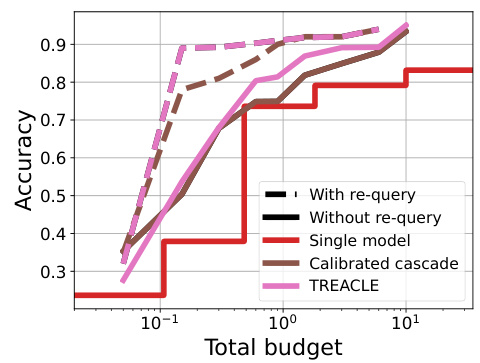
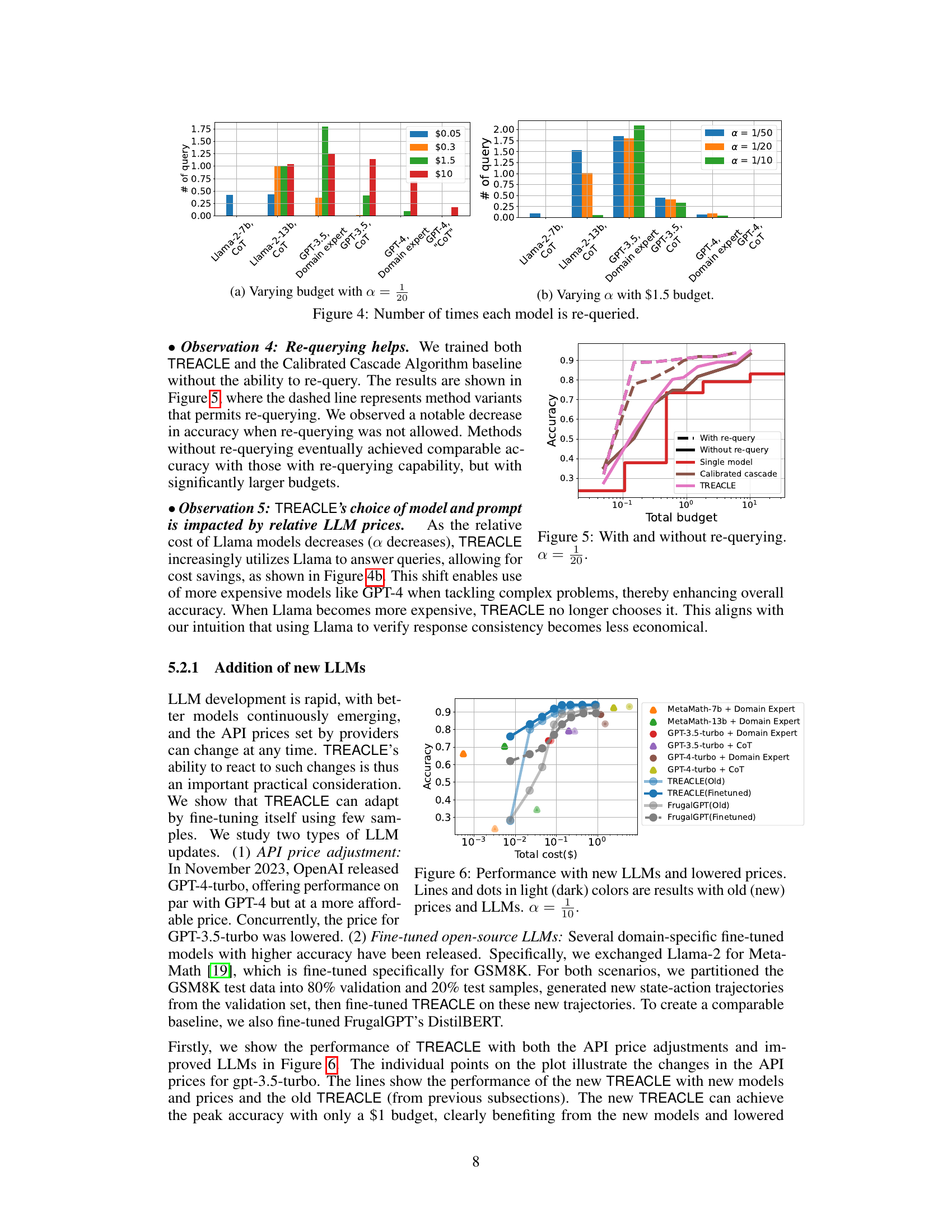
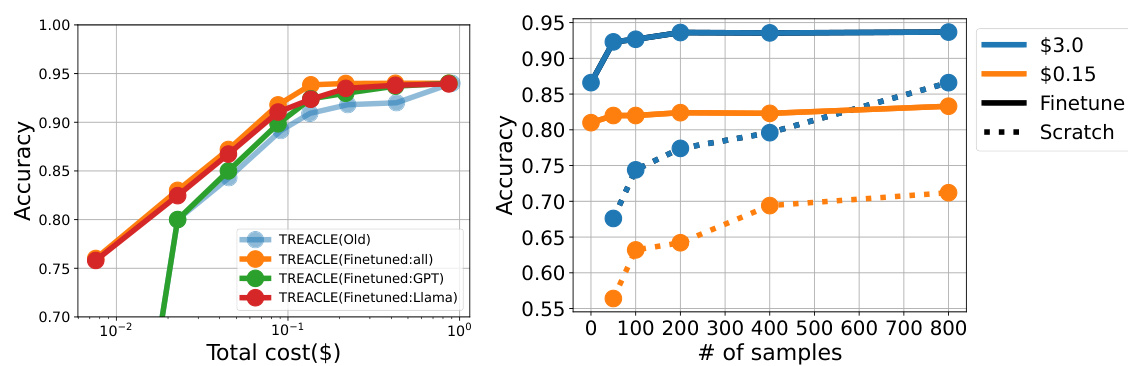
This figure compares the performance of TREACLE with and without the ability to re-query. The dashed lines represent model variants that permit re-querying, while the solid lines show models that do not allow re-querying. The figure shows that without re-querying, accuracy is significantly lower, especially at lower budgets. Only with significantly larger budgets do models without re-querying achieve comparable accuracy to those with re-querying, highlighting the importance of the re-querying mechanism for maintaining high accuracy while saving cost.
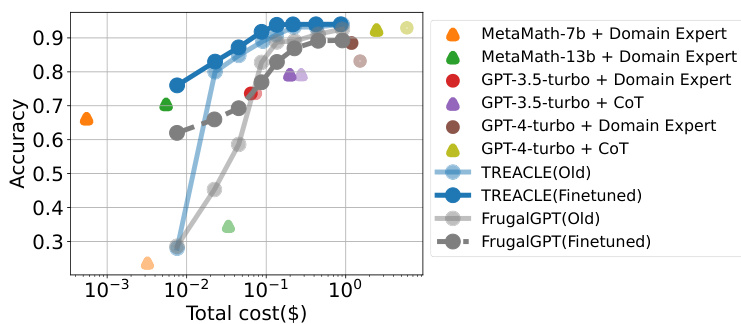
This figure shows the performance of various models (including TREACLE and FrugalGPT) before and after fine-tuning with new LLMs (MetaMath and GPT-4-turbo) and adjusted pricing. The x-axis represents the total cost, and the y-axis represents the accuracy. It demonstrates TREACLE’s adaptability to new models and price changes, showing that after fine-tuning, it achieves higher accuracy with a lower budget compared to both its previous version and FrugalGPT. Light colors represent the performance before the update, while dark colors represent the performance after updating with the new models and prices.
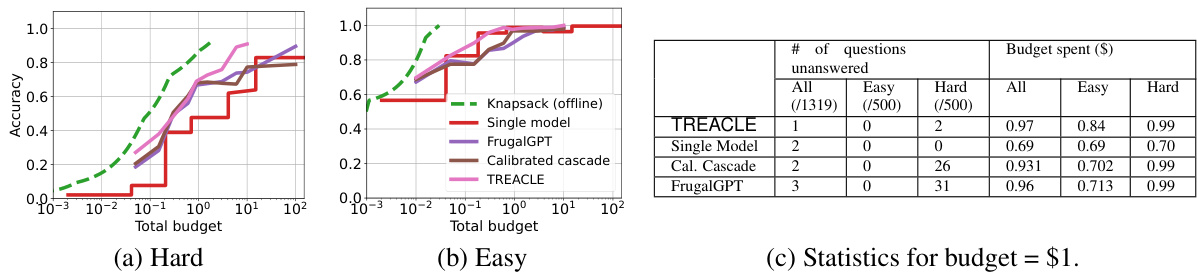
This figure compares the performance of TREACLE against several baseline methods across various cost functions and budget levels. The x-axis represents the total budget, while the y-axis shows the accuracy achieved. Different lines represent different methods: TREACLE, FrugalGPT, a calibrated cascade approach, an offline and online knapsack algorithm, and a single model. The dashed lines represent methods that have perfect knowledge of the optimal cost-accuracy tradeoff (offline knapsack), showcasing the upper bound for performance. The results demonstrate that TREACLE consistently outperforms the other methods, approaching the performance of the offline knapsack, which is not feasible in a real-world setting.

This figure compares the performance of TREACLE against several baseline methods under various budget constraints and cost functions. The x-axis represents the total budget, and the y-axis represents the accuracy. Different lines represent different methods: TREACLE, FrugalGPT, a calibrated cascade, an online knapsack, an offline knapsack, and a single model. The dashed lines show the performance of methods with perfect (offline) knowledge of the ideal model and prompt choices for each question, which is not feasible in reality but provides an upper bound on performance. The figure shows that TREACLE consistently outperforms the baselines in most scenarios, achieving accuracy close to the theoretical optimum (offline knapsack), especially when budgets are more constrained.
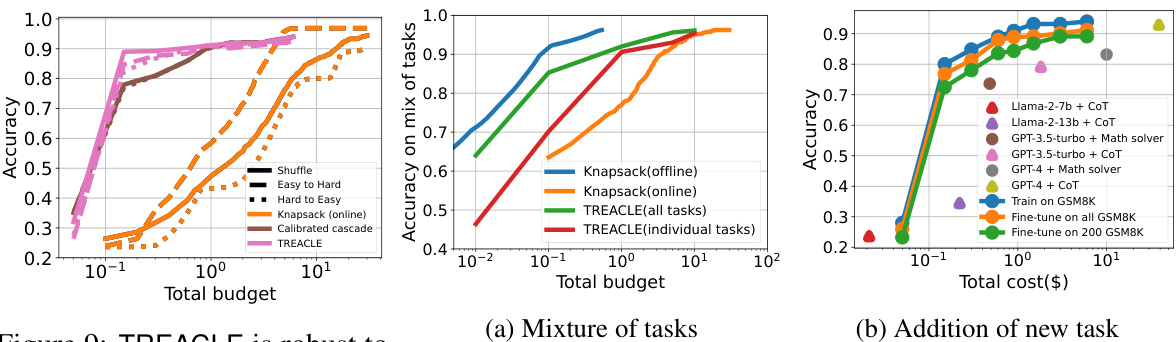
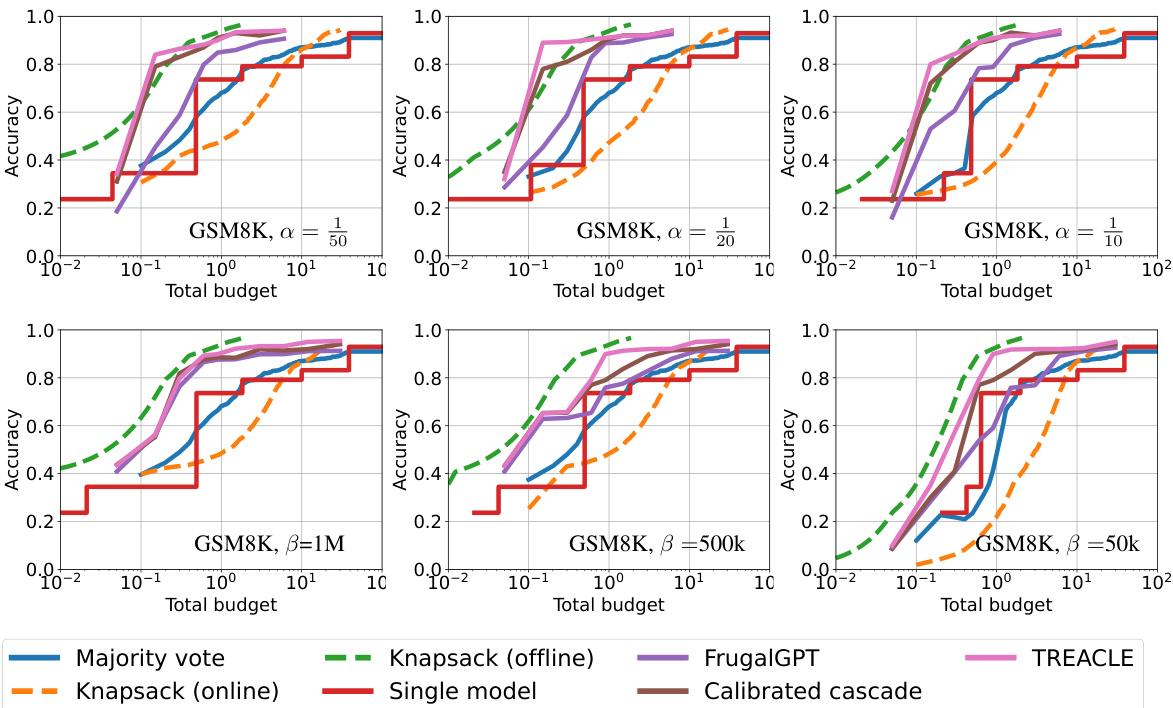
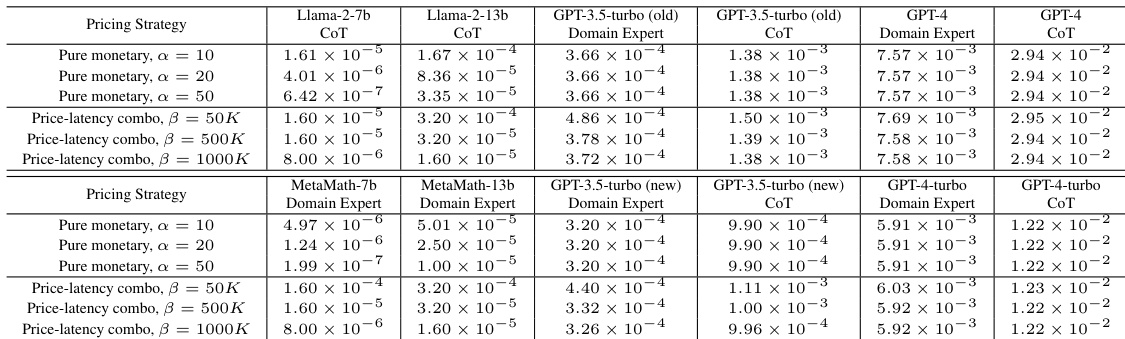
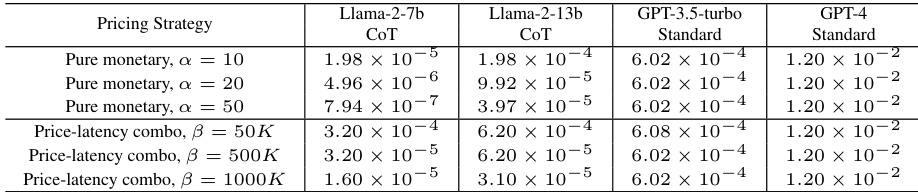
This figure compares the performance of TREACLE against several baseline methods across three different datasets (GSM8K, CSQA, and LLC) under various budget constraints and cost functions. The cost functions consider pure monetary cost (with different scaling factors α) and a combination of monetary and latency cost (with different tradeoff coefficients β). The x-axis shows the total budget, and the y-axis represents the accuracy achieved. The figure highlights that TREACLE consistently outperforms the baselines and approaches the performance of the offline knapsack method (which has access to perfect knowledge of question difficulty and costs, making it impractical in real-world scenarios).
This figure displays the performance of different methods for various cost functions and budget constraints. The x-axis represents the total budget, and the y-axis represents the accuracy achieved. Several methods are compared: Majority Vote, Knapsack (online and offline), Single model, FrugalGPT, Calibrated Cascade, and TREACLE. The dashed lines represent methods with perfect knowledge (ground truth) of the best model to use, which provides a theoretical upper bound for performance. The plot shows that TREACLE consistently outperforms the other baselines and approaches the performance of the impractical ground-truth methods. The plot is shown across multiple cost functions (α=1/50, 1/20, 1/10, and β=50k, 500k, 1M). Each of these represents different trade-offs between accuracy and monetary cost, showing the robustness of TREACLE.
This figure compares the performance of different methods for answering questions under various cost functions and budget constraints. The x-axis represents the total budget, while the y-axis shows the accuracy. Several methods are compared, including TREACLE, FrugalGPT, and various baseline methods. The dashed lines represent methods that have access to perfect knowledge (ground truth), which is not practical but serves as an upper bound on performance. The plot shows how TREACLE achieves high accuracy while saving on cost, outperforming other methods, especially under tighter budgets. The results are shown for different cost functions, demonstrating TREACLE’s robustness and adaptability.
This figure shows the accuracy vs. cost trade-offs of various Llama and GPT LLMs on grade school math word problems. The x-axis represents the total cost in dollars, and the y-axis represents the accuracy of the models. The different colored lines represent different LLMs and prompting schemes. The TREACLE line shows that the proposed approach achieves high accuracy at a significantly lower cost compared to the individual LLMs and prompting schemes. It essentially finds the Pareto optimal frontier between cost and accuracy.
This figure compares the performance of different methods for solving reasoning problems under various budget constraints and cost functions. The x-axis represents the total budget, and the y-axis represents the accuracy achieved. Multiple lines represent different methods: TREACLE (the proposed method), Majority Voting, Offline and Online Knapsack (theoretical optimal methods with complete knowledge of all costs and benefits), FrugalGPT, and Calibrated Cascade. The dashed lines represent theoretical upper bounds using offline methods that have access to perfect knowledge. The plot shows that TREACLE consistently outperforms other methods, approaching the performance of offline knapsack methods (which are impractical in real settings). The performance is shown for GSM8K across different cost parameterizations (α and β).
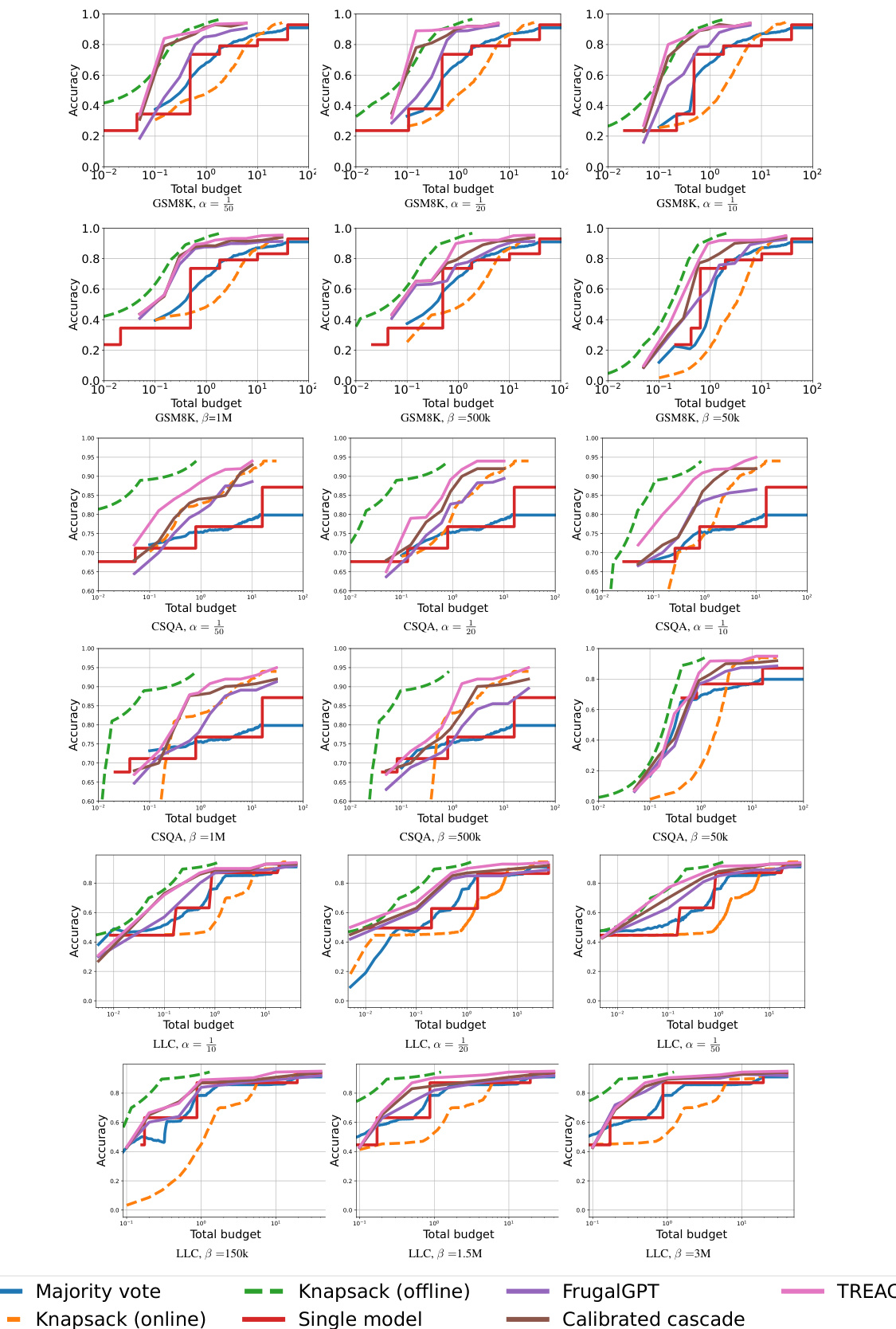
This figure compares the performance of different methods for solving reasoning problems under various cost constraints and functions. The x-axis represents the total budget allocated, and the y-axis represents the accuracy achieved. The methods compared include TREACLE, FrugalGPT, a calibrated cascade, majority voting, and both online and offline knapsack approaches (the latter two having perfect knowledge of optimal costs). For each method, multiple lines are shown, each corresponding to a different cost function (pure monetary cost with varying coefficients, and combinations of monetary cost and latency). The dashed lines represent upper bounds on performance achievable if one had perfect knowledge of optimal costs which is generally not realistic.
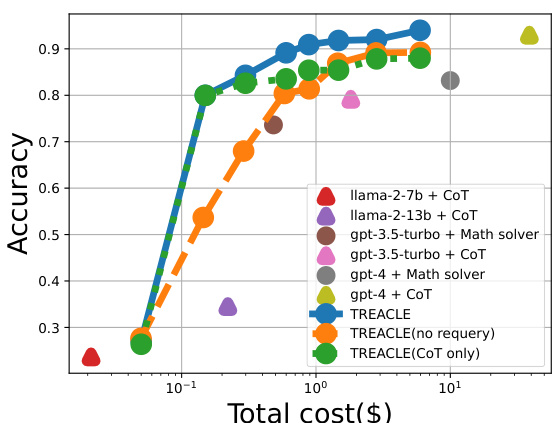
This figure shows the accuracy vs. total cost of various LLMs (Llama-2-7b, Llama-2-13b, GPT-3.5-turbo, GPT-4) using different prompting strategies (Chain-of-Thought (CoT), domain expert) on a specific task (grade-school math problems). It highlights that TREACLE, the proposed method, significantly reduces cost while maintaining high accuracy by intelligently selecting the most cost-effective LLM and prompting scheme for each question. The Pareto front formed by TREACLE demonstrates its superior performance compared to using individual LLMs alone.
This figure compares the performance of TREACLE against several baseline methods across various cost functions and budget constraints. The x-axis represents the total budget, and the y-axis represents the accuracy achieved. Different lines represent different methods, including TREACLE, a simple single model approach, FrugalGPT, and a calibrated cascade method. The dashed lines represent theoretical optimal methods (offline and online knapsack) that have access to perfect information about the accuracy and cost of each model. The figure shows that TREACLE consistently outperforms other methods across different budgets and cost functions.
More on tables

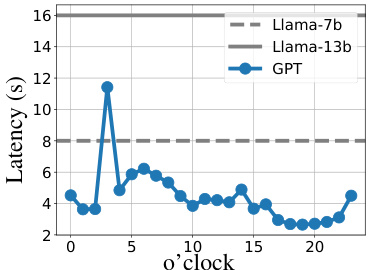
This table compares the accuracy of TREACLE and the Calibrated Cascade method under two scenarios: one with time-varying API latency and one with constant latency. It shows that TREACLE is more robust to fluctuating latency, maintaining higher accuracy than the Calibrated Cascade approach which assumes constant latency. The ‘Update time’ column indicates how long it takes to adjust for the changed latency for each method.
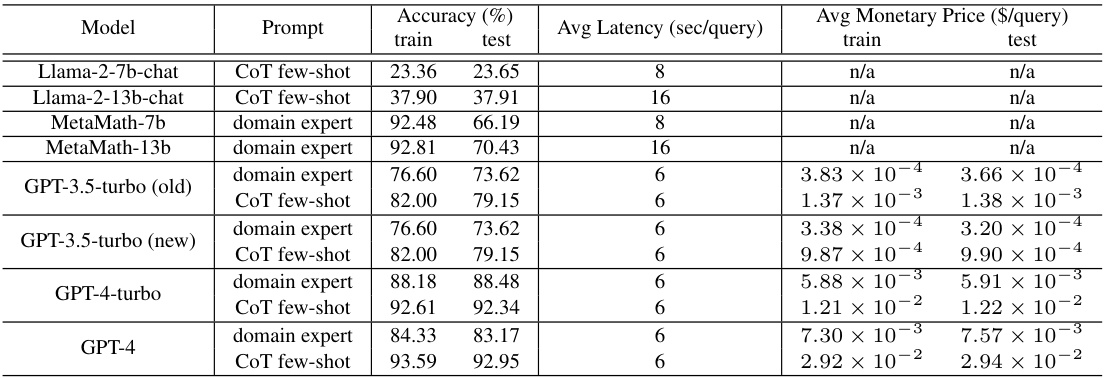
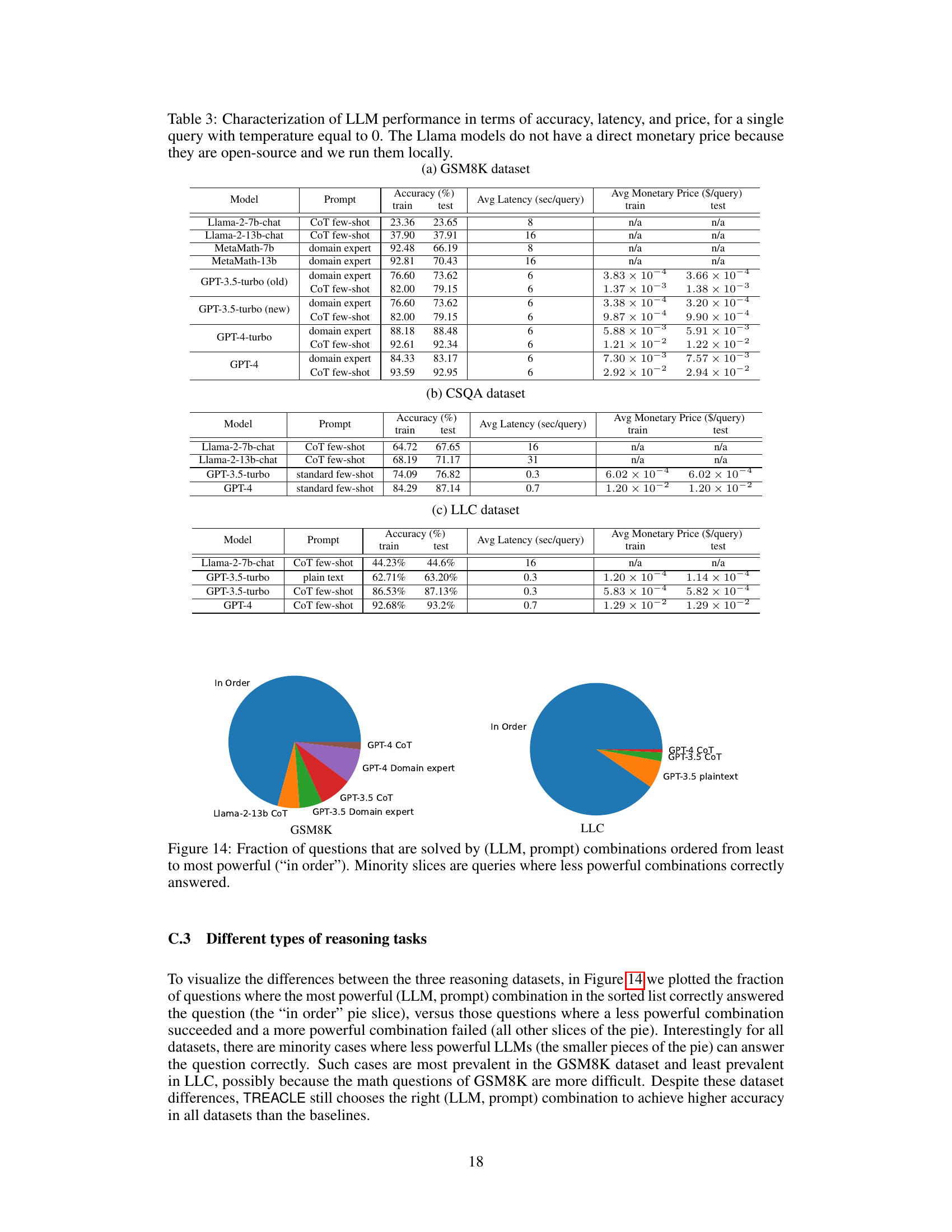
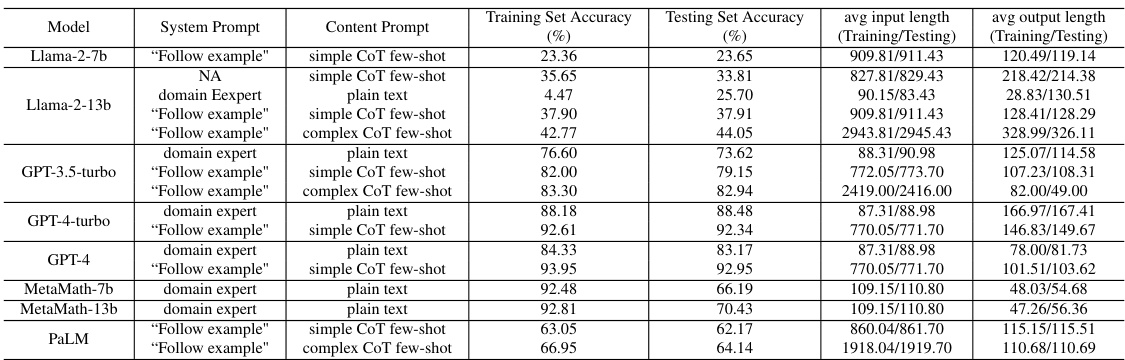
This table presents the performance of different LLMs and prompting strategies on three datasets (GSM8K, CSQA, LLC). For each model and prompt, it shows the accuracy achieved on training and test sets, average latency per query, and average monetary price per query. Note that Llama models don’t have a monetary price since they’re open source and run locally. This table provides a quantitative basis for comparing and selecting models based on their accuracy, cost, and latency trade-offs.

This table presents the performance of different LLMs across three datasets (GSM8K, CSQA, LLC) using three different prompting strategies (plain text, domain expert, CoT). For each LLM and prompt combination, it shows the training and testing accuracy, average query latency, and average monetary price. Note that the Llama models do not have a monetary price as they are open-source and run locally.

This table presents the performance of different LLMs (Llama and GPT variants) on three different datasets (GSM8K, CSQA, and LLC). For each LLM and dataset, the table shows the accuracy, average latency, and average monetary price for a single query with temperature set to 0. Note that Llama models don’t have a direct monetary price because they are open source and run locally. The table is useful for understanding the trade-offs between accuracy, latency, and cost across different LLMs and for different reasoning tasks.
This table presents the performance of different LLMs across three datasets (GSM8K, CSQA, LLC) using different prompting strategies. For each LLM and prompt type, it shows the accuracy achieved on the training and test sets, the average latency per query, and the average monetary price per query. Note that the Llama models do not have a direct monetary price as they are open-source and run locally.
This table presents the performance of different LLMs (Llama-2-7b, Llama-2-13b, GPT-3.5-turbo, GPT-4, and MetaMath) across three datasets (GSM8K, CSQA, LLC) using various prompting strategies (plain text, domain expert, and CoT few-shot). For each LLM and prompt combination, the table lists the accuracy, average latency (in seconds per query), and average monetary price (in dollars per query). Note that Llama models are open-source and thus do not incur a direct monetary cost, unlike the GPT models which utilize commercial APIs.

This table presents the performance of different LLMs (Llama and GPT variants) across three datasets (GSM8K, CSQA, LLC) using three different prompting strategies (plain text, domain expert, chain-of-thought). For each LLM and prompt combination, the average accuracy, latency, and monetary price (where applicable) are reported for both the training and test sets. The table highlights the varied capabilities and costs associated with different LLMs and prompting approaches.
This table presents the performance of different LLMs and prompting strategies on three datasets (GSM8K, CSQA, LLC). For each model and prompt combination, it lists the training and testing accuracy, average latency per query, and average monetary price per query. Note that the Llama models do not have a monetary price because they are open-source and run locally. The table helps to understand the trade-offs between accuracy, latency, and cost for various LLMs and prompting strategies, providing essential data for the TREACLE model’s decision-making process.
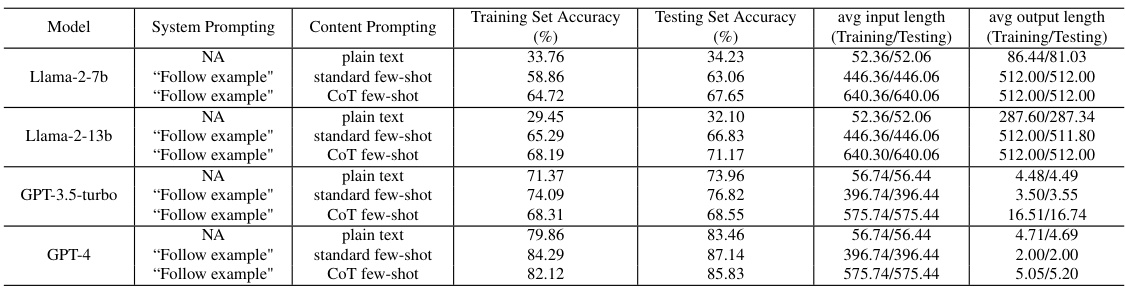
This table presents the performance of different LLMs on three datasets (GSM8K, CSQA, LLC) using three different prompting strategies (plain text, standard few-shot, CoT few-shot). For each LLM and prompt combination, the table shows the training and testing accuracy, average latency, and average monetary price per query. Note that the Llama models do not have a direct monetary price because they are open-source and run locally.

This table presents the performance of different LLMs (Llama and GPT variants) on three different datasets (GSM8K, CSQA, LLC). For each LLM, three different prompts are used (plain text, domain expert, and CoT). The table shows the accuracy, average latency, and average monetary price for each LLM-prompt combination. The Llama models are open-source and run locally, so they do not have a direct monetary price.
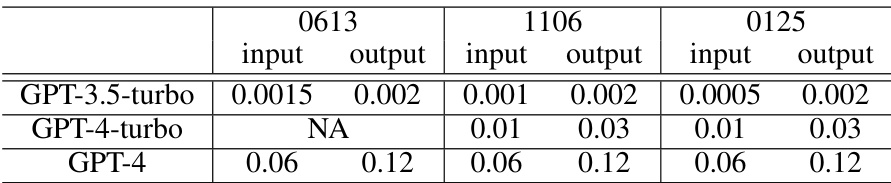
This table presents the performance of different LLMs (Llama and GPT variants) on three reasoning datasets (GSM8K, CSQA, and LLC). For each LLM and dataset, it shows the accuracy, latency, and price (where applicable) of using a single query with a temperature of 0. The table highlights the trade-offs between accuracy, latency, and cost for different models and datasets. Note that the Llama models are open source and run locally, so they do not have a direct monetary price.

This table presents a quantitative comparison of various LLMs across three different reasoning datasets (GSM8K, CSQA, and LLC). For each LLM and dataset combination, the table lists the average accuracy, latency, and monetary price (where applicable) observed when answering a single query with temperature set to 0. The results offer insights into the tradeoffs between accuracy, speed, and cost of different LLMs. Note that Llama models do not have a direct monetary price because they are open-source and were run locally.

This table presents the performance characterization of different LLMs (Llama and GPT variants) across three datasets (GSM8K, CSQA, LLC) using three different prompting strategies (plain text, domain expert, CoT). For each LLM and prompt combination, the table provides the training and testing accuracy, average latency per query, and average monetary price per query. Note that the Llama models do not have a direct monetary price since they are open-source and run locally.

This table presents the performance of different LLMs (Llama and GPT variants) on three different datasets (GSM8K, CSQA, LLC). For each LLM and dataset, it shows the accuracy, average latency, and average monetary price (for GPT models only) for a single query with a temperature of 0. The Llama models are open-source and run locally, so their monetary price is not applicable.

This table presents the performance of different LLMs (Llama and GPT variants) on three datasets (GSM8K, CSQA, LLC) using three different prompting strategies (plain text, domain expert, and chain-of-thought). For each LLM and prompt combination on each dataset, the table lists the accuracy, average latency, and monetary price (where applicable) of a single query with a temperature setting of 0. The Llama models are open source and run locally, so they don’t have a direct monetary cost. This data helps to quantify the accuracy-cost-latency tradeoffs of various LLMs and prompts that are relevant to the paper’s proposed TREACLE framework.

This table presents a comprehensive characterization of various Large Language Models (LLMs) across three different datasets (GSM8K, CSQA, LLC). For each LLM and dataset, it details the accuracy achieved on training and testing sets, the average latency experienced per query, and the average monetary price (where applicable). The table highlights the trade-offs between accuracy, latency, and cost, crucial factors for selecting appropriate LLMs for various applications. The temperature parameter used for all queries was set to 0, enabling a fair comparison of the models’ baseline performance.
Full paper#