↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Vision-Language Models (LVLMs) typically process a fixed number of visual tokens, limiting flexibility and efficiency. Existing methods often pre-determine the number of tokens, neglecting the potential benefits of dynamic adaptation. This inflexibility hinders deployment on resource-constrained devices and limits the model’s adaptability to various tasks.
This paper introduces the Matryoshka Query Transformer (MQT), a novel technique that allows LVLMs to use a flexible number of visual tokens during inference. MQT achieves this by employing a query transformer with latent tokens, randomly selecting a subset for training. Experiments using MQT-LLaVA show significant improvements in efficiency and a considerable reduction in the number of visual tokens needed, without significant performance loss, across various vision-language benchmarks. The ability to dynamically adjust the number of visual tokens makes MQT-LLaVA extremely versatile and efficient.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large vision-language models (LVLMs) because it introduces a novel approach to significantly improve efficiency without substantial performance loss. The flexible token allocation method presented is highly relevant to current research trends focusing on optimizing LVLMs for various computational constraints, thereby impacting deployment and resource management. This work opens avenues for optimizing resource use in other deep learning models.
Visual Insights#
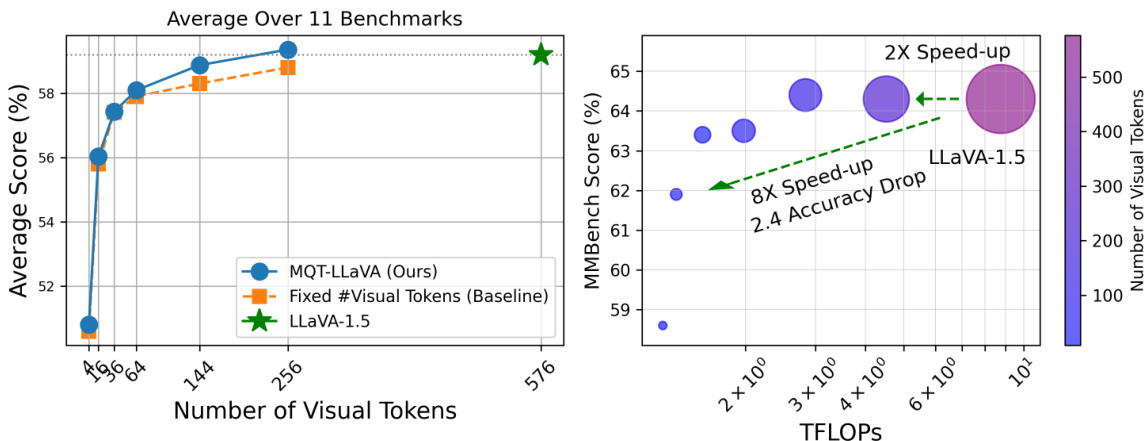
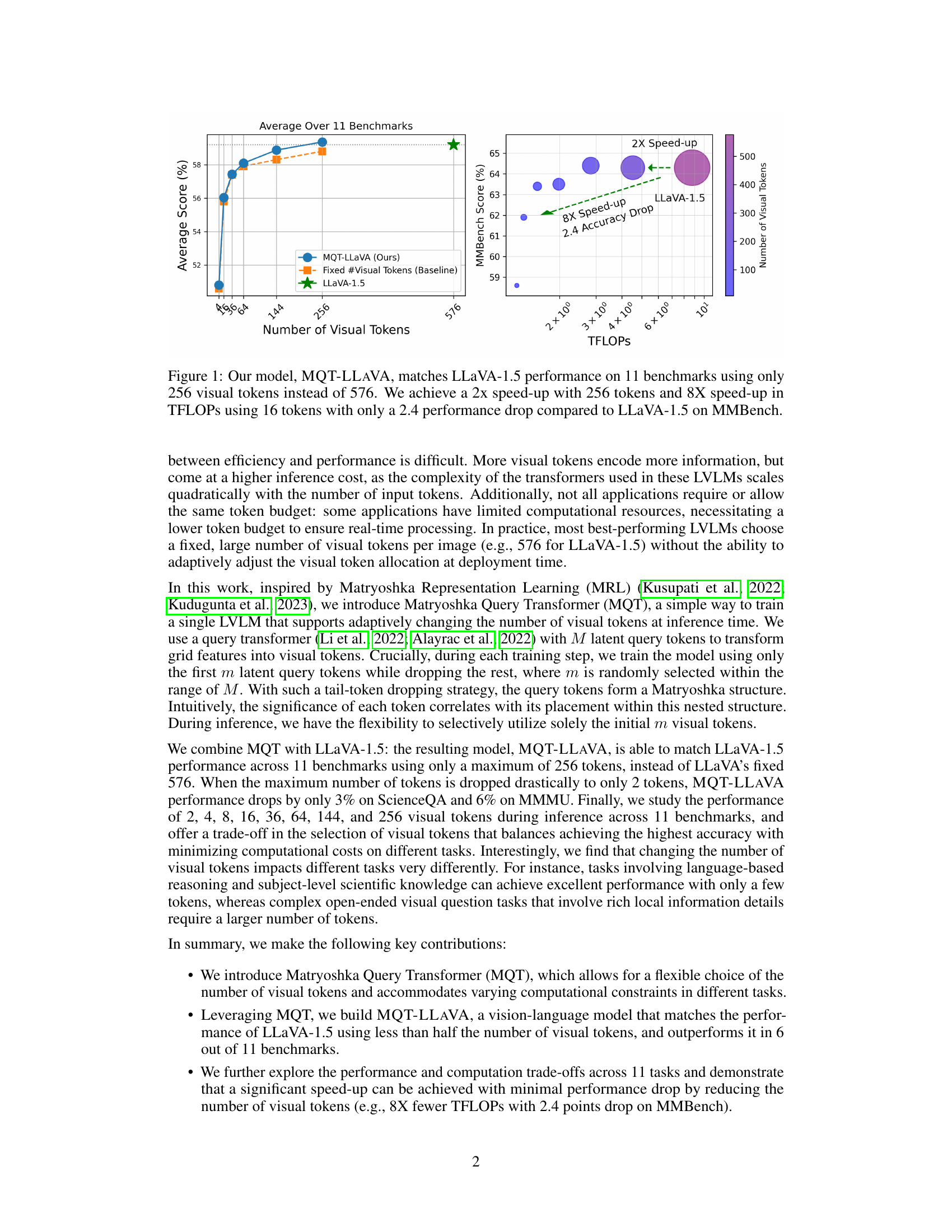
This figure demonstrates the performance and efficiency of the proposed model, MQT-LLAVA, compared to the baseline LLaVA-1.5 model. The left panel shows that MQT-LLAVA achieves similar performance to LLaVA-1.5 across 11 benchmarks while using significantly fewer visual tokens (256 vs 576). The right panel illustrates the computational efficiency gains, showing a 2x speedup with 256 tokens and an 8x speedup with only 16 tokens, at the cost of a small performance drop (2.4 points on MMBench).
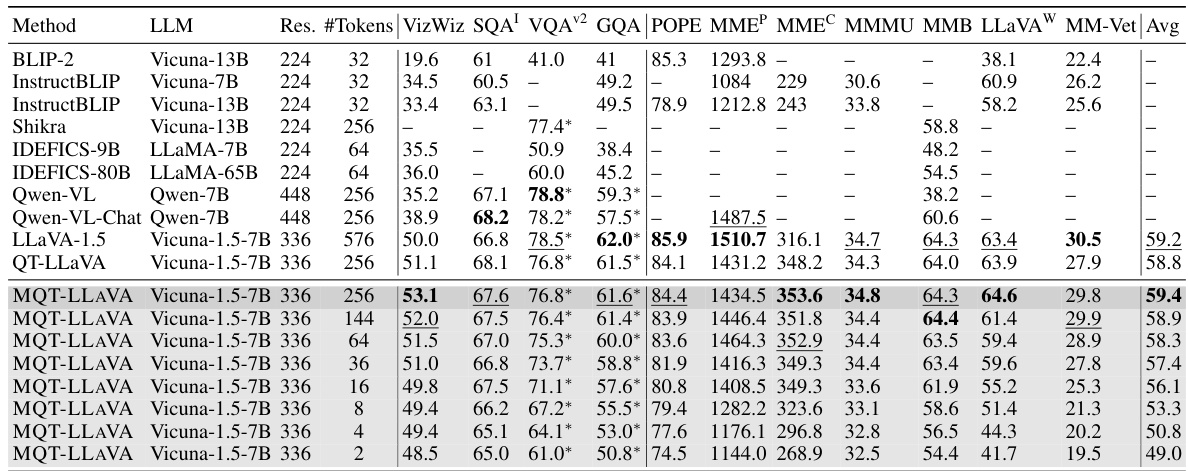
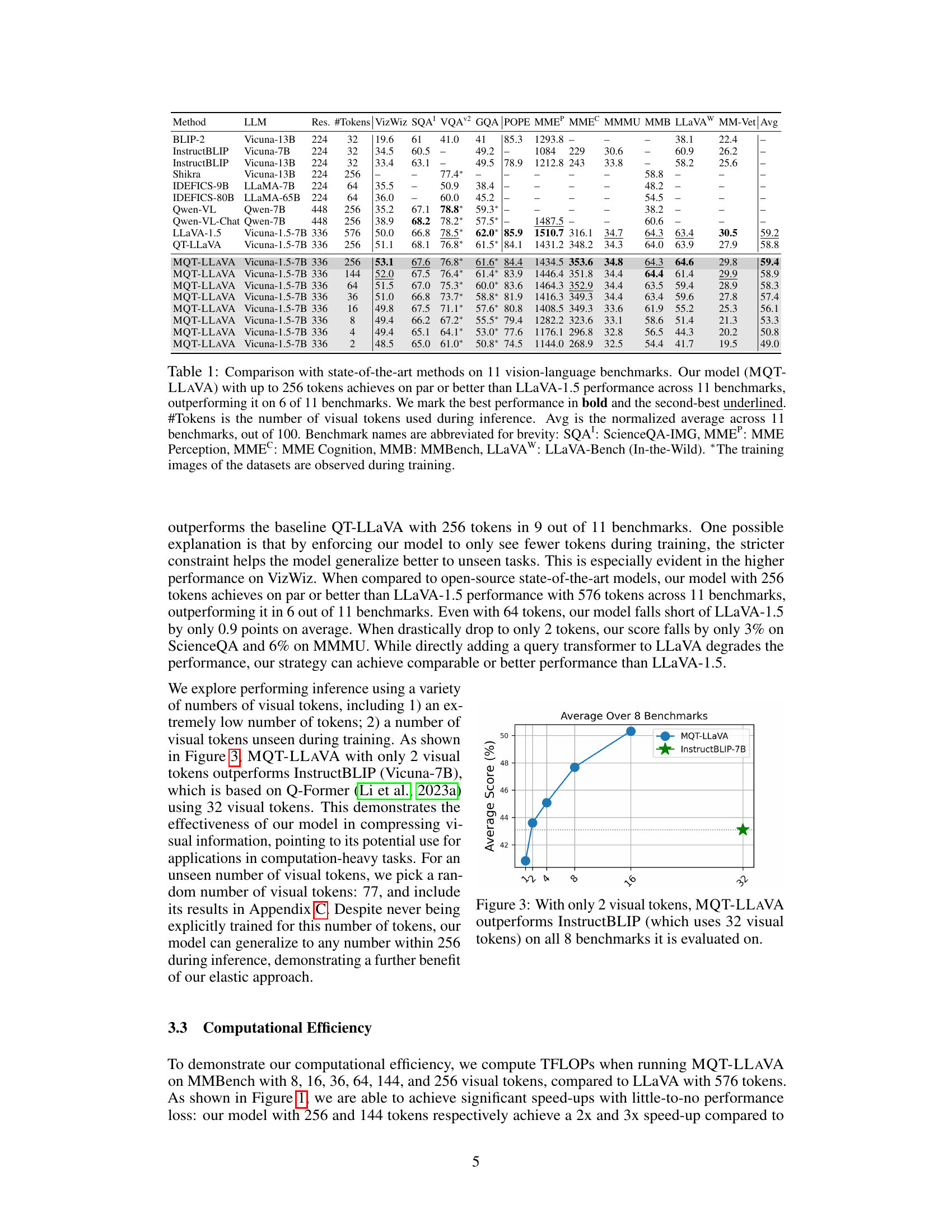
This table compares the performance of MQT-LLAVA with other state-of-the-art vision-language models across 11 benchmark datasets. It shows the average score across the benchmarks for each model, along with the number of visual tokens used and other key details. MQT-LLAVA demonstrates comparable or better performance than LLaVA-1.5 with significantly fewer tokens, highlighting its efficiency.
In-depth insights#
MQT: Core Idea#
The Matryoshka Query Transformer (MQT) introduces a novel approach to image encoding in large vision-language models (LVLMs) by achieving flexible visual token allocation during inference. Instead of a fixed number of visual tokens, MQT employs a query transformer with multiple latent query tokens. During training, a random subset of these tokens is used, discarding the rest. This process, inspired by Matryoshka Representation Learning, creates a nested structure that allows for drastically reduced token counts during inference, while maintaining performance. The flexibility in the number of tokens is key, enabling adaptation to diverse computational constraints and task requirements. This is a significant improvement over existing methods, allowing for efficient processing across various hardware and application scenarios, demonstrating a powerful trade-off between model accuracy and computational cost.
MQT-LLaVA Tests#
Hypothetical “MQT-LLaVA Tests” section would rigorously evaluate the model’s performance across diverse vision-language benchmarks. The tests would likely involve comparing MQT-LLaVA’s accuracy against state-of-the-art models, particularly focusing on the impact of varying the number of visual tokens. Key aspects would be evaluating performance trade-offs, demonstrating that reduced visual tokens maintain accuracy while significantly improving efficiency. This would involve ablation studies, systematically reducing the number of tokens to observe the effects on various tasks’ accuracy. The results would likely reveal a non-linear relationship between token count and performance, with some tasks showing greater robustness to token reduction than others. Detailed analysis of computational costs, measured in TFLOPs, would be crucial to highlight MQT-LLaVA’s efficiency gains. The tests would also include qualitative analyses using visualization techniques like Grad-CAM to illustrate how the model’s focus shifts with varying token numbers, providing insights into the information encoded at different granularities. A comprehensive error analysis, including evaluation of scenarios with both correct and incorrect outputs, would shed light on the model’s strengths and weaknesses.
Token Focus#
The concept of ‘Token Focus’ in vision-language models (VLMs) is crucial for understanding how these models process visual information. A key aspect is the relationship between the number of visual tokens and the granularity of visual features extracted. Fewer tokens might prioritize global scene understanding, emphasizing larger-scale contextual information. Conversely, more tokens allow for finer-grained feature extraction, focusing on smaller details and specific objects within the scene. The model’s attention mechanism plays a central role here, dynamically weighting the importance of different tokens based on the input image and the task at hand. Analyzing the ‘Token Focus’ reveals valuable insights into the model’s interpretation of images and how that relates to its ability to successfully complete visual reasoning tasks. Different tasks likely demand varying levels of token focus, with some requiring only global features while others benefit from detailed local analysis. A deep dive into this relationship is necessary to optimize VLM efficiency and performance across a wider range of tasks.
Efficiency Wins#
The heading ‘Efficiency Wins’ encapsulates a core theme in modern AI research, particularly relevant to large vision-language models (LVLMs). Efficiency is paramount because LVLMs are computationally expensive. A key focus of the research should be on methods to reduce computational cost without sacrificing performance. This could involve optimizing model architectures, employing more efficient training strategies, or developing innovative techniques for processing visual data, such as reducing the number of visual tokens. Balancing efficiency and performance is crucial; minor performance reductions might be acceptable if they lead to significant computational gains, making LVLMs more accessible and deployable on resource-constrained devices. The ultimate goal is to find a sweet spot where the gains in efficiency outweigh any performance trade-offs, achieving the best of both worlds – power and speed.
Future Work#
Future research directions stemming from this Matryoshka Query Transformer (MQT) approach could explore optimizing the token selection process to further enhance efficiency and accuracy. Investigating adaptive mechanisms that dynamically determine the optimal number of visual tokens based on image content and task complexity would significantly improve performance. A promising avenue lies in exploring the integration of MQT with other efficient vision transformers. The effectiveness of MQT across diverse visual modalities, beyond images, such as videos and 3D point clouds, warrants further investigation. Finally, thorough analysis of the trade-offs between accuracy and computational cost at different token counts across various datasets and tasks is crucial to determine the practical applicability of this approach.
More visual insights#
More on figures
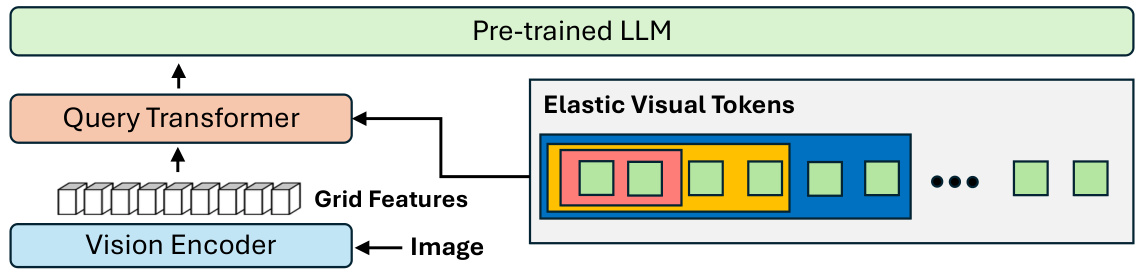
This figure illustrates the architecture of the Matryoshka Query Transformer (MQT). An image is first processed by a vision encoder which extracts grid features. These features are then fed into a query transformer, which generates a variable number of elastic visual tokens (m tokens, where m <= M, and M is the maximum number). The number of visual tokens selected (m) is randomly determined during training but can be flexibly chosen at inference time. The elastic visual tokens are then passed to a pre-trained large language model (LLM) for further processing.

The figure shows a graph comparing the average performance of MQT-LLAVA and InstructBLIP-7B across 8 benchmarks with varying numbers of visual tokens. MQT-LLAVA consistently outperforms InstructBLIP-7B, especially when using only 2 visual tokens.

This figure visualizes how the model’s focus changes with the number of visual tokens used. Grad-CAM is used to highlight the areas of the image that are most important to the model’s prediction for different numbers of tokens (8, 16, 64, 256). The results show that with fewer tokens, the model focuses on high-level concepts, while with more tokens, it attends to low-level details.
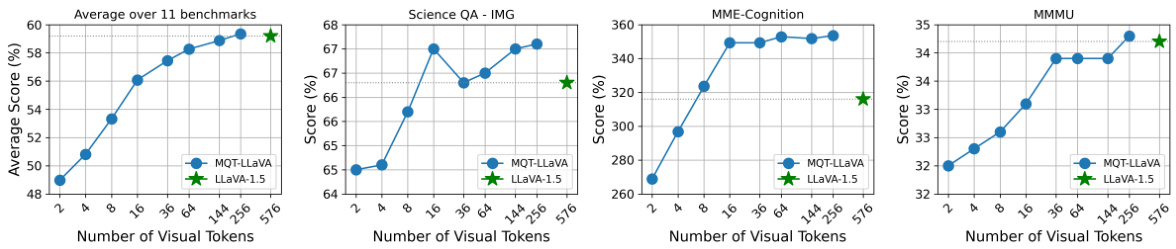
This figure shows a comparison of the performance and computational efficiency of the proposed model, MQT-LLAVA, against the baseline model, LLaVA-1.5, across 11 benchmark datasets. The left panel shows the average score across all benchmarks for different numbers of visual tokens. The right panel shows the relationship between the number of visual tokens and the computational cost (measured in TFLOPs). The results demonstrate that MQT-LLAVA achieves comparable performance to LLaVA-1.5 while significantly reducing the number of visual tokens and the computational cost. Using 256 visual tokens, MQT-LLAVA achieves similar performance as LLaVA-1.5 with a 2x speed-up, while using only 16 tokens results in an 8x speed-up with only a minor performance drop on MMBench.

This figure shows three examples from the MME Cognition benchmark dataset. Each example includes an image and a question. For each example, the Grad-CAM visualization using 16 visual tokens is shown, highlighting the regions of the image that the model focused on when answering the question. The results demonstrate the model’s ability to correctly answer questions by focusing on relevant image regions, even with a relatively small number of visual tokens.

This figure shows Grad-CAM visualizations for two Science-QA questions, comparing model performance using 16 and 144 visual tokens. In the first example (identifying a common property of a tortoise shell, crown, and basketball), the model with 16 tokens correctly focuses on the overall objects and their shared characteristic (opaque), while the model with 144 tokens fails by focusing on individual parts of each object. In the second example (identifying the highlighted state on a US map), the model with 144 tokens correctly identifies Virginia, but the model with 16 tokens makes a wrong prediction by focusing on a different area of the map. This illustrates how the optimal number of visual tokens varies depending on task complexity and the level of detail needed for accurate reasoning.

This figure displays the performance comparison between MQT-LLAVA and LLaVA-1.5 across 11 benchmarks. It highlights MQT-LLAVA’s ability to match LLaVA-1.5’s performance while using significantly fewer visual tokens (256 instead of 576). The chart also demonstrates the computational efficiency gains of MQT-LLAVA, achieving a 2x speed-up with 256 tokens and an 8x speed-up with only 16 tokens, resulting in a minimal performance drop of 2.4 points on MMBench.
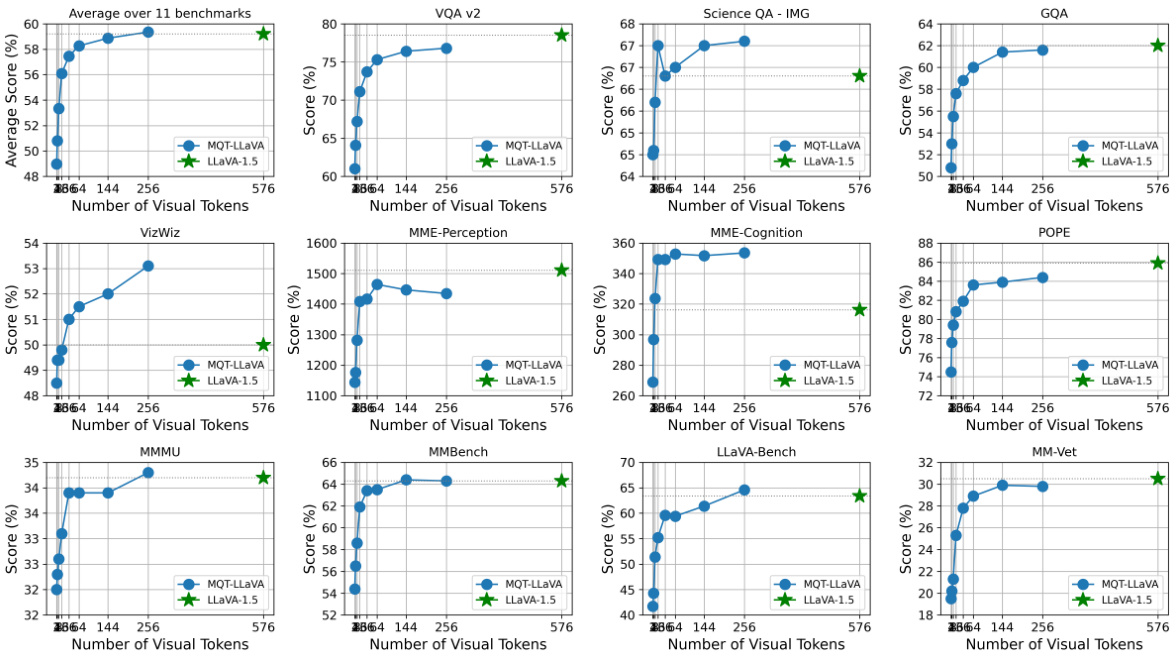
This figure showcases the performance and computational efficiency of MQT-LLAVA compared to LLaVA-1.5 across 11 benchmarks. The left panel demonstrates that MQT-LLAVA achieves comparable performance to LLaVA-1.5 while using significantly fewer visual tokens (256 instead of 576). The right panel highlights the substantial speed-up gained by MQT-LLAVA, especially when using only 16 visual tokens, with a minimal performance decrease compared to LLaVA-1.5 on the MMBench benchmark.
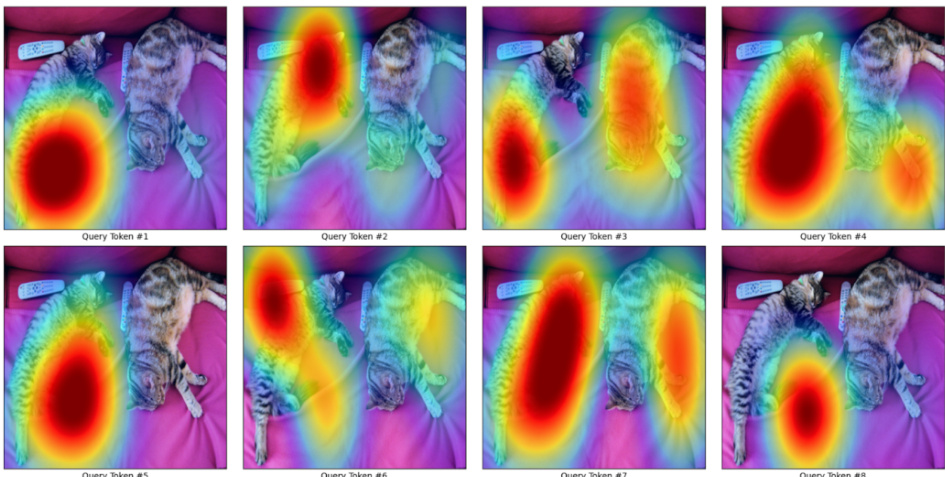
This figure shows Grad-CAM visualizations for different numbers of visual tokens (8, 16, 64, 256). Grad-CAM highlights the image regions that are most important for a particular token’s activation. The visualization demonstrates that with fewer tokens, the model focuses on high-level concepts, while more tokens allow the model to attend to finer details within the image.
More on tables

This table compares the performance of the proposed model, MQT-LLAVA, with other state-of-the-art vision-language models across 11 benchmark datasets. The table shows the average performance across these benchmarks, broken down by the number of visual tokens used (2, 4, 8, 16, 36, 64, 144, 256). It demonstrates that MQT-LLAVA achieves comparable or better performance than LLaVA-1.5 while using significantly fewer visual tokens.

This table compares the performance of the proposed model, MQT-LLAVA, with other state-of-the-art models on 11 vision-language benchmarks. It shows that MQT-LLAVA, even with significantly fewer visual tokens (up to 256 compared to LLaVA-1.5’s 576), achieves comparable or better performance across most benchmarks. The table also highlights the performance trade-offs with different numbers of visual tokens, demonstrating the model’s flexibility.
Full paper#