TL;DR#
Entity alignment (EA) is crucial for knowledge fusion, but existing methods struggle with “dangling entities”—entities in one knowledge graph without counterparts in another. The problem is worsened when these dangling entities are unlabeled, a common scenario in real-world datasets. This significantly impacts EA accuracy, especially when knowledge graphs are of different scales. Existing approaches frequently require a portion of labeled dangling entities for training, adding significant cost and complexity.
The proposed framework, Lambda, addresses this challenge head-on. It combines a GNN-based encoder (KEESA) that incorporates a spectral contrastive learning loss for EA with a novel iterative PU learning algorithm (iPULE) for detecting dangling entities. Lambda offers theoretical guarantees of unbiasedness and improved accuracy, surpassing baseline methods, even those leveraging labeled dangling data for training. This novel framework provides a more efficient and robust solution for handling incomplete and imbalanced data in entity alignment.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on entity alignment, particularly those dealing with knowledge graphs of varying scales. It addresses the challenging problem of unlabeled dangling entities, offering a novel framework and theoretical guarantees. This directly impacts the accuracy and robustness of real-world knowledge graph applications by providing a more effective method for handling incomplete data.
Visual Insights#

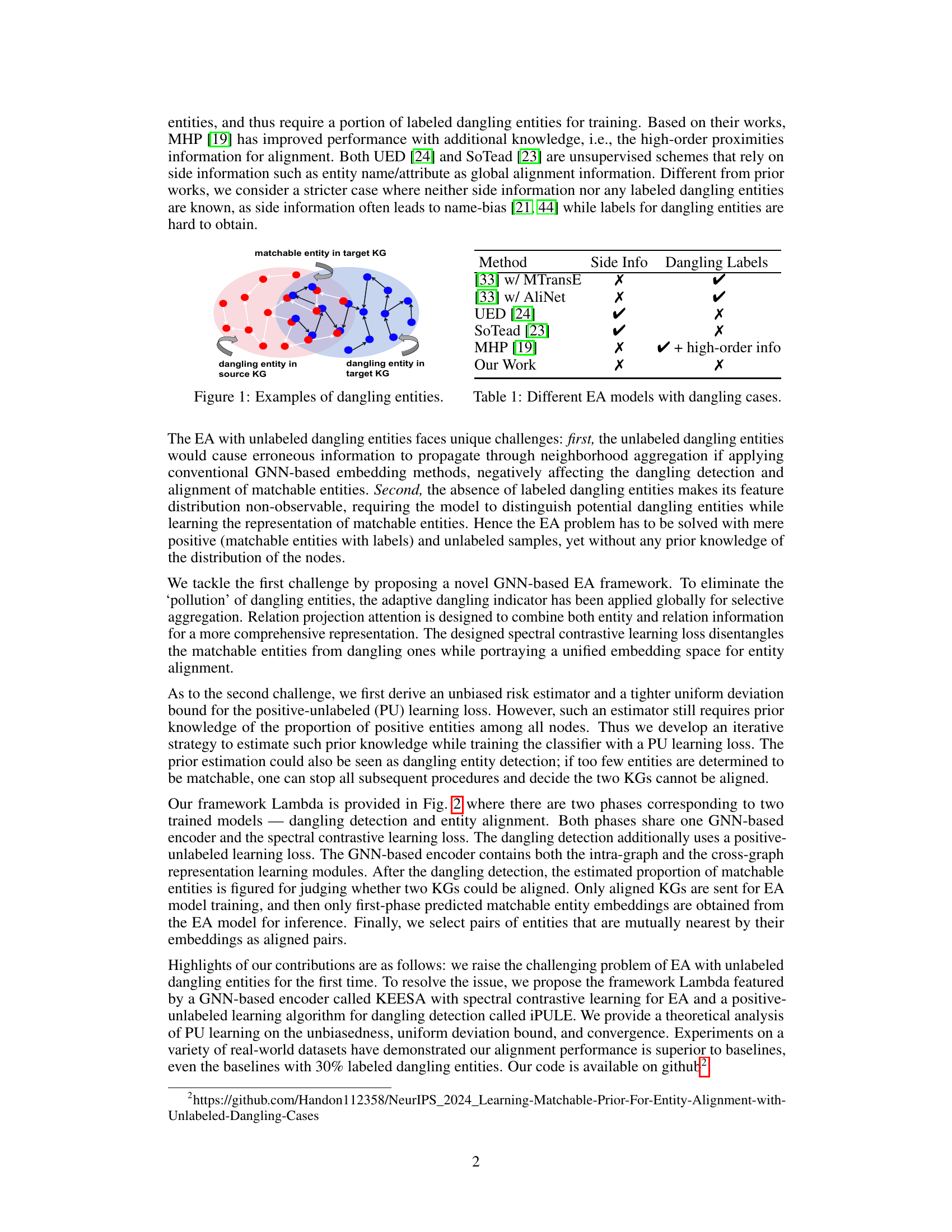
🔼 This figure illustrates the concept of dangling entities in entity alignment. Two knowledge graphs (KGs) are shown, represented by circles. Red nodes represent entities in the source KG, and blue nodes represent entities in the target KG. The overlapping area shows entities that have matches in both KGs (matchable entities). The nodes outside of the overlapping area are entities that only appear in one KG, which are the dangling entities. The arrows show connections (relationships) between entities within each KG. Dangling entities present a challenge for entity alignment because they lack corresponding entities in the other KG.
read the caption
Figure 1: Examples of dangling entities.

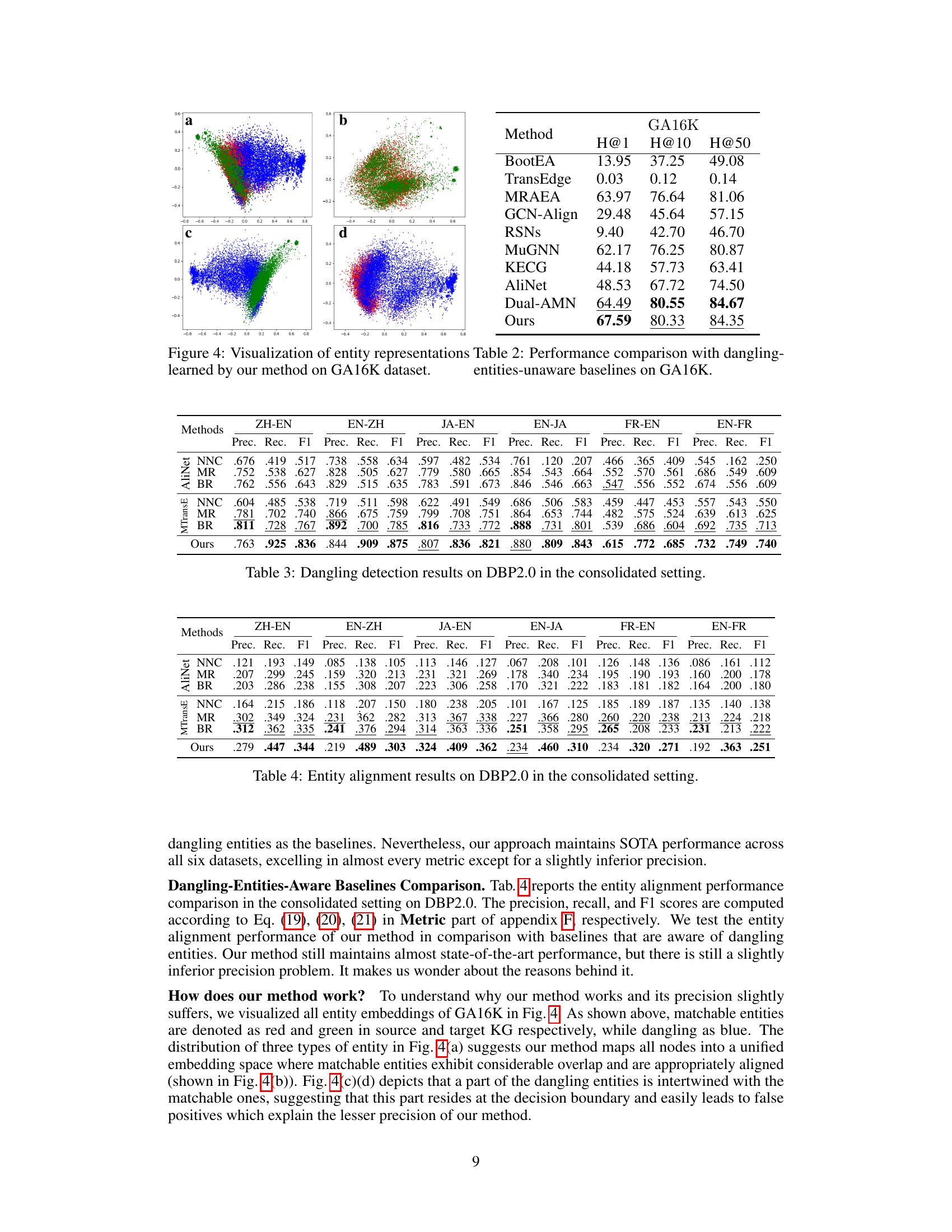
🔼 This table presents the performance comparison results on the GA16K dataset between the proposed method and several state-of-the-art dangling-entities-unaware baselines. The metrics used are Hits@1, Hits@10, and Hits@50, which measure the accuracy of the top-ranked predictions for entity alignment. The results show that the proposed method outperforms or matches the performance of most baselines, indicating its effectiveness in entity alignment tasks even without explicitly considering dangling entities.
read the caption
Table 2: Performance comparison with dangling-entities-unaware baselines on GA16K.
In-depth insights#
Dangling EA Problem#
The “Dangling EA Problem” highlights a critical challenge in Entity Alignment (EA): the presence of entities in one knowledge graph (KG) lacking counterparts in another. These dangling entities, often unlabeled, pose a significant hurdle for accurate alignment as they introduce noise and disrupt the learning process of embedding-based models. The problem is exacerbated when KGs are of vastly different scales, making comprehensive labeling of dangling entities impractical. Existing methods often rely on additional information or a subset of labeled dangling entities for training, limiting their applicability and generalizability. Addressing the dangling EA problem requires novel approaches that can effectively distinguish matchable from dangling entities using only positive (labeled) and unlabeled data. This necessitates techniques capable of handling the inherent class imbalance and uncertainty introduced by the unlabeled nature of the dangling entities. Robust solutions must also be computationally efficient to scale effectively to increasingly large and complex KGs.
KEESA Encoder#
The KEESA (KG Entity Encoder with Selective Aggregation) encoder is a crucial component designed to address challenges in entity alignment (EA) tasks, particularly when dealing with unlabeled dangling entities. KEESA employs a novel GNN-based architecture that leverages both intra-graph and cross-graph representation learning. A key innovation is the integration of an adaptive dangling indicator which dynamically weighs the contribution of neighboring entities during aggregation, effectively mitigating the negative effects of noisy dangling entities on the embeddings of matchable entities. Furthermore, relation projection attention mechanisms enhance the model’s ability to capture the rich relational information within the knowledge graphs, improving the overall representation learning. This sophisticated approach ensures that the learned embeddings effectively capture the similarities between matchable entities while minimizing the interference of unlabeled dangling entities. The resulting embeddings are then used downstream in spectral contrastive learning and positive-unlabeled learning for entity alignment and dangling detection, making KEESA a powerful and robust encoder for EA in complex scenarios.
iPULE Algorithm#
The iPULE (Iterative Positive-Unlabeled Learning) algorithm is a crucial component of the LAMBDA framework, addressing the challenge of entity alignment with unlabeled dangling cases. iPULE’s core innovation lies in its iterative approach to estimating the prior probability of positive (matchable) entities within the unlabeled data. This estimation is vital because standard PU learning methods often require knowing this prior, which is unavailable in the unlabeled dangling case. iPULE cleverly uses this prior estimate to guide a positive-unlabeled learning algorithm, enhancing dangling detection. By iteratively refining the prior and training the classifier, iPULE offers theoretical guarantees of unbiasedness, uniform deviation bounds, and convergence. This iterative refinement is key to the algorithm’s effectiveness, allowing for more accurate dangling entity detection without the need for labeled examples. The algorithm’s theoretical underpinnings provide confidence in its robustness and performance. Moreover, iPULE’s early stopping mechanism based on the estimated prior allows for efficient handling of cases where few or no matchable entities exist, avoiding unnecessary computation in the EA phase. The successful integration of iPULE within LAMBDA highlights its practical significance in solving a challenging real-world problem in knowledge graph alignment.
Ablation Studies#
Ablation studies systematically assess the contribution of individual components within a machine learning model. By removing or modifying specific parts (e.g., layers in a neural network, specific features, or regularization terms), researchers can evaluate their impact on overall performance. This helps to disentangle the effects of various components, revealing which are most essential for achieving good results. In entity alignment, ablation studies might involve removing the dangling detection module, the relation projection attention mechanism, or the spectral contrastive loss function to see how each affects the accuracy. The findings then inform future model design choices, identifying components for improvement or removal to increase efficiency and perhaps robustness. For example, if removing a module significantly reduces performance, it indicates the module’s importance, while minimal impact suggests that the module might be redundant or its impact minimal. Therefore, well-designed ablation studies are crucial for understanding model behavior and guiding future research directions in the field of entity alignment and knowledge graph tasks.
Future of EA#
The future of entity alignment (EA) hinges on addressing its current limitations and exploring new avenues. Handling unlabeled dangling entities, a significant challenge in real-world scenarios, necessitates developing more robust techniques that can effectively identify and manage these entities without relying on extensive manual labeling. Incorporating richer contextual information such as textual descriptions and visual features alongside structured data will significantly boost EA’s accuracy and applicability. Advancements in graph neural networks (GNNs), particularly those focusing on efficient and scalable graph representations, are essential for improving the performance of EA on massive knowledge graphs. Furthermore, the field could benefit from research on more effective evaluation metrics that better capture the complexities of EA tasks, especially in the presence of noise and uncertainty. Finally, exploring the integration of EA with other knowledge representation and reasoning methods holds immense potential, promising a more holistic and nuanced understanding of complex relationships across different knowledge sources.
More visual insights#
More on figures
🔼 This figure illustrates the LAMBDA framework for entity alignment with unlabeled dangling cases. It shows the two main phases: dangling detection and entity alignment. Both phases utilize a GNN-based encoder (KEESA) with spectral contrastive learning. The dangling detection phase incorporates an iterative positive-unlabeled learning algorithm (iPULE) to estimate the proportion of matchable entities and identify them. The framework uses a gating mechanism to integrate intra-graph and cross-graph representations for entity alignment. If the proportion of matchable entities is too low, the alignment phase is skipped.
read the caption
Figure 2: The illustration of our framework.
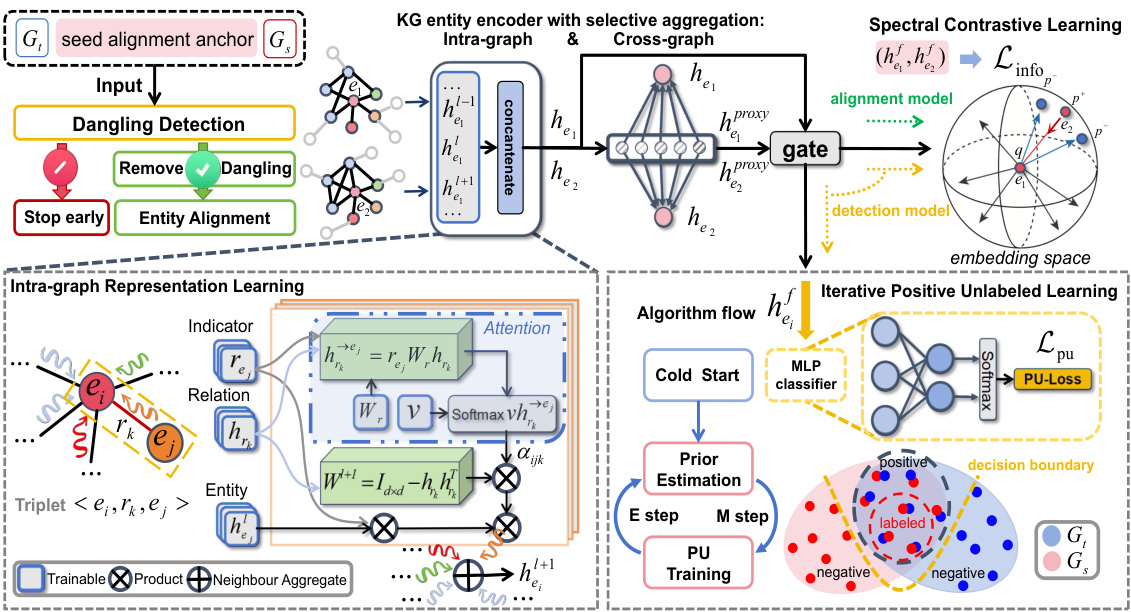
🔼 This figure illustrates the LAMBDA framework for entity alignment with unlabeled dangling cases. It shows the two main phases: dangling detection and entity alignment. Both phases share a GNN-based encoder (KEESA) with a spectral contrastive learning loss. The dangling detection module uses an iterative positive-unlabeled learning algorithm (iPULE) to estimate the proportion of matchable entities and identify them. The entity alignment module uses the KEESA encoder and spectral contrastive learning loss to align matchable entities. The framework also includes modules for adaptive dangling indication, relation projection attention, and selective aggregation to handle dangling entities effectively.
read the caption
Figure 2: The illustration of our framework.
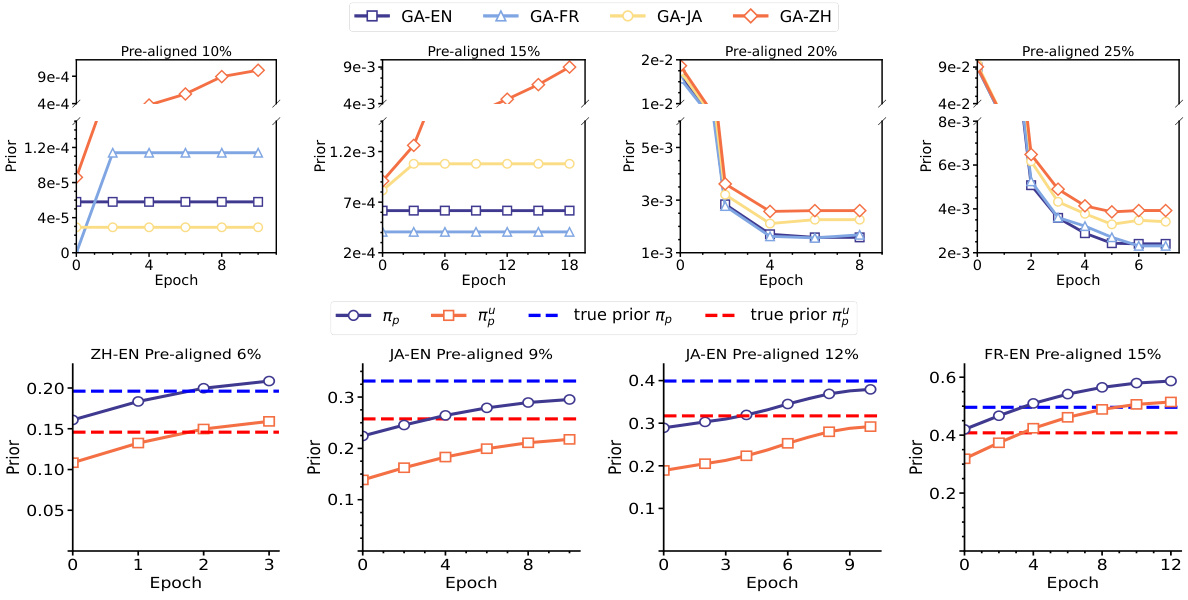
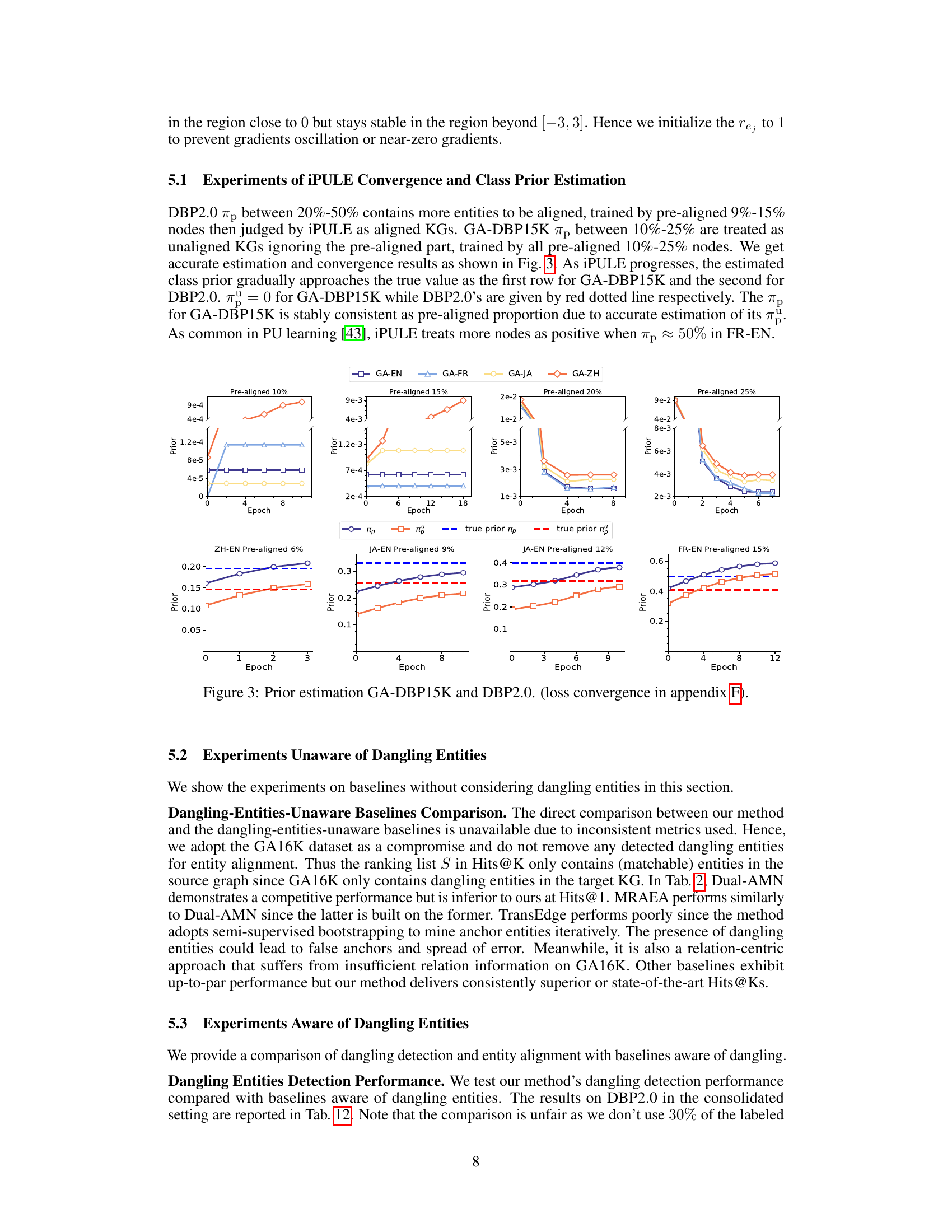
🔼 This figure shows the results of prior estimation and convergence for the GA-DBP15K and DBP2.0 datasets. The top row displays the prior estimation for the GA-DBP15K dataset with different pre-aligned percentages (10%, 15%, 20%, 25%), showing the estimated class prior gradually approaching the true value. The bottom row displays the same for the DBP2.0 dataset, illustrating how the estimated class prior converges to the true value. The plots demonstrate the effectiveness of the iterative positive-unlabeled (PU) learning algorithm in estimating the class prior and achieving convergence.
read the caption
Figure 3: Prior estimation GA-DBP15K and DBP2.0. (loss convergence in appendix F).

🔼 This figure visualizes the entity representations learned by the proposed method, LAMBDA, on the GA16K dataset. It shows the embedding space for the entities, differentiating between matchable entities (red and green) and dangling entities (blue). The visualization helps illustrate how LAMBDA effectively separates matchable and dangling entities in the embedding space, which is crucial for accurate entity alignment.
read the caption
Figure 4: Visualization of entity representations learned by our method on GA16K dataset.
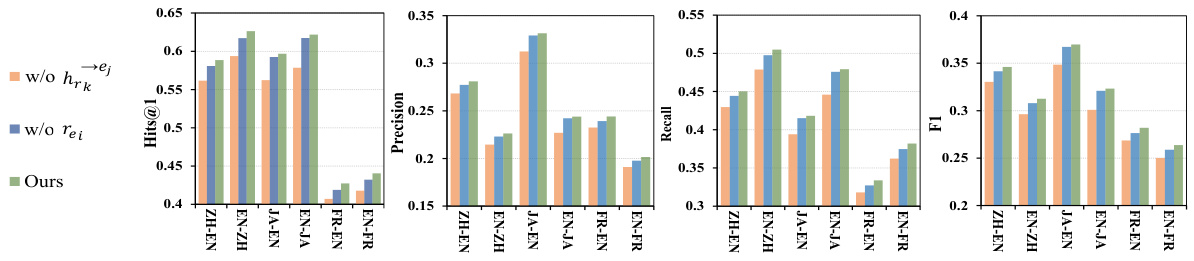
🔼 This figure presents the results of ablation studies conducted on the DBP2.0 dataset to evaluate the impact of the adaptive dangling indicator and relation projection attention mechanisms on the entity alignment performance. The ablation studies involved removing the adaptive dangling indicator (w/o re;), replacing the relation embedding (w/o hrk), and using the complete model (Ours). The results are shown separately for Hits@1, Precision, Recall, and F1-score across different language pairs (ZH-EN, EN-ZH, JA-EN, EN-JA, FR-EN, EN-FR). This allows for a detailed analysis of the contribution of each component in improving the overall alignment performance in scenarios with unlabeled dangling entities. The consolidated setting means the evaluation was performed considering both matchable and dangling entities.
read the caption
Figure 5: The ablation study of entity alignment performance in the consolidated setting on DBP2.0.

🔼 This figure shows how the entity alignment performance on the DBP2.0 dataset changes with varying pre-aligned anchor node ratios. The x-axis represents the anchor ratio (proportion of pre-aligned nodes), while the y-axis displays the performance metrics Hits@1, Precision, Recall, and F1-score. Different lines represent the performance for different language pairs (ZH-EN, EN-ZH, JA-EN, EN-JA, FR-EN, EN-FR). The results show that as the anchor ratio increases, the alignment performance generally improves for all language pairs, indicating the importance of having sufficient pre-aligned entities for effective alignment.
read the caption
Figure 6: The entity alignment performance on varying pre-aligned anchor nodes ratios on DBP2.0.

🔼 This figure visualizes the loss convergence during the training process of the proposed iPULE algorithm on the DBP2.0 and GA-DBP15K datasets. The plots show the mean and variance of the loss across multiple runs, with different colors representing different language pairs. The x-axis represents the training epoch, and the y-axis represents the loss value. The figure helps demonstrate the stability and convergence behavior of the iPULE algorithm for different datasets and language pairs. The histograms show the distribution of loss differences for each language pair, providing insight into the speed of convergence and the consistency of the algorithm’s performance.
read the caption
Figure 7: Visualization of loss convergence on DBP2.0 and GA-DBP15K.
More on tables
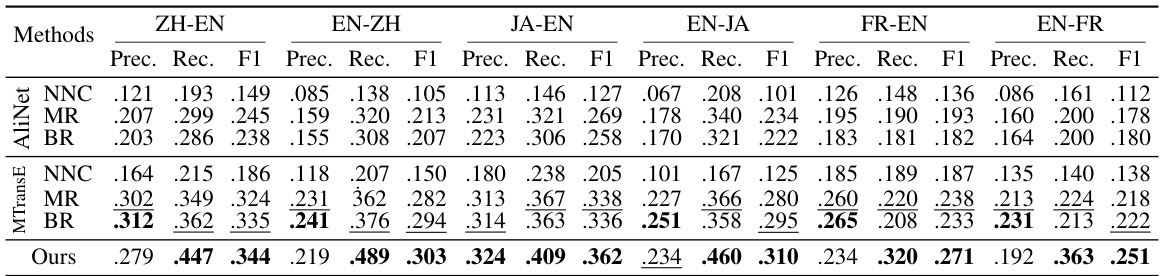
🔼 This table presents the performance of dangling entity detection methods on the DBP2.0 dataset, specifically focusing on the ‘consolidated setting.’ The consolidated setting means the evaluation includes both matchable and dangling entities. The results are broken down by language pair (e.g., ZH-EN, EN-ZH), and for each pair, it shows the precision, recall, and F1-score for three different methods: Nearest Neighbor Classification (NNC), Marginal Ranking (MR), and Background Ranking (BR). The table also includes the results for the proposed ‘Our Work’ method, demonstrating its performance compared to existing techniques in this more challenging scenario.
read the caption
Table 3: Dangling detection results on DBP2.0 in the consolidated setting.
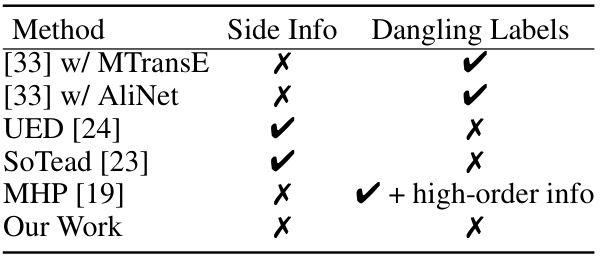
🔼 This table compares different entity alignment (EA) models in terms of their handling of dangling entities (entities without counterparts in the other knowledge graph). It shows whether each method uses side information (like entity names or attributes), and whether it requires labeled dangling entities for training. The table highlights that the proposed method in the paper is unique because it does not use side information nor labeled dangling entities.
read the caption
Table 1: Different EA models with dangling cases.
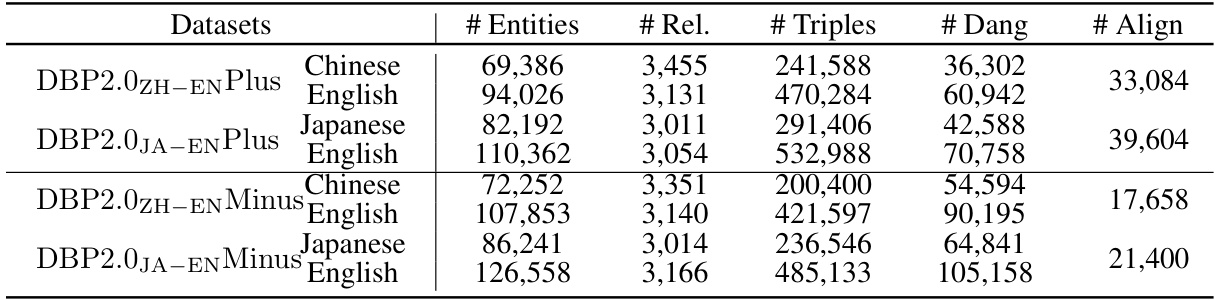
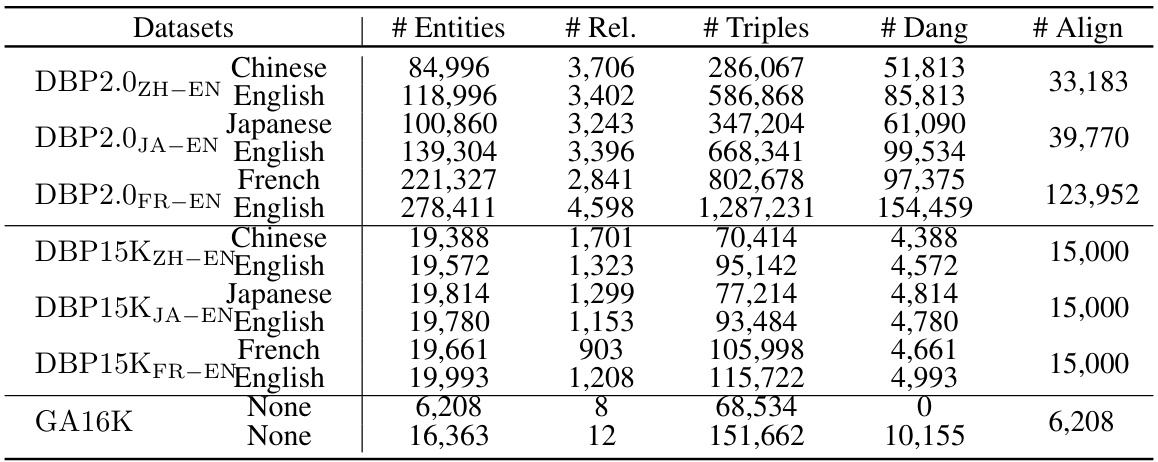
🔼 This table presents the statistics of the DBP2.0-Plus and DBP2.0-Minus datasets. These datasets are variations of the original DBP2.0 dataset, modified to have different proportions of positive (matchable) entities. DBP2.0-Plus has a higher proportion of positive entities than the original DBP2.0, while DBP2.0-Minus has a lower proportion. The table shows the number of entities, relations, triples, dangling entities, and aligned entities for each language pair (ZH-EN, JA-EN) in both datasets.
read the caption
Table 6: Statistics of DBP2.0-Plus and DBP2.0-Minus
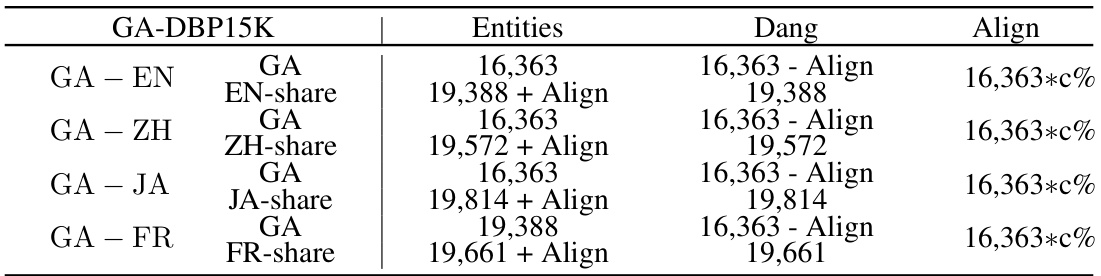
🔼 This table presents the statistics of the GA-DBP15K dataset, which is a combination of the GA16K and DBP15K datasets. It shows the number of entities, dangling entities, and aligned entities for each language pair (GA-EN, GA-ZH, GA-JA, GA-FR). The ‘Align’ column indicates the number of pre-aligned entity pairs from the DBP15K dataset, and the ‘c%’ represents the percentage of these pre-aligned pairs that are included in the final alignment, varying from 10% to 25%. This dataset is designed to evaluate the performance of entity alignment algorithms in the presence of a significant number of dangling entities.
read the caption
Table 7: Statistics of GA-DBP15K. c = [25%,20%,15%,10%].
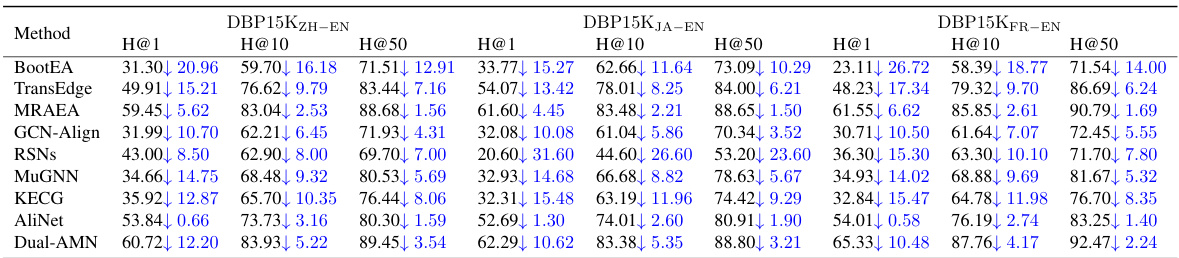
🔼 This table compares the performance of the proposed method with several dangling-entities-unaware baselines on the GA16K dataset. The metrics used are Hits@1, Hits@10, and Hits@50, which measure the accuracy of the entity alignment method at retrieving the correct alignment within the top 1, 10, and 50 results, respectively. The table highlights the superior performance of the proposed method compared to existing state-of-the-art methods.
read the caption
Table 2: Performance comparison with dangling-entities-unaware baselines on GA16K.

🔼 This table shows the impact of different embedding dimensions (64, 96, and 128) on the entity alignment performance across six different language pairs in the DBP2.0 dataset. The results, presented as precision, recall, and F1-score, highlight the optimal embedding dimension for each language pair, demonstrating the sensitivity of model performance to this hyperparameter.
read the caption
Table 9: The entity alignment performance over different embedding dimensions on DBP2.0.

🔼 This table presents a comparison of the proposed method’s performance against several other methods on the GA16K dataset. The methods compared are all ‘Dangling-Entities-Unaware,’ meaning they do not explicitly handle or account for dangling entities in their models. The table shows the Hits@K (K=1, 10, 50) metric for each method, which measures the accuracy of identifying correctly aligned entity pairs. Higher Hits@K scores indicate better performance. The results demonstrate that the proposed method outperforms the baselines, indicating its effectiveness even without specific handling of dangling entities.
read the caption
Table 2: Performance comparison with dangling-entities-unaware baselines on GA16K.

🔼 This table compares different entity alignment (EA) models based on whether they utilize side information and labeled dangling entities. It highlights that the proposed work, unlike others, does not require any labeled dangling entities or side information, making it suitable for scenarios with limited labeled data.
read the caption
Table 1: Different EA models with dangling cases.

🔼 This table compares the performance of the proposed method (Lambda) and a strong baseline method (LightEA) on the entity alignment task under a relaxed setting. The relaxed setting refers to a scenario where dangling entities are not removed from the evaluation. The results are shown for three different language pairs: ZH-EN, JA-EN, and FR-EN. Hits@1 and Hits@10 metrics are used to evaluate the performance.
read the caption
Table 12: Comparison of Lambda and LightEA under relaxed setting. '-' indicates the absence of data due to out of time.
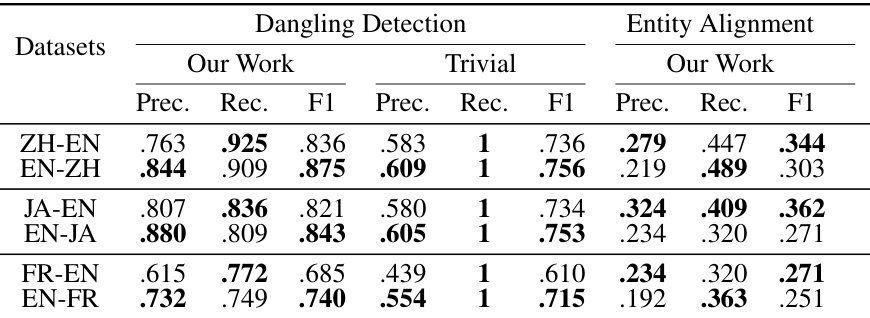
🔼 This table compares the performance of the proposed dangling entity detection method against a trivial classifier on the DBP2.0 dataset. The proposed method significantly outperforms the trivial classifier in terms of precision, recall, and F1-score for all language pairs. The trivial classifier, which classifies all entities as dangling, serves as a baseline for comparison. This highlights the effectiveness of the proposed method in accurately identifying dangling entities.
read the caption
Table 13: Dangling entities detection by our classifier v.s. a trivial one on DBP2.0.
Full paper#