↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing intent learning methods for recommendation systems suffer from complex, cumbersome alternating optimization, limiting performance and scalability. These methods typically involve separate steps for learning user behaviors and clustering latent intents, leading to suboptimal results, especially in large-scale applications. The computational cost and memory consumption of these methods also pose significant challenges.
To address these issues, the paper introduces ELCRec, a novel intent learning model that integrates behavior representation learning and clustering within a unified end-to-end framework. ELCRec employs a learnable clustering module to separate cluster centers (latent intents), improving the model’s scalability and efficiency. Furthermore, an intent-assisted contrastive learning mechanism is proposed to enhance the mutual promotion of behavior representation learning and clustering. Experimental results show that ELCRec outperforms existing methods on several benchmarks, offering significant improvements in NDCG@5 and a notable reduction in computational costs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in recommendation systems because it addresses the scalability and efficiency challenges of existing intent learning methods. Its end-to-end learnable clustering framework offers a novel approach, improving performance and reducing computational costs, paving the way for more effective and scalable recommendation systems, especially in industrial settings with large datasets.
Visual Insights#

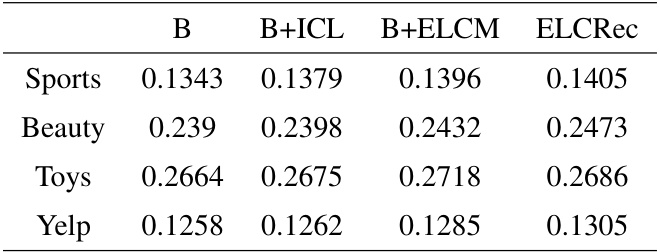
This figure presents the ablation study results for the proposed ELCRec model. Four different model versions are compared: the baseline (B), the baseline with intent-assisted contrastive learning (B+ICL), the baseline with the end-to-end learnable cluster module (B+ELCM), and the full ELCRec model (ELCRec). The y-axis represents the sum of four evaluation metrics (HR@5, HR@20, NDCG@5, and NDCG@20) for each model version. The results are shown separately for four datasets: Sports, Beauty, Toys, and Yelp. The figure demonstrates the individual contributions of ICL and ELCM to the overall performance of the ELCRec model.
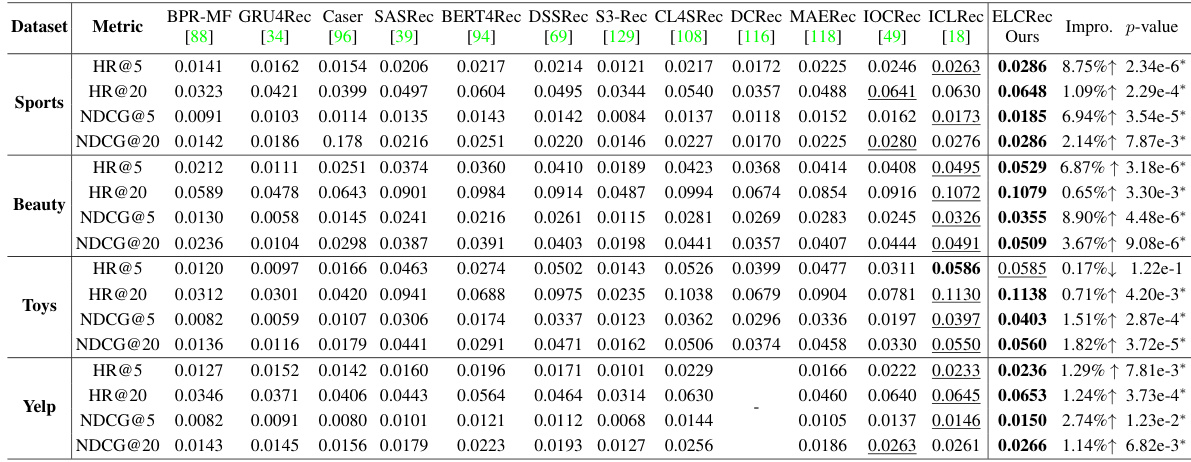
This table presents the performance comparison of the proposed ELCRec model against nine state-of-the-art recommendation baselines across four benchmark datasets (Sports, Beauty, Toys, and Yelp). Metrics used for comparison include HR@5, HR@20, NDCG@5, and NDCG@20. Bold values highlight the best performing method for each metric on each dataset, while underlined values indicate the second-best. The p-value from a t-test is provided to show statistical significance of improvements. A hyphen indicates that a particular model failed to converge during training.
In-depth insights#
ELCRec Framework#
The ELCRec framework introduces a novel approach to intent learning in recommendation systems by unifying behavior representation learning and clustering within an end-to-end learnable structure. Its core innovation lies in treating latent intents as learnable cluster centers (neurons), enabling simultaneous optimization of recommendation and clustering. This eliminates the cumbersome alternating optimization of traditional EM-based methods, enhancing both efficiency and scalability. A key component is the learnable clustering module, which effectively disentangles complex user intents into simpler units. Furthermore, intent-assisted contrastive learning leverages cluster centers as self-supervision signals, strengthening the interplay between representation learning and clustering. This unified framework results in a more effective and efficient recommendation system, particularly beneficial for large-scale applications, as demonstrated by its successful deployment in an industrial setting with millions of page views.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, this involves progressively simplifying the model and observing the impact on performance metrics. A well-designed ablation study helps establish the importance of each component, isolating the effects of individual parts rather than evaluating the system as a whole. The findings reveal which parts significantly enhance performance and which ones are less crucial or even detrimental. By observing the performance degradation after removing specific components, researchers can demonstrate the effectiveness and necessity of their proposed model’s design choices. It’s a powerful technique for clarifying the underlying mechanisms contributing to overall model success. Furthermore, ablation studies enhance the credibility and transparency of the presented model, allowing readers to understand its functionality better and to evaluate its components individually. Without these studies, claims about the impact of a model’s features could be unsubstantiated.
Scalability & Efficiency#
The research paper emphasizes scalability and efficiency as crucial aspects of its proposed ELCRec model for intent learning in recommendation systems. Existing methods often suffer from computationally expensive alternating optimization, limiting their applicability to large-scale datasets. In contrast, ELCRec addresses this by employing an end-to-end learnable clustering framework. This approach unifies behavior representation learning and clustering optimization, enabling simultaneous training and significantly reducing computational costs. The model’s scalability is further enhanced by a novel online clustering module that updates cluster centers incrementally using mini-batch data, eliminating the need for processing the entire dataset at once. The intent-assisted contrastive learning component also contributes to efficiency by leveraging cluster centers as self-supervision signals, thus improving representation learning and recommendation accuracy simultaneously. Experimental results demonstrate the superiority of ELCRec’s efficiency and scalability compared to existing methods, highlighting its ability to handle large-scale datasets effectively.
Real-world Impact#
The research paper’s real-world impact centers on enhancing recommendation systems. The proposed ELCRec model directly addresses the scalability and efficiency limitations of existing intent learning methods, making it suitable for real-world applications with massive datasets. Deployment in a production system with 130 million page views demonstrates practical applicability, showing improved NDCG@5 and reduced computational costs. This signifies a tangible improvement over existing systems, especially in high-volume scenarios where fast, accurate recommendations are critical. The emphasis on efficient online clustering and end-to-end learning is key to this success, enabling better real-time responses and adaption to evolving user behavior. Further, the method’s versatility across diverse recommendation domains—movies and news—highlights its broader applicability and potential for generalized use. The focus on overcoming cold-start problems by incorporating user activity features underscores its value in scenarios with sparse data, representing a significant contribution to recommendation systems technology and its practical implementation.
Future Directions#
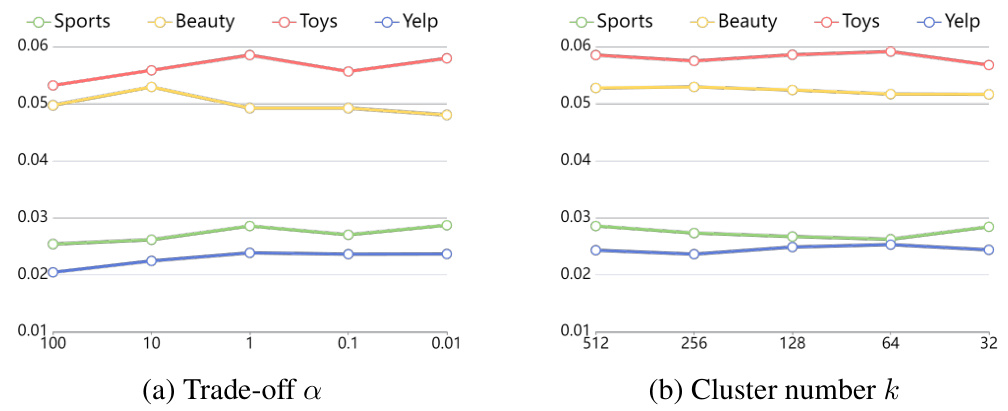
Future research could explore adaptive cluster number determination, moving beyond pre-defined k values to allow the model to dynamically adjust to varying data densities and user intent complexity. Another promising avenue is enhancing the model’s robustness to concept drift, enabling it to handle evolving user preferences and real-time changes in behavior patterns. This might involve incorporating techniques like online learning or incremental clustering. Investigating the impact of various data augmentation strategies on model performance and robustness is also warranted. A deeper analysis of the theoretical underpinnings of the proposed methods, particularly focusing on convergence properties and generalization bounds, would strengthen the paper’s contribution. Finally, expanding the range of real-world applications to diverse recommendation scenarios and conducting more extensive A/B testing on large-scale industrial datasets would establish the approach’s effectiveness in diverse settings.
More visual insights#
More on figures
This figure presents the ablation study results for the proposed ELCRec model, comparing different combinations of the end-to-end learnable cluster module (ELCM) and the intent-assisted contrastive learning (ICL). The y-axis represents the sum of four evaluation metrics (HR@5, HR@20, NDCG@5, NDCG@20), providing a comprehensive performance comparison. The x-axis shows the different model configurations: B (baseline), B+ICL (baseline + ICL), B+ELCM (baseline + ELCM), and ELCRec (baseline + ICL + ELCM). The results across four datasets (Sports, Beauty, Toys, Yelp) visually demonstrate the contribution of each module to the overall model performance.
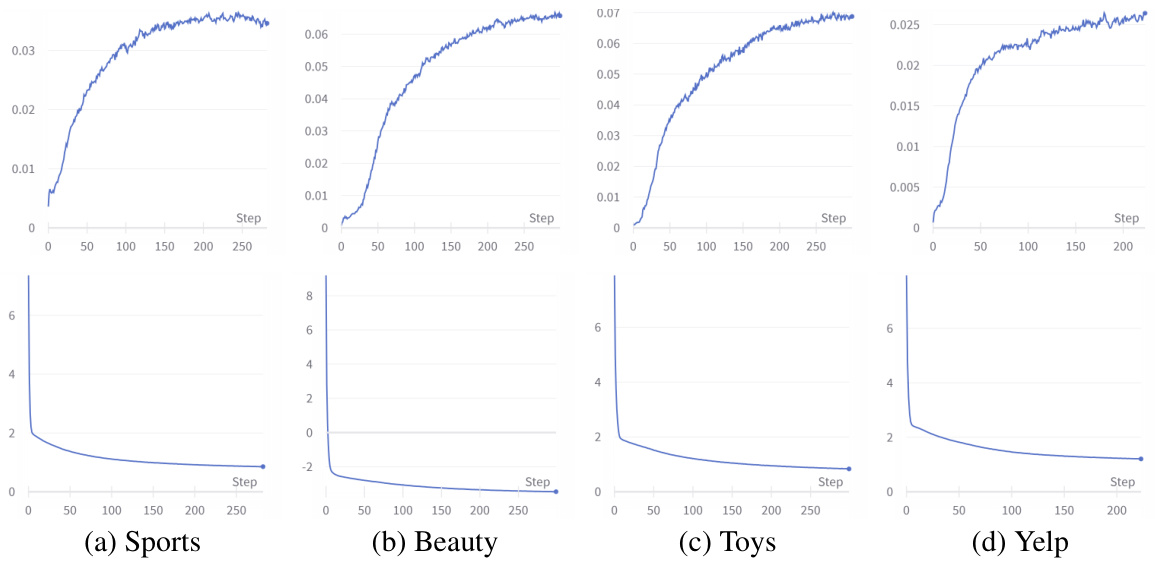
This figure displays the convergence behavior of the ELCRec model during training. The top row presents the HR@5 metric (a measure of recommendation accuracy) on the evaluation dataset across training steps. The bottom row shows the training loss over the same training steps. Each subplot corresponds to one of the four datasets used for evaluation (Sports, Beauty, Toys, and Yelp). The plots demonstrate how both the recommendation performance and the training loss change as the model learns, illustrating the model’s convergence.
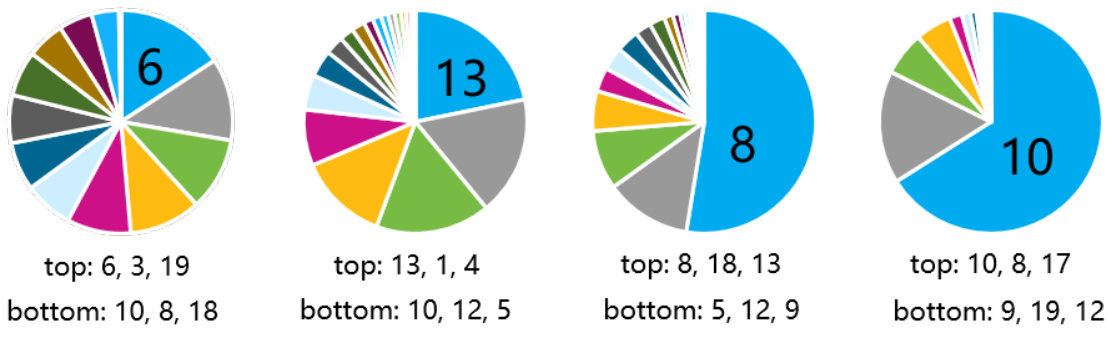
This figure visualizes the cluster distribution of four different user groups: new users, low-activity users, medium-activity users, and high-activity users. For each group, it shows the top three cluster IDs (those with the highest proportions of users in that group) and the bottom three cluster IDs (those with the lowest proportions). The visualization helps to understand how the learned clusters separate users based on their activity levels.

This figure presents the ablation study results for the proposed ELCRec model. It compares four different model variants to demonstrate the effectiveness of the ELCM and ICL modules: (a) Baseline (B): The basic model without any additional modules. (b) Baseline + ICL (B+ICL): The baseline model with only the intent-assisted contrastive learning module. (c) Baseline + ELCM (B+ELCM): The baseline model with only the end-to-end learnable cluster module. (d) ELCRec (B+ELCM+ICL): The complete ELCRec model with both the ICL and ELCM modules. The y-axis represents the sum of four evaluation metrics (HR@5, HR@20, NDCG@5, and NDCG@20) for each model variant. The x-axis represents the different datasets used for evaluation (Sports, Beauty, Toys, and Yelp). The results show the improvement in recommendation performance when adding both ICL and ELCM to the baseline.

This figure presents the ablation study results for the proposed ELCRec model. It compares four variations of the model: the baseline (B), the baseline with intent-assisted contrastive learning (B+ICL), the baseline with the end-to-end learnable cluster module (B+ELCM), and the complete model (ELCRec). The results, shown as the sum of four metrics (HR@5, HR@20, NDCG@5, and NDCG@20) across four different datasets (Sports, Beauty, Toys, and Yelp), demonstrate the effectiveness of both the ELCM and ICL components. Each bar represents a dataset; the height of the bar shows the performance. The comparison shows how each module contributes to the overall improvement.
More on tables

This table presents a comparison of the running time (in seconds) and GPU memory usage (in MB) for both ICLRec and ELCRec across four benchmark datasets (Sports, Beauty, Toys, Yelp). The ‘Improvement’ row indicates the percentage change in running time and memory consumption between ICLRec and ELCRec for each dataset, showing whether ELCRec is more efficient in terms of both time and memory.
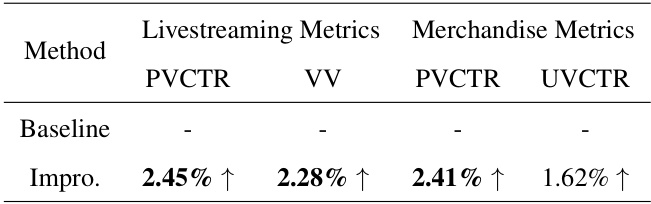
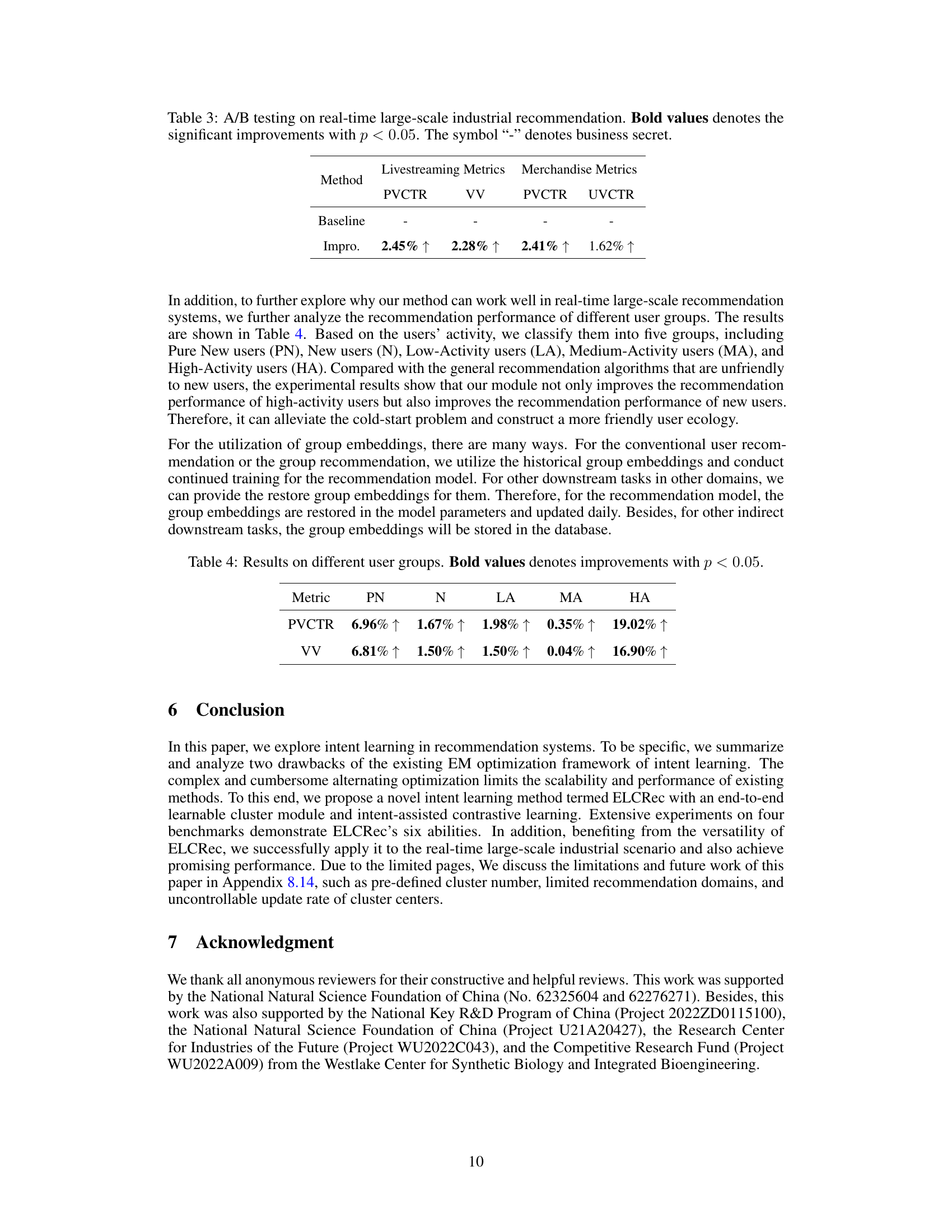
This table presents the results of A/B testing on a real-time, large-scale industrial recommendation system. It compares the performance of a baseline method against the proposed ELCRec method across four key metrics: Page View Click Through Rate (PVCTR) and Video View (VV) for livestreaming metrics, and PVCTR and User View Click Through Rate (UVCTR) for merchandise metrics. Bold values indicate statistically significant improvements (p<0.05) achieved by ELCRec. Hyphens indicate that the data is confidential.

This table presents the results of A/B testing on a real-time large-scale industrial recommendation system. It compares the performance of a baseline method against the proposed ELCRec method, using two key metrics: PVCTR (Page View Click Through Rate) and VV (Video View) for livestreaming metrics, and PVCTR and UVCTR (User View Click Through Rate) for merchandise metrics. Bold values indicate statistically significant improvements (p<0.05) achieved by ELCRec. The ‘-’ symbol represents business-sensitive data that could not be disclosed.

This table presents a comparison of the proposed ELCRec model against nine state-of-the-art recommendation baselines across four benchmark datasets (Sports, Beauty, Toys, and Yelp). For each dataset, multiple evaluation metrics are shown, including Hit Ratio@5 (HR@5), Hit Ratio@20 (HR@20), Normalized Discounted Cumulative Gain@5 (NDCG@5), and NDCG@20. Bold values highlight the best performing method for each metric and dataset, while underlined values indicate the second-best performance. The ‘*’ symbol signifies statistical significance (p<0.05) according to a t-test, meaning the best method significantly outperforms the runner-up. ‘-’ indicates that a model failed to converge during training.

This table presents the performance comparison of different recommendation models on four benchmark datasets (Sports, Beauty, Toys, and Yelp). The metrics used to evaluate the models include HR@5, HR@20, NDCG@5, and NDCG@20. Bold values indicate the best performance for each metric on each dataset, while underlined values represent the second-best performance. The ‘*’ symbol indicates that the best-performing model is statistically significantly better than the second-best model (p < 0.05). ‘-’ signifies that a model failed to converge during training.

This table presents the performance comparison of ELCRec with nine state-of-the-art recommendation methods across four benchmark datasets (Sports, Beauty, Toys, and Yelp). The metrics used for evaluation are HR@5, HR@20, NDCG@5, and NDCG@20. Bold values highlight the best performance for each metric on each dataset, and underlined values indicate the second-best performance. The * symbol shows statistically significant improvements over the runner-up according to a t-test (p < 0.05). A hyphen indicates that the method did not converge.

This table presents the performance comparison between ICLRec and ELCRec on the MovieLens 1M dataset. The metrics used are HR@5, HR@20, NDCG@5, and NDCG@20. Bold values indicate the best performance for each metric, and the * symbol indicates statistical significance (p-value < 0.05). The ‘Impro.’ row shows the percentage improvement of ELCRec over ICLRec, and the final row gives the p-values from the statistical significance test.

This table presents the performance comparison of the proposed ELCRec model against the ICLRec baseline on the MIND-small dataset. The metrics used for comparison are HR@5, HR@20, NDCG@5, and NDCG@20, which are standard measures of ranking quality in recommender systems. Bold values highlight the best results obtained by ELCRec, while the * symbol next to p-values indicates statistical significance (p<0.05), demonstrating that ELCRec’s superior performance is not due to random chance. The ‘Impro.’ row shows the percentage improvement of ELCRec over ICLRec for each metric.
This table presents the performance of various recommendation models on four benchmark datasets (Sports, Beauty, Toys, and Yelp). It compares the proposed ELCRec model against nine state-of-the-art baselines across four metrics: HR@5, HR@20, NDCG@5, and NDCG@20. Bold values highlight the best performance for each metric and dataset, while underlined values indicate the second-best performance. The ‘*’ symbol denotes statistically significant outperformance (p<0.05) of the best model compared to the second-best model. ‘-’ indicates cases where a model failed to converge.

This table presents a comparison of the running time (in seconds) and GPU memory usage (in MB) for three different methods: ICLRec, ELCRec, and S3-Rec. The comparison is done across four different datasets: Sports, Beauty, Toys, and Yelp. Bold values indicate better performance in terms of lower running time and memory usage. The table aims to demonstrate the efficiency gains of the proposed ELCRec method in terms of both time and memory consumption compared to existing approaches.

This table presents the performance comparison of the proposed ELCRec model against nine state-of-the-art recommendation baselines across four benchmark datasets (Sports, Beauty, Toys, and Yelp). The metrics used for comparison are HR@5, HR@20, NDCG@5, and NDCG@20. Bold values highlight the best-performing model for each metric and dataset, while underlined values indicate the second-best performance. The asterisk (*) indicates statistically significant improvements (p<0.05) of the best model over the second-best. A hyphen (-) signifies that the model did not converge.
Full paper#