↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Creating high-quality 360° views from limited input images is challenging due to insufficient information and minimal overlap between views. Existing methods often rely on per-scene optimization, making them time-consuming and impractical. This paper addresses these limitations by introducing a novel feed-forward approach that combines geometry-aware 3D reconstruction and temporally consistent video generation.
The proposed method, MVSplat360, effectively leverages a pre-trained Stable Video Diffusion model and renders features directly into its latent space. This allows for efficient rendering of arbitrary views with high visual quality, even from as few as 5 input images. Experiments on benchmark datasets demonstrate that MVSplat360 significantly outperforms existing state-of-the-art methods in terms of visual quality and other metrics.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MVSplat360, a novel feed-forward approach for high-quality 360° novel view synthesis from sparse views. This addresses a critical limitation of existing methods which often require many input images. The method’s superior performance on benchmark datasets opens new avenues for research in efficient 3D scene reconstruction and novel view synthesis, particularly for applications like augmented reality and virtual reality where capturing many images is impractical.
Visual Insights#

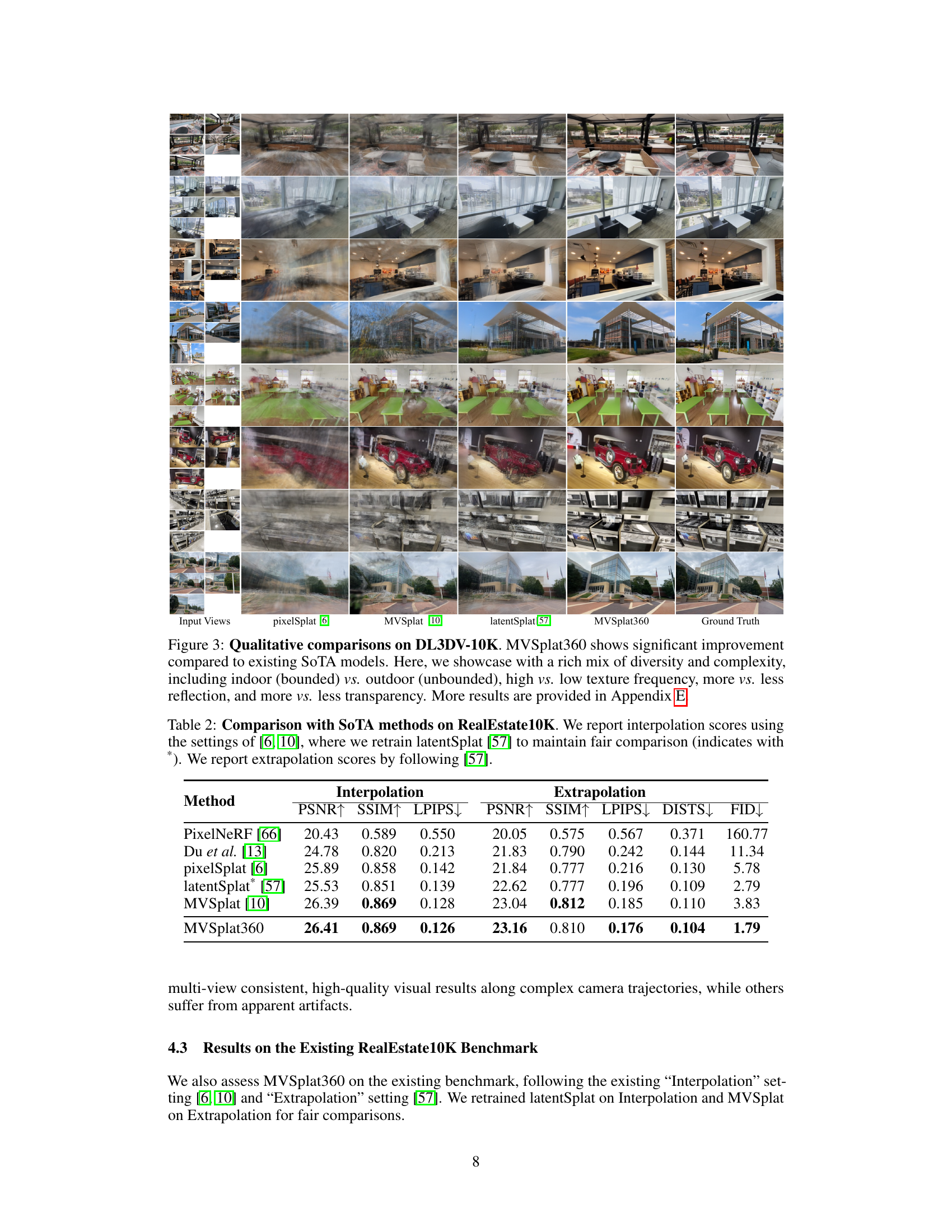
This figure compares the novel view synthesis results of MVSplat360 against other state-of-the-art methods on the DL3DV-10K dataset. It showcases various scenes with diverse characteristics (indoor/outdoor, high/low texture, reflective/non-reflective surfaces) to demonstrate the superior performance and robustness of MVSplat360 in handling challenging conditions. The visual differences highlight MVSplat360’s ability to produce more realistic and detailed novel views, particularly where other methods struggle with artifacts or missing information.

This table compares the performance of MVSplat360 against other state-of-the-art methods on the DL3DV-10K dataset for novel view synthesis tasks. It shows quantitative metrics (PSNR, SSIM, LPIPS, DISTS, FID) for two different settings (n=300 and n=150), representing the temporal distance between input and output views. The results highlight MVSplat360’s superior performance compared to existing methods.
In-depth insights#
Sparse View NVS#
Sparse View Novel View Synthesis (NVS) presents a significant challenge in computer vision, demanding the generation of realistic novel viewpoints from a limited set of input views. This sparsity inherently leads to ambiguity and missing information, making accurate 3D reconstruction and subsequent view synthesis difficult. Traditional methods often rely on dense views, making them unsuitable for this scenario. Feed-forward approaches are particularly attractive for sparse view NVS due to their efficiency, eliminating the need for per-scene optimization. However, these methods must creatively handle the lack of information, potentially leveraging techniques like geometry-aware feature extraction and fusion, latent diffusion models, or other forms of prior knowledge to effectively synthesize plausible novel views. The success of sparse view NVS hinges on effectively addressing the ill-posed nature of the problem, combining robust 3D reconstruction with powerful image generation techniques to produce high-quality, consistent results. Future research should focus on further improving the robustness and accuracy of feed-forward methods for even more extreme sparsity levels.
3DGS-SVD Fusion#
The proposed ‘3DGS-SVD Fusion’ method cleverly combines the strengths of two powerful techniques: 3D Gaussian Splatting (3DGS) for efficient 3D scene representation and Stable Video Diffusion (SVD) for high-quality video generation. 3DGS provides a coarse geometric reconstruction from sparse views, overcoming the limitations of traditional methods which struggle with limited overlap and insufficient information. This coarse reconstruction then acts as crucial input to the SVD model, guiding its denoising process and generating photorealistic views. The fusion is achieved by feeding the 3DGS-rendered features, not raw images, directly into the SVD’s latent space. This ensures that the gradients from the SVD model can properly backpropagate to the 3DGS model, leading to improved reconstruction quality and better alignment between the geometry and appearance. This end-to-end trainable approach is a key innovation, enabling efficient and effective novel view synthesis, even from extremely sparse input views. The effectiveness is further enhanced by incorporating a novel view selection strategy and a latent space alignment loss, which contribute to superior visual quality and robustness in challenging scenarios.
DL3DV-10K Bench#
The DL3DV-10K benchmark, as described in the research paper, is a crucial contribution for evaluating feed-forward 360° novel view synthesis (NVS) methods from sparse input views. It addresses a critical gap in existing benchmarks by specifically focusing on the challenging scenario of synthesizing wide-sweeping or even 360° views from a limited number of widely spaced input images. The benchmark’s use of the DL3DV-10K dataset, with its diversity and complexity of real-world scenes, ensures robust evaluation of NVS algorithms. The creation of new training and testing splits for this specific task, coupled with the introduction of relevant metrics, facilitates a meaningful comparison of different models, pushing the boundaries of current NVS research. The dataset’s size and the range of scenes provide a comprehensive assessment of a method’s capability to synthesize photorealistic 360° views in diverse settings. Therefore, the DL3DV-10K benchmark represents a significant advancement and a valuable resource for researchers in the field of computer vision and 3D scene reconstruction.
Feedforward 360#
The concept of “Feedforward 360” in the context of a research paper likely refers to a novel approach for 360° novel view synthesis (NVS) that utilizes a feedforward neural network architecture. This is a significant departure from traditional methods, which often rely on iterative, per-scene optimization. A feedforward approach promises faster processing speeds and enhanced efficiency, crucial for real-time applications and handling large datasets. The “360°” aspect signifies the system’s ability to generate realistic views from any angle around a given scene, achieving full spherical coverage. This is particularly challenging due to the inherent ill-posed nature of sparse view NVS, requiring the network to effectively infer missing information and handle complex occlusions. The success of such a system would be a major advancement, potentially enabling new applications in virtual reality, robotics, and 3D modeling, where fast and efficient 360° view generation is critical.
Future Work#
Future research directions stemming from the MVSplat360 paper could involve several key areas. Improving the efficiency and scalability of the model to process higher resolution inputs and more complex scenes is crucial. This could involve exploring alternative 3D scene representations or more efficient network architectures. Addressing the limitations in generating photorealistic results in challenging conditions, such as scenes with significant occlusion or limited texture information, could be achieved by incorporating more advanced techniques from image processing or computer graphics. Expanding the model’s capability beyond novel view synthesis, for instance, into tasks like 3D scene editing or manipulation, could significantly broaden the model’s applicability. Exploring different LDM architectures or incorporating more sophisticated conditioning mechanisms into the existing framework could improve the quality and consistency of generated videos. Finally, rigorous evaluation on a broader range of datasets with diverse scene characteristics, including various lighting conditions and object compositions, would validate the model’s robustness and provide valuable insights for future improvements.
More visual insights#
More on figures
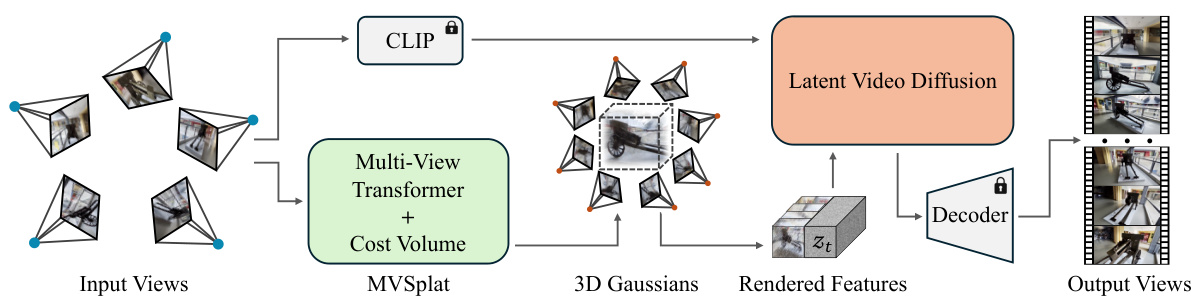
This figure illustrates the overall architecture of the MVSplat360 model. It consists of three main stages: (a) Multi-view feature fusion using a transformer and cost volume to combine information from sparse input views; (b) Coarse 3D geometry reconstruction using a 3D Gaussian Splatting (3DGS) model to obtain a rough 3D representation of the scene; and (c) Appearance refinement using a pre-trained Stable Video Diffusion (SVD) model, conditioned on features from the 3DGS model, to generate photorealistic and temporally consistent novel views.

This figure compares the novel view synthesis results of four different methods (pixelSplat, MVSplat, latentSplat, and MVSplat360) against ground truth images on the DL3DV-10K dataset. It demonstrates the superior visual quality of MVSplat360, particularly in handling scenes with varying levels of complexity (indoor/outdoor, texture, reflections, transparency). The results showcase MVSplat360’s ability to produce more realistic and detailed novel views, especially when compared to other feed-forward methods.

This figure compares the novel view synthesis results of four different methods (pixelsplat, MVSplat, latentSplat, and MVSplat360) on the DL3DV-10K dataset. It highlights the superior performance of MVSplat360 in generating high-quality, visually appealing results across a variety of scene types (indoor/outdoor, high/low texture, reflective/non-reflective). Red boxes highlight specific areas where MVSplat360’s performance is particularly impressive, showcasing its ability to reconstruct details missing from other methods. The ground truth images are also shown for comparison.

This figure shows the results of Structure from Motion (SfM) applied to both the input views and the novel views generated by MVSplat360. The input views are marked with red borders. The SfM process, using VGGSfM, successfully reconstructs the camera poses and a 3D point cloud from both the input and generated views. This demonstrates the multi-view consistency and geometric accuracy of the novel views produced by the MVSplat360 model.

This figure shows the impact of input image resolution on the SVD’s first-stage autoencoder. The autoencoder’s performance is sensitive to resolution differences between training and inference. The images on the left are the original inputs. The middle column shows results when using the original input resolution, illustrating the significant loss of detail. The right column shows the effect of upscaling the input images by a factor of 2 using bilinear interpolation before passing to the autoencoder; this improves results substantially, demonstrating that resolution matching is crucial for effective encoding into the latent space.

This figure compares the visual quality of novel view synthesis generated by MVSplat360 and other state-of-the-art methods on the DL3DV-10K dataset. It showcases the superior performance of MVSplat360 in handling diverse scene complexities, including variations in lighting, texture, and occlusion. The results demonstrate that MVSplat360 produces more visually appealing and realistic novel views than the other methods.

This figure compares the novel view synthesis results of four different methods on the DL3DV-10K dataset. The methods compared are pixelsplat, MVSplat, latentsplat, and the authors’ proposed method MVSplat360. The ground truth images are also shown for comparison. The figure highlights the superior visual quality of MVSplat360, particularly in handling challenging scenes with diverse lighting conditions, levels of texture and occlusion, and indoor vs outdoor settings.

This figure compares the novel view synthesis results of MVSplat360 against other state-of-the-art methods on the DL3DV-10K dataset. It demonstrates MVSplat360’s superior performance in generating high-quality, visually appealing novel views even in challenging scenarios with diverse scene complexities (indoors/outdoors, high/low texture, reflections, transparency). The results highlight the advantages of MVSplat360’s approach in handling scenes with limited overlapping sparse views.
More on tables

This table compares the performance of different methods on the RealEstate10K benchmark dataset for both interpolation and extrapolation tasks. It shows the PSNR, SSIM, LPIPS, DISTS, and FID scores for each method, indicating their ability to generate realistic novel views.
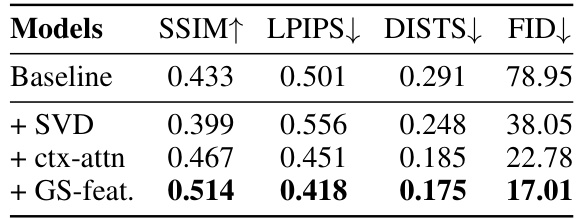
This table presents ablation studies on the MVSplat360 model, evaluating the impact of different components on the model’s performance. The baseline is the original MVSplat model, and the other rows show variations in which specific components are added or modified. These components include the use of a Stable Video Diffusion model (+SVD), incorporating cross attention across views (+ctx-attn), and the use of Gaussian Splat features (+GS-feat) that are fed into the SVD. The results are shown in terms of SSIM, LPIPS, DISTS, and FID metrics, measuring the quality of novel view synthesis.
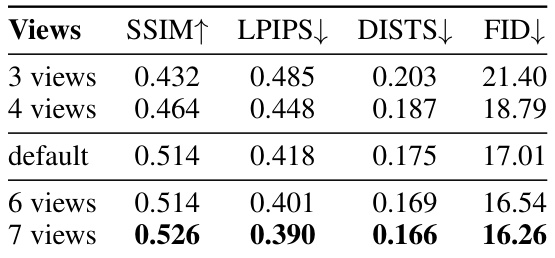
This table presents ablation studies conducted on the DL3DV-10K dataset to analyze the impact of different components and the number of input views on the performance of the MVSplat360 model. The metrics used for evaluation are SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), DISTS (Deep Image Structure and Texture Similarity), and FID (Fréchet Inception Distance). The results show that incorporating the SVD (Stable Video Diffusion) model, cross-attention mechanisms, and the rendering of 3D Gaussian splatting features significantly improves the performance. The number of input views also impacts performance, with better scores obtained using 6 or 7 views compared to using only 3 or 4 views. The ‘default’ row shows the configuration of the model used in the main experiments.
Full paper#