↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) usually have a limited context window, hindering their performance on tasks requiring longer contexts. Existing methods to extend this window often necessitate extensive fine-tuning at the target length or struggle to utilize information from the middle of the context, leading to the ‘Lost-in-the-Middle’ problem. These issues significantly impact the model’s ability to effectively process and understand extended contexts.
This paper introduces CREAM, a novel method that addresses these challenges. CREAM cleverly manipulates positional encodings to interpolate them effectively, allowing for extension to much longer context lengths while only requiring fine-tuning at the pre-trained context window size. Furthermore, CREAM incorporates a truncated Gaussian distribution during training to enhance the model’s focus on middle context information, thereby mitigating the ‘Lost-in-the-Middle’ problem. Experiments demonstrate that CREAM successfully extends LLMs to longer contexts, outperforming existing methods in both efficiency and accuracy on various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents CREAM, a novel and efficient method for extending the context window of large language models. It addresses the limitations of existing methods by improving training efficiency and focusing on information from the middle of long contexts, a critical area where many current models struggle. This work opens new avenues for research in long-context LLMs and has potential implications for numerous downstream applications.
Visual Insights#

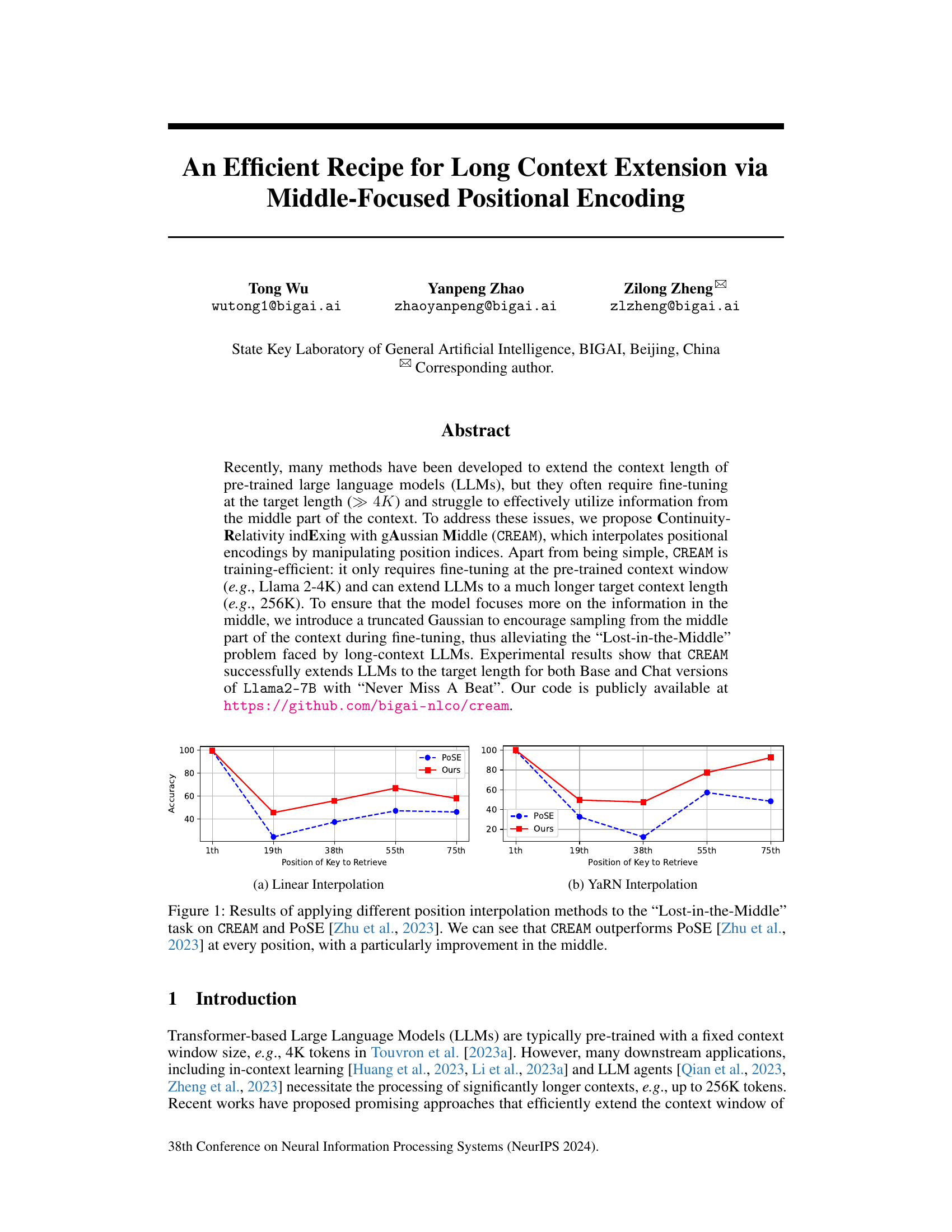
The figure shows the results of applying different position interpolation methods (linear and YaRN) to the task of retrieving information from the middle of a long context. The x-axis represents the position of the key to be retrieved, and the y-axis represents the accuracy. The results show that CREAM consistently outperforms the baseline (PoSE) across all positions, especially in the middle, demonstrating its effectiveness in mitigating the ‘Lost-in-the-Middle’ problem, which is common in long-context LLMs. This highlights CREAM’s ability to effectively utilize information from the middle part of a long context.

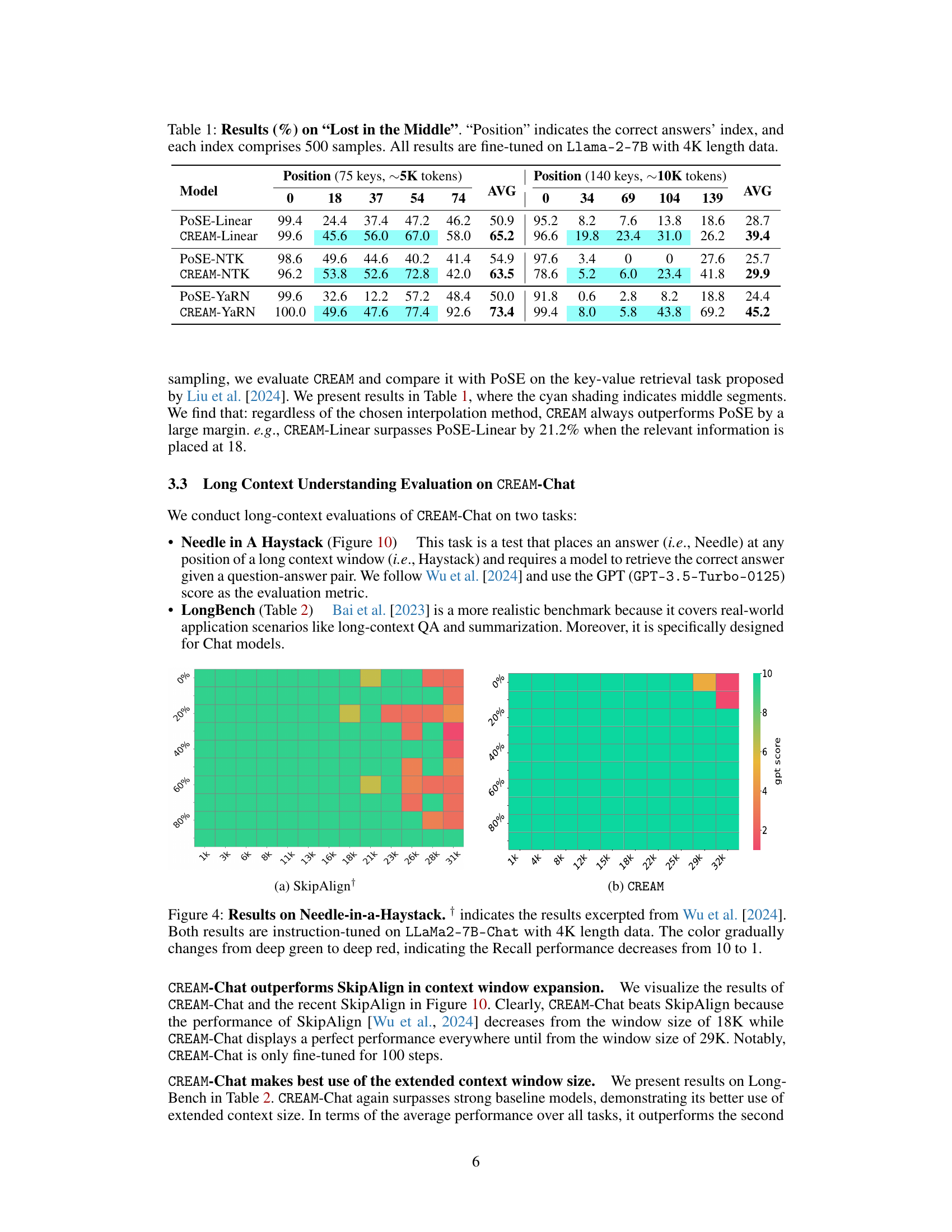
This table presents the results of the experiment on the ‘Lost-in-the-Middle’ task. The task evaluates the ability of different models to retrieve information from various positions within a long sequence. The table compares the performance of PoSE and CREAM with different interpolation methods (Linear, NTK, YaRN) across five key positions (0, 18, 37, 54, 74) for sequences of approximately 5K tokens and five key positions (0, 34, 69, 104, 139) for sequences of approximately 10K tokens. The average performance across all positions is also provided for each model and interpolation method. The results highlight the improvement of CREAM over PoSE.
In-depth insights#
Gaussian Middle Focus#
The concept of “Gaussian Middle Focus” in the context of long-context LLMs suggests a method to address the “Lost-in-the-Middle” problem, where models struggle to effectively utilize information from the central parts of extended text sequences. This approach likely involves using a truncated Gaussian distribution to weight the positional encodings. By assigning higher weights to the middle tokens using a Gaussian function, the model is encouraged to focus more attention on this crucial region during training and inference. This technique is particularly useful for long documents where the beginning and end might be disproportionately emphasized. The truncated nature of the Gaussian prevents over-emphasis on the extreme ends, ensuring a more balanced attention across the entire context. The effectiveness would depend on the choice of mean and standard deviation for the Gaussian, and would require careful tuning for optimal performance. This method elegantly combines a simple, interpretable mechanism with a theoretically well-grounded approach. The use of Gaussian weighting would necessitate modifications to the positional encoding scheme, making this a significant change to the architecture. Experimentation would be needed to determine its effects on the overall model performance compared to alternative long-context approaches.
PE Interpolation Methods#
Positional encoding interpolation methods are crucial for extending the context window of large language models (LLMs). These methods aim to effectively map the positional encodings of longer sequences to the pre-trained context window size, avoiding catastrophic forgetting and maintaining performance. Linear interpolation is a simple baseline, but more sophisticated methods like NTK (Neural Tangent Kernel) interpolation and YaRN (Yarn interpolation) offer improved performance. The choice of method influences the model’s ability to utilize information across the extended context, particularly mitigating the “lost-in-the-middle” problem. Careful consideration of the interpolation method is vital for balancing computational efficiency with performance gains. Further research should explore novel interpolation techniques that optimize for specific LLM architectures and downstream tasks, focusing on both accuracy and computational efficiency.
Long Context Efficiency#
Long context efficiency in LLMs is a crucial area of research, focusing on enabling models to process significantly longer sequences than their pre-trained limit. The core challenge lies in the quadratic complexity of self-attention, making it computationally expensive to extend context windows drastically. Current approaches often involve techniques like positional encoding interpolation, which aim to cleverly map longer sequences to the original context window size, allowing fine-tuning without retraining from scratch. Efficient methods are critical to unlock the full potential of LLMs for tasks demanding vast contextual understanding, such as summarization of extensive documents or complex question answering spanning multiple paragraphs. However, simply increasing context length isn’t sufficient; maintaining accuracy and avoiding the “lost-in-the-middle” problem, where information from the center of long sequences becomes less accessible, is equally important. Therefore, research emphasizes methods that intelligently weigh contextual information, potentially using attention mechanisms or specialized sampling strategies. Future research needs to strike a balance between computational efficiency and the ability to accurately utilize information across extremely long contexts.
CREAM’s Limitations#
While CREAM shows promise in extending context windows for LLMs, several limitations warrant consideration. Fine-tuning remains necessary, even though it’s performed within the pre-trained context window size; this still requires computational resources. The method’s performance is heavily reliant on the choice of positional interpolation method, with variations in accuracy observed across Linear, NTK, and YaRN interpolations. The truncated Gaussian sampling, designed to focus on the middle of the context, might not be universally optimal and further investigation into its parameter tuning is needed. Finally, CREAM’s effectiveness could be context-dependent; its generalization capabilities across diverse downstream tasks and different LLMs require additional testing and validation. Further research into these areas is crucial for improving CREAM’s robustness and applicability.
Future Extensions#
Future research could explore several promising directions. Extending CREAM to other LLM architectures beyond the Llama family would validate its general applicability and robustness. Investigating alternative positional encoding schemes in conjunction with CREAM, such as more sophisticated interpolation methods, could further enhance performance. A key area for future work is analyzing CREAM’s behavior with extremely long contexts (far beyond 256K tokens) to determine its scaling limits and potential optimizations. Finally, a thorough investigation into the interaction between CREAM and instruction tuning techniques is warranted to optimize performance in specific downstream tasks and improve instruction following. Addressing these points will solidify CREAM’s place as a powerful technique and uncover further insights into the challenges of extending context windows in LLMs.
More visual insights#
More on figures
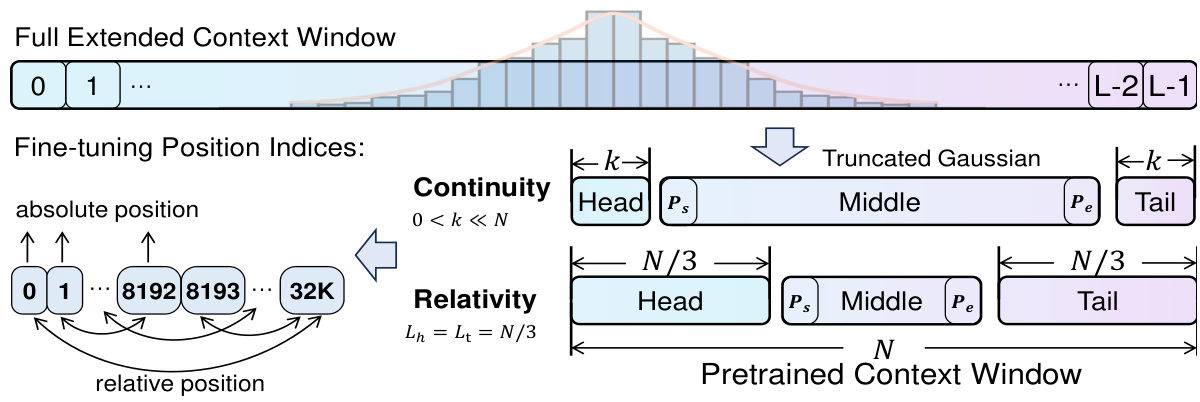
This figure illustrates the CREAM (Continuity-Relativity indExing with gAussian Middle) position interpolation method. The pre-trained context window (size N) is divided into three segments: head, middle, and tail. To maintain continuity in positional encoding, the lengths of the head and tail segments are kept small and fixed (k « N or N/3 for different strategies). Relativity is maintained by setting the head and tail to N/3 in the relativity strategy. Critically, the start and end indices of the middle segment are sampled using a truncated Gaussian distribution, focusing the model’s attention on the middle part of the longer context (size L) during fine-tuning. This addresses the ‘Lost-in-the-Middle’ problem where long-context LLMs struggle to effectively use information from the middle of the input.
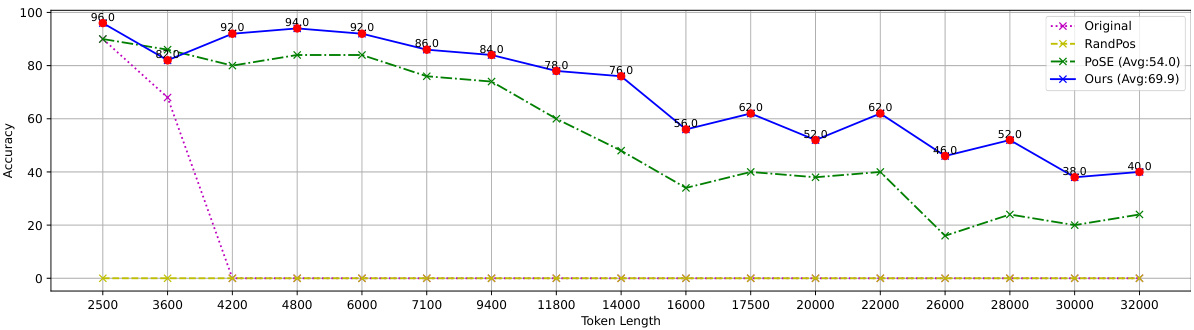
This figure compares different position interpolation methods’ performance on the “Lost-in-the-Middle” task. The task assesses the ability of a model to retrieve information from the middle of an extended context. Two methods are compared against the proposed CREAM method: linear interpolation and YaRN interpolation. The graph shows that CREAM consistently outperforms other methods across various positions in the context, particularly exhibiting a significant improvement in retrieving information from the middle. This result highlights CREAM’s effectiveness in addressing the ‘Lost-in-the-Middle’ problem that is often faced by long-context LLMs.

This figure compares the performance of different position interpolation methods on the ‘Lost-in-the-Middle’ task. The task involves retrieving information from the middle of a long context. The figure shows that CREAM outperforms POSE at all positions, especially in the middle.

The figure shows the results of applying different position interpolation methods to the ‘Lost-in-the-Middle’ task on CREAM and PoSE. It compares linear and YaRN interpolation methods, demonstrating that CREAM outperforms PoSE at every position, especially in the middle. This highlights CREAM’s ability to effectively utilize information from the middle part of the context, addressing a common limitation of existing long-context LLMs.
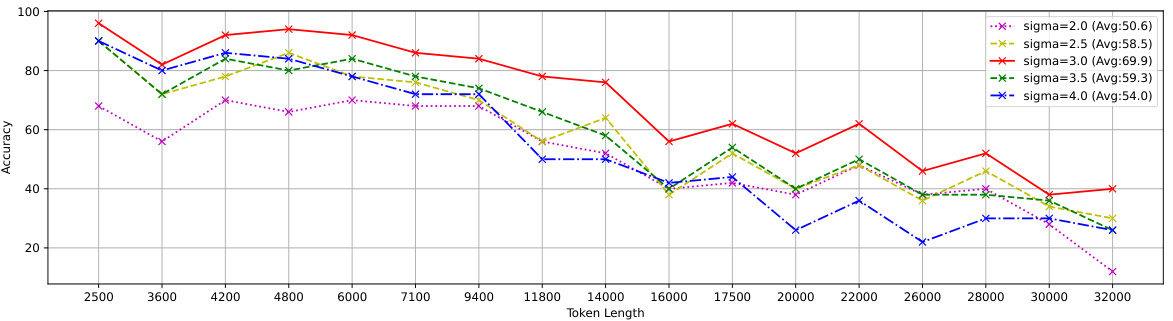
This figure shows the ablation study results on the LongChat-Lines dataset using linear interpolation on the Llama 2-7B model. It specifically investigates the impact of different values for the sigma hyperparameter (2.0, 2.5, 3.0, 3.5, and 4.0) within the truncated Gaussian distribution used in CREAM. The x-axis represents the token length, and the y-axis represents accuracy. Each line shows the accuracy across various token lengths, for a given sigma value. The average accuracy for each sigma value is included in the legend. The purpose of this analysis is to determine the optimal value for sigma, which results in the best overall performance.

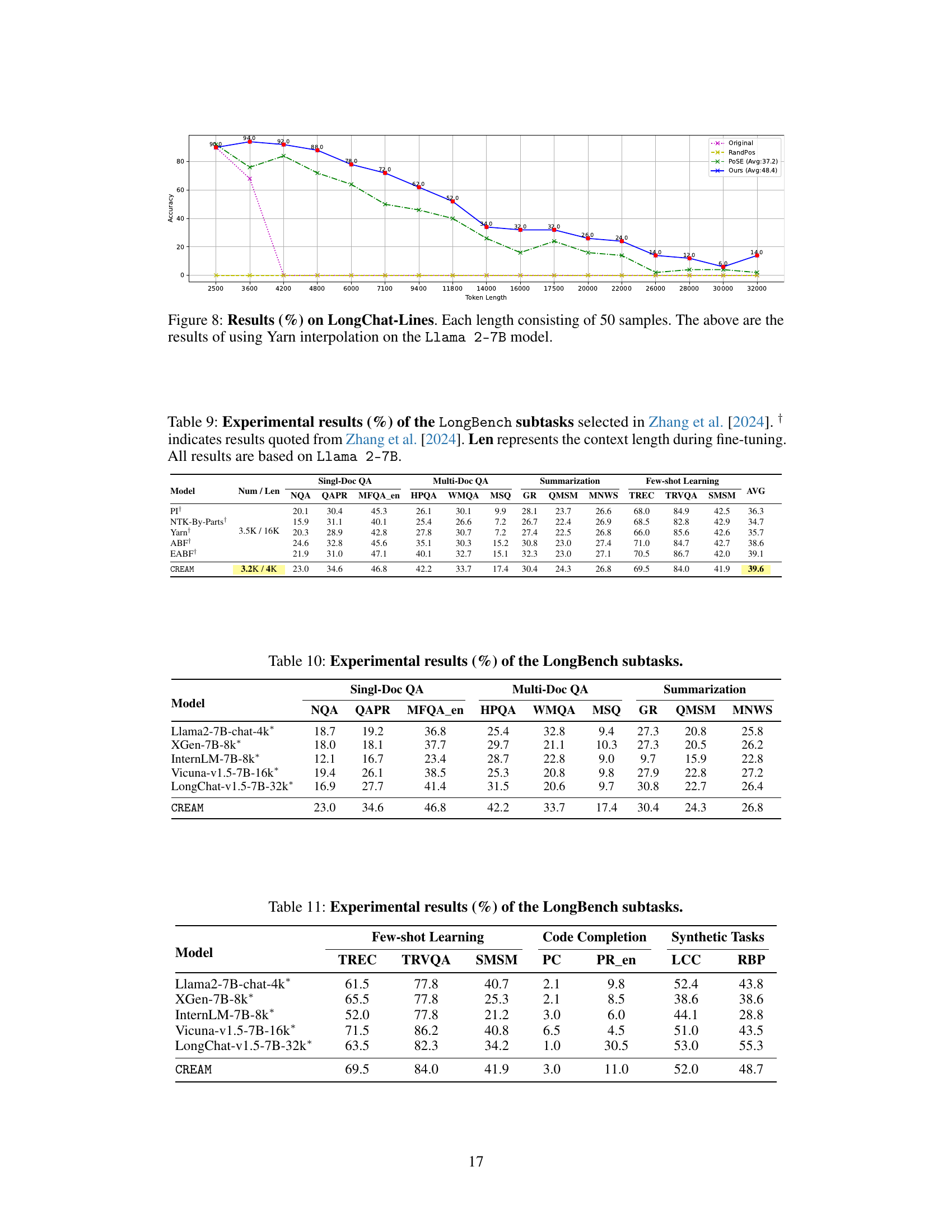
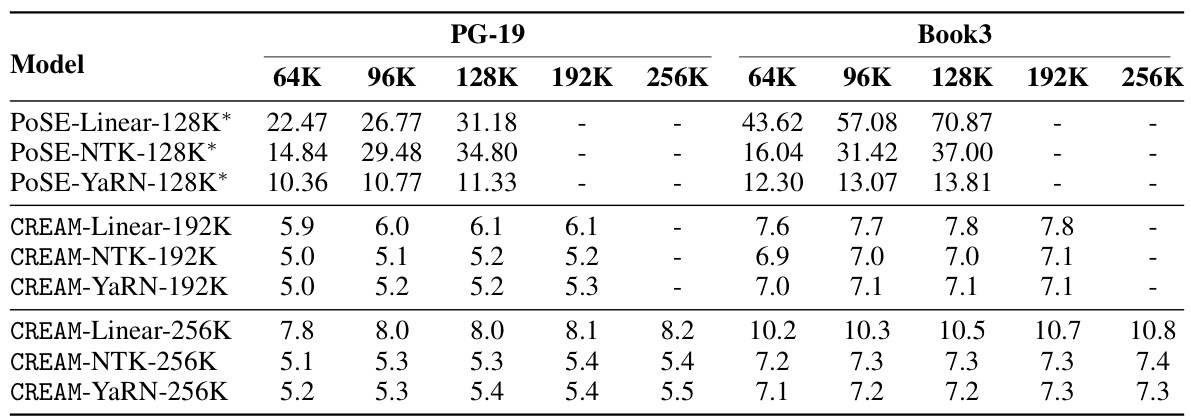
This figure displays the results of the LongChat-Lines experiment, comparing CREAM against several baseline methods (RandPos, POSE, and the original Llama-2-7B model). The y-axis represents accuracy, and the x-axis shows the token length used in the experiment. Each data point represents the average accuracy across 50 samples of that token length. The results show CREAM consistently outperforms the baselines, especially at longer context lengths, demonstrating its ability to effectively handle longer contexts while maintaining accuracy. The caption also indicates that more detailed results for other interpolation techniques are available in Appendix E.
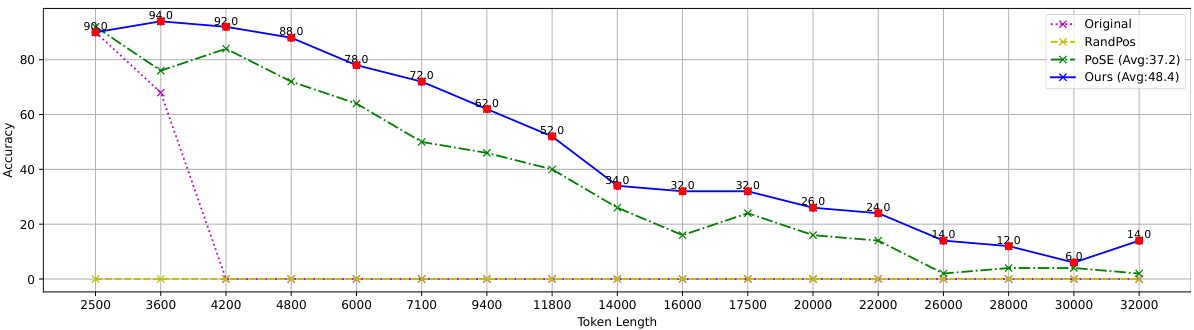
This figure shows the results of the LongChat-Lines experiment, comparing CREAM against baselines. The x-axis represents the context window size in tokens, and the y-axis represents the accuracy. Multiple lines represent different methods (Original, RandPos, POSE, and CREAM). Each point on each line is the average accuracy across 50 samples of that length. The graph illustrates CREAM’s superior performance in handling long contexts, especially at larger context window sizes. Appendix E provides additional results using different positional interpolation methods.

This figure compares the performance of different position interpolation methods on the Lost-in-the-Middle task, which is designed to evaluate the ability of LLMs to retrieve information from the middle of a long context. The results show that CREAM significantly outperforms the baseline PoSE method across all key positions, highlighting the effectiveness of the proposed method in addressing the Lost-in-the-Middle problem. The methods compared are linear interpolation and YaRN interpolation.

This figure compares the performance of different position interpolation methods (linear, YaRN) in addressing the ‘Lost-in-the-Middle’ problem for long-context LLMs. It shows that the proposed CREAM method significantly outperforms the baseline PoSE method across various key positions, especially in the middle of the context. This highlights CREAM’s effectiveness in focusing on and utilizing information from the middle section of extended contexts.
More on tables
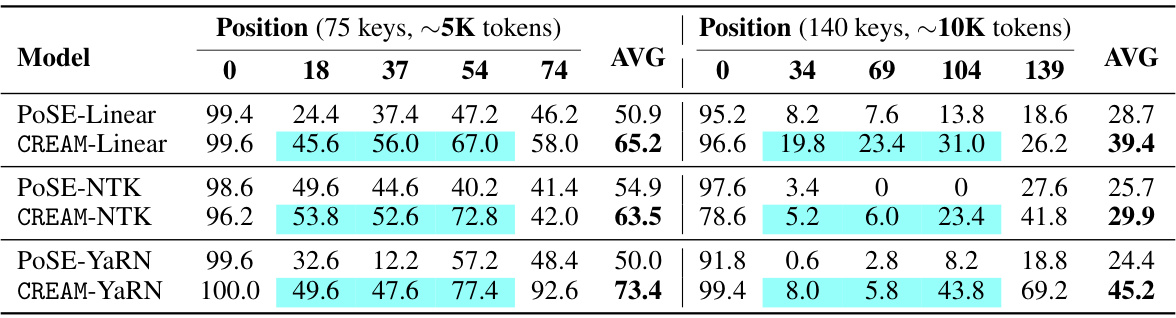
This table presents the performance of different models on the ‘Lost in the Middle’ task, a key-value retrieval task assessing a model’s ability to accurately retrieve information located at various positions within an extended context. The table shows the accuracy of POSE and CREAM models with different positional interpolation methods (Linear, NTK, YaRN) at various key positions (0, 18, 37, 54, 74 for the ~5K token length; 0, 34, 69, 104, 139 for the ~10K token length). The average accuracy across all positions is also provided. The results highlight CREAM’s improved performance over POSE, particularly in retrieving information from the middle of the context.

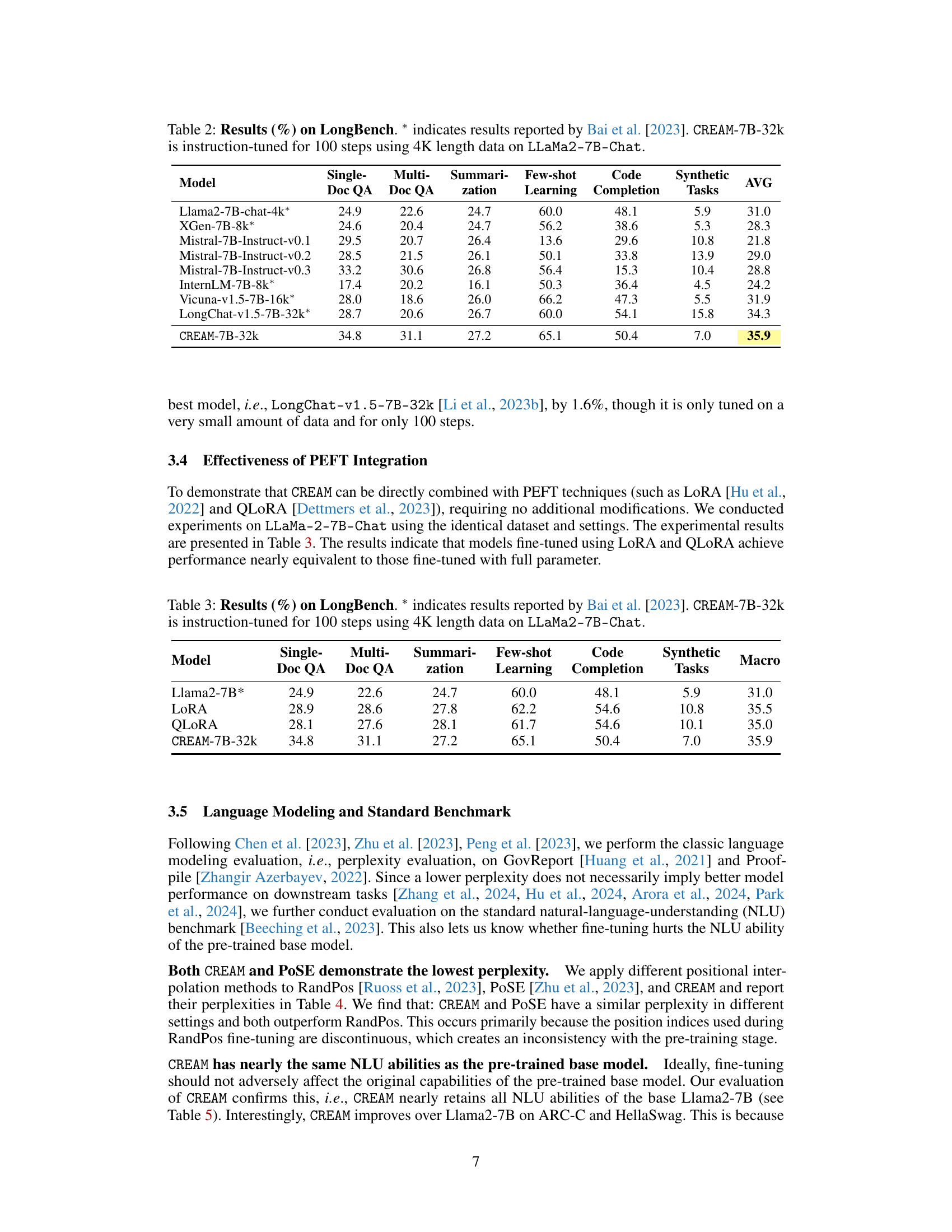
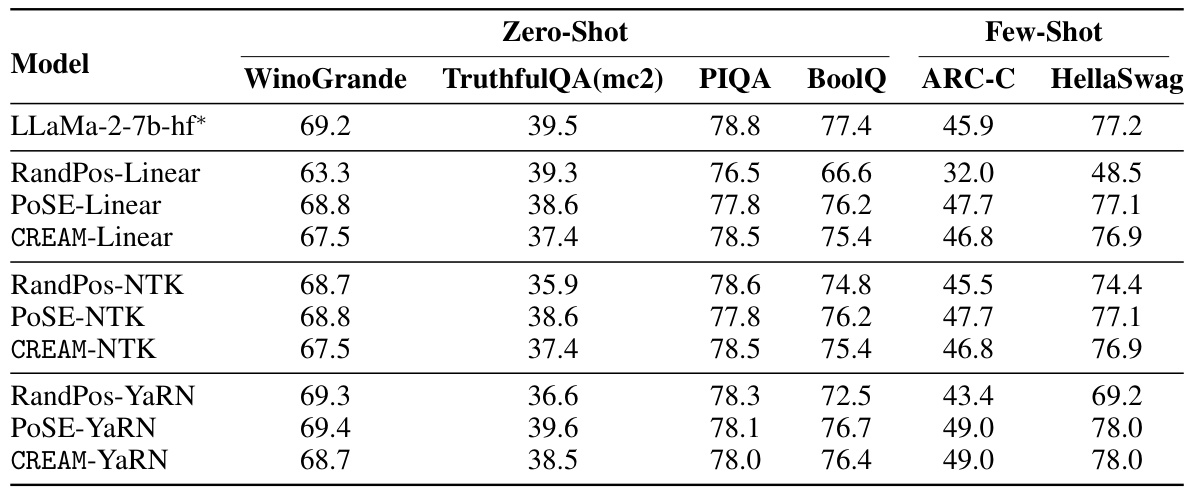
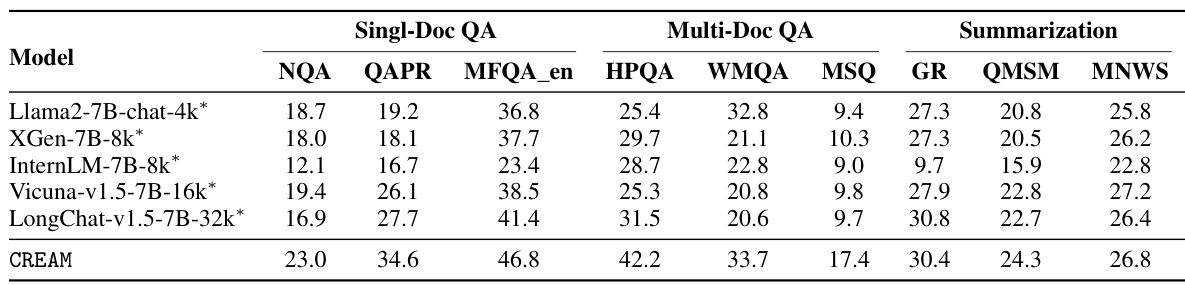
This table presents the performance of different language models on the LongBench benchmark. The models are evaluated on various subtasks, including single-document question answering, multi-document question answering, summarization, few-shot learning, code completion, and synthetic tasks. The results show CREAM-7B-32k outperforms other models, particularly in code completion, highlighting its capability in handling extended context lengths.

This table presents the results of evaluating the CREAM-7B-32k model on the LongBench benchmark, comparing its performance to other models such as Llama2-7B-chat, XGen-7B-8k, Mistral models, InternLM-7B-8k, Vicuna-v1.5-7B-16k, and LongChat-v1.5-7B-32k. The evaluation covers various subtasks including single-document QA, multi-document QA, summarization, few-shot learning, code completion, and synthetic tasks. The CREAM-7B-32k model shows competitive or superior performance compared to other models, especially considering it only underwent 100 steps of instruction tuning.
This table presents the results of the experiment on the ‘Lost in the Middle’ task. The task evaluates the ability of different models to retrieve information located in the middle of a long sequence. The table shows the accuracy of different models (POSE and CREAM with various interpolation methods) at different positions within the sequence. The data is from Llama-2-7B models fine-tuned with a 4K context window.
This table presents the results of evaluating different models on the ‘Lost in the Middle’ task. The task assesses a model’s ability to retrieve information from the middle of an extended context. The table shows the accuracy (%) of different models (POSE-Linear, CREAM-Linear, POSE-NTK, CREAM-NTK, POSE-YaRN, CREAM-YaRN) at retrieving information located at various positions (0, 18, 37, 54, 74, and 0, 34, 69, 104, 139) within the context. The average accuracy across all positions is also provided for each model. All models were fine-tuned on Llama-2-7B with a context window size of 4K tokens.
This table presents the results of the ‘Lost in the Middle’ experiment. It shows the accuracy of retrieving information from different positions within a long sequence (75 and 140 keys, corresponding to approximately 5K and 10K tokens). The models were fine-tuned on Llama-2-7B with a 4K context window. The table compares the performance of several positional interpolation methods (Linear, NTK, YaRN) applied to both the PoSE and CREAM models across various key positions within the sequence. The average accuracy for each method across all positions is also reported.

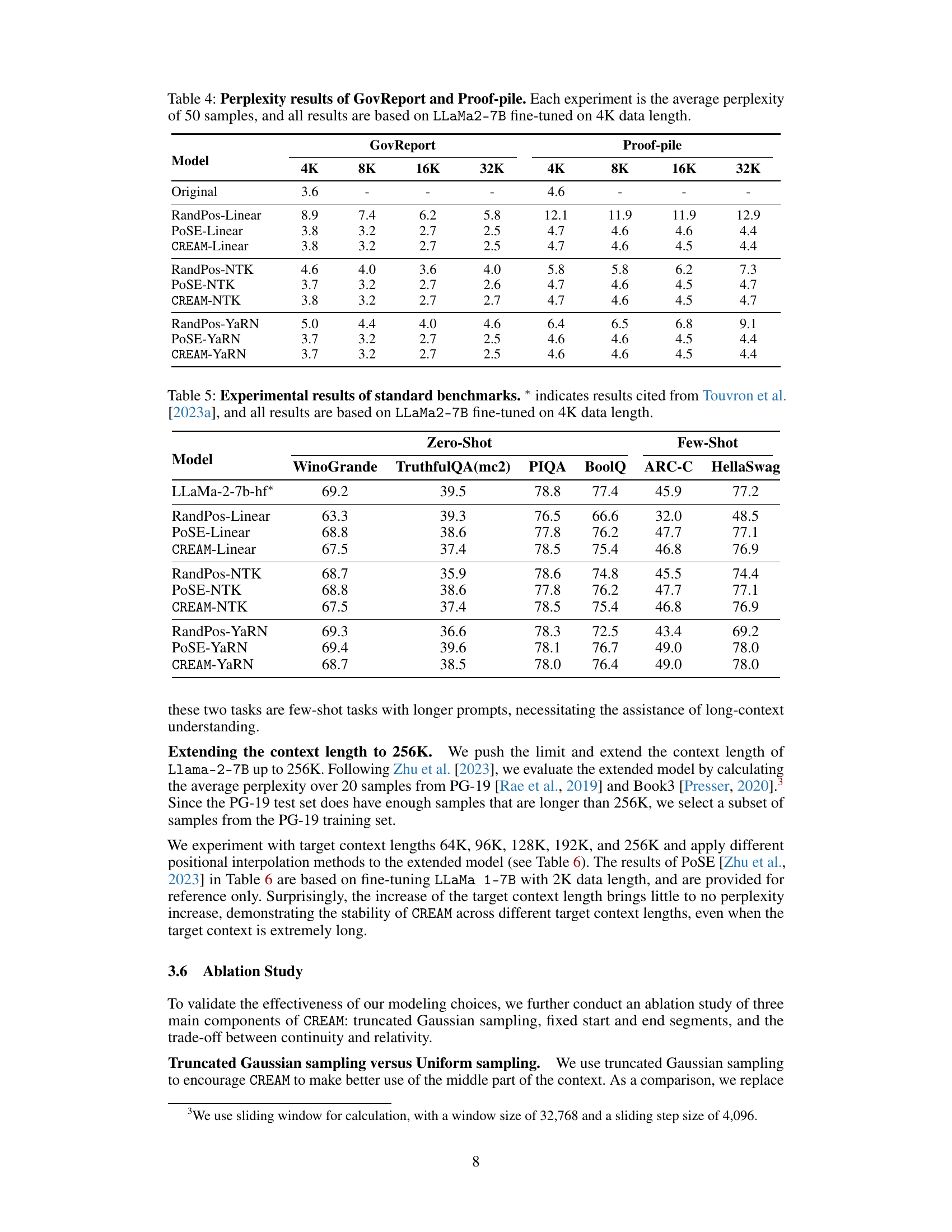
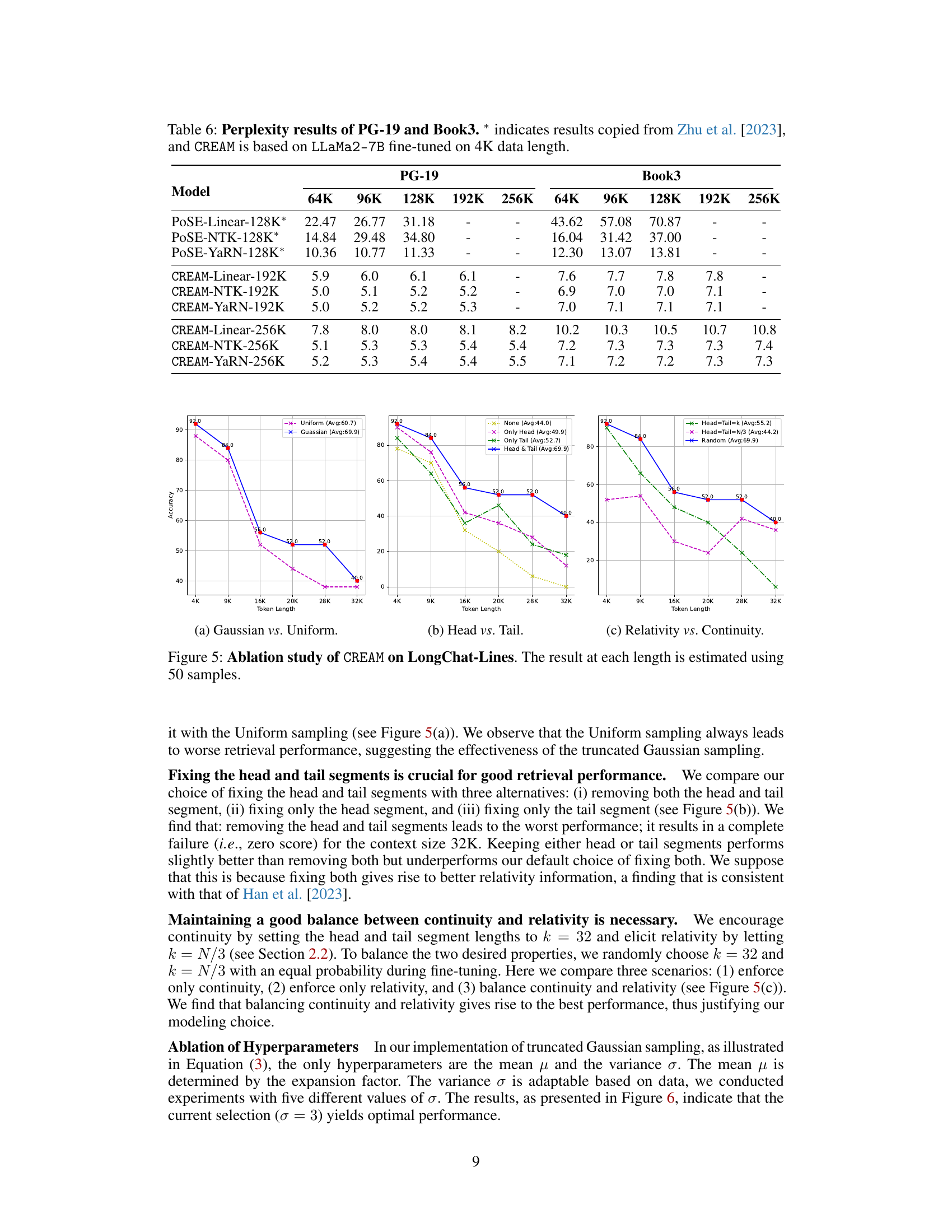
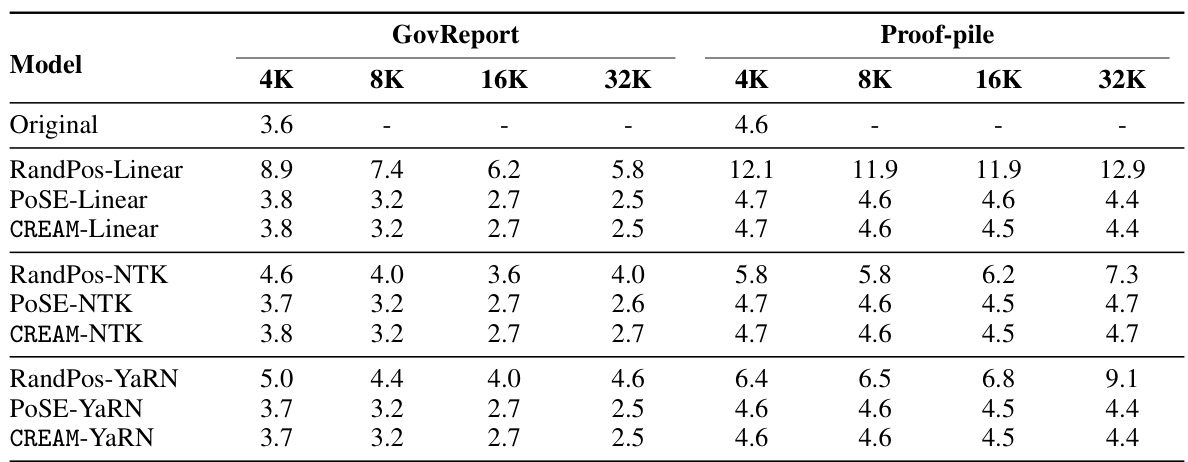
This table presents the perplexity scores achieved by the original model and CREAM-Linear model on the GovReport and Proof-pile datasets. The perplexity is calculated for different context window sizes (4K, 8K, 16K, 32K tokens). Lower perplexity indicates better performance. The results demonstrate the effectiveness of CREAM-Linear in reducing perplexity, especially as the context window size increases.

This table presents the results of the ‘Lost in the Middle’ experiment, which evaluates the ability of different models to retrieve information from various positions within a long context. The experiment uses Llama-2-7B models fine-tuned with a 4K context window. Each position index contains 500 samples. The table compares the performance of POSE and CREAM models using different interpolation methods (Linear, NTK, and YaRN). The results demonstrate CREAM’s superior performance, particularly in retrieving information from the middle of the context.

This table presents the experimental results on 12 selected subtasks from the LongBench benchmark. The results are compared across different models and different context lengths during fine-tuning. The table helps to understand the performance of various models on different subtasks, showing how the context length impacts their results. The models compared include methods such as NTK-by-Parts, Yarn, ABF, EABF, and CREAM, all based on the Llama 2-7B model.
This table presents the results of the ‘Lost-in-the-Middle’ experiment. It evaluates the ability of different models to retrieve information from various positions within a long sequence. The table shows the accuracy of each model at retrieving information from different positions (0, 18, 37, 54, 74 for the shorter sequence and 0, 34, 69, 104, 139 for the longer sequence), all of which were fine-tuned using a 4K token context window. The models compared include POSE with different interpolation methods (Linear, NTK, YaRN) and CREAM with the same interpolation methods. The average accuracy across all positions is also provided for each model and interpolation method.
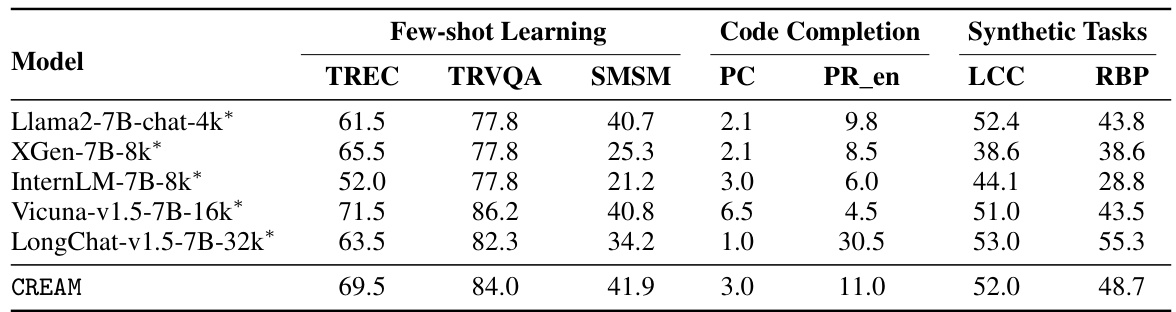
This table presents the performance of various LLMs on the LongBench benchmark’s subtasks, specifically focusing on few-shot learning, code completion, and synthetic tasks. The models compared include Llama2-7B-chat-4k, XGen-7B-8k, InternLM-7B-8k, Vicuna-v1.5-7B-16k, LongChat-v1.5-7B-32k, and CREAM. The results are shown as percentages for each subtask, offering a comprehensive comparison of their performance across different capabilities.
Full paper#