↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing test-time prompt tuning methods suffer from performance degradation as prompts are continuously updated with new data, especially when data domains shift. This is because these methods fail to retain valuable knowledge from previous data points.
HisTPT introduces three types of knowledge banks (local, hard sample, and global) that memorize useful past learning to prevent catastrophic forgetting. An adaptive knowledge retrieval mechanism further refines the predictions of each test sample. Extensive experiments demonstrate HisTPT’s superior performance and robustness across various visual recognition tasks, especially in handling dynamically changing domains.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on test-time adaptation, prompt tuning, and memory-based learning in computer vision. It offers a novel solution to the problem of catastrophic forgetting in online learning scenarios, paving the way for more robust and adaptable vision foundation models. The proposed method is easily adaptable and applicable to various visual tasks, opening up exciting new avenues of research for the broader computer vision community.
Visual Insights#

This figure illustrates the concept of test-time prompt tuning (TPT). Subfigure (a) shows the basic TPT process: prompts are learned online using unlabeled test samples, which are fed into a pre-trained vision model. The model’s predictions are then used to self-supervise the prompt tuning process. Subfigure (b) shows a comparison of different prompt tuning methods. It highlights that existing methods (TPT, DiffTPT) suffer from performance degradation, especially as the domain of test samples changes. The proposed HisTPT method is designed to address this issue of knowledge forgetting.
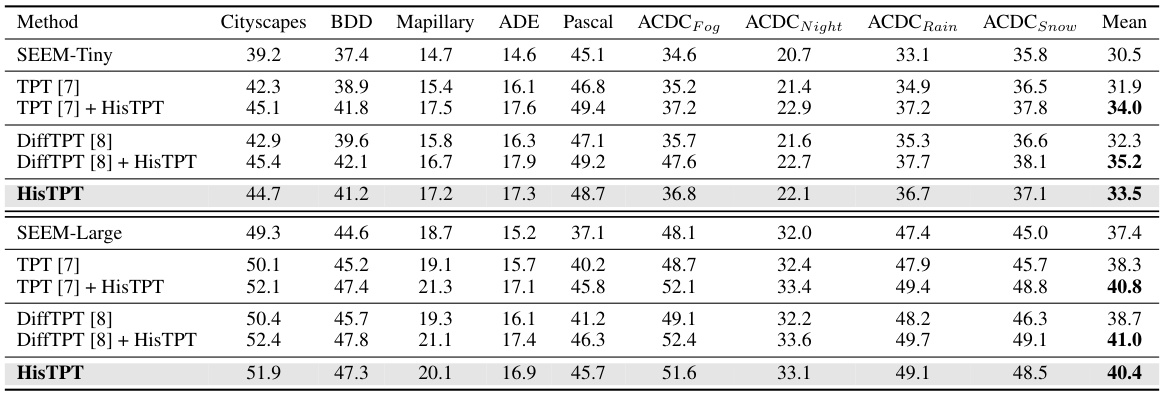
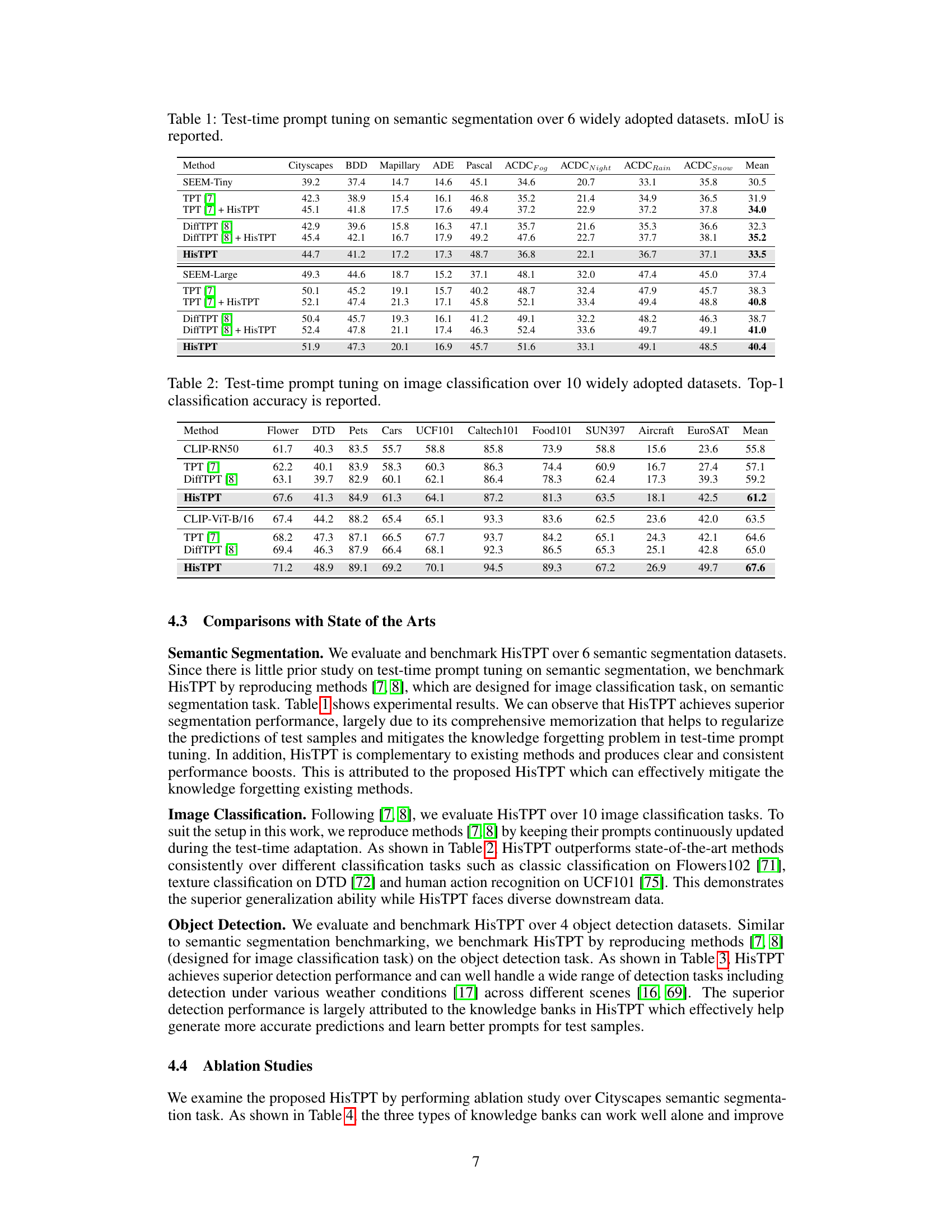
This table presents the results of test-time prompt tuning for semantic segmentation on six different datasets. The table compares several methods, including SEEM-Tiny, TPT [7], DiffTPT [8], and the proposed HisTPT method, both individually and combined. It shows the mean Intersection over Union (mIoU) score achieved by each method on each dataset. The datasets represent various scenarios, as indicated by the column names, allowing for a comprehensive evaluation of the methods’ performance.
In-depth insights#
HisTPT: Intro#
The introductory section, “HisTPT: Intro,” would ideally lay the groundwork for understanding the paper’s core contribution: Historical Test-time Prompt Tuning. It should begin by highlighting the limitations of existing test-time prompt tuning methods, emphasizing their tendency to “forget” previously learned knowledge and thus suffer performance degradation, especially when dealing with continuously changing data domains. This would naturally lead to the introduction of HisTPT as a novel solution designed to address these issues. The introduction should clearly state HisTPT’s key innovation—its use of historical knowledge banks (local, hard-sample, and global) to effectively memorize useful information from past test samples and an adaptive knowledge retrieval mechanism to regularize predictions. A concise overview of the paper’s structure and the key experimental results would also be beneficial, giving the reader a clear sense of the paper’s scope and the evidence supporting the claims made. Finally, the introduction should be written in a way that’s engaging and accessible to a broad audience, clearly motivating the need for HisTPT and emphasizing its potential impact on the field of vision foundation models.
Knowledge Banks#
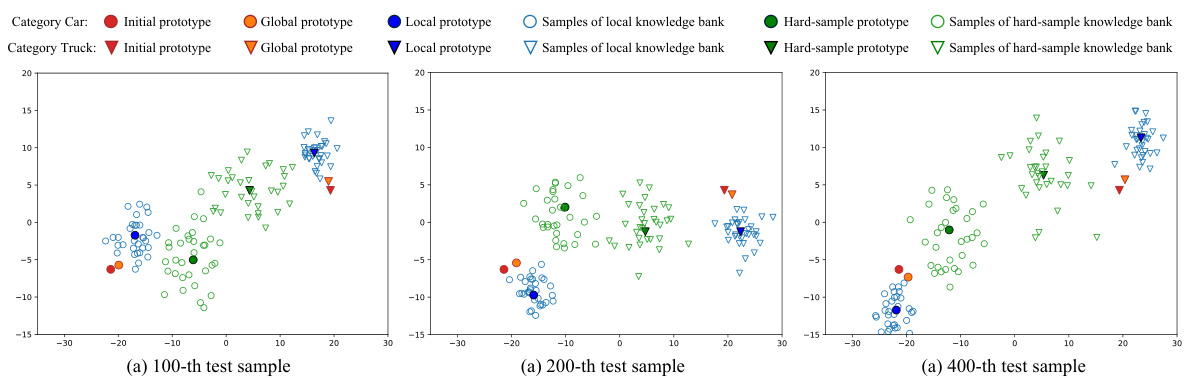
The concept of ‘Knowledge Banks’ in this context is crucial for robust test-time prompt tuning. Three distinct banks—local, hard-sample, and global—are strategically designed to address the ‘forgetting’ problem inherent in continuously updating prompts with streaming data. The local bank acts as a short-term buffer, capturing recent sample features, while the hard-sample bank focuses on memorizing challenging samples, identified by high prediction uncertainty, thus addressing edge cases. Finally, the global bank provides long-term memory, accumulating and compacting information from both the local and hard-sample banks. This tiered system allows for effective knowledge retention, balancing current data trends with consistent knowledge representation. The adaptive knowledge retrieval mechanism intelligently uses these stored features to regularize prediction and prompt optimization, improving overall model performance and generalization.
Ablation Studies#
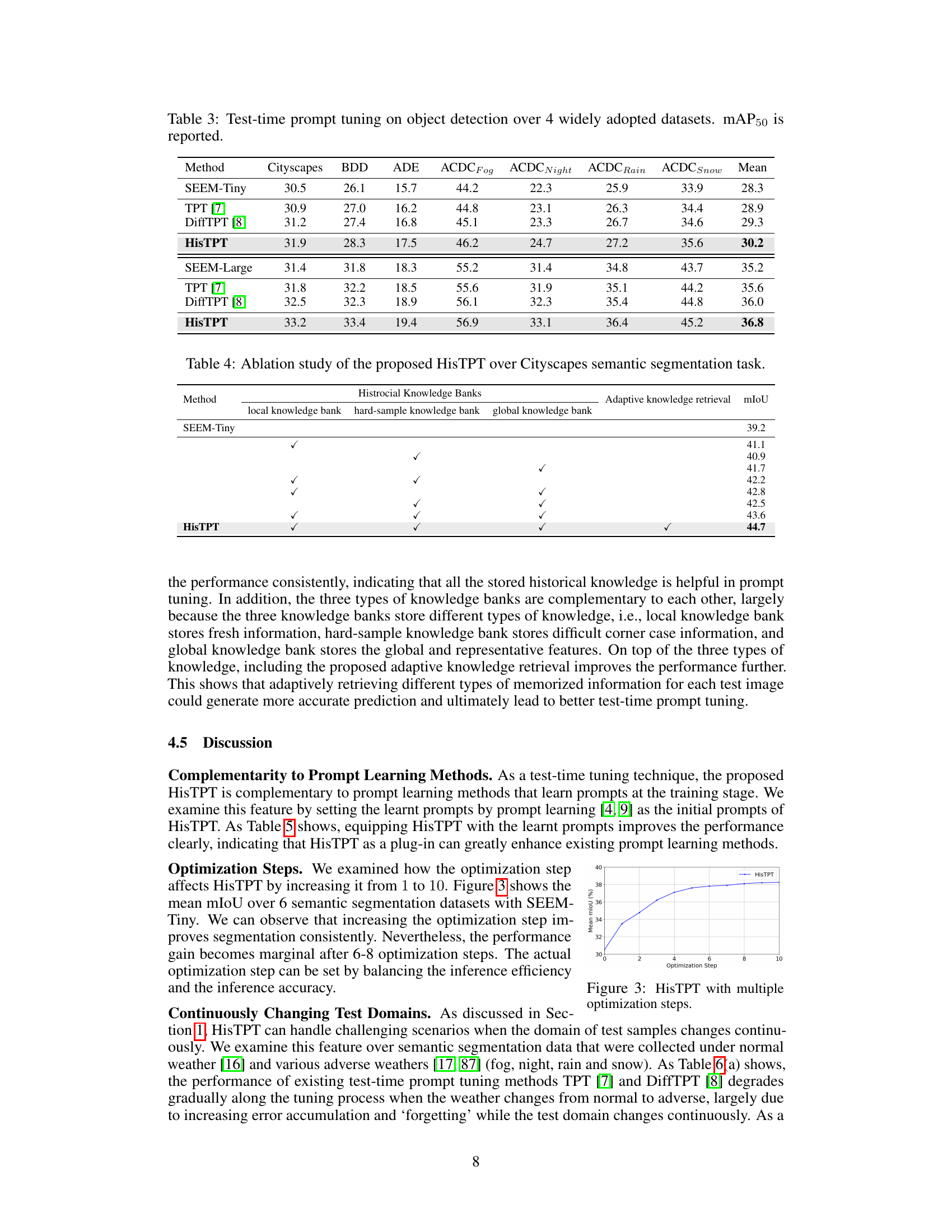
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a prompt-tuning vision model, this might involve removing or altering aspects like the types of knowledge banks (local, hard-sample, global), the adaptive retrieval mechanism, or the prediction regularization strategy. By isolating each component, researchers can determine its impact on overall performance, such as mIoU or accuracy, and identify which parts are crucial for success. The results of ablation studies usually present a table detailing the performance with different combinations of components removed, highlighting the importance of specific design choices and providing evidence for the effectiveness of the proposed method. Well-designed ablation studies are crucial for establishing the validity and robustness of a model, moving beyond just demonstrating superior performance compared to other models. Furthermore, they help researchers better understand the underlying mechanisms and the interaction between different components of the system, potentially leading to more efficient and effective model designs in the future.
Future Work#
The paper’s ‘Future Work’ section could explore several promising avenues. Extending HisTPT to other VFM architectures beyond SEEM and CLIP, and evaluating its performance on diverse tasks such as video understanding and 3D vision would strengthen the generality claims. Investigating alternative memory mechanisms, such as attention-based methods or neural networks, may enhance the efficiency and capacity of knowledge storage. A deeper exploration into the theoretical properties of HisTPT, providing formal analyses of convergence and generalization, is warranted. Furthermore, empirical investigations should focus on handling concept drift more robustly, perhaps through incorporating online learning techniques or exploring novel objective functions. Finally, addressing the computational cost of knowledge storage and retrieval at scale is critical for real-world applications, requiring research into efficient data structures and algorithms.
Limitations#
A thoughtful analysis of the limitations section of a research paper would explore several key aspects. First, it needs to identify the scope of the study’s constraints, acknowledging factors that could limit generalizability or reproducibility. This could include dataset limitations, such as size, bias, or representativeness, which might affect the conclusions’ broad applicability. Second, it should address methodological weaknesses, pointing out any assumptions or simplifications made during the design or implementation phases that might compromise the results’ validity or interpretability. For example, the use of specific models or algorithms might influence the findings, and these should be critically examined. The analysis must also consider any unaddressed confounding variables, and acknowledge that the findings might be affected by factors not explicitly controlled for in the study’s design. Finally, it’s crucial to consider potential limitations in the interpretation of findings, acknowledging areas where the results might not provide a definitive answer to the research question. A robust limitations section fosters transparency and encourages future research to address these identified gaps.
More visual insights#
More on figures
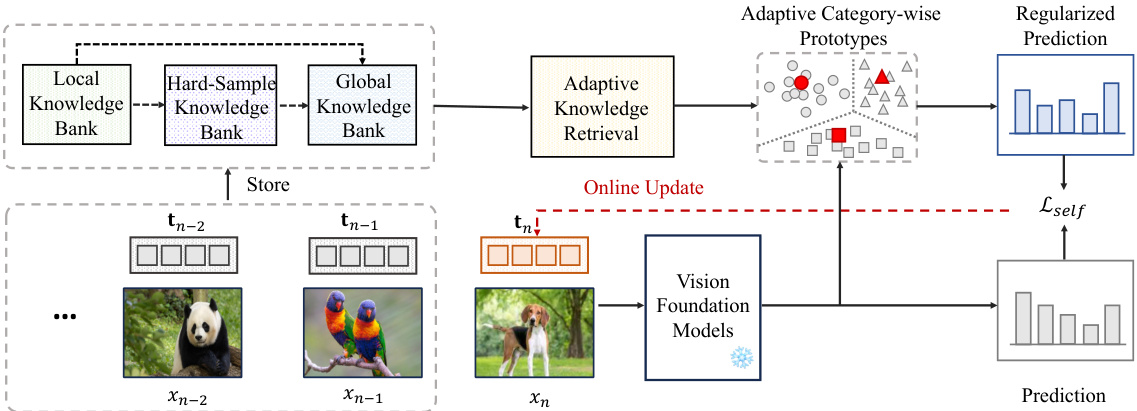
This figure illustrates the overall architecture of the proposed HisTPT model. It shows how the model uses three knowledge banks (local, hard-sample, and global) to store historical information from previous test samples. The adaptive knowledge retrieval mechanism uses this stored information to regularize the prediction of new test samples and optimize the prompts. The online update process is also shown, illustrating the continuous learning process of the model.

This figure shows the mean mIoU over 6 semantic segmentation datasets using SEEM-Tiny as the model backbone. The x-axis represents the number of optimization steps, and the y-axis shows the mean intersection over union (mIoU) achieved. The plot demonstrates that increasing the number of optimization steps improves the model’s performance, but the gains diminish after 6-8 steps. This suggests a balance point between computational cost and performance gain exists when choosing the number of optimization steps for HisTPT.

This figure shows the performance of existing test-time prompt tuning methods (TPT and DiffTPT) along with the proposed method (HisTPT). The left panel (a) illustrates the general concept of test-time prompt tuning, where prompts are learned from a continuous stream of unlabeled test data. The right panel (b) shows a performance comparison. Existing methods exhibit performance degradation when the domain of test samples changes continuously, demonstrating knowledge forgetting. HisTPT is shown to maintain better performance in this scenario.
This figure illustrates the architecture of the proposed HisTPT method. It shows how three knowledge banks (local, hard-sample, and global) work together to memorize useful knowledge from previous test samples and use it to regularize the prediction of the current test sample. An adaptive knowledge retrieval mechanism is used to select the most relevant memorized knowledge for each test sample.

This figure shows a qualitative comparison of the semantic segmentation results obtained using three different methods: SEEM-Tiny, TPT, and HisTPT. For each of five example images, the original image is shown alongside the segmentation masks produced by each method and the ground truth segmentation. The purpose of the figure is to visually demonstrate the improved performance of HisTPT compared to the baseline and a previous state-of-the-art method.
More on tables

This table presents the results of test-time prompt tuning experiments on 10 different image classification datasets. The table compares the performance of three different methods (TPT, DiffTPT, and HisTPT) and a baseline (CLIP-RN50 and CLIP-ViT-B/16) across various datasets. The performance metric used is top-1 classification accuracy. This allows for a comparison of the methods’ ability to adapt to diverse image classification tasks.

This table presents the performance of different test-time prompt tuning methods (SEEM-Tiny, TPT [7], DiffTPT [8], and HisTPT) on four widely used object detection datasets (Cityscapes, BDD100K, ADE20K, and ACDC). The results are reported in terms of mean Average Precision at 50% IoU (mAP50), showing the average performance across various weather conditions (fog, night, rain, snow) for each dataset. The table highlights the improvement achieved by HisTPT compared to existing methods.

This table presents the results of an ablation study conducted on the Cityscapes semantic segmentation dataset to evaluate the contribution of each component of the proposed HisTPT model. It shows the impact of using each knowledge bank (local, hard-sample, and global) individually and in combination, as well as the effect of the adaptive knowledge retrieval mechanism. The results demonstrate the importance of each component and their synergistic effect in achieving the superior performance of the HisTPT model.

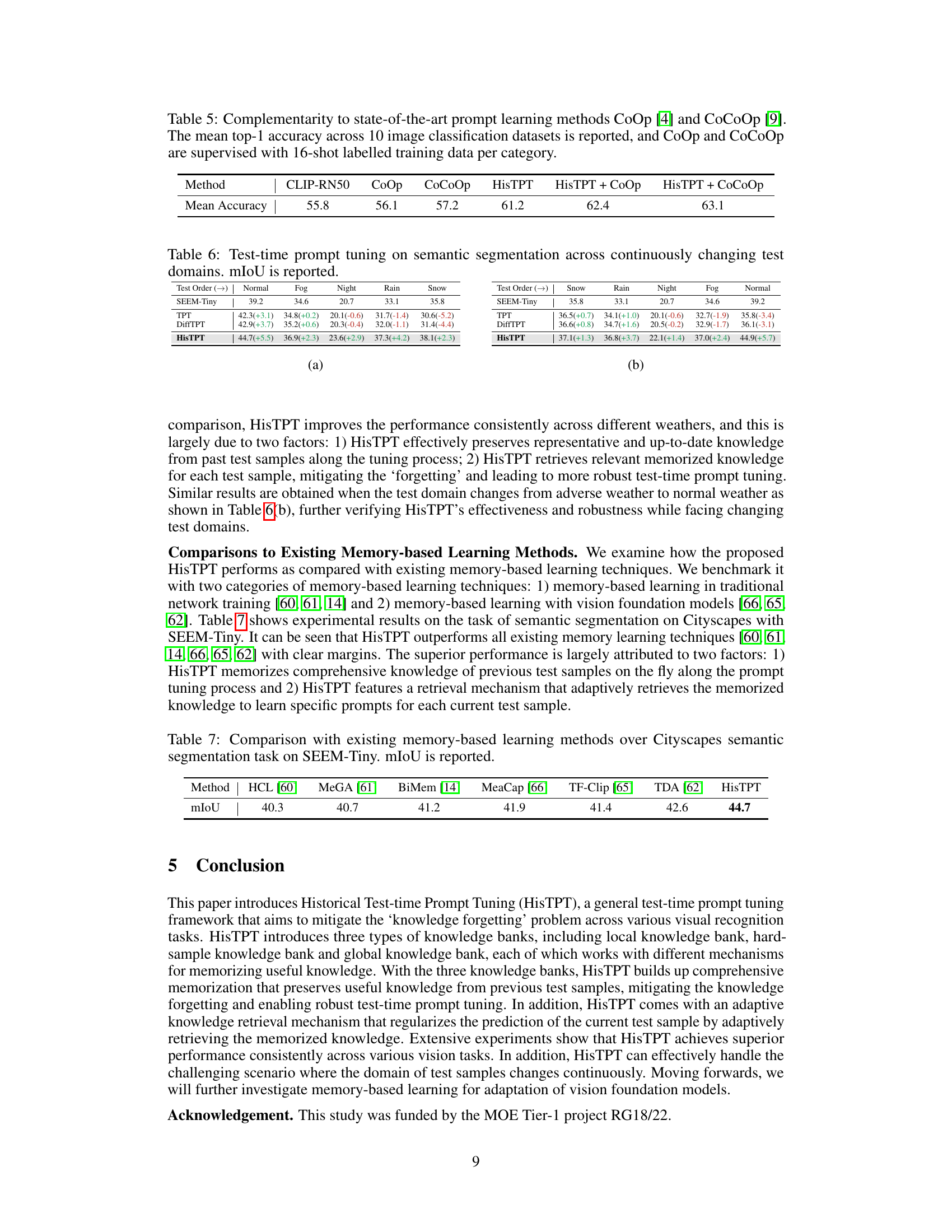
This table demonstrates the complementary nature of HisTPT with existing prompt learning methods. It shows the mean top-1 accuracy across 10 image classification datasets. HisTPT is tested alone and also combined with CoOp and CoCoOp, which are other prompt learning techniques. CoOp and CoCoOp are trained using 16 labeled samples per category.
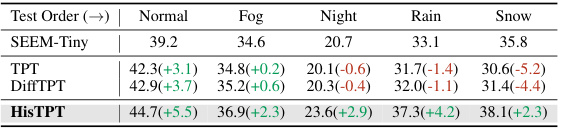
This table presents the results of test-time prompt tuning for semantic segmentation across different weather conditions (Normal, Fog, Night, Rain, Snow). The performance of three methods (SEEM-Tiny, TPT, and DiffTPT) is compared against the proposed HisTPT method. The numbers in parentheses show the performance difference compared to the SEEM-Tiny baseline. HisTPT shows consistent improvement over the baselines, especially in challenging weather conditions.
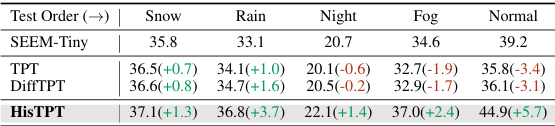
This table presents the results of test-time prompt tuning for semantic segmentation when the test domain changes continuously. It shows the mean Intersection over Union (mIoU) achieved by different methods (SEEM-Tiny, TPT, DiffTPT, and HisTPT) across five different weather conditions (Snow, Rain, Night, Fog, Normal), simulating a continuously changing test domain. The numbers in parentheses indicate the performance difference relative to the baseline (SEEM-Tiny). The table demonstrates HisTPT’s robustness and ability to retain knowledge even as the test domain shifts.

This table compares the performance (mIoU) of HisTPT against other memory-based learning methods on the Cityscapes semantic segmentation dataset using the SEEM-Tiny model. It highlights HisTPT’s superior performance compared to existing methods.

This table presents the results of test-time prompt tuning experiments on six widely used semantic segmentation datasets. The method being evaluated is compared against several baseline and alternative methods. The primary metric used is mean Intersection over Union (mIoU), a common measure of accuracy in semantic segmentation, indicating the average overlap between the predicted and ground-truth segmentation masks. The results demonstrate the performance gains achieved by the proposed method compared to existing methods.

This table compares two different methods for updating the hard-sample knowledge bank in the HisTPT model on the Cityscapes semantic segmentation dataset using SEEM-Tiny. The first method updates directly using selected features, while the second method updates using compacted features with an average operation. The mIoU metric is used to evaluate the performance of each method. The table shows that using compacted features with an average operation leads to better performance than directly updating with selected features.

This table presents an ablation study on the update methods of the global knowledge bank within the HisTPT model. It compares three different methods: updating only with local knowledge bank features, only with hard-sample knowledge bank features, and with both. The results show that combining both local and hard-sample knowledge bank features leads to the best performance, highlighting their complementary nature in providing comprehensive and representative global memorization for robust prompt tuning.

This table presents the mean Intersection over Union (mIoU) scores achieved by different test-time prompt tuning methods on six widely used semantic segmentation datasets. The methods compared include SEEM-Tiny, TPT [7], TPT [7] + HisTPT, DiffTPT [8], DiffTPT [8] + HisTPT, and HisTPT. The table shows the performance of each method across various datasets, providing a comparison of their effectiveness in semantic segmentation.

This table presents the results of test-time prompt tuning on semantic segmentation using six well-known datasets. It compares the mean Intersection over Union (mIoU) scores achieved by several methods, including the proposed HisTPT, against baseline models and other existing test-time prompt tuning approaches. The datasets included represent a variety of urban scene and outdoor imagery contexts, and the results demonstrate HisTPT’s performance improvement across a range of challenging scenarios.
Full paper#