↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models often struggle with generalization, failing to perform well on unseen data. This is due in part to the models learning spurious correlations from the training data, rather than true underlying patterns. Existing methods often focus on modifying model architectures or loss functions to improve this issue.
This paper introduces a new regularization technique called Learning from Teaching (LOT). LOT enhances generalization by using auxiliary student models that attempt to learn the same correlations as a main teacher model. The student models’ success at imitating the teacher’s performance is used as a feedback mechanism to refine the teacher’s learned correlations, helping it to focus on more generalizable features and discard noise. Experiments across multiple domains showed significant improvements in generalization performance, highlighting LOT’s efficiency and potential to improve state-of-the-art models.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel regularization technique, LOT, that significantly improves the generalization ability of deep learning models. LOT addresses a critical challenge in machine learning, enhancing model performance across various tasks and architectures. The findings open new avenues for research, particularly in understanding and leveraging the learning process for enhanced generalization. Its simplicity and effectiveness make it a valuable tool for researchers seeking to improve model performance.
Visual Insights#

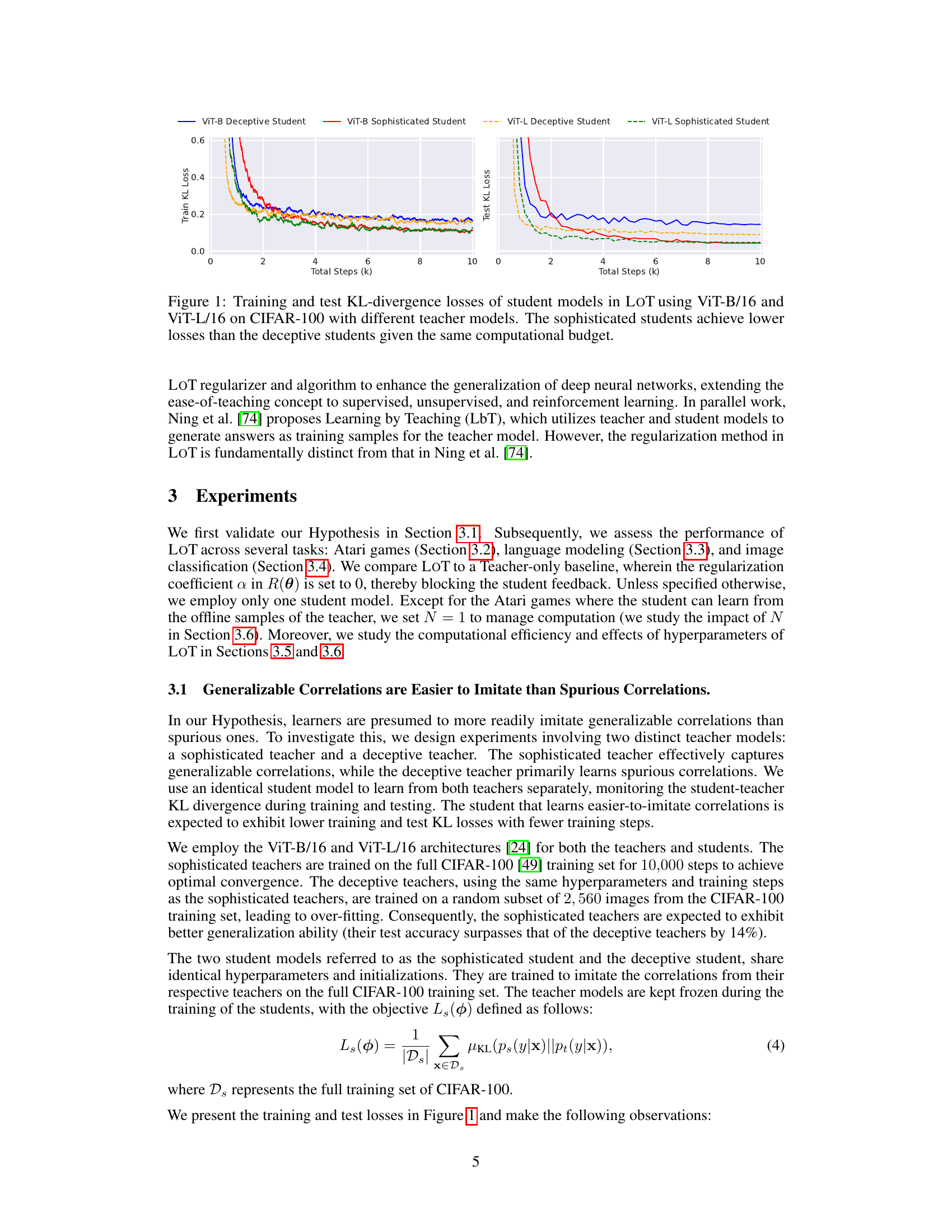
This figure displays the training and testing KL divergence losses for student models trained using the LOT method. Two types of teacher models are used: sophisticated (capturing generalizable correlations) and deceptive (capturing spurious correlations). The results show that student models imitating sophisticated teachers consistently exhibit lower losses during both training and testing compared to students imitating deceptive teachers, even with the same computational resources. This finding supports the hypothesis that generalizable correlations are easier to learn than spurious correlations.

This table presents the test perplexity results for different language models (LSTM, AWD-LSTM, Transformer-XL) trained on two benchmark datasets (PTB and WikiText-103) using both the proposed LOT method and a standard teacher-only training approach. The results are averaged over three runs to demonstrate the consistency of the method. The table highlights the consistent improvement in test perplexity achieved by LOT across various model architectures and datasets.
In-depth insights#
LOT Regularization#
The core of LOT regularization lies in its conceptualization of generalizable correlations as easily imitable patterns by auxiliary student models. The main model (’teacher’) trains student learners, and the ease with which students imitate the teacher’s learned correlations serves as a regularization signal. This operationalizes the idea that simple, generalizable knowledge is more readily transferable. The LOT regularizer, a key component, is calculated based on the difference between the teacher’s and student’s predictions, encouraging the teacher to learn features that are readily imitated and therefore more likely to generalize. The method’s effectiveness stems from its ability to identify and reinforce generalizable patterns while discarding spurious correlations, leading to improvements in various machine learning domains. It’s an innovative approach that blends aspects of knowledge distillation and the concept of ease-of-teaching, offering a novel way to enhance model generalization.
Imitable Correlations#
The concept of “imitable correlations” in machine learning centers on the idea that generalizable patterns are inherently easier to learn and replicate than spurious ones. This is analogous to how humans identify and learn abstract concepts, filtering out noise to focus on fundamental relationships. A model that readily reveals its internal logic, enabling other models (student learners) to effectively reproduce its behavior, is considered to capture these imitable correlations. The ease of imitation acts as a measure of generalizability. Therefore, a regularization technique focusing on this imitability, such as the proposed LOT (Learning from Teaching), can improve a model’s capacity to identify and prioritize true correlations, ultimately enhancing its generalization performance by reducing overfitting and noise sensitivity. This approach leverages the power of collaborative learning and the notion that simplicity and ease of explanation often translate to robust, transferable knowledge.
Atari Game Results#
The Atari game results section likely demonstrates the effectiveness of the proposed method in a reinforcement learning context. It would show how the novel technique improves agent performance across several classic Atari games. Key aspects to look for include the magnitude of performance gains compared to a baseline method (e.g., a standard RL algorithm without the proposed regularization). The results should ideally quantify improvements using metrics like average episodic return or reward, and may also illustrate these gains visually with plots showing learning curves. Consistency across games would strengthen the findings, suggesting that the improvement is a general property of the method, rather than specific to certain game dynamics. A discussion of computational efficiency compared to the baseline would be very important, because computationally expensive methods can be less practical. The results could also explore the sensitivity of performance to hyperparameters and the overall training stability of the approach. Overall, this section will showcase the practical applicability and advantages of the proposed learning method in a challenging RL environment.
LOT’s Efficiency#
LOT’s efficiency is a crucial aspect of its practical applicability. The method’s design incorporates an iterative training process between a teacher model and one or more student models. While this introduces additional computational overhead compared to training a single model, the paper presents evidence suggesting that LOT’s gains in generalization outweigh this cost. Key efficiency improvements stem from LOT’s ability to identify and focus on generalizable data correlations while discarding spurious ones. This allows for faster convergence to a generalized solution. The method’s effectiveness is further enhanced by its flexibility in adapting to varying resource constraints, allowing users to adjust the number of student models based on available computational resources. Experiments across various domains highlight that LOT achieves comparable performance to other methods, often with fewer training steps, demonstrating its efficiency. The authors also make the implementation details publicly available, promoting reproducibility and further exploration of LOT’s efficiency.
Future of LOT#
The “Future of LOT” holds significant promise in advancing machine learning generalization. LOT’s core strength lies in its ability to distinguish between generalizable and spurious correlations, promoting the learning of more robust and readily imitable patterns. Future research could explore different imitability metrics beyond KL-divergence, potentially incorporating techniques from information theory or complexity science. Extending LOT to other learning paradigms, such as unsupervised and reinforcement learning, presents exciting avenues. Investigating the optimal balance between teacher and student model complexity is crucial, as is exploring efficient ways to scale LOT to massive datasets. Addressing potential computational costs associated with multiple student learners through efficient training strategies warrants further research. Finally, investigating the theoretical underpinnings of LOT’s effectiveness, perhaps by connecting it to existing frameworks of generalization theory, would enhance its impact and improve its design.
More visual insights#
More on figures

This figure displays the episodic return of both the LOT (Learning from Teaching) and Teacher-only agents across four different Atari games: BeamRider, Gravitar, UpNDown, and Breakout. The results are averaged over ten independent runs. The shaded area represents the standard deviation across these runs. The graph shows that the LOT agent consistently outperforms the Teacher-only agent in terms of episodic return across all four games. The improvement becomes more significant as the number of training steps (in millions) increases.

This figure shows the training and test KL-divergence losses for four different student models trained using the LOT method. Two models were trained using a teacher model that learned generalizable correlations and two other models were trained using a teacher model that learned spurious correlations. The results demonstrate that the sophisticated students (those that learn generalizable correlations) achieve lower training and test losses than the deceptive students (those that learn spurious correlations), even with the same computational budget.

This figure shows the impact of hyperparameters α and N on the performance of the LOT method. The left panel shows that a regularization coefficient α of 1 yields the lowest test perplexity (a measure of model performance), suggesting a balance between the main task loss and the LOT regularizer is crucial for optimal results. The right panel shows that a moderate student steps ratio N (around 4 or 5) leads to the best teacher model performance, indicating that too little or too much interaction with the student models hinders overall generalization.

This figure shows the training and test KL-divergence losses for student models trained using the Learning from Teaching (LOT) regularization method. Two types of teacher models are used: sophisticated teachers, which effectively capture generalizable correlations, and deceptive teachers, which primarily learn spurious correlations. For each teacher type, two student models are trained: one to imitate the sophisticated teacher and one to imitate the deceptive teacher. The results show that the student models imitating the sophisticated teacher (i.e., those learning generalizable correlations) achieve significantly lower KL-divergence losses during both training and testing, and converge faster, compared to the student models imitating the deceptive teacher. This supports the hypothesis that generalizable correlations are easier to imitate.
More on tables
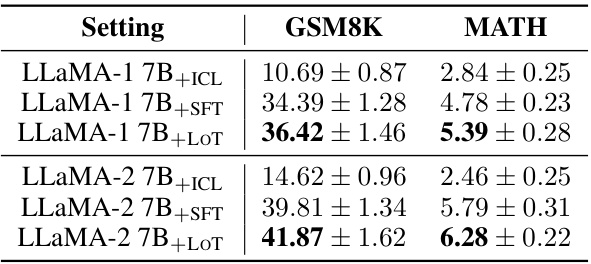
This table presents the accuracy results of the teacher model trained with LOT and compared to the baselines (In-context learning and supervised fine-tuning) on two mathematical reasoning benchmarks: GSM8K and MATH. The results are averaged across three runs, highlighting the performance improvement achieved by LOT.
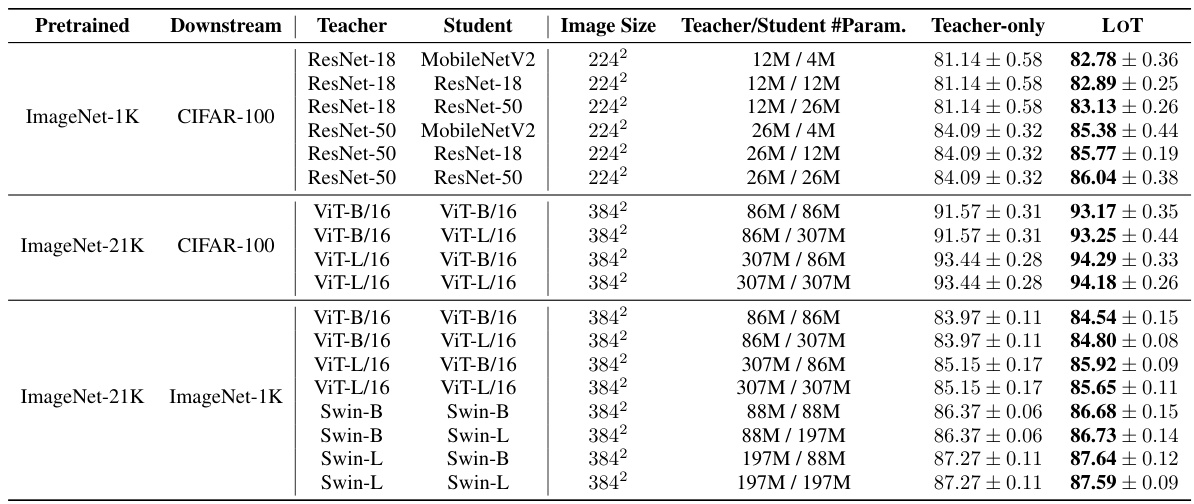
This table presents the test accuracy results for image classification experiments using various teacher-student model combinations. The models were pre-trained on ImageNet-1K or ImageNet-21K and then fine-tuned on CIFAR-100 and ImageNet-1K. Both the ‘Teacher-only’ (no LOT regularization) and ‘LOT’ (with Learning from Teaching regularization) approaches are compared for each combination. The results demonstrate that LOT consistently improves test accuracy across all model combinations.

This table compares the performance of three different methods on the CIFAR-100 dataset: Teacher-only, BAN (Born Again Networks), and LOT (Learning from Teaching). For each method, the table shows the teacher and student model architectures used, and the resulting accuracy. The results demonstrate that LOT consistently outperforms both Teacher-only and BAN, highlighting the effectiveness of LOT in enhancing the generalization capabilities of deep neural networks.
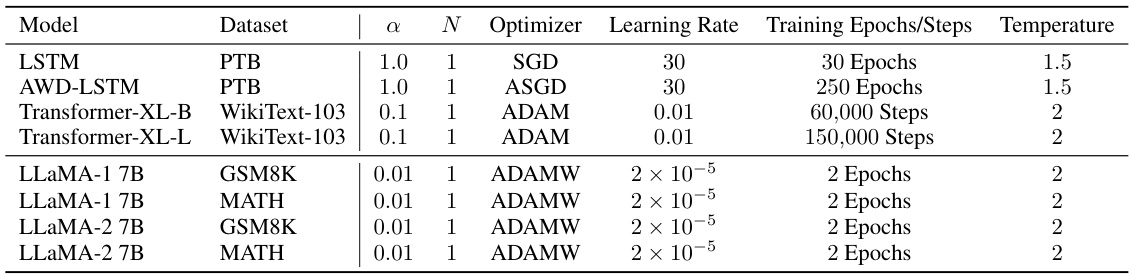
This table lists the hyperparameters used for the language modeling experiments. It specifies the model (LSTM, AWD-LSTM, Transformer-XL-B, Transformer-XL-L, LLaMA-1 7B, LLaMA-2 7B), the dataset (PTB, WikiText-103, GSM8K, MATH), the regularization coefficient (α), the student steps ratio (N), the optimizer (SGD, ASGD, ADAM, ADAMW), the learning rate, the number of training epochs or steps, and the temperature used for the KL divergence calculation.

This table lists the hyperparameters used in the image classification experiments. It shows the model, dataset, alpha (α) value, number of students (N), optimizer, learning rate, training epochs/steps, and temperature used in the LOT experiments for various image classification models and datasets.

This table compares the performance of the teacher model trained with the LOT regularizer and the Teacher-only baseline on image classification tasks using different training steps. It shows that LOT consistently improves the performance of the teacher model, even when using the same number of total training steps.
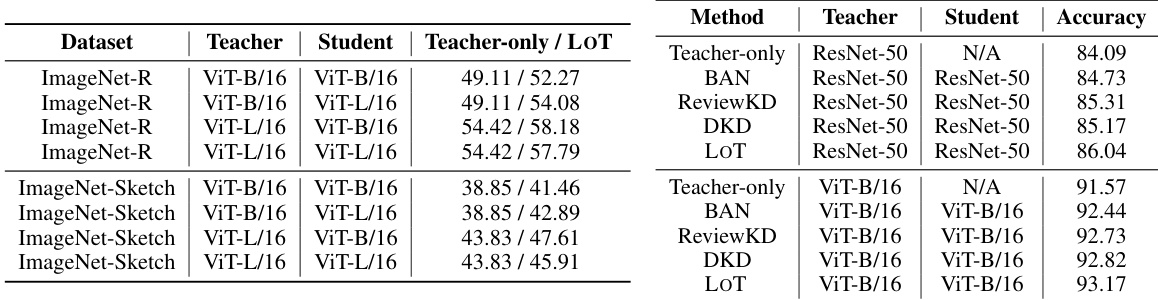
This table presents the performance comparison between the proposed LOT method and the baseline Teacher-only method on two image datasets: ImageNet-R and ImageNet-Sketch. The results are shown for different combinations of teacher and student model architectures (ViT-B/16 and ViT-L/16), demonstrating the impact of LOT on out-of-distribution generalization.

This table shows the test perplexity results for different language models (LSTM, AWD-LSTM, Transformer-XL) trained on two datasets (PTB and WikiText-103) using two methods: LOT (Learning from Teaching) and a baseline (Teacher-only). The results, averaged over three runs, demonstrate that LOT consistently achieves lower perplexity (better performance) across various model architectures and datasets.

This table presents the test perplexity results for language modeling experiments on the Penn Treebank (PTB) and WikiText-103 datasets. The results compare the performance of the teacher model trained with the proposed Learning from Teaching (LOT) regularization against a baseline (Teacher-only) model, for different model architectures (LSTM, AWD-LSTM, Transformer-XL). The perplexity, a measure of how well a language model predicts a sample of text, is lower for the LOT models across all architectures and datasets, demonstrating the effectiveness of the LOT regularization technique in improving generalization.

This table details the computational resources, memory usage, and training time required for both LOT and Teacher-only methods across various tasks (Atari game, language modeling, image classification). It provides a comprehensive comparison of resource utilization and training efficiency for different models and datasets, highlighting the computational overhead introduced by the student models in LOT while showing that the total training time is often comparable or even lower than that of Teacher-only, demonstrating the efficiency of LOT.

This table presents the results of experiments conducted to evaluate the performance of using L2 loss as the imitability metric in the LOT regularizer, compared to using KL-divergence. The experiment used the CIFAR-100 dataset, with different combinations of teacher and student ViT models (ViT-B/16 and ViT-L/16). The table shows the test accuracy achieved by the teacher model under three different scenarios: the Teacher-only baseline (no LOT regularization), LOT using KL-divergence as the imitability metric, and LOT using L2 loss. The results demonstrate that using L2 loss for the LOT regularizer also improves the generalization performance of the teacher model.
Full paper#