↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multiple Object Tracking (MOT) using end-to-end transformer-based trackers faces challenges such as negative interference and poor domain generalization. These issues stem from the trackers learning conflicting scene-specific parameters, requiring costly fine-tuning for new domains. Existing methods often struggle to balance model complexity, computational cost, and generalization ability.
The proposed Parameter-efficient Scenario-specific Tracking Architecture (PASTA) tackles these issues by employing a modular design that uses Parameter-Efficient Fine-Tuning (PEFT) for each scenario attribute (e.g., lighting, viewpoint). This method allows the tracker to generalize to new domains without increasing inference time or requiring extensive fine-tuning. Experiments on various benchmarks showed PASTA’s superior performance over monolithic trackers, demonstrating its effectiveness in achieving both efficiency and accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multiple object tracking (MOT) due to its innovative approach to address the challenges of negative interference and domain generalization in transformer-based trackers. By introducing the Parameter-efficient Scenario-specific Tracking Architecture (PASTA), the research offers a practical solution to improve the efficiency and generalizability of MOT models, paving the way for more robust and versatile applications in various fields like video surveillance and autonomous driving. The modular approach proposed is also significant as it allows for easier adaptation to new scenarios and facilitates future development through the extension of existing modules.
Visual Insights#
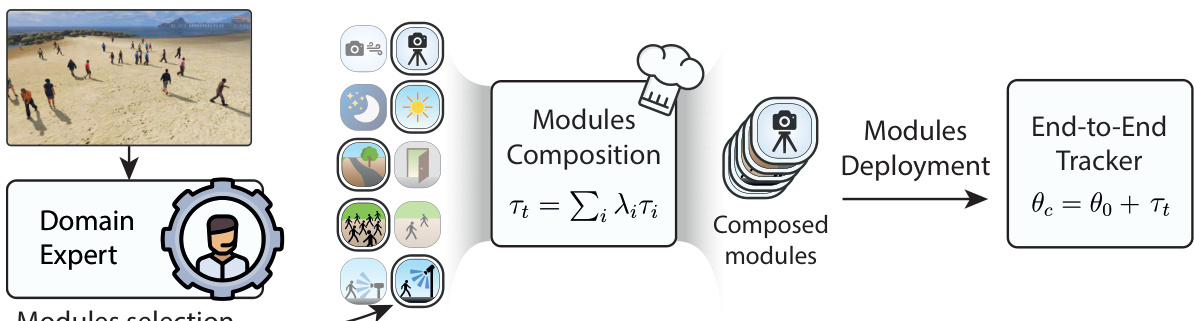
This figure illustrates the PASTA framework’s workflow. First, a ‘Domain Expert’ (either a human operator or an automated system) analyzes the input scene and selects the appropriate modules based on scene attributes like lighting conditions, indoor/outdoor setting etc. These individual modules, pre-trained on specific conditions, are then combined (composed) in the parameter space, which creates a specialized model for that scene. Finally, this combined model is deployed to the end-to-end tracker for processing.
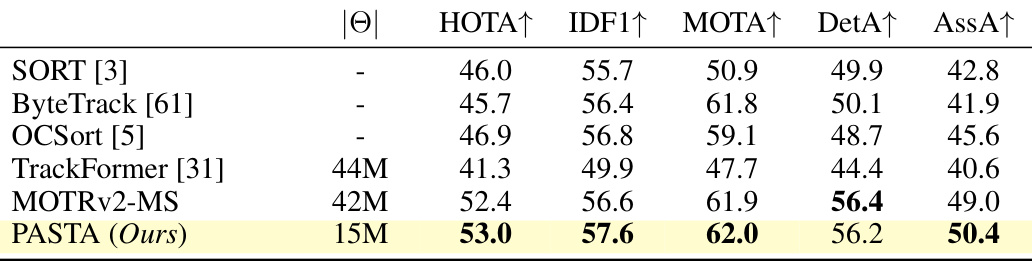
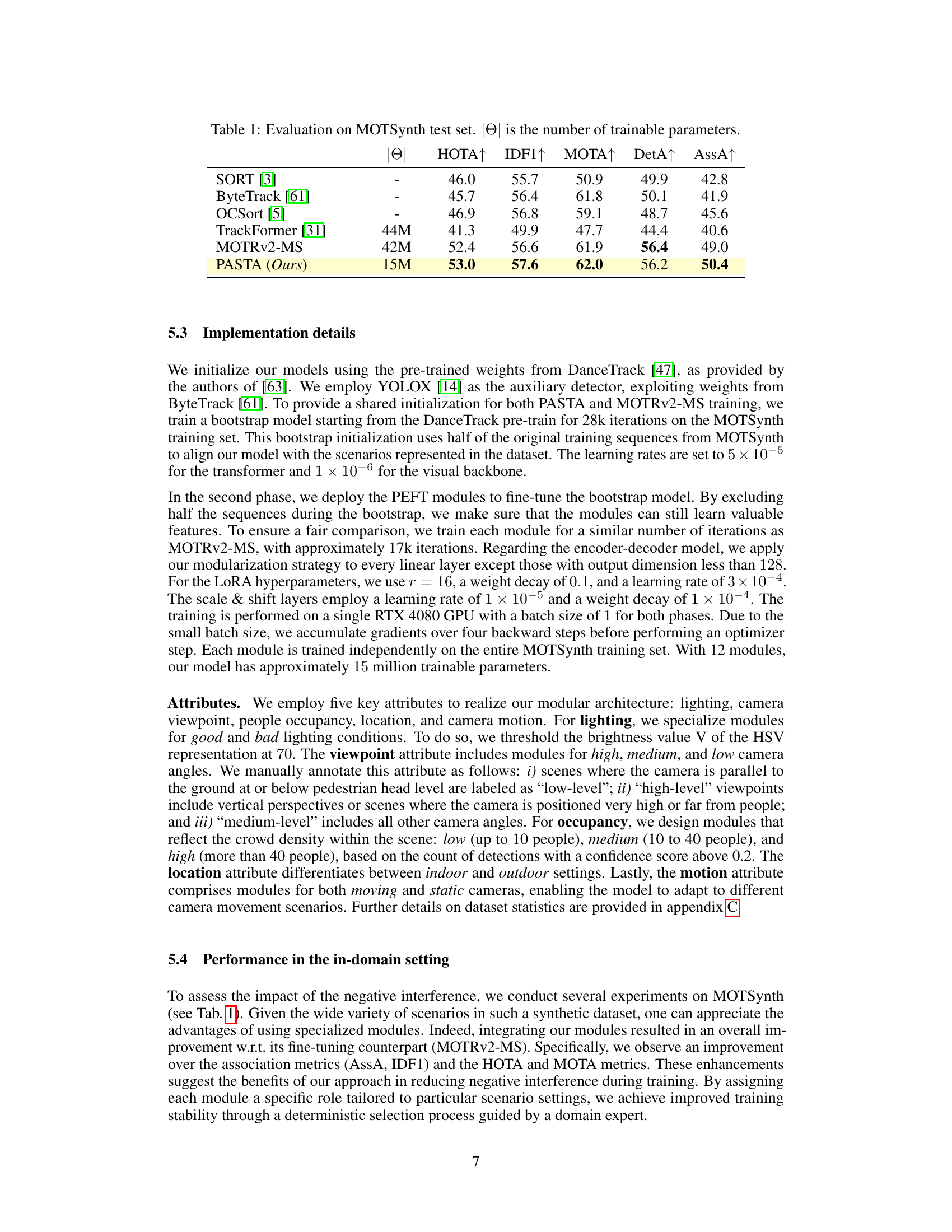
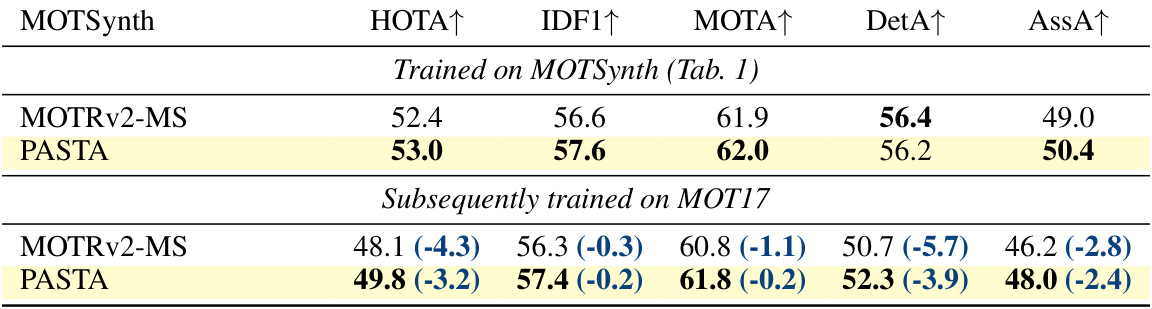
This table presents the performance evaluation results of different multiple object tracking (MOT) methods on the MOTSynth test dataset. The metrics used include HOTA, IDF1, MOTA, DetA, and AssA, which comprehensively assess the accuracy of detection, association, and overall tracking performance. The number of trainable parameters for each method is also provided. The table allows for a comparison of the proposed PASTA method against various state-of-the-art MOT algorithms.
In-depth insights#
Modular Tracking#
Modular tracking presents a compelling paradigm shift in multiple object tracking (MOT), addressing limitations of monolithic, end-to-end approaches. By decomposing the tracker into specialized modules, each handling specific scenario attributes (lighting, viewpoint, occlusion, etc.), it enables parameter-efficient fine-tuning and avoids negative interference. This modularity promotes generalization across diverse domains and facilitates zero-shot adaptation, reducing computational costs and enhancing performance significantly. Key advantages include adaptability to new scenarios by simply combining pre-trained modules and improved robustness due to reduced overfitting. However, challenges remain in automating module selection and addressing potential biases introduced during the training of individual modules. Future research should focus on refining module selection strategies and exploring methods to mitigate these potential biases for enhanced performance and broader applicability.
PEFT for MOT#
Parameter-Efficient Fine-Tuning (PEFT) methods offer a compelling approach to adapt pre-trained models for Multiple Object Tracking (MOT), addressing challenges like dataset scarcity and computational expense. PEFT’s low-rank adaptations, such as LoRA, allow for efficient fine-tuning by only updating a small subset of parameters, significantly reducing computational cost and memory requirements compared to full fine-tuning. This is particularly beneficial for MOT, where training large transformer-based trackers often necessitates substantial resources. However, negative transfer remains a concern when adapting models across diverse scenarios. The effectiveness of PEFT in MOT hinges on careful selection of the attributes to specialize on, and effective strategies to combine specialized modules, potentially employing modular deep learning techniques to mitigate negative interference. Modular PEFT, where separate modules are trained for specific attributes (lighting, viewpoint etc.) and combined at inference, represents a promising avenue. Zero-shot performance evaluation becomes crucial for assessing the generalization capabilities of these specialized PEFT models to unseen scenarios.
Zero-Shot Generalization#
Zero-shot generalization, the ability of a model to perform well on unseen tasks or domains without any specific training on them, is a highly sought-after capability in machine learning. This is particularly important in scenarios where obtaining labeled data for every possible task is impractical or impossible. In the context of multiple object tracking (MOT), zero-shot generalization allows a system trained on one type of visual data (e.g., synthetic data) to successfully track objects in a completely different setting (e.g., real-world videos) without needing to be retrained on that new data. This is achieved by leveraging either transferable features learned during training on the source domain or by employing methods such as modular design, which allows for the combination of specialized modules to adapt to new conditions. Successfully achieving zero-shot generalization in MOT requires careful consideration of factors that affect model transferability, such as the choice of architecture, the training regimen, and the representation of the data. Furthermore, carefully curated synthetic data can play a crucial role in facilitating zero-shot generalization by providing a robust and diverse training base. However, the evaluation of zero-shot performance needs to be rigorous to reflect real-world applicability and to avoid over-optimistic claims.
Domain Adaptation#
Domain adaptation in the context of multiple object tracking (MOT) is a crucial challenge, as models trained on one dataset often fail to generalize to others due to differences in environments, viewpoints, or object appearances. Current methods often struggle with negative interference, where the model learns conflicting parameters. The proposed PASTA framework directly addresses this limitation through a modular design, allowing for efficient learning of scene-specific attributes without negative interference. By training specialized Parameter-Efficient Fine-Tuning (PEFT) modules for key attributes such as lighting, viewpoint, and occupancy, PASTA enables better generalization across different domains. This modularity is a significant advance, showing that disentangling domain-specific knowledge and core pre-training knowledge improves model performance. The approach elegantly addresses the problem of domain shifts, moving beyond expensive fine-tuning. Zero-shot evaluation demonstrates the effectiveness of PASTA’s modular design and its ability to generalize without retraining, clearly highlighting the benefits of a specialized, modular approach to tackling domain adaptation in MOT.
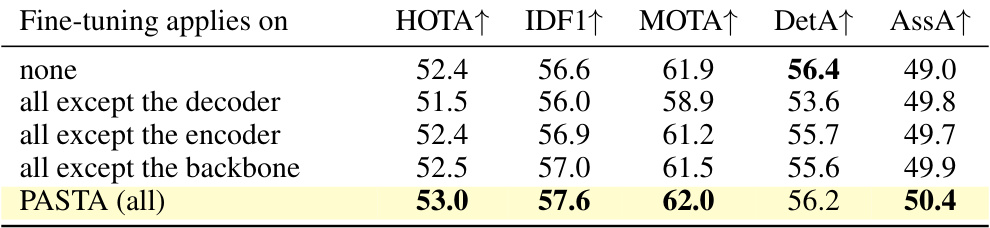
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, it would involve isolating and disabling certain modules (lighting, viewpoint, etc.) within the proposed PASTA architecture, one at a time or in various combinations, to observe the impact on the overall Multiple Object Tracking (MOT) performance. A key focus would be to verify that the modular design doesn’t create negative interference; the performance with multiple modules active should be demonstrably better than using only a single monolithic model. Results would quantify the impact of each module on metrics like HOTA, IDF1, and MOTA, revealing which attributes significantly contribute to accuracy and robustness. Careful analysis would identify if any modules hinder performance and whether any synergistic effects exist among specific module combinations. Such an analysis helps justify the architecture’s design, identify potential redundancies, and potentially refine the model by either improving weaker modules or selectively removing unnecessary ones. The study may further analyze whether modules generalise well across different datasets or domains. Quantifying the degree of zero-shot generalization would be a critical aspect of the ablation studies and confirm the model’s ability to adapt to new, unseen conditions using just the pre-trained modules. In short, a thorough ablation study would solidify the claims regarding improved performance, robustness, and efficiency through the modular design.
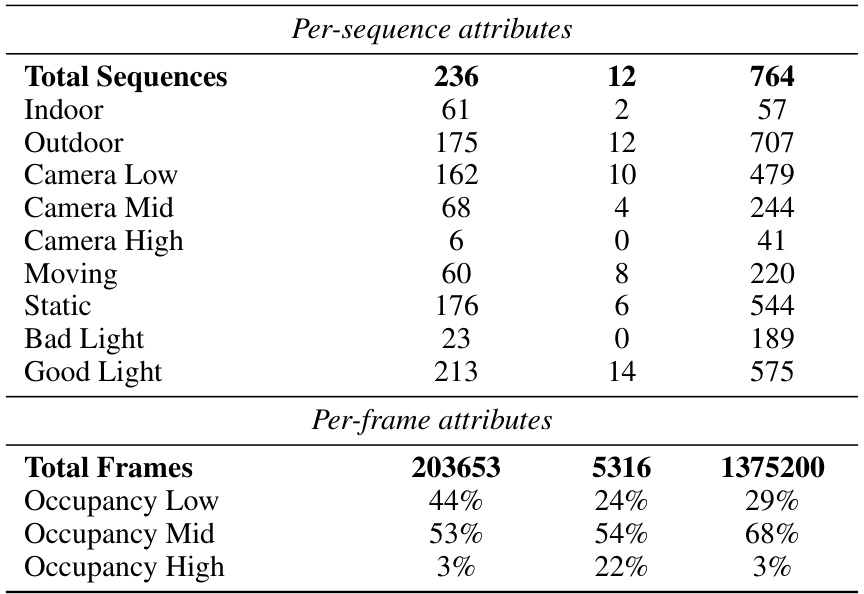
More visual insights#
More on figures
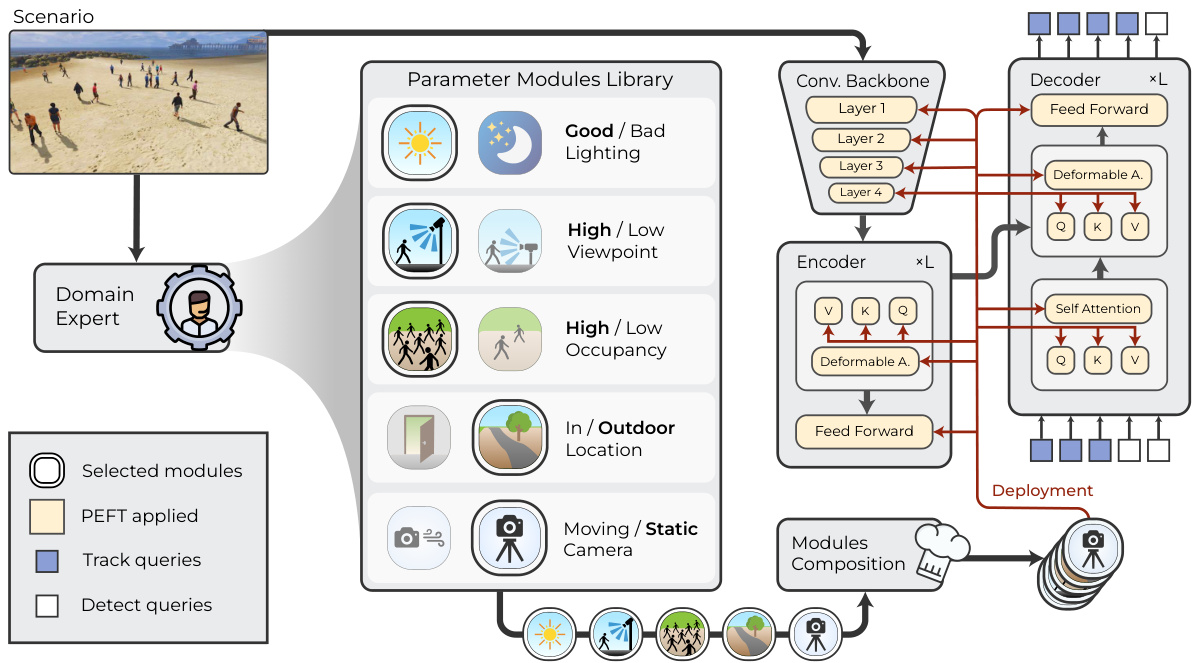
This figure illustrates the PASTA architecture. A domain expert selects pre-trained PEFT (Parameter-Efficient Fine-Tuning) modules based on scene attributes (lighting, viewpoint, occupancy, location, camera movement). These selected modules are then combined in the parameter space, modifying the backbone and encoder-decoder. The process results in a specialized model tailored to the input scene.

This figure illustrates the modular architecture of the proposed PASTA framework. It shows how a domain expert selects pre-trained PEFT (Parameter-Efficient Fine-Tuning) modules based on attributes of the input video sequence (lighting, camera viewpoint, etc.). These selected modules are then composed (combined) and applied to different layers of the backbone and encoder-decoder architecture of the query-based multiple object tracking model. This modular approach allows the model to adapt to different scenarios and domains without requiring extensive retraining.
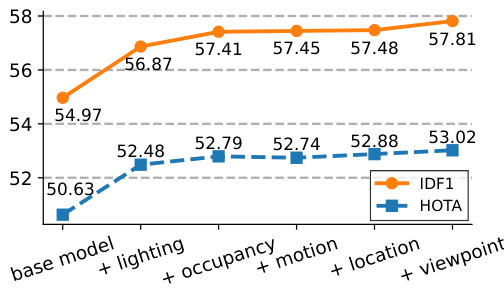
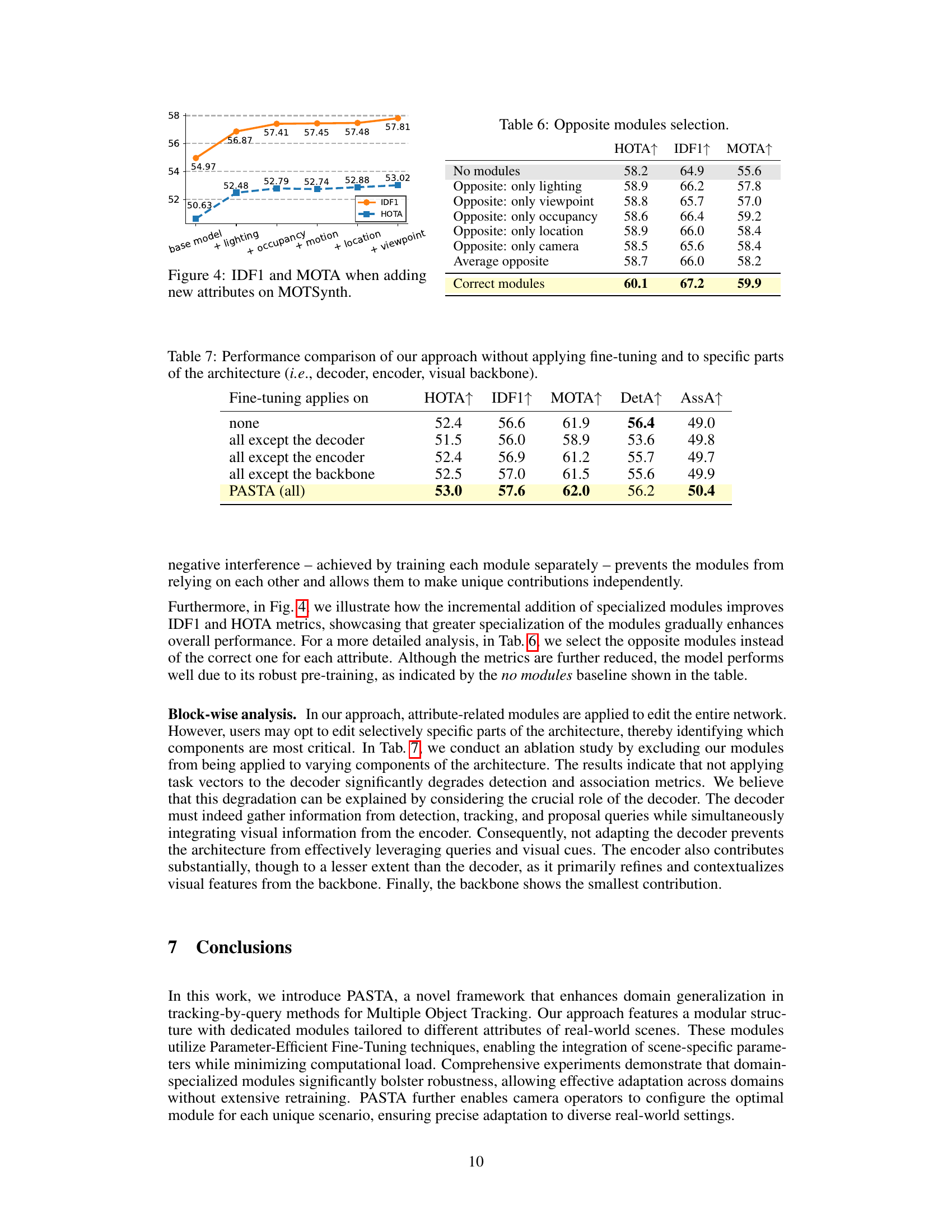
This figure shows the impact of incrementally adding specialized modules on the MOTSynth dataset. The x-axis represents the cumulative addition of attributes (lighting, occupancy, motion, location, viewpoint), and the y-axis represents the IDF1 and HOTA metrics. We observe a clear upward trend in both metrics as more attributes (and modules) are incorporated, demonstrating that a more specialized model (as generated by our modular approach) improves performance.
More on tables
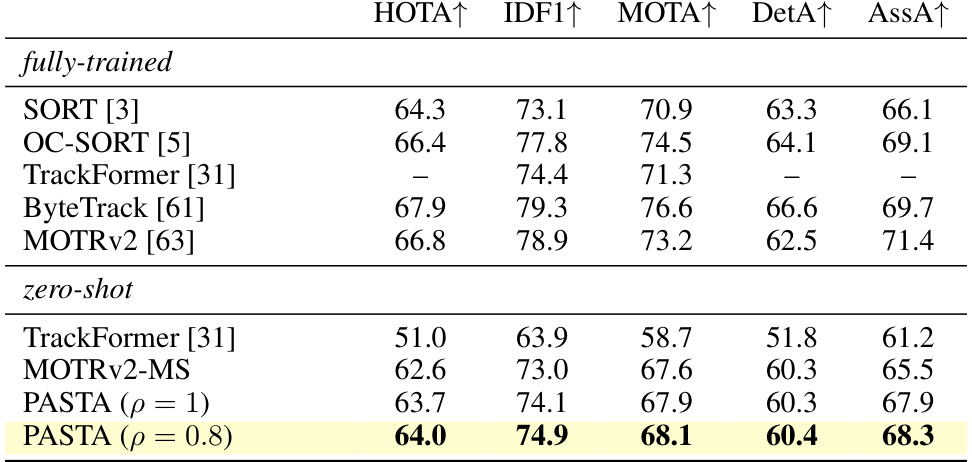
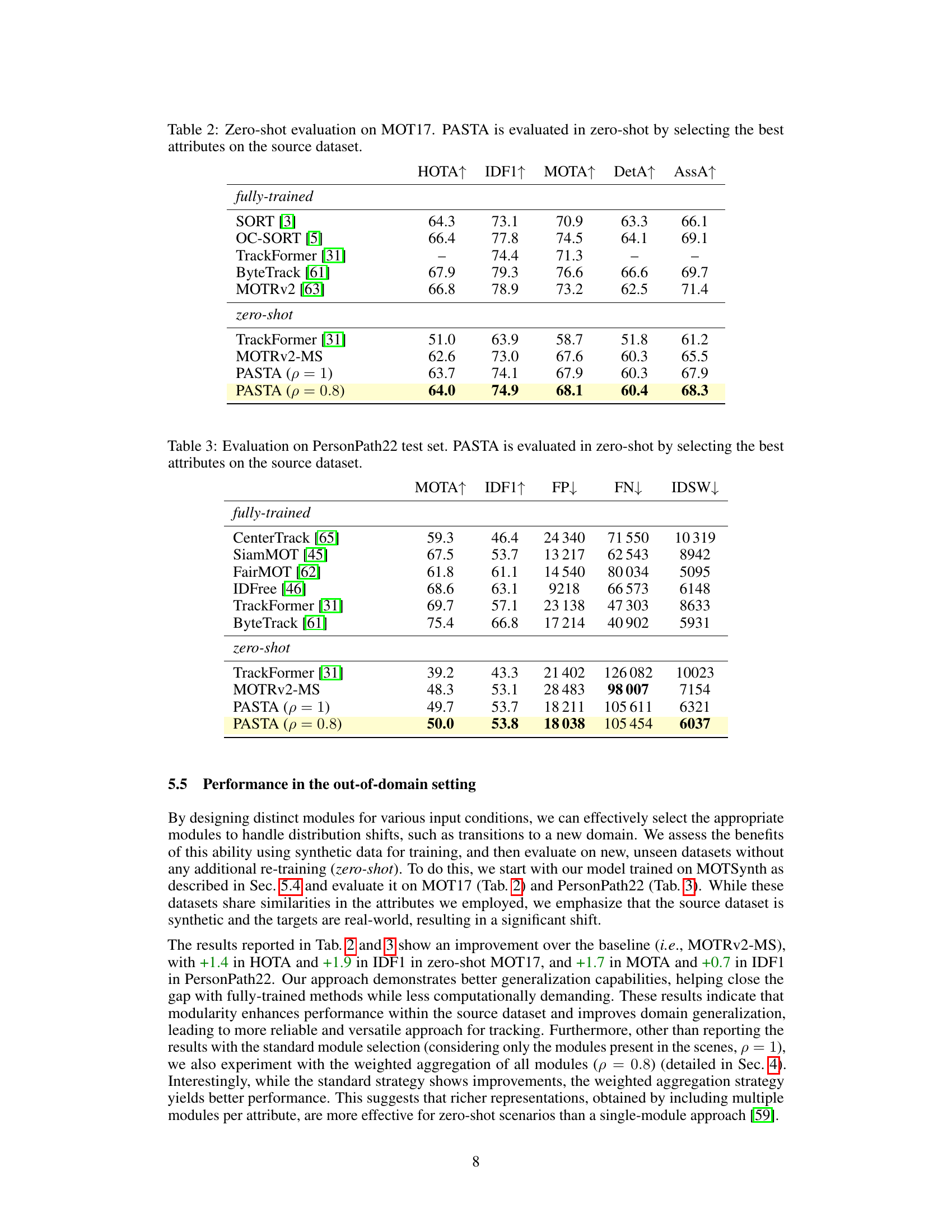
This table presents the results of a zero-shot evaluation of the PASTA model on the MOT17 dataset. The model was initially trained on a different dataset (the source dataset, not specified in this excerpt). For the zero-shot evaluation, the best-performing modules (as determined from the source dataset) were selected for each attribute, applied to MOT17, and the performance was measured using several metrics. The table compares PASTA’s performance to several other methods. The goal is to demonstrate PASTA’s ability to generalize to new, unseen datasets.
This table presents a zero-shot evaluation of the PASTA model on the MOT17 dataset. Zero-shot means the model was trained on a different dataset (the source dataset, not specified here but implied to be MOTSynth) and then directly evaluated on MOT17 without any further training or fine-tuning. The best attributes from the source dataset were selected for use in the evaluation. The table compares PASTA’s performance to several other methods, including fully-trained versions of those methods. Metrics include HOTA, IDF1, MOTA, DetA, and AssA.
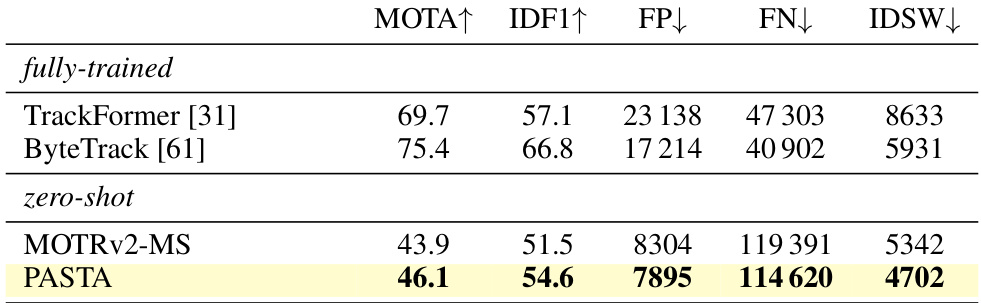
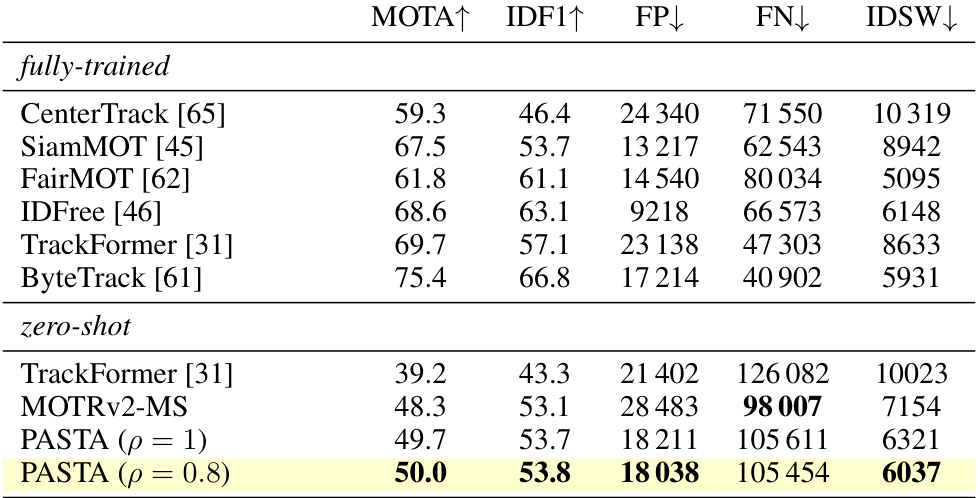
This table presents the results of a zero-shot evaluation of the PASTA model. The model was initially trained on the MOT17 dataset and then tested on the PersonPath22 dataset without any further training. The best attributes were selected from the source dataset (MOT17) for this evaluation. The metrics used are MOTA, IDF1, FP, FN, and IDSW, which assess the performance of the model in terms of accuracy, completeness, and the number of false positives, false negatives, and identity switches.

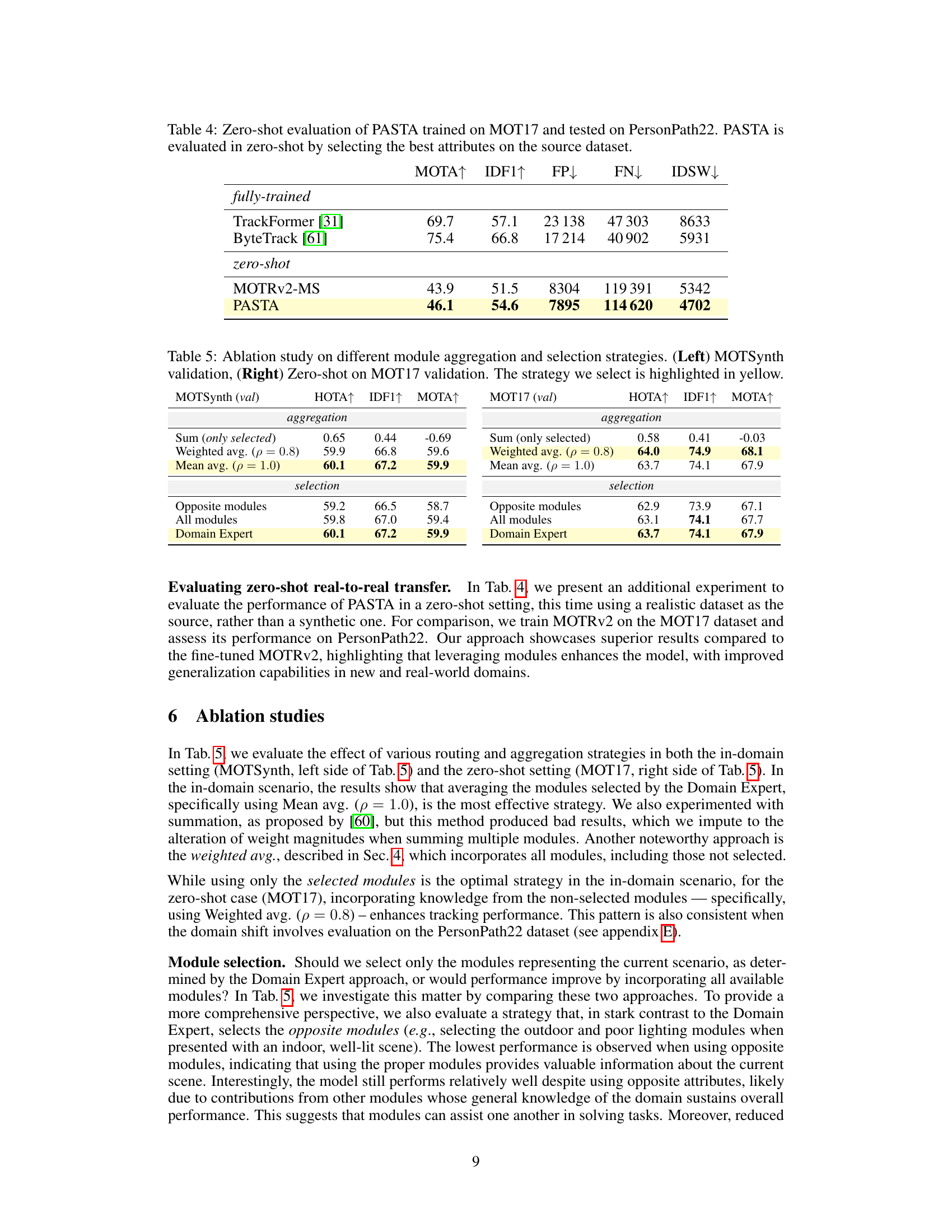
This table presents the results of an ablation study comparing different module aggregation and selection strategies for the proposed PASTA model. The left side shows the results for in-domain evaluation on the MOTSynth dataset, while the right side presents zero-shot performance on the MOT17 dataset. Three aggregation methods (Sum, Weighted average, and Mean average) and three selection strategies (Opposite modules, All modules, and Domain Expert) are compared, with the best-performing strategy highlighted for each evaluation. The table aims to demonstrate the impact of the chosen aggregation and selection techniques on the model’s overall performance.
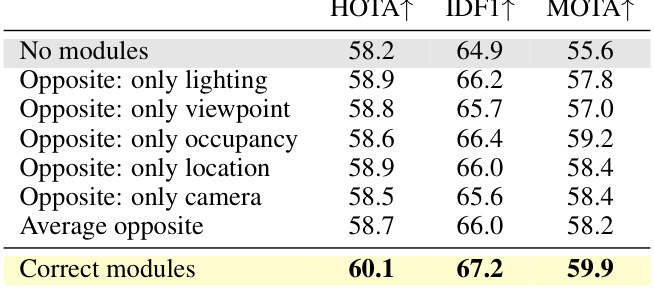
This table presents an ablation study on the impact of using ‘opposite’ modules (modules corresponding to attributes that are opposite to the actual scene attributes) in the PASTA model. It compares the performance of using opposite modules for different attributes (lighting, viewpoint, occupancy, location, camera) individually and on average against the performance of using the correct modules. The metrics used for evaluation are HOTA, IDF1, and MOTA.
This table presents the performance evaluation results on the MOTSynth test set for different multiple object tracking (MOT) methods. It compares the proposed PASTA method against several state-of-the-art trackers (SORT, ByteTrack, OCSort, TrackFormer, MOTRv2-MS) using five standard MOT metrics: HOTA, IDF1, MOTA, DetA, and AssA. The number of trainable parameters for each method is also shown, highlighting the parameter efficiency of PASTA.
This table presents the quantitative results of different multiple object tracking methods on the MOTSynth test set. It compares the performance of several established trackers (SORT, ByteTrack, OCSort, TrackFormer, MOTRv2-MS) against the proposed PASTA method. The metrics used for comparison include HOTA, IDF1, MOTA, DetA, and AssA, which comprehensively evaluate various aspects of tracking performance, from detection accuracy to track association quality and overall consistency. The number of trainable parameters for each method is also indicated to highlight the efficiency of the proposed PASTA method.
This table presents the results of evaluating different multiple object tracking methods on the MOTSynth test set. The metrics used are HOTA, IDF1, MOTA, DetA, and AssA, which are common evaluation metrics for multiple object tracking. The table compares the performance of several existing methods (SORT, ByteTrack, OCSort, TrackFormer, and MOTRv2-MS) against the proposed PASTA method. The number of trainable parameters for each model is also included. The results show that PASTA outperforms the other methods in terms of several metrics, demonstrating its effectiveness.

This table presents the results of a zero-shot evaluation of the PASTA model on the PersonPath22 dataset. The evaluation is performed by selecting the best attributes from the source dataset. The table shows the performance metrics MOTA, IDF1, FP, FN and IDSW, which are standard metrics for evaluating multiple object tracking algorithms. The results are compared to fully trained methods on the same dataset. The ‘fully-trained’ rows represent models that have been trained directly on the PersonPath22 dataset, whereas the ‘zero-shot’ rows represent models trained on a different dataset and then applied to PersonPath22 without further fine-tuning. The table demonstrates the effectiveness of the proposed modular approach in zero-shot scenarios.

This table presents the results of a zero-shot evaluation of the proposed PASTA model on the MOT17 dataset. The model was initially trained on the MOTSynth dataset and then tested on MOT17 without any further fine-tuning. The evaluation metrics (HOTA, IDF1, MOTA, DetA, and AssA) are shown for PASTA and other state-of-the-art methods (SORT, OC-SORT, TrackFormer, ByteTrack, and MOTRv2). The ‘fully-trained’ rows show the performance of models trained directly on MOT17, while ‘zero-shot’ rows show the performance of models trained on MOTSynth and tested on MOT17 without additional training. The table helps to assess the model’s generalization ability and compare its performance with existing methods.
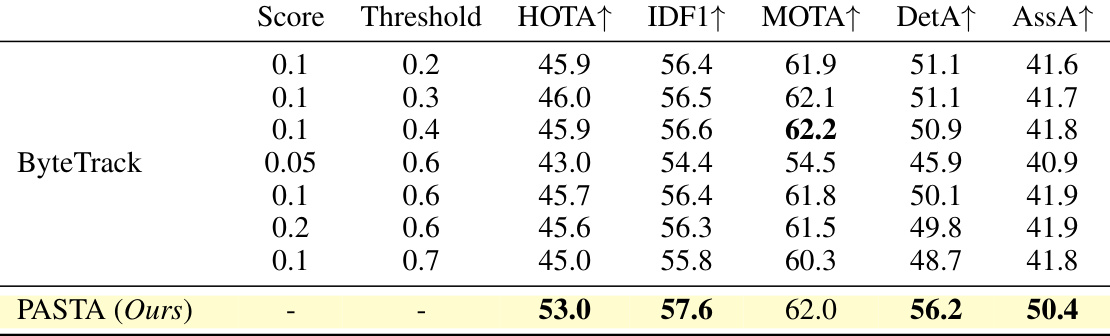
This table presents the quantitative evaluation results of different multiple object tracking (MOT) methods on the MOTSynth test set. The metrics used include HOTA, IDF1, MOTA, DetA, and AssA, which are common evaluation metrics for MOT. The number of trainable parameters for each method is also shown. The table allows for a comparison of the performance of various MOT algorithms, highlighting the effectiveness of the proposed PASTA framework.
Full paper#