↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Dataset condensation aims to create smaller, representative datasets for training deep learning models, saving resources and improving efficiency. However, existing methods have limitations such as high computational costs or suboptimal design choices. These limitations hinder the scalability and overall effectiveness of dataset condensation, especially for large datasets.
This paper introduces a novel framework, Elucidating Dataset Condensation (EDC), that addresses these issues. EDC uses a uni-level optimization paradigm with carefully chosen design choices, including soft category-aware matching and a smoothing learning rate schedule. These techniques lead to a state-of-the-art performance on several benchmarks, outperforming existing methods in both accuracy and efficiency, especially on large datasets such as ImageNet-1k. The researchers provide both empirical evidence and theoretical analysis to support their design choices.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep learning and data-centric AI. It introduces a novel framework for dataset condensation, a technique to significantly reduce training data size without performance loss. This addresses the growing demands of advanced deep learning models and provides valuable insights into optimizing the design space, impacting model training efficiency and resource management. The findings also offer promising new avenues for continual learning, neural architecture search, and training-free network slimming.
Visual Insights#

This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a flowchart of the EDC process, highlighting key design choices such as flatness regularization, soft category-aware matching, real image initialization, and weak augmentation. The right panel presents a comparison of different configurations of EDC on ResNet-18 with an IPC (Images Per Class) of 10, showing the top-1 accuracy on ImageNet-1k and the time spent on data synthesis for each configuration. CONFIG G represents the final, integrated EDC model.
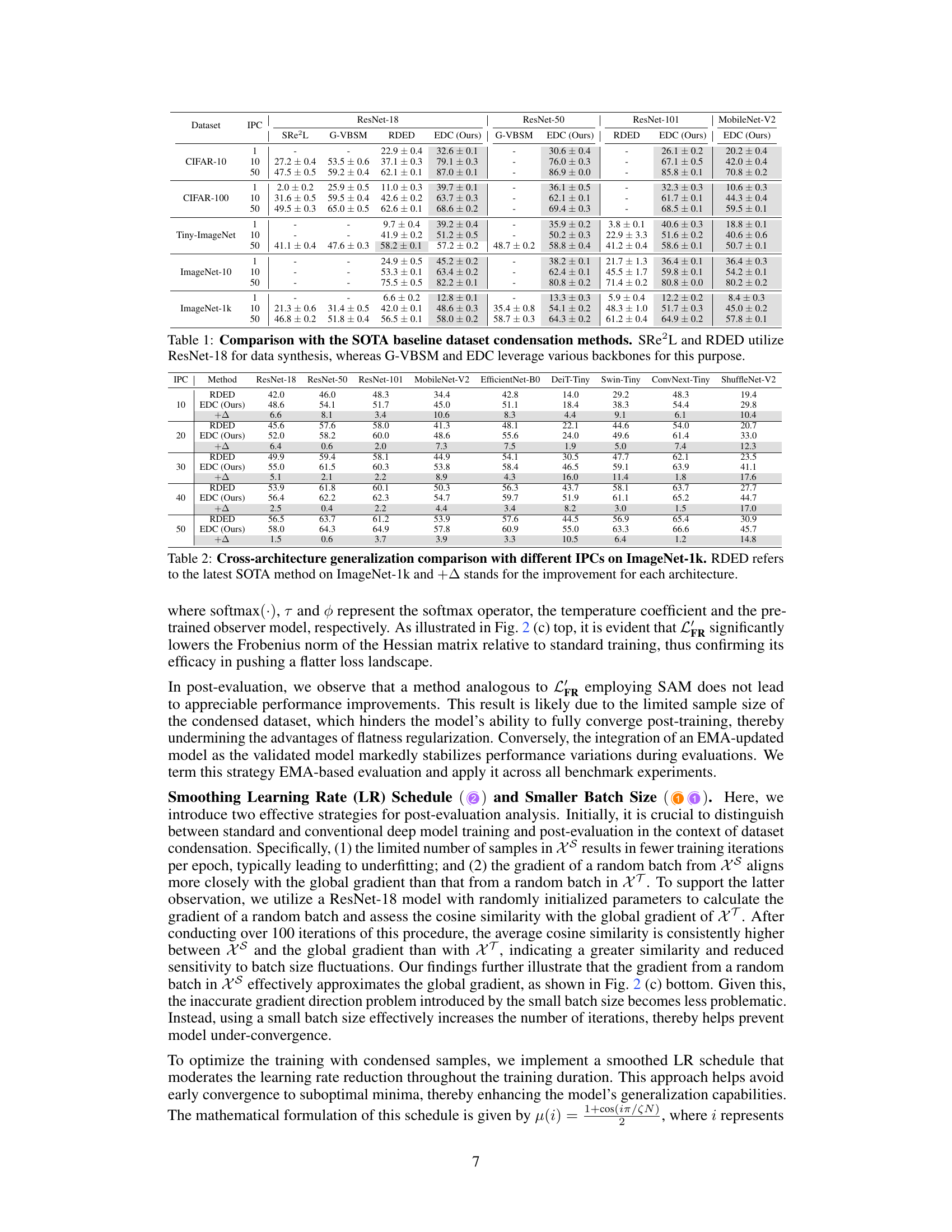
This table compares the performance of the proposed EDC method with three state-of-the-art (SOTA) baseline dataset condensation methods (SRe²L, G-VBSM, and RDED) across various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and different image per class (IPC) values. The table highlights EDC’s superior accuracy compared to the baselines, particularly in scenarios with high compression ratios (low IPC). The use of different backbones for G-VBSM and EDC is also noted.
In-depth insights#
Condensation Design#
Dataset condensation, a crucial aspect of data-centric AI, aims to create smaller, representative datasets. Effective condensation design hinges on several key factors. Data synthesis strategies are paramount, with choices ranging from simple random sampling to sophisticated generative models, each impacting the realism and diversity of the condensed dataset. The quality of soft labels, assigned to the synthetic data, profoundly influences model training, requiring careful consideration of techniques like teacher-student distillation. Finally, evaluation methods must be robust and reliable, often involving techniques that account for potential biases or limitations in smaller datasets, Hyperparameter optimization is another key component and must be done carefully to ensure optimal performance. A thoughtful condensation design balances these elements, taking into account computational constraints and application-specific needs to achieve superior data efficiency while preserving model accuracy.
Improved EDC#
The concept of ‘Improved EDC’ suggests advancements over a pre-existing dataset condensation method, likely called ‘EDC’. These improvements probably focus on enhancing the efficiency and effectiveness of the original method. Improved data synthesis techniques are likely a key aspect, possibly through more sophisticated matching mechanisms or novel data generation approaches. Enhanced soft label generation is also probable, maybe by incorporating more informative labels or refining the label assignment process. Streamlined post-evaluation strategies could optimize the condensed dataset’s performance assessment, possibly by employing more advanced evaluation metrics or employing efficient validation techniques. Overall, ‘Improved EDC’ aims to address limitations inherent in the original EDC by optimizing the entire dataset condensation pipeline, from data synthesis to final evaluation, resulting in a more robust and efficient method. Key improvements likely involve reducing computational costs while simultaneously enhancing the quality and generalizability of the resulting condensed dataset, and ensuring the new method provides superior accuracy and efficiency compared to previous approaches.
Ablation Studies#
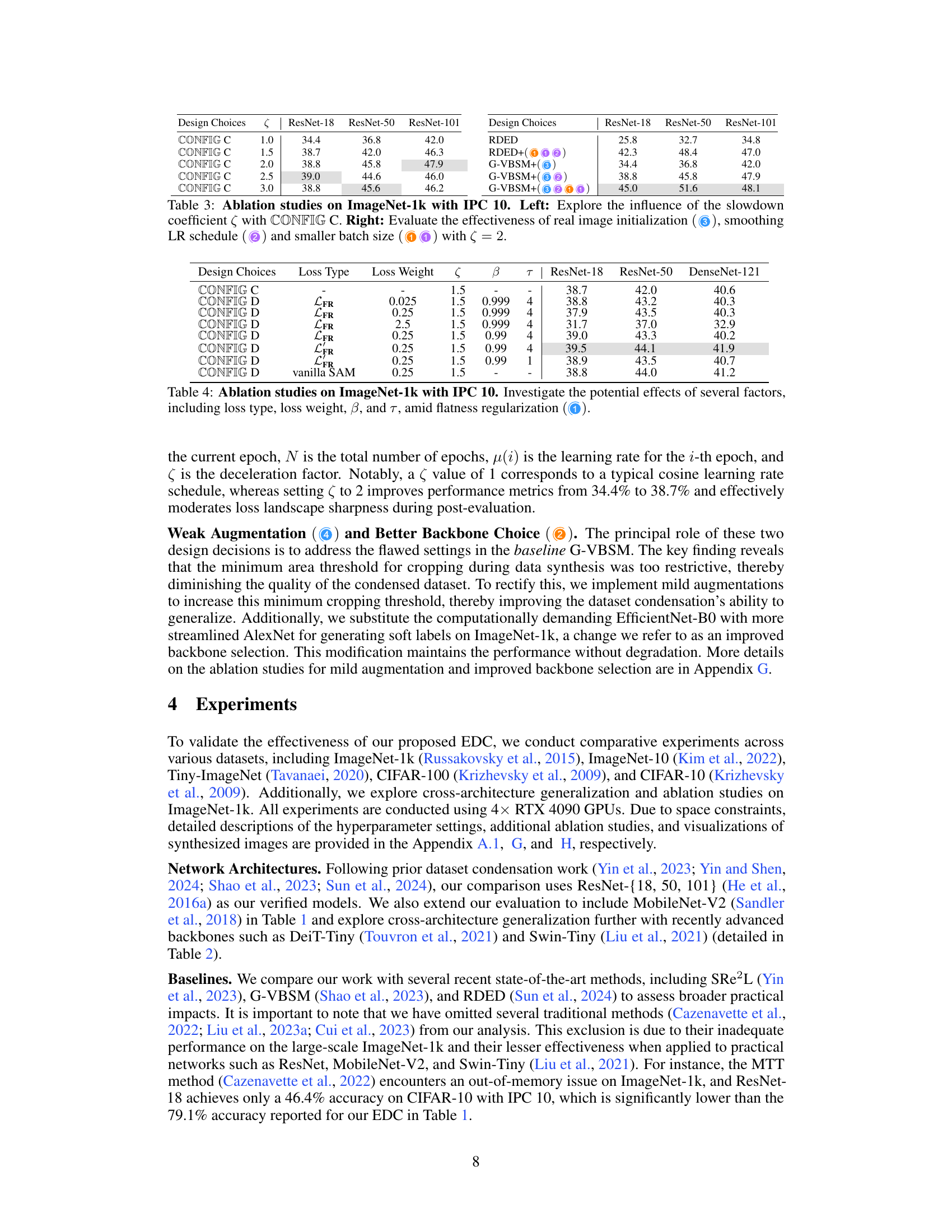
Ablation studies systematically investigate the contribution of individual components or design choices within a complex system. In the context of a research paper, ablation studies help isolate the impact of specific elements by removing them and measuring the resulting change in performance. This allows researchers to understand which features are essential and which ones are redundant or even detrimental. Well-designed ablation studies are crucial for establishing causality and supporting claims about a method’s effectiveness. They move beyond simple comparisons by providing insights into the interactions between different parts of the system. For instance, in machine learning, an ablation study might involve removing regularization techniques, specific layers in a neural network, or data augmentation strategies to understand their effects on model accuracy, generalization, and training efficiency. By carefully analyzing the effects of these changes, researchers can gain a deeper understanding of the mechanism underlying the method’s success, as well as identify potential areas for improvement or future research. The results of ablation studies are usually presented in tables or figures, showcasing the performance differences between the complete system and variations with components removed. The rigor and thoroughness of these studies directly contribute to the credibility and impact of the research.
Large-Scale Results#
A dedicated ‘Large-Scale Results’ section would delve into the performance of the proposed dataset condensation method on substantial, real-world datasets. It would likely present quantitative results comparing the method’s accuracy, efficiency (in terms of time and computational resources), and generalization ability against existing state-of-the-art techniques. Key metrics would include top-1 and top-5 accuracy, compression ratio, training time, and perhaps parameter counts of the trained models. The section would need to showcase the method’s scalability, demonstrating its effectiveness on datasets significantly larger than those used in smaller-scale experiments. Visualizations such as graphs showing accuracy versus compression ratio or training time would be beneficial. A discussion of any challenges encountered when scaling to a larger scale, and the strategies used to overcome these challenges, would strengthen the analysis. The results should be presented in a clear and concise manner, allowing for easy comparison and interpretation. Robustness analysis, evaluating performance across different model architectures or under noisy conditions, could also be incorporated to demonstrate the method’s generalizability and reliability.
Future Research#
Future research directions stemming from this dataset condensation work could explore several promising avenues. Extending EDC to even larger datasets beyond ImageNet-1k, such as JFT-300M, would be a significant undertaking. Investigating the impact of different architectures and model sizes on EDC’s performance is also crucial. Developing more sophisticated matching mechanisms that go beyond simple statistical measures, perhaps incorporating semantic understanding or adversarial training, could enhance the quality and realism of condensed datasets. Another key area for future work is improving the theoretical understanding of EDC’s performance, including rigorous analysis of its generalization capabilities and convergence properties. Finally, it would be beneficial to explore the application of EDC to other data-centric learning tasks, such as data augmentation and federated learning, to further demonstrate its versatility and usefulness.
More visual insights#
More on figures
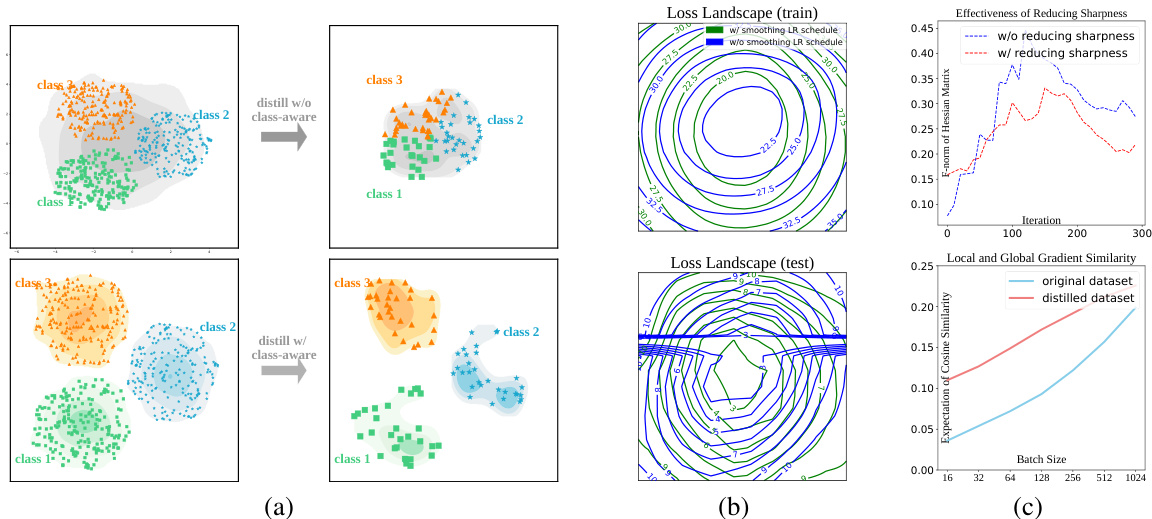
This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a flowchart summarizing the key design choices incorporated into EDC for ImageNet-1k dataset condensation, highlighting improvements in data synthesis, soft label generation, and post-evaluation. The right panel presents a comparison of different configurations of EDC, showcasing the impact of individual design choices on model accuracy and training time using a ResNet-18 model with an IPC of 10. This comparison demonstrates the effectiveness of the complete EDC framework (CONFIG G).

This figure compares the data synthesis process using real image initialization versus random initialization (using Gaussian noise). It shows three stages of the synthesis process (iterations 1, 20, and 1000) for both methods. Real image initialization starts with actual images from the original dataset, leading to more realistic and coherent image generation over the iterations. Random initialization, starting with noise, produces less realistic and more distorted images, especially in the initial stages. The figure visually demonstrates how real image initialization leads to better image quality and potentially improved model performance after the condensation process.
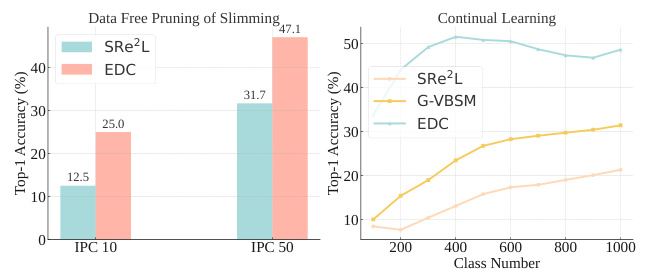
This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a summary of the key design choices that contribute to EDC’s improved performance on ImageNet-1k. The right panel presents a quantitative comparison of different configurations of EDC, highlighting the impact of these design choices on accuracy and computational efficiency. Each configuration is evaluated using ResNet-18 with an IPC (Images Per Class) of 10. The ‘CONFIG G’ refers to the complete EDC model, representing the optimal configuration.

This figure displays example images generated by three different dataset condensation methods: SRe2L, CDA, and G-VBSM. These methods are all categorized as training-dependent. The images are meant to illustrate the quality of the synthetic data created by these methods. In particular, it highlights that these methods, which begin data synthesis with Gaussian noise, tend to produce images that lack realism and fail to convey clear semantics. This supports a main point of the paper that previous approaches had significant limitations and demonstrates the need for a new approach.
This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a flowchart summarizing the key design choices for dataset condensation, emphasizing improvements over existing methods. The right panel presents a quantitative comparison of different configurations of EDC, highlighting the impact of individual design choices (e.g., soft category-aware matching, smoothing learning rate, etc.) on the final performance (accuracy and time cost) when using a ResNet-18 model with an IPC of 10 on the ImageNet-1k dataset. CONFIG G represents the complete EDC approach.

This figure illustrates the proposed Elucidating Dataset Condensation (EDC) method. The left panel shows a flowchart summarizing the design choices made for data synthesis, soft label generation, and evaluation stages. The right panel presents a table comparing different configurations of EDC, showing their top-1 accuracy on ImageNet-1k using a ResNet-18 model with an IPC of 10, and the time taken for data synthesis. The best performing configuration is labeled as CONFIG G, representing the complete EDC method.

This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows the key design choices integrated into EDC, categorized into three stages: Data Synthesis, Soft Label Generation, and Post-Evaluation. The right panel presents a comparison of different EDC configurations on ResNet-18 with an IPC of 10, highlighting their accuracy, training time, and resource utilization. The configurations (CONFIG A-G) represent incremental improvements to the approach, with CONFIG G representing the final, optimized EDC model.

This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a summary of the design choices that improved the performance of dataset condensation on ImageNet-1k. The right panel presents a comparison of different configurations of EDC on ResNet-18 model with an IPC of 10, showcasing the trade-offs between accuracy, time spent for data synthesis, and other factors. CONFIG G represents the complete and optimized EDC approach.

This figure illustrates the Elucidating Dataset Condensation (EDC) framework. The left panel shows a summary of the key design choices incorporated into EDC for improving dataset condensation on ImageNet-1k. The right panel presents a quantitative comparison of different configurations of EDC, highlighting the impact of each design choice on the model’s accuracy and the time required for data synthesis using a ResNet-18 model with an IPC of 10. The final configuration, denoted as CONFIG G, represents the complete EDC method.

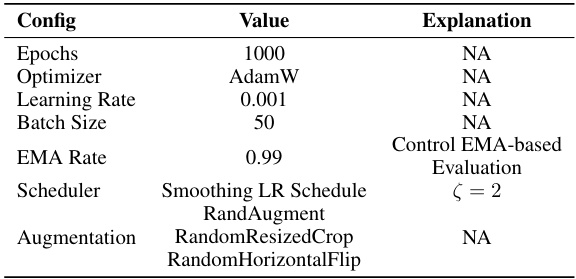
This figure illustrates the proposed Elucidating Dataset Condensation (EDC) method. The left panel shows a flowchart summarizing the key design choices that improve EDC’s performance, including real image initialization, soft category-aware matching, smoothing LR schedule, and EMA-based evaluation. The right panel presents a table comparing different configurations of EDC on ResNet-18 with an IPC of 10, showing their top-1 accuracy, time spent for data synthesis, batch size, memory usage and other hyperparameters. CONFIG G represents the complete EDC model.
More on tables
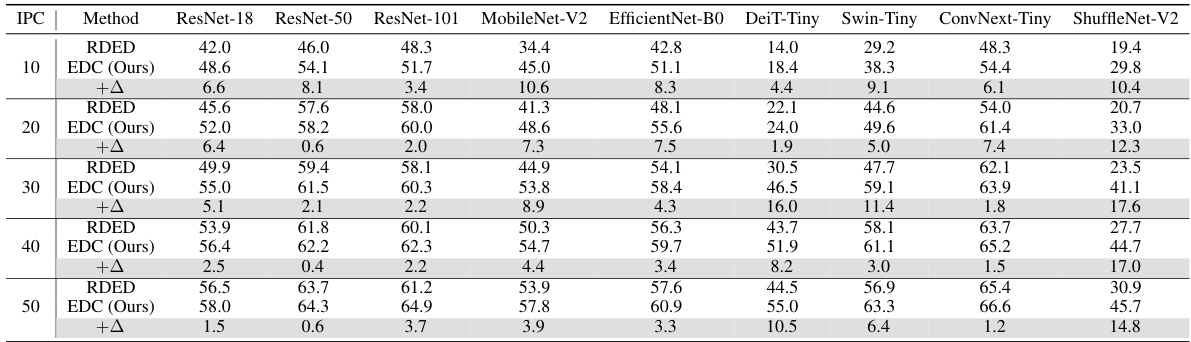
This table compares the performance of the proposed EDC method against three state-of-the-art (SOTA) baseline methods for dataset condensation across different datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and image processing compression (IPC) rates. The table highlights the superior accuracy achieved by EDC, especially at higher IPC values, demonstrating its efficiency and effectiveness in various settings and model architectures.

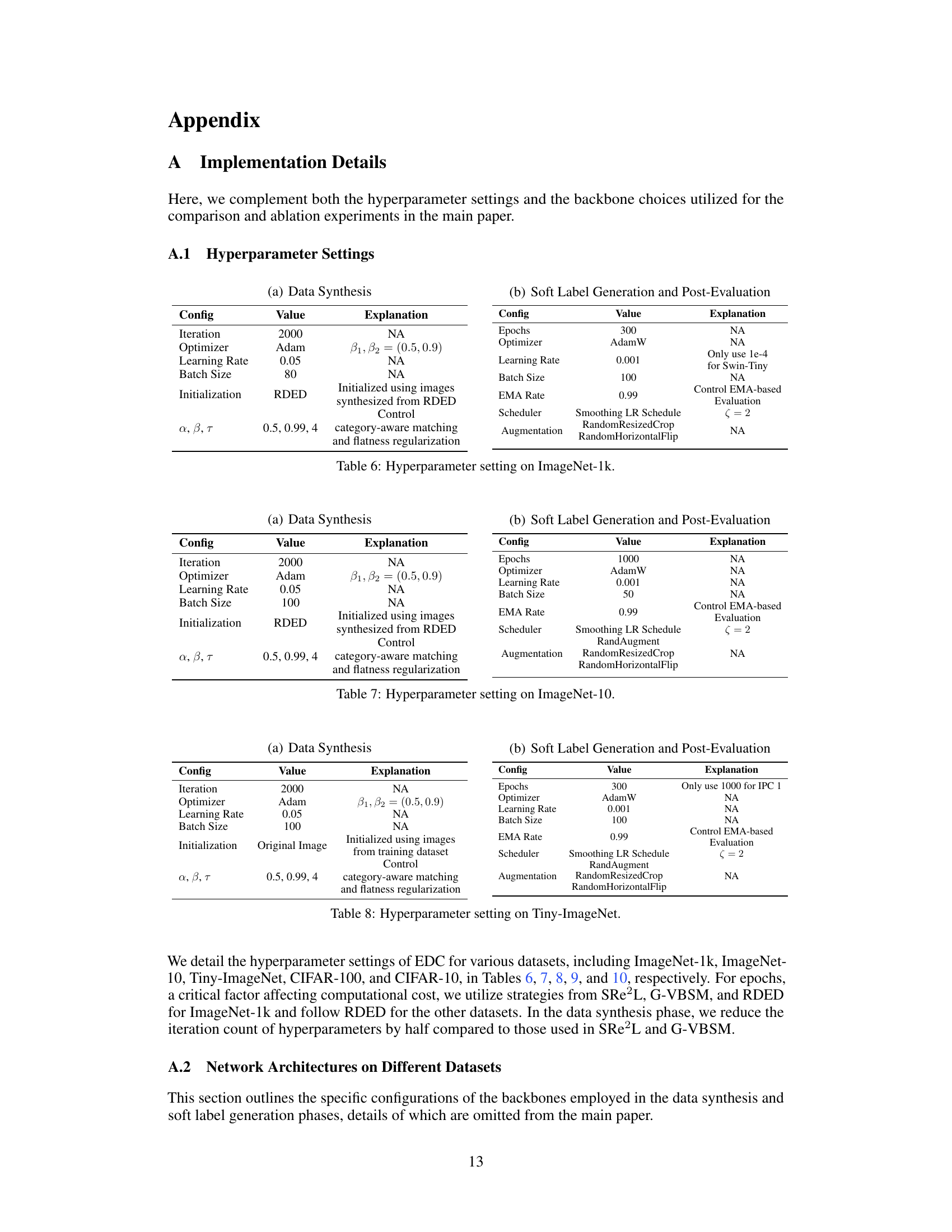
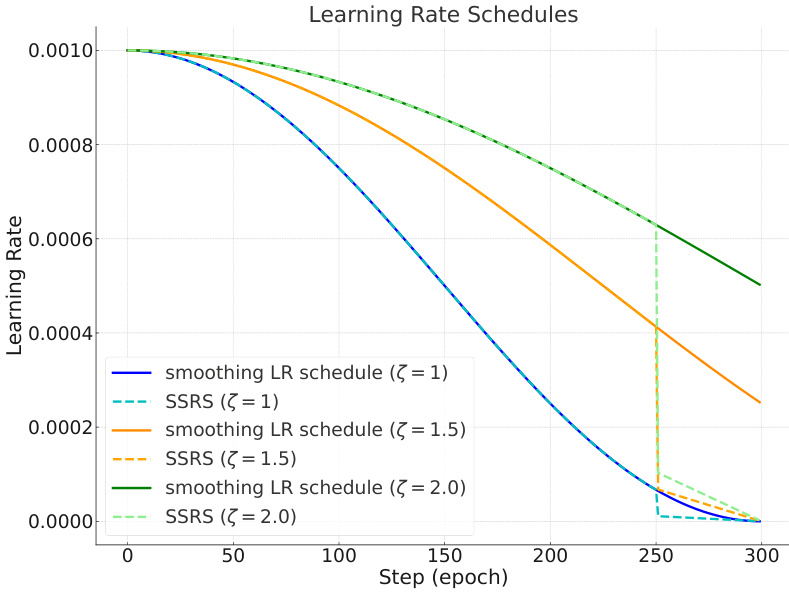
This ablation study on ImageNet-1k with an IPC of 10 investigates the impact of several design choices on model performance. The left half of the table shows the effect of varying the slowdown coefficient (ζ) in the smoothing learning rate schedule on ResNet-18, ResNet-50, and ResNet-101 architectures. The right half evaluates the combined effects of real image initialization, smoothing learning rate schedule, and a smaller batch size, showing the performance improvements achieved through these modifications.
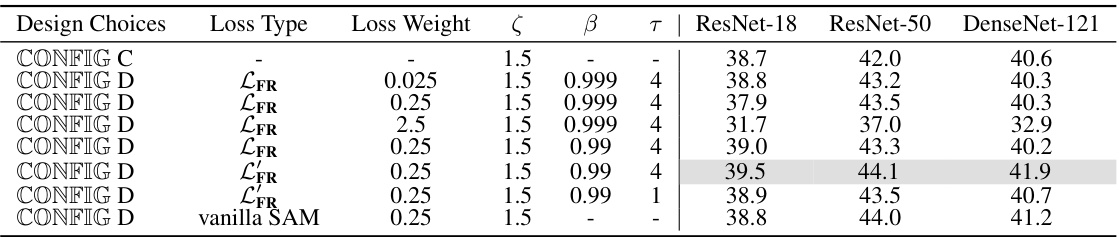
This table presents ablation study results on ImageNet-1k with an IPC of 10. It examines the impact of different choices in the flatness regularization strategy on model performance across various network architectures (ResNet-18, ResNet-50, DenseNet-121). Specifically, it investigates the effects of varying the loss type (LFR, L’FR, vanilla SAM), loss weight, and hyperparameters β and τ on the final accuracy achieved.
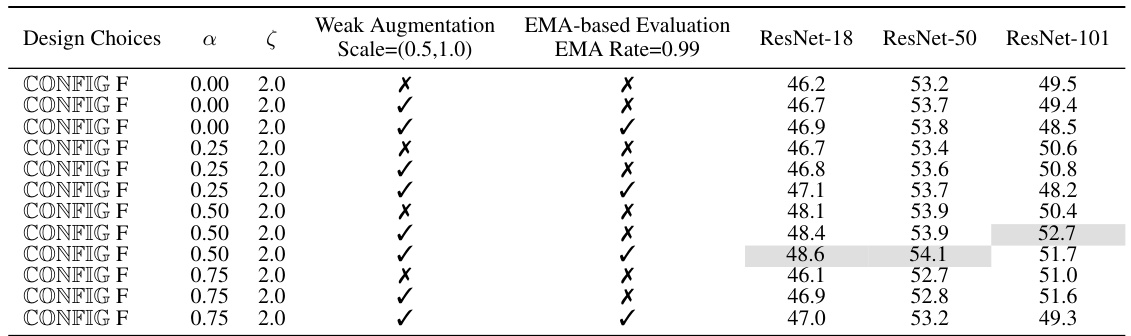
This table presents the ablation study results on ImageNet-1k with an IPC of 10. It investigates the impact of several design choices on the model’s performance. The design choices include soft category-aware matching (parameter α), weak augmentation (scale parameter ζ), and EMA-based evaluation. The table shows the Top-1 accuracy achieved by ResNet-18, ResNet-50, and ResNet-101 models under different configurations of these design choices. Each row represents a different combination of the design choices, allowing for an analysis of their individual and combined effects on the model’s accuracy.
This table compares the proposed EDC method with three state-of-the-art (SOTA) baseline dataset condensation methods (SRe2L, G-VBSM, and RDED) across various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and different image per class (IPC) values. It shows the top-1 accuracy achieved by each method on each dataset and IPC. Notably, it highlights that while SRe2L and RDED use ResNet-18 for their data synthesis, G-VBSM and EDC utilize multiple different backbone network architectures.
This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method against state-of-the-art (SOTA) baseline methods for dataset condensation. It shows the top-1 accuracy achieved on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) using different Image Processing Counts (IPC) values and different network architectures (ResNet-18, ResNet-50, ResNet-101, MobileNet-V2). The results demonstrate that EDC outperforms SOTA methods across various datasets, IPCs, and model architectures. Note that SRe²L and RDED use ResNet-18 for data synthesis, while G-VBSM and EDC use a variety of backbone networks.
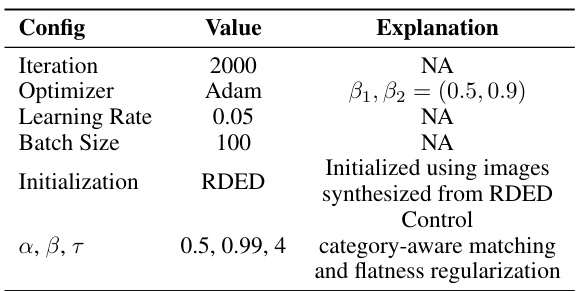
This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method with state-of-the-art (SOTA) baseline methods for dataset condensation. The comparison is made across different datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and at various Image Per Class (IPC) values, representing different compression ratios. It highlights EDC’s superior accuracy and efficiency compared to SOTA methods, especially at higher compression ratios (lower IPC). Note that while SRe2L and RDED use ResNet-18 for data synthesis, EDC and G-VBSM explore the use of various backbones.
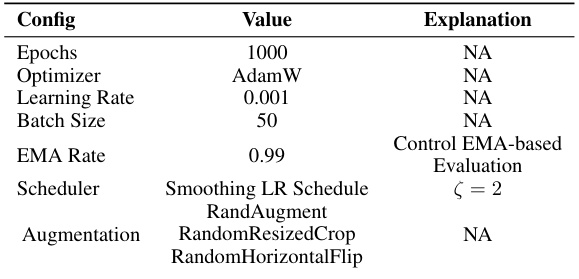
This table compares the performance of the proposed Elucidate Dataset Condensation (EDC) method with state-of-the-art (SOTA) baseline methods for dataset condensation. It shows the top-1 accuracy achieved on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) using different image per class (IPC) values. The table also highlights that while SOTA methods like SRe2L and RDED use ResNet-18 for data synthesis, EDC utilizes a variety of backbones, demonstrating its adaptability and superior performance.
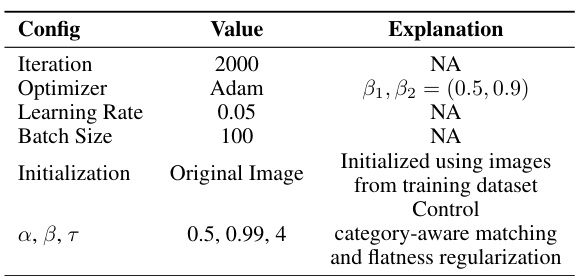
This table compares the proposed Elucidating Dataset Condensation (EDC) method with other state-of-the-art (SOTA) dataset condensation methods. The comparison is made across several datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and different image processing computation (IPC) values (1, 10, 50). The table shows the top-1 accuracy achieved by each method for each dataset and IPC. Importantly, it highlights that EDC outperforms the other methods in almost all scenarios, underscoring its effectiveness. The table also notes that SRe²L and RDED use ResNet-18 for the data synthesis process, whereas G-VBSM and EDC utilize a broader range of backbones, adding to the versatility of the EDC approach.
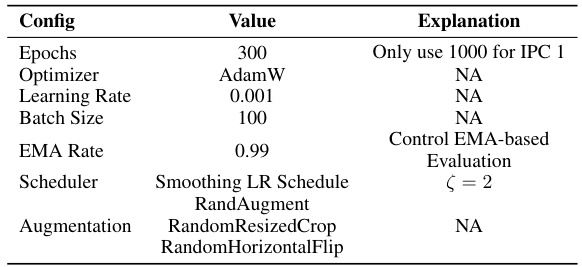
This table compares the performance of the proposed EDC method with other state-of-the-art (SOTA) dataset condensation methods across several datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) at different IPC (Images Per Class) values. It shows the top-1 accuracy achieved by each method, highlighting the superior performance of EDC across various datasets and model architectures (ResNet-18, ResNet-50, ResNet-101, and MobileNet-V2). Note that SRe2L and RDED used ResNet-18 for data synthesis, while G-VBSM and EDC utilized multiple backbones.

This table compares the performance of the proposed Elucidate Dataset Condensation (EDC) method with state-of-the-art (SOTA) baseline methods for dataset condensation on various datasets and image classification tasks. It shows the top-1 accuracy achieved by different methods on several datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) at different Image Per Class (IPC) ratios. The table highlights that EDC outperforms SOTA methods, especially at lower IPC values (higher compression ratios), demonstrating its superior efficiency and effectiveness in transferring critical attributes to smaller synthetic datasets.
This table compares the proposed Elucidating Dataset Condensation (EDC) method with other state-of-the-art (SOTA) dataset condensation methods. It shows the top-1 accuracy achieved on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) at different IPC (Images Per Class) values. The table highlights EDC’s superior performance across different datasets and model architectures (ResNet-18, ResNet-50, ResNet-101, MobileNet-V2), particularly at higher compression ratios (lower IPC values). It also notes that while some SOTA methods use a single model architecture (ResNet-18), EDC uses a variety of models for comparison.
This table compares the performance of the proposed Elucidate Dataset Condensation (EDC) method with three state-of-the-art (SOTA) baseline methods (SRe²L, G-VBSM, and RDED) for dataset condensation on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and different image processing counts (IPC). The table shows that EDC consistently outperforms the other methods across all datasets and IPCs. Note that SRe²L and RDED use ResNet-18 for data synthesis, while G-VBSM and EDC use a variety of backbones.
This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method against state-of-the-art (SOTA) baseline dataset condensation methods, namely SRe²L, G-VBSM, and RDED. The comparison is done across various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and at different Image Per Class (IPC) values. It highlights EDC’s superior accuracy and efficiency, especially at higher compression ratios (lower IPC). The use of ResNet-18 for the SOTA baselines vs. varying backbones for EDC is also noted.

This ablation study investigates the impact of different numbers of backbones on the performance of G-VBSM for CIFAR-10 dataset with IPC 10. It compares the original 5 backbones used in G-VBSM against using 100 backbones (MTT) and a new setting of 8 backbones to show the optimal backbone combination for better performance. The results demonstrate that the new backbone setting improves the accuracy across ResNet-18, AlexNet and VGG11-BN.

This ablation study investigates the impact of different backbone choices for the data synthesis stage of the EDC method on ImageNet-1k using an IPC of 10. The table shows the top-1 accuracy achieved using ResNet-18 as the verified model, varying the observer model across different architectures (ResNet-18, MobileNet-V2, EfficientNet-B0, ShuffleNet-V2, WRN-40-2, AlexNet, ConvNext-Tiny, DenseNet-121). The results highlight the relative performance of each backbone in this specific stage of the dataset condensation process.

This table presents the ablation study results on the ImageNet-1k dataset with an IPC of 1, focusing on the impact of different backbone choices for soft label generation within the EDC framework. The experiment uses CONFIG G (with ς = 2). The table shows that the combination of ResNet-18, MobileNet-V2, EfficientNet-B0, ShuffleNet-V2 and AlexNet for soft label generation results in the best performance.

This ablation study investigates the impact of the slowdown coefficient (ζ) in the smoothing learning rate schedule on the performance of the MobileNet-V2 model for ImageNet-1k dataset condensation with an IPC of 10. The results show how different values of ζ affect the model’s top-1 accuracy.
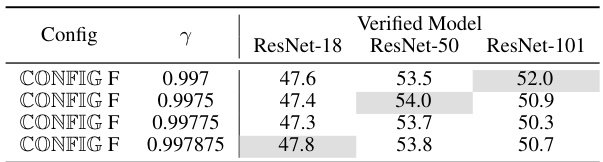
This ablation study investigates the impact of different Adaptive Learning Rate Scheduler (ALRS) settings on the performance of the model after dataset condensation on ImageNet-1k with an IPC of 10. The table shows that while ALRS doesn’t provide a clear performance boost, certain settings achieve results close to the optimal configuration.

This table presents ablation study results on ImageNet-1k with an IPC of 40, focusing specifically on evaluating the impact of different learning rate schedulers during the post-evaluation phase. It compares the performance of using a standard smoothing learning rate schedule against the proposed early Smoothing-later Steep Learning Rate Schedule (SSRS). The results show that SSRS improves performance without introducing additional computational overhead.

This table presents the ablation study on the impact of EMA Rate on the performance of the EMA-based evaluation method on ImageNet-1k with an IPC of 10. Different EMA Rates were tested (0.99, 0.999, 0.9999, 0.999945) and their corresponding top-1 accuracy is reported. The results show that a specific EMA Rate is most effective for this setting.

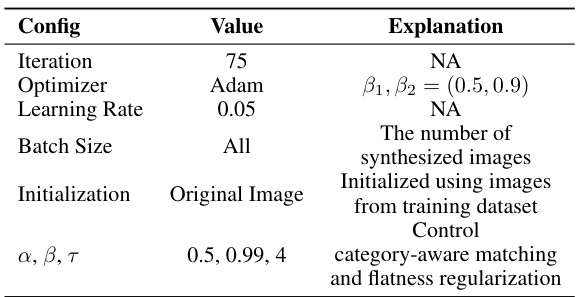
This ablation study investigates the effect of the number of iterations during the post-evaluation phase on the performance of the dataset condensation method EDC on the CIFAR-10 dataset with an IPC of 10. ResNet-18 is used as the backbone network for both data synthesis and soft label generation. The hyperparameters are kept consistent with those used in the RDED method. The table shows that the optimal number of iterations is 75, as it achieves the highest accuracy of 42.7%.

This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method with three state-of-the-art (SOTA) baseline dataset condensation methods: SRe2L, G-VBSM, and RDED. The comparison is done across multiple datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and different image processing compression ratios (IPC). The results show that EDC consistently outperforms the baseline methods across all datasets and IPCs, demonstrating its superior accuracy in dataset condensation.

This table compares the proposed EDC method with state-of-the-art (SOTA) baseline dataset condensation methods (SRe2L, G-VBSM, RDED) across different datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, ImageNet-1k) and image per class (IPC) values. The table highlights the superior accuracy achieved by EDC, particularly at higher IPC values, showcasing its effectiveness in dataset condensation.

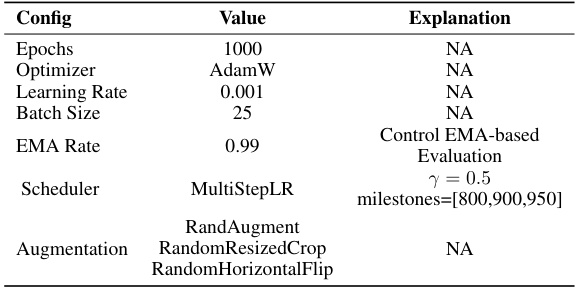
This table presents the ablation study results on CIFAR-10 with an IPC of 10, focusing on the impact of different learning rate schedulers during the post-evaluation phase. The schedulers compared include smoothing LR schedule with two different ζ (slowdown coefficient) values, and MultiStepLR with two different γ (decay rate) values and milestone settings. The hyperparameters for other settings followed those in Table 10. The table shows the top-1 accuracy achieved by different verified models (ResNet-18, ResNet-50, ResNet-101, and MobileNet-V2) under each scheduler configuration.

This table presents a comparison of different dataset condensation methods on the ImageNet-21k dataset. The results show the top-1 accuracy achieved by each method (SRe2L, CDA, RDED, EDC) using a compression ratio of 10, along with the baseline accuracy obtained using the original dataset. It demonstrates the scalability of EDC to larger datasets.

This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method against state-of-the-art (SOTA) baseline methods for dataset condensation. It shows the top-1 accuracy achieved on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) using different Image Processing Counts (IPC) values, representing different compression ratios. The table highlights that EDC outperforms other methods, especially at higher IPC values, indicating its effectiveness in generating high-quality condensed datasets.
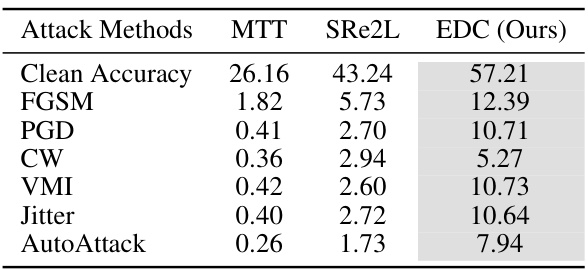
This table compares the performance of the proposed Elucidating Dataset Condensation (EDC) method against state-of-the-art (SOTA) baseline methods for dataset condensation on various datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and at different IPCs (images per class). The table shows that EDC achieves superior accuracy compared to SOTA methods across all datasets and IPCs. Notably, the table highlights that SRe2L and RDED use ResNet-18 architecture for data synthesis, while G-VBSM and EDC use various backbones, demonstrating the versatility and effectiveness of EDC.
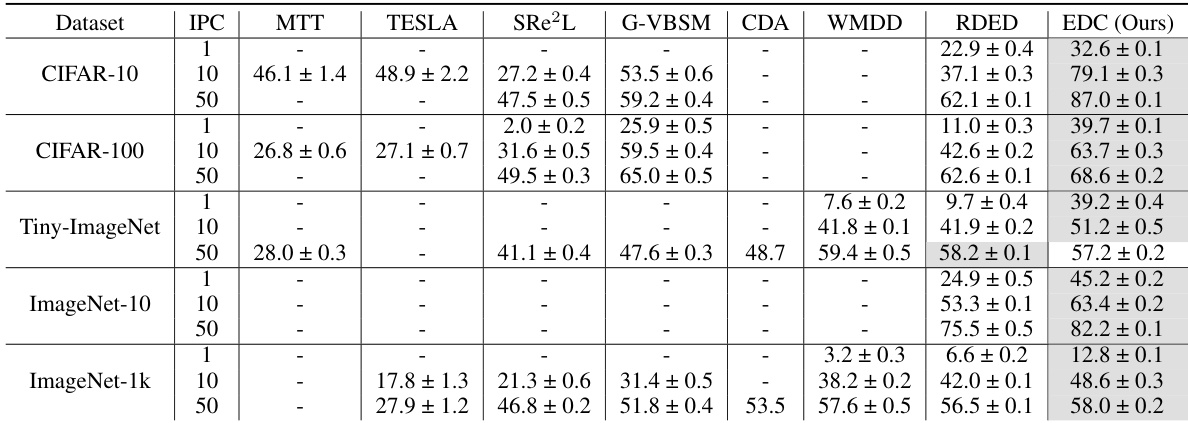
This table compares the performance of the proposed Elucidate Dataset Condensation (EDC) method with state-of-the-art (SOTA) baseline methods for dataset condensation across different datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, ImageNet-10, and ImageNet-1k) and image per class (IPC) values. It highlights EDC’s superior accuracy and efficiency, particularly on larger datasets. Note that different methods use different backbone networks for comparison.
Full paper#