↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current state-of-the-art image segmentation models like SAM require extensive human annotation, hindering scalability and potentially introducing biases. The need for an efficient, unbiased, and scalable alternative is clear. Many researchers have tried to address this by utilizing self-supervised learning techniques in unsupervised image segmentation, but existing methods have limitations in capturing the fine-grained and multi-granular details of images.
This paper introduces UnSAM, an unsupervised image segmentation method that uses a divide-and-conquer strategy. This approach first partitions an image into segments, then iteratively merges them to create a hierarchical structure. These unsupervised multi-granular masks are used to train the model. UnSAM significantly surpasses previous unsupervised methods and produces results comparable to supervised SAM. Furthermore, integrating UnSAM’s pseudo masks with existing supervised models improves their accuracy, highlighting the benefits of a synergistic training approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel unsupervised method for image segmentation, overcoming the limitations of existing supervised approaches that rely on extensive manual labeling. This opens up new avenues for research in computer vision, particularly in areas where large labeled datasets are scarce or expensive to acquire. The findings also have practical implications for various applications that require efficient and accurate image segmentation.
Visual Insights#

This figure compares the performance of UnSAM (unsupervised), SAM (supervised), and UnSAM+ (lightly semi-supervised) on several datasets. It shows examples of whole-image segmentations and segmentations based on a point prompt, and provides quantitative results using Mask AR and Point IoU.

This table compares the performance of UnSAM against other unsupervised image segmentation methods on seven datasets. The datasets are categorized into those focusing on whole entities and those focusing on parts of entities. The results show UnSAM significantly outperforms previous state-of-the-art methods across all datasets, achieving a substantial improvement in Average Recall (AR). The comparison highlights the effectiveness of UnSAM’s approach, even when trained with limited data.
In-depth insights#
UnSAM: Core Idea#
UnSAM’s core idea revolves around a self-supervised learning approach to image segmentation, eliminating the need for labor-intensive human annotation. It cleverly employs a divide-and-conquer strategy, initially partitioning an image into segments using top-down clustering (identifying instance/semantic levels). Subsequently, a bottom-up clustering method iteratively merges these segments to build a hierarchical representation. This unsupervised process generates multi-granular masks which then serve as pseudo-ground truth labels to train the model. The hierarchical structure allows for fine-grained detail capture, exceeding the capabilities of the supervised counterpart. This approach contrasts sharply with existing methods, which typically rely on single-level segmentations or less robust hierarchical structures. UnSAM’s innovative method represents a significant advancement in unsupervised image segmentation, achieving highly competitive performance relative to supervised models and opening up new possibilities for scalability and bias reduction.
Divide & Conquer#
The “Divide & Conquer” strategy, as implemented in the unsupervised image segmentation model UnSAM, offers a powerful approach to parsing complex visual scenes. It leverages a hierarchical decomposition, initially partitioning an image into segments via top-down clustering (the “divide” phase). This initial segmentation, though potentially noisy, provides a foundation for a subsequent bottom-up refinement process. The “conquer” phase involves iteratively merging similar segments based on various similarity thresholds, building a hierarchy of increasingly larger regions. This two-stage approach generates a rich set of multi-granular masks, addressing the limitations of previous methods that focused on either top-down or bottom-up processes alone. The resulting hierarchical segmentation provides a robust and comprehensive representation of visual scenes, thereby enhancing both the granularity and accuracy of unsupervised pseudo masks crucial for model training. This allows UnSAM to excel at segmentation tasks, identifying fine details overlooked by both previous unsupervised techniques and even its supervised counterpart, SAM.
Unsupervised Masks#
The concept of “Unsupervised Masks” in the context of image segmentation represents a significant advancement. It addresses the critical limitation of existing supervised methods which heavily rely on laborious manual annotation of images for training. By generating masks without human intervention, unsupervised approaches like the one described unlock the potential for scalability and efficiency. The core challenge, however, lies in the quality and diversity of the automatically generated masks. Effective unsupervised methods must develop robust techniques to accurately capture the hierarchical structure of visual scenes, generating masks that represent not just individual objects but also their meaningful parts and relationships at multiple granularities. The success of unsupervised masks depends on innovative clustering algorithms and creative self-training strategies capable of refining initial imperfect masks, ultimately producing data suitable for effective model training. Ultimately, the quality of these unsupervised masks determines the performance and generalization capabilities of the resulting segmentation model. Achieving comparable results to supervised methods remains a significant and exciting area of ongoing research.
SAM Enhancement#
The paper explores enhancing the Segment Anything Model (SAM) by leveraging unsupervised learning. A key approach involves a divide-and-conquer strategy to generate pseudo-masks, capturing a hierarchical structure of images without human annotation. This unsupervised method, termed UnSAM, creates multi-granular masks that act as training data for a self-supervised learning process. The resulting model not only achieves comparable performance to supervised SAM but even outperforms it in certain aspects. Integrating these unsupervised pseudo-masks into SAM’s supervised training (UnSAM+) significantly improves results, surpassing SAM’s AR and AP on SA-1B. This enhancement demonstrates that self-supervised data can mitigate the limitations of existing supervised datasets, such as annotation biases and overlooked small entities. The overall enhancement highlights the potential of leveraging unsupervised learning to overcome the limitations of large-scale supervised training in computer vision tasks.
Future of UnSAM#
The “Future of UnSAM” section could explore several promising avenues. Improving the efficiency and scalability of the divide-and-conquer strategy is crucial; perhaps investigating more sophisticated clustering algorithms or leveraging parallel processing techniques. Expanding UnSAM’s capabilities to handle videos or 3D data would significantly broaden its applications. Addressing limitations in segmenting highly textured or fine-grained objects remains a key challenge, potentially through incorporating advanced feature extraction methods. Finally, research into integrating UnSAM with other models could unlock powerful synergistic effects, such as combining it with a generative model for enhanced image synthesis or a large language model for contextual understanding of visual scenes. Investigating potential biases introduced by the unsupervised learning process and the SA-1B dataset will be essential for responsible development.
More visual insights#
More on figures

This figure illustrates the two-stage pipeline used in UnSAM to generate pseudo masks for training. The first stage (divide) uses top-down clustering to extract initial semantic/instance-level masks. The second stage (conquer) uses iterative bottom-up clustering to refine these masks, creating a hierarchy of masks with varying levels of granularity. This hierarchical structure represents the hierarchical structure of visual scenes.

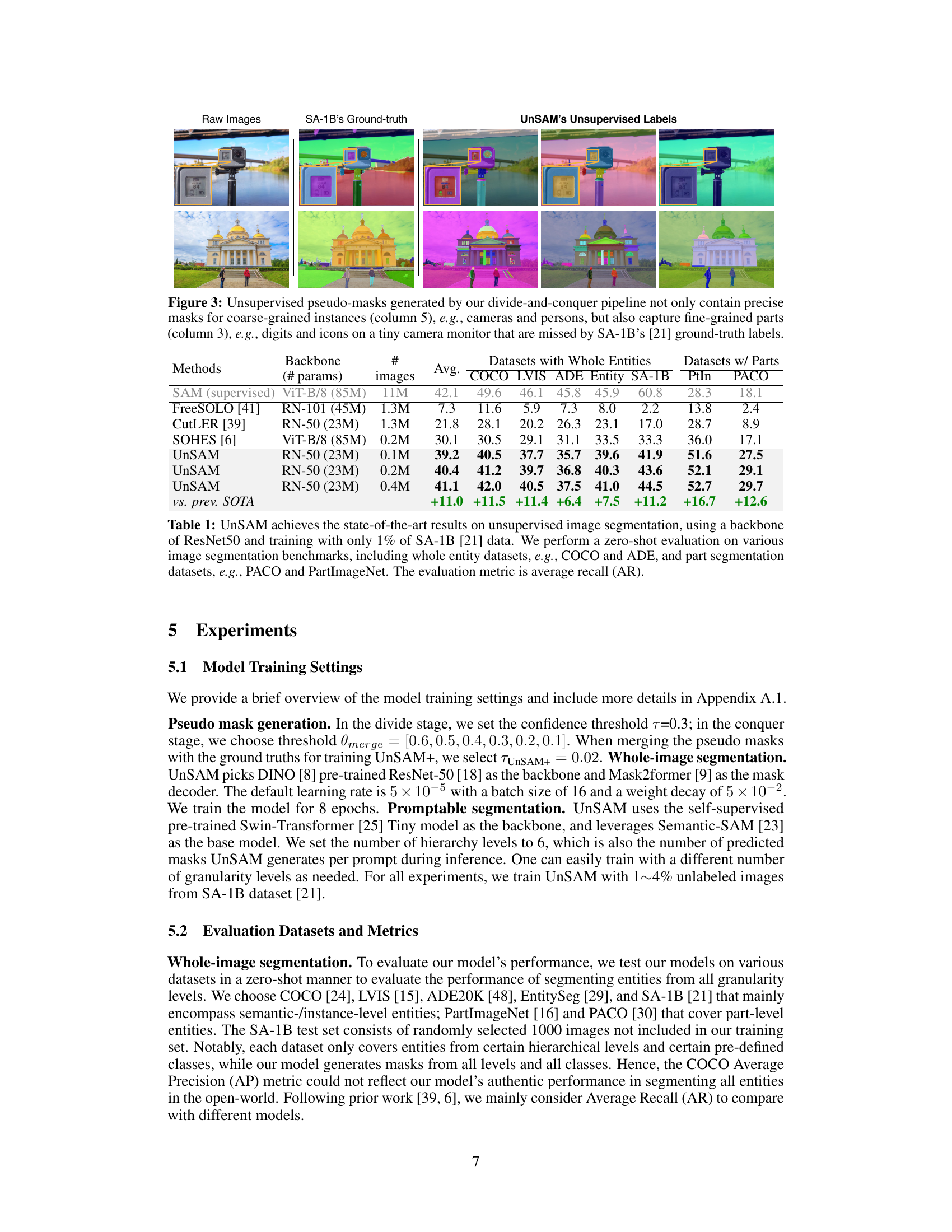
This figure shows a comparison of the ground truth masks from the SA-1B dataset and the unsupervised pseudo-masks generated by the UnSAM model. The figure highlights that UnSAM is able to generate masks not only for coarse-grained objects, but also for fine-grained details that are often missed in the human-annotated ground truth masks. This demonstrates the ability of UnSAM to capture a wider range of granularity levels compared to previous methods.

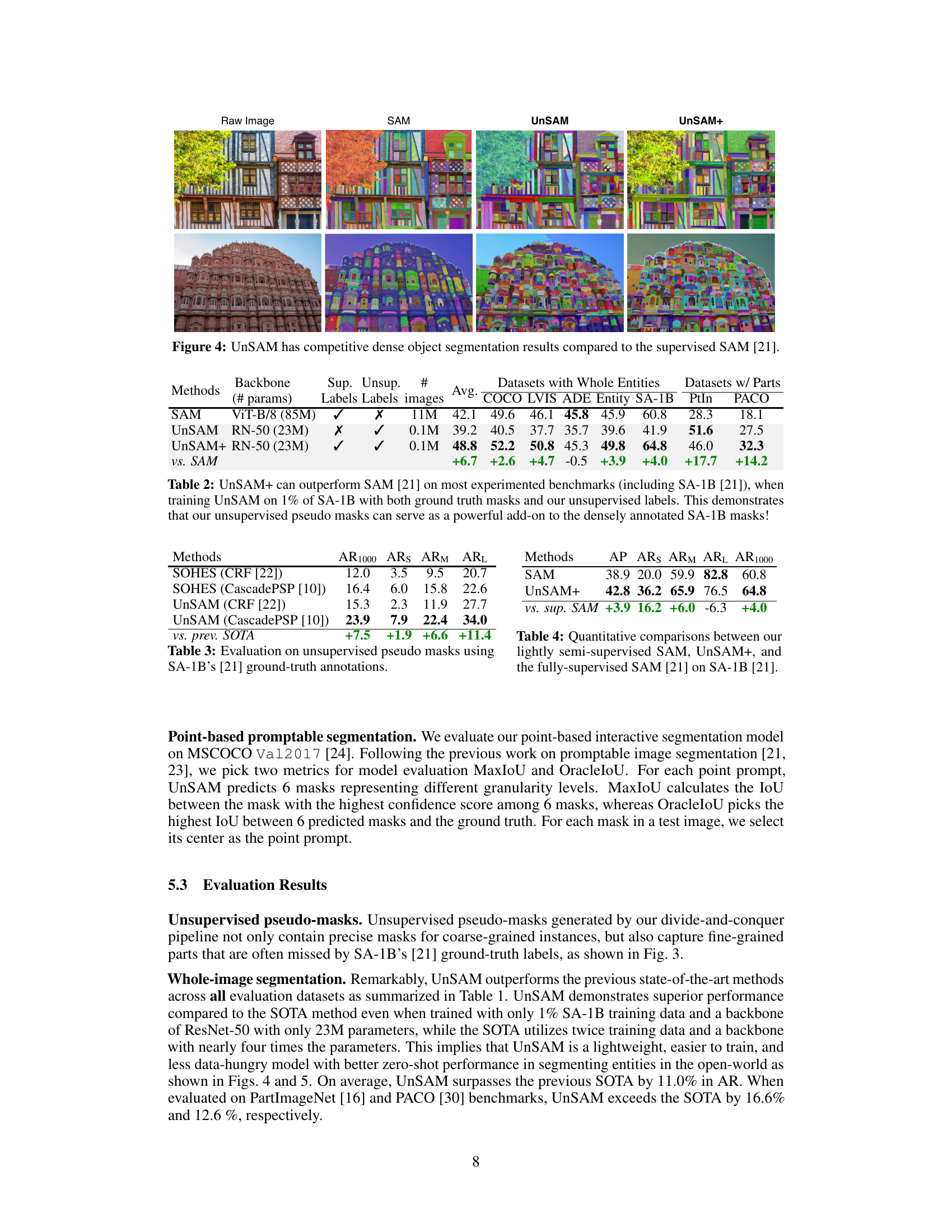
This figure shows a comparison of image segmentations produced by three different models: SAM (supervised), UnSAM (unsupervised), and UnSAM+ (lightly supervised) on the COCO dataset. The top row displays a set of raw images from the COCO dataset. The second row displays the segmentation masks generated by the SAM model. The third row displays the segmentation masks generated by the UnSAM model. The bottom row displays the segmentation masks generated by the UnSAM+ model. The goal is to visually demonstrate the differences in segmentation quality and detail between the three models. The color variations within each segmentation likely represent different identified objects or regions within the image.

This figure compares the performance of UnSAM against previous state-of-the-art unsupervised segmentation methods. It showcases UnSAM’s ability to generate more fine-grained masks and a wider range of granularity levels compared to existing techniques, using examples from the SA-1B dataset.

This figure displays a qualitative comparison of the promptable image segmentation results obtained using three different models: the fully-supervised SAM, the unsupervised UnSAM, and the lightly semi-supervised UnSAM+. The comparison highlights the ability of UnSAM and UnSAM+ to generate high-quality, multi-granular segmentation masks from point prompts, which are represented by star marks in the images. The results showcase the performance of the proposed unsupervised and semi-supervised methods in comparison to the fully-supervised state-of-the-art.

This figure displays a comparison of image segmentations across three different models: SAM (supervised), UnSAM (unsupervised), and UnSAM+ (lightly supervised). For several images from the SA-1B dataset, it shows the original image alongside the segmentations produced by each model. This visual comparison highlights the differences in segmentation quality and granularity between the supervised and unsupervised approaches, showcasing UnSAM’s ability to produce segmentations comparable to SAM, especially when augmented with a small amount of supervised data as in UnSAM+.

This figure compares the performance of UnSAM (unsupervised), SAM (supervised), and UnSAM+ (lightly supervised) on several datasets. The top half shows example images and their segmentations using SAM and UnSAM, illustrating UnSAM’s ability to produce comparable results without human supervision. The bottom half presents quantitative results, showing that UnSAM significantly outperforms previous state-of-the-art unsupervised methods and that UnSAM+ even surpasses SAM’s performance.

This figure provides more visual comparisons of the results from the SAM, UnSAM, and UnSAM+ models on the COCO dataset. Each row shows four images, following the pattern of raw image, SAM segmentation, UnSAM segmentation, and UnSAM+ segmentation. The color-coded segmentations allow for a visual comparison of the models’ performance in segmenting various objects in different images.

This figure showcases instances where the unsupervised model, UnSAM, struggles to achieve accurate segmentation compared to the supervised model SAM. The examples highlight the challenges posed by dense fine-grained details and instances with similar textures, where UnSAM tends to miss objects or over-segment the scene. It illustrates limitations associated with unsupervised approaches in handling complex visual data compared to supervised models with access to labelled data.
More on tables

This table compares the performance of three different models: SAM (supervised), UnSAM (unsupervised), and UnSAM+ (lightly supervised) across various datasets. The key takeaway is that integrating the unsupervised pseudo-masks generated by UnSAM into the training data of SAM significantly improves performance, highlighting the value of the self-supervised labels generated by UnSAM.

This table compares the performance of three models on the SA-1B dataset: the fully supervised SAM, the unsupervised UnSAM, and the lightly semi-supervised UnSAM+. The metrics used are Average Precision (AP), Average Recall at 1000 (AR1000), and Average Recall at different IoU thresholds (ARS, ARM, ARL). UnSAM+ shows improvements in several metrics compared to SAM, highlighting the potential benefits of integrating unsupervised pseudo-masks into the training process.

This table presents the performance comparison of UnSAM and SOHES methods on the task of unsupervised pseudo mask generation. The methods are evaluated using the SA-1B dataset’s ground truth annotations. The results are presented in terms of average recall (AR) across different metrics: AR1000 (average recall on 1000 randomly selected images), ARs (average recall on small entities), ARM (average recall on medium entities), and ARl (average recall on large entities). The table highlights the significant improvement achieved by UnSAM over the previous state-of-the-art (SOTA) method, SOHES, across all metrics.

This table compares the performance of three different models (SAM, UnSAM, and UnSAM+) on the promptable image segmentation task using the COCO dataset. It highlights that UnSAM+, a lightly semi-supervised model trained with only 1% of the SA-1B dataset, outperforms the fully supervised SAM model, even though it uses a smaller backbone network.
Full paper#