↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality videos from various viewpoints is a challenge in current video generation models. Existing methods often struggle to maintain consistency across different camera angles, resulting in inconsistencies in the content and dynamics. This limits the applicability of video generation in many downstream tasks requiring consistent multi-view videos, such as large-scale 3D scene generation and virtual reality.
This paper introduces Collaborative Video Diffusion (CVD), a novel framework that addresses this issue. CVD uses a novel cross-video synchronization module that leverages epipolar attention to maintain consistency across videos. The model is trained on video pairs with individually controllable camera trajectories and then extended to generate an arbitrary number of videos. Extensive experiments demonstrate CVD’s superior performance in generating high-quality and consistent multi-view videos compared to existing baselines.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a significant challenge in video generation: creating consistent multi-view videos. It introduces a novel approach to generate multiple videos from different camera viewpoints while ensuring content consistency, addressing a key limitation of existing models. This opens avenues for advancements in large-scale 3D scene generation, virtual reality, and other applications requiring consistent multi-view experiences.
Visual Insights#
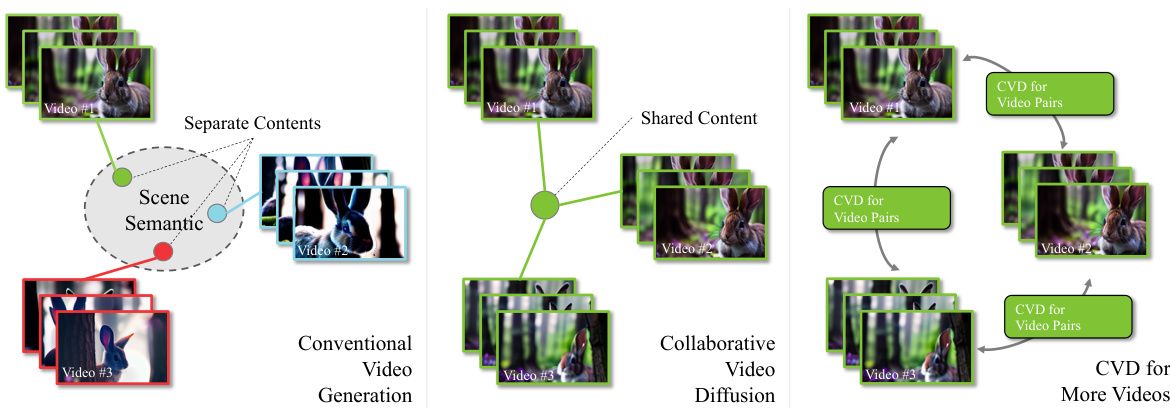
This figure illustrates the difference between conventional video generation and collaborative video diffusion. Conventional methods generate videos independently, leading to inconsistencies in content and dynamics across videos. Collaborative video diffusion, on the other hand, generates videos with shared underlying content, ensuring consistency despite different camera angles. The figure shows how this approach can be scaled from pairs of videos to multiple videos.
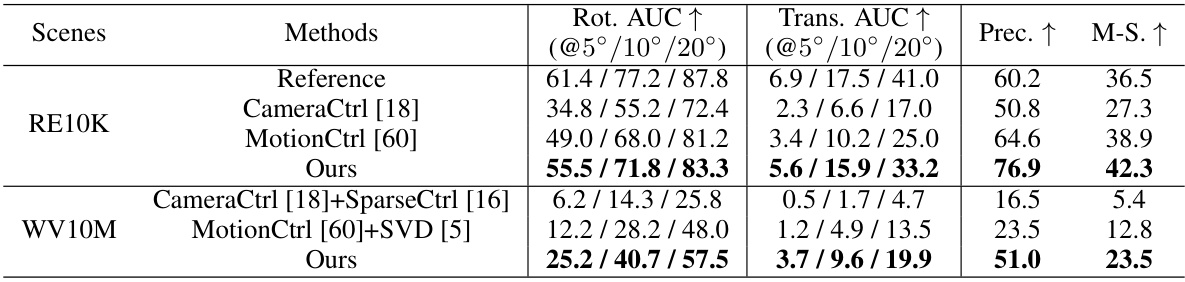
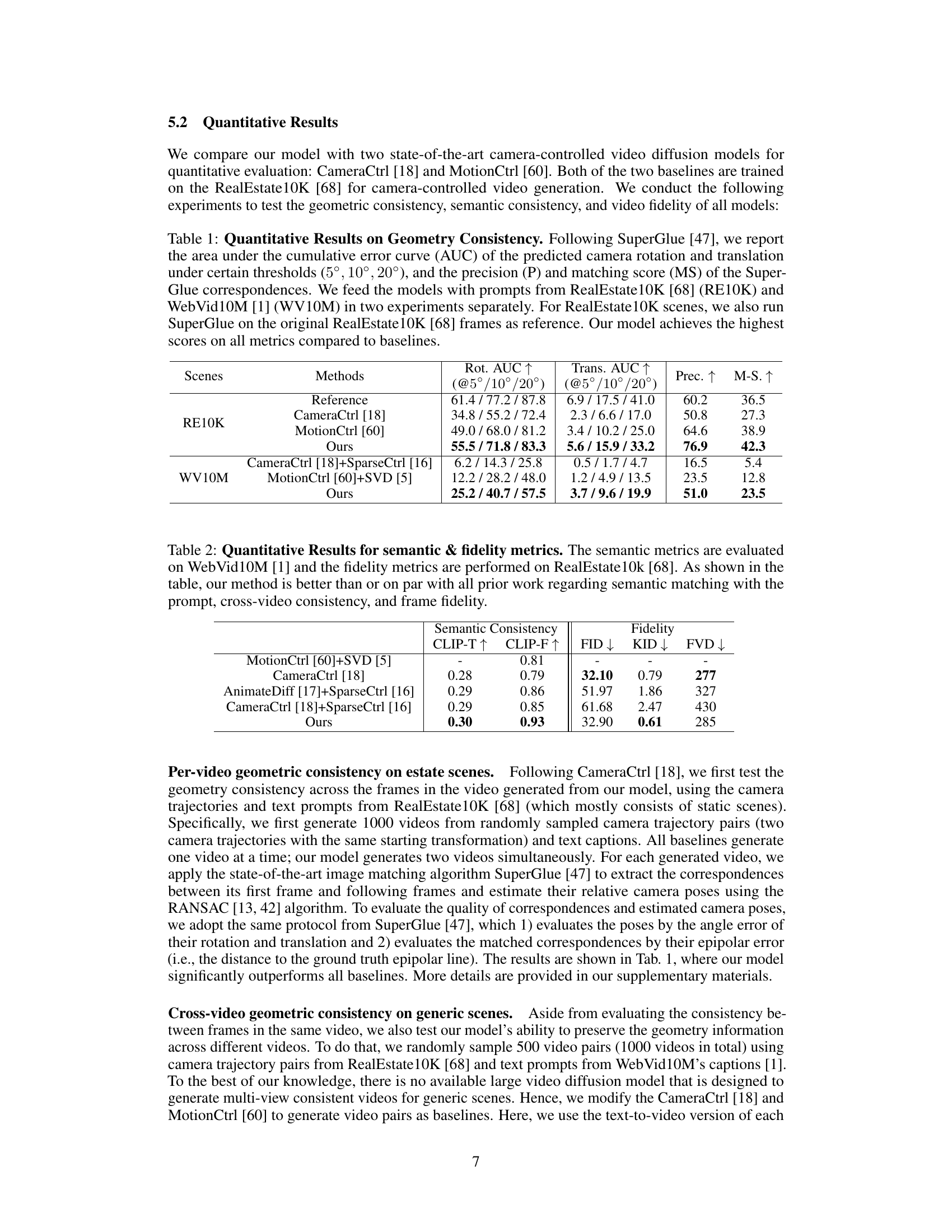
This table presents a quantitative comparison of different video generation models in terms of geometry consistency. It uses the SuperGlue metric to assess the accuracy of predicted camera rotations and translations, evaluating performance across various error thresholds. The models are tested on two datasets: RealEstate10K (static scenes) and WebVid10M (dynamic scenes), with SuperGlue scores calculated for the original RealEstate10K frames as a reference. The results show that the proposed model outperforms existing methods on all metrics.
In-depth insights#
CVD Framework#
The CVD framework, as implied by its name, centers on collaborative video diffusion. It tackles the challenge of generating multiple videos of the same scene from diverse camera viewpoints while maintaining high consistency. This is achieved through a novel cross-video synchronization module, leveraging an epipolar attention mechanism to align corresponding frames across different views. This module promotes consistency in geometry and semantics by focusing on epipolar relationships between pixels, enhancing structural coherence. A hybrid training strategy employing both static and dynamic datasets further boosts performance. The framework is designed for scalability, extending beyond pairs of videos to handle multiple video generation using a collaborative inference approach. Overall, the CVD framework presents a significant advancement in multi-view video generation, surpassing limitations of existing single-view techniques by explicitly addressing the need for cross-video consistency and achieving highly coherent multi-video outputs.
Cross-View Sync#
A crucial aspect of multi-view video generation is ensuring consistency across different viewpoints. A module focused on ‘Cross-View Synchronization’ would be essential for achieving this. The core challenge lies in aligning features and ensuring that the generated videos share the same underlying content and dynamics, despite originating from disparate camera perspectives. Effective cross-view synchronization necessitates a mechanism to bridge the gap between distinct views and establish correspondences between frames from various viewpoints. This might involve techniques such as epipolar geometry, where the geometric relationships between corresponding points in different images are leveraged to establish pixel-level correspondence. Another approach could utilize attention mechanisms, where the model is trained to attend to relevant features in other views based on context. Advanced architectures could incorporate learned feature embeddings, capturing semantic relationships across views, beyond simple geometric alignment. Successfully synchronizing multiple views requires careful consideration of the training process as well, and employing a dataset comprising multiple synchronized views, or developing smart data augmentation techniques, would be paramount for effective learning. Ultimately, the effectiveness of cross-view synchronization hinges on the ability to achieve robust feature alignment while maintaining both geometric and semantic consistency, creating videos that appear as though they were captured simultaneously from multiple positions within a shared 3D scene.
Hybrid Training#
The hybrid training strategy is a key innovation enabling the model to learn from diverse data sources, overcoming limitations of existing datasets. By combining static, multi-view data from RealEstate10k with dynamic monocular data from WebVid10M, the model effectively learns camera control and motion, addressing the scarcity of large-scale, multi-view dynamic scene data. This two-phase approach leverages the strengths of each dataset: RealEstate10k provides geometric consistency and camera pose information, while WebVid10M offers rich dynamic content. This hybrid strategy is crucial for generating multi-view videos with consistent content and motion, a task significantly hindered by the absence of comprehensive training data. The model’s capability to seamlessly integrate data from these disparate sources demonstrates its robust learning capacity and adaptability.
Multi-View Inference#
Multi-view inference, in the context of video generation, presents a significant challenge and opportunity. The goal is to generate consistent video content from multiple viewpoints simultaneously, requiring sophisticated coordination between individual video streams. Successful multi-view inference necessitates a model’s ability to understand and maintain scene consistency across different perspectives. This implies a deep understanding of 3D scene geometry, object interactions, and camera movements. A key aspect is dealing with the inherent ambiguity of multiple viewpoints, where occlusion and perspective differences can lead to inconsistencies. Effective techniques may involve cross-view attention mechanisms or epipolar geometry constraints to ensure consistent geometry and semantics. The availability of training data poses a major hurdle, as large-scale multi-view datasets are scarce. Clever data augmentation strategies, such as utilizing existing monocular data in conjunction with novel methods for pseudo-view generation, are important for addressing this shortage. Multi-view inference promises advancements in large-scale 3D scene generation, novel-view synthesis, and other applications demanding consistent multi-perspective content.
Future Works#
Future work could explore several promising avenues. Extending CVD to handle more complex scene dynamics and longer video sequences is crucial for broader applicability. This might involve investigating more sophisticated temporal modeling techniques or incorporating additional conditioning signals beyond camera poses and text prompts. Another direction would be improving the efficiency and scalability of CVD, potentially through architectural optimizations or leveraging more efficient training strategies. The current model relies on paired videos; developing techniques to generate consistent multi-view videos from a single source or fewer inputs would significantly increase usability. Additionally, exploring the use of CVD in applications beyond video generation warrants further exploration. The model’s ability to generate consistent content across multiple viewpoints opens up exciting possibilities in large-scale 3D scene reconstruction, virtual reality, and other domains. Finally, while the model demonstrates strong performance, a more comprehensive analysis of its limitations and failure modes is needed to better understand its capabilities and limitations. Addressing these points will significantly improve and expand the utility of CVD.
More visual insights#
More on figures
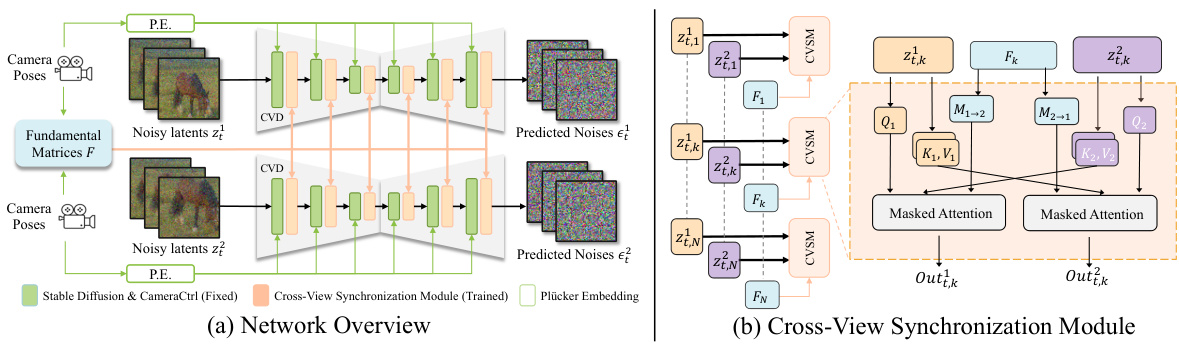
This figure illustrates the architecture of the Collaborative Video Diffusion (CVD) model. The left panel shows an overview of the model’s architecture, highlighting the input (noisy video features and camera trajectories), the processing steps (CVD model and Cross-View Synchronization Module), and the output (predicted noise for each video). The right panel zooms in on the Cross-View Synchronization Module, showing how it uses masked attention to align features from corresponding frames of different videos. This module is a key component of CVD, enabling consistent multi-video generation.
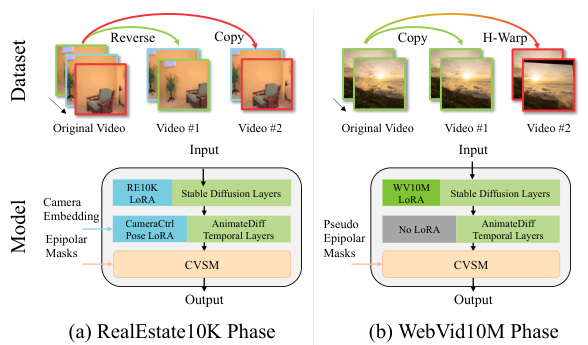
This figure illustrates the two-phase hybrid training strategy used in the paper. The top half shows how the two datasets, RealEstate10K and WebVid10M, are processed differently. RealEstate10K videos are folded to create synchronized video pairs, while WebVid10M videos undergo homography augmentation to simulate multiple views. The bottom half shows the distinct model structures used for each phase. The RealEstate10K phase leverages CameraCtrl and its associated components, while the WebVid10M phase uses AnimateDiff and only includes the cross-view synchronization module (CVSM) with pseudo-epipolar masks, without the pose LoRA and camera embedding components used in the RealEstate10K phase.
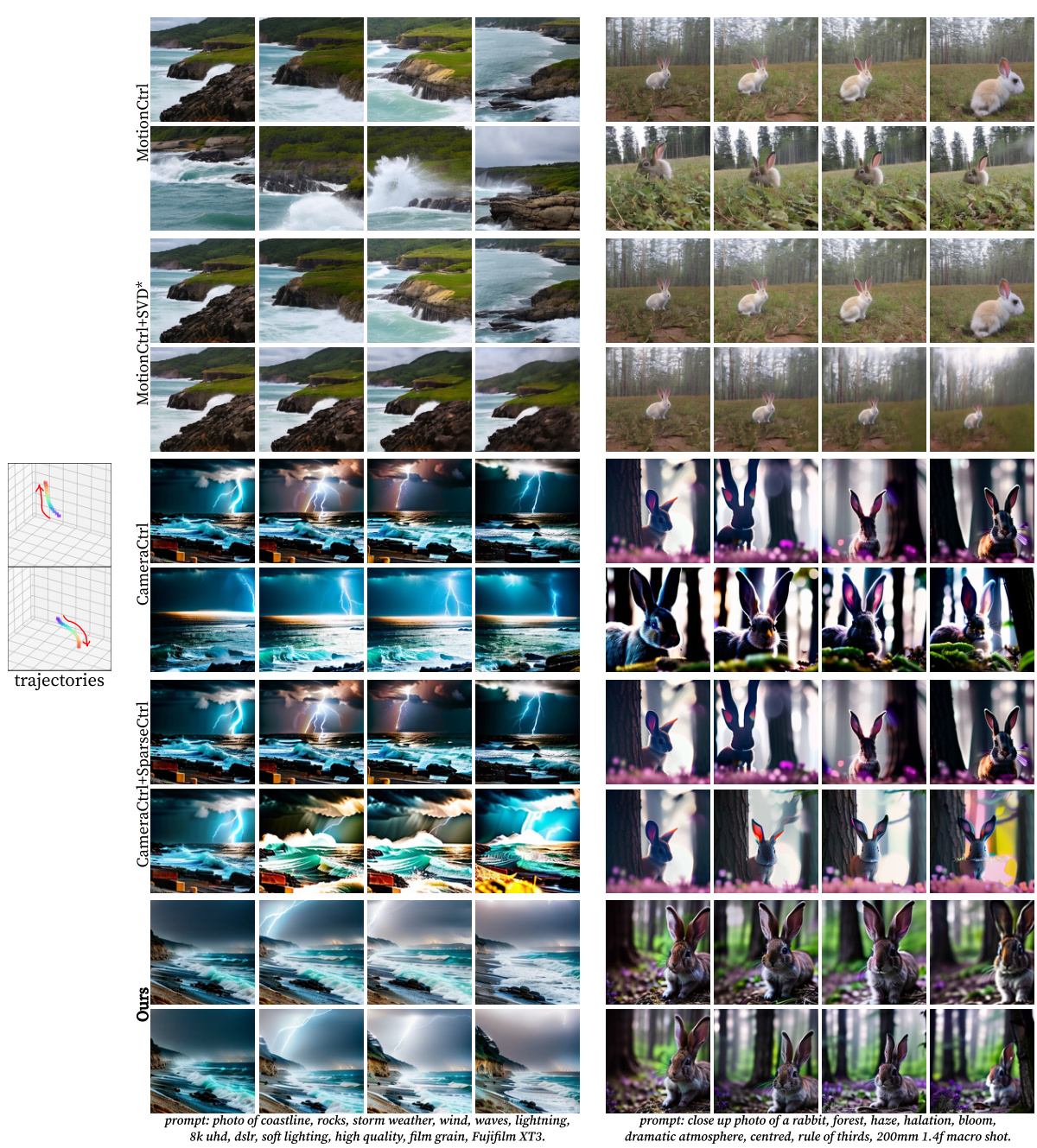
This figure compares the results of CVD with several baselines on generating videos from the same prompts but with different camera trajectories. The left column shows results for prompts related to a coastline with stormy weather, while the right column shows results for prompts related to rabbits in a forest. Each row represents a different method: MotionCtrl, MotionCtrl+SVD, CameraCtrl, CameraCtrl+SparseCtrl, and CVD (Ours). The figure highlights CVD’s ability to maintain consistency in content and dynamics across multiple videos, a significant improvement over the baselines, which struggle to maintain consistency, especially in terms of motion. Note that MotionCtrl+SVD failed to generate any significant motion besides simple zooming.
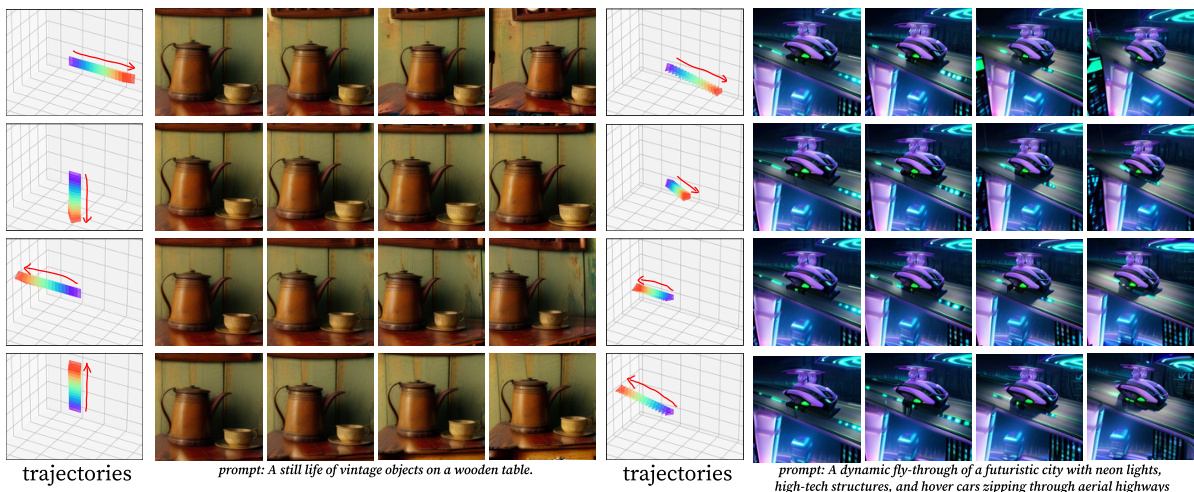
This figure shows examples of multi-view video generation results. The left side demonstrates videos generated with camera trajectories moving in four different directions while focusing on a single 3D point. The right side showcases videos where trajectories are interpolated, starting from one path and smoothly transitioning to another.

This figure illustrates the architecture of the Collaborative Video Diffusion (CVD) model. The left panel shows an overview of the CVD model which takes as input multiple noisy video features and corresponding camera trajectories. These inputs are processed to generate noise predictions for each video. The image autoencoder from Stable Diffusion is not explicitly shown for simplification. The right panel zooms into the Cross-View Synchronization Module (CVSM), a crucial part of CVD. The CVSM takes corresponding frames from different videos and their fundamental matrices as input. It utilizes a masked cross-view attention mechanism to enhance consistency between the videos by aligning features based on epipolar geometry.

This figure visualizes the attention mechanism used in the Cross-View Synchronization Module. It shows attention maps for two example images, one of a fish tank and the other of a landscape. The green circles highlight specific pixels in the first image, and the corresponding attention weights are displayed in the second image. The brighter colors indicate stronger attention to corresponding epipolar regions, demonstrating the model’s ability to effectively correlate semantically consistent regions across videos from different camera viewpoints.

This figure compares the results of the proposed Collaborative Video Diffusion (CVD) model with several baseline models for generating videos from different camera viewpoints. The left column shows videos of a castle scene, and the right column shows videos of an aquarium scene. The top rows show the results of the baseline models: CameraCtrl, CameraCtrl+SparseCtrl, and MotionCtrl+SVD. The bottom row shows the results of the proposed CVD model. The CVD model produces significantly more consistent videos across different camera perspectives, especially in the dynamic aspects of the scenes, such as the movement of fish in the aquarium or the lightning in the castle scene.

This figure shows a qualitative comparison of the proposed CVD model with several baselines on video generation. The results demonstrate that CVD outperforms the baselines in maintaining consistency across videos generated with different camera trajectories, especially in dynamic scenes. The superior performance of CVD is highlighted by the consistent content and motion across multiple videos, unlike the baselines which often exhibit inconsistencies in geometries, objects, and motions.
This figure illustrates the architecture of the Collaborative Video Diffusion (CVD) model. The left panel shows an overview of the CVD model’s structure, highlighting its input (noisy video features and camera trajectories), its processing of these inputs, and its output (noise predictions for video generation). The right panel focuses specifically on the Cross-View Synchronization Module, detailing its input (frames from two videos and the fundamental matrix) and its operation (masked cross-view attention). The figure emphasizes the key components involved in achieving consistent multi-video generation with camera control, showing the interaction between the main model and the synchronization module.
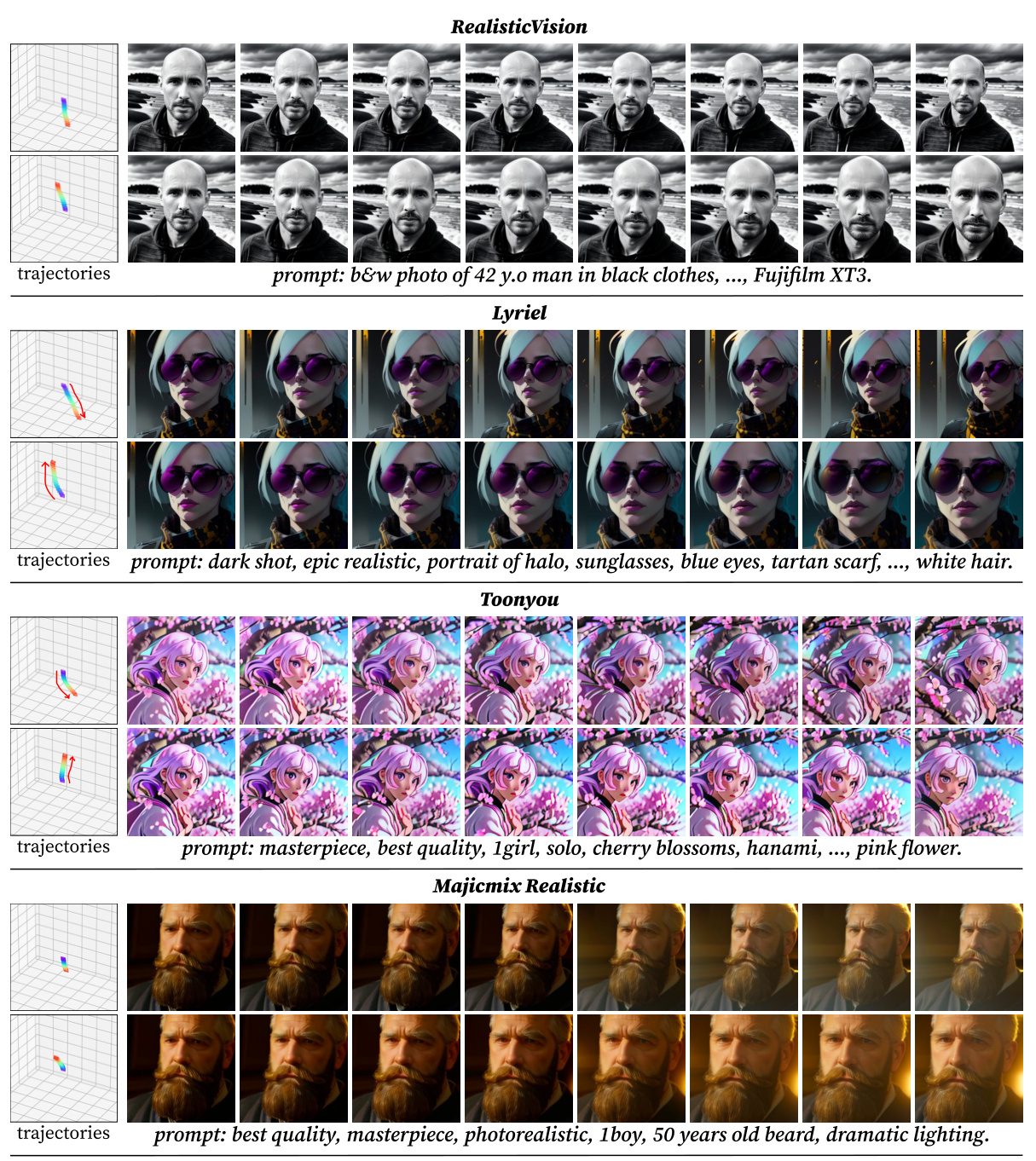
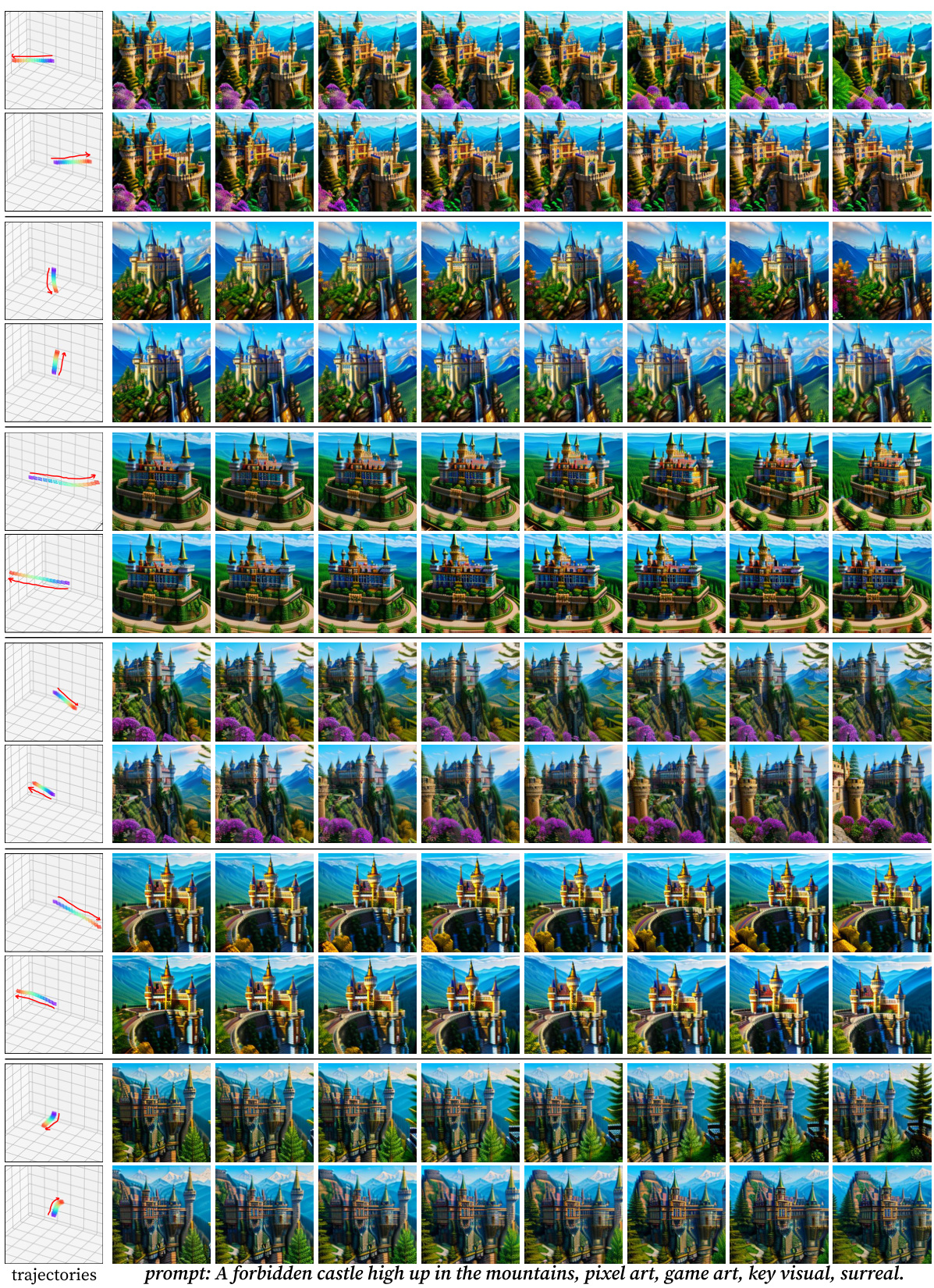
This figure shows additional qualitative results demonstrating the model’s ability to generate multiple videos with different camera trajectories and realizations while maintaining consistent content and dynamics. Each row represents a separate set of videos generated from the same text prompt, but with varying camera viewpoints. The consistency in content across different viewpoints highlights the effectiveness of the proposed Collaborative Video Diffusion (CVD) method in achieving multi-view video generation with camera control.

This figure shows additional qualitative results generated by the model with different camera trajectories and realizations. The prompt used was: ‘an aerial view of a cyberpunk city, night time, neon lights, masterpiece, high quality.’ The results demonstrate the model’s ability to generate consistent videos across multiple viewpoints, even when the camera movements vary significantly. Each row represents a different set of camera trajectories, and the images within each row show the generated video frames for that set of trajectories.
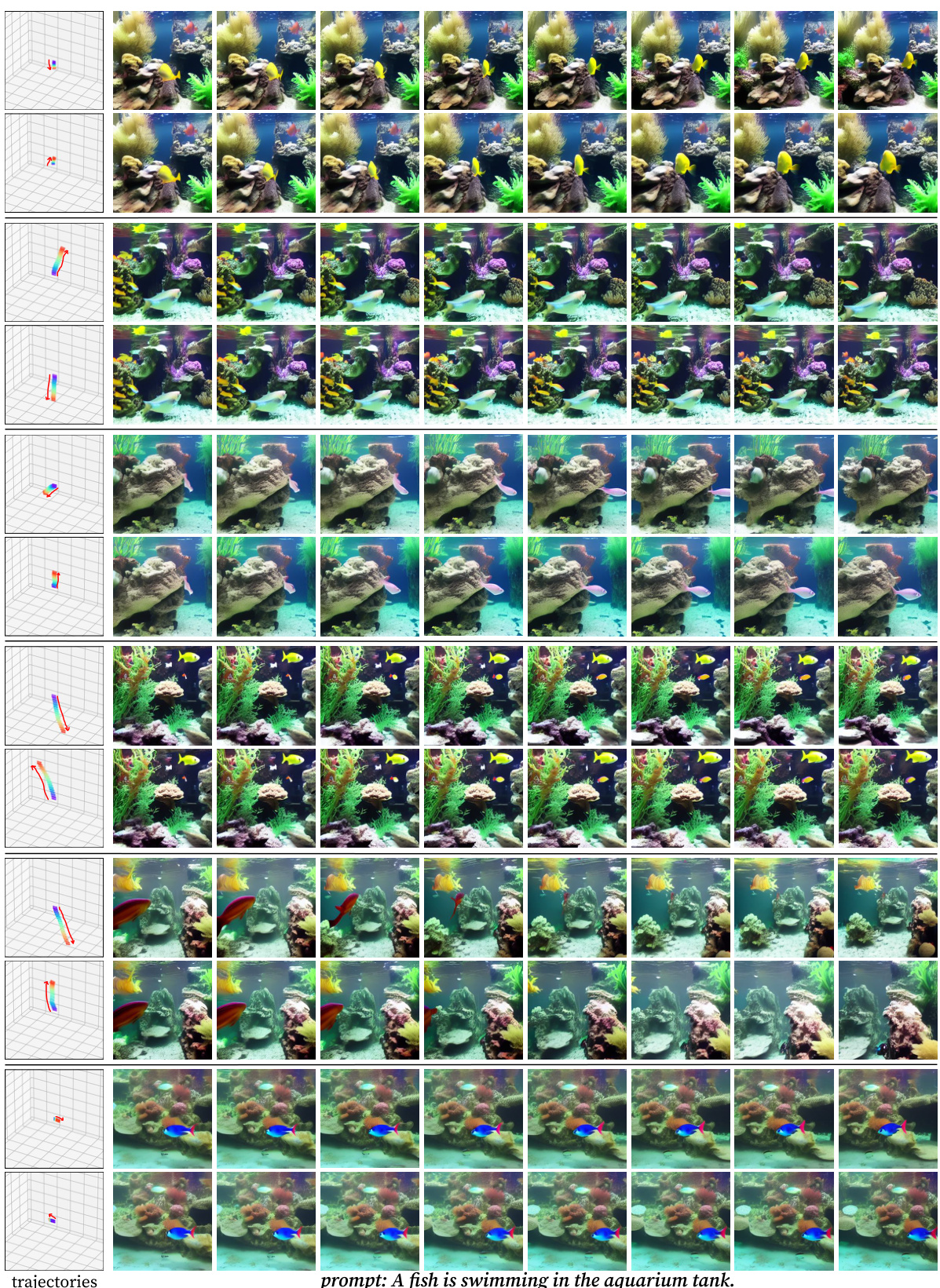
This figure shows several sets of videos generated using different camera trajectories. Each set contains multiple videos, all sharing the same scene and content, but viewed from different angles and perspectives. The consistency of the generated videos across different viewpoints demonstrates the effectiveness of the proposed CVD method in generating coherent multi-view video content.
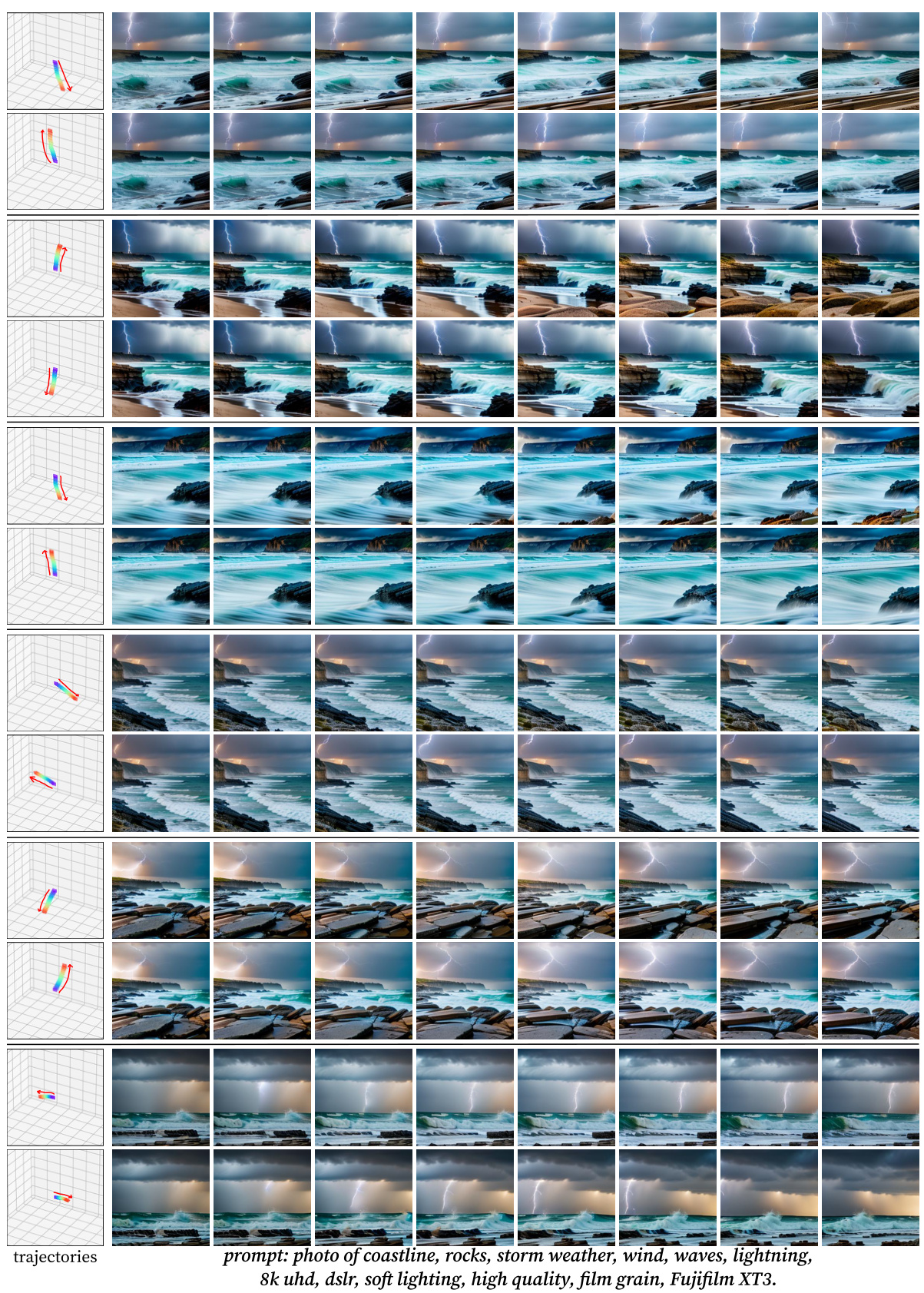
This figure compares the results of the proposed CVD model with several baseline methods for generating videos from the same scene with different camera trajectories. The results show that the CVD model produces videos with higher consistency in terms of content and motion, even when compared to baselines that also incorporate camera control. Notably, existing methods struggle to create multiple videos of dynamic scenes from various viewpoints.

This figure illustrates the difference between conventional video generation and collaborative video generation. Conventional methods produce videos independently, leading to inconsistencies in content across different videos. In contrast, collaborative video generation aims to produce videos sharing the same underlying content and motion, ensuring consistency. The figure demonstrates how the authors’ method extends pairwise video generation to create multiple collaborative videos from different camera angles.

This figure shows example video clips from the WebVid10M dataset before and after applying homography transformations. Homography warping is a technique used to transform an image into a new perspective by applying a homography matrix, which represents a projective transformation. In the context of this paper, homography warping is used to augment the WebVid10M dataset by creating additional video pairs for training a model that generates multiple consistent videos from different camera trajectories.
More on tables
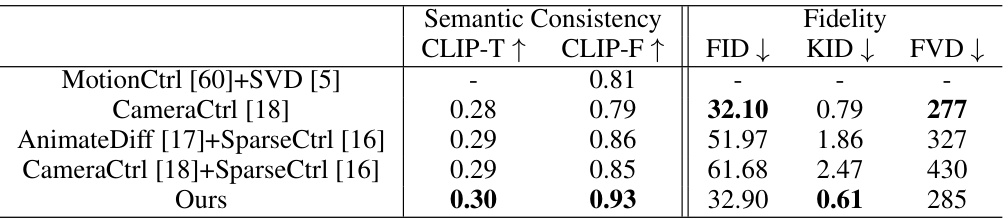
This table presents a quantitative comparison of the proposed CVD model against several baselines across various metrics. The metrics are grouped into two categories: semantic consistency (CLIP-T and CLIP-F) and fidelity (FID, KID, and FVD). CLIP-T measures the similarity between the generated videos and the input text prompts, assessing the semantic consistency of the generated content. CLIP-F evaluates the semantic consistency between video pairs, ensuring that the same scene is depicted in multiple views. FID, KID, and FVD are image quality metrics assessing the visual fidelity of the generated videos. The results show that CVD demonstrates comparable or superior performance to the baselines in terms of both semantic consistency and visual fidelity.
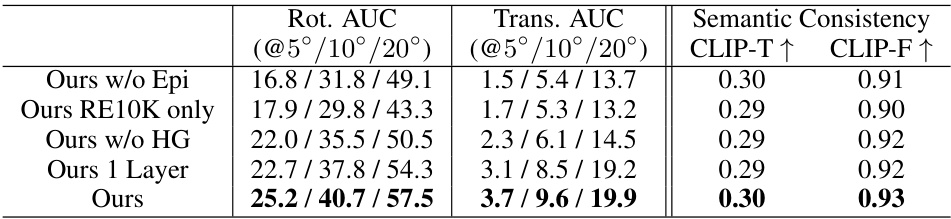
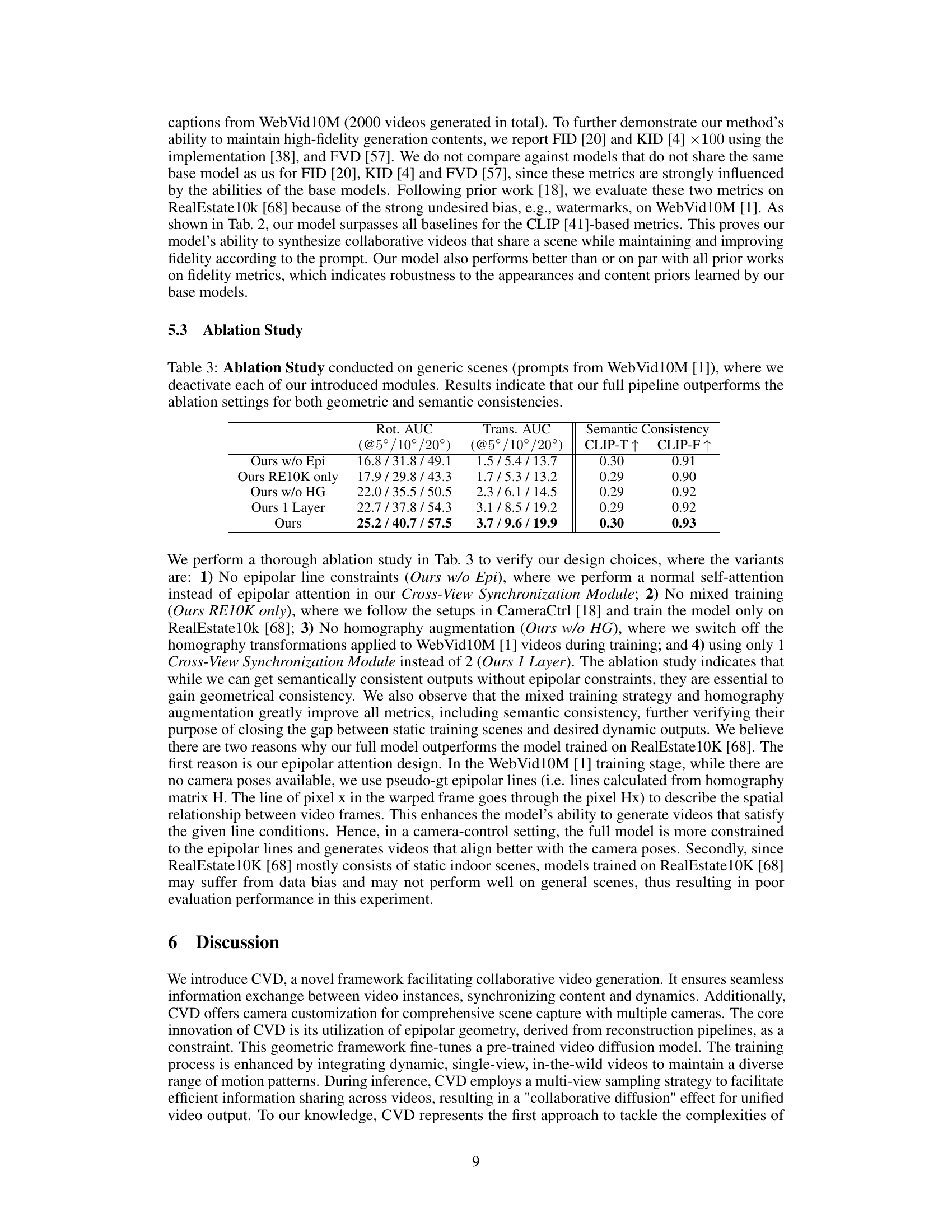
This table presents the results of an ablation study conducted to evaluate the contribution of different modules in the proposed Collaborative Video Diffusion (CVD) model. The study focuses on generic scenes using prompts from the WebVid10M dataset. Several variations of the CVD model were tested, each excluding a specific module, to assess their impact on geometric and semantic consistency. The results demonstrate that the full CVD model, incorporating all modules, achieves superior performance compared to the ablation variants, highlighting the importance of each component for optimal results.
Full paper#