↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Robust reinforcement learning (RL) aims to create policies that work well even when the environment differs slightly from the training data. Existing robust RL methods often rely on either a generative model (which creates data) or a large pre-collected dataset, limiting their real-world applicability. This paper focuses on a more realistic scenario where the RL agent learns by interacting directly with the environment, making it more challenging to ensure robustness and efficiency.
This paper addresses these issues by establishing a fundamental hardness result, showing that sample-efficient robust RL is impossible without additional assumptions. To circumvent this, they introduce a new assumption (vanishing minimal value assumption) that mitigates support shift problems (where the training and testing environments have different relevant states). Under this assumption, they propose a novel algorithm (OPROVI-TV) with a provable sample complexity guarantee, demonstrating that sample-efficient robust RL via interactive data collection is feasible under specific conditions. This represents a significant advancement towards making robust RL more applicable and effective in real-world applications where direct interaction is necessary and data is limited.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles a significant challenge in robust reinforcement learning (RL): achieving sample efficiency when learning from interactions with only the training environment. This is highly relevant due to the cost and difficulty of acquiring data in real-world settings for many RL applications. The findings provide valuable insights and potential solutions for improving the practicality of robust RL in such scenarios. The proposed algorithm and theoretical analysis open new avenues for research focusing on interactive data collection, specific assumptions for tractability, and the development of more efficient, robust RL algorithms.
Visual Insights#
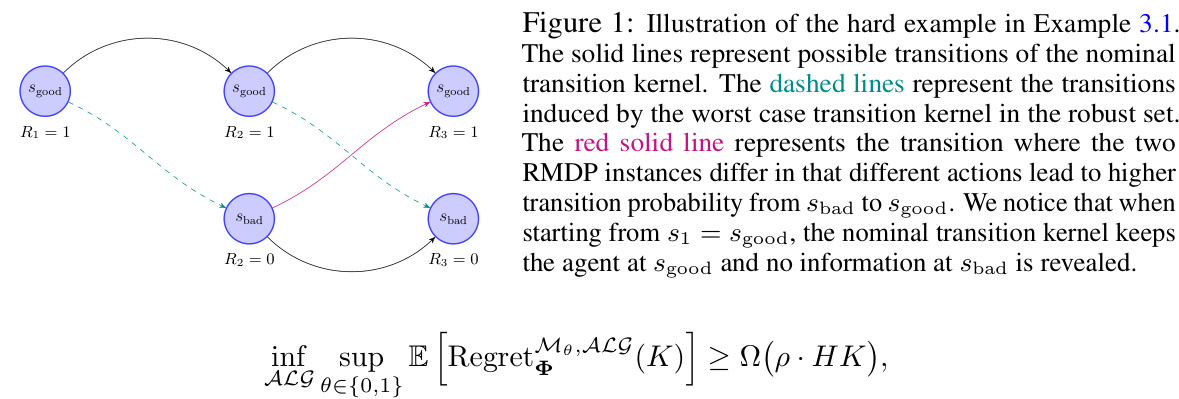
This figure illustrates Example 3.1 from the paper, which presents a hard instance for robust reinforcement learning with interactive data collection. It shows two Markov Decision Processes (MDPs), M0 and M1, differing only in their transition probabilities from the ‘bad’ state (sbad) to the ‘good’ state (sgood). The solid lines represent the nominal transition probabilities in M0, while dashed lines depict the worst-case transition probabilities within a specified uncertainty set. The red line highlights the crucial difference: In M1, a specific action leads to a higher probability of transitioning from sbad to sgood, a transition that is highly unlikely in M0, starting from s1 = sgood. This exemplifies the ‘curse of support shift’ – crucial information about parts of the state space relevant for robust policy learning might be hard to obtain via interactive data collection in the training environment.
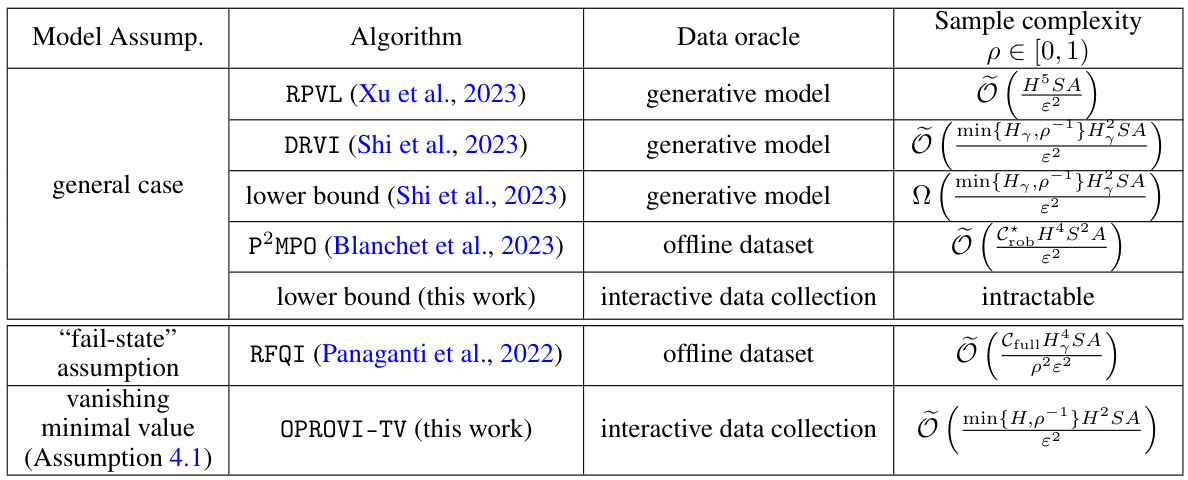
This table compares the sample complexity of the proposed OPROVI-TV algorithm with existing algorithms for solving robust Markov Decision Processes (RMDPs). It shows the sample complexity under different data oracle settings (generative model, offline dataset, interactive data collection) and model assumptions, highlighting the improvements achieved by OPROVI-TV in the interactive data collection setting under the vanishing minimal value assumption.
Full paper#



















