TL;DR#
Current AI models are primarily evaluated on prediction accuracy, overlooking the validity of their reasoning. This can lead to unsafe predictions, especially in high-stakes scenarios, where understanding the model’s rationale is crucial. This paper highlights the importance of achieving “double-correct” predictions—correct predictions with correct rationales. The current lack of datasets with structured rationales and suitable optimization methods makes this a major challenge.
To address this, the researchers propose a two-phase approach. First, they create a new dataset with structured rationales for visual recognition. Second, they introduce a novel rationale-informed optimization method that guides the model to generate correct rationales and localizes relevant visual evidence. Extensive experiments show that this method significantly improves both prediction accuracy and rationale correctness, outperforming state-of-the-art methods by a notable margin. This work contributes to the growing field of explainable AI, offering a significant step towards developing trustworthy AI models for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of ensuring trustworthy AI systems by focusing on the correctness of not only predictions but also the rationales behind them. This is vital for high-stakes applications where understanding the “why” is as important as the “what.” The proposed method and dataset offer a significant advancement for building safer and more reliable AI models, paving the way for future research into explainable AI and trustworthy AI.
Visual Insights#

🔼 This figure showcases two examples where large language models (LLMs) produce predictions that are either factually incorrect or based on flawed reasoning. In the first example, CLIP correctly identifies a red traffic light in an image but incorrectly attributes this identification to a cluster of red balloons in the background. The second example shows GPT-4V making an incorrect prediction (that a truck’s door is closed) based on a seemingly plausible rationale derived from visual details such as the door’s alignment with the truck’s body and the visibility of the side mirror. These examples highlight the importance of evaluating not only the accuracy of model predictions but also the validity of their underlying rationales.
read the caption
Figure 1: Unsafe prediction examples. Correct prediction, incorrect rationale: CLIP identifies a red light, but wrongly based on red balloons. Incorrect prediction, correct rationale: GPT-4V incorrectly predicts a closed door, yet based on plausible visual evidence.
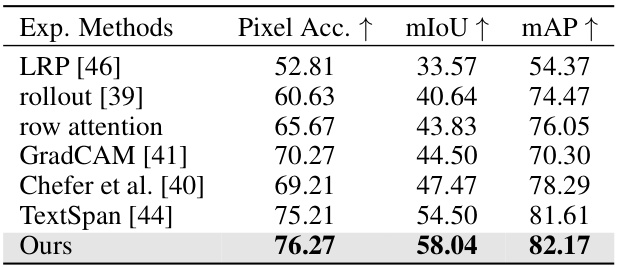
🔼 This table presents the results of a weakly-supervised segmentation task performed on the ImageNet-Seg dataset. The performance of various explanation methods is compared using three metrics: Pixel Accuracy, mean Intersection over Union (mIoU), and mean Average Precision (mAP). The proposed method outperforms all other methods across all three metrics. This highlights the accuracy and faithfulness of the proposed explanation method.
read the caption
Table 1: Weakly-supervised segmentation accuracy on ImageNet-Seg [45]. We threshold explanation heatmaps from CLIP-ViT-L-14 as segmentation masks. Our method outperforms existing explanation methods in segmentation accuracy, demonstrating the high faithfulness of our explanations.
In-depth insights#
Rationale-Informed Optimization#
The proposed rationale-informed optimization method is a novel approach to enhance the prediction accuracy and correctness of large foundation models. Unlike existing methods that primarily focus on prediction accuracy, this approach addresses the critical aspect of rationale validity. The core idea is to guide the model’s learning process by incorporating structured rationales, thereby encouraging the model to disentangle and localize visual evidence relevant to each rationale. This is achieved without manual annotations, making it scalable and practical for large-scale datasets. The method’s effectiveness is demonstrated through extensive experiments and ablation studies, showcasing significant improvements in both prediction accuracy and rationale correctness across various tasks. This two-pronged approach—curated datasets and an optimization method—presents a significant advancement in building trustworthy and reliable large language models, particularly for high-stakes applications where the validity of the reasoning is crucial.
Double-Correct Predictions#
The concept of “Double-Correct Predictions” introduces a crucial shift in evaluating AI models, moving beyond mere accuracy to encompass the validity of the reasoning behind predictions. It argues that a truly reliable system must not only produce the correct output but also arrive at it through a sound and justifiable process. This necessitates the development of methods to assess and improve the correctness of rationales, requiring datasets with structured rationales and novel optimization techniques that encourage models to ground their decision-making in verifiable evidence. The approach’s significance lies in building trustworthy AI systems suitable for high-stakes applications, where confidence in the “how” is as important as the “what.” Achieving this requires addressing challenges like the acquisition of reliable rationales and the development of methods to gauge their correctness effectively, which is a complex undertaking with significant implications for AI safety and reliability.
Structured Rationale Dataset#
The creation of a structured rationale dataset is a crucial contribution. It addresses the limitations of existing datasets which lack the detailed reasoning behind predictions. The tree-structured format of the rationales allows for a more nuanced representation of the knowledge, capturing the complex relationships between attributes, rather than just providing simple labels. This structured approach is tailored for visual recognition tasks, making it highly relevant for the research on double-correct predictions. The use of LLMs (Large Language Models) for generating the dataset demonstrates an innovative and scalable method. However, careful quality control measures, including human and machine evaluations, are essential to ensure the reliability and accuracy of these automatically generated rationales and mitigate potential biases or hallucinations inherent in LLMs. The dataset’s size and coverage of ImageNet categories make it a valuable resource for the broader research community.
Faithful Explanation#
The concept of “Faithful Explanations” in the context of visual recognition models is crucial for building trust and ensuring safe deployment. Faithfulness implies that the explanation accurately reflects the model’s reasoning process, aligning with human understanding of visual evidence. The paper critiques existing methods, highlighting how they fail to fully capture the model’s internal workings, sometimes relying solely on attention maps which are insufficient. Instead, the proposed approach uses a novel methodology that decomposes the model’s outputs, considering contributions from all layers and attention heads to weight the importance of visual tokens. This weighted mean-ablation strategy is a key innovation for building more faithful explanations and demonstrates improvements in both accuracy and faithfulness of explanations, as evidenced by weakly-supervised segmentation experiments. By incorporating this faithful explanation mechanism, the model generates more reliable and transparent predictions, moving beyond mere accuracy towards a more comprehensive understanding of AI decision-making.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. Its primary goal is to understand the impact of each part on the overall performance, helping to isolate crucial elements and identify potential redundancies. By carefully removing features or modules one by one, researchers can isolate specific contributions and pinpoint the most impactful components for model success. In the context of a visual recognition model with explainability, an ablation study might involve removing or altering individual components (e.g., attention mechanisms, specific layers, or specific modules responsible for rationale generation) to determine how each element affects the model’s overall accuracy and the quality of its generated rationales. This process helps determine which components are essential for both predictive accuracy and fidelity of explanations and can reveal unexpected interactions between the different parts of the model. The results of ablation studies provide valuable insights into model design, leading to improved architectures and a deeper understanding of how the model makes predictions.
More visual insights#
More on figures

🔼 This figure illustrates the structure of the structured rationale dataset created for the paper. It shows examples of ontologies for three ImageNet categories: American Robin, Airliner, and Wombat. Each ontology is a tree-like structure where the root node is the category. The nodes below the root represent attributes of that category, and the leaf nodes show sub-attributes. This structured approach helps to represent the detailed reasoning process involved in visual recognition. The figure highlights that the dataset contains over 4,000 unique rationales, providing detailed reasoning for each of the 1,000 ImageNet categories.
read the caption
Figure 2: Our structured rationales capture the major attributes and their sub-attributes that lead to the recognition of objects. Our dataset offers over 4,000 unique rationales covering all 1,000 categories from ImageNet [18].
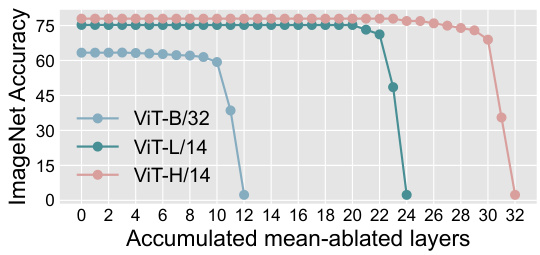
🔼 This figure shows the results of a multi-head self-attention (MSA) ablation study on Vision Transformer (ViT) models. By replacing the direct effects of MSAs up to a specific layer with their mean values (calculated across ImageNet validation set), the researchers assessed the impact on ImageNet accuracy. The plot demonstrates that most performance gains come from the final layers of the ViT architecture.
read the caption
Figure 3: Multi-head Self Attention (MSA) accumulated mean-ablation study. Based on Eq. 2, we replace the direct effects of MSAS up to a specific layer with their mean values calculated across the ImageNet [18] validation set. Most of the performance gains can be attributed to the final layers of the ViT.

🔼 This figure shows a qualitative comparison of rationale explanations generated by the CLIP model and the proposed model. The top row displays the original images and the corresponding rationales (e.g., for an American Robin, the rationales might be ‘gray wings’, ‘pointed beak’, etc.). The middle row shows the attention heatmaps generated by CLIP for each rationale. Note that CLIP’s heatmaps often highlight the entire object, rather than focusing specifically on the visual evidence relevant to a particular rationale. The bottom row shows the attention heatmaps generated by the proposed model; these heatmaps demonstrate much better localization of the evidence supporting each rationale, highlighting only the relevant parts of the image.
read the caption
Figure 4: Qualitative results of rationale disentanglement and localization. The rationales' visual evidence of the CLIP model [1] typically highlights the entire object, lacking precise localization. In contrast, our model can correctly localize rationales, thereby enhancing trust in its predictions.

🔼 This figure shows a qualitative comparison of zero-shot text-to-image retrieval results between the CLIP model and the proposed model. The task was to retrieve the top 5 images given a specific rationale (e.g., ‘a photo of long neck’, ‘a photo of wings’). CLIP’s results show a strong bias towards retrieving images of specific categories (giraffes for long necks, airplanes for wings). In contrast, the proposed model shows a more diverse and accurate retrieval, demonstrating an improved understanding of the rationales independently from the category.
read the caption
Figure 5: Qualitative results of zero-shot text-to-image retrieval on MSCOCO [66]. The task is to retrieve the top-5 images with a given rationale presented. The CLIP results reveal a significant entangle of rationales with a specific category, such as “long neck” with giraffes and “wings” with airliners. In contrast, our model treats rationales independently from categories, thus offering diverse retrieval results. For example, the “long neck” found in birds, giraffes, dears, and bottles.
More on tables
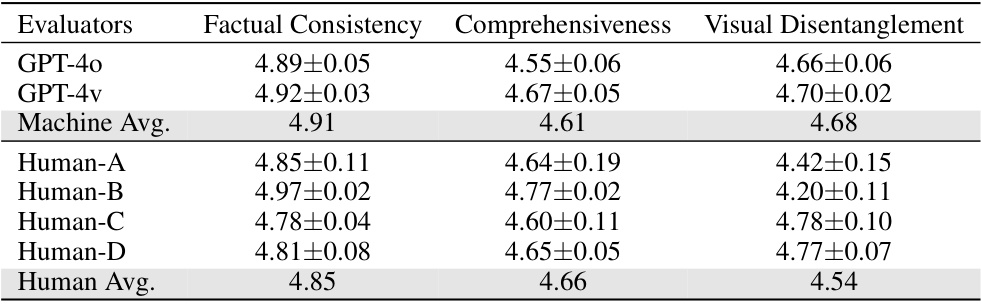
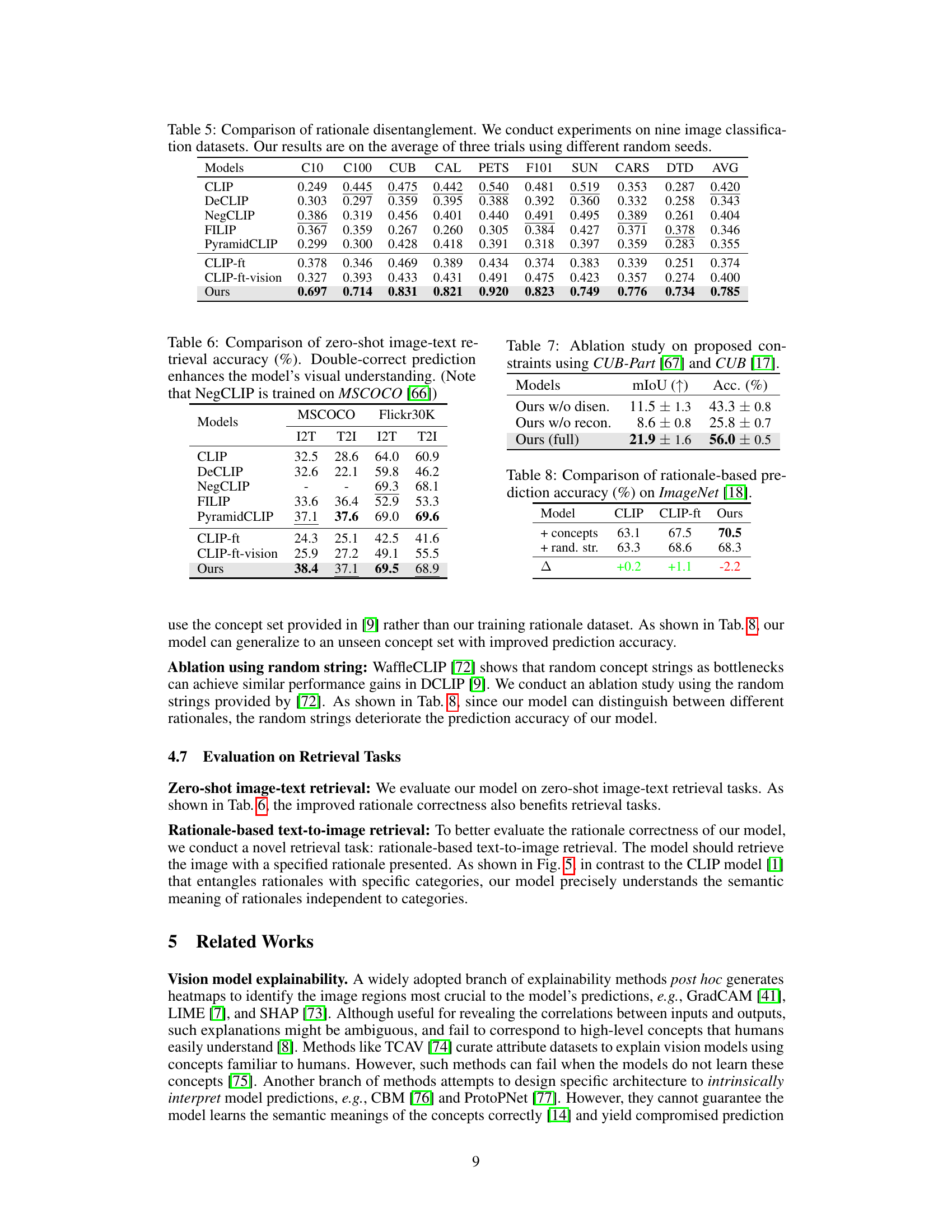
🔼 This table presents the results of a human and machine evaluation of the quality of the structured rationale dataset created by the authors. Three metrics were used to assess quality: Factual Consistency, Comprehensiveness, and Visual Disentanglement. Each metric was scored on a 5-point Likert scale by four human evaluators and two large language models (GPT-4 and GPT-4v). The results show a strong agreement between human and machine evaluations, indicating that the vast majority (over 90%) of the rationales are of high quality.
read the caption
Table 2: Evaluation results of rationale quality. Both machine and human evaluators receive the same instructions about the metrics. The scores for all three metrics are nearly identical between machine and human evaluators, indicating that over 90.3% of our rationales are of high quality.
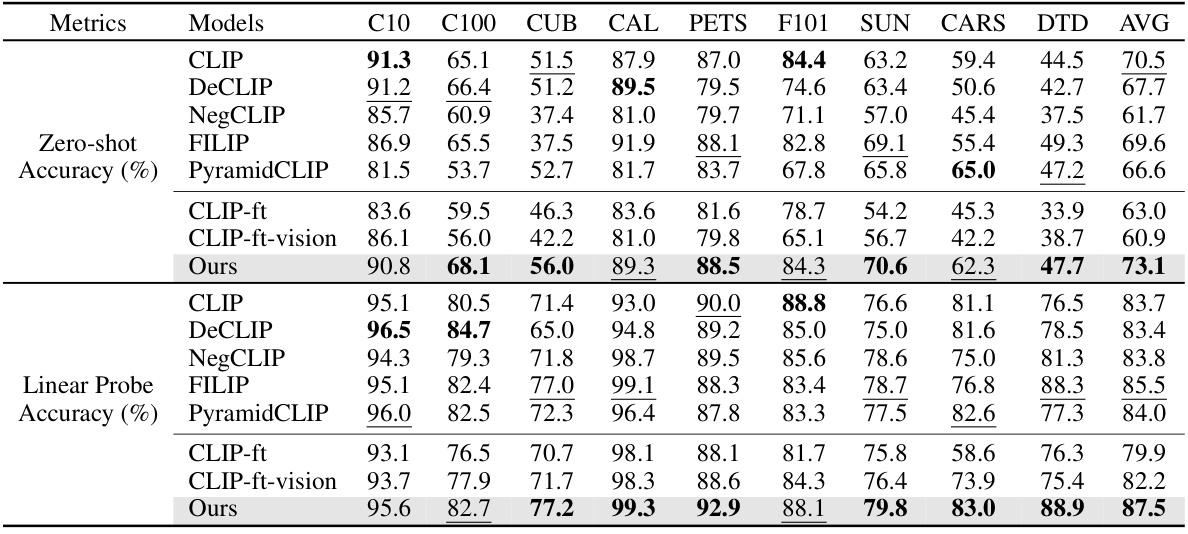
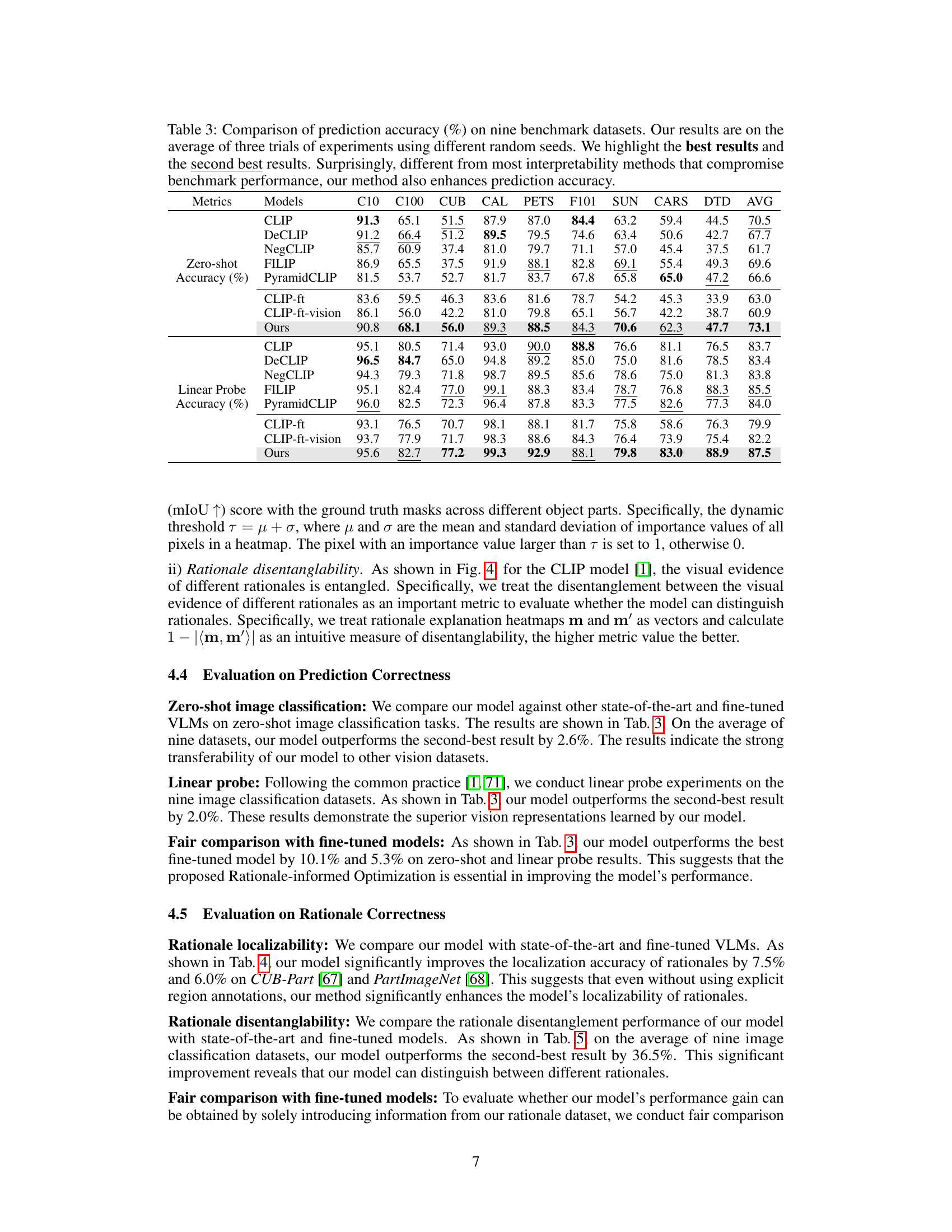
🔼 This table presents a comparison of prediction accuracy across nine benchmark datasets for various models, including the proposed model and several state-of-the-art models. It showcases zero-shot and linear probe accuracies, demonstrating the model’s performance and comparing it to fine-tuned versions of existing models. Noteworthy is the observation that the proposed method enhances prediction accuracy, unlike most interpretability methods that often compromise accuracy for improved interpretability.
read the caption
Table 3: Comparison of prediction accuracy (%) on nine benchmark datasets. Our results are on the average of three trials of experiments using different random seeds. We highlight the best results and the second best results. Surprisingly, different from most interpretability methods that compromise benchmark performance, our method also enhances prediction accuracy.
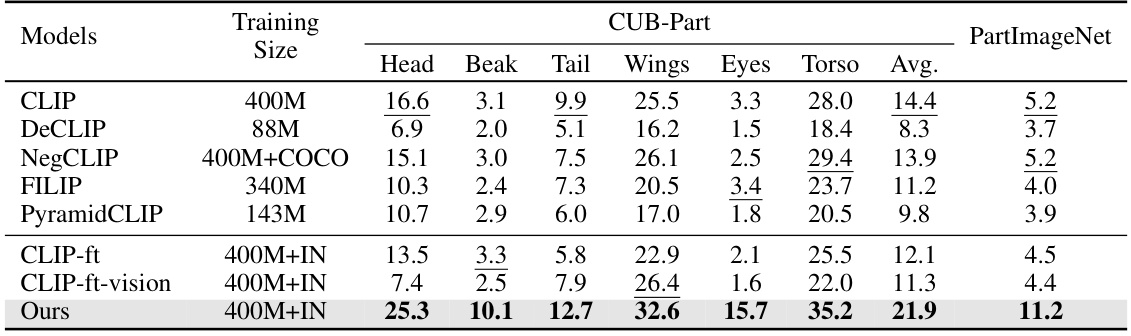
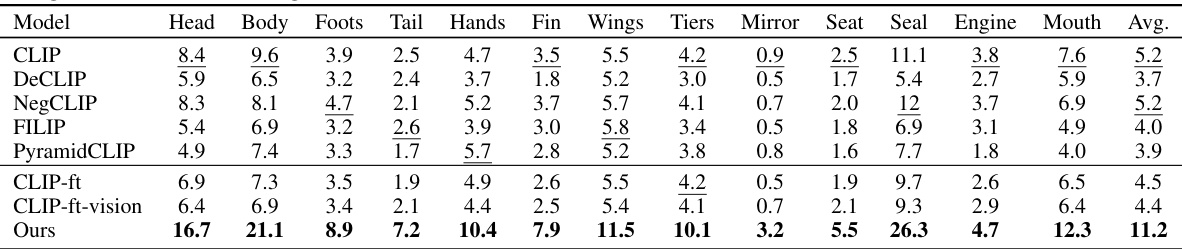
🔼 This table presents a comparison of rationale localizability, a metric evaluating how well a model can pinpoint the visual evidence supporting its rationales. The comparison is made across different models (CLIP, DeCLIP, NegCLIP, FILIP, PyramidCLIP, fine-tuned CLIP variants, and the proposed ‘Ours’ model) on two datasets: CUB-Part and PartImageNet. The results are shown as mean Intersection over Union (mIoU) scores for several object parts (head, beak, tail, wings, eyes, torso) and an average mIoU across all parts for each dataset. Higher mIoU values indicate better localization accuracy. The table highlights the superior performance of the proposed model in accurately localizing the visual evidence relevant to each rationale.
read the caption
Table 4: Comparison of rationale localizability on CUB-Part [67] and PartImageNet [68]. As detailed in Sec. 4.3, we threshold rationales' explanation heatmaps as segmentation masks and calculate their mIoU (↑) with ground truth masks of corresponding object parts. Our model significantly improves the localization accuracy of fine-grained object parts. Full table in Appendix C.

🔼 This table presents a comparison of prediction accuracy across nine benchmark datasets (C10, C100, CUB, CAL, PETS, F101, SUN, CARS, DTD) for various models. The models include CLIP, DeCLIP, NegCLIP, FILIP, PyramidCLIP, CLIP fine-tuned (CLIP-ft), CLIP fine-tuned with vision-encoder-only (CLIP-ft-vision), and the proposed method (Ours). The results are averaged across three trials, each with different random seeds, showcasing the consistency and robustness of the proposed method. The table highlights the best and second-best performances for each dataset. Notably, unlike many interpretability methods that often sacrifice accuracy, the proposed method achieves higher prediction accuracy than other state-of-the-art models across the board.
read the caption
Table 3: Comparison of prediction accuracy (%) on nine benchmark datasets. Our results are on the average of three trials of experiments using different random seeds. We highlight the best results and the second best results. Surprisingly, different from most interpretability methods that compromise benchmark performance, our method also enhances prediction accuracy.
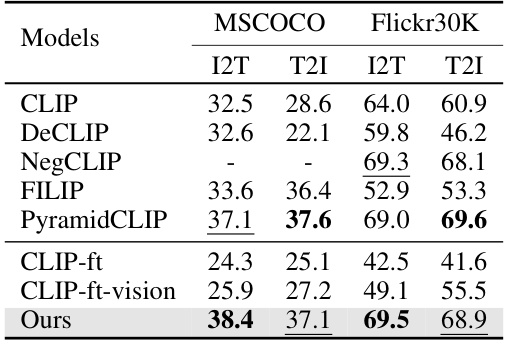
🔼 This table presents the zero-shot image-text retrieval accuracy of different models on two benchmark datasets, MSCOCO and Flickr30K. The accuracy is measured in two directions: Image-to-Text (I2T) and Text-to-Image (T2I). The table shows that the proposed model (‘Ours’) significantly improves the retrieval accuracy compared to existing state-of-the-art models, particularly in the I2T direction on the MSCOCO dataset. This improvement highlights the effectiveness of the model in integrating structured rationales to achieve a deeper and more accurate understanding of visual concepts, ultimately leading to better performance in retrieval tasks.
read the caption
Table 6: Comparison of zero-shot image-text retrieval accuracy (%). Double-correct prediction enhances the model's visual understanding. (Note that NegCLIP is trained on MSCOCO [66])
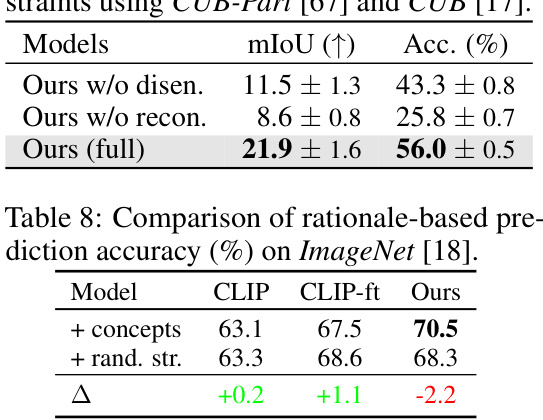
🔼 This table compares the prediction accuracy of different models on the ImageNet dataset when using rationale-based methods. It shows the performance of CLIP, CLIP fine-tuned (CLIP-ft), and the proposed method (‘Ours’). The comparison is made under three conditions: using structured concepts for rationales, using random strings instead of concepts, and the full method. The delta column shows the improvement over the CLIP baseline for each condition.
read the caption
Table 8: Comparison of rationale-based prediction accuracy (%) on ImageNet [18].

🔼 This table presents the results of evaluating the quality of the full rationale dataset using machine evaluators (GPT-4v and GPT-40). Three metrics are used to assess the rationales: Factual Consistency, Comprehensiveness, and Visual Disentanglement. Each metric is scored on a 5-point Likert scale, with higher scores indicating better performance. The table shows the average score for each metric across both GPT-4v and GPT-40.
read the caption
Table 9: The machine evaluation results on the quality of the full rationale dataset.
🔼 This table presents a comparison of prediction accuracy across nine benchmark datasets for various models, including the proposed model and several state-of-the-art baselines. The accuracy is reported for three different settings: zero-shot, linear probe, and fine-tuning. The table highlights that the proposed model achieves superior performance across all settings, and notably, unlike many interpretability methods, it does not compromise prediction accuracy.
read the caption
Table 3: Comparison of prediction accuracy (%) on nine benchmark datasets. Our results are on the average of three trials of experiments using different random seeds. We highlight the best results and the second best results. Surprisingly, different from most interpretability methods that compromise benchmark performance, our method also enhances prediction accuracy.
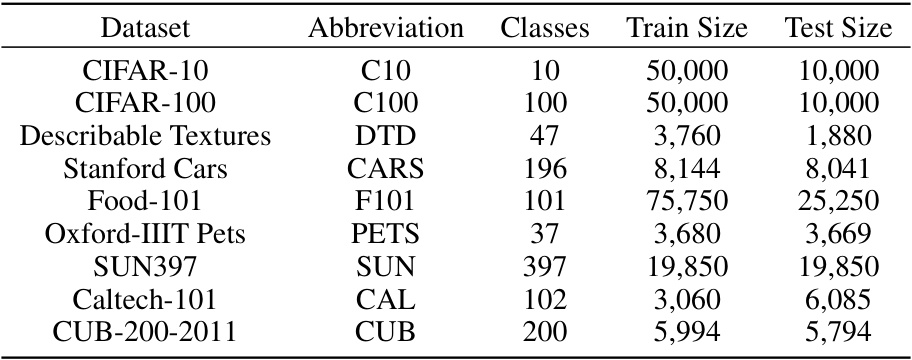
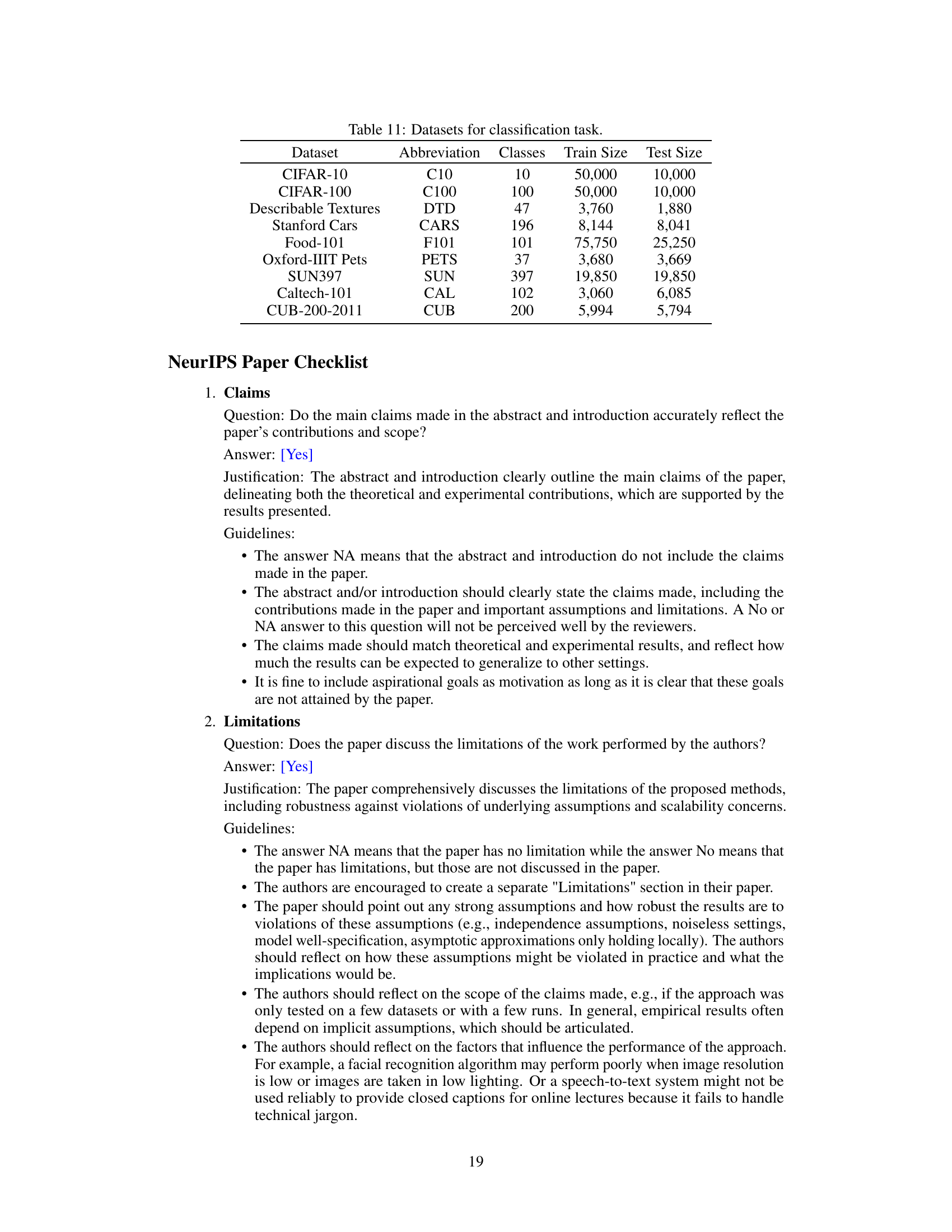
🔼 This table presents the details of nine benchmark datasets used for image classification in the paper. For each dataset, it lists its abbreviation, the number of classes, the size of the training set, and the size of the testing set. The datasets vary significantly in size and number of classes, allowing for a comprehensive evaluation of the model’s performance on diverse visual recognition tasks.
read the caption
Table 11: Datasets for classification task.
Full paper#