↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image diffusion models are slow due to their sequential sampling process. Recent diffusion distillation methods aim to speed this up, but they lack the full range of diffusion capabilities, including real image inversion necessary for precise image manipulation. Existing editing methods are computationally expensive and often compromise on either editing fidelity or efficiency.
This research introduces Invertible Consistency Distillation (iCD), a generalized framework that addresses these issues. iCD leverages both forward and reverse consistency models to enable accurate image encoding and decoding in only 3-4 steps. The integration of dynamic classifier-free guidance further reduces reconstruction errors and enhances editability. Results show that iCD, combined with dynamic guidance, is a highly effective tool for zero-shot text-guided image editing, achieving comparable or superior performance to more expensive alternatives.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation and editing because it presents Invertible Consistency Distillation (iCD), a novel framework enabling high-quality image synthesis and accurate image encoding in only a few steps. This addresses the major limitation of existing methods. iCD’s dynamic guidance strategy further enhances efficiency and performance, making real-time text-guided image editing feasible. It opens up new avenues for research on efficient and high-quality image manipulation techniques, bridging the gap between model speed and accuracy.
Visual Insights#

This figure showcases the effectiveness of Invertible Consistency Distillation (iCD) in performing text-guided image editing. The top row displays an original image with a pug’s head, followed by edits transforming the head into a bear, then a pug wearing a hoodie, and finally a raccoon. The bottom row shows similar edits applied to a person’s shirt, changing the color, adding actions (raising the hand), and changing the background. The speed of the image editing is highlighted in the caption, demonstrating its efficiency with iCD.
This table presents the Fréchet Inception Distance (FID) scores and negative log-likelihood (NLL) values for Stable Diffusion 1.5 (SD1.5) noise latents generated using different encoding strategies. The strategies compared include no classifier-free guidance (CFG), dynamic CFG with thresholds of 0.6 and 0.8, and constant CFG. Lower FID scores indicate better image quality, while lower NLL indicates that the generated latents are closer to the true data distribution. The results show that while dynamic CFG produces more realistic latents compared to constant CFG, the best performance is still achieved with no CFG during the encoding phase.
In-depth insights#
Invertible Distillation#
Invertible distillation is a promising technique that combines the benefits of diffusion models and distillation. Invertible refers to the ability to not only generate images from noise but also to encode real images into the model’s latent space, enabling precise image manipulation. Distillation involves compressing a large, computationally expensive model into a smaller, faster one while maintaining comparable performance. This combination is powerful because it allows for efficient, high-quality image editing and generation in a small number of steps. The method’s effectiveness, especially when paired with dynamic guidance, which adjusts the classifier-free guidance over different sampling steps, shows significant potential for real-time, zero-shot text-guided image editing. However, challenges remain, such as accurately reconstructing images, especially those with complex details and potential for misuse with high-quality image generation. Future research will need to address these challenges and explore different applications of invertible distillation. Dynamic classifier-free guidance enhances both generation quality and inversion performance.
Dynamic Guidance#
The concept of “Dynamic Guidance” in the context of diffusion models presents a compelling approach to enhance both the quality and diversity of generated images. Instead of applying a constant classifier-free guidance (CFG) scale throughout the entire sampling process, dynamic guidance strategically adjusts the CFG scale across different noise levels. This technique acknowledges that high CFG scales, while beneficial for achieving high-fidelity results aligned with textual prompts, can also restrict the model’s exploration of the latent space, leading to less diverse outputs. By reducing or even temporarily disabling CFG at specific stages, particularly at high-noise levels, the model gains more freedom to explore and generate more varied results. This dynamic approach helps to balance the fidelity driven by the guidance and diversity attained through exploration. The practical implications are significant, leading to improved image quality for edited images and reducing the likelihood of out-of-distribution results during image inversion. The integration of dynamic guidance within the invertible consistency distillation framework demonstrates a notable efficiency gain, as it leverages the efficiency of distilled models while mitigating the potential downsides of high CFG scales, suggesting this as a powerful tool for future image editing and generation tasks.
Multistep Inversion#
Multistep inversion in the context of diffusion models addresses the challenge of efficiently and accurately reconstructing a high-fidelity image from its latent representation, which is often achieved through a series of denoising steps. A key challenge is handling the complexity introduced by classifier-free guidance (CFG), a technique commonly used to improve image quality and alignment with text prompts. Straightforward inversion methods often struggle with CFG’s impact, leading to substantial reconstruction errors. Multistep approaches aim to mitigate this by strategically incorporating or modifying CFG during the inversion process. This might involve progressively reducing CFG influence as the inversion progresses or employing techniques such as dynamic CFG to manage its effect across different stages of the process. The effectiveness of multistep inversion is critically tied to the balance between computational efficiency and reconstruction accuracy; striking this balance is crucial for practical applications of the technology in text-guided image editing or other image manipulation tasks. Another vital consideration is the choice of consistency distillation framework used. The distillation approach significantly influences the inversion’s efficacy. Therefore, the choice and implementation details of the method are key factors determining the success of multistep inversion, ultimately contributing to enhanced precision and speed in image manipulation.
Editing Perf#
An in-depth analysis of a research paper’s ‘Editing Perf’ section would involve a multifaceted assessment. First, it’s crucial to understand the metrics used to evaluate editing performance. Are they subjective (human judgment) or objective (quantitative measures like LPIPS or FID scores)? A mix of both is ideal for a comprehensive evaluation. The paper should clearly define these metrics, their limitations, and how they relate to the user experience. Second, the dataset used for evaluation is key. Is it representative of real-world images and editing tasks? A diverse dataset increases the generalizability of the findings. Third, the comparison to baselines is essential. How does the proposed method compare to existing state-of-the-art editing techniques? A thorough comparison highlights the unique advantages and disadvantages. Finally, a detailed discussion of failure cases would provide valuable insights into the algorithm’s robustness and limitations. Overall, a strong ‘Editing Perf’ section demonstrates the practical utility and potential impact of the proposed image editing approach.
Future Work#
Future research directions stemming from this invertible consistency distillation (iCD) work could explore several promising avenues. Improving the efficiency of the multi-boundary approach is crucial, potentially through more sophisticated trajectory sampling methods or novel distillation architectures. Investigating alternative dynamic guidance strategies, beyond CADS, to further optimize the balance between generation quality and inversion accuracy warrants attention. Expanding iCD’s application beyond image editing to encompass more complex image manipulation tasks, such as seamless object insertion and removal, would be valuable. A particularly compelling area is extending iCD to video editing, a vastly more challenging but potentially impactful domain. Finally, a thorough exploration of the ethical implications of highly realistic image editing tools, including bias mitigation and safeguard development, is critical for responsible innovation.
More visual insights#
More on figures

This figure illustrates two different strategies for dynamic classifier-free guidance (CFG) in diffusion models. (a) shows the CADS dynamic, where the guidance scale gradually increases from zero to its initial high value over the sampling process. (b) shows another strategy, where the guidance is deactivated for low and high noise levels and used only on the middle time step interval. Both strategies aim to improve distribution diversity without compromising sampling quality.

This figure illustrates the core idea of the Invertible Consistency Distillation (iCD) framework. The framework uses two models: a forward model (fCDm) and a reverse model (CDm). The forward model encodes real images into latent noise, while the reverse model decodes the latent noise into images. The key innovation is the use of multiple boundary points in both models (m > 1). This allows for a deterministic multistep inversion process, improving the accuracy of both encoding and decoding compared to the single-step approach (m = 1). The figure shows examples for single boundary (m=1) and double boundary (m=2) cases.

This figure shows the impact of classifier-free guidance (CFG) on image reconstruction quality during the decoding process of a diffusion model. The left panel (a) presents a graph illustrating the reconstruction error (measured as Mean Squared Error, MSE) for varying CFG turn-on thresholds (T). A threshold of T represents the noise level below which CFG is activated. The graph reveals that using CFG at high noise levels significantly increases reconstruction error, whereas using no CFG or using CFG only at low noise levels leads to good reconstruction. The right panel (b) displays examples of image inversions using different CFG turn-on thresholds. It demonstrates that when CFG is deactivated at higher noise levels (T = 0.4 or T = 0.8), the inversion is faithful, but when CFG is activated at all noise levels (T = 1.0), the inversion quality is severely compromised.

This figure shows the relationship between generation performance (Image Reward) and reconstruction quality (Mean Squared Error) using different settings for dynamic classifier-free guidance (CFG). The left graph (a) plots the MSE against the IR, with different lines showing various T1 and T2 values which control the dynamic CFG. The right image (b) displays example images generated with several of those settings and constant CFG values, highlighting the trade-off between generation quality and image reconstruction fidelity. The optimal tradeoff is at T1=T2=0.8

This figure showcases the results of Invertible Consistency Distillation (iCD) on image editing. The ‘Original’ column displays the initial images. The ‘Editing’ column demonstrates the results of applying iCD for text-guided image editing, which was completed in approximately 0.9 seconds. The examples illustrate that iCD is capable of quickly and effectively editing images while achieving high-quality results comparable to those obtained from more computationally expensive methods. The variety of edits applied further emphasizes the flexibility of iCD in producing diverse image manipulations.

This figure shows the impact of dynamic guidance and preservation losses on the quality of image inversion using the Invertible Consistency Distillation (iCD) method. It visually compares the results of image inversion under various configurations, highlighting the improvements achieved by incorporating dynamic guidance and the preservation losses. The improvements are evident in the enhanced fidelity and detail of the reconstructed images.

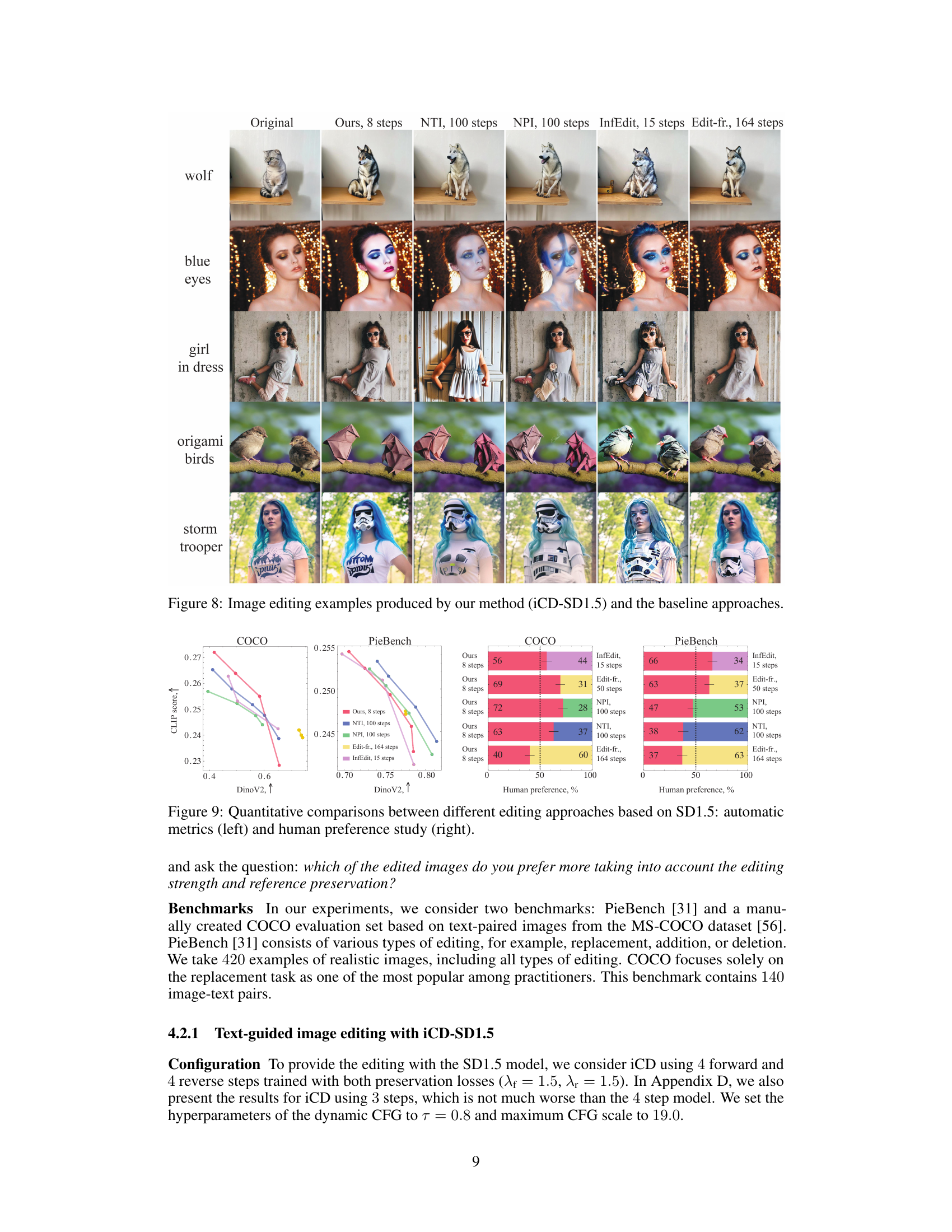
This figure showcases image editing results using the proposed invertible consistency distillation (iCD) method, compared against several baseline techniques. The examples demonstrate the ability of iCD to perform various image manipulations, such as changing attributes (e.g., eye color, clothing), adding elements (e.g., origami birds), and applying stylistic changes (e.g., storm trooper helmet). The comparison visually highlights the effectiveness of iCD in maintaining image quality while achieving desired editing effects, relative to the other methods.

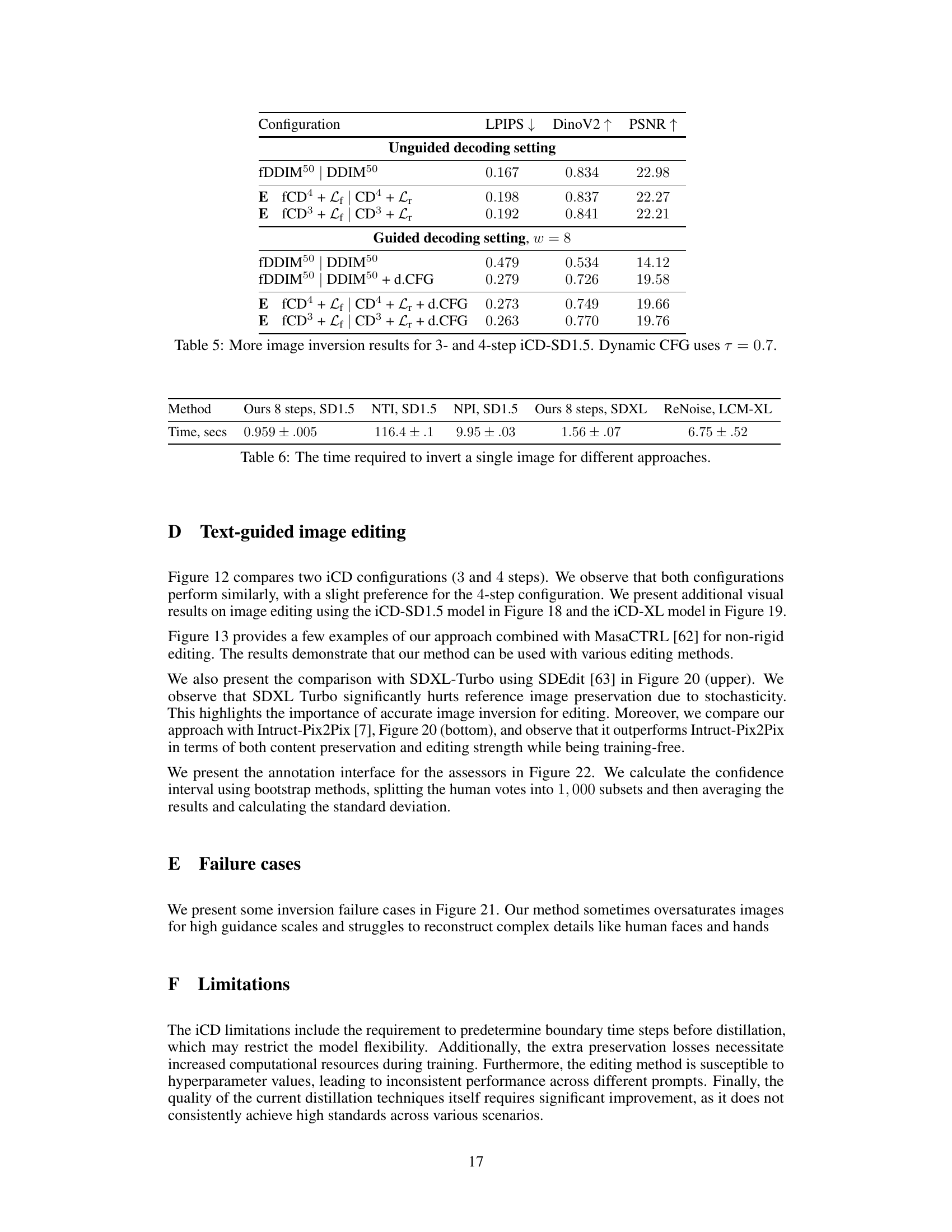
This figure shows a comparison of different image editing approaches using the Stable Diffusion 1.5 model. The left side presents quantitative comparisons using automatic metrics, while the right side displays the results of a human preference study. The automatic metrics likely include measures like CLIP score (measuring semantic similarity to a target prompt) and DinoV2 (measuring perceptual similarity to a reference image). The human preference study likely involved human raters comparing pairs of edited images and choosing their preferred result for each edit. The figure helps to illustrate the trade-off between automatic metrics and human perception in image editing.

This figure shows several examples of image editing performed using XL models. It visually demonstrates the capabilities of the proposed iCD method (ours) compared to other state-of-the-art techniques (ReNoise Turbo, ReNoise SDXL, ReNoise LCM) on various editing tasks. Each row represents a different starting image and prompt pair, showcasing the results of each method on modifying the input image according to the prompt.
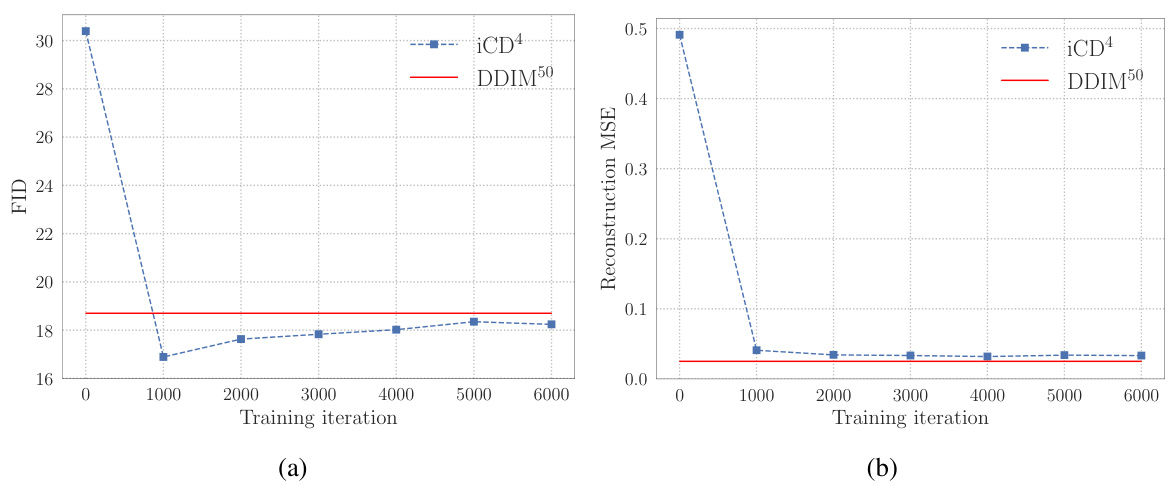
The figure shows the training progress of the Invertible Consistency Distillation (iCD) model, specifically for Stable Diffusion 1.5 (SD1.5). The left plot (a) displays the FID (Fréchet Inception Distance) score, a metric for evaluating the quality of generated images, over training iterations. The right plot (b) illustrates the reconstruction Mean Squared Error (MSE), measuring the difference between the original and reconstructed images. Both plots show how the FID score decreases and the reconstruction MSE decreases during training, indicating improved performance.

This figure presents both quantitative and qualitative results of image editing experiments using the proposed Invertible Consistency Distillation (iCD) method with the Stable Diffusion 1.5 model. The quantitative analysis (a) shows the trade-off between CLIP score (a measure of editing quality) and DinoV2 (a measure of image fidelity) for both 3-step and 4-step iCD configurations on the PieBench dataset. The qualitative results (b) display example images demonstrating the effectiveness of the method in editing images using different prompts.

This figure demonstrates the effectiveness of Invertible Consistency Distillation (iCD) for text-guided image editing. The top row shows original images of a pug, a bear, and a raccoon. The bottom row presents the edited images resulting from applying iCD, showcasing modifications such as changing the animal’s pose, adding clothing, and altering the background. The speed of the editing process (~0.9 secs) is highlighted, emphasizing iCD’s efficiency in achieving high-quality results within a limited number of steps.

This figure presents a comparison of image inversion results obtained using three different methods: the proposed method (Ours, 8 steps), Negative Prompt Inversion (NPI, 100 steps), and Null-text Inversion (NTI, 100 steps). Each row shows the original image followed by the reconstructions from each method. The goal is to visually demonstrate the relative quality and fidelity of the inversion process across different approaches. The comparison highlights the effectiveness of the proposed method in achieving high-quality inversions with significantly fewer steps than the baseline techniques.
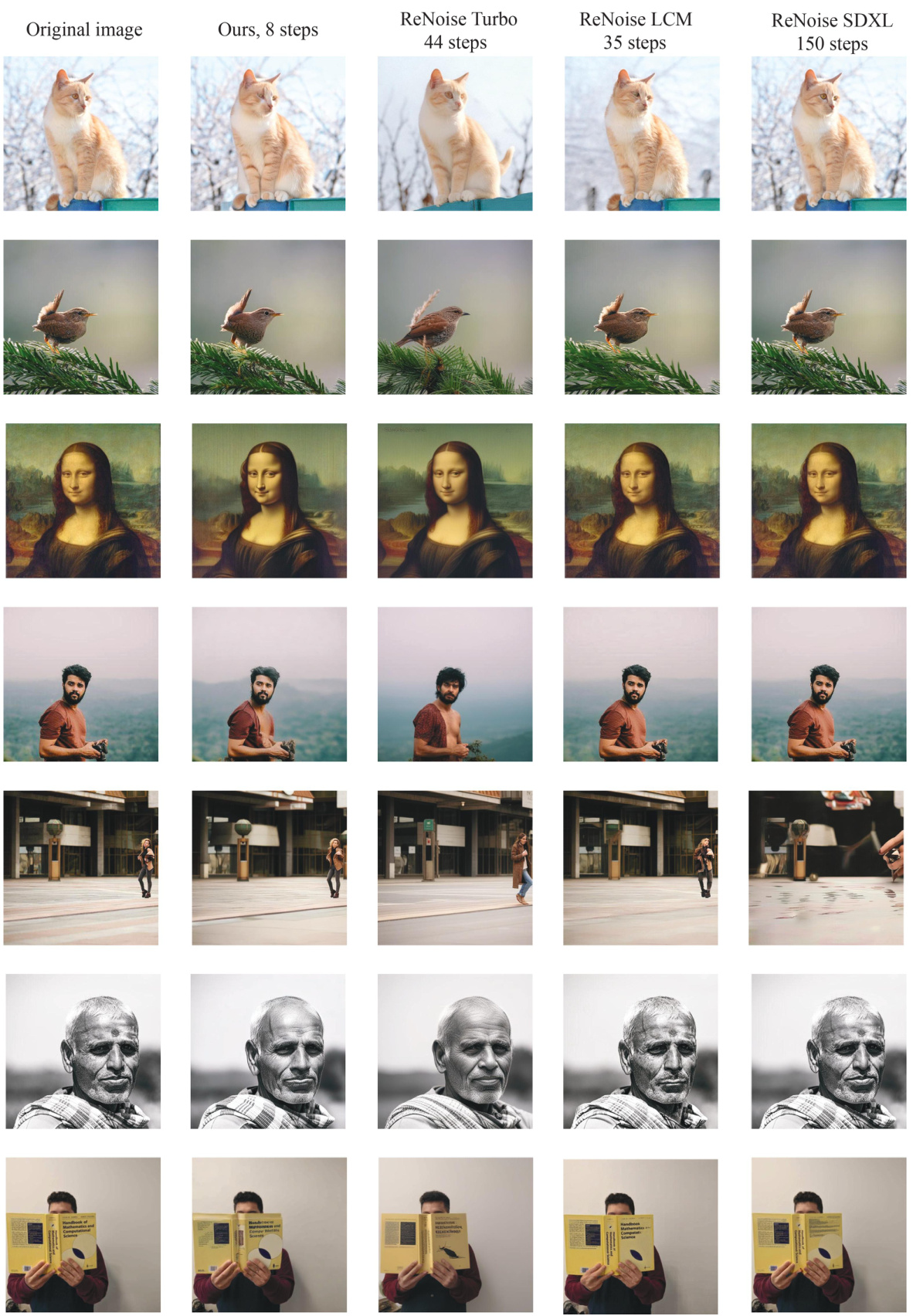
This figure displays several image inversion results produced by different models, including the proposed method (Ours, 8 steps) and several baselines (ReNoise Turbo, ReNoise LCM, and ReNoise SDXL). Each row shows the original image and its inversions generated by each model. The goal is to demonstrate the quality of image reconstruction for different models, especially in comparison to the proposed method.

This figure shows the impact of dynamic classifier-free guidance (CFG) on image reconstruction quality during the decoding process. (a) plots the reconstruction error (MSE) against different CFG turn-on thresholds (T). Higher T values mean CFG is deactivated at lower noise levels. The plot shows a significant decrease in reconstruction error as T increases, indicating that turning off guidance at higher noise levels improves inversion. (b) shows example images illustrating the improvement in image inversion quality when dynamic CFG is used.

This figure showcases the effectiveness of Invertible Consistency Distillation (iCD) in text-guided image editing. The ‘Original’ column displays the source images. The ‘Editing’ column demonstrates how quickly and effectively iCD can modify these images based on text prompts. The speed of editing is highlighted (~0.9 seconds). The examples show various manipulations such as changing animal features, adding clothing items, and modifying the background.

This figure shows the results of applying Invertible Consistency Distillation (iCD) to image editing. The ‘Original’ column displays the original images. The ‘Editing (~0.9 secs)’ column shows the results of editing these images using iCD, which is remarkably fast. The various edits demonstrate the capabilities of iCD in modifying image content and style using text prompts, showing strong generation quality within just a few model evaluations. The speed and quality highlight the effectiveness of iCD for text-guided image manipulation.

This figure shows the impact of dynamic guidance and preservation losses on image inversion using the Invertible Consistency Distillation (iCD) method. It visually demonstrates how these techniques improve image inversion quality by comparing the results with and without the application of dynamic guidance and preservation losses.

This figure demonstrates the impact of dynamic guidance and preservation losses on image inversion quality using the invertible Consistency Distillation (iCD) method. It shows a comparison between different configurations of iCD, highlighting how the use of dynamic guidance and preservation losses improves the fidelity of the image inversion process compared to using a constant guidance scale or no preservation losses.

This figure shows the results of using Invertible Consistency Distillation (iCD) for text-guided image editing. The ‘Original’ column displays the initial images. The ‘Editing (~0.9 secs)’ column shows the edited images after applying iCD, demonstrating fast and high-quality results. The edits involve replacing faces (dog-bear, wearing a hoodie, dog-raccoon), changing clothing (blue t-shirt), and adding contextual elements (raising his hand, on the beach). The speed of the editing process is highlighted, indicating the efficiency of the iCD method.

This figure shows the results of applying Invertible Consistency Distillation (iCD) to image editing. The leftmost column shows the original images. The next three columns showcase the edited images generated using iCD, demonstrating the method’s ability to perform fast and high-quality image editing with minimal model evaluations. The text prompts used for the editing are listed below each image.

This figure showcases the results of Invertible Consistency Distillation (iCD) on image editing. The leftmost column shows the original images. The subsequent columns depict the results of applying the iCD method to edit the images based on different text prompts. The speed of image editing is highlighted, with editing taking around 0.9 seconds. The high quality of the generated results demonstrates the strong generation performance achieved by the model.

This figure shows example results of image editing using the Invertible Consistency Distillation (iCD) method. The ‘Original’ column displays the input images. The ‘Editing (~0.9 secs)’ column shows the edited images produced by iCD within approximately 0.9 seconds. Each edited image is accompanied by a short textual description of the edit performed, demonstrating the model’s ability to perform precise text-guided image manipulation efficiently.

This figure showcases the results of Invertible Consistency Distillation (iCD) applied to image editing. The ‘Original’ column displays the input images. The ‘Editing (~0.9 secs)’ column shows the edited images, demonstrating fast and effective text-guided image manipulation with different prompts, such as changing the animal’s head, adding clothing, or changing the background. This illustrates the speed and effectiveness of the iCD method for text-guided image editing, achieved in only around 7 steps.

This figure shows examples of text-guided image editing using the Invertible Consistency Distillation (iCD) method. The leftmost column presents the original images. Subsequent columns show the results of the image editing process, demonstrating that the method can quickly and effectively modify images based on text prompts, such as changing objects, clothing, or background. The caption highlights the method’s speed and ability to perform high-quality image editing and generation with just a few model evaluations.

This figure shows the results of using Invertible Consistency Distillation (iCD) for text-guided image editing. The left side shows the original images, and the right side shows the edited images. The editing process is fast, taking only around 0.9 seconds, and the results are of high quality. iCD enables both fast image editing and strong generation performance with only a few model evaluations. The example edits demonstrate changes such as replacing a dog’s head with a bear’s, adding a hoodie to a person, replacing a dog’s head with a raccoon’s, changing a shirt color, and adding actions (raising a hand).

This figure shows multiple examples of text-guided image editing using different methods. The first column shows the original images. The subsequent columns illustrate the editing results obtained using the proposed iCD method (Ours, 8 steps), Null-text Inversion (NTI, 100 steps), Negative-prompt Inversion (NPI, 100 steps), InfEdit (15 steps), and Edit-friendly DDPM (Edit-fr., 164 steps). Each row represents a different editing task with varying complexity and image content.

This figure shows the results of text-guided image editing using different models based on the Stable Diffusion XL (SDXL). The ‘Original’ column displays the original image. The ‘Ours, 8 steps’ column showcases the results using the proposed method (iCD-SDXL) with 8 steps. The remaining columns show results from the ReNoise method using different models (Turbo, SDXL, and LCM) and various numbers of steps. The figure demonstrates the visual quality and fidelity of edits achievable through different approaches, highlighting the strengths and weaknesses of each technique.

This figure compares the image editing results of the proposed method against SDXL-Turbo using two different baselines: SDEdit and Instruct-P2P. The top row shows examples using SDEdit, a method that edits images based on modifying the image prompt. The bottom row shows examples using Instruct-P2P, another method for image editing. Each row demonstrates editing scenarios, showing both the original and edited images, highlighting the differences in how the two approaches handle edits.

This figure showcases the effectiveness of Invertible Consistency Distillation (iCD) in text-guided image editing. The ‘Original’ column displays the initial images. The ‘Editing’ column shows the results of applying image editing using iCD, demonstrating that high-quality edits can be achieved quickly (in roughly 0.9 seconds). The examples illustrate various editing operations, including replacing parts of the image with different elements (e.g., changing a dog’s head), adding accessories (hoodies), and altering the background.

This figure shows examples of text-guided image editing using the proposed Invertible Consistency Distillation (iCD) method. The top row displays the original images. The bottom row shows the edited images, demonstrating that iCD is able to produce high-quality edits quickly, requiring only around 0.9 seconds for editing. The edits include replacing parts of faces with other animal faces, adding clothing items, and changing the background.
More on tables
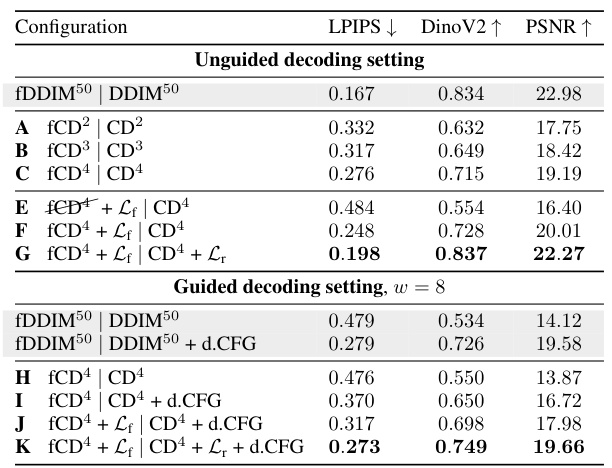
This table presents a comprehensive evaluation of different configurations of the Invertible Consistency Distillation (iCD) framework, specifically using the Stable Diffusion 1.5 model (iCD-SD1.5), for image inversion. It compares various settings, including the number of forward and reverse consistency model steps (2, 3, or 4), the inclusion of preservation losses (Lf and Lr), and the use of dynamic classifier-free guidance (d.CFG). The performance is assessed using three metrics: LPIPS, DinoV2, and PSNR, to quantify the quality of the inverted images. Both unguided (w=1) and guided (w=8) decoding settings are explored, providing a complete picture of iCD’s performance under different conditions.
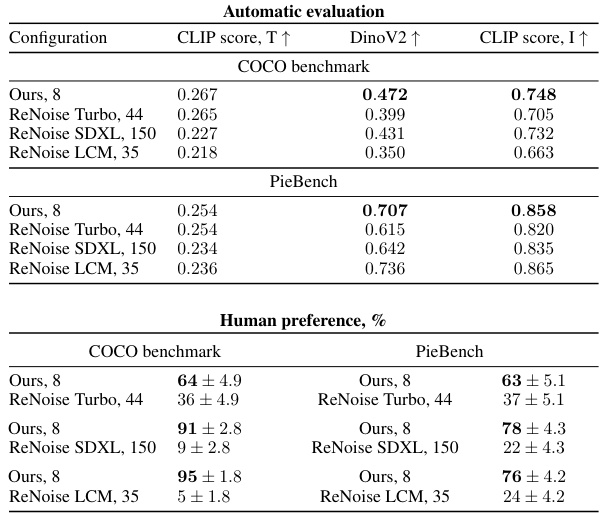
This table presents a quantitative and qualitative comparison of the proposed iCD-XL model against the ReNoise baseline for text-guided image editing. The automatic metrics section includes CLIP score (for target prompt alignment), DinoV2 (for reference image preservation), and CLIP score (for overall editing quality). The human preference section shows the percentage of human evaluators who preferred each method’s results for both COCO and PieBench datasets. The results demonstrate that iCD-XL achieves competitive performance compared to ReNoise, often with higher human preference, especially on the COCO benchmark.
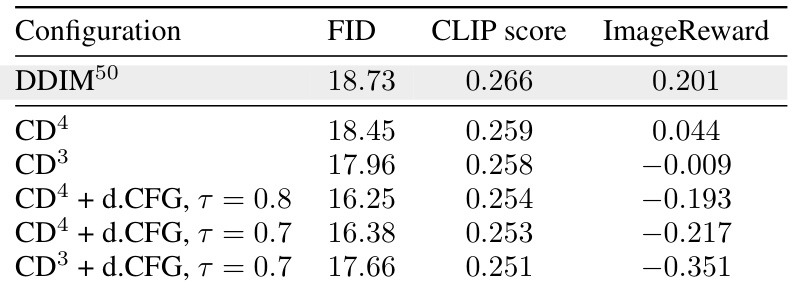
This table shows the FID, CLIP score and ImageReward of different configurations of the SD1.5 model for text-to-image generation. It compares the performance of the original DDIM model against different variations of Consistency Distillation (CD) models with and without dynamic Classifier-Free Guidance (d.CFG). The different configurations allow for the analysis of the influence of the number of steps and d.CFG in image generation.

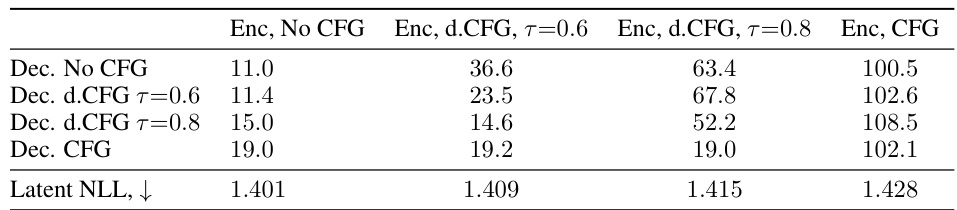
This table presents a comprehensive evaluation of different configurations of the Invertible Consistency Distillation (iCD) framework applied to the Stable Diffusion 1.5 model for image inversion. It compares various settings, including the number of forward and reverse consistency models (fCDm and CDm), the inclusion of preservation losses (Lf and Lr), and the use of dynamic classifier-free guidance (d.CFG). The performance is measured using three metrics: LPIPS (lower is better), DinoV2 (higher is better), and PSNR (higher is better). The table is divided into two sections, one for unguided decoding (w = 1) and one for guided decoding (w = 8), allowing for a comparison of inversion quality under different guidance strategies.

This table presents the time taken to perform image inversion using different methods. The methods include the proposed method (Ours, 8 steps) for both Stable Diffusion 1.5 (SD1.5) and SDXL models, along with baseline methods such as Null-text Inversion (NTI), Negative-prompt Inversion (NPI), and ReNoise LCM-XL. The time is measured in seconds, and the values represent the mean ± standard deviation.
Full paper#