TL;DR#
Current methods for predicting gaze and social gaze in videos often handle these tasks separately and struggle with multiple people and temporal context. This leads to models that lack generalizability and fail to fully capture social interactions. Prior work also often relies on single-person analysis, ignoring important contextual information.
The MTGS framework tackles these issues by jointly predicting gaze and social gaze labels for all individuals in a video scene. It employs a temporal transformer architecture that effectively models temporal dynamics and inter-personal interactions. The framework is evaluated on a novel dataset (VSGaze), which unifies existing data and extends annotations for better analysis. The results demonstrate state-of-the-art performance, highlighting the importance of this unified approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and social interaction analysis. It introduces a novel framework for jointly predicting gaze targets and social gaze labels for multiple people in videos. This addresses limitations of prior work by handling temporal dynamics and multi-person interactions. The results achieve state-of-the-art performance and provide a unified solution for these fundamental tasks. The publicly available code and dataset will greatly benefit the community. The proposed method also opens new avenues for research involving multi-modal data and the integration of social cues for understanding human behavior.
Visual Insights#

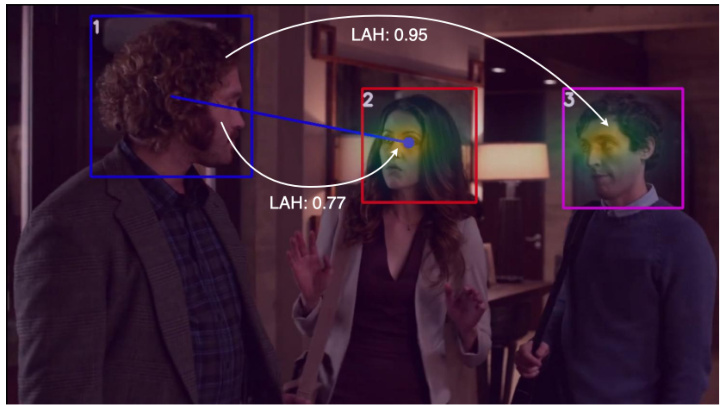
🔼 This figure shows example results from the authors’ proposed multi-person temporal transformer architecture. The model predicts gaze targets and three types of social gaze: Looking at Humans (LAH), Looking at Each Other (LAEO), and Shared Attention (SA). For each frame, the figure displays the predicted social gaze for each person, indicated by a numerical ID and labeled with the type of social interaction (LAH, LAEO, or SA).
read the caption
Figure 1: Results of our multi-person and temporal transformer architecture for joint gaze following and social gaze prediction, namely Looking at Humans (LAH), Looking at Each Other (LAEO), and Shared Attention (SA). For each person, the social gaze predictions are listed with the associated person ID (e.g. in frame 1, person 2 is in SA with person 4). More qualitative results can be found in the supplementary G.
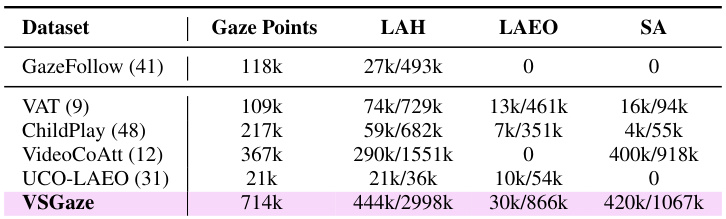
🔼 This table presents the statistics of gaze points and social gaze annotations for several datasets used in the paper. It shows the number of person-wise gaze point annotations and pair-wise social gaze annotations (both positive and negative examples) for each dataset. The table highlights the unification of annotation types within the VSGaze dataset, which combines data from multiple sources.
read the caption
Table 1: Person-wise gaze point and pair-wise social gaze annotation (positive/negative) statistics for our datasets. VSGaze unifies annotation types across VAT, ChildPlay, VideoCoAtt and UCO-LAEO.
In-depth insights#
Multi-person Gaze#
Multi-person gaze analysis presents a significant challenge in computer vision, moving beyond single-person gaze estimation to understand complex social interactions. Accurate detection and tracking of multiple gaze targets within a scene requires robust algorithms capable of handling occlusions, variations in lighting, and head poses. Further complicating the matter is the need to disambiguate gaze targets, particularly in densely populated scenarios. This necessitates advanced techniques such as incorporating temporal information to resolve ambiguities and leveraging contextual cues like body language and environmental factors to infer attentional focus. The ultimate goal is to move beyond simple gaze direction estimation to deeper semantic understanding, such as inferring shared attention, social gaze, and communicative intent, which is crucial for applications in human-computer interaction, social robotics, and clinical psychology. Successfully addressing multi-person gaze will require the development of sophisticated models that integrate multiple modalities and handle the inherent complexities of social interactions.
Temporal Modeling#
In many vision-based tasks, incorporating temporal information significantly boosts performance. The paper’s exploration of temporal modeling, though not explicitly detailed under that heading, is crucial. It uses a temporal transformer to process sequences of gaze embeddings, capturing the dynamics of gaze over time. This approach moves beyond static methods, acknowledging that gaze isn’t fixed but changes dynamically within social interactions. The effectiveness of this temporal modeling is evident in the improved performance for the shared attention task, suggesting the model better captures the subtle temporal cues crucial for understanding joint attention. However, the benefit isn’t uniformly distributed across all tasks, implying that the optimal granularity and methodology for temporal information integration require further investigation. The use of a temporal window, rather than continuous sequences, represents a design choice balancing computational efficiency with the information captured. Further research could explore alternative temporal architectures to fully unlock the potential of temporal data within this task.
VSGaze Dataset#
The VSGaze dataset represents a significant contribution to the field of gaze estimation and social gaze prediction. By unifying multiple existing datasets, it addresses the critical limitation of limited scale and diversity in temporal gaze data. VSGaze’s unified annotation types across different datasets facilitate joint training of gaze following and social gaze prediction models, enabling more comprehensive and accurate analyses of social interactions. The inclusion of head track annotations ensures that all individuals in a scene are accounted for, even in cases with missing annotations in the source datasets. This aspect is particularly crucial for evaluating multi-person social interactions. While the dataset skews towards negative social interaction cases, this reflects a realistic distribution which is important for model robustness and generalization. The development of new social gaze protocols and metrics further enhances VSGaze’s value for evaluating model performance, particularly from a social interaction perspective. Overall, VSGaze establishes a robust and valuable resource, promoting substantial advancements in both the understanding and modeling of social dynamics via gaze.
Joint Prediction#
The concept of “Joint Prediction” in the context of a multi-person gaze following and social gaze prediction model is a significant advancement. Instead of treating gaze following and social gaze prediction as separate tasks, a joint prediction approach attempts to simultaneously model both. This has several key advantages. First, it leverages the inherent interdependencies between gaze direction and social interactions; information from one task can inform and improve the accuracy of the other. Second, a joint model is potentially more efficient computationally, avoiding redundant processing steps compared to a pipeline approach. Third, joint training can lead to a more holistic and integrated understanding of the visual scene and the social dynamics within it, potentially improving overall performance beyond what would be possible with independently trained models. However, a joint prediction model introduces additional complexity in the design and training of the neural architecture, requiring careful consideration of the model’s capacity to learn the nuances of multi-person interaction. The success of a joint approach will hinge upon the quality and quantity of training data, which must adequately represent the multifaceted nature of real-world social interactions.
Future Directions#
Future research directions stemming from this multi-person gaze following and social gaze prediction work could involve exploring more complex social interactions beyond dyadic relationships, perhaps incorporating group dynamics and hierarchical structures within social scenes. Improving the model’s robustness to noisy or occluded data is also crucial, potentially through the integration of additional modalities like depth information or improved temporal modeling techniques. The current model’s reliance on head detection could be mitigated by developing more robust gaze estimation techniques that are less dependent on precise head localization. This might involve leveraging alternative cues like pupil dilation or eye-tracking algorithms that operate even when faces are partially obscured. Lastly, exploring the generalizability of the model to diverse populations and cultural contexts would greatly increase its value and impact, requiring significant efforts in data collection and model design.
More visual insights#
More on figures
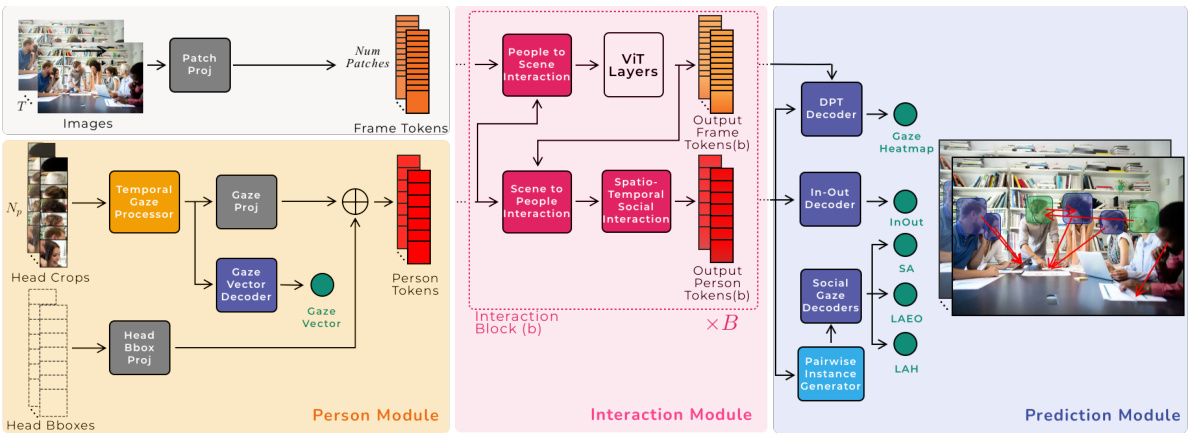
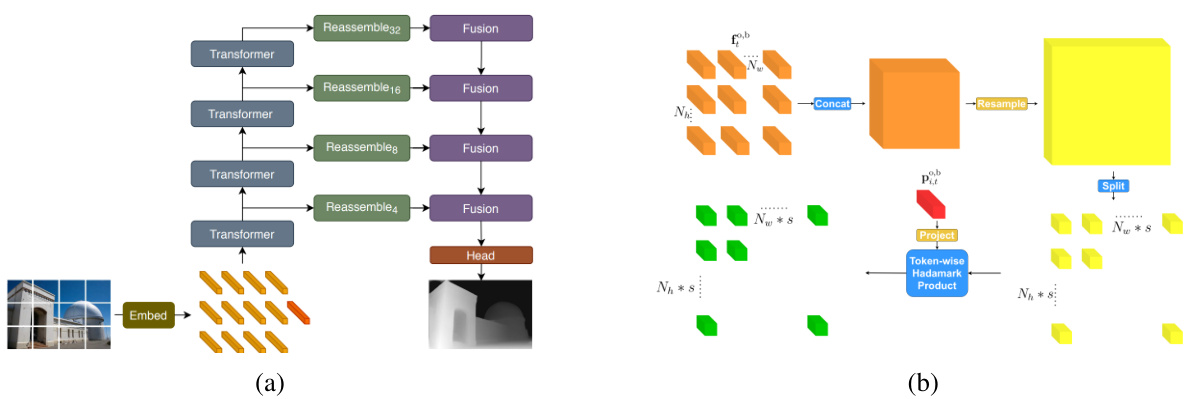
🔼 This figure illustrates the proposed architecture for jointly predicting gaze target and social gaze label for all people in a scene. It consists of three main modules: (1) a Person Module processes head crops to produce person-specific tokens capturing gaze information and temporal dynamics; (2) an Interaction Module jointly processes frame and person tokens using transformer-based layers with person-scene and spatio-temporal social interactions; (3) a Prediction Module predicts gaze heatmaps, in-out gaze labels and social gaze labels (LAH, LAEO, SA) using the output frame and person tokens.
read the caption
Figure 2: Proposed architecture for multi-person temporal gaze following and social gaze prediction. See approach overview in Section 3.
🔼 This figure shows example results from the model for multi-person gaze following and social gaze prediction. The model predicts three types of social gaze: Looking at Humans (LAH), Looking at Each Other (LAEO), and Shared Attention (SA). For each frame, the figure displays the predicted social gaze labels for each person, along with their corresponding ID numbers. The caption indicates that more qualitative results are available in supplementary material G.
read the caption
Figure 1: Results of our multi-person and temporal transformer architecture for joint gaze following and social gaze prediction, namely Looking at Humans (LAH), Looking at Each Other (LAEO), and Shared Attention (SA). For each person, the social gaze predictions are listed with the associated person ID (e.g. in frame 1, person 2 is in SA with person 4). More qualitative results can be found in the supplementary G.
🔼 The figure shows the architecture of a novel framework for jointly predicting gaze target and social gaze label for all people in a scene. It uses a temporal transformer-based architecture with person-specific tokens and frame tokens. The architecture consists of three modules: a Person Module, an Interaction Module, and a Prediction Module. The Person Module processes head crops to generate person tokens. The Interaction Module processes interactions between person and scene tokens to capture spatio-temporal social interactions. Finally, the Prediction Module predicts gaze heatmaps, in-out gaze labels, and social gaze labels.
read the caption
Figure 2: Proposed architecture for multi-person temporal gaze following and social gaze prediction. See approach overview in Section 3.

🔼 This figure shows qualitative results comparing the performance of three different models: the proposed model, the model with speaking information, and the model without temporal information. The results are presented visually for three different video clips, illustrating how each model performs in predicting gaze targets and social gaze labels in different scenarios. The visualizations highlight how the inclusion of speaking information and temporal modeling affect the accuracy and robustness of the predictions.
read the caption
Figure 5: Qualitative results of our proposed model (Ours), our model with speaking information (Ours-spk) and our model without temporal information (Ours-static). When the target is predicted to be inside the frame, we display the predicted gaze point and the social gaze tasks with the associated person id(s).

🔼 This figure shows a qualitative comparison of the results obtained from three different models: the proposed model (Ours), a model incorporating speaking information (Ours-spk), and a static model without temporal information (Ours-static). The results are presented as image sequences, highlighting predicted gaze points and social gaze labels (LAH, LAEO, SA) for each person. The comparison aims to illustrate the impact of incorporating temporal and speaking information on the accuracy of gaze prediction and social gaze analysis.
read the caption
Figure 5: Qualitative results of our proposed model (Ours), our model with speaking information (Ours-spk) and our model without temporal information (Ours-static). When the target is predicted to be inside the frame, we display the predicted gaze point and the social gaze tasks with the associated person id(s).

🔼 This figure compares the qualitative results of the proposed model against three other state-of-the-art methods in various complex scenarios. The scenarios showcase challenging situations such as obscured eyes, multiple salient targets, and varied settings and age groups. The results demonstrate the superior performance of the proposed model compared to the other methods.
read the caption
Figure 6: Qualitative comparison of our model against other methods Chongs, Chongт (9), Gupta (17). Our model performs better overall, outperforming other methods in complex scenes with obscured eyes, multiple salient targets, varied settings and age groups.

🔼 This figure shows the architecture of a novel framework for jointly predicting gaze target and social gaze label for all people in a scene. It’s a temporal transformer-based architecture using frame tokens and person-specific tokens to capture gaze information and temporal dynamics. It includes a Person Module, an Interaction Module, and a Prediction Module. The Person Module processes individual head crops to extract gaze-related information. The Interaction Module incorporates both person and scene tokens through a cross-attention mechanism, modeling the interactions between people and the scene. The Prediction Module predicts the gaze heatmaps, in-out gaze labels, and social gaze labels (LAH, LAEO, SA).
read the caption
Figure 2: Proposed architecture for multi-person temporal gaze following and social gaze prediction. See approach overview in Section 3.

🔼 This figure shows the architecture used for multi-person temporal gaze following and social gaze prediction. It consists of three main modules: a Person Module that processes head crops and bounding boxes for each person; an Interaction Module that models interactions between people and the scene; and a Prediction Module that outputs the gaze heatmaps, in-out labels, and social gaze labels (LAH, LAEO, and SA). The architecture includes several components such as a Temporal Gaze Processor, Gaze Vector Decoder, Person-Scene Interaction, Spatio-Temporal Social Interaction, and Pairwise Instance Generator. The figure is a visual representation of the process described in Section 3 of the paper.
read the caption
Figure 2: Proposed architecture for multi-person temporal gaze following and social gaze prediction. See approach overview in Section 3.
More on tables
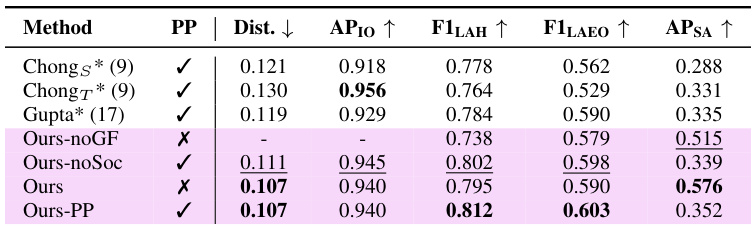
🔼 This table compares the performance of the proposed multi-person temporal gaze following and social gaze prediction model against several state-of-the-art gaze following methods. The models are evaluated using various metrics, such as average precision (AP), F1 score (F1), and average distance (Dist.) on the VSGaze dataset. The table also shows the impact of using social gaze predictions from post-processing gaze following results (PP) versus predictions directly from the decoders.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.
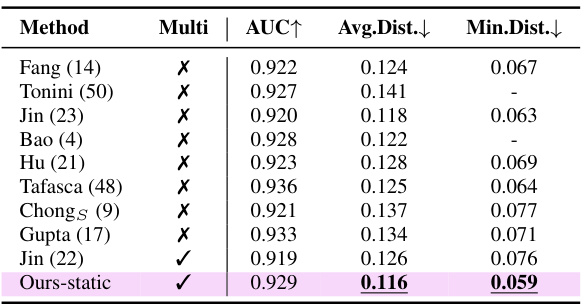
🔼 This table compares the performance of the proposed multi-person gaze following model against several state-of-the-art single-person models on four different datasets: GazeFollow, VAT, ChildPlay, and UCO-LAEO. The table shows the AUC, Average Distance, and Minimum Distance metrics, along with an indicator of whether the method was multi-person or single-person. It also presents results for two versions of the proposed model: one initialized from training on GazeFollow, and another initialized from training on the VSGaze dataset. The best results for multi-person methods and overall best results are highlighted.
read the caption
Table 3: Comparison against task specific methods fine-tuned on individual datasets. Best multi-person results are in bold, overall best results are underlined. Multi indicates multi-person (✔) vs single-person (X) gaze following methods. Ours is initialized from training on GazeFollow, while Ours† is initialized from training on VSGaze.
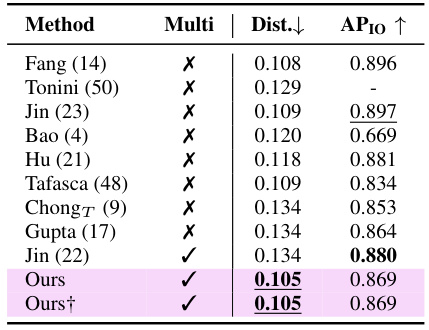
🔼 This table compares the performance of the proposed multi-person gaze following model against several state-of-the-art single-person methods on the VSGaze dataset. It shows the average distance error (Dist.), average precision at 10% (AP10) and F1 scores for looking at humans (LAH), looking at each other (LAEO), and shared attention (SA). The table also contrasts the results of using post-processing of gaze following results to obtain social gaze labels versus directly predicting them from the decoders. The best and second-best performing models are highlighted.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.

🔼 This table compares the performance of the proposed multi-person gaze following model against state-of-the-art single-person models on four different datasets. It shows the average distance and average precision (AP) metrics for each model. The table also highlights whether the model is multi-person or single-person and how it was initialized (either from GazeFollow or VSGaze). The best performing model in each category is bolded, and the second best is underlined.
read the caption
Table 3: Comparison against task specific methods fine-tuned on individual datasets. Best multi-person results are in bold, overall best results are underlined. Multi indicates multi-person (✔) vs single-person (X) gaze following methods. Ours is initialized from training on GazeFollow, while Ours† is initialized from training on VSGaze.
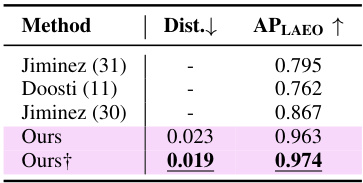
🔼 This table compares the performance of the proposed multi-person gaze following model against several single-person and multi-person state-of-the-art methods on four different datasets. It highlights the model’s performance when fine-tuned on individual datasets versus when initialized from training on a larger unified dataset (VSGaze). The metrics used are average distance error (Dist.) and Average Precision for LAEO (APLAEO).
read the caption
Table 3: Comparison against task specific methods fine-tuned on individual datasets. Best multi-person results are in bold, overall best results are underlined. Multi indicates multi-person (✔) vs single-person (X) gaze following methods. Ours is initialized from training on GazeFollow, while Ours† is initialized from training on VSGaze.

🔼 This table compares the performance of the proposed multi-person temporal gaze following and social gaze prediction model against several state-of-the-art single-person gaze following methods. It shows performance metrics such as average precision (AP) at 10% recall, F1 scores for Looking at Humans (LAH) and Looking at Each Other (LAEO) social gaze tasks, and average precision for Shared Attention (SA). The comparison highlights the model’s performance with and without post-processing social gaze predictions from gaze following outputs, demonstrating the benefits of the proposed joint prediction approach.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.

🔼 This table compares the performance of different methods for gaze following on the VSGaze dataset. It shows the performance using different approaches, including those that predict social gaze from post-processing gaze following results and those using dedicated decoders for both tasks. Metrics include average precision (AP) for in-out gaze predictions, average precision at 10 (AP10), and F1 scores for Looking At Humans (LAH) and Looking At Each Other (LAEO) social gaze tasks, and average precision (AP) for Shared Attention (SA). The best results for each metric are highlighted in bold, and the second-best results are underlined.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.
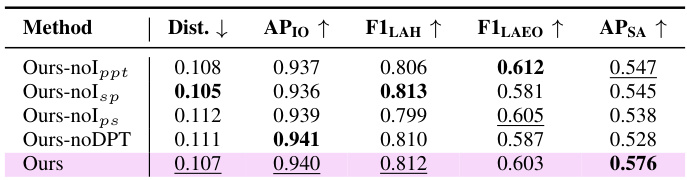
🔼 This table compares the performance of the proposed multi-person temporal gaze following and social gaze prediction model against several state-of-the-art single-person gaze following methods. The comparison is done using the VSGaze dataset. The table shows several metrics including average precision (AP) for in-out gaze prediction, average precision for the social gaze task and F1 scores for LAH and LAEO. The table highlights the performance gain achieved by jointly modeling gaze following and social gaze tasks compared to traditional post-processing approaches.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.

🔼 This table compares the performance of the proposed multi-person temporal gaze following and social gaze prediction model against existing state-of-the-art single-person gaze following methods. The comparison is done on the VSGaze dataset. It shows the Average Precision at 10 (AP10), F1-scores for Looking at Humans (LAH) and Looking at Each Other (LAEO), and Average Precision for Shared Attention (SA). The table also contrasts results when social gaze predictions are derived from post-processing gaze following outputs versus directly from the model’s decoders, highlighting the impact of the joint prediction framework.
read the caption
Table 2: Comparison against gaze following methods on VSGaze. All models were trained on VSGaze. PP indicates social gaze predictions from post-processing gaze following outputs (✔) vs predictions from decoders (X). Best results are in bold, second best results are underlined.
Full paper#



















