↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional few-shot learning methods struggle with the limited data available for new tasks, leading to poor generalization. This often requires significant model retraining and fine-tuning, which is computationally expensive. Moreover, these methods often fail to capture the underlying concepts and relationships between different tasks, resulting in limited ability to leverage prior knowledge or synthesize new behaviors.
This paper proposes a new method called FTL-IGM that tackles these issues. FTL-IGM uses a pretrained generative model to learn new task concepts from a small number of demonstrations. By utilizing the invertibility of the generative model, the method can infer the underlying concepts by backpropagation without updating the model’s weights. This is more efficient and leads to better generalization. The experimental results showcase the method’s ability to successfully learn and generate novel task concepts in various domains, including object rearrangement, autonomous driving, and human motion capture, demonstrating its broad applicability and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to few-shot task learning, a crucial area in AI research. Its use of inverse generative modeling offers a potential solution to the data scarcity problem and enables generalization to unseen scenarios. The experimental results across various domains demonstrate its effectiveness and open new avenues for exploring few-shot learning techniques with generative models. The method’s ability to learn new tasks from limited data and compose learned concepts makes it highly relevant for real-world applications. Researchers in robotics, machine learning, and computer vision will find this work particularly insightful.
Visual Insights#
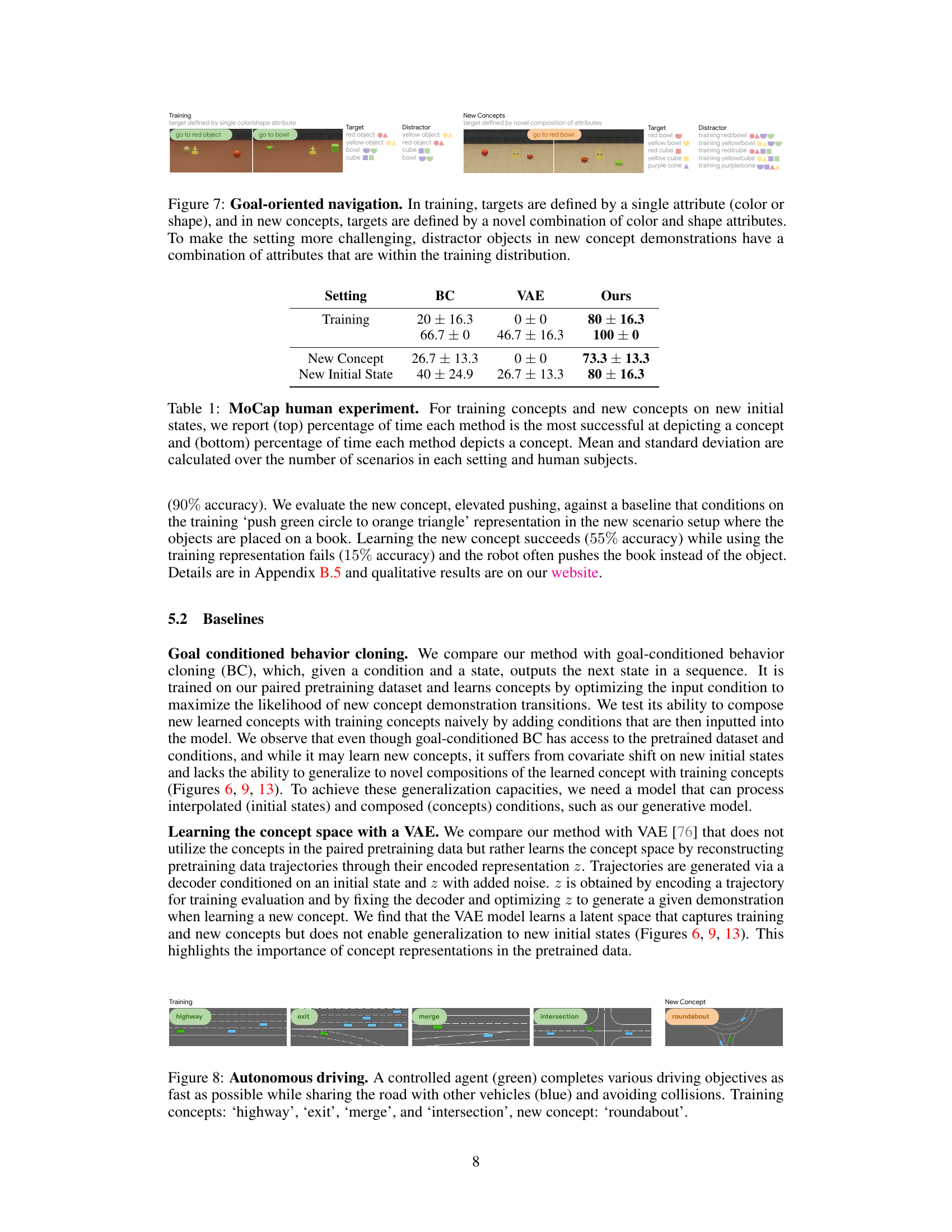
This figure illustrates the two-stage process of the Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM) method. In the pretraining stage, a generative model (Gθ) is trained on paired task demonstrations (T) and their corresponding concept representations (C). This model learns to map concepts to behaviors. In the few-shot learning stage, the pretrained model is frozen, and a new concept (č) is learned by backpropagation. This is done by optimizing the input concept (č) to maximize the likelihood of generating new demonstrations (˜T) of an unseen task.
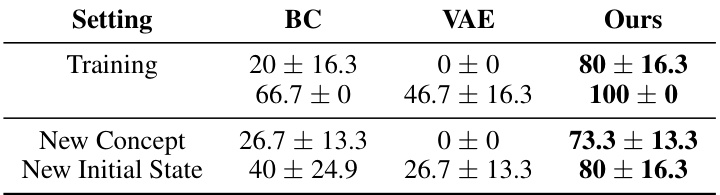
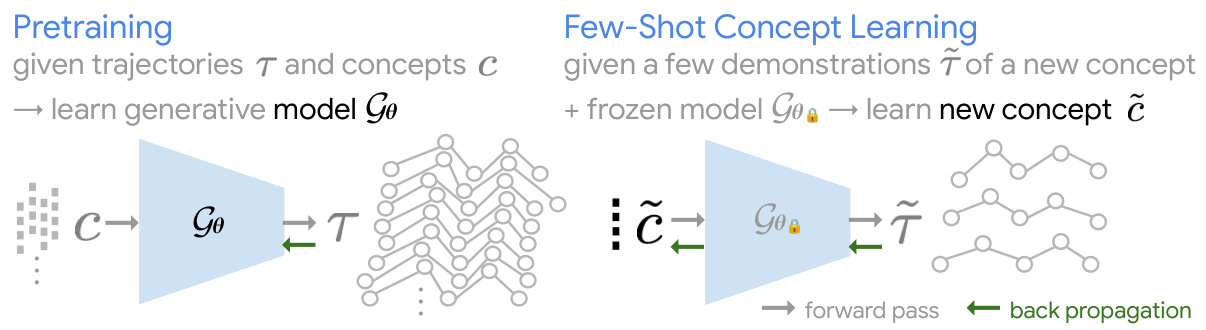
This table presents the results of a human evaluation comparing the performance of different methods (BC, VAE, In-Context, and the proposed FTL-IGM) in generating human motion corresponding to training and novel concepts. The ‘Training’ section shows the success rate of each method in generating the motion concepts used during training. ‘New Concept’ and ‘New Initial State’ evaluate the method’s performance on novel concepts presented with either their standard initial state or a novel initial state. The top row gives the percentage of time the given method had the highest success rate for a given trial. The bottom row presents the average success rate of a method across all trials. Note that a method could depict a concept correctly yet not have the best result if another method had even better results for that same trial.
In-depth insights#
Inverse Generative Models#
Inverse generative models represent a powerful paradigm shift in machine learning, enabling the inference of underlying causes from observed effects. Instead of directly generating data, they learn to invert the generative process, effectively learning a mapping from observations back to latent variables representing the underlying factors. This approach offers several key advantages. First, it allows for efficient few-shot learning by leveraging pre-trained generative models. Second, it enables learning complex, compositional concepts where the underlying factors are themselves combinations of simpler concepts. The ability to disentangle these latent factors enhances interpretability and controllability. However, this methodology presents challenges. The invertibility requirement necessitates carefully designed architectures and training procedures. Furthermore, the performance is critically dependent on the quality and representativeness of the pre-trained generative model. Successfully applying inverse generative models requires careful consideration of these limitations to fully harness their potential in learning complex and nuanced representations.
Few-Shot Learning#
Few-shot learning tackles the challenge of training machine learning models with limited data. It’s particularly valuable when obtaining large labeled datasets is expensive or impossible. The core idea is to enable models to generalize effectively from only a few examples, mimicking human learning capabilities. The paper explores inverse generative modeling as a pathway to few-shot learning, proposing a method (FTL-IGM) that leverages pretrained generative models to learn new task concepts without updating model weights. This is achieved by formulating few-shot learning as an inverse problem, finding the latent concept that best explains the observed demonstrations. This approach is advantageous as it leverages pretrained model priors, making it highly data efficient and robust to overfitting. The paper demonstrates FTL-IGM across multiple domains, showcasing its ability to generate diverse and novel behavior conditioned on learned concepts, even in unseen environments and compositional settings. This highlights the potential for applying generative models to solve the broader problem of efficient concept learning in AI. The success is largely attributed to the generative model’s capacity to capture strong priors and implicit relationships within the data, allowing effective generalization from limited data.
Concept Compositionality#
Concept compositionality, within the context of few-shot task learning, explores the capacity of learned models to generate novel concepts by combining previously learned ones. The core idea is that a model, pretrained on a set of basic concepts, should be able to construct new, more complex concepts without explicit retraining. This is achieved by leveraging the model’s internal representation of these basic concepts; the model infers the representation of a novel concept from a few demonstrations, effectively composing simpler concepts to create a more sophisticated understanding. This approach differs from traditional methods that require extensive retraining for each new concept, showing significant efficiency in learning. Successful concept compositionality implies a level of generalization beyond simple memorization; the model demonstrates understanding of underlying relationships between concepts. However, limitations remain. The success of concept composition heavily relies on the quality and diversity of the pretrained data; if the pretrained concepts do not sufficiently capture the underlying structure of the task domain, composing novel concepts will be challenging. Furthermore, the process of composition itself might be inherently limited; the model may struggle to combine concepts in unexpected or highly complex ways. Future research should focus on improving both the efficiency and robustness of concept composition, potentially incorporating methods to better represent and combine abstract concepts.
Cross-Domain Results#
A hypothetical ‘Cross-Domain Results’ section would analyze whether a model trained on one domain generalizes effectively to others. It would present a comparative analysis of model performance across various tasks. Key aspects to explore are consistency of performance: Does the model maintain similar accuracy levels across different domains? Transferability of learned concepts: Are skills learned in one domain successfully utilized in others? Domain-specific challenges: Are there domains where the model struggles significantly, revealing limitations in transferability and generalization? Finally, comparative analysis with baselines is crucial to demonstrate whether the proposed approach offers any advantages over existing methods in cross-domain scenarios. The discussion should highlight key factors influencing cross-domain performance and potential reasons for observed differences in accuracy or concept transferability across the different domains.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency and scalability of the inverse generative modeling approach is crucial, perhaps through the development of more efficient generative models or the exploration of alternative optimization strategies. Extending the framework to handle more complex tasks and environments, including those with noisy or incomplete observations, presents a significant challenge. Investigating the compositionality of concepts more deeply through a systematic evaluation of the limits of concept combination and decomposition is also needed. Additionally, the development of more robust methods for handling concept drift and unexpected situations would be invaluable, allowing agents to adapt more effectively in dynamic environments. Finally, rigorous theoretical analysis of the method’s convergence properties and generalization capabilities would strengthen the overall contribution.
More visual insights#
More on figures

The figure shows five different domains used to evaluate the proposed Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM) method. These domains are: Object Rearrangement, Navigation to Goal, Motion Capture (MoCap), Autonomous Driving, and Real-world Table-Top Manipulation. Each domain presents unique challenges and requires the agent to learn different types of concepts from limited demonstrations.

This figure illustrates the diverse concept generation capabilities of the proposed FTL-IGM method. It shows how the learned model can generate variations of a new behavior by conditioning on the learned concept representation. The top section demonstrates generation from new initial states, showcasing the model’s ability to generalize to unseen starting points. The bottom section shows the composition of the learned concept with existing concepts from the training data, demonstrating the system’s capability to create novel behaviors by combining learned knowledge.

This figure illustrates the different types of concepts used in the object rearrangement experiments. Training concepts involve simple spatial relationships between two objects (e.g., ‘A is to the right of B’). New concepts are created by combining these basic relationships to form more complex configurations (composition) or introducing entirely new spatial arrangements not seen during training (novel concepts). The diagram visually represents examples of each concept type.

This figure shows a qualitative evaluation of the model’s ability to learn a new concept, ‘square diagonal to triangle’, and to compose this new concept with an existing training concept, ‘circle right of square’. The figure presents a series of object arrangements generated by the model, illustrating the successful composition and generation of novel behaviors based on the learned concepts.

This figure presents a quantitative comparison of the proposed FTL-IGM method against several baselines (BC, VAE, and In-Context) on two different tasks: object rearrangement and goal-oriented navigation. The results showcase FTL-IGM’s ability to generate novel concepts, handle novel compositions of concepts, and generalize to unseen initial states, outperforming the baselines in accuracy. Error bars represent the standard error.

This figure shows examples of driving scenarios used in the autonomous driving experiments. The training scenarios include driving on a highway, exiting a highway, merging onto a highway, and navigating an intersection. The new concept, shown on the far right, involves navigating a roundabout. The green vehicle represents the controlled agent, while blue vehicles represent other traffic. The goal is for the controlled agent to successfully complete each scenario while avoiding collisions.
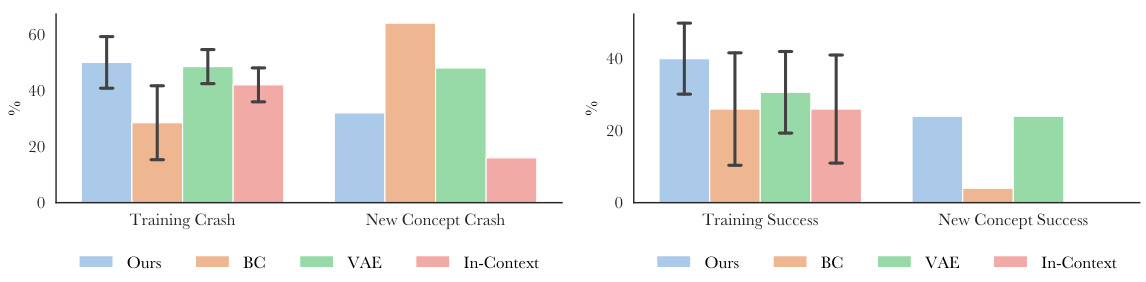
This figure presents a quantitative comparison of the proposed FTL-IGM method against several baselines for few-shot concept learning. The left panel shows results for object rearrangement, while the right panel shows results for the AGENT task. The evaluation metrics assess the accuracy of concept generation across four scenarios: training concepts, novel compositions of training concepts, novel concepts, and new initial states. Error bars represent the standard error, showcasing the performance consistency across different trials. The figure highlights that FTL-IGM achieves competitive performance compared to other baselines, particularly in generating novel concepts and handling new initial states.

This figure shows a real-world robotic manipulation experiment. The left side displays training concepts which include pick-and-place actions on various surfaces (book, table) and push actions on a flat surface. The right side shows a novel concept (pushing an object on an elevated surface—a book). It illustrates the ability of the model to generalize and adapt to new tasks based on its training.
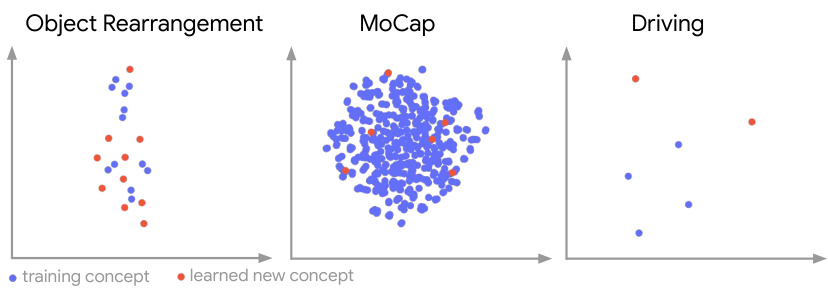
This figure visualizes the t-SNE embeddings of the training concepts and the learned new concept components in three different domains: Object Rearrangement, MoCap, and Driving. The visualization shows how the learned components (red dots) are positioned relative to the training concepts (blue dots). The spatial proximity of the learned components to the training concepts suggests that the model is learning new concepts that build upon or are related to the existing concepts, even when these new concepts are not simply compositions of the training concepts. The interactive version on the website likely provides more specific labels to help clarify the meaning of individual data points within these visualizations.

This figure shows a qualitative evaluation of the model’s ability to learn new concepts that are compositions of existing concepts in the object rearrangement task. The top row displays a successful decomposition where each learned component corresponds to one of the two component concepts. The bottom row shows a case where one component captures both component concepts, demonstrating that the model can achieve more complex compositions than a simple one-to-one mapping.
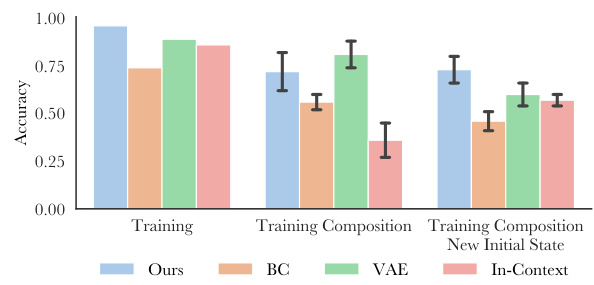
This figure presents a quantitative comparison of the proposed Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM) method against several baselines (BC, VAE, and In-Context) across two different tasks: object rearrangement and goal-oriented navigation. The evaluation metrics assess the accuracy of concept generation for training concepts, novel compositions of training concepts, completely new concepts, and scenarios with new initial states. The results, shown as average accuracy with standard error bars, demonstrate the superior performance of the FTL-IGM method across all scenarios.
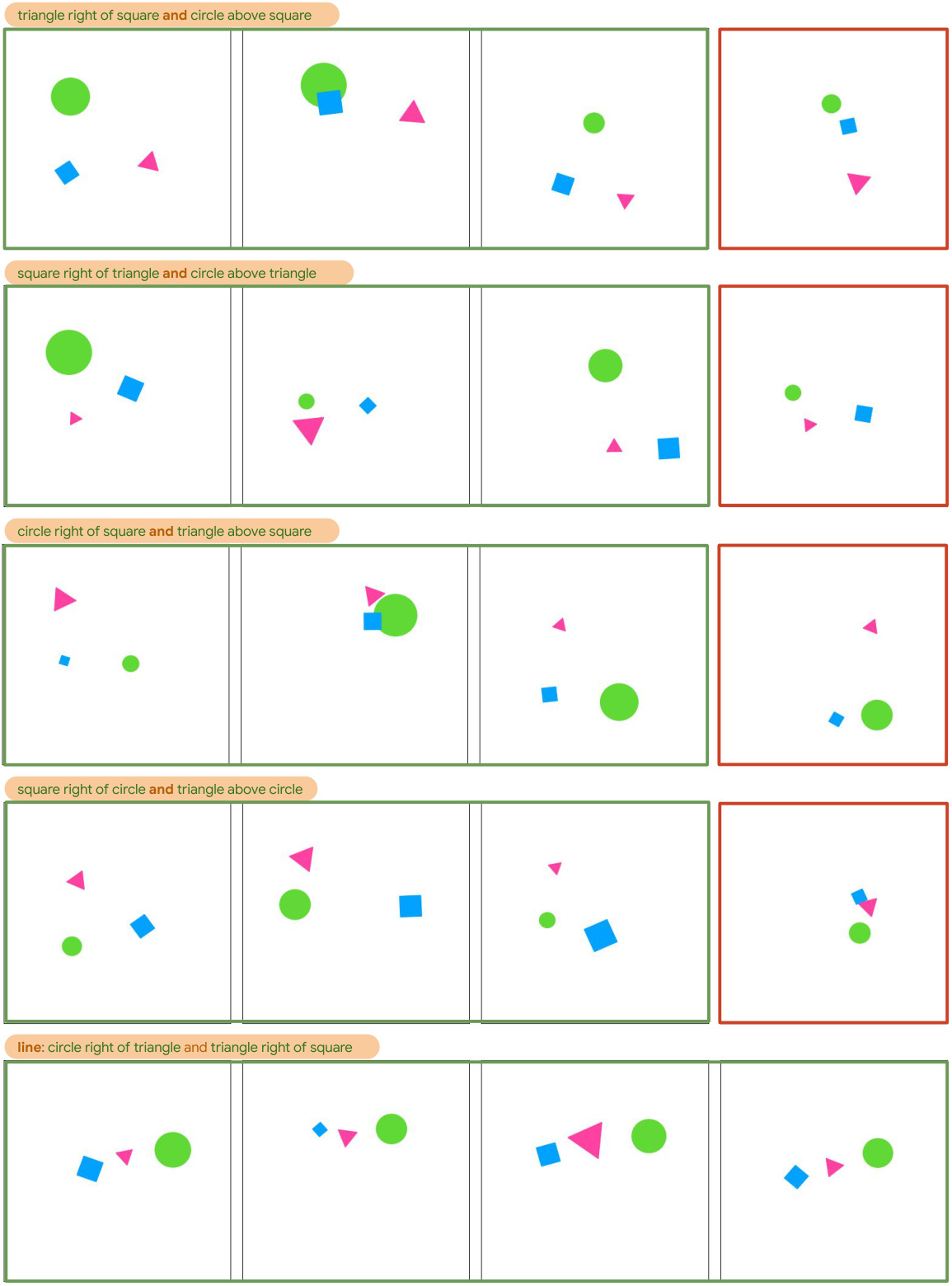
This figure shows examples of object rearrangement scenarios generated by the model. Each row represents a new concept that is actually a combination of training concepts. Green frames indicate successful generations matching the desired concept, while red frames indicate failures. The figure visually demonstrates the model’s ability to synthesize novel behavior by combining previously learned concepts.

This figure shows the results of generating states using a model trained on compositions of training concepts. The model attempts to generate states corresponding to four new concepts that are not simply combinations of the training concepts. Green frames indicate successful generations, while red frames show unsuccessful attempts. This demonstrates the model’s ability to learn new concepts beyond simple combinations of the training data.

This figure demonstrates the model’s ability to generate diverse trajectories by composing a newly learned concept with existing training concepts. The green frames show successful generations where the model successfully combines the new and old concepts. Red frames indicate unsuccessful attempts, highlighting the challenges in seamlessly integrating new and previously learned concepts.
More on tables
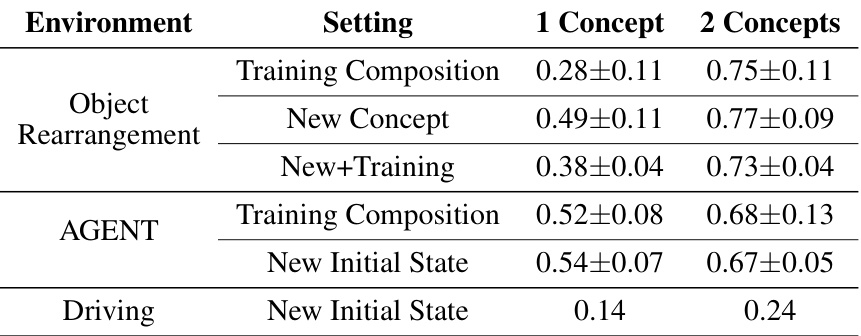
This table presents the results of an ablation study on the number of learned concepts used in the Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM) method. The study compares the performance of the model when learning one concept component versus two, measuring the generation accuracy of new concepts. Results are reported for Object Rearrangement, AGENT, and Driving environments, showing that learning two concept components generally yields higher accuracy. Note that the Driving environment only uses a single new concept in this experiment.
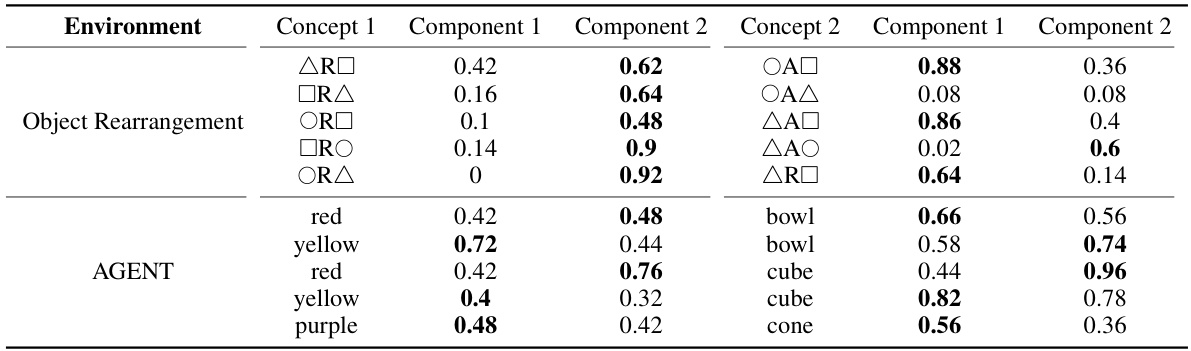
This table analyzes the learned components of new concepts that are compositions of training concepts. For each concept, it shows the accuracy of each learned component in generating trajectories that match the target concept. For example, in the AGENT domain, if a new concept involves a red bowl, the table indicates the percentage of trajectories where the first learned component successfully generated a trajectory targeting the red object and the second component successfully generated a trajectory targeting the bowl object.
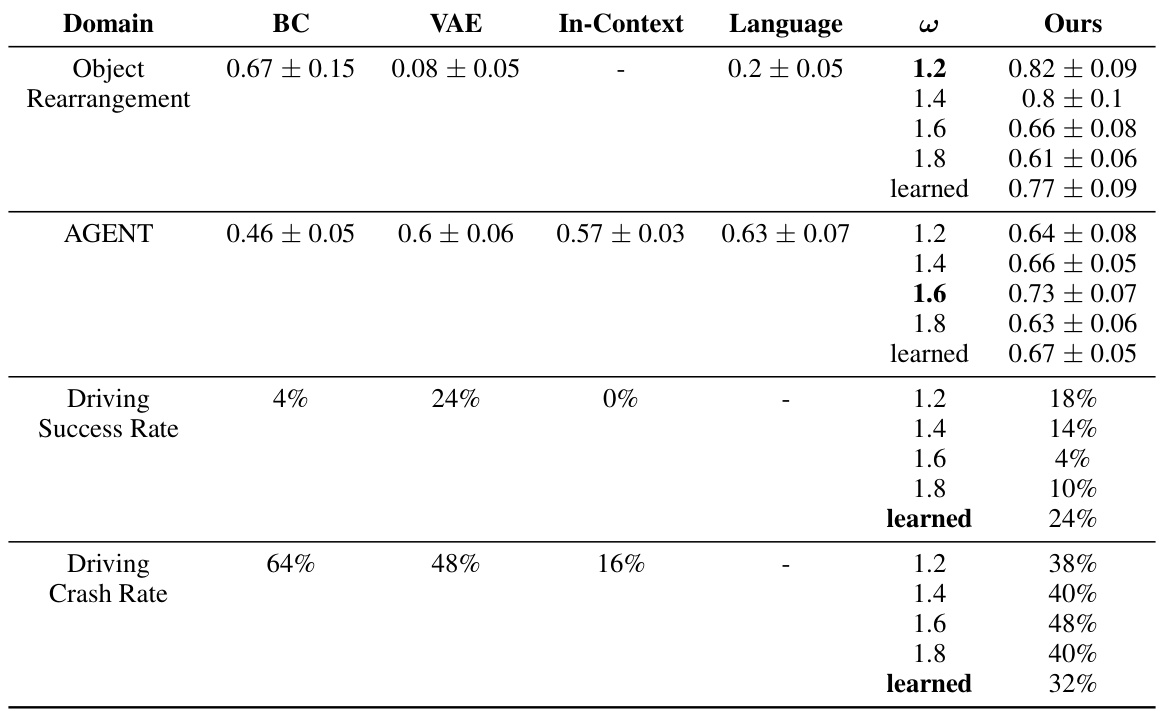
This table shows the effect of different classifier-free guidance weights (w) on the performance of the proposed Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM) method across three different domains: Object Rearrangement, Goal-Oriented Navigation, and Autonomous Driving. It compares the performance of FTL-IGM with various weights to four baselines: Behavior Cloning (BC), Variational Autoencoder (VAE), In-Context learning, and Language-based learning. The results indicate how the choice of the guidance weight affects the accuracy, success rate, and crash rate for each domain. The learned w represents the best weight found during hyperparameter search and reported in the main figures.
Full paper#