TL;DR#
Tree-based models combined with automated feature engineering often outperform deep learning on tabular data. However, existing methods often rely on pre-defined search spaces and validation scores, limiting their effectiveness. This paper addresses these limitations by proposing a novel framework called OCTree that leverages Large Language Models (LLMs) for automated feature generation. OCTree uses LLMs to identify effective feature generation rules and decision trees to provide language-based reasoning information, improving the iterative rule refinement process.
OCTree uses LLMs and decision trees to generate and iteratively refine column features for tabular data. The framework enhances various prediction models across multiple benchmarks, outperforming existing automated feature engineering methods. The use of LLMs allows OCTree to avoid pre-defined search spaces, incorporate feedback from previous experiments, and leverage language understanding for more effective optimization. The consistent performance improvements across diverse datasets demonstrate the effectiveness of OCTree’s novel approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and data science due to its novel approach to automated feature generation for tabular data. OCTree’s innovative use of LLMs and decision tree reasoning offers significant improvements over existing methods, opening exciting new avenues for research in automated machine learning and improving the performance of various prediction models. The findings are highly relevant to current trends in LLMs and automated feature engineering, promising advancements in both fields.
Visual Insights#
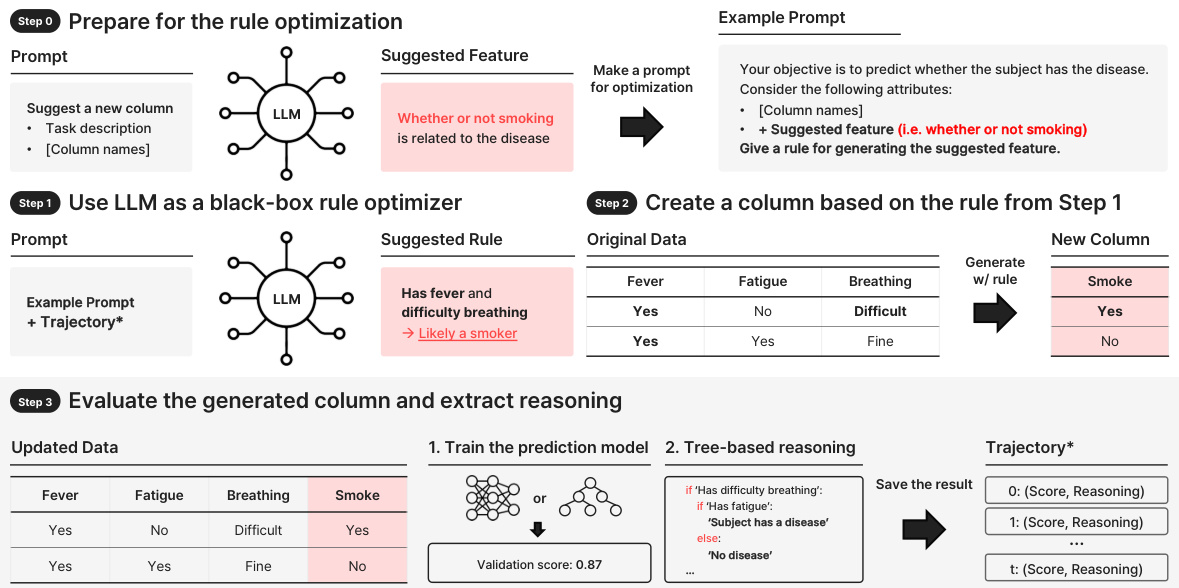
🔼 This figure shows the overall workflow of OCTree, which uses LLMs to generate new features iteratively. The process begins with prompting the LLM for a new column name and rule for generating its values. A prediction model is then trained with the new column, and its performance (validation score) and a decision tree-based explanation of feature importance are given back as feedback to the LLM. Steps 1-3 are repeated, and the best performing rule is selected.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times and select the rule with the best validation score.
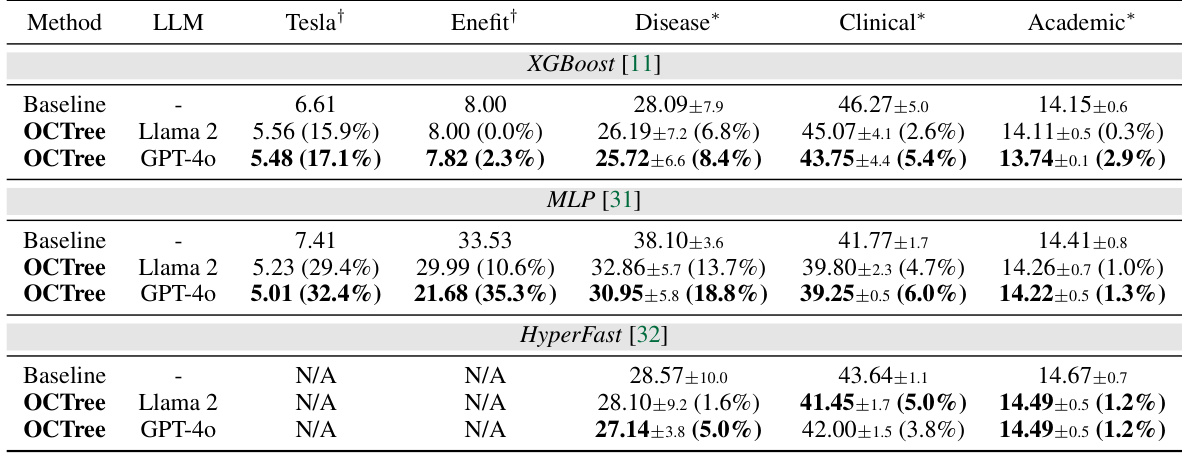
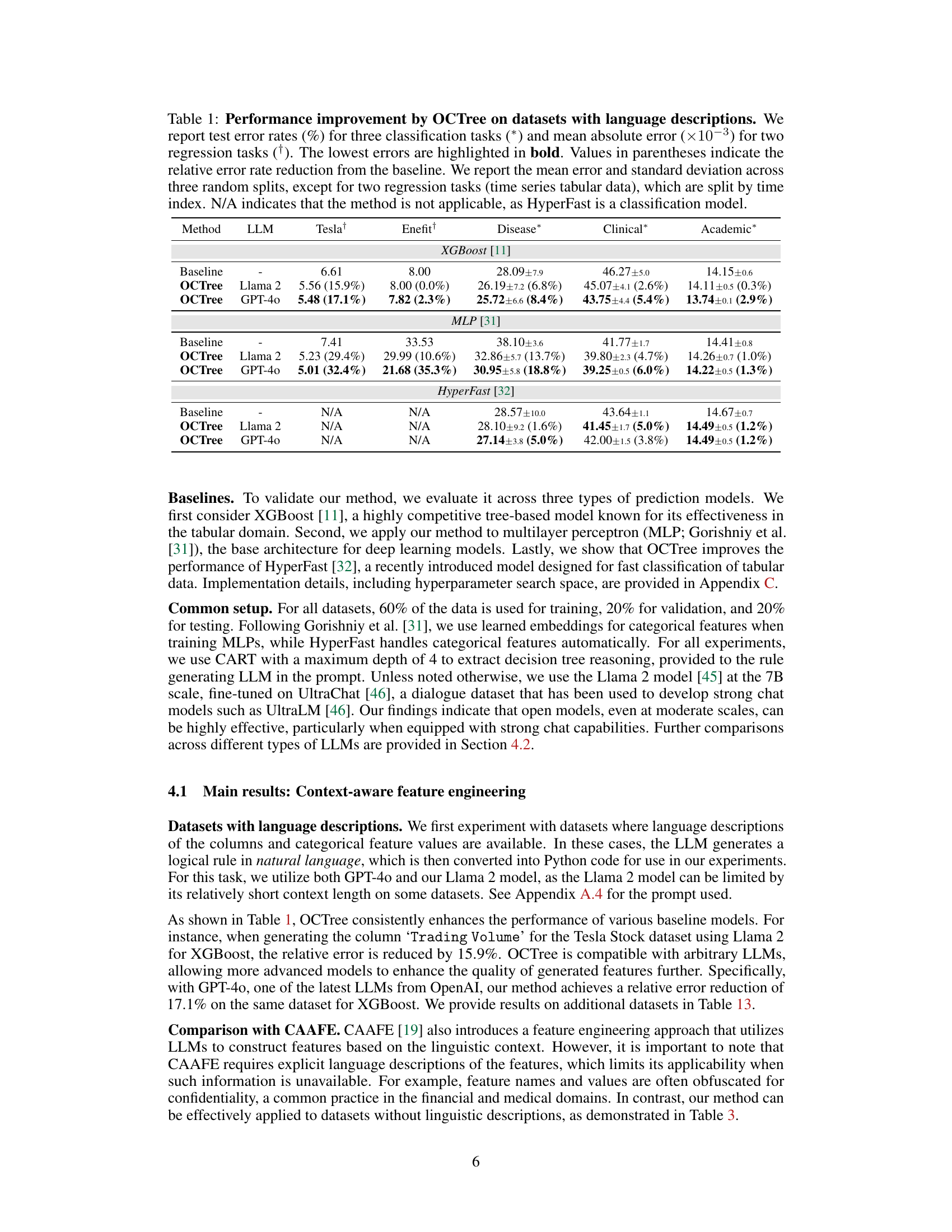
🔼 This table presents the results of the OCTree method on datasets with language descriptions. It compares the test error rates (or mean absolute errors for regression) achieved by different models (XGBoost, MLP, and HyperFast) with and without OCTree. The table shows the baseline performance, the performance after applying OCTree with Llama 2, and the performance after applying OCTree with GPT-40. The improvement in performance using OCTree is shown in parentheses as a percentage reduction in error.
read the caption
Table 1: Performance improvement by OCTree on datasets with language descriptions. We report test error rates (%) for three classification tasks (*) and mean absolute error (×10−3) for two regression tasks (†). The lowest errors are highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline. We report the mean error and standard deviation across three random splits, except for two regression tasks (time series tabular data), which are split by time index. N/A indicates that the method is not applicable, as HyperFast is a classification model.
In-depth insights#
LLM Feature Eng#
The heading ‘LLM Feature Eng’ suggests a research area focusing on leveraging large language models (LLMs) for automated feature engineering. This approach is particularly innovative because it moves beyond traditional methods which often rely on predefined search spaces and heuristic rules. LLMs offer the potential to learn complex feature relationships directly from the data and generate novel, potentially more effective features than human engineers. The method likely involves prompting the LLM with the data and task description, enabling it to generate and refine candidate features iteratively. A key aspect would be how the LLM’s reasoning process is integrated into the feature selection; this could involve generating explanations, justifications or identifying patterns, which could enhance the transparency and understanding of the generated features. Challenges might include controlling the complexity and interpretability of the LLM’s output, ensuring feature quality and preventing overfitting or biases. Successful application could drastically reduce the time and effort needed for feature engineering, speeding up the development of predictive models, and potentially enhancing model performance. Overall, ‘LLM Feature Eng’ represents a promising approach that combines the power of LLMs with the critical task of feature engineering in machine learning.
Decision Tree Aid#
A hypothetical “Decision Tree Aid” section in a research paper could explore how decision trees are used to enhance a machine learning model’s performance or interpretability. It might discuss how decision trees provide insights into feature importance and interactions, guiding feature engineering or selection for improved model accuracy. The section could also examine how a decision tree can be used to explain a complex model’s predictions, making it more transparent and easier to understand. The effectiveness of the aid in terms of accuracy gains, computational cost, and interpretability improvements would be key areas of analysis. Furthermore, the section could compare the decision tree aid against other explanation methods, such as LIME or SHAP, demonstrating its unique advantages and limitations. Finally, the discussion might consider the generalizability of the approach to different datasets and model types, as well as the potential ethical implications, especially regarding bias and fairness.
OCTree Framework#
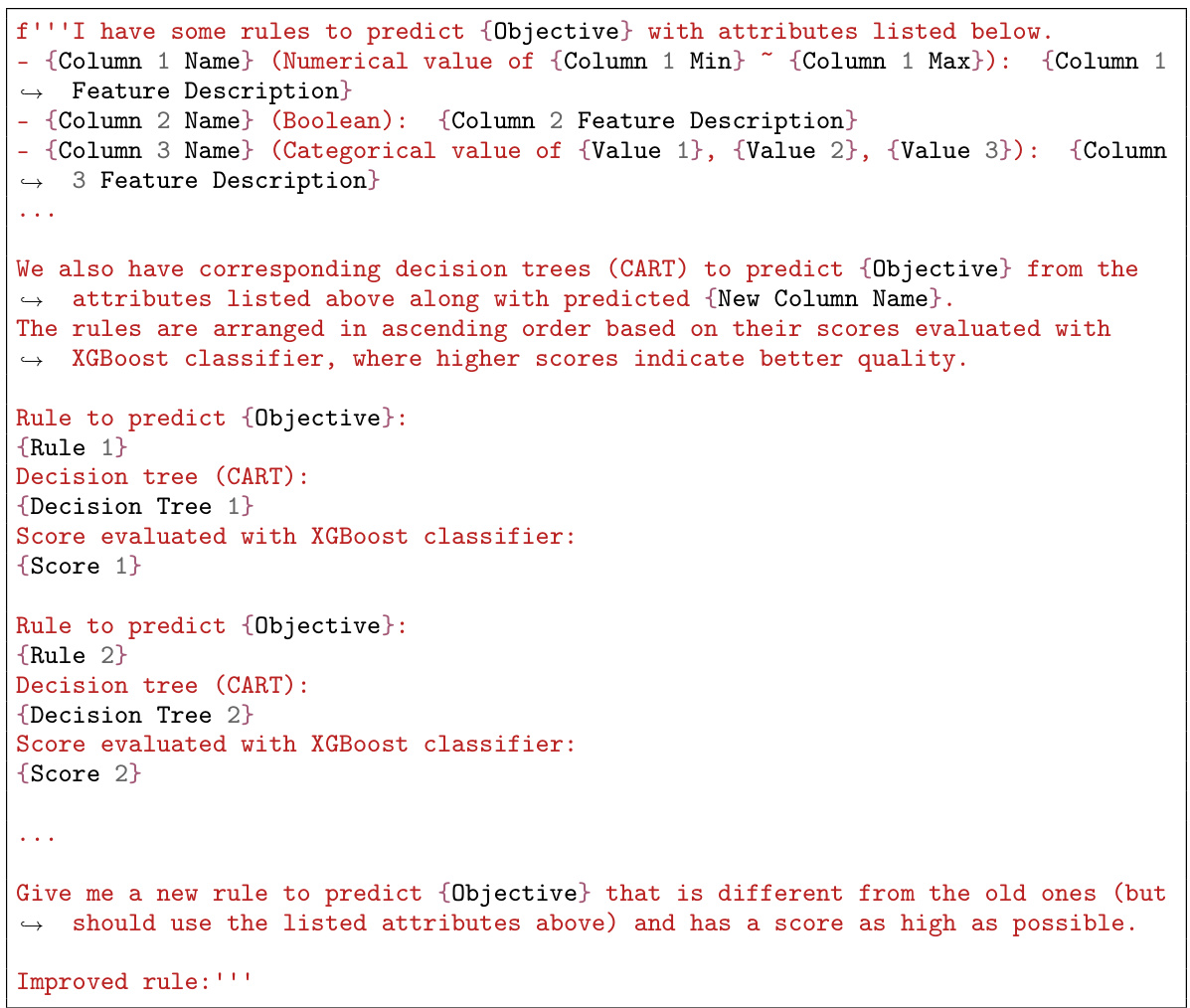
The OCTree framework presents a novel approach to automated feature generation for tabular data by leveraging the capabilities of Large Language Models (LLMs). Its core innovation lies in using LLMs not just for feature generation, but also for iterative rule optimization, guided by decision tree reasoning and validation scores. This iterative process allows OCTree to refine feature generation rules without manual specification of the search space, overcoming limitations of traditional methods. The integration of decision trees is particularly insightful, as they provide human-readable explanations of feature importance, enabling the LLM to learn from past experiments and improve subsequent feature generation. This feedback loop, combined with the LLM’s reasoning abilities, enables OCTree to discover effective features even in the absence of explicit language descriptions of the data. The framework’s generality is highlighted by its applicability across various prediction models and its consistent improvement in prediction accuracy across diverse benchmark datasets. While the reliance on LLMs introduces potential limitations such as hallucination, the iterative refinement process and integration of decision tree reasoning help mitigate these issues. OCTree represents a significant advancement in automated feature engineering, pushing the boundaries of what is possible through the synergistic combination of LLMs and decision tree reasoning.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper is crucial for evaluating the proposed method’s performance. It should present a comprehensive comparison against existing state-of-the-art techniques using widely accepted benchmark datasets. Quantitative metrics, such as accuracy, precision, recall, F1-score, or AUC, should be reported, along with their statistical significance (e.g., confidence intervals or p-values). The choice of benchmarks should be justified, highlighting their relevance to the problem domain and ensuring that they represent a fair and challenging evaluation. Visualizations, like tables and graphs, can improve readability and facilitate the comparison. Importantly, the results should be discussed in detail, analyzing both strengths and weaknesses of the proposed method, identifying any limitations, and explaining any unexpected findings. A robust ‘Benchmark Results’ section builds credibility and demonstrates the practical impact of the research by providing strong evidence of the method’s efficacy.
Future Enhancements#
Future enhancements for this research could explore several promising directions. Improving the LLM’s reasoning capabilities is crucial; more sophisticated prompting techniques or fine-tuning on larger, more relevant datasets could significantly enhance the quality of generated features. Expanding the range of compatible prediction models beyond those currently tested would demonstrate broader applicability. Incorporating more advanced feature selection methods could further refine the feature set, potentially improving performance and interpretability. Investigating the effects of different LLM architectures and sizes on feature generation is also warranted. Finally, a thorough investigation into the handling of imbalanced datasets and exploring techniques to mitigate potential biases in generated features would ensure fairness and robustness. This would enhance the method’s reliability and make it suitable for a wider variety of real-world applications.
More visual insights#
More on figures
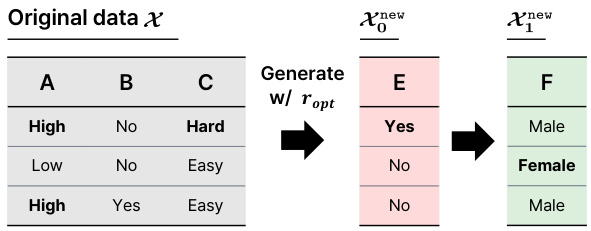
🔼 The figure shows how OCTree iteratively generates multiple features. It starts with the original dataset and generates a new feature (Xnew_0) using the optimized rule (ropt). Then, it uses this new feature and the original features to generate another new feature (Xnew_1), and this process continues until the validation score no longer improves. Each new feature is added as a new column to the dataset.
read the caption
Figure 2: Generation of multiple features. The optimization process is repeated to generate multiple column features in sequence.

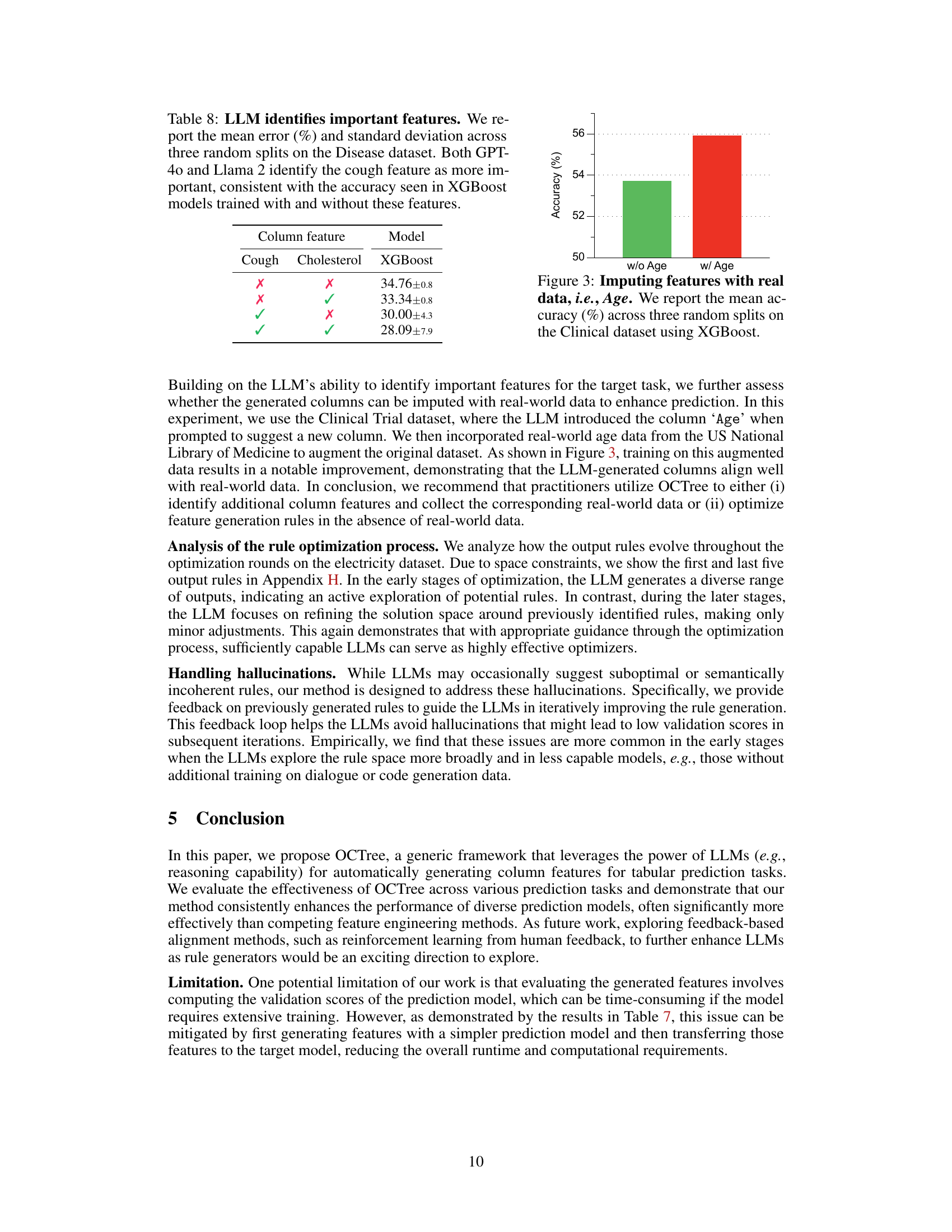
🔼 This figure shows the impact of imputing real-world age data on the performance of a prediction model. The experiment used the Clinical Trial dataset, where the LLM introduced the column ‘Age’ when prompted to suggest a new column. By incorporating real-world age data from the US National Library of Medicine, the accuracy of the XGBoost model was significantly improved, highlighting the importance of using real-world data when available. The results clearly demonstrate that the LLM-generated features align with real-world data and can improve prediction performance when combined appropriately.
read the caption
Figure 3: Imputing features with real data, i.e., Age. We report the mean accuracy (%) across three random splits on the Clinical dataset using XGBoost.

🔼 This figure shows the overview of the OCTree framework. It consists of four steps. In step 0, the LLM is prompted to suggest a name for a new column feature. In step 1, a rule for generating the feature is created by prompting the LLM using feedback from previous iterations and relevant information. In step 2, a new column is generated based on the rule. In step 3, a prediction model is trained on the new data, and the validation score and tree-based reasoning are computed and used as feedback. Steps 1-3 are repeated for a fixed number of times (step 4), and the rule with the best validation score is selected.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times, then select the rule with the best validation score.

🔼 This figure illustrates the overall workflow of the OCTree framework. It outlines the four steps involved in optimizing the generation of new column features using LLMs and decision trees. Step 0 involves prompting the LLM for a new column name. Step 1 focuses on generating a rule for the new feature using LLM prompting incorporating past results. Step 2 involves using the proposed rule to create the new column and Step 3 evaluates the generated column by training a prediction model and extracting decision tree reasoning to provide feedback to the LLM. Step 4 repeats Steps 1-3 iteratively and selects the best-performing rule.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times, then select the rule with the best validation score.
🔼 This figure illustrates the workflow of the OCTree framework. It starts with prompting a large language model (LLM) to suggest a name for a new column feature. Then, the LLM generates a rule to create this new column based on existing data and previous feedback. The generated column is evaluated using a prediction model, and the validation score and a decision tree reasoning are extracted. This information is fed back to the LLM to iteratively refine the rule. The process repeats until a predetermined number of iterations are performed, at which point the rule that achieves the best validation score is selected.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times, then select the rule with the best validation score.

🔼 This figure illustrates the overall process of OCTree, which leverages LLMs for automated feature generation. It shows a four-step iterative process: Step 0 initializes the process by prompting the LLM to suggest a name for a new column. Step 1 prompts the LLM to generate a rule for creating this new feature, incorporating feedback from previous iterations and data insights. Step 2 uses the generated rule to create the new column in the dataset. Step 3 trains a prediction model, evaluates its performance via a validation score, and extracts reasoning using a decision tree, which is provided as feedback to the LLM. This iterative cycle (steps 1-3) repeats a set number of times before choosing the rule producing the best-performing feature.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times, then select the rule with the best validation score.

🔼 This figure illustrates the four steps involved in OCTree’s optimization process. It starts by prompting an LLM to suggest a name for a new column, generating a rule for creating this column, evaluating the generated column’s performance, and repeating steps 1-3 for iterative improvements. The process culminates in selecting the rule that yields the best validation score.
read the caption
Figure 1: Overview of OCTree. (Step 0) Prompt the LLM to propose a name for the new column. (Step 1) Generate a rule by prompting the LLM with feedback on previously generated rules and relevant information for reasoning about the data. (Step 2) Generate a new column feature based on the proposed rule. (Step 3) Train a prediction model on the new data and compute the validation score and tree-based reasoning, provided as feedback for iterative improvements. (Step 4) Repeat steps 1-3 a fixed number of times, then select the rule with the best validation score.
More on tables

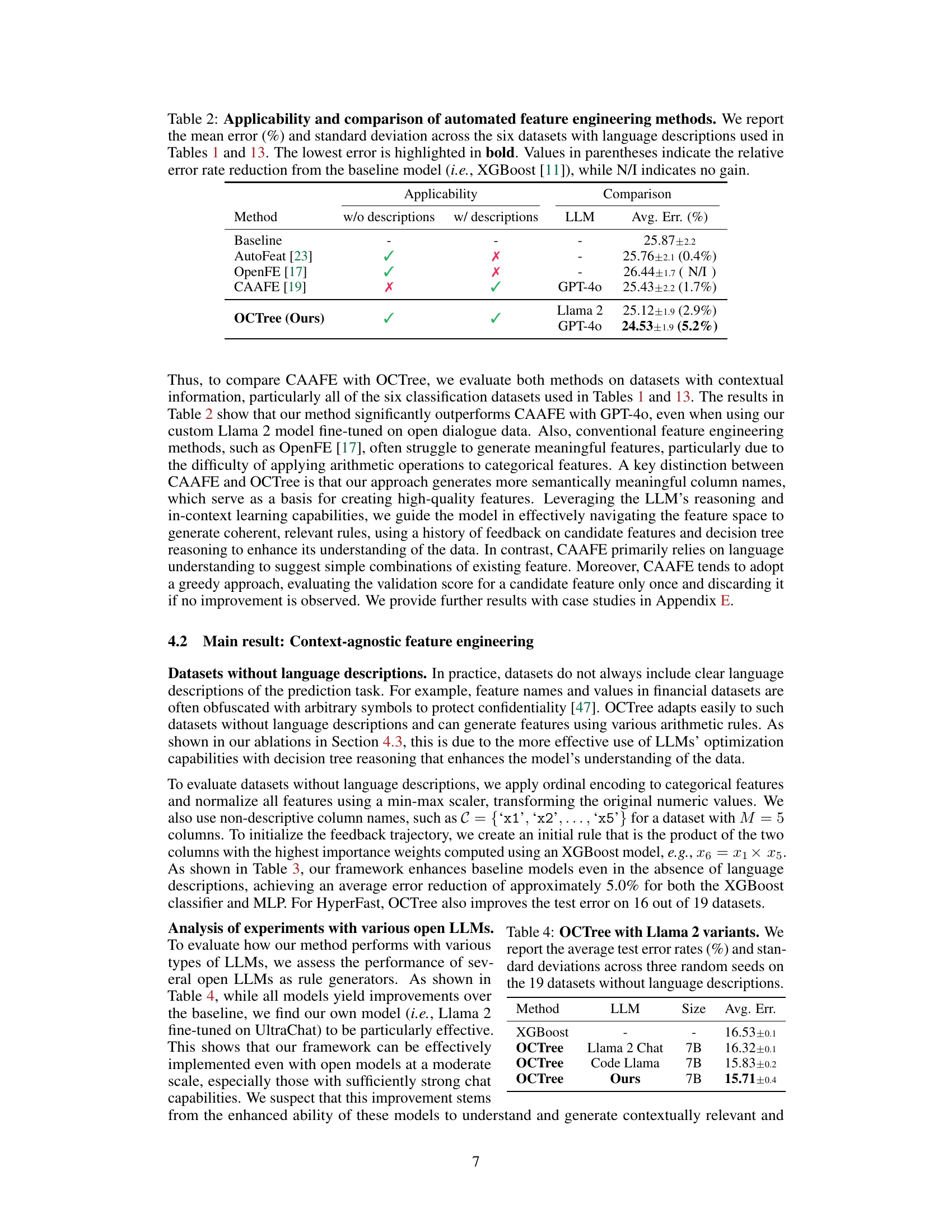
🔼 This table compares the performance of OCTree against other automated feature engineering methods (AutoFeat, OpenFE, and CAAFE). It shows the average error rate across six datasets, highlighting OCTree’s superior performance, particularly when using GPT-40. The table also demonstrates OCTree’s ability to handle datasets with and without language descriptions, unlike some of the other methods.
read the caption
Table 2: Applicability and comparison of automated feature engineering methods. We report the mean error (%) and standard deviation across the six datasets with language descriptions used in Tables 1 and 13. The lowest error is highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline model (i.e., XGBoost [11]), while N/I indicates no gain.

🔼 This table compares the performance of OCTree using different variants of the Llama 2 language model on 19 classification datasets. The datasets lack language descriptions of features, making this a context-agnostic setting. The table shows average test error rates and standard deviations across three independent trials for each model variant, allowing for a comparison of their effectiveness in automated feature generation for tabular data.
read the caption
Table 4: OCTree with Llama 2 variants. We report the average test error rates (%) and standard deviations across three random seeds on the 19 datasets without language descriptions.
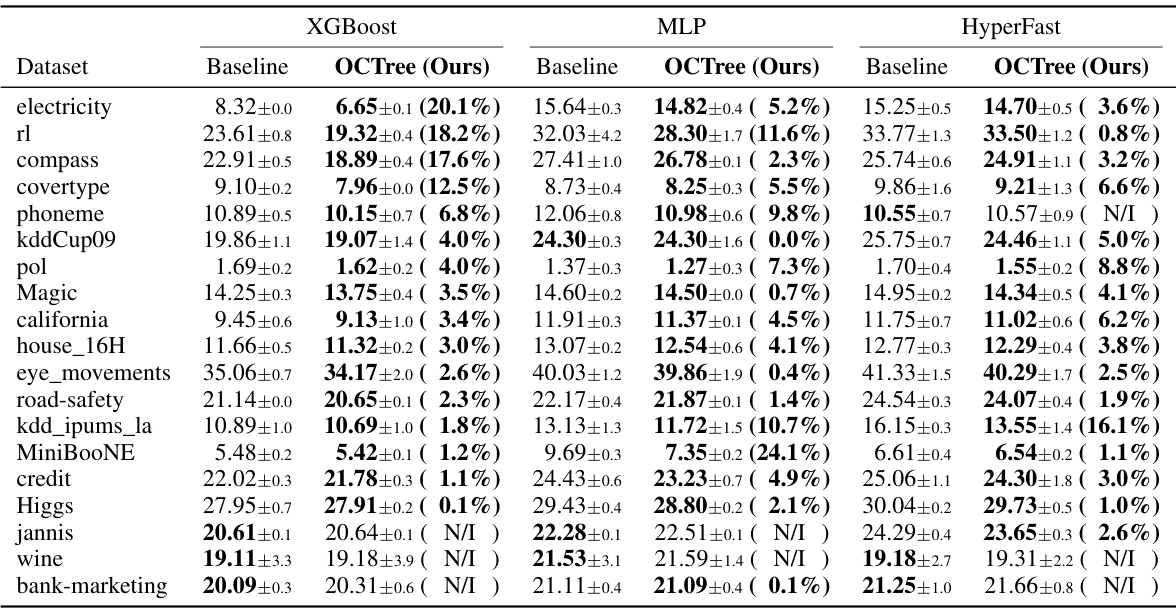
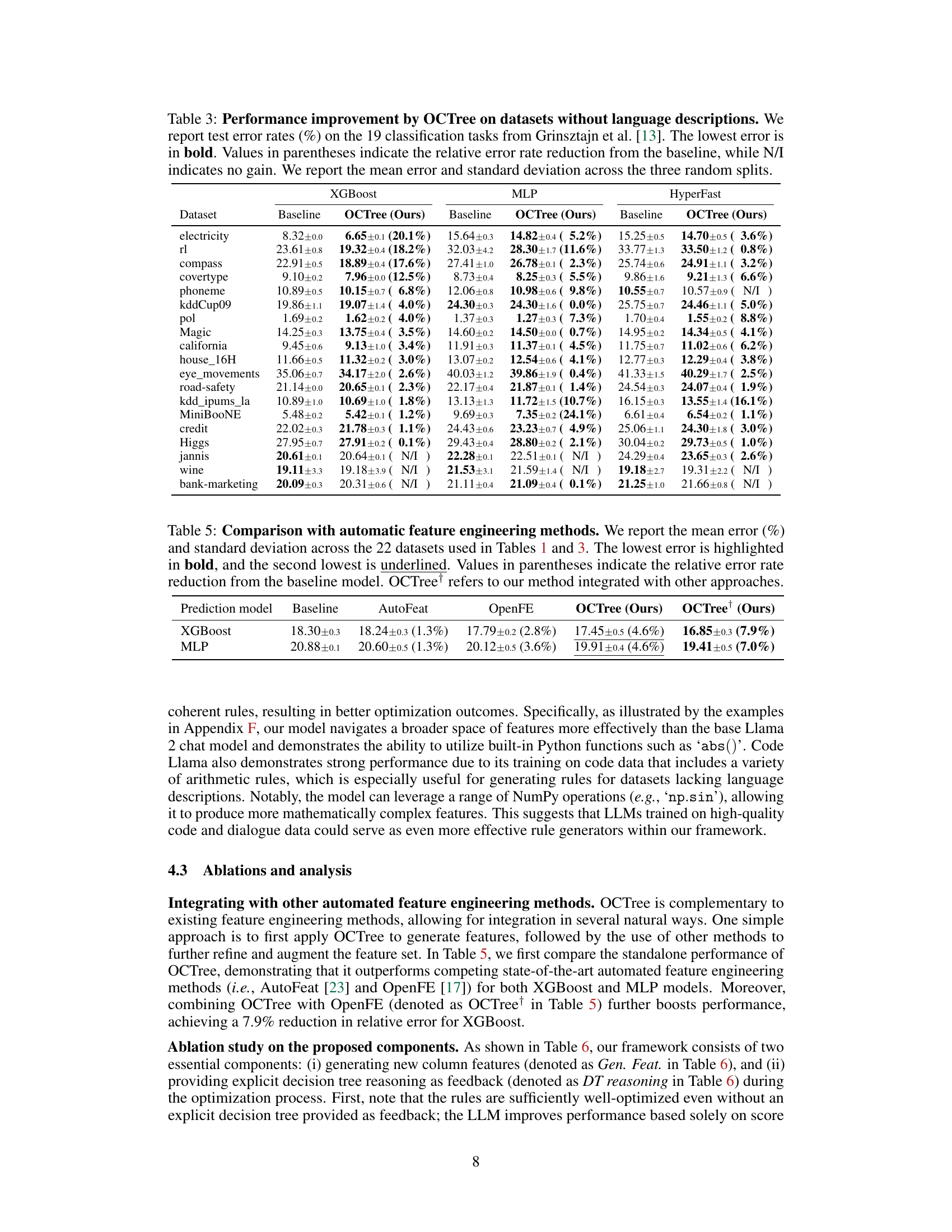
🔼 This table presents the results of applying the OCTree method to 19 classification datasets that do not include language descriptions. It compares the test error rates achieved by using OCTree against a baseline XGBoost model for each dataset. The lowest error rate for each dataset is highlighted, and the percentage reduction in error achieved using OCTree is indicated in parentheses. ‘N/I’ indicates no improvement was observed.
read the caption
Table 3: Performance improvement by OCTree on datasets without language descriptions. We report test error rates (%) on the 19 classification tasks from Grinsztajn et al. [13]. The lowest error is in bold. Values in parentheses indicate the relative error rate reduction from the baseline, while N/I indicates no gain. We report the mean error and standard deviation across the three random splits.

🔼 This table compares the performance of OCTree against other automated feature engineering methods (AutoFeat and OpenFE) on 22 datasets. It shows the mean error and standard deviation for both XGBoost and MLP models. The results demonstrate that OCTree consistently outperforms the other methods and that integrating OCTree with OpenFE further improves performance.
read the caption
Table 5: Comparison with automatic feature engineering methods. We report the mean error (%) and standard deviation across the 22 datasets used in Tables 1 and 3. The lowest error is highlighted in bold, and the second lowest is underlined. Values in parentheses indicate the relative error rate reduction from the baseline model. OCTree refers to our method integrated with other approaches.

🔼 This table presents the results of an ablation study to evaluate the impact of the two main components of the proposed OCTree framework: the generation of new column features and the incorporation of decision tree reasoning as feedback to the LLM. The study is conducted on four datasets: two with language descriptions and two without. The table shows the mean error and standard deviation for each dataset and condition, highlighting the lowest error rate in bold and providing the relative error reduction from the baseline in parentheses. This helps to quantify the effect of each component on model performance.
read the caption
Table 6: Ablation study of the proposed decision tree reasoning. We report the mean error (%) and standard deviation across three random splits on two datasets with language descriptions (*) and two datasets without language descriptions (†). The lowest error is highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline model.
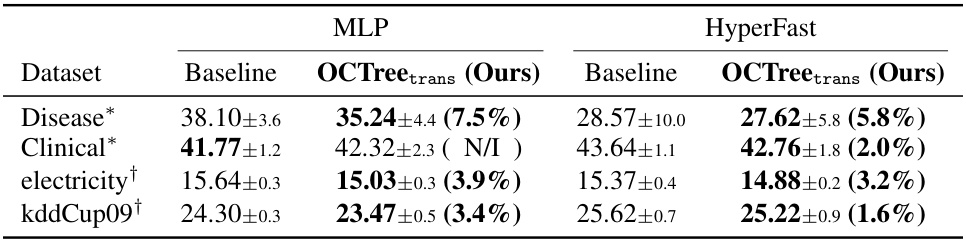
🔼 This table presents the results of an experiment to evaluate the transferability of features generated by OCTree using XGBoost to other prediction models, specifically MLP and HyperFast. The experiment uses four datasets, two with language descriptions and two without. It shows the baseline error rates for each model and dataset, and then shows the error rates after transferring features generated by OCTree. The improvement, or lack thereof, is presented as a percentage reduction. N/I indicates no improvement.
read the caption
Table 7: Performance improvement through feature transfer. We optimize the feature generation rule using XGBoost and transfer the generated features to improve MLP and HyperFast (OCTreetrans). We report the test error rates (%) and standard deviation across three random seeds for two datasets with language descriptions (*) and two datasets without (†). The lowest error is in bold, with values in parentheses indicating the relative error rate reduction from the baseline model. N/I denotes cases where no improvement was observed.

🔼 This table presents the results of an experiment designed to assess the ability of LLMs to identify important features for a prediction task. The experiment involved removing two features (‘Cough’ and ‘Cholesterol’) from the Disease dataset and prompting two different LLMs (GPT-40 and Llama 2) to rank the importance of these features for predicting the target variable. The table shows the mean error and standard deviation across three random splits for an XGBoost model trained with different combinations of these features. The results indicate that both LLMs correctly identified ‘Cough’ as the more important feature, which is consistent with the better accuracy achieved by the XGBoost model trained with the ‘Cough’ feature.
read the caption
Table 8: LLM identifies important features. We report the mean error (%) and standard deviation across three random splits on the Disease dataset. Both GPT-40 and Llama 2 identify the cough feature as more important, consistent with the accuracy seen in XGBoost models trained with and without these features.
🔼 This table shows the performance improvement achieved by OCTree on 19 classification datasets from Grinsztajn et al. [13], where language descriptions for features are not available. The table compares the test error rates of OCTree against baseline models (XGBoost, MLP, and HyperFast) and presents the relative error reduction achieved by OCTree. The lowest error rates for each dataset are highlighted in bold, and N/I is used to denote cases with no improvement. The mean error and standard deviation are reported across three random splits for each dataset.
read the caption
Table 3: Performance improvement by OCTree on datasets without language descriptions. We report test error rates (%) on the 19 classification tasks from Grinsztajn et al. [13]. The lowest error is in bold. Values in parentheses indicate the relative error rate reduction from the baseline, while N/I indicates no gain. We report the mean error and standard deviation across the three random splits.

🔼 This table presents the results of applying the OCTree method to datasets with language descriptions. It compares the performance of different models (XGBoost, MLP, HyperFast) with and without OCTree, using metrics appropriate for both classification and regression tasks. The improvement in performance offered by OCTree is shown using both absolute error values and the percentage reduction in error compared to baseline models.
read the caption
Table 1: Performance improvement by OCTree on datasets with language descriptions. We report test error rates (%) for three classification tasks (*) and mean absolute error (×10−3) for two regression tasks (†). The lowest errors are highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline. We report the mean error and standard deviation across three random splits, except for two regression tasks (time series tabular data), which are split by time index. N/A indicates that the method is not applicable, as HyperFast is a classification model.

🔼 This table presents the results of applying the OCTree method to datasets with descriptions available in natural language. It shows the test error rates for classification tasks and mean absolute error for regression tasks. The best performing model for each task is shown in bold, and the improvement percentage compared to the baseline model is given in parentheses. The table also differentiates between results obtained using Llama 2 and GPT-4, and includes the results for three different prediction models (XGBoost, MLP, and HyperFast).
read the caption
Table 1: Performance improvement by OCTree on datasets with language descriptions. We report test error rates (%) for three classification tasks (*) and mean absolute error (×10−3) for two regression tasks (†). The lowest errors are highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline. We report the mean error and standard deviation across three random splits, except for two regression tasks (time series tabular data), which are split by time index. N/A indicates that the method is not applicable, as HyperFast is a classification model.

🔼 This table shows the performance improvement achieved by OCTree on several datasets with language descriptions, comparing it to various baseline models (XGBoost, MLP, HyperFast). It presents test error rates for classification and mean absolute error for regression tasks. The results are averaged across three random splits (except for time series data), with standard deviations reported. The relative error reduction compared to the baseline is also given in parentheses. The table highlights the best-performing methods in bold.
read the caption
Table 1: Performance improvement by OCTree on datasets with language descriptions. We report test error rates (%) for three classification tasks (*) and mean absolute error (×10−3) for two regression tasks (†). The lowest errors are highlighted in bold. Values in parentheses indicate the relative error rate reduction from the baseline. We report the mean error and standard deviation across three random splits, except for two regression tasks (time series tabular data), which are split by time index. N/A indicates that the method is not applicable, as HyperFast is a classification model.

🔼 This table compares the performance of OCTree against CAAFE and a baseline model on datasets with language descriptions. It shows the test error rates for classification tasks and mean absolute errors for regression tasks. The results demonstrate the improvement achieved by OCTree in terms of relative error rate reduction.
read the caption
Table 13: Performance improvements by OCTree on datasets with language descriptions. We report test error rates (%) on six classification tasks (*) and mean absolute errors (×10−3) for two regression tasks (†). The lowest error is in bold. Values in parentheses indicate the relative error rate reduction from the baseline. We report the mean error and standard deviation across three random splits, except for the two regression tasks (time series tabular data), which are split by time index. GPT-40 was used for both CAAFE and OCTree.

🔼 This table presents the results of applying OCTree to datasets with a large number of features (madelon with 501 features and nomao with 119 features). It compares the mean error rate achieved by OCTree against a baseline XGBoost model. The percentage improvement achieved by OCTree is shown in parentheses for each dataset.
read the caption
Table 14: OCTree on datasets with hundreds of features. We report the mean error (%) and the lowest error is highlighted in bold. Values in parentheses indicate the relative error reduction from the baseline model (i.e., XGBoost [11]).
Full paper#