TL;DR#
Current text-conditioned motion synthesis excels in single-person animations but struggles with multi-person interactions due to the complexity of modeling interactions and the lack of large-scale multi-person interaction datasets. Existing methods often rely on training with fixed numbers of characters, limiting their generalization capabilities. They also fail to precisely control individual character’s joints, which is crucial for generating realistic interactions.
This paper introduces InterControl, which tackles these issues by representing interactions as pairs of joints with specified contact or distance constraints. Instead of training a multi-person model, InterControl adapts a single-person motion generation model to precisely control each joint’s position using a novel motion controller and inverse kinematics. The method successfully generates realistic interactions for an arbitrary number of people in a zero-shot manner, demonstrating promising results on HumanML3D and KIT-ML datasets. This significantly reduces the need for massive multi-person datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it presents InterControl, a novel method for generating multi-person interactions using only single-person motion data. This addresses a significant limitation of existing methods and opens up exciting new avenues for research in areas such as virtual reality, animation, and robotics. The zero-shot capability and high precision of joint control offered by InterControl have significant implications for applications involving diverse and complex human interactions. The annotation-free nature using an LLM reduces the workload for data collection and annotation which is significant for the human motion research community.
Visual Insights#

🔼 This figure demonstrates the ability of the InterControl model to generate realistic multi-person interactions from a single-person motion dataset. The model takes joint-joint contact and separation information as input and synthesizes motions accordingly. The top row shows various daily life scenarios (a), while the middle row demonstrates fighting scenarios (b). These interactions are diverse and naturally-looking. The bottom row (c) presents an example of using the generated group motions as input to a physics simulator, showcasing the potential for applying the generated motions to realistic simulations.
read the caption
Figure 1: InterControl is able to generate interactions of a group of people given joint-joint contact or separation pairs as spatial condition, and it is only trained on single-person data. Our generated interactions are realistic and similar to real interactions in internet images in (a) daily life and (b) fighting. (c) shows our generated group motions (red dots) could serve as reference motions for physics animation.
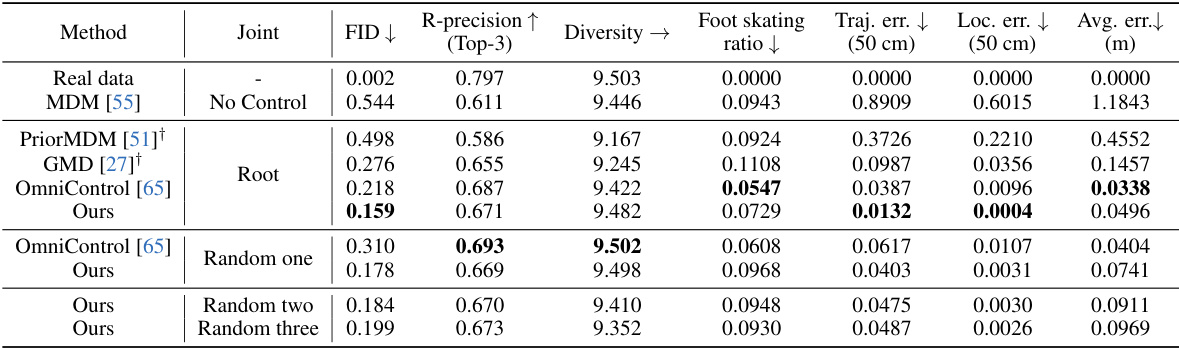
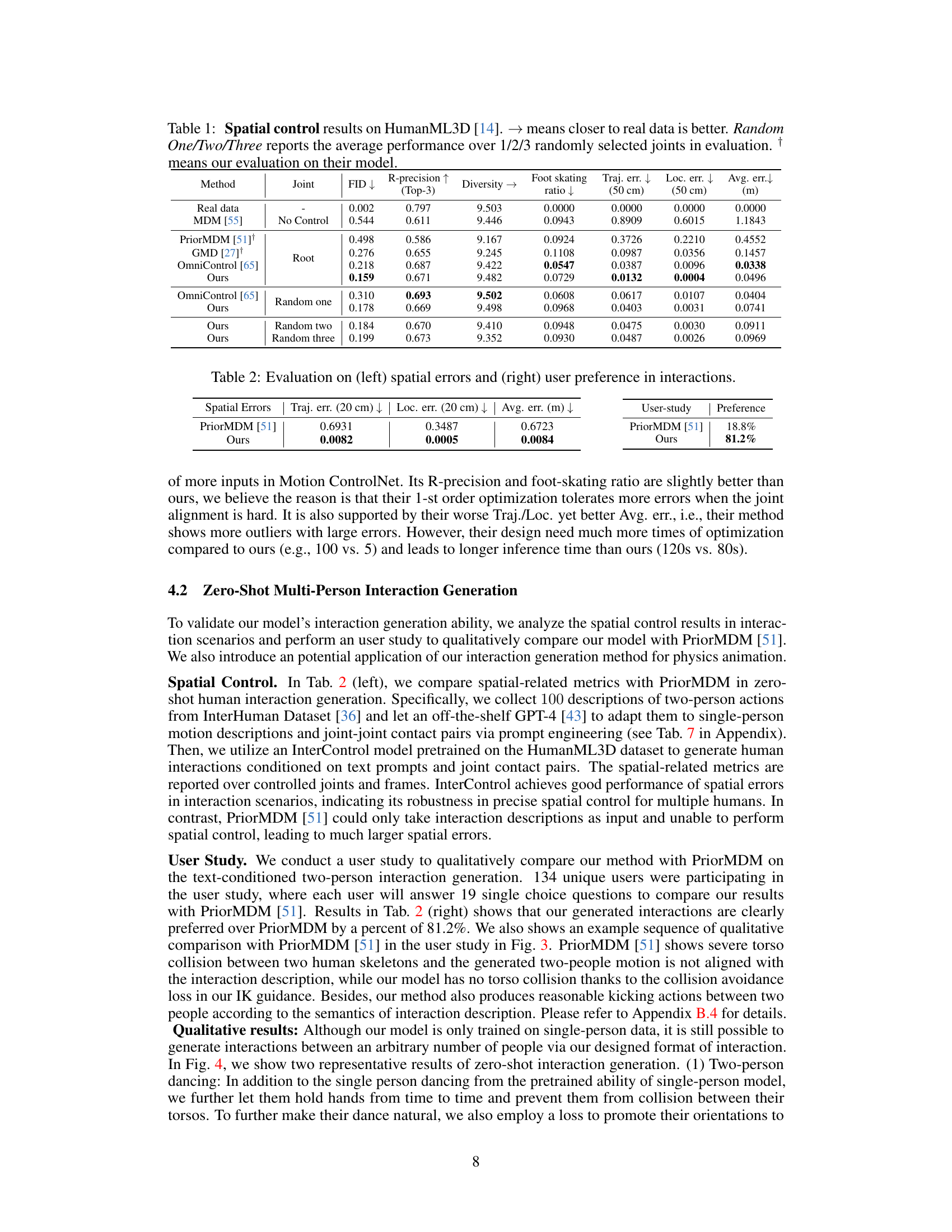
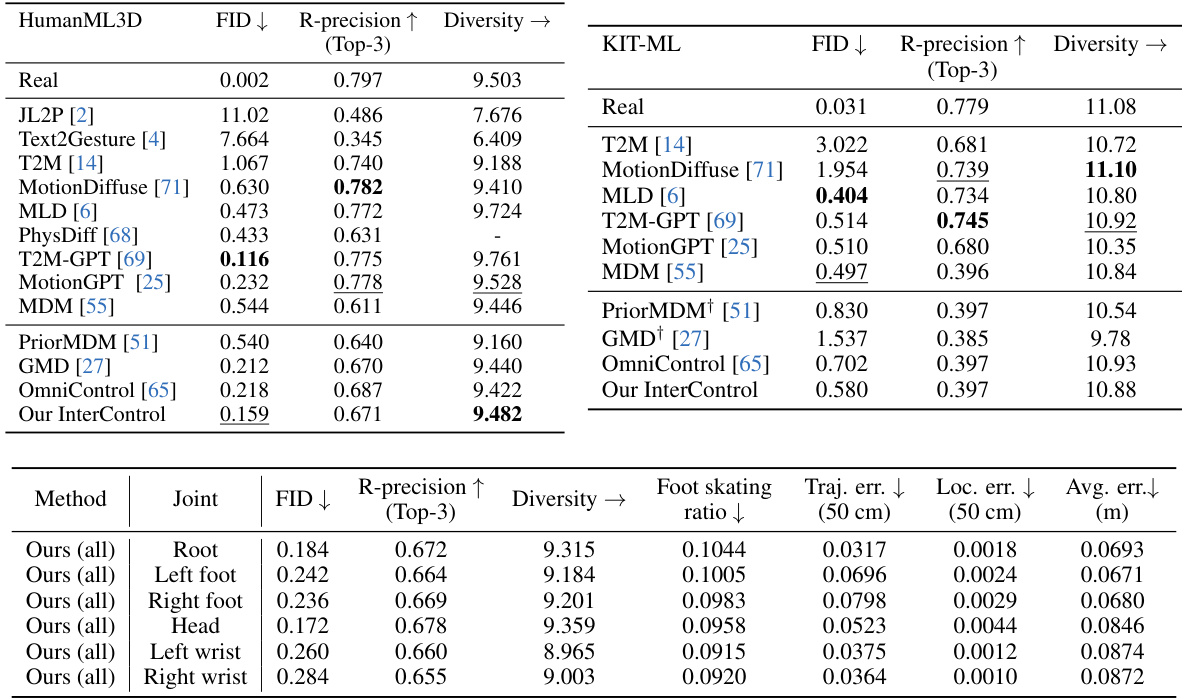
🔼 This table presents a comparison of spatial control performance on the HumanML3D dataset. Several methods are compared, including MDM (without control), PriorMDM, GMD, and OmniControl. The table shows performance metrics such as FID (lower is better), R-precision (higher is better), diversity (higher is better), foot skating ratio (lower is better), trajectory error, location error, and average error (all lower is better). The ‘Joint’ column indicates whether all joints, a single random joint, two random joints, or three random joints were used for control. The † symbol indicates that the result is based on the authors’ own evaluation of another method.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.
In-depth insights#
Zero-Shot Interaction#
Zero-shot interaction in AI research signifies a model’s ability to generate interactions between multiple agents or objects without explicit training on those specific interactions. This is a significant step towards more generalizable and robust AI systems. The core challenge lies in enabling the model to understand and reason about the complex dynamics inherent in multi-agent scenarios. Success often hinges on leveraging pre-trained models and transferring knowledge learned from simpler tasks. Effective methods often involve representing interactions as a set of constraints or rules, enabling the model to implicitly learn interaction patterns from spatial relationships and contextual cues. However, limitations exist, as the complexity of nuanced interactions may surpass the model’s capacity for generalization. Future research should focus on enhancing model capacity and developing more sophisticated methods for representing and reasoning about interactions. This could involve incorporating physics engines, improved methods for handling uncertainty, or incorporating techniques from reinforcement learning.
Joint Precision Control#
Achieving joint precision control in character animation presents a significant challenge, demanding a system capable of accurately positioning and orienting each joint in three-dimensional space. Precise control is crucial for realistic depictions of human movement, especially when modeling complex interactions like handshakes or combat. Methods addressing this need might involve techniques such as inverse kinematics (IK), which solves for joint angles given desired end-effector positions, or model-based approaches that leverage physics simulations to maintain realistic joint constraints. Sophisticated control algorithms are essential to handle the complexities of multi-joint coordination and avoid unnatural poses or collisions between body parts. The development of robust and efficient control systems is key to enabling expressive and believable character animation, opening doors for advancements in virtual reality, gaming, and film production. The challenge lies in balancing control precision with computational efficiency, particularly when dealing with large numbers of joints and complex interactions. Future research should explore the use of more advanced techniques such as machine learning to improve control accuracy and efficiency.
LLM for Interaction#
Utilizing Large Language Models (LLMs) for interaction generation in virtual environments presents exciting possibilities. LLMs excel at understanding and generating human-like text, offering a powerful tool to translate high-level interaction descriptions into low-level control signals. This approach bypasses the limitations of traditional methods reliant on large, meticulously annotated datasets. Instead of explicitly programming interactions, an LLM can interpret descriptions like “two people shake hands” and infer the necessary joint movements and timing. This zero-shot capability is particularly valuable for generating diverse and complex interactions involving many characters or scenarios where data collection is difficult or impossible. However, challenges remain in ensuring the LLM’s output is accurate and detailed enough for precise control of character animations, as well as managing potential ambiguities in natural language descriptions. The success of this approach hinges on the quality of the LLM and the effectiveness of the system translating textual instructions into a physically plausible simulation.
Physics Animation#
Integrating physics simulation into animation offers a powerful way to enhance realism and create believable character movements. Physics-based animation allows for more natural interactions between characters and their environment. By simulating realistic physics, the animation can respond dynamically to external forces and constraints, resulting in more nuanced and engaging motion. However, achieving a balance between physical accuracy and artistic control is a major challenge. Overly realistic simulations might look unnatural or require significant computational resources. Conversely, oversimplifying physics can lead to stiff, unconvincing results. The level of physical detail required for a convincing physics-based animation is highly dependent on the context. In some cases, a simple approximation may suffice, while others may demand high-fidelity simulation. Careful consideration of computational cost is critical, as high-fidelity simulations can be very demanding, particularly when dealing with complex characters or environments. Successful physics-based animation relies on clever algorithms and techniques that manage computational complexity while delivering visually compelling and believable motion.
Future Directions#
Future research could explore improving the LLM’s ability to generate diverse and nuanced interaction descriptions, moving beyond simple joint-contact specifications to encompass more complex interactions and contextual factors. Addressing the limitations of the single-person motion model by incorporating multi-person data or developing more sophisticated methods for handling interactions would significantly enhance the system’s realism. Investigating different control mechanisms, such as incorporating physics simulations directly into the motion generation process, could lead to more physically plausible interactions. Extending the framework to handle more complex scenarios with greater numbers of actors, more varied interactions, and richer environmental details would showcase its versatility. Finally, exploring user-centric applications that allow for interactive manipulation of the generated motions, possibly through VR or AR interfaces, would create innovative and immersive experiences.
More visual insights#
More on figures

🔼 This figure illustrates the overall architecture of the InterControl model. It shows how the model uses an LLM to generate interaction descriptions (e.g., two people fighting), which are then converted into joint-joint contact pairs. These pairs serve as spatial controls for a motion diffusion model. The controls are processed by a Motion ControlNet and refined further with inverse kinematics guidance, enabling precise control of character joints in the global space. The final output are realistic multi-person interactions.
read the caption
Figure 2: Overview. Our model could precisely control human joints in the global space via the Motion ControlNet and IK guidance module. By leveraging LLM to adapt interaction descriptions to joint contact pairs, it could generate multi-person interactions via a single-person motion generation model in a zero-shot manner.

🔼 This figure demonstrates the capabilities of the InterControl model. It showcases the generation of realistic multi-person interactions from simple joint-pair constraints (contact or separation distances). The model is trained only on single-person data, achieving zero-shot generalization to multiple people. Subfigures (a) and (b) show examples from daily life and fighting scenarios, respectively. These examples highlight the model’s ability to produce interactions resembling real-world examples found in internet images. Subfigure (c) further illustrates how the generated group motions can be used as input for physics-based animation simulations.
read the caption
Figure 1: InterControl is able to generate interactions of a group of people given joint-joint contact or separation pairs as spatial condition, and it is only trained on single-person data. Our generated interactions are realistic and similar to real interactions in internet images in (a) daily life and (b) fighting. (c) shows our generated group motions (red dots) could serve as reference motions for physics animation.
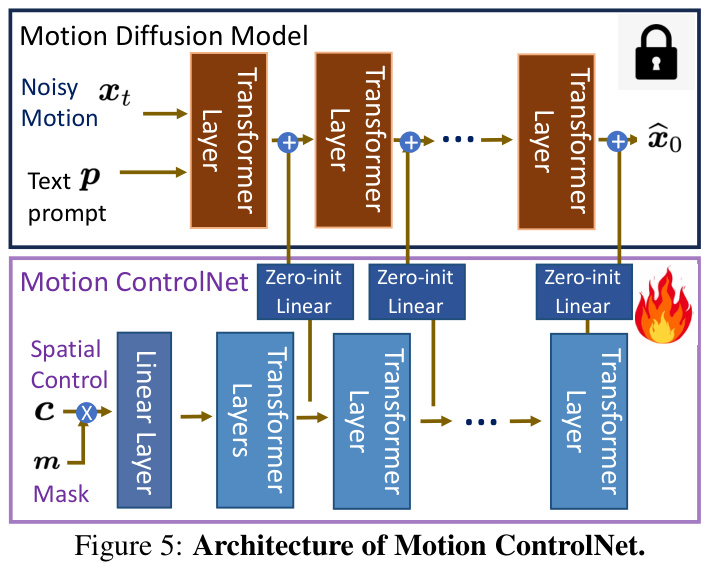
🔼 This figure illustrates the overall architecture of the InterControl model. It shows how the model uses a large language model (LLM) to convert interaction descriptions into joint contact pairs, which are then used as spatial controls. These spatial controls are processed by two modules: Motion ControlNet, a fine-tuned copy of a pre-trained motion diffusion model, and IK Guidance, an inverse kinematics module. These modules work together to precisely control human joints in the global space, allowing the generation of realistic and diverse multi-person interactions from a single-person motion model.
read the caption
Figure 2: Overview. Our model could precisely control human joints in the global space via the Motion ControlNet and IK guidance module. By leveraging LLM to adapt interaction descriptions to joint contact pairs, it could generate multi-person interactions via a single-person motion generation model in a zero-shot manner.

🔼 The figure shows a qualitative comparison between the proposed InterControl method and the PriorMDM method in a user study on zero-shot human interaction generation. It provides two example sequences of two-person interactions generated by each method alongside a text description of the intended interaction. The visual comparison highlights the differences in the realism and accuracy of the generated interactions, particularly regarding torso collision and alignment with the given textual description. InterControl’s results demonstrate a significant improvement in both aspects.
read the caption
Figure 3: Comparison with PriorMDM [51] in user-study of zero-shot human interaction generation.
More on tables

🔼 This table presents a comparison of spatial errors and user preferences between the proposed InterControl method and the baseline PriorMDM [51] for human interaction generation. The left side shows quantitative results of spatial errors, including trajectory error (within 20 cm), location error (within 20 cm), and average error (in meters), demonstrating the precision of joint control in generated interactions. The right side displays the results of a user study comparing user preferences between the two methods, indicating a clear preference for the InterControl method’s generated interactions.
read the caption
Table 2: Evaluation on (left) spatial errors and (right) user preference in interactions.

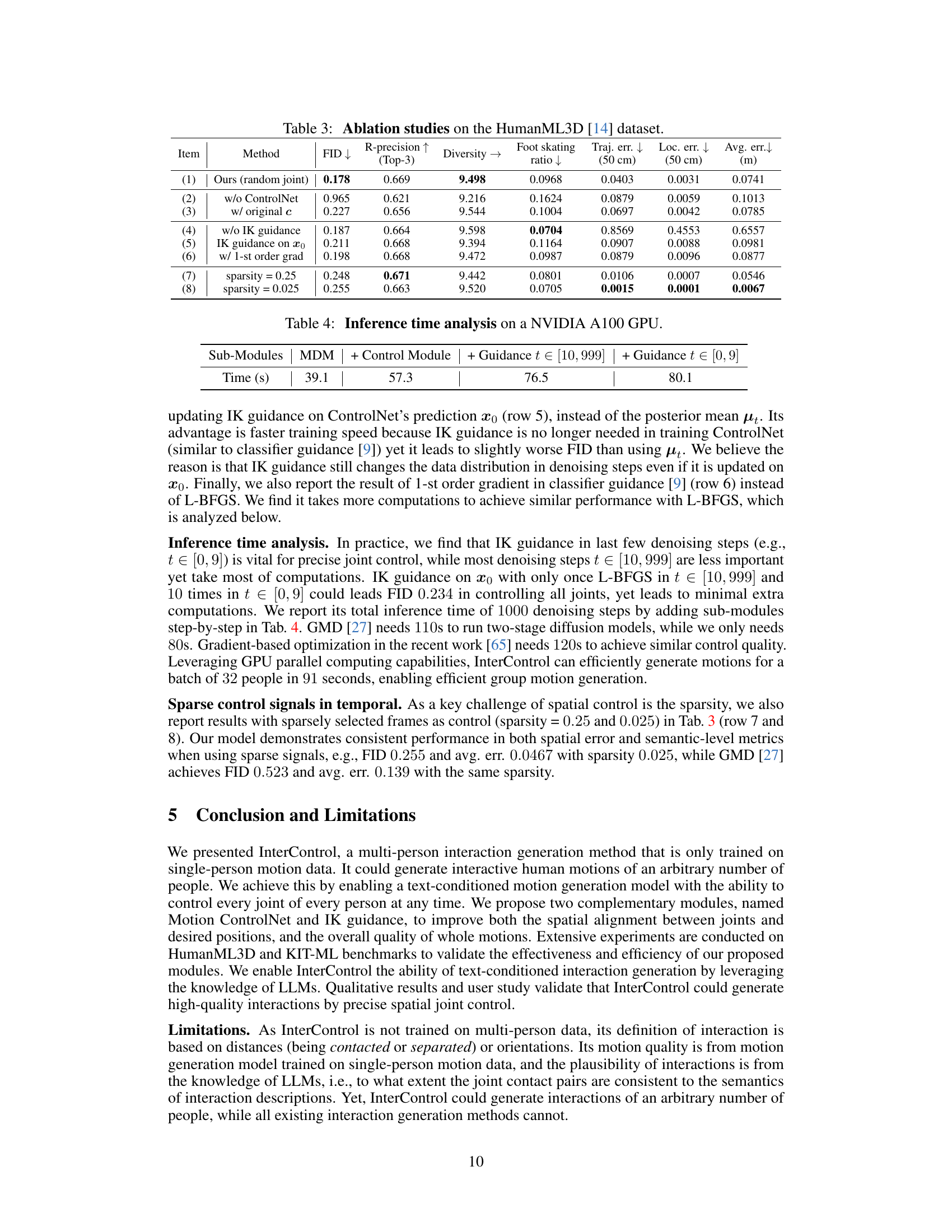
🔼 This table presents the results of ablation studies performed on the HumanML3D dataset to evaluate the effectiveness of different components of the InterControl model. Specifically, it shows the impact of removing the Motion ControlNet, IK guidance, and using different sparsity levels for the spatial control signals. The metrics reported include FID (Frechet Inception Distance), R-precision (Top-3), Diversity, Foot skating ratio, Trajectory error, Location error, and Average error. Lower FID and trajectory/location errors generally indicate better performance.
read the caption
Table 3: Ablation studies on the HumanML3D [14] dataset.

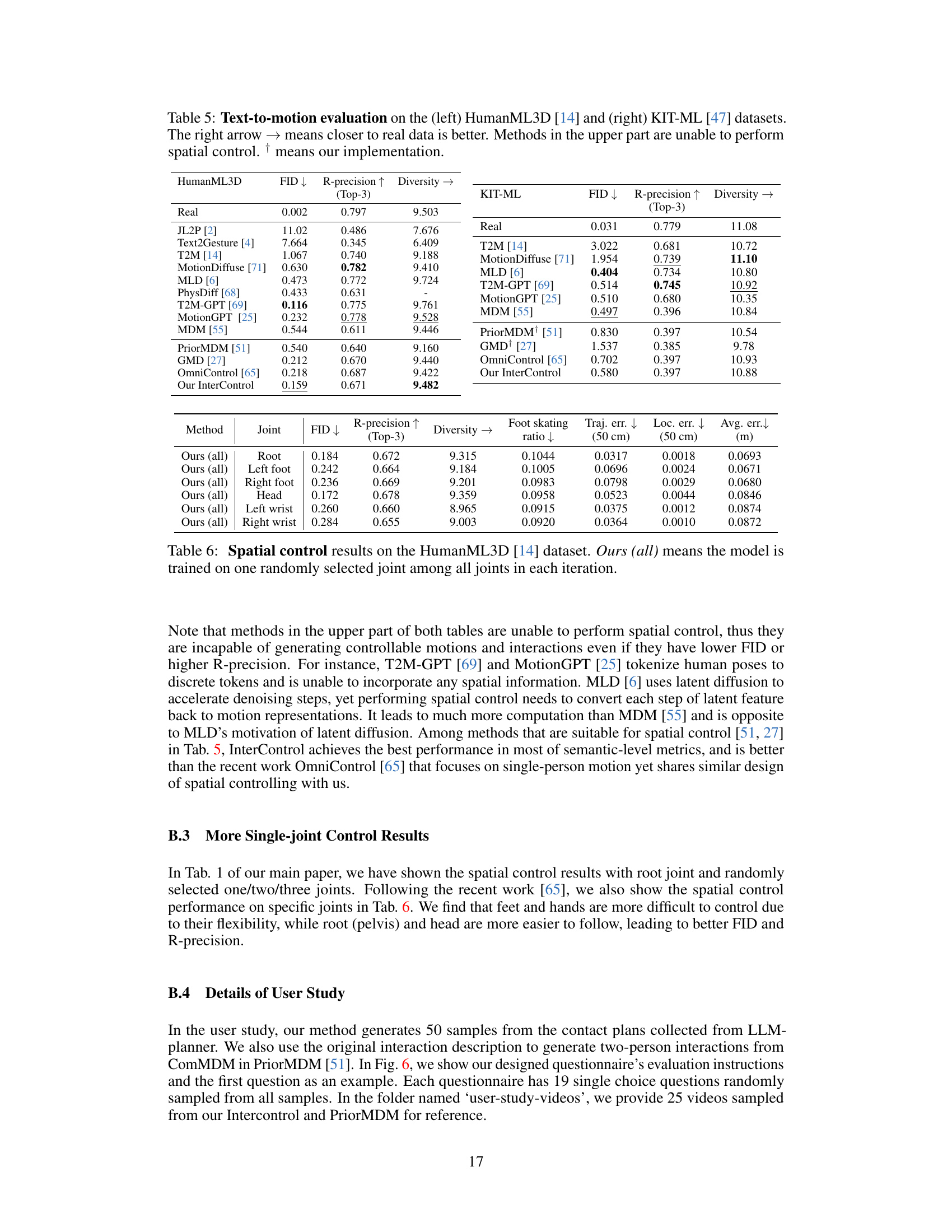
🔼 This table presents a comparison of different methods for spatial control in human motion generation using the HumanML3D dataset. It evaluates various metrics including Frechet Inception Distance (FID), R-precision, Diversity, Foot skating ratio, Trajectory error, Location error, and Average error. The results are shown for different scenarios: no control, root control, and random control of one, two, or three joints. The table highlights the superior performance of the proposed InterControl method, particularly in achieving lower errors in spatial control while maintaining good quality in motion generation.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.
🔼 This table presents a comparison of different methods for spatial control in human motion generation, evaluated using the HumanML3D dataset. Metrics include Frechet Inception Distance (FID), R-precision, diversity, foot skating ratio, trajectory error, location error, and average error. The table shows the performance of various methods, including the proposed InterControl method, when controlling different numbers of joints (one, two, or three) and also when controlling the root joint only.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.

🔼 This table presents a comparison of different methods for spatial control in human motion generation using the HumanML3D dataset. Metrics include Frechet Inception Distance (FID), R-precision, diversity, foot skating ratio, trajectory error, location error, and average error. The results are shown for different scenarios: no control, control of the root joint only, and control of one, two, or three randomly selected joints. The table highlights the superior performance of the proposed InterControl method across various metrics, particularly in reducing errors in spatial control while maintaining realistic motion quality.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.

🔼 This table presents a comparison of different methods for spatial control in human motion generation using the HumanML3D dataset. It shows the performance of various models across several metrics, including Frechet Inception Distance (FID), R-precision, diversity, foot skating ratio, trajectory error, location error, and average error. The metrics evaluate the accuracy and realism of the generated motions, particularly focusing on how well the model controls the spatial aspects of the movements. The table distinguishes between methods that don’t have spatial control and those that do, highlighting the improvement achieved by the proposed InterControl method. The results are presented for both controlling one specific joint and randomly selected multiple joints.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.

🔼 This table compares the performance of InterControl with other methods on the HumanML3D dataset in terms of spatial control. It shows metrics such as FID (Frechet Inception Distance), R-precision, diversity, foot skating ratio, trajectory error, location error, and average error. The comparison includes methods with no spatial control, root-only control, and random joint selection for various numbers of joints. The arrow (→) indicates better performance closer to real data. The † symbol indicates results obtained by the authors using other methods’ models.
read the caption
Table 1: Spatial control results on HumanML3D [14]. → means closer to real data is better. Random One/Two/Three reports the average performance over 1/2/3 randomly selected joints in evaluation. † means our evaluation on their model.
Full paper#