↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Visual Table Understanding (VTU) is crucial for processing documents but faces challenges due to varied table structures and content. Previous methods often tackle individual tasks (like table detection and question answering) separately, leading to isolated models and complex workflows. This limits the overall understanding and hinders real-world applications.
TabPedia overcomes these issues by integrating all VTU tasks within a unified framework. It leverages a concept synergy mechanism that harmonizes table perception and comprehension tasks. The model’s effectiveness is validated through extensive experiments on public benchmarks and a new, comprehensive benchmark (ComTQA) created by the authors. This unified approach significantly improves performance and opens up new avenues for future research in VTU.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces TabPedia, a novel large vision-language model that significantly improves visual table understanding. It addresses the limitations of previous task-specific approaches by using a unified framework and concept synergy, leading to superior performance across various benchmarks. The open-sourced ComTQA benchmark further enhances the field by providing a more realistic and comprehensive evaluation dataset for future research. This work has strong implications for document processing, data extraction, and question-answering applications.
Visual Insights#

This figure compares the traditional task-specific approach for visual table understanding (VTU) with the proposed TabPedia method. The traditional approach uses separate pipelines for different VTU tasks such as table detection, structure recognition, querying, and question answering. This leads to modal isolation and complex workflows. In contrast, TabPedia integrates all these tasks into a unified framework using a large vision-language model (LLM) and a concept synergy mechanism. This allows for more efficient and seamless processing of visual tables.
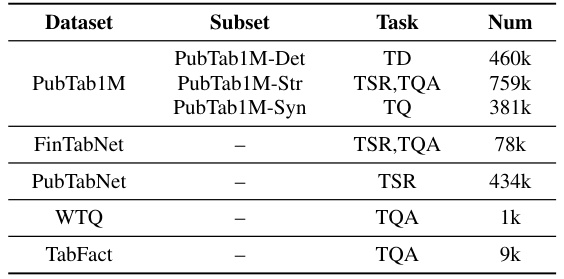
This table summarizes the datasets used in the fine-tuning stage of the TabPedia model training. It shows the dataset name, the subset used (if applicable), the tasks performed on that subset, and the number of samples in each subset. The datasets include PubTab1M (with subsets for detection, structure recognition/question answering, and querying), FinTabNet (structure recognition/question answering), PubTabNet (structure recognition), WikiTableQuestions (question answering), and TabFact (question answering).
In-depth insights#
Concept Synergy#
The concept of ‘Concept Synergy’ in this research paper appears to address the limitations of traditional task-specific approaches in visual table understanding (VTU). Instead of isolated modules for tasks like table detection, structure recognition, and question answering, a unified framework is proposed where these diverse tasks are treated as interconnected concepts. This synergy is achieved by representing all VTU tasks and their associated visual embeddings as concepts within a large vision-language model (LLM). The LLM then seamlessly integrates these concepts, enabling the model to leverage information across various tasks. This holistic approach contrasts with the modular pipelines found in prior work and potentially offers superior performance. The concept’s effectiveness is validated through experiments on benchmark datasets, implying that such an approach enhances understanding of visual tables. However, the specific mechanisms that facilitate this synergy (such as attention mechanisms or other interaction methods within the LLM) are not fully elucidated and may require further investigation. The key innovation of ‘Concept Synergy’ is its unified treatment of multiple VTU subtasks and the potential to surpass current state-of-the-art methods in accuracy and efficiency, even though implementation details might still require further explanation.
Unified Framework#
A unified framework in research often signifies a paradigm shift towards integrating previously disparate methodologies or data sources. This holistic approach aims to address limitations of task-specific models, which may struggle with generalization and efficiency. By integrating various components into a single framework, researchers can leverage synergies and achieve more comprehensive results. A key benefit is streamlined workflows, eliminating the complexities of integrating separate systems, potentially leading to more efficient and reproducible studies. However, designing a truly effective unified framework can be challenging. Careful consideration must be given to compatibility issues, data integration strategies, and the overall design architecture. The potential for increased complexity and computational costs also needs careful evaluation. Ultimately, the success of a unified framework hinges on its ability to not only improve efficiency and reproducibility but also to generate novel insights unattainable through individual, isolated approaches. Therefore, a thorough evaluation of its advantages and limitations is critical.
ComTQA Benchmark#
The ComTQA benchmark, a novel and comprehensive table VQA dataset, significantly advances the field of visual table understanding. Its creation directly addresses the limitations of existing VQA datasets by featuring approximately 9,000 QA pairs, addressing the scarcity of such data in real-world scenarios. The inclusion of diverse question types, encompassing multiple answers, mathematical calculations, and logical reasoning, pushes the boundaries of table comprehension capabilities. This complexity mirrors real-world challenges, where accurate understanding requires more than just simple factual recall. ComTQA’s open-sourced nature promotes collaborative research and facilitates the development of more robust and generalized visual table understanding models. By providing a more challenging evaluation benchmark, ComTQA accelerates progress towards achieving true, human-level comprehension of tabular information within complex documents.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, an ablation study on a visual table understanding model might involve progressively disabling features like the high-resolution encoder, low-resolution encoder, or the concept synergy mechanism. The goal is to isolate the impact of each component and quantify its effect on the overall performance. By comparing performance metrics (e.g., accuracy, F1-score) across different configurations, researchers can determine which components are most crucial for success and identify potential areas for improvement or further investigation. For example, a significant drop in performance after removing the high-resolution encoder might suggest the importance of fine-grained visual details. Conversely, minimal impact upon removing a component suggests that it is either redundant or less critical to the model’s functioning. Careful analysis of the ablation study results provides strong evidence supporting the model’s design choices and offers valuable insights for future model development and refinement. The results should be presented clearly, often using tables or graphs, to facilitate easy interpretation and comparison of the different configurations.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of TabPedia is crucial for handling larger datasets and more complex tables. This involves optimizing the model architecture and training processes, potentially exploring techniques like model quantization or pruning. Further investigation into multimodal synergy is warranted; how TabPedia can seamlessly integrate other modalities (audio, video) beyond images and text. Research on robustness and generalization is also key, especially in handling diverse table structures, noisy data, and cross-lingual scenarios. Developing advanced reasoning capabilities is critical for advanced tasks beyond basic question answering, requiring enhanced understanding of complex relationships and calculations within tables. Finally, exploring the application of TabPedia in various domains, like scientific literature analysis, financial reporting, and healthcare information extraction could greatly expand its impact. Addressing these challenges would help solidify TabPedia as a state-of-the-art visual table understanding solution.
More visual insights#
More on figures
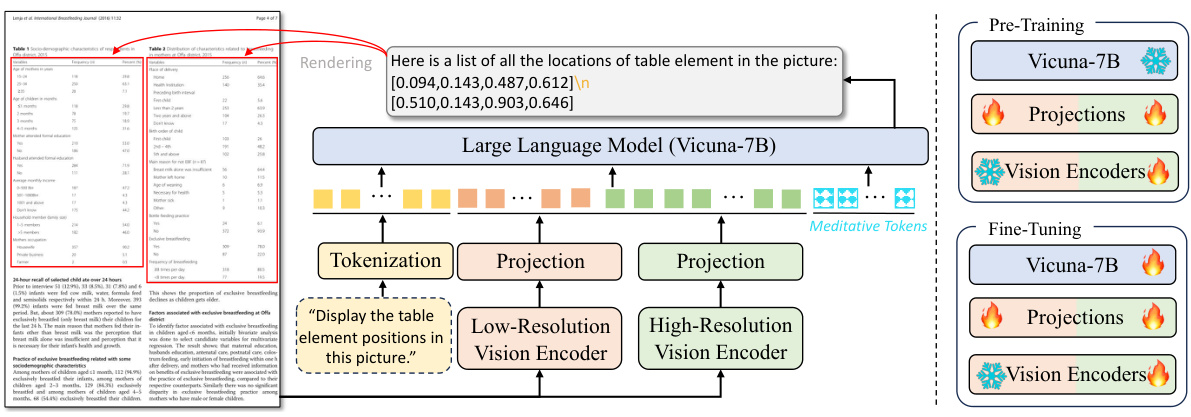
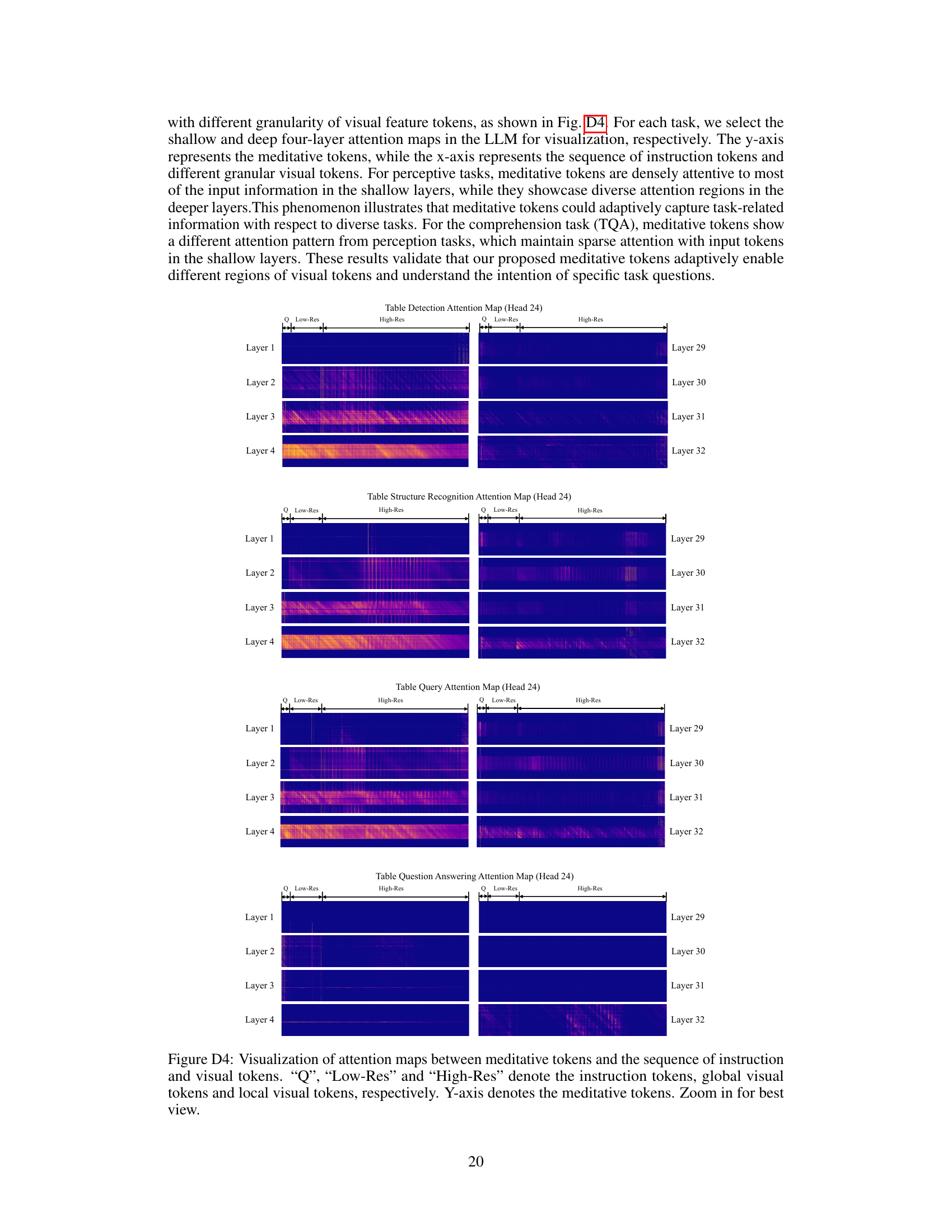
This figure illustrates the architecture of TabPedia, a novel large vision-language model for comprehensive visual table understanding. It shows how TabPedia processes an input image using dual vision encoders (high-resolution and low-resolution) to extract different levels of visual features. These features, along with instruction tokens, are fed into a large language model (LLM), which generates a response based on its understanding of the table content. The use of meditative tokens is highlighted, showing their role in harmonizing table perception and comprehension tasks.

The figure compares two approaches for visual table understanding: (a) previous task-specific pipelines and (b) the proposed TabPedia. The task-specific approach uses separate models for each subtask (table detection, structure recognition, querying, and question answering), leading to complex workflows. In contrast, TabPedia uses a unified framework leveraging large language models (LLMs) and a concept synergy mechanism to perform all tasks seamlessly by integrating various visual embeddings and task instructions, resulting in a more efficient and flexible approach.

This figure compares the task-specific pipelines used in previous visual table understanding methods with the proposed TabPedia model. The left side shows traditional approaches where different models are used for tasks like table detection, structure recognition, querying, and question answering. This results in isolated tasks and complex workflows. In contrast, TabPedia integrates all these tasks into a single, unified framework using a large language model (LLM), improving efficiency and performance.

This figure compares the traditional task-specific approach for visual table understanding with the proposed TabPedia approach. The traditional approach uses separate pipelines for different tasks (table detection, structure recognition, querying, and question answering), leading to modal isolation and complex workflows. In contrast, TabPedia uses a unified framework that leverages the power of large language models (LLMs) to seamlessly integrate these tasks, resulting in a more efficient and comprehensive approach to visual table understanding.
This figure illustrates the architecture of TabPedia, a novel large vision-language model for comprehensive visual table understanding. It shows how TabPedia uses dual vision encoders (high- and low-resolution) to extract visual features, which are then combined with instruction tokens and fed into a large language model (LLM). The LLM processes this information to generate a response.

This figure compares the traditional task-specific approach to visual table understanding with the proposed TabPedia model. The traditional approach uses separate pipelines for different tasks like table detection, structure recognition, querying, and question answering. In contrast, TabPedia integrates all these tasks into a unified framework using a large language model, improving efficiency and effectiveness.
This figure compares the traditional task-specific approach to visual table understanding with the proposed TabPedia model. The traditional approach involves separate pipelines for different tasks like table detection, structure recognition, querying, and question answering. In contrast, TabPedia integrates all these tasks into a unified framework by using a large vision-language model (LLM) and a concept synergy mechanism, enabling more efficient and comprehensive understanding.

This figure compares the traditional task-specific approach for visual table understanding with the proposed TabPedia approach. The traditional approach uses separate pipelines for different tasks like table detection, structure recognition, querying, and question answering. In contrast, TabPedia integrates all these tasks into a unified framework by using a large vision-language model (LLM). This allows TabPedia to leverage the LLM’s capabilities for a more comprehensive and efficient understanding of visual tables.
More on tables
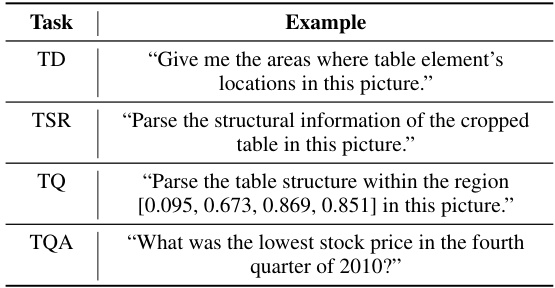
This table shows four different visual table understanding (VTU) tasks and provides an example instruction for each. The tasks are Table Detection (TD), Table Structure Recognition (TSR), Table Querying (TQ), and Table Question Answering (TQA). Each example shows how a user might instruct a model to perform that task. This demonstrates the diversity of tasks encompassed by VTU and highlights the variety of input/output modalities.
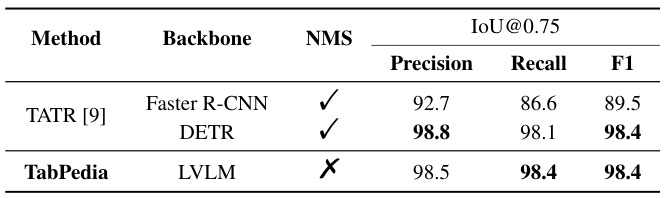
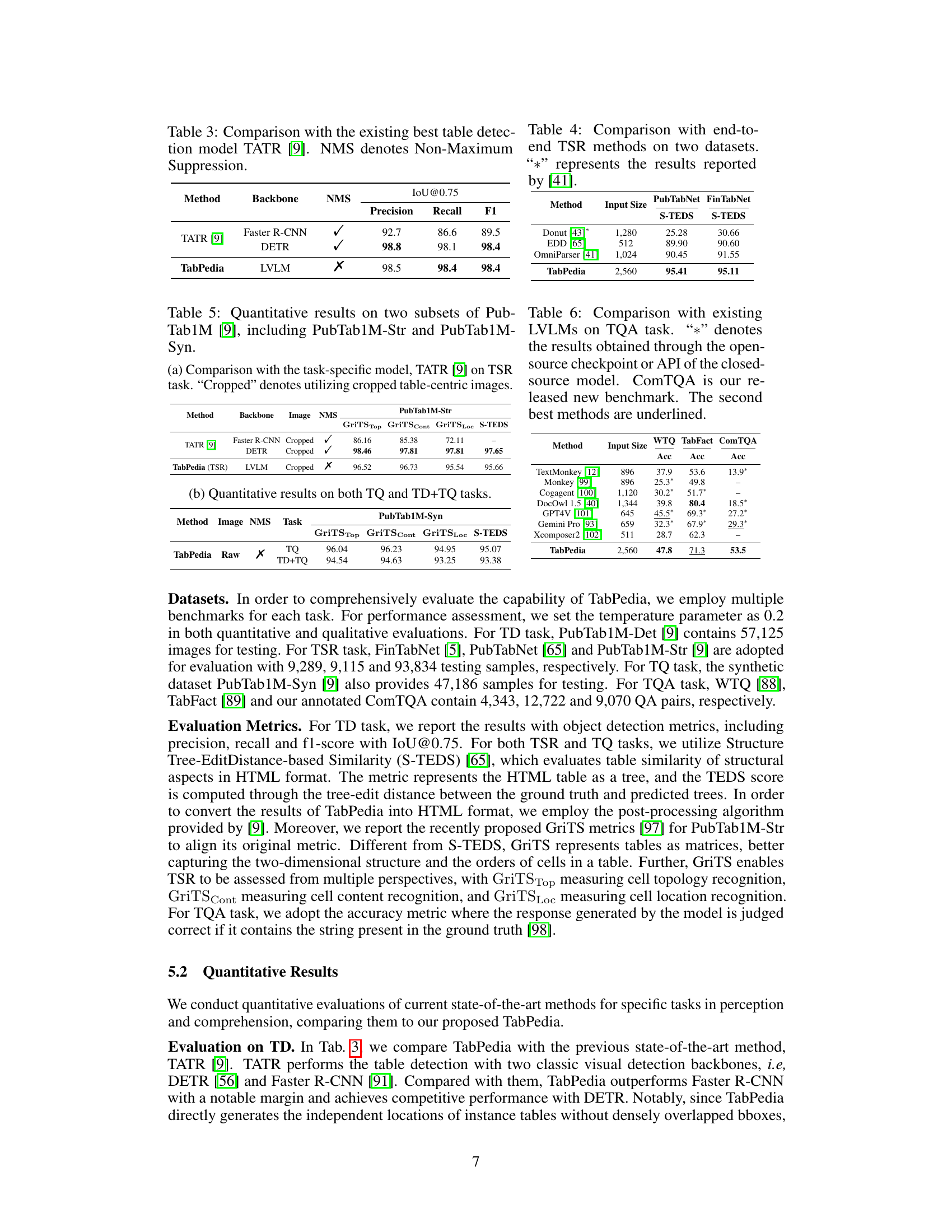
This table compares the performance of TabPedia with the state-of-the-art table detection model, TATR [9], on the task of table detection. It shows that TabPedia achieves comparable performance to TATR, especially when using the DETR backbone, but without using Non-Maximum Suppression (NMS), indicating a more efficient and potentially more robust approach.
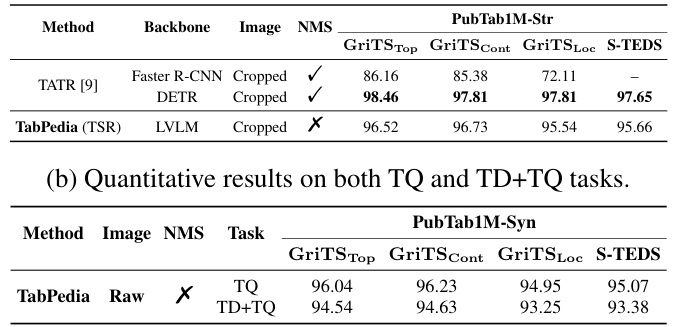
This table presents a quantitative comparison of the TabPedia model’s performance on two subsets of the PubTab1M dataset: PubTab1M-Str (table structure recognition) and PubTab1M-Syn (synthetic table querying). It compares TabPedia against the task-specific model TATR [9] for the table structure recognition task, showcasing TabPedia’s competitive performance despite being a general-purpose model for various visual table understanding (VTU) tasks. The table also includes results on both table querying (TQ) and the combined table detection and querying (TD+TQ) tasks, highlighting TabPedia’s ability to handle multiple tasks within a unified framework.
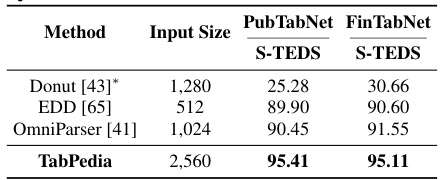
This table compares the performance of TabPedia with three other end-to-end table structure recognition (TSR) methods on two datasets: PubTabNet and FinTabNet. The metrics used are the S-TEDS scores (Structure Tree-EditDistance-based Similarity), which measure the similarity between the predicted and ground truth table structures. The input size refers to the resolution of the images used for processing. The results indicate TabPedia’s superior performance compared to the other methods.
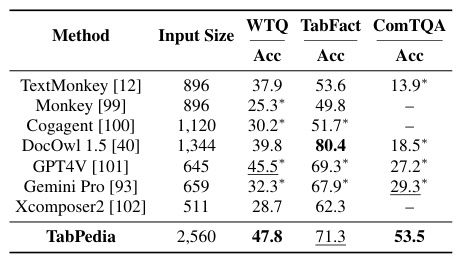
This table compares the performance of TabPedia against other Large Vision Language Models (LVLMs) on the Table Question Answering (TQA) task. It shows accuracy scores on three datasets: WTQ, TabFact, and the newly introduced ComTQA benchmark. ComTQA is highlighted as a more challenging, real-world benchmark.

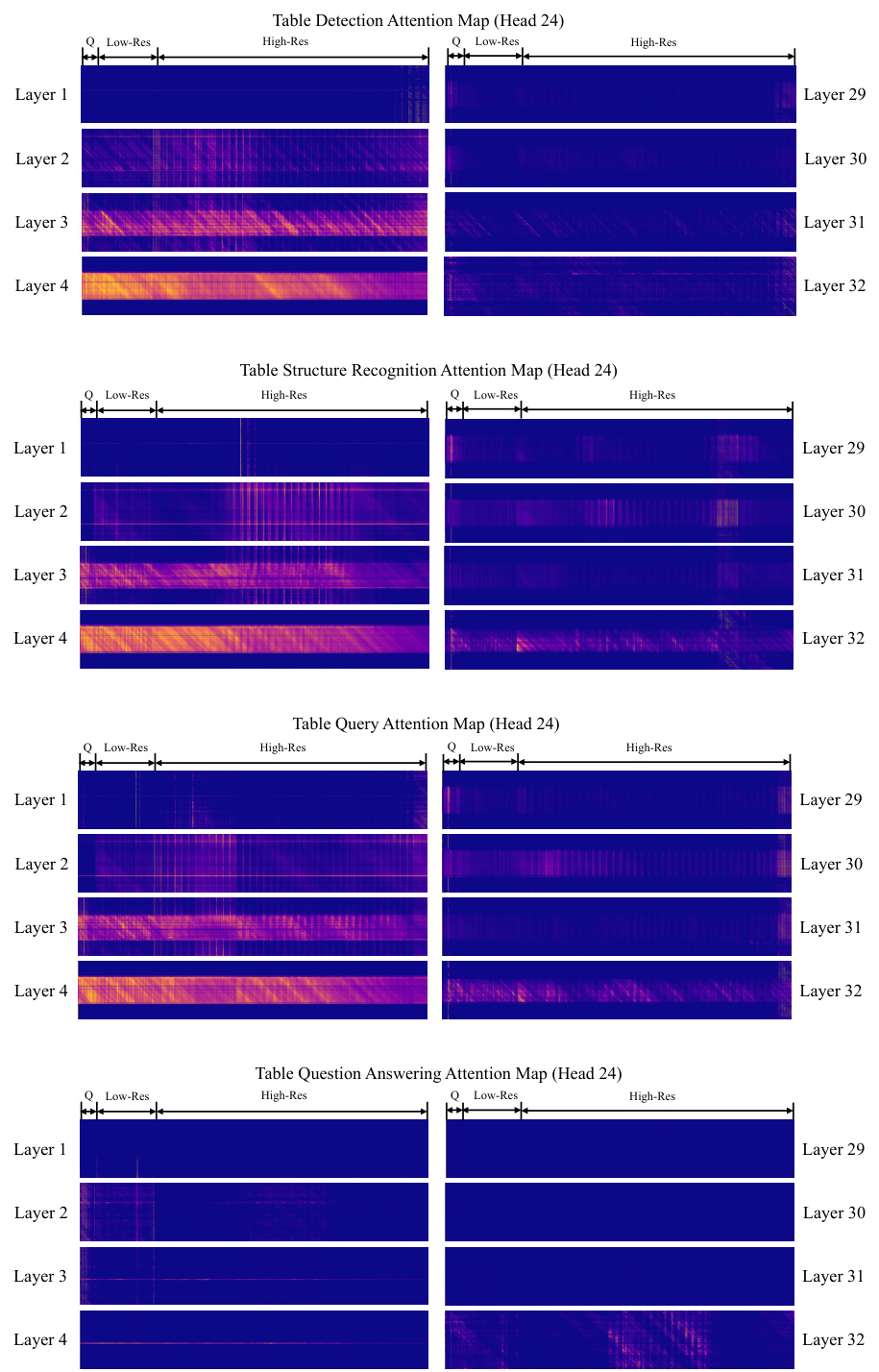
This table presents the averaged attention scores of different tokens (Meditative tokens, High-res visual tokens, Low-res visual tokens) across all layers and attention heads from the LLM, showing their contribution to the generation of satisfactory answers for different tasks (TD, TSR, TQ, TQA).
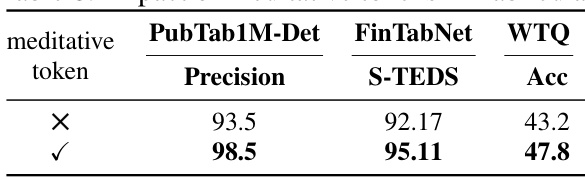
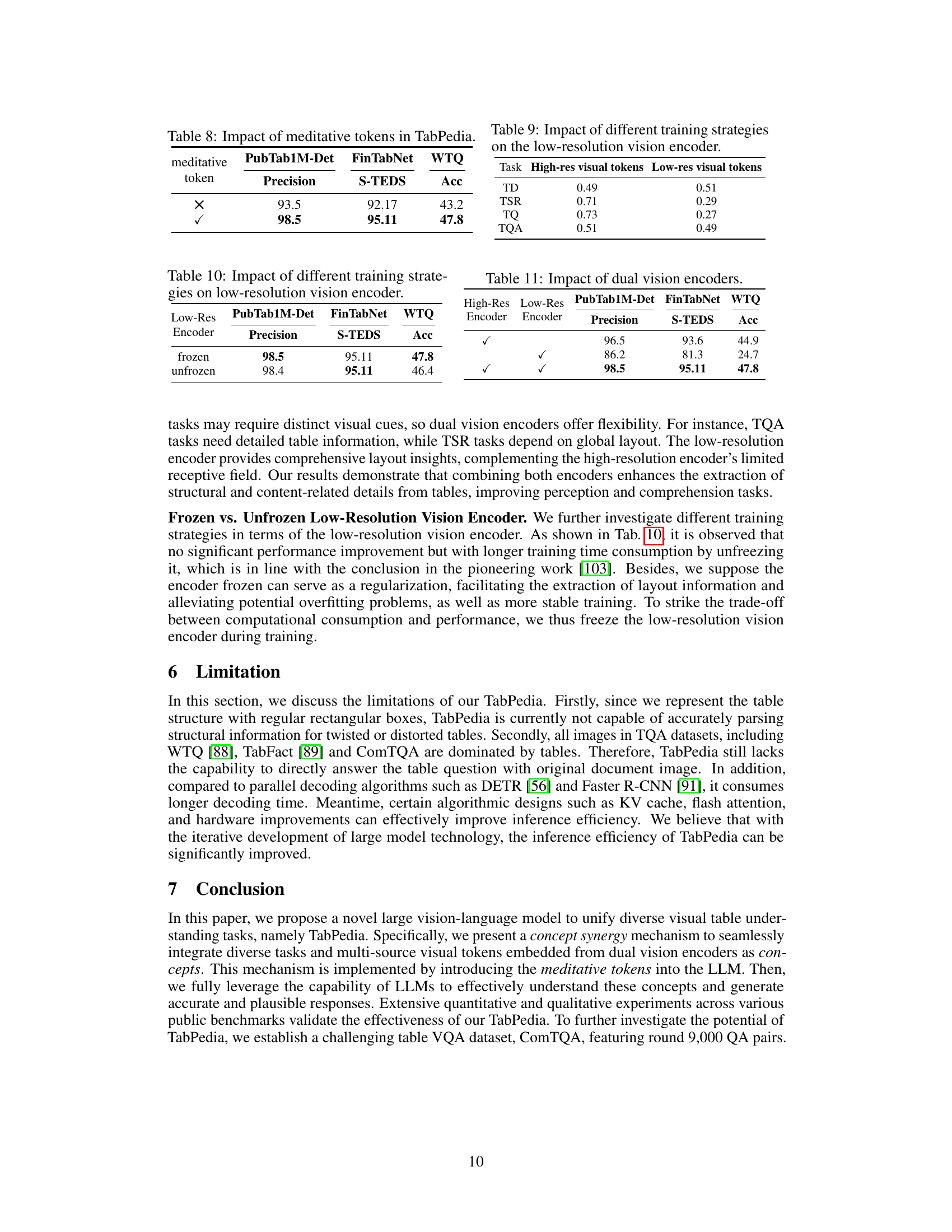
This table presents the impact of using meditative tokens in the TabPedia model. It compares the performance metrics (Precision for PubTab1M-Det, S-TEDS for FinTabNet, and Accuracy for WTQ) with and without the meditative tokens. The results show a significant improvement in performance when using meditative tokens.
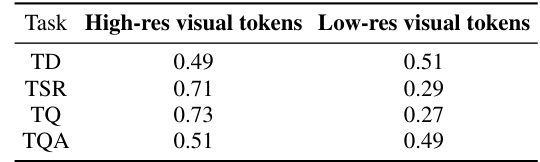
This table presents the averaged attention scores of the TabPedia-generated answers with respect to meditative tokens, high-resolution visual tokens, and low-resolution visual tokens across all the attention maps from the LLM for different tasks (TD, TSR, TQ, and TQA). The results demonstrate the importance of the meditative tokens in generating satisfactory answers and the varying contributions of high- and low-resolution visual information for different tasks.
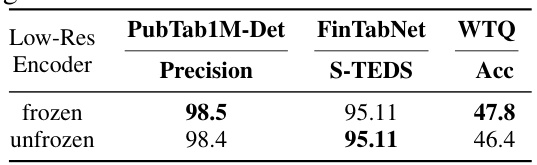
This table shows the impact of different training strategies (frozen vs. unfrozen) on the low-resolution vision encoder’s performance across three datasets (PubTab1M-Det, FinTabNet, WTQ) using different metrics (Precision, S-TEDS, Acc). The results indicate that freezing the encoder leads to comparable performance with slightly improved accuracy and reduced training time.

This table presents the results of experiments evaluating the impact of using both high-resolution and low-resolution vision encoders in the TabPedia model. The results are shown for three different tasks (PubTab1M-Det, FinTabNet, WTQ), each using a different metric (Precision, S-TEDS, and Accuracy, respectively). The table compares the model’s performance when only the high-resolution encoder is used, only the low-resolution encoder is used, and when both encoders are used together.

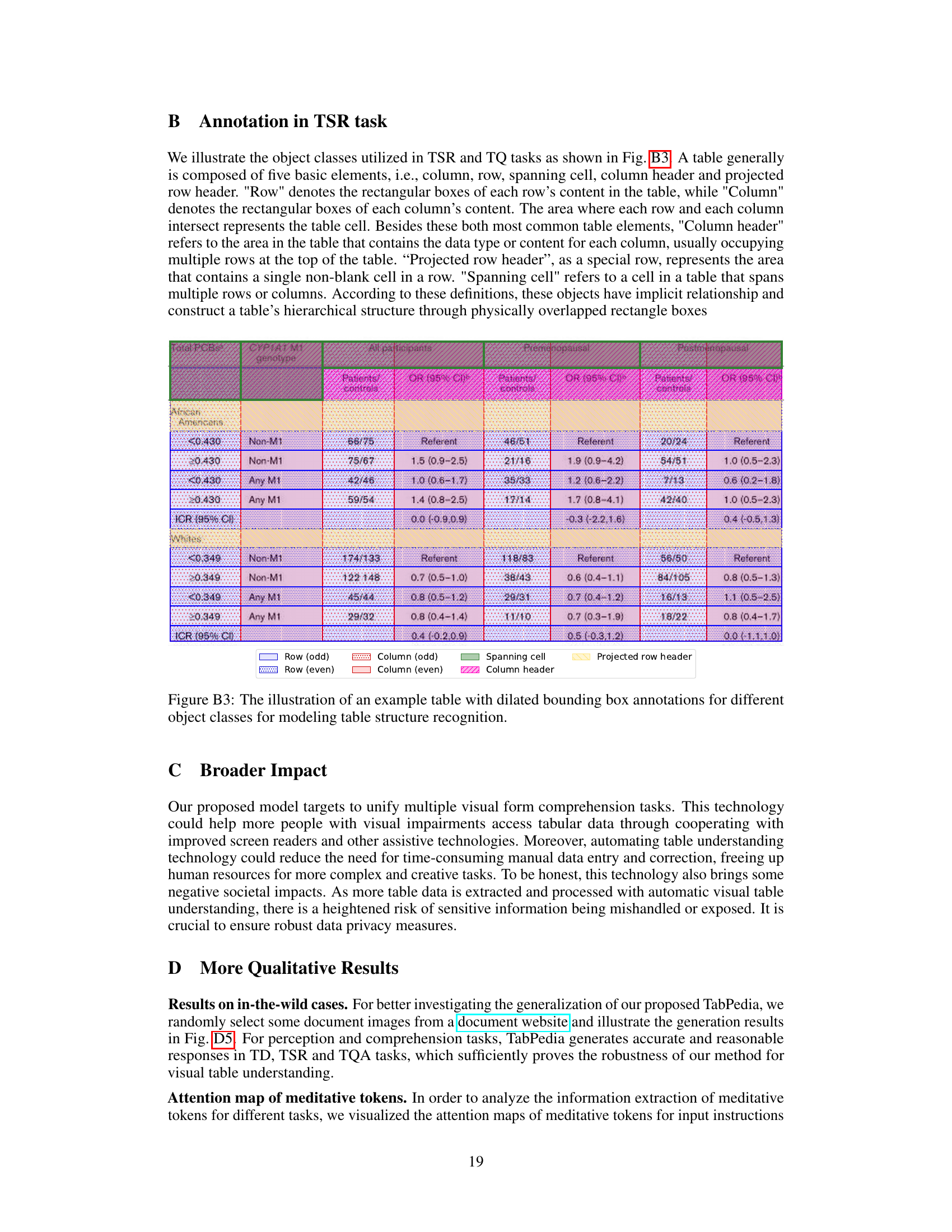
This table shows an example of how table structure is represented using dilated bounding boxes. Each box represents a different component of the table structure, such as rows, columns, column headers, projected row headers, and spanning cells. The visual representation helps in modeling the table’s structure for machine comprehension. This aids in tasks like Table Structure Recognition (TSR).

This table shows several examples of qualitative results comparing TabPedia’s responses with and without meditative tokens. It demonstrates how the inclusion of meditative tokens leads to more complete and accurate responses, particularly in longer-form answers and those requiring complex reasoning.
Full paper#