↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Long videos present a significant challenge for video understanding due to their high computational cost and the risk of losing early contextual information. Existing approaches often rely on sparse sampling or frame compression, but these methods often discard important temporal information or spatial details. This leads to flawed video representation, affecting the accuracy of downstream tasks such as question answering.
VideoStreaming tackles this challenge by using a novel two-stage approach. First, a memory-propagated streaming encoding architecture segments the video into short clips and encodes each clip sequentially, incorporating the preceding clip’s encoded results as historical memory. This approach maintains a fixed-length memory, representing even arbitrarily long videos concisely, and integrating long-term temporal dynamics. Second, an adaptive memory selection strategy chooses a fixed number of question-related memories, feeding them into an LLM to generate precise responses. This disentangled design increases efficiency and accuracy, avoiding the need to re-encode the whole video for each question. The experimental results demonstrate superior performance and efficiency compared to other approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on long video understanding and vision-language models. It addresses the computational challenges of processing long videos by proposing efficient encoding and memory selection techniques. This work opens new avenues for future research in handling long-term temporal dynamics in video understanding and is directly relevant to the current trend of integrating LLMs with other modalities.
Visual Insights#

This figure illustrates the VideoStreaming framework. Part (a) shows the overall architecture: a long video is segmented into short clips, each encoded into a compact memory representation. For a given question, relevant memory subsets are selected and fed to a large language model (LLM) to generate the answer. Part (b) details a single iteration of the streaming encoding process, showing how current clip features, historical memory from the previous clip, and a time prompt are combined to create an updated memory representation for the current time step.

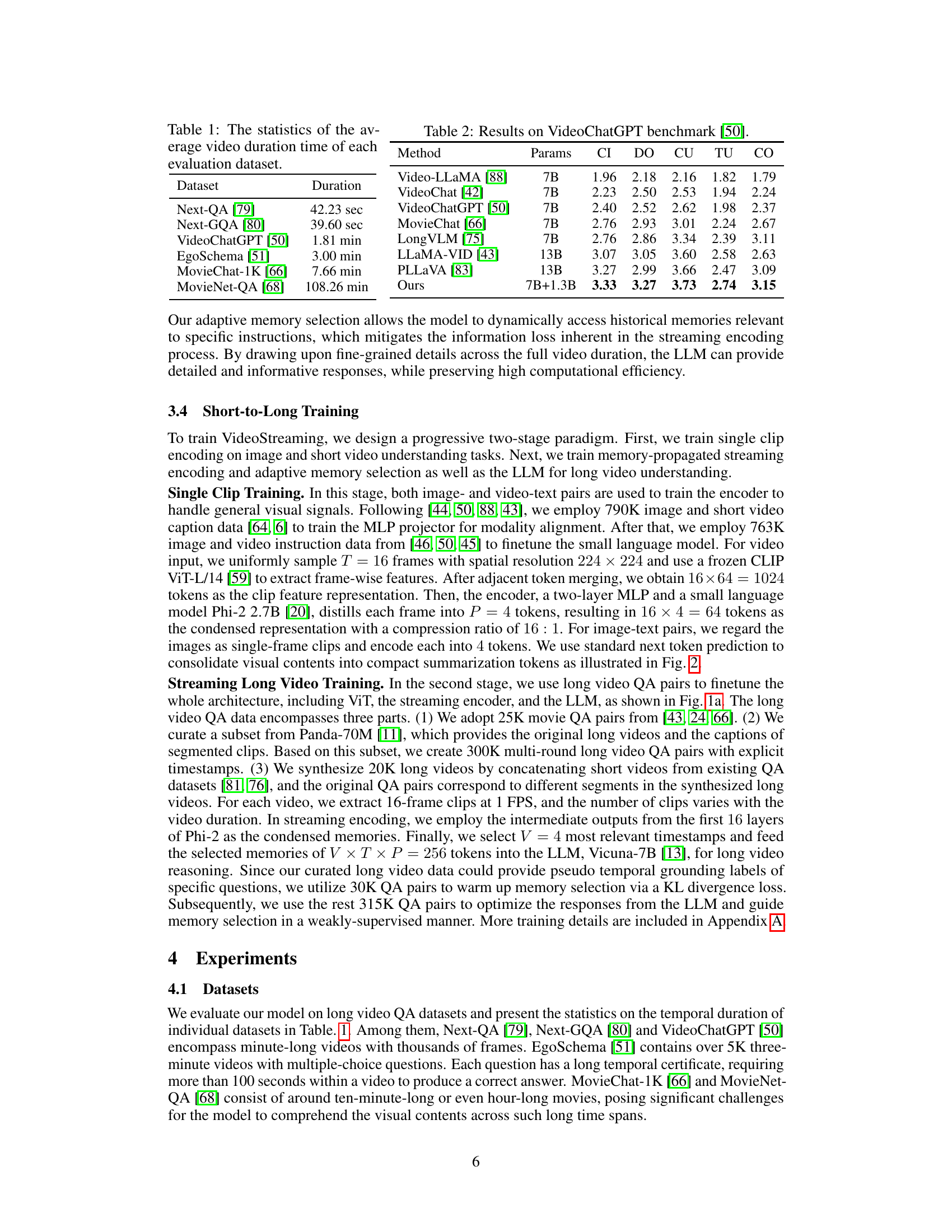
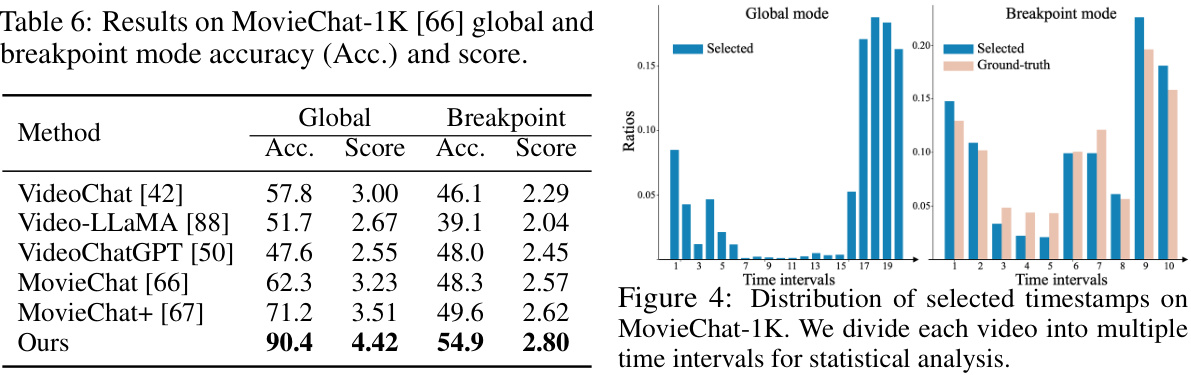
This table presents the results of VideoStreaming and other state-of-the-art methods on the VideoChatGPT benchmark. The benchmark evaluates video understanding models on five aspects: Correctness of Information (CI), Detailed Orientation (DO), Contextual Understanding (CU), Temporal Understanding (TU), and Consistency (CO). Higher scores indicate better performance on each aspect. The table shows that VideoStreaming achieves superior performance to other models, especially in temporal understanding.
In-depth insights#
LongVid Streaming#
LongVid Streaming, a hypothetical system for processing lengthy videos, presents significant challenges and opportunities. Efficient encoding is crucial; naive approaches using all frames lead to excessive computational cost and potential loss of temporal context. Memory-based mechanisms, which store and selectively access relevant information from earlier segments, offer a promising solution, enabling the system to handle long videos with bounded resources. Adaptive selection strategies, which choose the most pertinent historical memories based on a given query, are critical for both efficiency and accuracy. A key design aspect is the balance between preserving long-term temporal dynamics and maintaining a manageable memory footprint. The success of LongVid Streaming hinges on the development of robust methods for video compression, memory management, and efficient query processing. The use of large language models (LLMs) offers the capability to handle complex video understanding tasks, but careful consideration of how to effectively integrate visual and textual representations remains a critical factor in achieving optimal performance.
Adaptive Mem Select#
Adaptive memory selection is a crucial component for efficiently handling long videos. The core idea is to avoid processing the entire video for every question. Instead, a subset of relevant memories, or video segments, is selected based on the specific question’s focus. This addresses the computational challenges of processing long video sequences and prevents information overload to the Large Language Model (LLM). The selection process itself requires a mechanism to assess relevance; one approach might be to compute the similarity between a question’s embedding and the embeddings of different video segments. This selection is adaptive because different questions will trigger different subsets of memories, allowing the system to focus on the pertinent information for each query. The effectiveness of adaptive memory selection hinges on several factors including: the quality of memory representations (encoded video segments), the robustness of the similarity metric, and the overall architecture’s integration with the LLM. Successfully implementing this strategy dramatically improves efficiency without sacrificing accuracy, making it a key innovation for long-video understanding.
Two-Stage Training#
A two-stage training process is often employed to effectively train complex models, especially in scenarios involving multiple components or tasks. The first stage typically focuses on pre-training a foundational model on a large, general dataset. This establishes a strong base and allows the model to learn fundamental features and representations. The second stage then involves fine-tuning the pre-trained model on a more specific dataset and task. This adaptation process leverages the knowledge acquired in the first stage, making the learning process more efficient and potentially achieving better performance. The division into two stages facilitates tackling complex problems by breaking them down into manageable steps, allowing for better control and optimization. Transfer learning, a prominent concept here, is central to this approach’s success. The initial stage’s general knowledge can then be transferred to specific tasks, often requiring much less data than training from scratch. The success of this approach significantly depends on the relevance between the pre-training and fine-tuning datasets and the appropriate architecture design. A poorly aligned approach can lead to suboptimal results and hinder the transfer learning process.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper provides crucial evidence of a model’s capabilities. It should present a comprehensive comparison against state-of-the-art (SOTA) methods on multiple established benchmarks, detailing the metrics used, showcasing performance gains, and thoroughly explaining any discrepancies. Clear visualizations such as tables and graphs effectively convey performance differences across various benchmarks and metrics. Statistical significance should be established through proper error bars and p-values, emphasizing reliability over isolated, exceptional results. The discussion should not just focus on superior numbers, but provide insightful analysis on why the model performs better or worse on specific benchmarks. It is vital to discuss the limitations of the benchmarks and the model’s strengths and weaknesses within the context of those limitations. Robustness analysis, testing the model on diverse datasets and under various conditions, adds credibility. Overall, a strong ‘Benchmark Results’ section demonstrates the model’s real-world applicability and contributes meaningfully to the field.
Future Directions#
Future research could explore adaptive sampling techniques to address the limitations of uniform sampling in VideoStreaming, potentially using content-aware methods to focus on information-rich segments. Improving the efficiency and scalability of the model is also crucial. This could involve exploring more efficient architectures for the streaming encoder and memory selection components, as well as optimizing the interaction with the large language model. Furthermore, investigating alternative methods for memory representation and retrieval could enhance the model’s ability to handle very long videos and complex queries. Multi-modal enhancements beyond video and text, such as integrating audio or other sensor data, could also unlock new capabilities. Finally, a rigorous evaluation of the model’s robustness and fairness across diverse datasets and scenarios is needed to ensure responsible deployment and mitigate potential biases. The study of explainability within the video processing pipeline could further enhance trust and facilitate understanding of the model’s internal mechanisms.
More visual insights#
More on figures

This figure illustrates the VideoStreaming framework. (a) shows the overall process: a long video is segmented into short clips, each encoded into a compact memory representation. Based on a question, relevant memory subsets are selected and fed to a Large Language Model (LLM) for answering. (b) details a single iteration of the streaming encoding process, showing how the current clip features are combined with the previous clip’s memory and fed to a small language model. The output is a new condensed memory representing the video up to that point, and a clip indicator token for later memory selection.
This figure provides a high-level overview of the VideoStreaming framework. (a) shows the overall process: a long video is segmented into clips, each clip is encoded into a compact memory representation, and a subset of relevant memories is selected based on the question and fed into an LLM for response generation. (b) zooms into a single iteration of the streaming encoding process, highlighting the integration of current clip features, historical memory from the previous clip, and a summarization token to create a condensed representation of the video content up to that point.

This figure shows an overview of the VideoStreaming framework. Part (a) illustrates the system’s pipeline: long videos are segmented into short clips, each encoded into a compact memory representation. Based on a user’s question, a subset of these memories are selected and fed to a large language model (LLM) for answering. Part (b) details a single iteration of the streaming encoding process, showing how the current clip’s features are combined with historical memory and fed to a smaller language model to produce a condensed representation.

This figure illustrates the VideoStreaming framework. (a) shows an overview of the system, segmenting a long video into short clips, iteratively encoding them into compact memories, and then selecting relevant memories based on the question to feed into an LLM for response generation. (b) details a single iteration of the streaming encoding process, showing how current clip features are encoded with reference to preceding clip’s encoded results (historical memory), specific timestamps, and the current clip’s summarization tokens. The result is a condensed representation of the video up to that point.

This figure shows an overview of the VideoStreaming framework. (a) illustrates the process of segmenting a long video into short clips, iteratively encoding each clip into a compact memory representation, and then selecting relevant memories based on specific questions to feed into a large language model (LLM) for generating responses. (b) provides a detailed breakdown of the streaming encoding process for a single clip, showing how current clip features, historical memory from previous clips, timestamps, and summarization tokens are combined to produce a condensed representation.

This figure illustrates the VideoStreaming framework. (a) shows the overall process: a long video is segmented into short clips, each encoded into a compact memory representation. Relevant memories are selected based on the question and fed to an LLM. (b) details one iteration of the streaming encoding, showing how current clip features are combined with historical memory and fed into a small language model to produce a condensed representation.
This figure shows the VideoStreaming framework. (a) provides a high-level overview of the process: long videos are segmented into short clips, which are encoded into compact memories. A language model (LLM) then uses a subset of these memories (selected based on the question) to generate an answer. (b) zooms in on a single iteration of the streaming encoding process, showing how current clip features, historical memory, and a summarization token are used to create a condensed representation of the video content up to that point.
More on tables
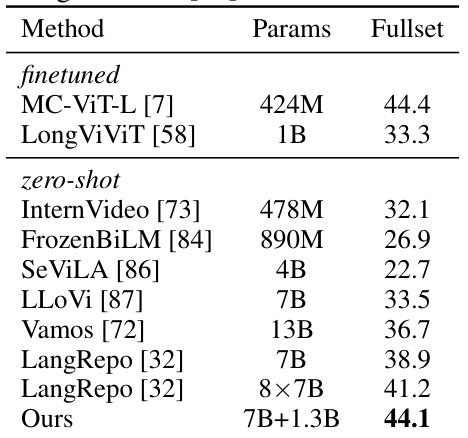
This table presents the results of various methods on the EgoSchema benchmark’s fullset test split. The benchmark focuses on long-form video understanding. The table compares the performance of several methods, showing their parameters (model size) and their performance score on the fullset. The ‘Ours’ row indicates the performance of the proposed VideoStreaming model.

This table presents the results of several methods on the validation set of the Next-QA benchmark. The benchmark consists of multiple-choice questions about videos, categorized into three types: causal, temporal, and descriptive. The table shows the performance of each method across these categories and overall.

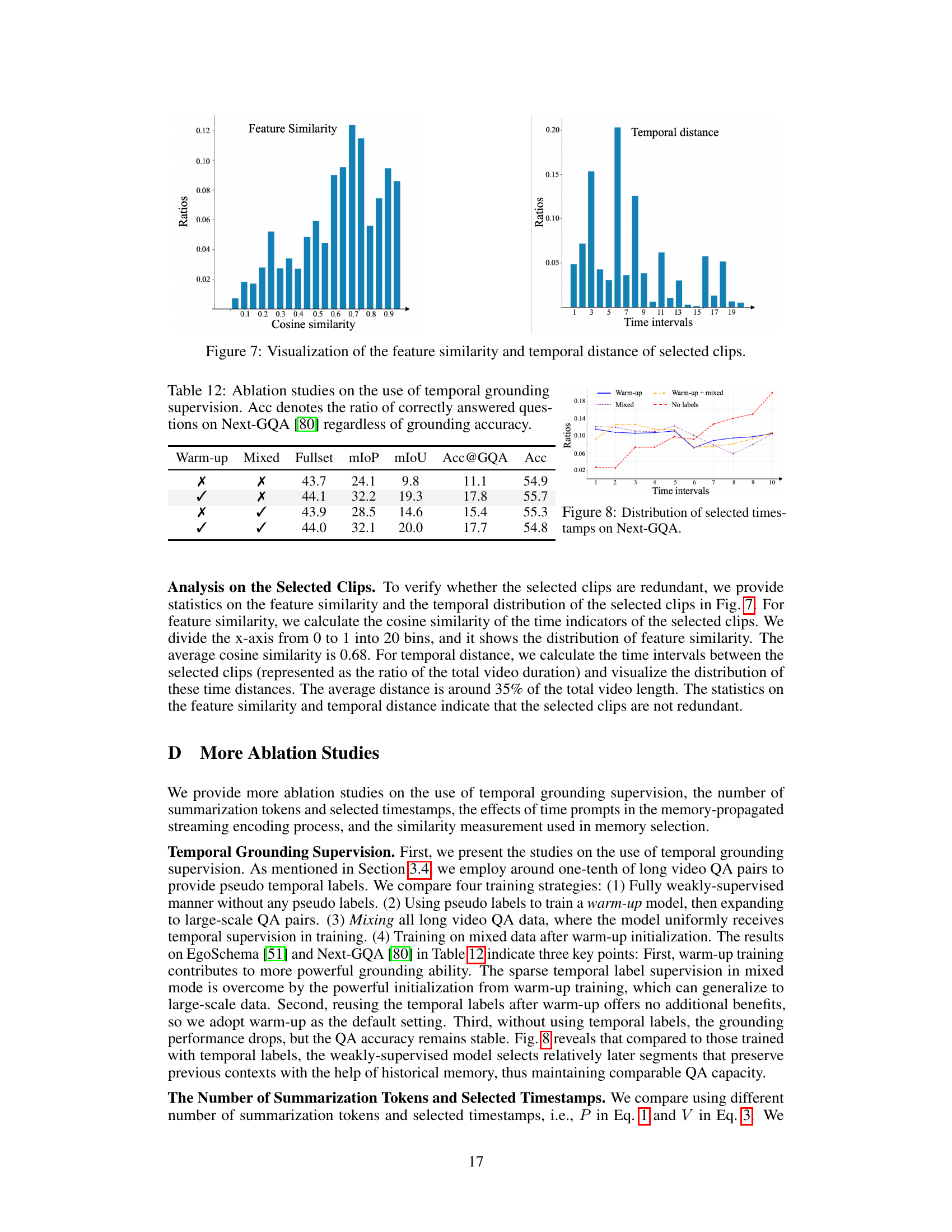
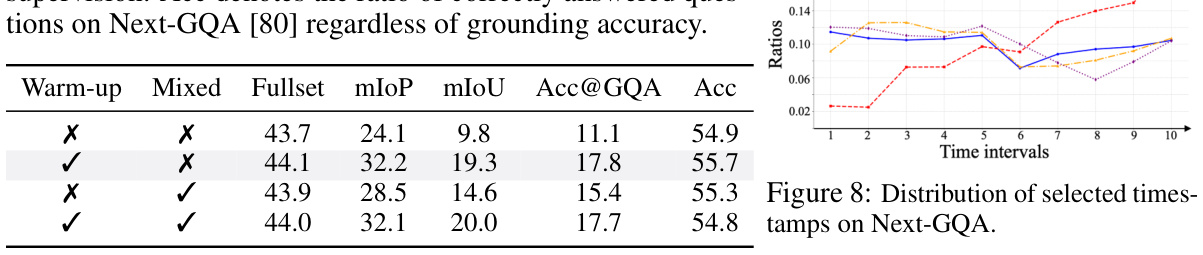
This table presents the results of different methods on the Next-GQA benchmark. The metrics evaluated include mean Intersection over Prediction (mIoP), Intersection over Prediction at 0.5 threshold (IoP@0.5), mean Intersection over Union (mIoU), mIoU@0.5, and Accuracy at GQA (Acc@GQA). Acc@GQA specifically measures the percentage of questions correctly answered and visually grounded with an IoP above 0.5, indicating both accurate answers and precise visual grounding. The table compares the performance of various methods, including those with and without specialized grounding modules, highlighting the superior performance of the proposed VideoStreaming model.
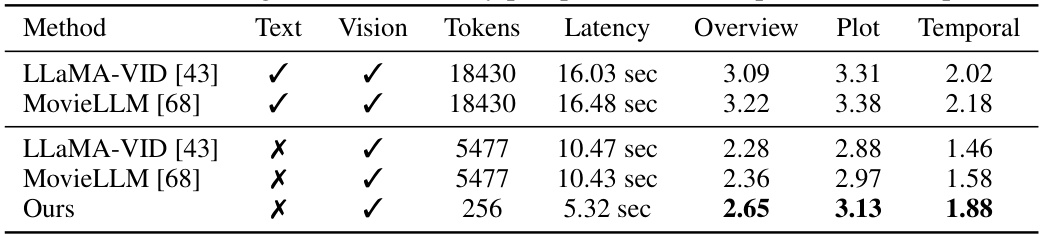
This table presents a comparison of different methods on the MovieNet-QA benchmark. It shows the performance of three different models, including LLaMA-VID, MovieLLM, and the proposed VideoStreaming model, in terms of overview, plot, and temporal understanding of long videos. The table also provides information on whether text and vision modalities were used, the number of tokens processed, and the inference latency. The results highlight the efficiency of the VideoStreaming model in processing and accurately understanding long videos.

This table presents the ablation study results focusing on the impact of memory selection and historical memory within the streaming encoding process of the VideoStreaming model. It shows the performance (Fullset, Global Acc., Break. Acc.) under different configurations: with/without propagated memory and with/without adaptive memory selection. The results highlight the contribution of each component to the overall performance of the model on long video understanding tasks.

This table presents the results of ablation studies comparing two sampling strategies for video processing: clip-based sampling and frame-based sampling. The results are evaluated on two metrics: Accuracy (Acc.) and the number of Frames used in each method. The comparison is performed on two datasets, Fullset and MovieNet, to assess the impact of sampling on performance across different video lengths and complexities.
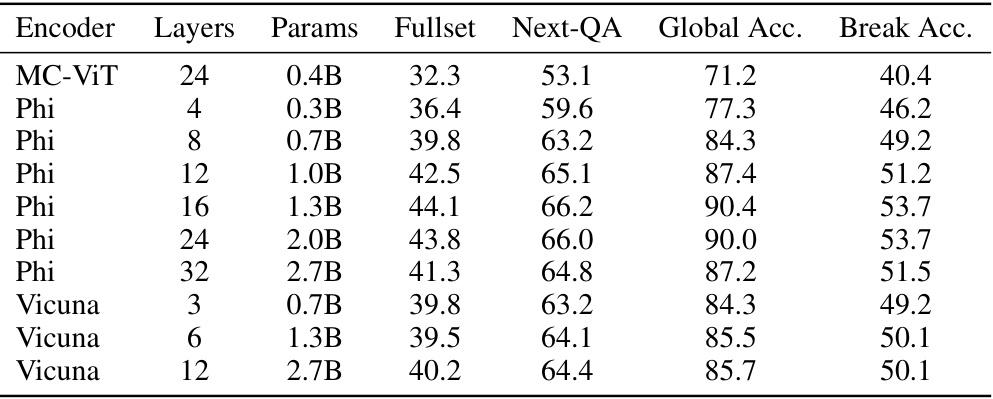
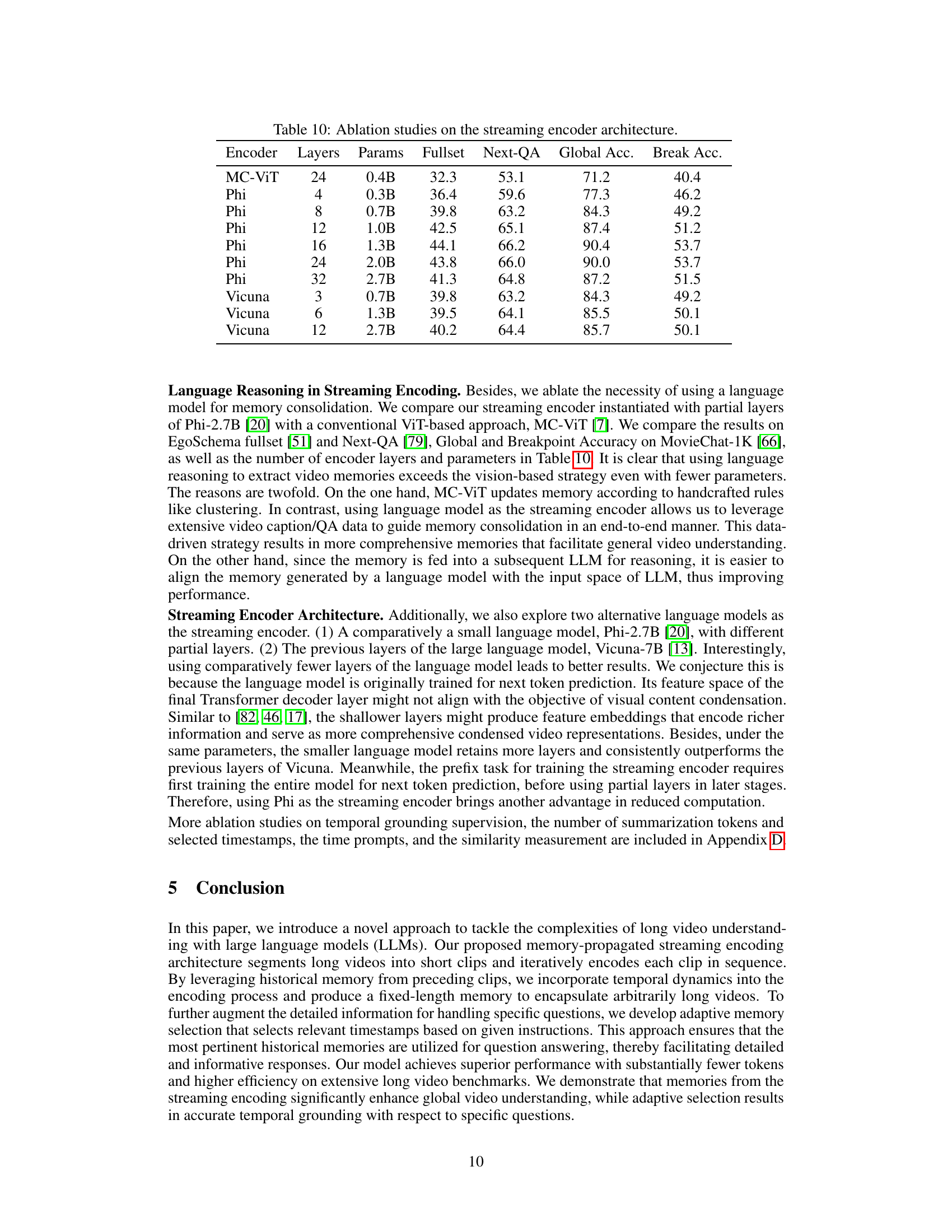
This table presents the results of an ablation study on the streaming encoder architecture, comparing different encoder models (MC-ViT, Phi, Vicuna) with varying numbers of layers and parameters. The performance is evaluated on three metrics: Fullset, Next-QA, and MovieChat-1K’s global and breakpoint accuracy. The results show how the choice of encoder model and its complexity affect the performance on the various video understanding tasks.

This table presents the performance comparison of different methods on the IntentQA dataset. IntentQA is a long-form video understanding dataset consisting of 4.3K videos with 16K multiple-choice questions categorized into three types: why, how, and before/after. The table shows the accuracy of each method for each question type and overall accuracy. The results highlight the performance of the proposed VideoStreaming model in comparison to several other recent state-of-the-art models.

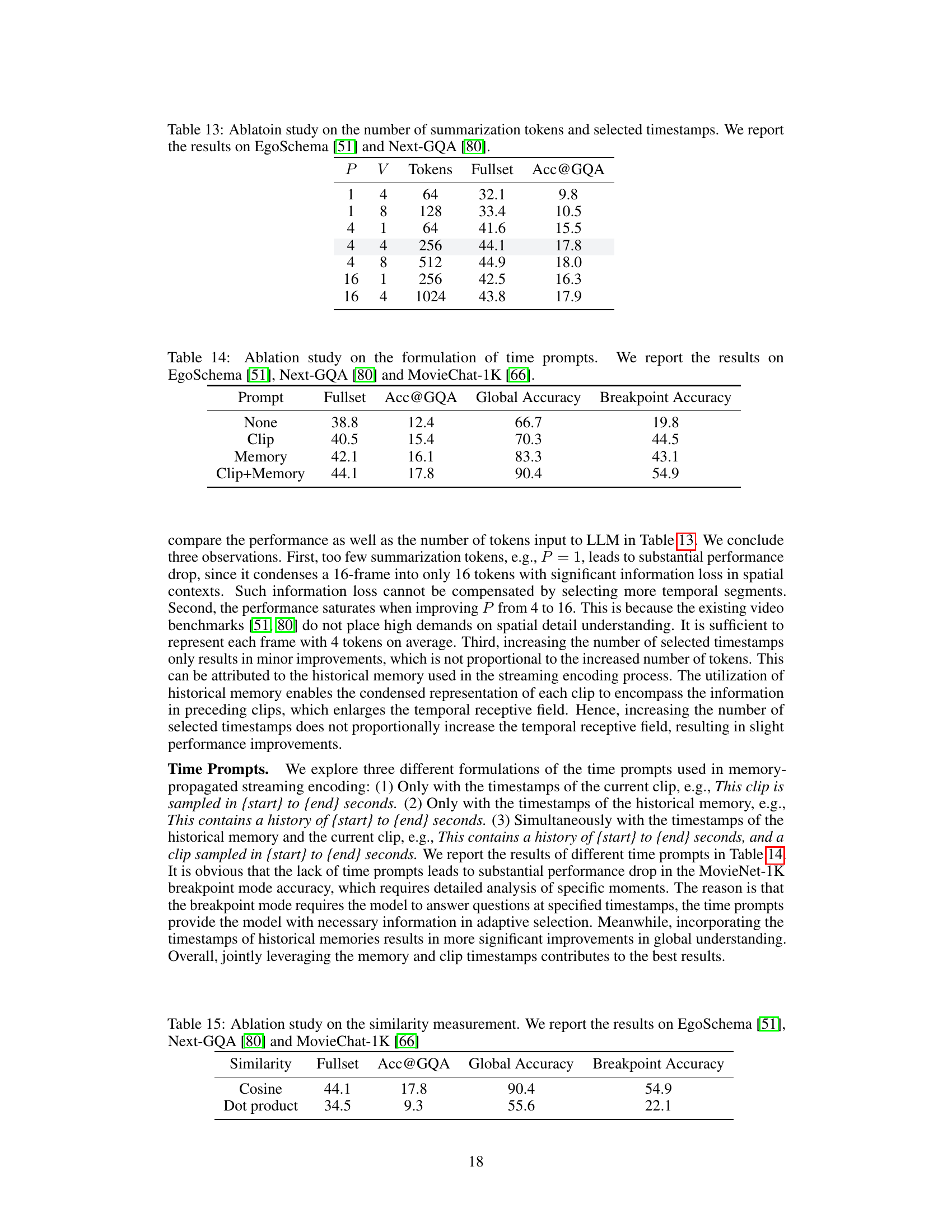
This table presents the results of ablation studies conducted to analyze the impact of varying the number of summarization tokens (P) and the number of selected timestamps (V) on the model’s performance. The studies were performed on two benchmark datasets: EgoSchema [51] and Next-GQA [80]. The table shows how changes in these parameters affect the model’s performance, measured by the Fullset and Acc@GQA metrics. Different combinations of P and V were tested, resulting in varying numbers of tokens used as input to the Language Model (LLM). The results reveal the optimal balance between the number of summarization tokens, selected timestamps, and overall model performance.

This table presents the ablation study results on different prompt formulations in the VideoStreaming model. It compares the model’s performance across four scenarios: no prompt, using only the current clip’s timestamp in the prompt, using only the historical memory’s timestamps, and using both the current clip and historical memory timestamps. The results are presented for three different metrics: Fullset accuracy, Acc@GQA, and breakpoint accuracy for EgoSchema, Next-GQA and MovieChat-1K benchmarks.

This table presents the ablation study comparing two different similarity measurements used in the adaptive memory selection process: cosine similarity and dot product. The results are reported across three different benchmarks: EgoSchema, Next-GQA, and MovieChat-1K. Each benchmark measures different aspects of video understanding. The table shows the impact of the choice of similarity metric on the overall performance.
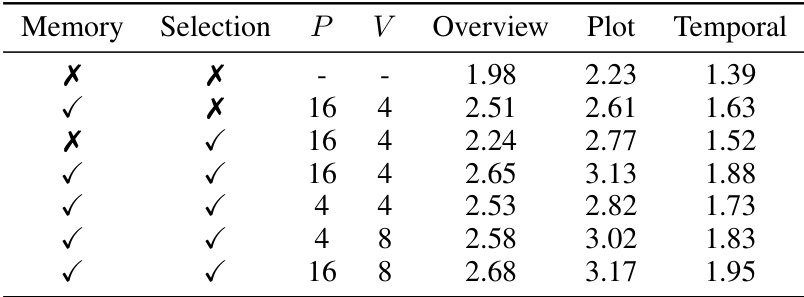
This table presents the ablation study results focusing on four key aspects of the VideoStreaming model on the MovieNet-QA benchmark, which contains hour-long videos. The aspects studied are memory propagation, temporal selection, the number of summarization tokens (P), and the number of selected clips (V). For each configuration, the table shows the performance across three perspectives: overview, plot, and temporal understanding. This helps analyze the individual and combined effects of these design choices on the model’s overall performance in handling long videos.
Full paper#