↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Crowdsourcing, while cost-effective, suffers from noisy labels and intractable instances, hindering accurate model training. Existing algorithms primarily focus on improving data quality (label accuracy), neglecting model quality (prediction accuracy) which is the ultimate goal. This often leads to suboptimal model performance despite high label accuracy.
The proposed IWBVT method tackles this by focusing on model quality. It introduces a novel instance weighting mechanism that reduces the impact of intractable instances. Then, it employs probabilistic loss regression to achieve a bias-variance trade-off, resulting in better generalization and significantly improved model accuracy. IWBVT demonstrates effectiveness as a universal post-processing method, enhancing existing label integration and noise correction algorithms. The findings highlight the importance of prioritizing model quality in crowdsourcing.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in crowdsourcing and machine learning because it addresses the critical issue of model quality, a frequent shortcoming of existing label integration and noise correction algorithms. IWBVT offers a novel post-processing approach that significantly improves model accuracy, making it highly relevant to current research and opening new avenues for enhancing the reliability of crowd-sourced datasets. The methodology and results provide valuable insights and techniques for improving the practical application of crowdsourcing in various fields.
Visual Insights#

This figure illustrates the proposed instance weighting method in the IWBVT approach. The left side shows how the probability distribution P(ŷi|Li) and the complementary entropy Ent(Pi) are used to estimate the weight wi for each instance xi. The right side displays four scenarios based on different combinations of P(ŷi|Li) and Ent(Pi), showing how the weight wi is adjusted (increased or decreased) accordingly.

This table compares the performance of four instance weighting methods on several complex label distributions. The methods are compared based on their ability to assign higher weights to instances with more confident labels (i.e., labels where there is a greater consensus among annotators) and lower weights to instances with less confident labels (i.e., ambiguous labels). The results show that the proposed method in the paper is superior to the existing methods in distinguishing complex distributions.
In-depth insights#
Bias-Variance Trade-off#
The concept of the bias-variance trade-off is central to machine learning, representing the balance between model accuracy and its generalizability. High bias implies the model is too simplistic, failing to capture the complexity of the data and leading to underfitting. Conversely, high variance suggests an overly complex model that fits the training data too closely, resulting in overfitting and poor performance on unseen data. The IWBVT approach, by focusing on instance weighting and probabilistic loss regressions, directly addresses this trade-off. By mitigating the impact of unreliable instances, IWBVT aims to reduce variance. The probabilistic loss regression then fine-tunes the model, seeking an optimal balance between bias and variance to improve overall generalization. The success of IWBVT hinges on its ability to effectively weigh instances to remove the noise and inaccuracies that contribute to high variance, allowing for a more robust and generalizable model.
Instance Weighting#
The concept of instance weighting, crucial in the paper, addresses the challenge of inconsistent data quality in crowdsourcing. Intractable instances, those difficult to label even by experts, significantly impact model accuracy. The proposed weighting method cleverly mitigates this by leveraging complementary set and entropy. It assigns lower weights to instances with high entropy in their label distributions, implying ambiguity and unreliability. This approach is particularly significant because it addresses limitations of existing methods, which struggle with complex label distributions, thereby enhancing the robustness and generalizability of the model. By effectively down-weighting unreliable data points, instance weighting facilitates a bias-variance trade-off, ultimately resulting in improved model quality and reduced generalization error. This technique is a novel contribution, acting as a universal post-processing step to boost the performance of existing label integration and noise correction algorithms, improving model quality without significantly impacting label quality.
IWBVT Algorithm#
The IWBVT algorithm tackles the challenge of improving model quality in crowdsourced datasets by addressing the limitations of existing label integration and noise correction methods. Its core innovation is a novel instance weighting scheme that leverages complementary set and entropy to identify and mitigate the impact of intractable instances – those that are difficult to label accurately due to ambiguous attributes. This weighting is crucial because intractable instances disproportionately harm model quality, unlike label quality where their effect is less pronounced. IWBVT further enhances model quality by incorporating probabilistic loss regressions based on bias-variance decomposition, which strategically balances bias and variance to minimize generalization error. This two-pronged approach of effective instance weighting and bias-variance trade-off makes IWBVT a versatile post-processing technique applicable to a range of existing label integration and noise correction algorithms, offering a universal method to significantly boost model performance in various crowdsourced scenarios.
Model Quality Focus#
The research paper emphasizes a shift in focus from solely improving label quality in crowdsourced datasets to prioritizing model quality. This means the goal isn’t just to get highly accurate integrated labels from multiple annotators, but to use those labels to train models that generalize well to unseen data. The paper argues that existing methods, while effective at improving label accuracy, often fail to significantly boost model performance because of intractable instances which confound model training. Therefore, the proposed IWBVT method directly targets model quality by using instance weighting to down-weight the effect of such problematic data points, and by explicitly optimizing for a bias-variance trade-off. This refined approach is demonstrated as a universal post-processing technique applicable to various state-of-the-art label integration and noise correction algorithms, promising a substantial improvement in real-world model performance.
Future Enhancements#
Future enhancements to the IWBVT model could focus on several key areas. Improving robustness to diverse data distributions is crucial; the current model may struggle with highly skewed or complex label distributions. Exploring alternative instance weighting methods beyond the proposed entropy-based approach could lead to more effective weighting schemes and more robust performance. Incorporating advanced bias-variance decomposition techniques could provide a more nuanced understanding of model behavior, leading to more precise bias-variance trade-off adjustments. Investigating the effects of different loss functions in the probabilistic loss regression step is also warranted. Finally, extending IWBVT to handle various crowdsourcing scenarios, such as those with unreliable workers or complex task designs, would further enhance its practicality and generalizability. A thorough investigation into these areas would solidify IWBVT’s position as a leading post-processing technique for improving model quality in crowdsourced datasets.
More visual insights#
More on figures
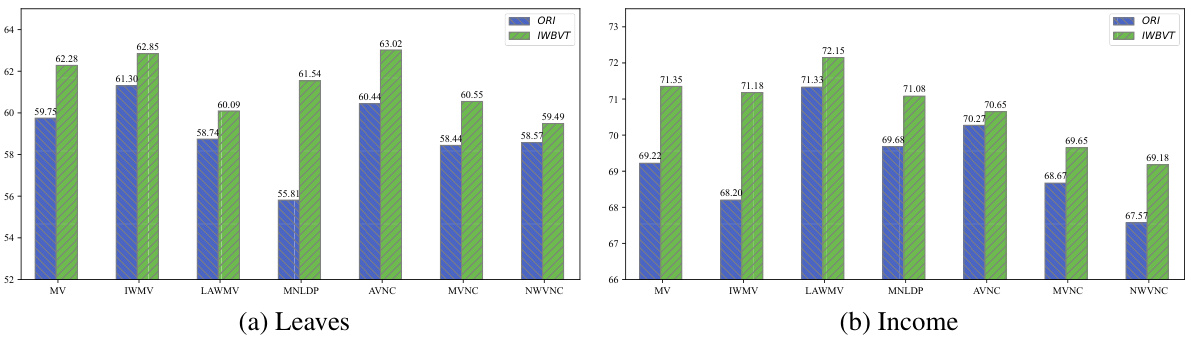
This figure compares the model quality (in percentage) of seven different algorithms (MV, IWMV, LAWMV, MNLDP, AVNC, MVNC, and NWVNC) before and after applying the proposed IWBVT method on two real-world datasets: Leaves and Income. The bars represent the model quality for each algorithm on each dataset, with the blue bars showing the original performance and green showing the improvement after IWBVT is applied. It illustrates the effectiveness of IWBVT in enhancing the performance of various state-of-the-art algorithms in real-world scenarios.

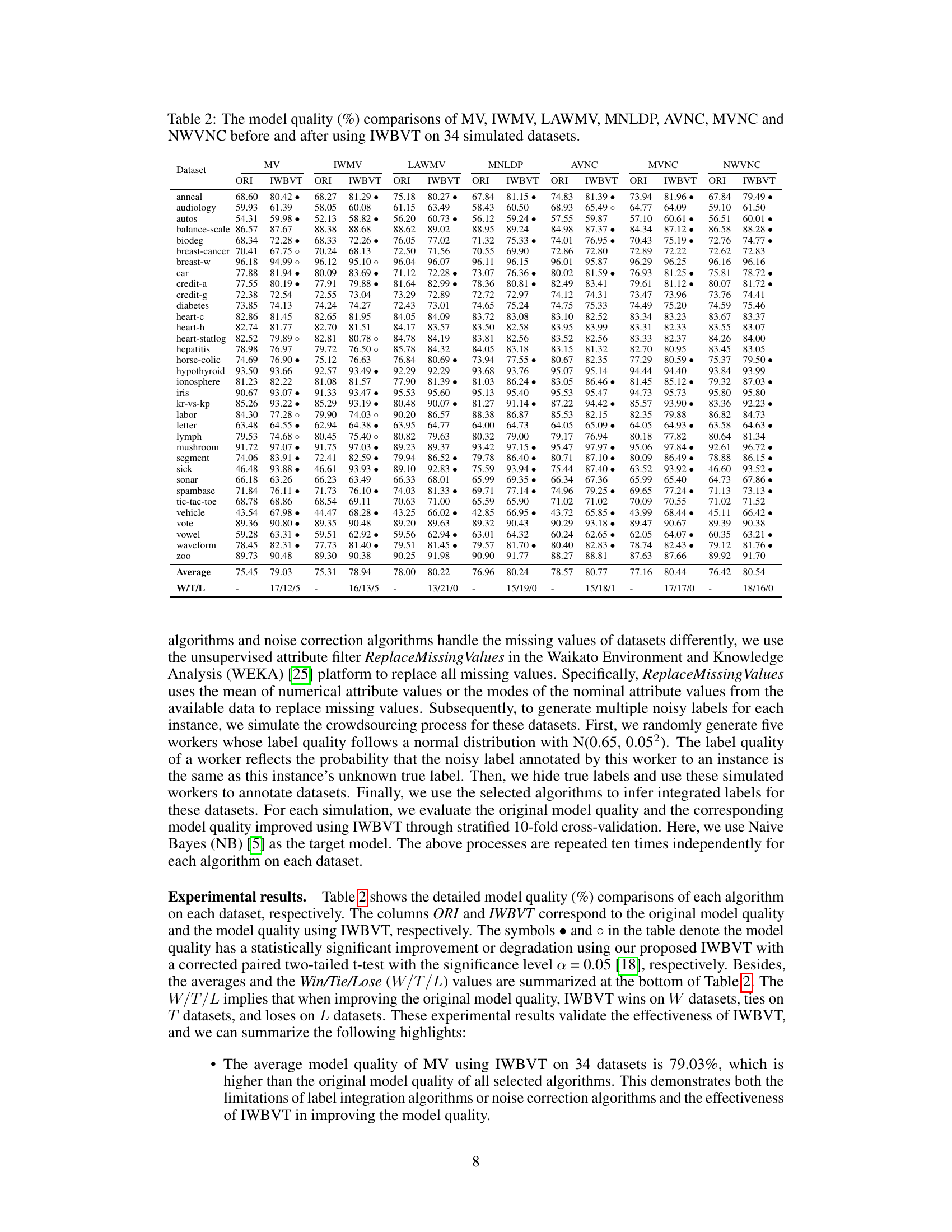
Figure 3(a) shows the bias and variance of the model trained with true labels, labels inferred by MV, labels with instance weighting, and labels with both instance weighting and bias-variance trade-off. Figure 3(b) shows the model quality of these four models. The results demonstrate that instance weighting and bias-variance trade-off improve the model quality.
Full paper#