↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Open-vocabulary semantic segmentation is crucial for image understanding, but existing methods rely on large, expensive-to-acquire datasets with pixel-level semantic labels. This makes scaling such models challenging. The problem is exacerbated by the fact that vision-language models like CLIP excel at identifying objects in images, but struggle with pixel-level recognition. This paper aims to address these shortcomings.
PixelCLIP tackles this challenge by using unlabeled images and masks generated from Vision Foundation Models (like SAM and DINO). It employs an online clustering algorithm with learnable class names to create general semantic concepts without relying on semantic labels. PixelCLIP’s novel approach significantly improves upon CLIP’s performance and is competitive with other caption-supervised methods, proving that leveraging readily available image masks is a viable and effective approach to achieving robust open-vocabulary semantic segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and open-vocabulary semantic segmentation. It introduces a novel method, achieving significant performance improvements over existing techniques and paving the way for more effective, label-efficient semantic segmentation models. The use of unlabeled masks and an online clustering algorithm offers new avenues for research, especially in areas dealing with limited datasets and resources. The work directly addresses the challenges of current methods, opening doors for future advancements in the field.
Visual Insights#
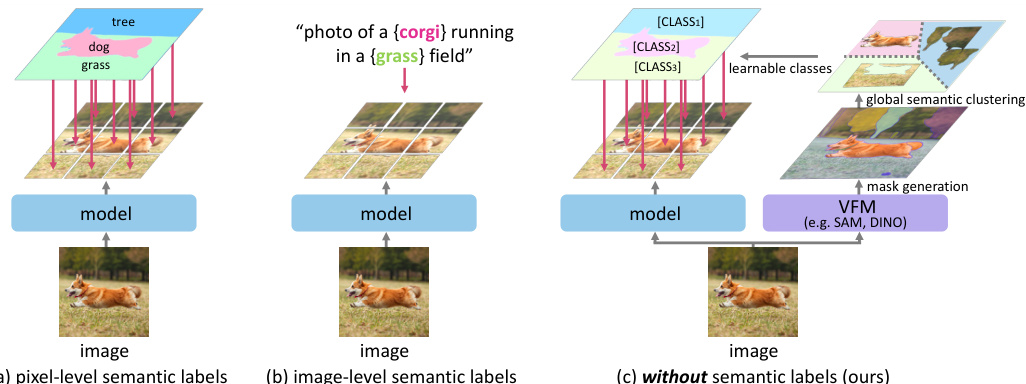
This figure illustrates three different approaches to open-vocabulary semantic segmentation. (a) shows the traditional method using pixel-level semantic labels, which requires extensive manual annotation. (b) demonstrates a less demanding approach utilizing image-level semantic labels (e.g., captions). (c) presents the proposed method, PixelCLIP, which leverages unlabeled masks generated by vision foundation models (like SAM and DINO). These masks, without explicit semantic labels, provide a novel form of supervision for training.
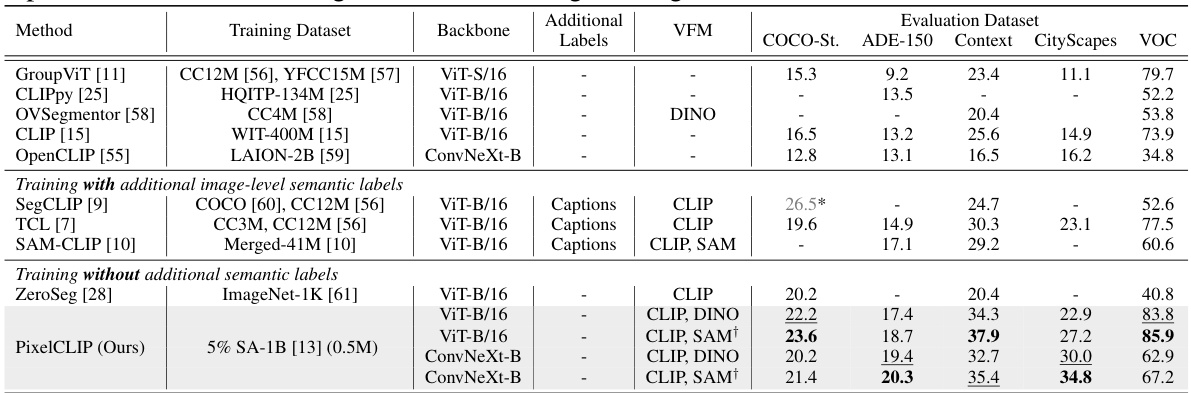
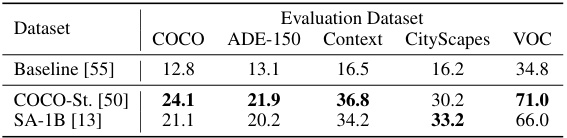
This table quantitatively compares the performance of PixelCLIP with other state-of-the-art open-vocabulary semantic segmentation methods. It shows results on several benchmark datasets (COCO-Stuff, ADE-20K, PASCAL-Context, Cityscapes, and VOC), breaking down the methods by whether they use pixel-level labels, image-level captions, or no labels at all. The table highlights PixelCLIP’s competitive performance even without using pixel-level semantic labels, surpassing some methods that do utilize them.
In-depth insights#
Vision-Language Fusion#
Vision-language fusion is a crucial area in artificial intelligence that aims to bridge the gap between visual and textual information. Effective fusion methods leverage the strengths of both modalities to achieve enhanced performance in tasks like image captioning, visual question answering, and visual grounding. The core challenge lies in developing effective representations and alignment strategies to seamlessly integrate visual features (e.g., from convolutional neural networks) and textual features (e.g., from transformers). Successful approaches often involve multimodal learning paradigms, such as joint training, where vision and language models are trained simultaneously on paired image-text data, or late fusion, where independent visual and textual representations are combined in a downstream task. The choice of fusion method depends on various factors, including task complexity, data availability, and computational resources. Furthermore, attention mechanisms are frequently employed to focus on relevant visual and textual regions, improving alignment and promoting better fusion. A key consideration is handling diverse data types, as visual data can be images, videos, or even 3D point clouds and textual information can range from simple descriptions to rich narratives. Future directions might involve exploring more advanced fusion techniques, enhancing cross-modal interactions, and broadening applications to real-world problems requiring robust and context-aware understanding of both visual and textual cues.
Mask-Guided Training#
Mask-guided training is a powerful technique in deep learning that leverages masks to supervise the learning process. Instead of relying solely on fully annotated images, which can be expensive and time-consuming to obtain, this method uses masks to provide partial supervision. Masks highlight regions of interest, guiding the model to focus on specific areas of the input while ignoring less relevant parts. This approach is particularly effective in scenarios like semantic segmentation where pixel-level accuracy is crucial. By strategically designing masks, for instance, using coarse or fine-grained annotations, the learning process can be adapted to various levels of detail, offering a flexible and efficient training strategy. This helps to address class imbalance issues and improve the overall accuracy of the model. It also allows for semi-supervised learning, which combines labelled and unlabelled data to improve generalization. A key advantage is the ability to create a pipeline where masks can be generated from foundation models, reducing the need for extensive manual annotations, and thus enhancing scalability and cost-effectiveness. The challenge, however, lies in the design of effective masking strategies, as poorly designed masks might hinder, rather than help the training process. The selection of an appropriate foundation model to generate masks is also a factor to consider.
Semantic Clustering#
Semantic clustering, in the context of this research paper, is a crucial technique for enhancing open-vocabulary semantic segmentation. The core idea is to group similar image masks generated by vision foundation models into semantically meaningful clusters. This addresses the over-segmentation issue, where masks are too small or incomplete to have distinct semantic meaning. By clustering masks into broader groups, the model can learn general semantic concepts, avoiding the need for fine-grained, pixel-level semantic labels. The method employs an online clustering algorithm, which is computationally efficient and adapts to new data during training. Crucially, the clusters are defined by learnable class prompts, represented as text features fed into a vision-language model like CLIP. This approach allows the model to acquire general semantic concepts while avoiding the limitations of using image-level supervision alone. The success of semantic clustering hinges on the ability of the online clustering to capture the underlying semantic relationships, allowing for the effective integration of mask-based supervision with CLIP. The use of learnable class prompts ensures the learned clusters capture nuanced and rich semantic information, leading to improved accuracy in semantic segmentation.
Open-Vocab Seg#
Open-vocabulary semantic segmentation, or ‘Open-Vocab Seg’, represents a significant advancement in computer vision, aiming to generalize semantic segmentation beyond predefined classes. Traditional methods require extensive, pixel-level annotations, limiting scalability and hindering broader applicability. Open-Vocab Seg leverages the power of large-scale vision-language models like CLIP, which learn relationships between images and text descriptions. This allows for the classification of pixels into open-ended semantic categories. However, challenges remain in effectively utilizing image-level or weak supervision from unlabeled masks, image captions, or other sources to guide pixel-level classification. Methods often struggle with localization precision due to the nature of weak supervision, hindering accuracy. Future directions should focus on improving the quality of weak supervision, addressing challenges of over-segmentation, exploring more effective training strategies, and investigating new ways to incorporate contextual information. The ultimate goal is to achieve high accuracy in open-vocabulary semantic segmentation without the need for large, annotated datasets.
Future Work#
The paper’s ‘Future Work’ section could explore several promising avenues. Improving the efficiency of the online clustering algorithm is crucial, potentially through exploring more sophisticated clustering techniques or incorporating more advanced prompt engineering methods. Investigating the effect of different vision foundation models (VFMs) beyond SAM and DINO on the overall performance is important, assessing their strengths and weaknesses in mask generation for this specific task. Expanding the application to other modalities, like videos and 3D point clouds, presents a challenge but could significantly broaden the impact. Finally, and critically, a thorough investigation of the model’s biases and limitations arising from the pre-trained vision-language models and the inherent biases in unlabeled data is needed. This would enhance the reliability and fairness of the system in real-world applications.
More visual insights#
More on figures

This figure shows the masks generated by two different vision foundation models, SAM and DINO. The raw masks from each model are shown alongside versions where the masks have been clustered to improve semantic coherence. The goal of the clustering is to group fine-grained masks into larger, more semantically meaningful regions.

This figure illustrates the PixelCLIP framework. It shows how unlabeled images and masks from vision foundation models (like SAM and DINO) are used to guide the CLIP image encoder to perform open-vocabulary semantic segmentation. The process involves online clustering of masks using learnable class prompts, and a momentum encoder is used during training for stability. Inference, however, only utilizes the image and text encoders of CLIP.

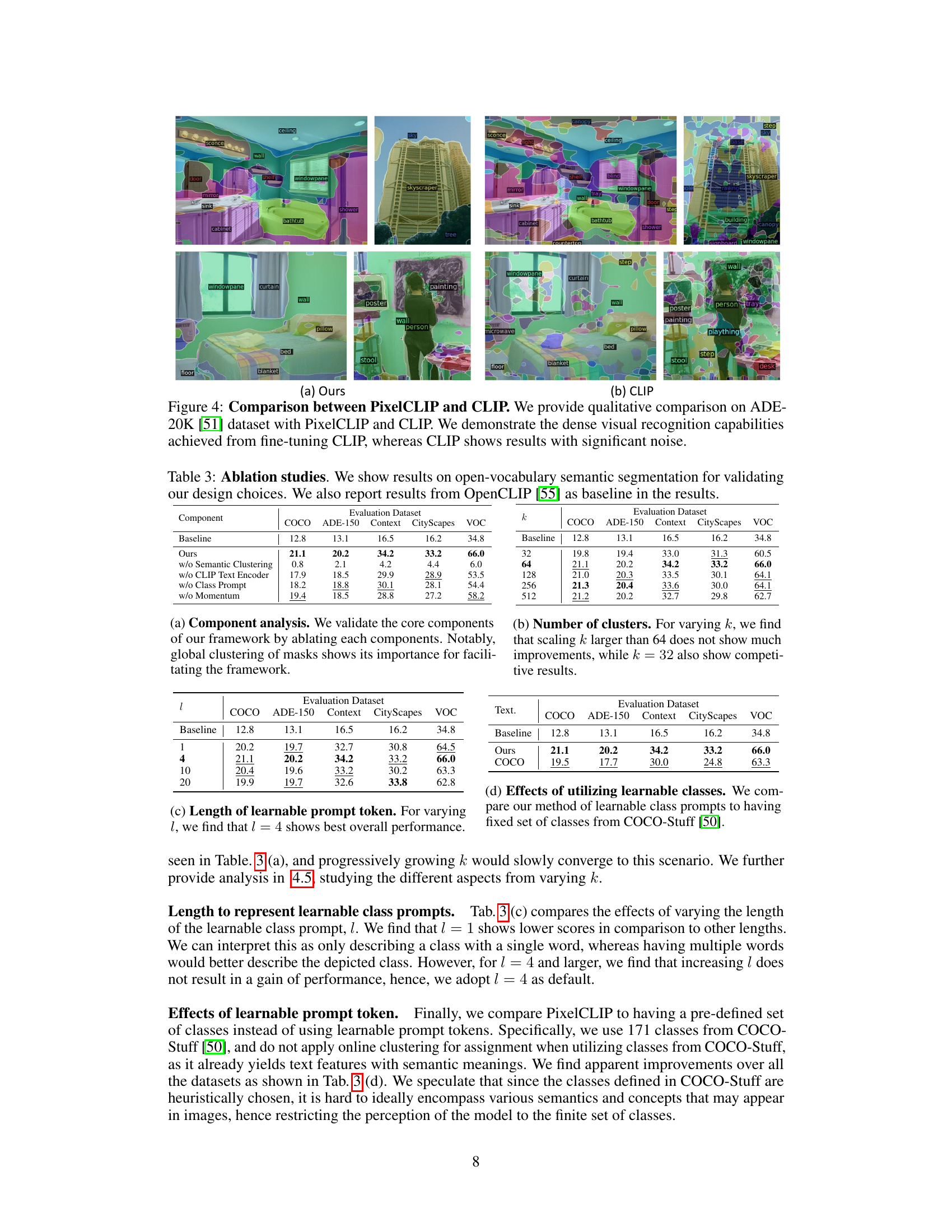
This figure compares the qualitative results of open-vocabulary semantic segmentation on the ADE-20K dataset between PixelCLIP and CLIP. PixelCLIP demonstrates superior performance in recognizing and segmenting objects within the images, while CLIP’s results are noisy and less accurate. The figure highlights the improved visual recognition capabilities of PixelCLIP by showing examples where PixelCLIP successfully segments objects, while CLIP struggles to do so.
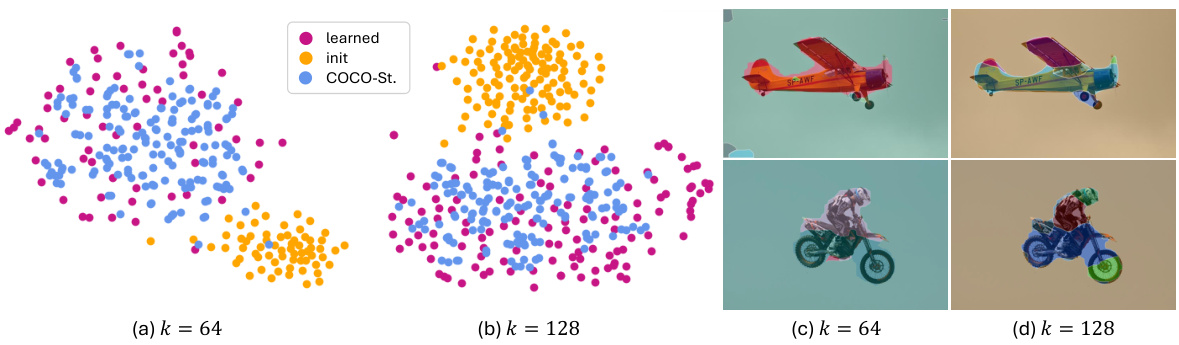
This figure visualizes the learned class prompts’ text features using t-SNE for dimensionality reduction. (a) and (b) compare the learned prompts (purple) to COCO-Stuff class names (orange) for different numbers of clusters (k=64 and k=128). The visualization shows how well the learned prompts capture semantic concepts. (c) and (d) display images generated using the learned class prompts, demonstrating the model’s ability to generate images based on the learned semantic representation.

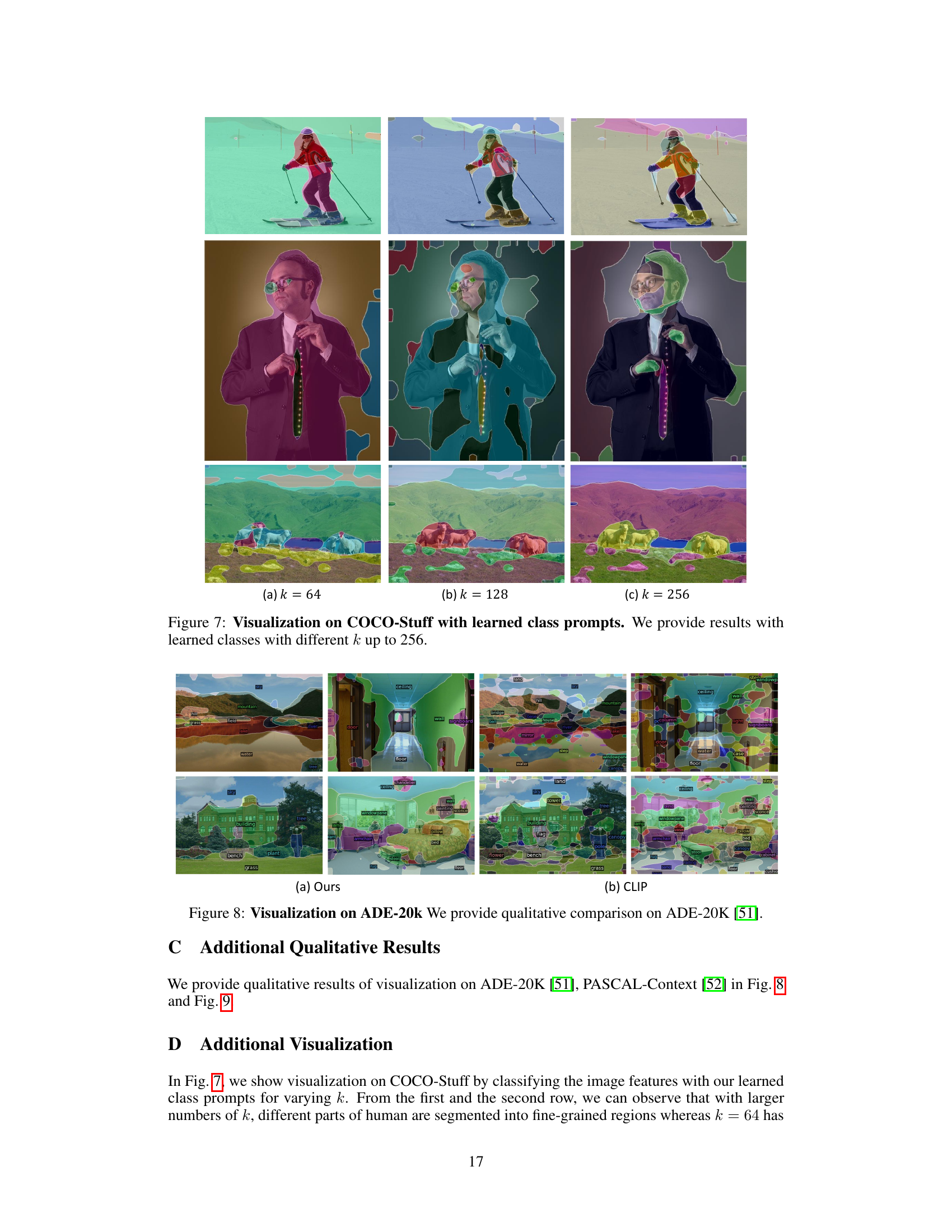
This figure visualizes the results of using learned class prompts to predict semantic segmentation masks. The learned prompts, represented by embeddings, are mapped to the nearest class names from the COCO-Stuff dataset. The images show the predicted masks overlaid on the original image, illustrating how well the learned prompts capture semantic concepts and how the predictions align with the ground truth classes. The comparison between results using 64 and 128 clusters highlights the impact of the number of clusters on the granularity of semantic understanding.

This figure visualizes the results of applying PixelCLIP on the COCO-Stuff dataset with varying numbers of clusters (k). It shows the segmentation masks generated by the model for different values of k (64, 128, and 256). The images demonstrate how the model’s segmentation performance changes as the number of clusters increases. Specifically, it highlights the impact of the online clustering algorithm on the granularity of the segmentation. With a lower k, larger semantic regions are clustered together; a higher k results in more refined segmentation that separates semantically similar regions.

This figure shows a qualitative comparison of the results obtained by PixelCLIP and CLIP on the ADE-20K dataset. PixelCLIP demonstrates significantly improved dense visual recognition capabilities, producing clearer and more accurate segmentations compared to CLIP, which exhibits substantial noise and inaccuracies in its predictions.

This figure shows a qualitative comparison of the results obtained by PixelCLIP and CLIP on the ADE20K dataset. PixelCLIP, by leveraging unlabeled masks and fine-tuning the CLIP image encoder, demonstrates significantly improved dense visual recognition compared to the standard CLIP model, which produces results with considerable noise.
More on tables
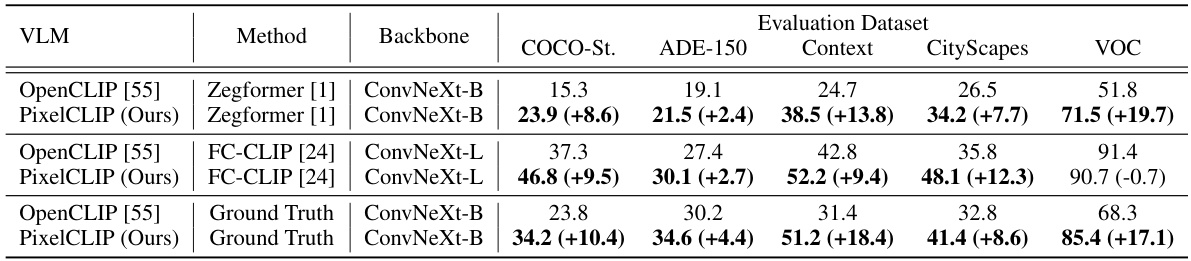
This table compares the performance of PixelCLIP against other methods on zero-shot mask classification. It shows results using both ground truth masks and masks generated by other methods, highlighting PixelCLIP’s ability to perform competitively even without using ground truth data.

This table presents the ablation study results of the PixelCLIP model. It shows the impact of removing key components of the model on the performance of open-vocabulary semantic segmentation. The components ablated include semantic clustering, the CLIP text encoder, learnable class prompts, and the momentum encoder. The baseline results are also given for comparison, using OpenCLIP [55]. Each row shows the mIoU (mean Intersection over Union) scores on several datasets (COCO, ADE-150, Context, Cityscapes, and VOC).
This table presents the ablation study results for the PixelCLIP model. It shows the impact of removing or modifying key components of the model, such as semantic clustering, the CLIP text encoder, learnable class prompts, and the momentum encoder. The baseline results are also provided for comparison using OpenCLIP. The results are evaluated on several standard semantic segmentation datasets and metrics, allowing researchers to understand the contribution of individual components to the model’s overall performance.
This table presents ablation study results on open-vocabulary semantic segmentation. It shows the impact of different components of the PixelCLIP model, such as semantic clustering, the CLIP text encoder, learnable class prompts, and the momentum encoder, on the performance. A baseline using OpenCLIP is also provided for comparison.
This ablation study table presents the results of experiments conducted to validate the design choices made in the PixelCLIP model. It compares the performance of the full PixelCLIP model against versions where key components (semantic clustering, CLIP text encoder, class prompts, and momentum encoder) are removed or modified. A baseline using OpenCLIP is also included for comparison. The results are reported across various evaluation datasets, allowing for a comprehensive assessment of each component’s contribution to the overall performance.

This table presents a quantitative comparison of various methods for open-vocabulary semantic segmentation. It compares the performance of PixelCLIP against other state-of-the-art methods including vision-language models and image-level supervised methods, across various evaluation datasets. The table highlights PixelCLIP’s improvements over existing methods, particularly in scenarios without densely annotated labels. The results show mean Intersection over Union (mIoU) scores for each dataset and method.
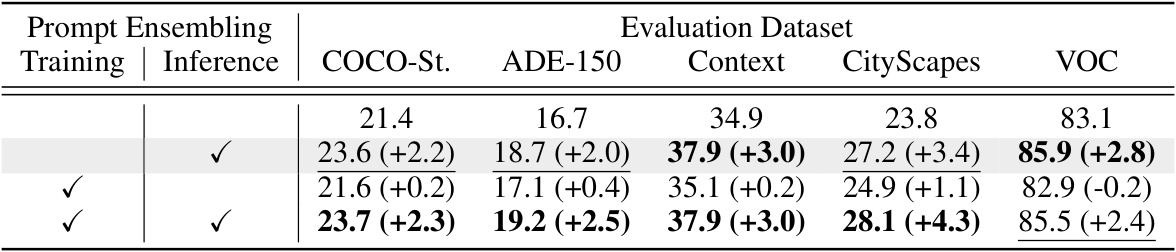
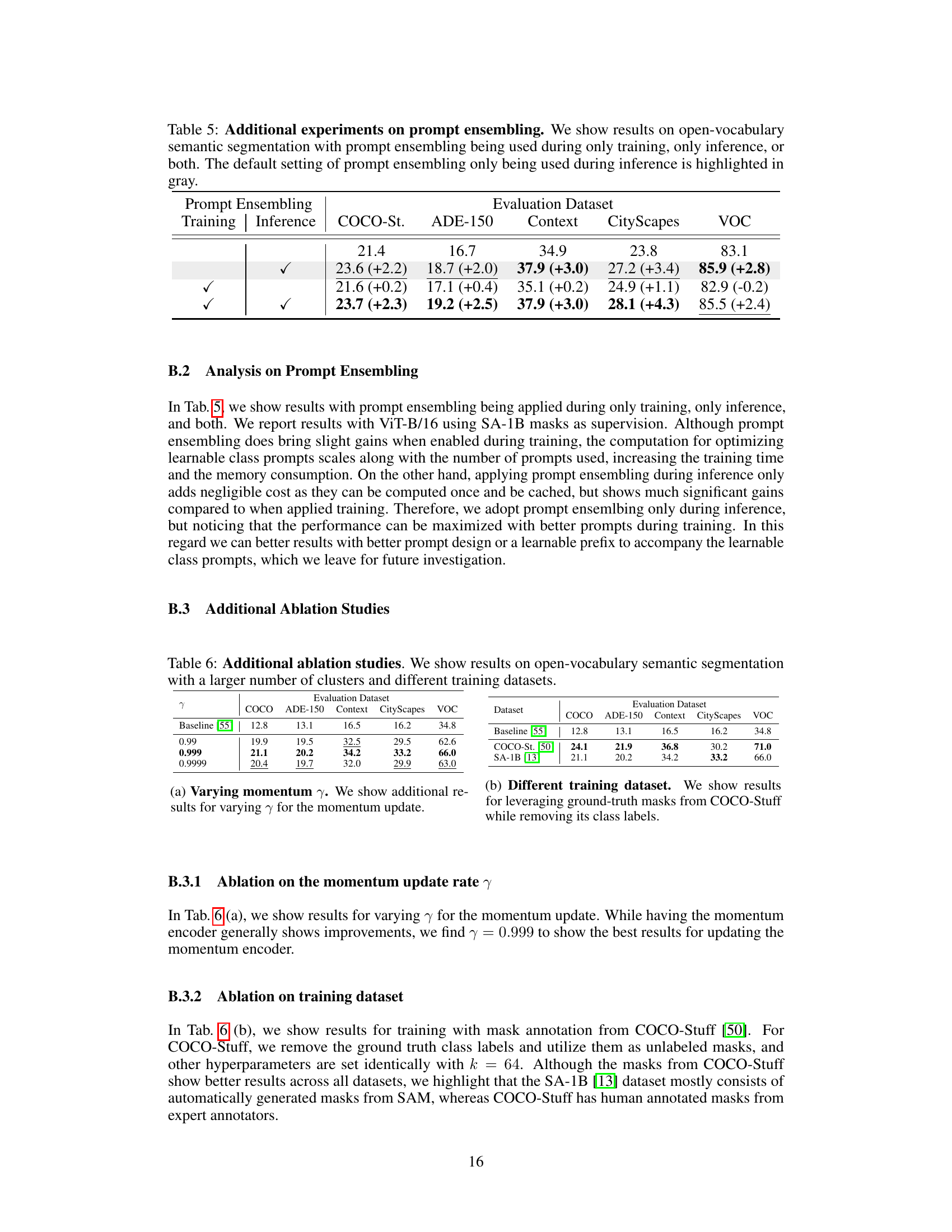
This table presents the results of experiments evaluating the effect of prompt ensembling on open-vocabulary semantic segmentation. Three scenarios are compared: using prompt ensembling during training only, during inference only (the default setting), and during both training and inference. The results are shown across five evaluation datasets (COCO-Stuff, ADE-150, Context, Cityscapes, and VOC) using the mean Intersection over Union (mIoU) metric. The numbers in parentheses represent the change in mIoU compared to the default setting (inference-only).

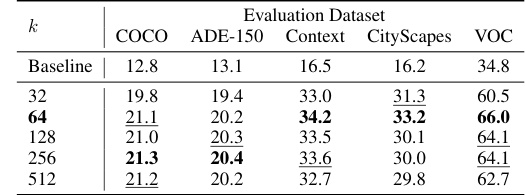
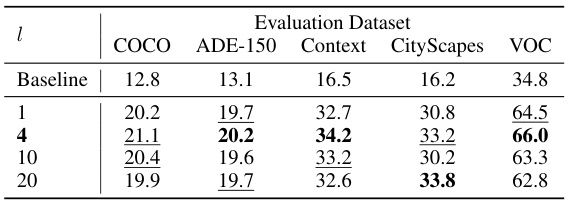
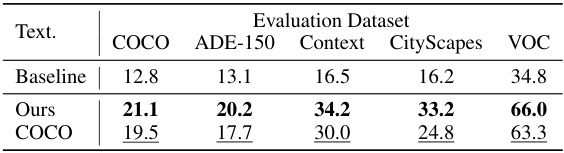
This table presents ablation study results focusing on two key hyperparameters: the momentum update rate (γ) and the number of clusters (k) used in the online clustering algorithm. It shows the impact of these parameters on the performance of PixelCLIP across various datasets (COCO, ADE-150, Context, Cityscapes, and VOC). Different values of γ are tested, along with results obtained using COCO-Stuff dataset instead of SA-1B to evaluate the effect of the training dataset.
This table presents ablation study results focusing on two key aspects: the number of clusters used in the online clustering algorithm and the choice of training dataset. It compares the performance of the PixelCLIP model across different settings. The baseline results are from OpenCLIP [55], and the table shows how changes in the number of clusters (k) and the source of training data (COCO-Stuff vs. SA-1B) impact the model’s performance on several evaluation datasets (COCO, ADE-150, Context, Cityscapes, VOC).
Full paper#