↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional distributed learning methods like Minibatch-SGD and Local-SGD face challenges, especially in heterogeneous environments where data distributions vary across machines. These methods either suffer from slow convergence due to limited communication or from bias introduced by local updates. This paper tackles this problem.
The proposed solution, SLowcal-SGD, employs a customized slow querying technique. This technique, inspired by Anytime-SGD, allows machines to query gradients at slowly changing points which reduces the bias from local updates. The algorithm also uses importance weighting to further enhance performance. Experiments on MNIST dataset demonstrate that SLowcal-SGD consistently outperforms both Minibatch-SGD and Local-SGD in terms of accuracy and convergence speed.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in distributed learning and federated learning. It addresses the limitations of existing local update methods by proposing a novel approach with provable benefits over established baselines. This opens new avenues for improving the efficiency and scalability of distributed machine learning systems, which is of great practical relevance in various applications.
Visual Insights#

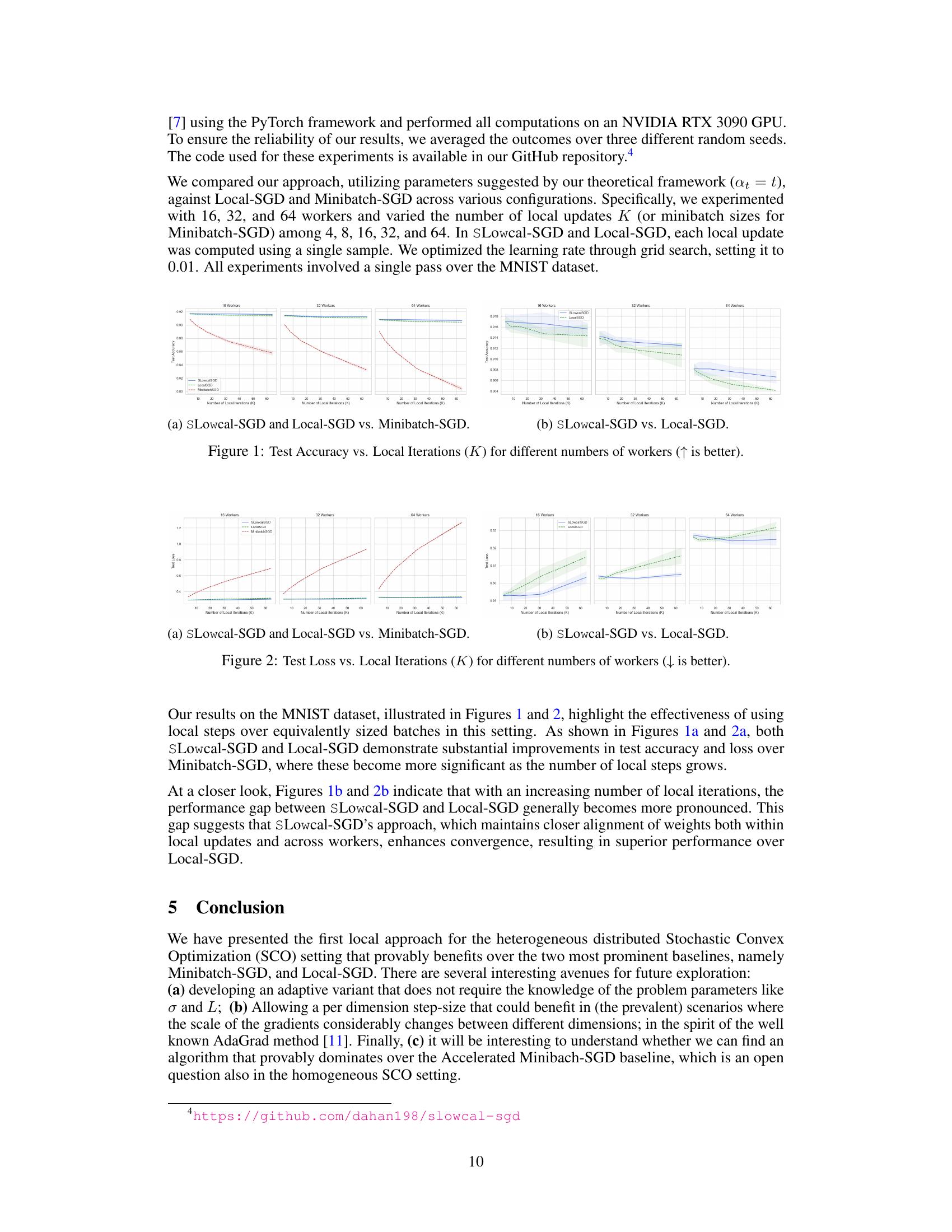
This figure displays the test accuracy achieved by three different stochastic gradient descent (SGD) algorithms: SLowcal-SGD, Local-SGD, and Minibatch-SGD. The x-axis represents the number of local iterations (K), which is the number of local gradient updates performed by each machine before the global aggregation step. The y-axis represents the test accuracy achieved. Three different subfigures show results for 16, 32, and 64 workers, respectively. The upward-pointing arrow indicates that higher values are preferable in terms of accuracy. The figure shows that SLowcal-SGD generally outperforms Local-SGD and Minibatch-SGD across different numbers of workers and local iterations.
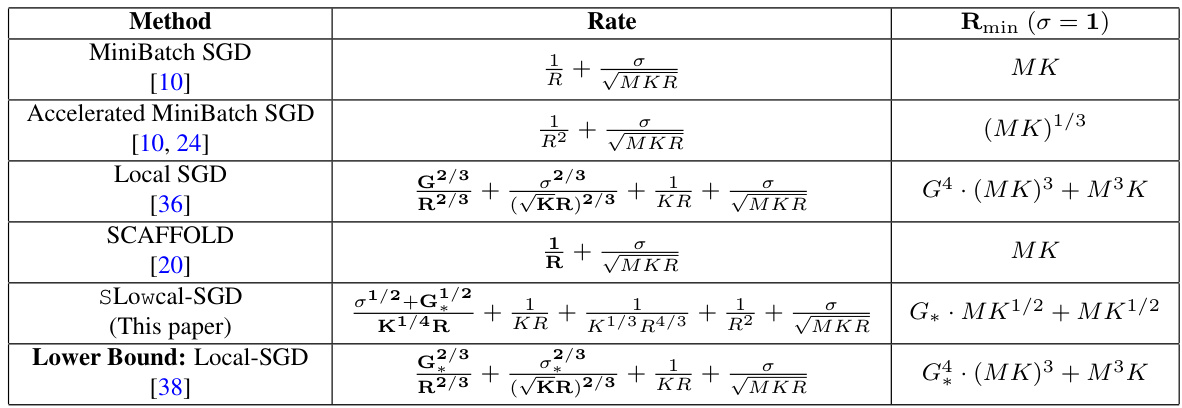
This table compares the convergence rates and the minimum number of communication rounds required for linear speedup of different parallel learning algorithms in the heterogeneous stochastic convex optimization (SCO) setting. It contrasts the performance of SLowcal-SGD (the proposed algorithm) against existing baselines like Minibatch-SGD and Local-SGD, highlighting the advantage of SLowcal-SGD in terms of communication efficiency.
Full paper#