↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Recommender systems are susceptible to manipulation by strategic agents who might misrepresent their features to get recommended more often. This manipulation can significantly impact the system’s effectiveness and user experience. Existing algorithms often fail to account for such strategic behavior, leading to poor performance.
This research introduces the Optimistic Grim Trigger Mechanism (OptGTM), an algorithm designed to address this problem. OptGTM uses a combination of online learning and mechanism design techniques to discourage strategic manipulation while minimizing regret, that is, the difference between the system’s performance with and without manipulation. The paper demonstrates theoretically and through simulations that OptGTM outperforms traditional algorithms in scenarios with strategic agents.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges online learning and mechanism design, tackling a critical issue in recommender systems. By addressing strategic manipulation by agents, it improves fairness and system integrity. This opens doors for future research in incentive-aware algorithms and their application in various online platforms.
Visual Insights#

This figure compares the performance of the Optimistic Grim Trigger Mechanism (OptGTM) and the Linear Upper Confidence Bound (LinUCB) algorithm in a strategic linear contextual bandit setting. It shows how the strategic regret of both algorithms changes over 20 epochs, where strategic arms adapt their strategies to maximize their selection frequency. OptGTM maintains relatively consistent performance across epochs, while LinUCB’s performance degrades significantly as the arms learn to game the system. Subplots (b) and (c) provide a detailed view of the regret at the beginning (truthful arms) and end (strategic arms) of the experiment.
In-depth insights#
Strategic Bandits#
The concept of “Strategic Bandits” blends online learning with game theory, addressing scenarios where agents strategically interact with a learning algorithm. The core challenge is aligning the incentives of self-interested agents with the algorithm’s goal of minimizing regret. This necessitates moving beyond traditional bandit algorithms and incorporating mechanism design principles. A key insight is that incentive-aware algorithms are crucial to avoid linear regret, which can result from agents gaming the system. The design of such algorithms involves a trade-off between incentivizing truthful behavior and minimizing the algorithm’s regret. Optimistic mechanisms that utilize confidence sets and penalize untruthful behavior offer a promising approach. The strategic setting introduces significant complexity compared to traditional bandit problems, emphasizing the interplay between online learning and game-theoretic considerations.
Mechanism Design#
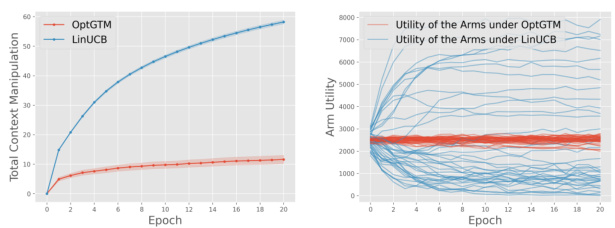
Mechanism design, in the context of the research paper, is crucial for aligning the incentives of strategic agents (arms) with the overall goal of minimizing regret for the learner. The paper highlights that a naive approach to online learning, ignoring the strategic nature of agents, results in linear regret. This underscores the necessity of incorporating mechanism design principles. Incentive-compatible mechanisms, such as the Optimistic Grim Trigger Mechanism (OptGTM) proposed in this work, aim to encourage truthful behavior from agents, preventing them from manipulating the system for their benefit. The paper demonstrates a trade-off between mechanism design and regret minimization, suggesting that perfect incentive compatibility may conflict with optimal regret bounds in certain contexts. The efficacy of OptGTM is demonstrated both theoretically through the analysis of Nash Equilibria and experimentally through simulations of strategic agent behavior.
Incentive Aware#
The concept of “Incentive Aware” in the context of a research paper likely revolves around designing systems or algorithms that explicitly consider and react to the incentives of different agents involved. This is crucial in scenarios where agents can strategically manipulate the system to maximize their own gains, potentially at the expense of the overall system’s performance or objectives. A key aspect is the alignment of incentives, where the system tries to guide the behavior of agents toward a desired outcome by structuring incentives that reward cooperative or beneficial behaviors. Mechanism design principles often play a significant role, focusing on creating rules and structures that incentivize truthful reporting or desirable actions. The analysis of such systems likely includes the study of game-theoretic equilibria, such as Nash Equilibrium, to understand how rational agents will behave within the designed incentive structure. A critical evaluation of the trade-offs between incentive alignment and other goals, such as efficiency or fairness, would be another essential component of an “Incentive Aware” analysis. Robustness to various forms of strategic manipulation attempts is another factor to consider.
Regret Minimization#
Regret minimization is a central theme in online learning, particularly within the context of multi-armed bandits and contextual bandits. The core idea is to design algorithms that minimize the cumulative difference between rewards obtained and the rewards that could have been obtained by selecting the optimal arm in hindsight. This involves a delicate balance between exploration (trying out different arms to learn their rewards) and exploitation (choosing the arm believed to yield the highest reward based on current knowledge). The paper delves into this exploration-exploitation dilemma, complicating it with the introduction of strategic agents, i.e., arms that can manipulate their contexts to increase their probability of being selected. This introduces the crucial concept of incentive alignment; the algorithm must discourage agents from gaming the system while simultaneously minimizing regret. The exploration-exploitation trade-off becomes interwoven with the need for mechanisms to ensure truthful reporting from self-interested arms. The paper’s contribution lies in proposing and analyzing mechanisms that address this complex interplay, showing theoretically that failure to account for strategic behavior leads to linear regret, while the proposed methods achieve sublinear regret under various equilibria.
Empirical Results#
An Empirical Results section in a research paper would typically present the findings from experiments designed to test the paper’s hypotheses or claims. A strong section would start with a clear overview of the experimental setup, including the data used, the metrics employed, and the experimental design. Data characteristics, such as size, distribution, and any preprocessing steps are vital. The presentation of results should be concise and focused, employing tables, figures, and concise textual descriptions to highlight key observations. Statistical significance should be clearly indicated using techniques appropriate to the data (e.g., p-values, confidence intervals) and the chosen experimental design. Furthermore, a discussion comparing observed results with the expected outcomes based on the proposed theory is crucial. This requires a nuanced interpretation of both statistical significance and practical relevance. Finally, limitations and potential confounding factors should be acknowledged, maintaining transparency and rigorous scientific practice. A high-quality Empirical Results section, therefore, isn’t just about presenting numbers; it’s about providing a compelling narrative that links the methodology, the data, and the interpretation to deliver convincing support for the paper’s claims.
More visual insights#
More on figures

This figure compares the strategic regret of two algorithms, OptGTM and LinUCB, across 20 epochs. The arms strategically adapt their strategies over time. The figure shows that OptGTM’s regret remains relatively consistent, while LinUCB’s regret increases substantially as the arms adapt, approaching that of a uniformly random selection strategy. Subfigures 1b and 1c zoom in on the regret at the beginning (truthful arms) and end (adapted arms) of the experiment to highlight the performance difference.
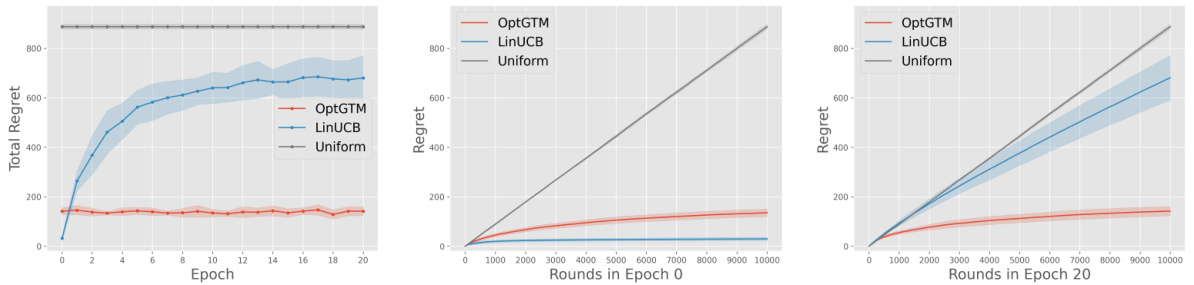
This figure compares the performance of the Optimistic Grim Trigger Mechanism (OptGTM) and LinUCB algorithms in a strategic linear contextual bandit setting. It shows that OptGTM maintains relatively consistent regret over 20 epochs, while LinUCB’s regret significantly increases as strategic arms adapt their strategies to exploit LinUCB’s weaknesses. The figure is broken into three subplots: one showing overall regret across epochs, and two focusing on epoch 0 (where the arms are truthful) and epoch 20 (after the arms have fully adapted).
This figure compares the strategic regret of two algorithms, OptGTM and LinUCB, across 20 epochs where strategic arms adapt their strategies. The left panel (1a) shows the overall regret; OptGTM’s regret remains relatively stable, while LinUCB’s regret increases significantly as the arms adapt. The right two panels (1b and 1c) provide detailed regret comparisons for epoch 0 (truthful arms) and epoch 20 (strategic arms), respectively, illustrating the performance difference more clearly.
Full paper#



















