↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current 3D reconstruction models struggle with multi-view inconsistencies and blurred textures due to computationally expensive architectures. These methods also often compromise multi-view information to manage costs. Existing feed-forward Gaussian reconstruction models typically adopt powerful yet computationally intensive architectures to generate long sequences of Gaussians for intricate 3D modeling, compromising the integrity of multi-view information propagation to manage computational costs.
The researchers introduce MVGamba, a lightweight Gaussian reconstruction model featuring a multi-view Gaussian reconstructor based on the RNN-like State Space Model (SSM). This approach efficiently maintains multi-view information integrity and enables cross-view self-refinement. MVGamba achieves state-of-the-art performance across various 3D generation tasks (image-to-3D, text-to-3D, and sparse-view reconstruction), exhibiting approximately 10 times smaller model size compared to baselines.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D content generation because it introduces MVGamba, a novel, efficient, and high-quality model that significantly advances the state-of-the-art. Its unified framework handles various input types (single image, sparse views, text), offering a versatile solution for diverse applications. The linear complexity and cross-view self-refinement strategies are particularly valuable, and the open-sourced code promotes further research and development.
Visual Insights#
This figure shows the overall architecture of MVGamba, a unified 3D content generation framework. It highlights the framework’s ability to generate high-quality 3D models from various input types: single images, multiple views (sparse-view reconstruction), and text prompts. The core of the framework is built upon Gaussian splatting, which allows for fast and efficient 3D model generation.
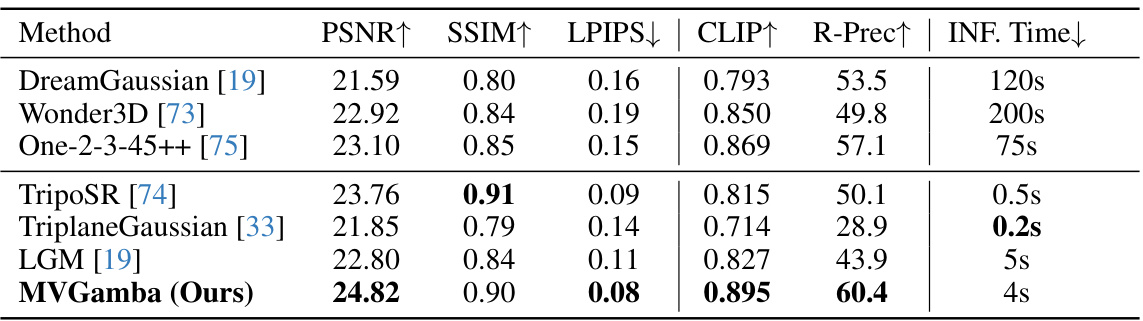
This table presents a quantitative comparison of MVGamba against several state-of-the-art 3D generation methods across various metrics. The metrics used to evaluate the methods include PSNR (peak signal-to-noise ratio), SSIM (structural similarity index), LPIPS (learned perceptual image patch similarity), CLIP (Contrastive Language–Image Pre-training) score, R-Prec (Recall@Precision) and inference time. Higher values for PSNR, SSIM, CLIP, and R-Prec indicate better performance, while lower values for LPIPS and inference time are preferred. The table shows that MVGamba outperforms most other methods across all metrics, particularly in terms of PSNR, SSIM, and CLIP.
In-depth insights#
MVGamba Overview#
MVGamba presents a novel approach to 3D content generation, unifying various tasks such as image-to-3D, text-to-3D, and sparse-view reconstruction. Its core innovation lies in the multi-view Gaussian reconstructor, which leverages an RNN-like State Space Model (SSM) for efficient and coherent processing of multi-view information. This SSM architecture, unlike traditional transformer-based methods, maintains the integrity of multi-view data throughout the generation process, resulting in high-quality outputs with reduced artifacts. Causal context propagation within the SSM ensures that later predictions benefit from earlier ones, leading to a self-refinement process that enhances the overall quality. Furthermore, MVGamba’s design incorporates efficient components such as a lightweight Gaussian decoder and linear complexity Mamba blocks, leading to both high quality and speed. The unified pipeline simplifies the workflow, integrating readily available multi-view diffusion models to create the input for the reconstructor. The model demonstrates improved performance and efficiency compared to existing state-of-the-art approaches, showcasing its potential as a versatile solution for various 3D content generation tasks.
SSM-based Recon.#
The heading ‘SSM-based Recon.’ strongly suggests a novel approach to reconstruction leveraging State Space Models (SSMs). This likely involves representing the reconstruction process as a sequence of states, each updated through a recurrent mechanism. The SSM framework offers potential advantages in handling long sequences and temporal dependencies inherent in many reconstruction tasks, unlike traditional methods that might struggle with long-range context. This approach likely models the generation of the reconstruction as a series of probabilistic updates, enabling efficient and potentially more accurate results by exploiting the inherent structure and temporal relationships within the data. The use of SSMs is particularly relevant when the data possesses temporal or sequential properties, such as in video reconstruction or time-series analysis. By casting reconstruction as a state-space problem, the authors likely achieve better performance by modeling the evolution of states, thus incorporating context from previous states in the current state estimation. A core aspect would be the design of the state transition function and the observation model within the SSM, crucial elements that determine the model’s ability to accurately capture the dynamics of the data. The effectiveness of this methodology hinges on the appropriate choice of SSM architecture and parameterization, and the quality of the initial state estimate. The results presented should demonstrate substantial improvements over existing methods, highlighting the unique advantages conferred by the SSM-based reconstruction framework. Further insights would be gained by examining the specific SSM used (e.g., linear vs. non-linear, type of recurrence), the dimensionality of the state space, and the methods for learning SSM parameters.
Multi-view Handling#
The effectiveness of any 3D reconstruction or generation model heavily relies on its ability to effectively handle multi-view data. A robust multi-view handling strategy is crucial for achieving high-fidelity and consistent 3D representations. The core challenge lies in fusing information from multiple viewpoints, which may contain inconsistencies due to variations in imaging conditions, camera poses, or even noise. Different approaches exist, ranging from simple concatenation or averaging of features extracted from each view to more sophisticated methods using attention mechanisms or recurrent neural networks. Effective strategies must address view alignment and registration problems, handle occlusions, and resolve conflicts between differing views. A successful multi-view strategy should not only achieve high accuracy but also maintain computational efficiency. The choice of a specific strategy is heavily dependent on the overall system architecture, the complexity of the target scene, and the computational constraints. The use of state-of-the-art techniques such as transformer networks or recurrent neural networks can significantly improve the quality of multi-view fusion, but they often come at a higher computational cost. Careful consideration is needed to strike a balance between accuracy and efficiency.
Ablation Studies#
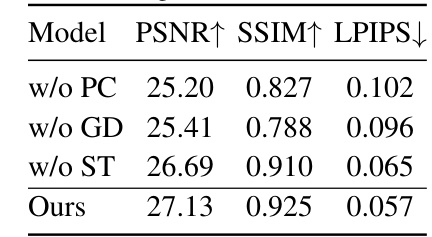
Ablation studies systematically remove or alter components of a model to assess their individual contributions. In this context, such studies would likely involve removing or modifying elements of the Multi-View Gaussian Mamba (MVGamba) architecture to isolate the effects of specific design choices. This might include removing the RNN-like State Space Model (SSM), evaluating different image tokenizers, altering the Gaussian decoder structure, or modifying the multi-view information integration strategy. By comparing the performance of the model with and without these components, the researchers can quantify the impact of each part on the overall accuracy and efficiency of 3D content generation. Key insights from these studies would reveal which components are essential to MVGamba’s success, those that are redundant, and areas where the model can be simplified without significantly sacrificing performance. This would inform future model improvements and possibly lead to more lightweight or computationally efficient versions. A particularly insightful aspect would involve examining the interaction between the multi-view components. Do all views contribute equally? Does a reduction in the number of views severely impact performance? Answering these questions is key to understanding MVGamba’s capabilities and limitations in various scenarios like single-image, sparse-view, or text-based 3D generation.
Future Work#
Future research directions stemming from this work could focus on several key areas. Improving the robustness of the model to noisy or inconsistent multi-view inputs is crucial, perhaps through exploring more sophisticated data augmentation techniques or developing more robust multi-view feature fusion methods. Addressing the limitations related to the depth estimation of front-view inputs, as noted in the paper, is also important. This might involve investigating alternative input ordering strategies or incorporating explicit depth cues into the model architecture. Another promising direction is exploring different 3D representations beyond Gaussian splatting, potentially enhancing visual quality and detail. Investigating the integration with more advanced multi-view diffusion models is also needed to leverage improvements in the quality and consistency of generated multi-view images. Finally, extending the application to more complex and dynamic 3D scenes, such as those involving articulated objects or temporal consistency, would significantly expand the applicability and usefulness of this approach.
More visual insights#
More on figures

The figure illustrates the limitations of previous Gaussian reconstruction models and introduces the efficiency of Mamba. In (a), the comparison shows that prior models compromised multi-view information integrity for computational efficiency, leading to inconsistent and blurry results. In contrast, (b) demonstrates that Mamba achieves linear complexity, significantly reducing computational costs compared to the quadratic complexity of Transformers.
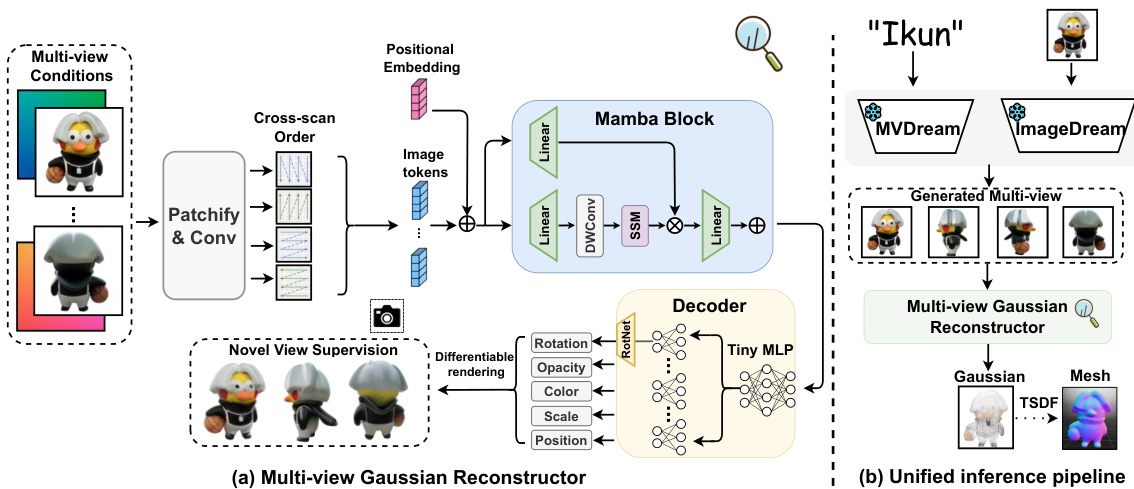
This figure illustrates the architecture of the MVGamba model. (a) shows the multi-view Gaussian reconstructor, which takes multi-view images as input, processes them using a causal sequence modeling approach based on Mamba blocks, and predicts the parameters of 3D Gaussians. Novel view supervision and differentiable rendering are used during training. (b) shows the unified inference pipeline, which combines multi-view diffusion models (MVDream and ImageDream) with the multi-view Gaussian reconstructor to generate 3D content from single images or text prompts. The output is then converted into a mesh via TSDF.

This figure shows a qualitative comparison of the 3D model generation results of four different methods: DreamGaussian, Triplane-Gaussian, LGM, and MVGamba. Each row represents a different input (either a single image or a text prompt). The figure demonstrates that MVGamba produces 3D models with higher visual fidelity and better overall quality than the other methods. The Appendix C contains additional results.

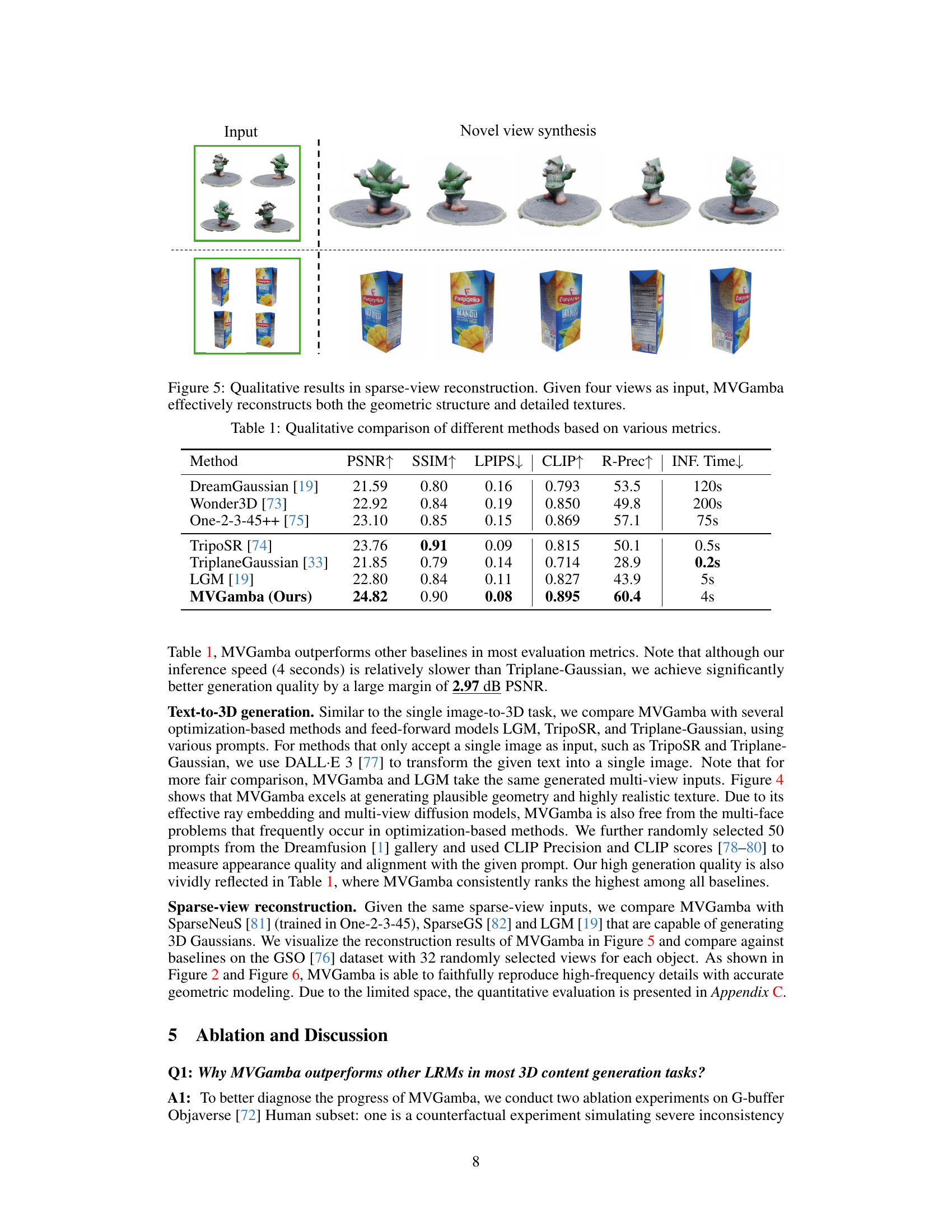
This figure shows the results of sparse-view reconstruction using MVGamba. The top row displays four input views of a garden gnome. The bottom row shows four input views of a mango juice box. In each case, MVGamba successfully reconstructs the 3D model from the limited input views, generating novel views that accurately represent the object’s geometry and texture. This demonstrates the model’s ability to reconstruct detailed 3D models from a sparse set of input views, showcasing its effectiveness in handling incomplete visual information.

This figure compares the image-to-3D and text-to-3D generation results of MVGamba against several other state-of-the-art methods. Different input prompts (single image or text) and the corresponding 3D model outputs are shown for each method. This allows a visual comparison of the quality and fidelity of the 3D models generated by each approach. More detailed results can be found in Appendix C of the paper.
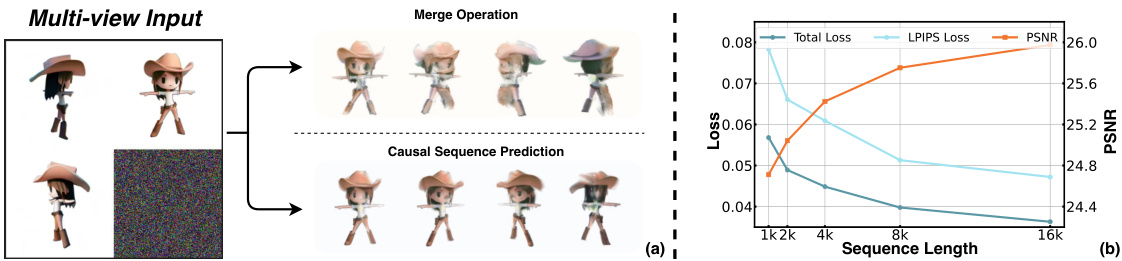
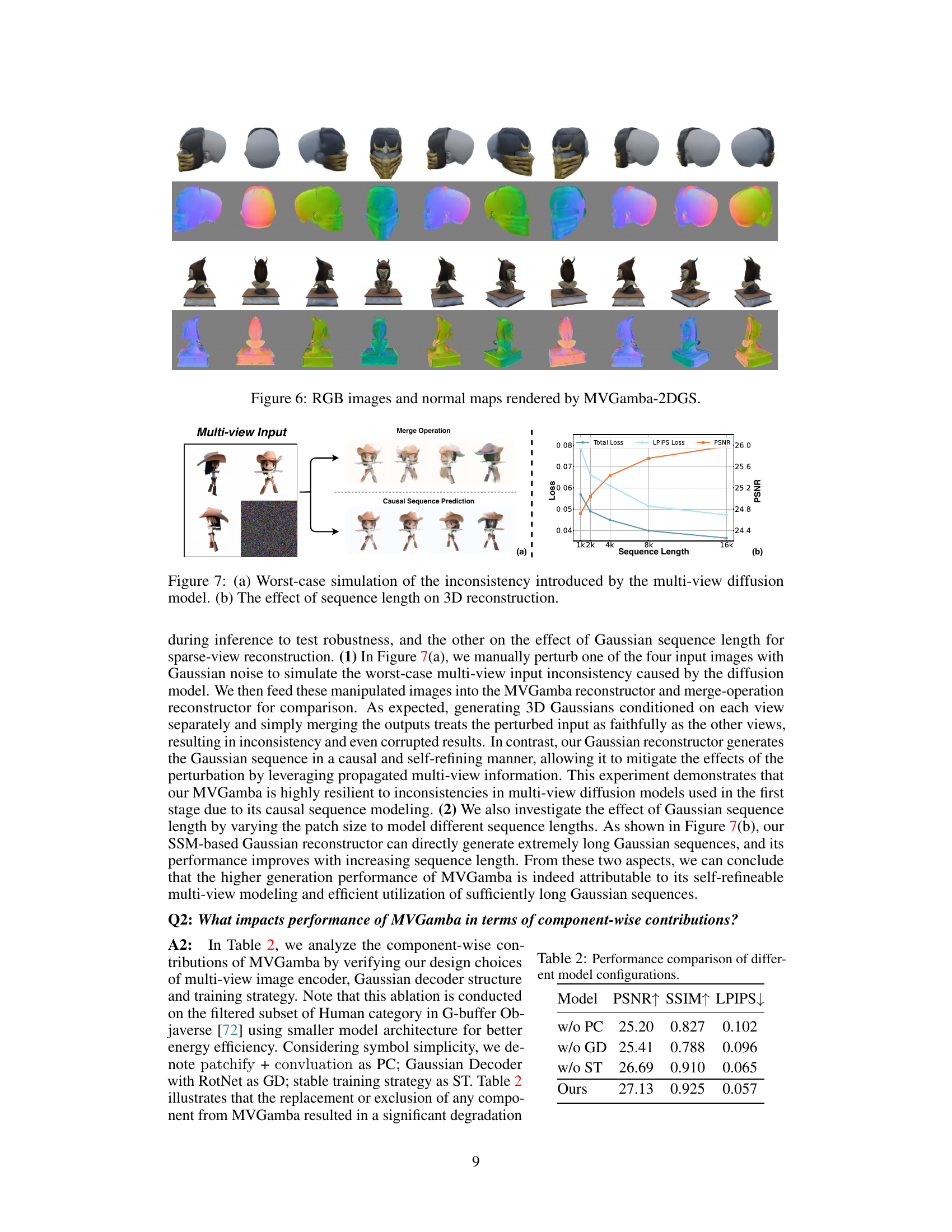
The figure shows two experiments conducted to diagnose the progress of MVGamba. (a) shows a worst-case simulation to test the robustness of MVGamba to multi-view input inconsistency. It compares the results of MVGamba’s causal sequence prediction with a merge operation method, demonstrating that the causal model is more robust to noise. (b) illustrates the effect of varying the length of the Gaussian sequence on 3D reconstruction performance. It shows that the model’s performance improves with increasing sequence length. These findings support the claims made in the paper about MVGamba’s effectiveness.

This figure shows an ablation study on the input order for MVGamba. The top row demonstrates that if the depth of the front view is incorrectly estimated and the front view is input first, the model may fail to generate satisfactory 3D content. The bottom row shows that changing the input order to prioritize the side view (which contains sufficient depth information) enables MVGamba to generate satisfactory 3D content. This highlights the importance of input order and depth estimation accuracy for optimal performance.

This figure displays a qualitative comparison of the image-to-3D and text-to-3D generation capabilities of MVGamba against several state-of-the-art baselines. Each row represents a different input (an image or a text prompt), and the columns show the results of different methods. The results demonstrate that MVGamba produces higher-quality results, especially in terms of detail and consistency across different viewpoints. Appendix C contains further results.

This figure shows a qualitative comparison of the 3D models generated by MVGamba and several other state-of-the-art methods, including DreamGaussian, Triplane-Gaussian, and LGM. For each method, the figure shows several examples of 3D models generated from either a single image or text prompt. The figure demonstrates that MVGamba is able to generate high-quality 3D models that are comparable in quality to the other methods, and in some cases, even superior in quality. The figure also shows the variety of different 3D models that MVGamba can generate, demonstrating the versatility of the approach.

This figure presents a qualitative comparison of the 3D models generated by MVGamba and other state-of-the-art methods. The comparison is done for both image-to-3D and text-to-3D generation tasks, showing the results for various inputs such as single images and text prompts. The figure showcases the visual differences in the quality and details of the generated 3D models, allowing for a visual assessment of the performance of MVGamba compared to its counterparts.

This figure presents a qualitative comparison of 3D model generation results from different methods (DreamGaussian, Triplane-Gaussian, LGM, and MVGamba). It showcases the visual quality of generated 3D models from both single images and text prompts. The figure highlights that MVGamba achieves better results compared to other methods in terms of generating high fidelity and detailed 3D content from different input types. More detailed results can be found in Appendix C.

This figure shows the architecture of the MVGamba model. (a) illustrates the multi-view Gaussian reconstructor which takes multi-view images as input, processes them through a causal sequence modeling approach, and predicts Gaussians for novel views. (b) shows the unified inference pipeline where multi-view diffusion models are used to generate initial multi-view images which are fed to the multi-view Gaussian reconstructor to produce final high-quality 3D content in a short timeframe.
More on tables
This table presents a quantitative comparison of MVGamba against several state-of-the-art 3D generation methods across different metrics, including PSNR, SSIM, LPIPS, CLIP, R-Prec, and Inference Time. The metrics evaluate the quality of the generated 3D models in terms of image fidelity, visual similarity, and geometric accuracy. It demonstrates MVGamba’s superior performance compared to other methods, particularly in terms of generation quality, despite having a significantly smaller model size.

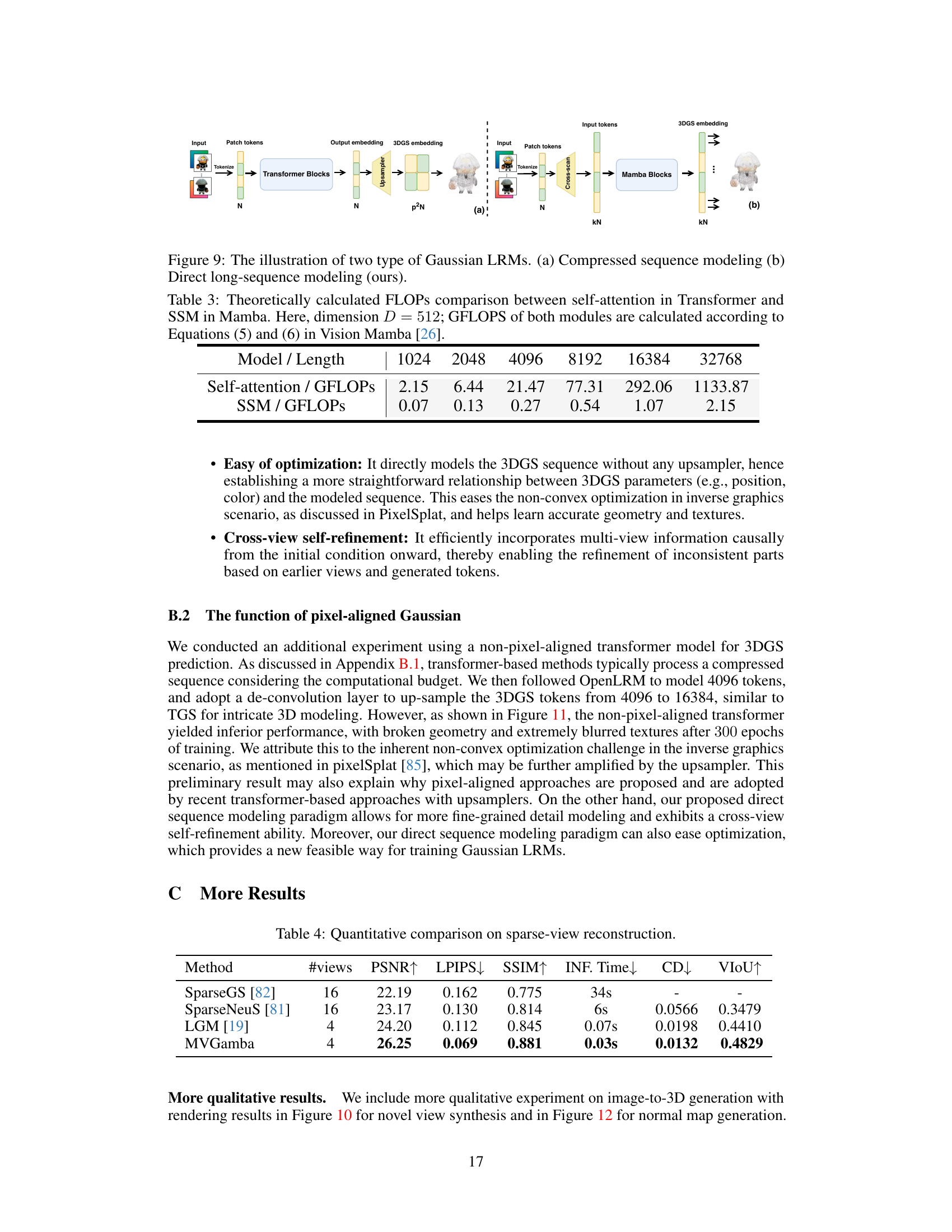
This table compares the computational cost (GFLOPs) of self-attention in Transformer networks and SSM (State Space Model) in Mamba networks for various sequence lengths (1024, 2048, 4096, 8192, 16384, and 32768). It demonstrates the linear complexity of Mamba compared to the quadratic complexity of Transformer self-attention, highlighting Mamba’s computational efficiency for long sequences.

This table presents a quantitative comparison of MVGamba against several state-of-the-art methods for single image-to-3D generation. The metrics used for comparison include PSNR, SSIM, LPIPS, CLIP score, R-Precision, and inference time. Higher PSNR and SSIM values, along with a lower LPIPS score, indicate better visual quality. A higher CLIP score represents better alignment with the given text prompt, and higher R-Precision indicates better reconstruction of the objects’ geometry. Lower inference time is preferred. The table shows that MVGamba significantly outperforms existing methods across most of the metrics, particularly in terms of visual quality and precision.
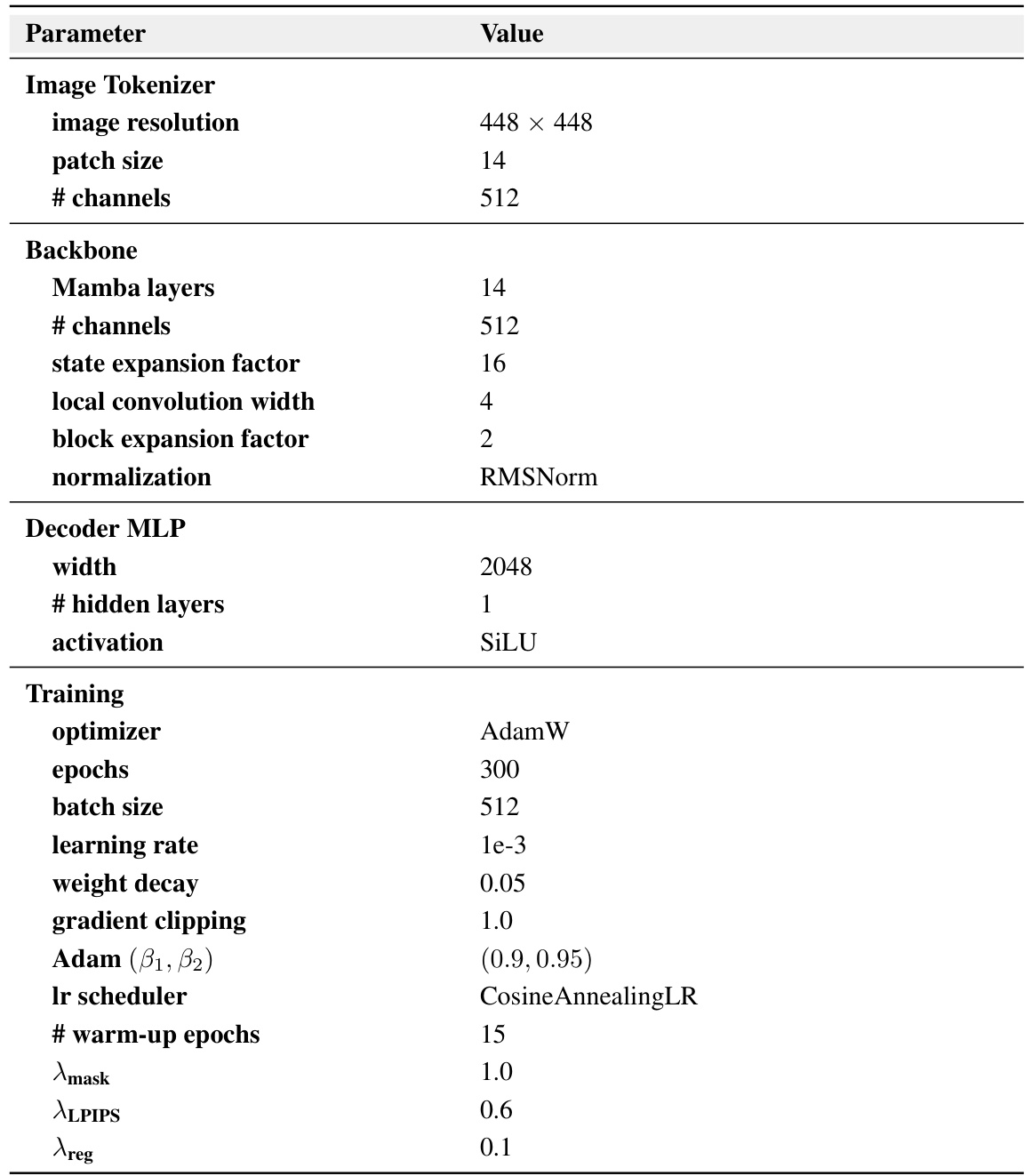
This table presents a quantitative comparison of MVGamba against other state-of-the-art 3D generation methods across various metrics including PSNR, SSIM, LPIPS, CLIP score, R-Precision, and inference time. It highlights MVGamba’s superior performance in terms of generation quality and efficiency.
Full paper#