↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline reinforcement learning (RL) has seen progress in handling out-of-distribution (OOD) actions, but the problem of OOD states—where the agent encounters states unseen during training—remains under-addressed. This leads to unpredictable behavior and reduced performance, particularly in real-world scenarios with environmental variability. Existing methods often tackle OOD states and actions separately, leading to complex models and inefficiencies.
This paper introduces SCAS, a simple yet effective approach to address both OOD states and actions. SCAS achieves value-aware OOD state correction by guiding the agent from OOD states to high-value, in-distribution states. This is done by aligning a value-aware state transition distribution with the dynamics induced by the policy. This method also implicitly suppresses OOD actions, leading to improved robustness and performance. Experimental results demonstrate SCAS’s superiority on standard benchmarks, confirming its effectiveness and efficiency without extensive hyperparameter tuning.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a significant gap in offline reinforcement learning by highlighting and addressing the often-overlooked out-of-distribution (OOD) state issue. It provides a novel, unified solution (SCAS) that improves offline RL robustness, enhances performance, and offers theoretical justification, opening avenues for research in handling unseen states during deployment and improving the safety and reliability of offline RL agents. The simplicity and effectiveness of SCAS make it particularly valuable for practical applications.
Visual Insights#

This figure compares the state distributions generated by three offline RL algorithms (CQL, TD3BC, and SCAS) with the optimal state distribution on the HalfCheetah-medium-expert environment. The plots (a), (b), and (c) show that SCAS is much better at keeping its state distribution within the range of the offline data, which is an indication of its effectiveness at handling out-of-distribution (OOD) states. Plot (d) displays the optimal value for each state, visually demonstrating that SCAS successfully avoids OOD states with low values, unlike CQL and TD3BC.

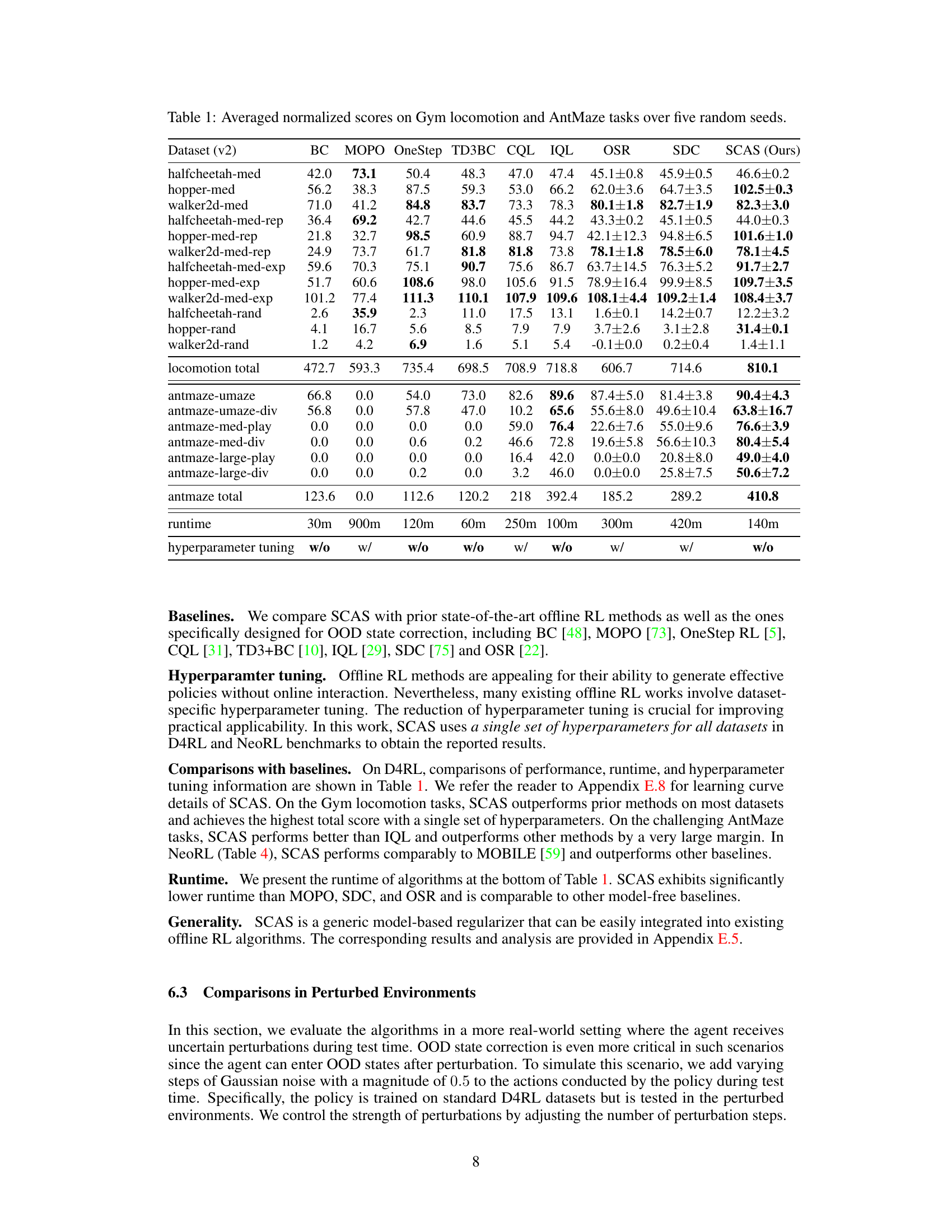
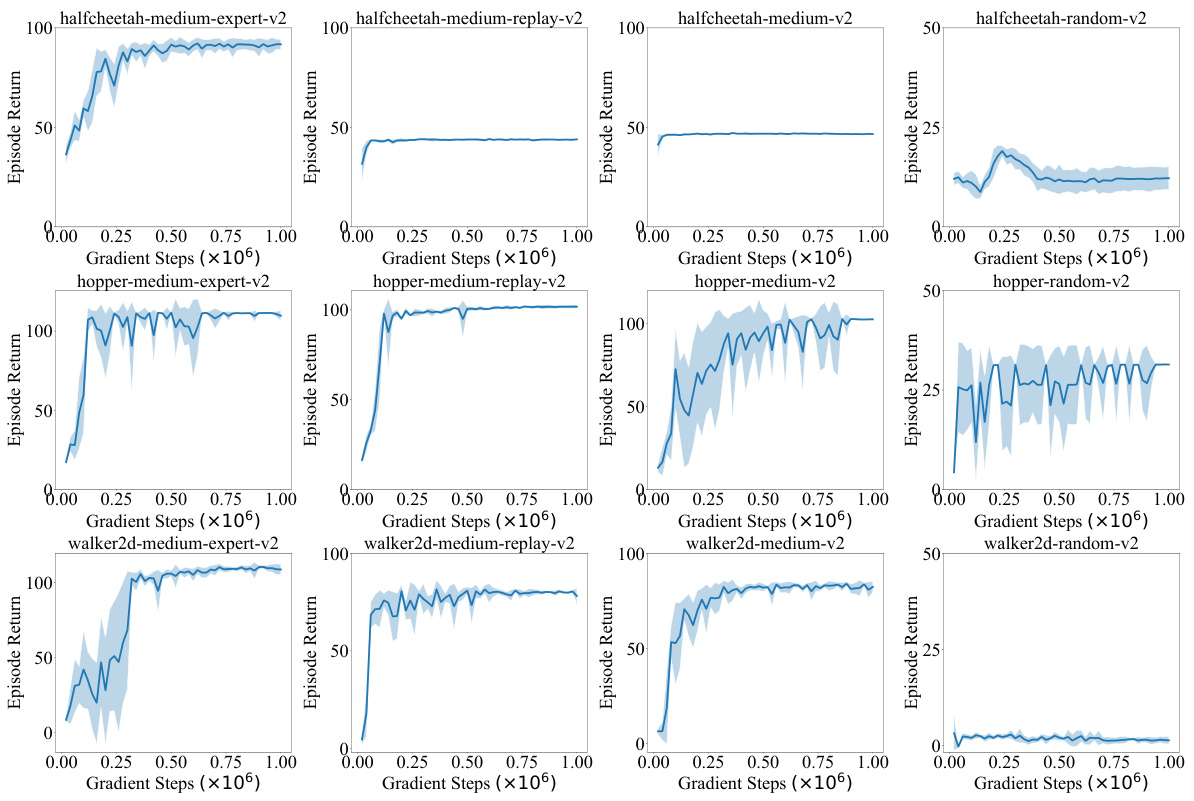
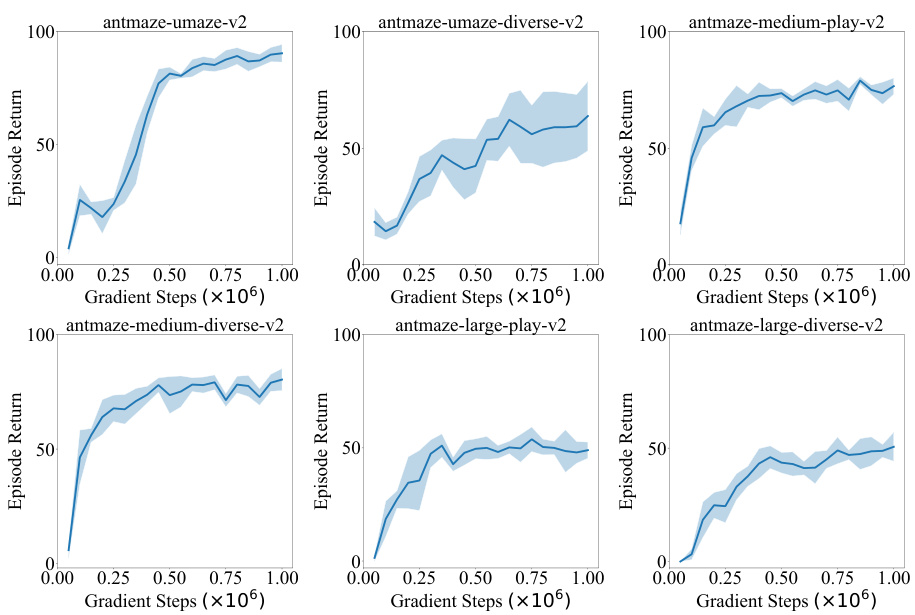
This table presents the average normalized scores achieved by different offline reinforcement learning algorithms across various locomotion and AntMaze tasks. The results are averaged over five independent runs with different random seeds to ensure reliability and statistical significance. The algorithms compared include BC, MOPO, OneStep, TD3BC, CQL, IQL, OSR, SDC, and the proposed SCAS method. The table allows for a quantitative comparison of the performance of these methods on diverse, challenging benchmark tasks.
In-depth insights#
OOD State Issue#
The “OOD State Issue” in offline reinforcement learning (RL) highlights a critical problem where an agent encounters states during testing that are significantly different from those present in the training dataset. This is distinct from the well-researched “OOD Action Issue,” which focuses on actions outside the training distribution. The presence of OOD states leads to unpredictable agent behavior and performance degradation, as the learned policy has no experience to guide actions in these unfamiliar situations. The core challenge lies in the fact that standard offline RL algorithms are trained solely on in-distribution (ID) data and thus lack the ability to generalize to unseen states. Addressing this issue requires novel methods to guide the agent from OOD states towards ID regions during the test phase, potentially by employing state correction techniques and ensuring that such corrections lead to high-value regions within the dataset distribution. Furthermore, value-aware approaches are crucial, as guiding an agent from an OOD state to any arbitrary ID state might be counterproductive if that ID state represents a low-reward condition. Therefore, a successful solution needs to combine OOD state correction with implicit or explicit mechanisms to also avoid selecting low-value ID states.
SCAS Framework#
The SCAS framework, designed for offline reinforcement learning, tackles the often-overlooked problem of out-of-distribution (OOD) states alongside the more commonly addressed OOD action issue. Its core innovation lies in unifying OOD state correction and OOD action suppression within a single, efficient approach. Value-aware state correction is a key feature, guiding the agent from OOD states towards high-value, in-distribution states rather than simply any in-distribution state. This is achieved through an analytical formulation of a value-aware state transition distribution, which is strategically aligned with the policy’s dynamics. The framework’s elegance lies in its simplicity, avoiding complex distribution modeling and achieving excellent performance without extensive hyperparameter tuning. Furthermore, the theoretical analysis demonstrates the inherent OOD action suppression, showcasing its comprehensive approach to robustness in offline reinforcement learning environments.
Value-Aware Correction#
The concept of “Value-Aware Correction” in offline reinforcement learning addresses the challenge of out-of-distribution (OOD) states, where an agent encounters states unseen during training. Standard correction methods often merely try to guide the agent back to any in-distribution state. A value-aware approach, however, is more sophisticated; it prioritizes transitions to high-value in-distribution states. This nuanced strategy is more effective because it avoids potentially steering the agent towards low-reward or suboptimal states within the in-distribution set. The core idea is to selectively correct the agent’s trajectory, prioritizing those state transitions that maximize expected future rewards. This approach could dramatically improve robustness and overall performance by preventing the agent from getting trapped in low-value regions or exhibiting undesirable behaviour when confronted with unexpected or novel situations during deployment.
OOD Action Suppression#
The concept of “OOD Action Suppression” in offline reinforcement learning (RL) centers on mitigating the risks associated with the agent taking actions outside the distribution of the training data. These out-of-distribution (OOD) actions often lead to poor performance and instability as the learned policy hasn’t been trained to handle them. Approaches to suppress OOD actions often involve methods to constrain the policy’s actions to the support of the training data’s actions, using techniques like penalizing OOD actions in the Q-value function, or directly modifying the policy to reduce probability of taking such actions. Effective OOD action suppression is crucial for safe and reliable deployment of offline RL policies in real-world scenarios where encountering OOD situations is inevitable. The challenge lies in finding the right balance between constraining actions enough to ensure safety and avoid overestimation, and allowing sufficient exploration to achieve good performance. Value-aware approaches, that prioritize correcting the agent to high-value states, potentially offer a more effective approach than simply suppressing all OOD actions indiscriminately. Future work will likely focus on developing more sophisticated and adaptive mechanisms for OOD action management, considering factors such as uncertainty and the context of the OOD action.
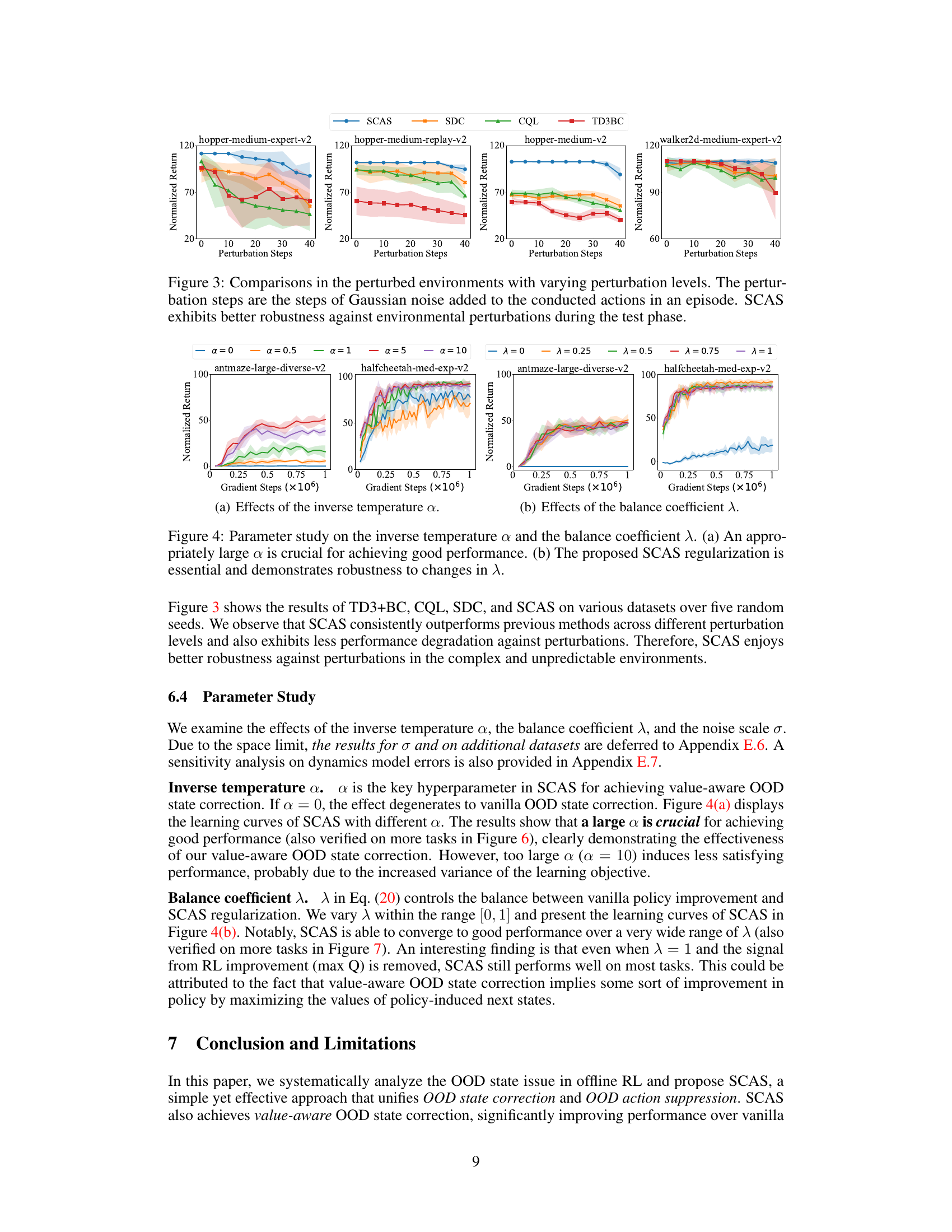
Perturbation Robustness#
The concept of “Perturbation Robustness” in the context of offline reinforcement learning (RL) centers on how well an RL agent trained on a static dataset performs when exposed to unexpected variations or disturbances during real-world deployment. A robust agent should gracefully handle these perturbations, such as sensor noise, actuator failures, or environmental changes, without significant performance degradation. This is crucial because offline RL datasets rarely perfectly capture the complexity and variability of real-world scenarios. Methods to enhance perturbation robustness often involve data augmentation techniques to make the training data more representative of the diverse conditions encountered during testing. Regularization techniques can also play a vital role, encouraging the learned policy to avoid overly sensitive regions of the state-action space where small perturbations could cause drastic performance drops. Models that explicitly estimate uncertainty in their predictions offer another promising avenue, allowing the agent to adapt its behavior based on the confidence in its predictions. Evaluating perturbation robustness typically involves testing the agent on a variety of perturbed environments or datasets, measuring its performance under different levels of disturbance. Ultimately, the goal is to develop offline RL agents that exhibit more generalizable and dependable behavior in real-world applications, even in the face of unexpected variability and unforeseen challenges.
More visual insights#
More on figures
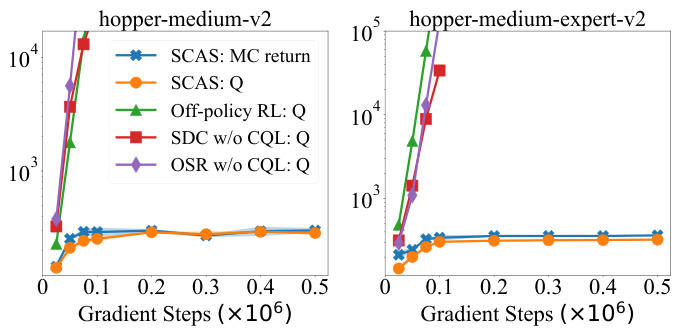
This figure compares the learned Q-values of SCAS with three baseline methods: ordinary off-policy RL, SDC without CQL, and OSR without CQL. The oracle Q-values for SCAS are estimated using Monte Carlo returns. The plot shows that the Q-values of the baseline methods diverge, indicating value overestimation and OOD actions. In contrast, SCAS’s learned Q-values remain close to the oracle values, showing that its OOD state correction effectively suppresses OOD actions and prevents overestimation.
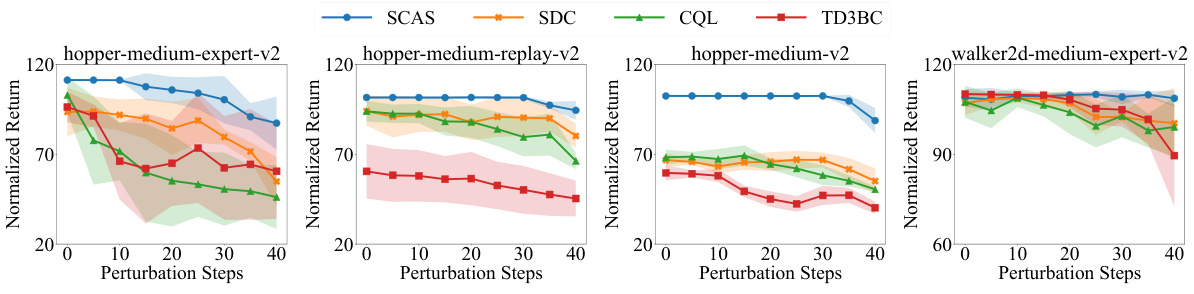
This figure compares the performance of SCAS and other offline RL algorithms (SDC, CQL, TD3+BC) in perturbed environments. The x-axis represents the number of perturbation steps (amount of Gaussian noise added to actions). The y-axis shows the normalized return, a measure of algorithm performance. The shaded regions represent the standard deviation across multiple runs. The plot demonstrates that SCAS shows greater robustness to increasing perturbation levels, maintaining higher performance than the other algorithms.
This figure compares the state distributions generated by different offline RL algorithms (CQL, TD3BC, and SCAS) with the optimal state distribution obtained from online TD3 training. It visualizes how well each algorithm’s learned policy keeps the agent’s states within the distribution of the offline dataset and avoids low-value, out-of-distribution (OOD) states. SCAS demonstrates a superior ability to remain within the in-distribution (ID) state space.
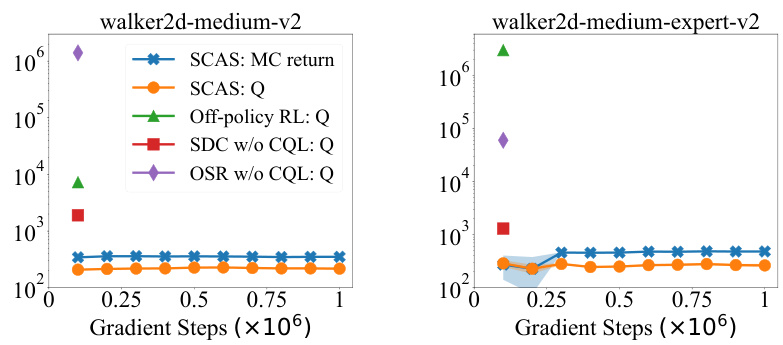
This figure compares the learned Q-values of SCAS against three baseline methods: ordinary off-policy RL, SDC without CQL, and OSR without CQL. It shows how SCAS’s unique OOD state correction prevents the Q-values from diverging (overestimating values), a common issue in offline RL caused by out-of-distribution actions. The oracle Q-values, estimated using Monte Carlo returns, serve as a ground truth comparison. The figure demonstrates that only SCAS effectively suppresses OOD actions and maintains accurate Q-value estimations during training.
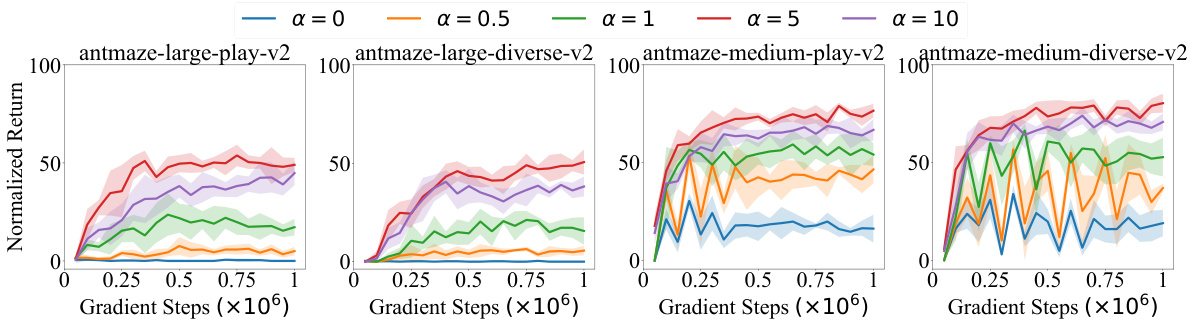
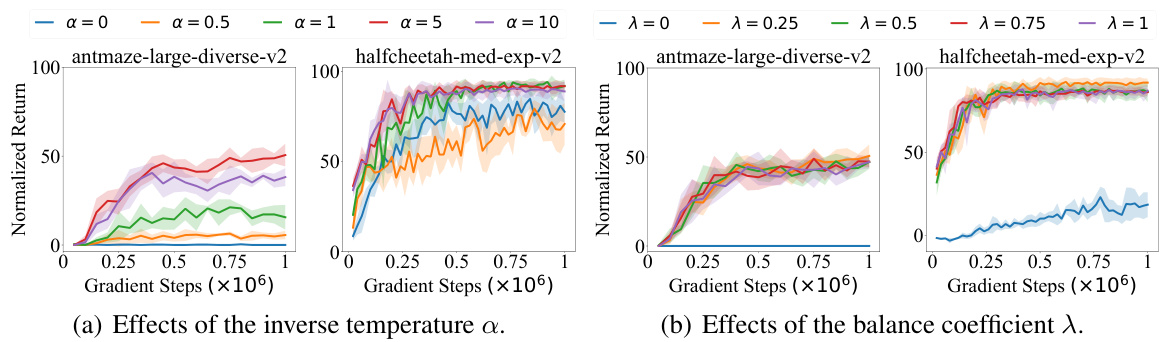
This figure shows the results of experiments on the effect of the inverse temperature α on the performance of the SCAS algorithm. It displays learning curves for SCAS with different values of α across four different AntMaze datasets. The results demonstrate that a large α is crucial for achieving good performance, showcasing the effectiveness of value-aware OOD state correction. However, excessively large α values can lead to less satisfying performance due to increased variance in the learning objective. The shaded areas represent the standard deviations across 5 random seeds.

This figure compares the performance of SCAS and other offline RL algorithms in perturbed environments. The x-axis represents the number of perturbation steps (how many times Gaussian noise was added to the actions taken during an episode), and the y-axis represents the normalized return. The figure demonstrates that SCAS exhibits enhanced robustness to environmental perturbations, maintaining better performance than the other algorithms as the number of perturbation steps increases.
This figure compares the performance of SCAS and other offline RL algorithms in perturbed environments. The x-axis shows the number of perturbation steps (amount of Gaussian noise added to actions). The y-axis represents the normalized return achieved by each algorithm. The results demonstrate that SCAS is more robust to environmental perturbations, maintaining higher performance even with a substantial number of perturbation steps, unlike the other algorithms whose performance degrades significantly. This robustness highlights the effectiveness of SCAS’s OOD state correction in handling real-world uncertainties.

This figure compares the performance of SCAS and other algorithms in perturbed environments. The x-axis represents the number of perturbation steps (how many times Gaussian noise is added to actions in an episode), and the y-axis represents the normalized return. The plot shows that SCAS is much more robust to perturbations compared to other offline RL algorithms, maintaining a significantly higher return even with a substantial number of perturbation steps.
This figure compares the state distributions generated by different offline RL algorithms (CQL, TD3BC, and SCAS) with the optimal state distribution obtained from an online TD3 algorithm. The subfigures (a), (b), and (c) show the state distributions generated by CQL, TD3BC, and SCAS respectively, in comparison to the offline dataset’s state distribution. Subfigure (d) shows the optimal value associated with each state. The key takeaway is that SCAS’s state distribution closely matches the offline dataset’s, avoiding low-value, out-of-distribution states which are present in the CQL and TD3BC results.
This figure compares the state distributions generated by different offline RL algorithms (CQL, TD3BC, and SCAS) with the optimal state distribution obtained using TD3. It shows that SCAS produces a state distribution almost entirely within the support of the offline dataset, avoiding low-value states, unlike CQL and TD3BC which tend to generate out-of-distribution (OOD) states with extremely low values.
More on tables
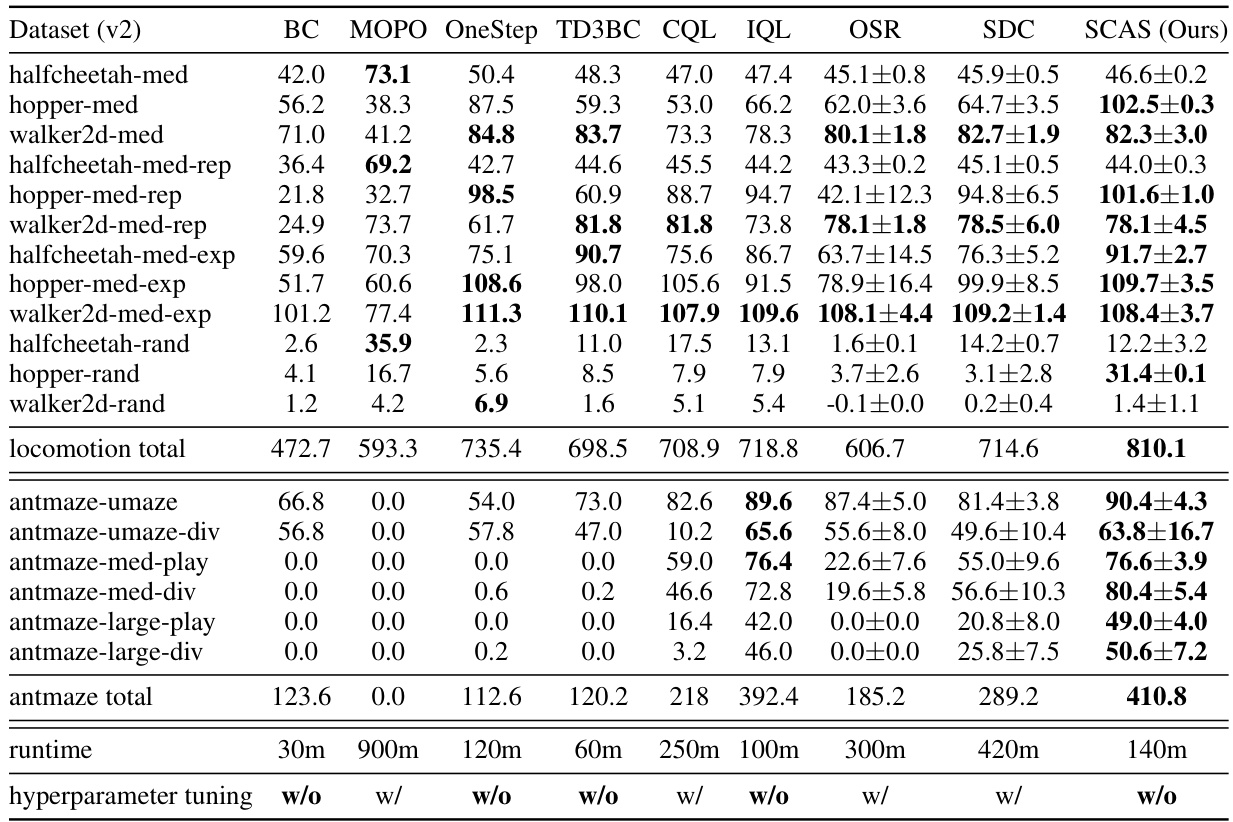
This table presents the average normalized scores achieved by different offline reinforcement learning algorithms across various locomotion and AntMaze tasks. The scores are normalized against random and expert policy returns, providing a standardized performance metric. Results are averaged over five random seeds for each algorithm and task combination, reflecting performance consistency and stability. The table also includes the runtime of each algorithm, along with an indication of whether hyperparameter tuning was employed, offering insights into computational efficiency and generalizability.
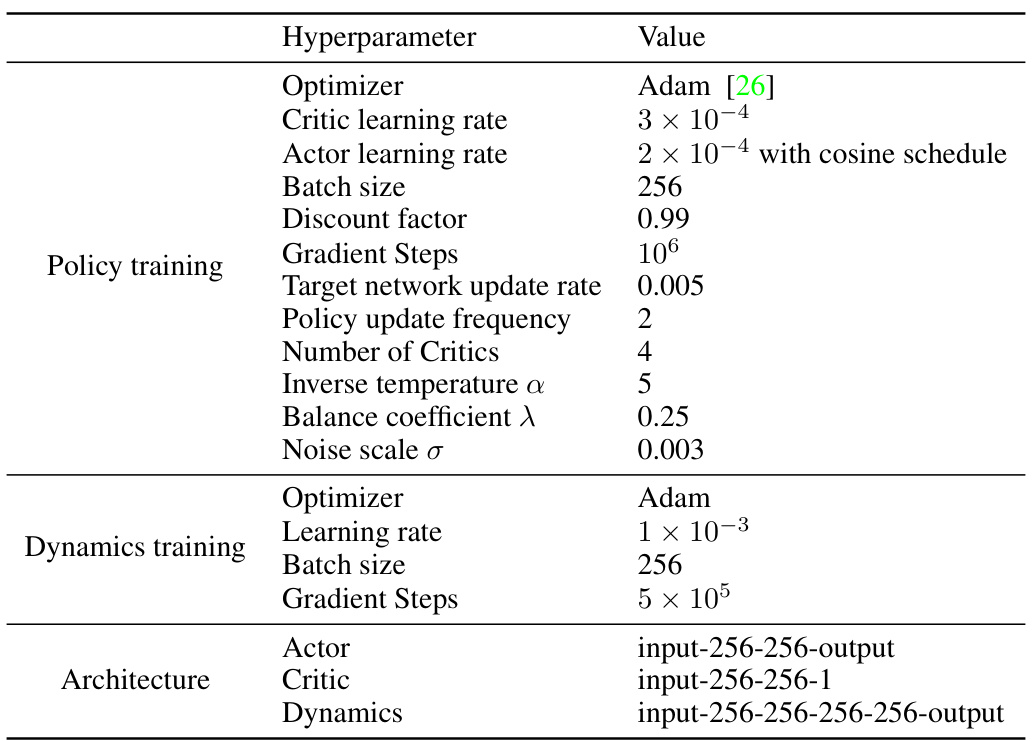
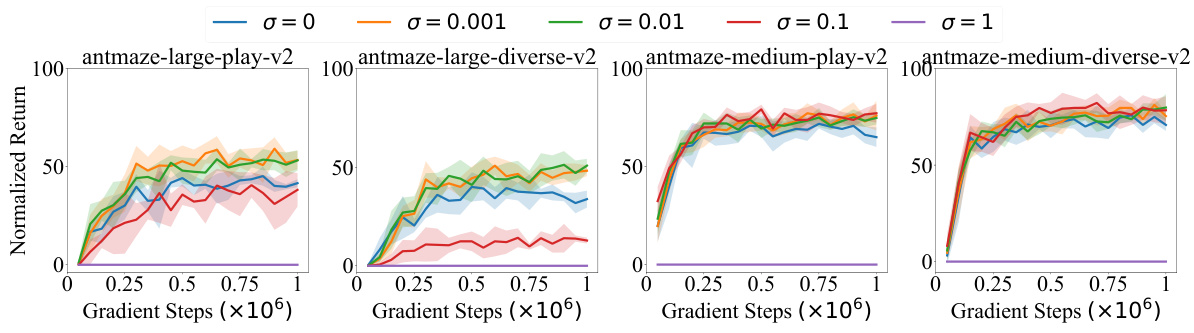
This table lists the hyperparameters used in the SCAS algorithm, categorized into policy training, dynamics training, and architecture. It specifies the optimizer, learning rates, batch size, discount factor, gradient steps, target network update rate, policy update frequency, number of critics, inverse temperature (alpha), balance coefficient (lambda), and noise scale (sigma). The architecture section details the input and output layers for the actor, critic, and dynamics networks.

This table presents a comparison of the performance of several offline reinforcement learning algorithms on a modified version of the maze2d-open-v0 environment. The modification involves removing transitions that contain states within a specific region, creating out-of-distribution (OOD) states during testing. The algorithms are evaluated based on two metrics: the average number of steps spent in OOD states during testing and the D4RL score, which is a normalized performance metric. The results show that SCAS significantly outperforms other algorithms in terms of both metrics, indicating better robustness to OOD states.
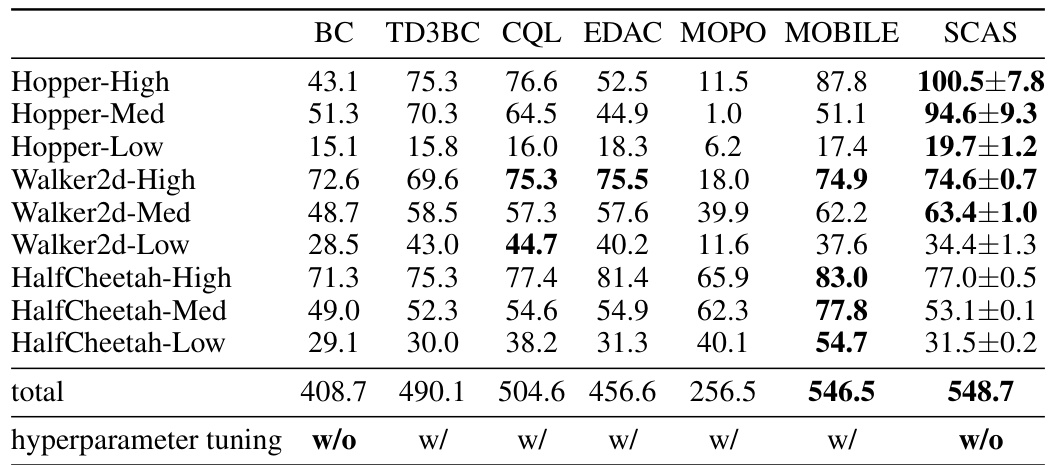
This table presents a comparison of the average normalized scores achieved by different offline reinforcement learning algorithms across various locomotion and AntMaze tasks from the D4RL benchmark. The scores are averaged over five separate runs with different random seeds to provide a measure of the algorithms’ robustness and performance consistency. The algorithms compared include several state-of-the-art methods, as well as SCAS (the method proposed in the paper). The table also indicates whether hyperparameter tuning was performed for each algorithm.

This table presents the average normalized scores achieved by different offline reinforcement learning algorithms across various locomotion and AntMaze tasks. The scores are normalized relative to random and expert policy returns, providing a standardized performance measure. Results are averaged over five random seeds to account for variability. The table offers a comprehensive comparison of the performance of several methods including SCAS (the proposed method), highlighting SCAS’s competitive performance compared to baselines on multiple benchmarks.
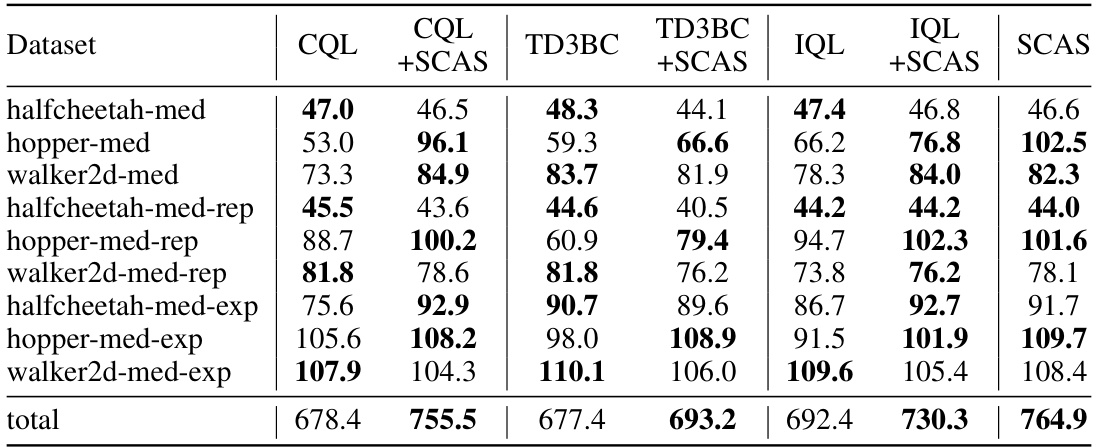
This table compares the performance of several offline reinforcement learning algorithms on the D4RL benchmark. It shows the average normalized scores achieved by CQL, TD3BC, and IQL, both with and without the SCAS regularizer. The results highlight the performance improvement achieved by adding the SCAS regularizer to these algorithms across different tasks in the D4RL benchmark.
Full paper#