↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large-scale training of Latent Diffusion Models (LDMs) has shown impressive results in image generation. However, the lack of openly available training recipes and the complexity of the models hinder reproducible research and progress. This paper addresses these issues by re-implementing five previously published LDMs with their training recipes. It provides a comparative analysis focusing on conditioning mechanisms and pre-training strategies.
This research introduces a novel conditioning mechanism which enhances LDM training by decoupling the semantic level from control metadata conditions. This allows for better user control and more effective training with lower-quality data. Moreover, the authors improve pre-training strategies by efficiently transferring representations from smaller and lower-resolution datasets to larger ones. These improvements lead to a new state-of-the-art in class-conditional and text-to-image generation tasks, showcasing significant improvements over existing models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in diffusion models because it systematically analyzes various training recipes and conditioning mechanisms, providing valuable insights for improving model efficiency and performance. It also offers practical guidelines and improvements, enabling researchers to achieve state-of-the-art results and explore new avenues in generative modeling. Its focus on reproducibility is especially important, facilitating validation of progress and comparison across different models.
Visual Insights#

This figure displays eight example images generated by the model trained on the Conceptual Captions 12M dataset at a resolution of 512x512 pixels. The images showcase the model’s ability to generate diverse and realistic images across different styles and subject matters, demonstrating the capabilities of the improved conditioning and pre-training strategies presented in the paper. Each image is accompanied by a short text description of its content.

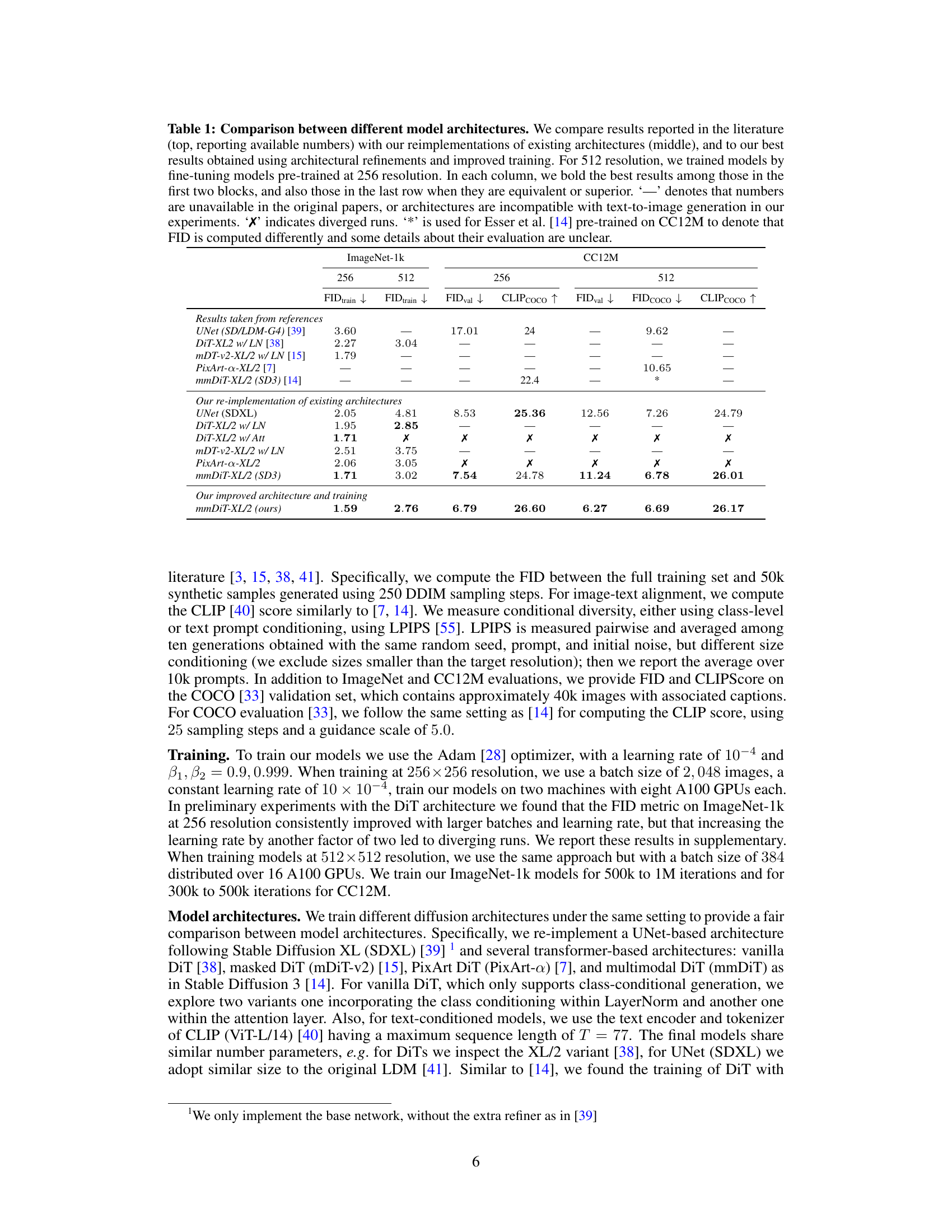
This table compares the performance of five different diffusion model architectures across two datasets (ImageNet-1k and CC12M) at two resolutions (256x256 and 512x512). It shows the FID (Fréchet Inception Distance) and CLIP scores for each model. The table includes results from previously published papers, the authors’ re-implementations of those models, and finally their improved models. It highlights how architectural choices and training strategies affect model performance.
In-depth insights#
LDM Training#
Training Latent Diffusion Models (LDMs) effectively is crucial for high-quality image generation. The process involves several key considerations, including the choice of architecture (e.g., U-Net, transformer-based models), the conditioning mechanisms employed (e.g., class labels, text prompts, control metadata), the training dataset size and resolution, and optimization strategies. Efficient training recipes often remain unpublished, hindering reproducibility and the validation of progress in the field. This lack of transparency necessitates careful re-implementation and ablation studies to isolate the effects of individual components. A key challenge is balancing training efficiency with model performance. Pre-training on smaller, lower-resolution datasets can significantly reduce training costs, but it’s vital to carefully manage the transfer of learned representations to larger datasets and higher resolutions. Disentangling different conditioning signals (e.g., semantic vs. control information) is important for improved control and higher-quality outputs. Careful attention to detail in training parameters and data augmentation strategies is also critical for optimal results. Ultimately, effective LDM training requires a holistic approach, carefully considering interactions between all these factors to maximize the trade-off between efficiency and generative quality.
Cond. Mechanisms#
The section on conditioning mechanisms in this research paper is crucial for understanding how the model effectively generates images based on user inputs. The authors explore several existing methods, such as adaptive layer normalization and cross-attention, for incorporating class labels and text prompts. A key contribution is the introduction of a novel conditioning mechanism that elegantly separates semantic-level (text/class) from control-level (image size, flip) metadata. This disentanglement is critical because it prevents interference between these distinct aspects of the generation process, leading to improved image quality and user control. The efficacy of this decoupling is demonstrated through experiments showing that the model trained with the new approach achieves state-of-the-art results on class-conditional generation on ImageNet-1k and text-to-image generation on CC12M datasets. Furthermore, the study investigates how various weighting strategies (like cosine scheduling) affect the influence of control information during different stages of generation, highlighting the significance of carefully managing this interplay for optimal results. Overall, this research provides a thorough investigation and innovative improvement to conditioning mechanisms, ultimately enhancing the capabilities and performance of latent diffusion models.
Pre-train Strategies#
The research paper explores pre-training strategies for diffusion models, focusing on efficient scaling and improved performance. Transfer learning is highlighted as a key technique, where models pre-trained on smaller, lower-resolution datasets are leveraged to initialize models trained on larger, higher-resolution datasets. This approach significantly reduces training time and computational costs. The authors investigate and propose several enhancements to this transfer learning process, including: interpolation of positional embeddings to better handle resolution changes; scaling of the noise schedule to adapt to varying uncertainties at different resolutions; and optimizing cropping strategies during pre-training to better align training distributions across resolutions. These optimizations are shown to improve the transferability and efficiency of pre-training, leading to state-of-the-art results. The study emphasizes the importance of careful pre-training strategies in achieving both effective training and high-quality generative models. Disentangling different types of conditioning (e.g., semantic and control) and proposing a novel conditioning mechanism are also significant aspects of the work aiming to enhance controllability and training efficiency. The study systematically assesses multiple architectural choices and conditioning techniques. The findings provide valuable guidance for future research on scaling diffusion models efficiently and effectively.
Resolution Scaling#
Resolution scaling in diffusion models is crucial for efficiently generating high-resolution images. Simply upscaling a lower-resolution model often leads to suboptimal results, requiring strategies to adapt different model components. The paper highlights the importance of carefully scaling the noise schedule, as higher resolutions necessitate adjustments to maintain the desired noise level throughout the denoising process. Interpolation of positional embeddings is also presented as a superior technique compared to extrapolation, ensuring proper alignment between image features and their positions in higher resolutions. Furthermore, the influence of pre-training strategies at lower resolutions is highlighted, proposing and evaluating approaches to transfer knowledge effectively to higher-resolution counterparts. The impact of cropping strategies during pre-training is investigated, revealing trade-offs between various methods. Overall, the section emphasizes the critical need for a holistic approach to resolution scaling, acknowledging the interconnectedness of noise scheduling, positional embeddings, and pre-training, ultimately impacting model performance and training efficiency.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency of training large diffusion models remains a crucial area. Investigating alternative training strategies, such as incorporating techniques from other generative models or exploring novel architectures specifically designed for efficiency, could yield significant advancements. Furthermore, research into more effective and robust conditioning mechanisms is warranted. This could involve exploring new ways to integrate semantic information, developing more sophisticated control mechanisms, or investigating advanced techniques such as prompt engineering to improve the quality and controllability of generated images. A deeper dive into the transferability of pre-trained models is also needed. A more comprehensive understanding of how factors like dataset distribution, resolution, and architecture interact during transfer learning could lead to more reliable and efficient methods for scaling up diffusion models. Finally, exploring the ethical implications of high-quality image generation remains critical, prompting research into methods for detecting and mitigating potential biases, harmful uses (e.g., deepfakes), and privacy concerns.
More visual insights#
More on figures

This figure demonstrates the impact of different control conditioning methods on image generation. The top row shows images generated using a model trained with constant weighting of the size condition, leading to unwanted correlations between image content and size. The bottom row shows images generated with a cosine weighting of low-level conditioning, effectively decoupling the size condition from the content, resulting in more controlled and natural-looking outputs.
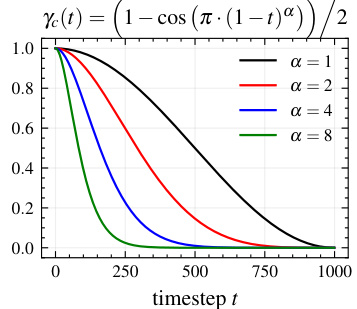
This figure shows the cosine weighting schedule used for low-level control conditions in the improved conditioning mechanism. The x-axis represents the timestep t, and the y-axis represents the weight applied to the low-level control embedding. Different curves are plotted for different values of the parameter α, which controls the steepness of the cosine curve. The weight starts at 1.0 at the beginning of the generation process (t=0) and gradually decreases to 0.0 as the generation process continues. This ensures that low-level details are only added towards the end of the generation process, after high-level semantic information has already been established. This helps disentangle control metadata from semantic-level conditioning to avoid undesired interference between them.
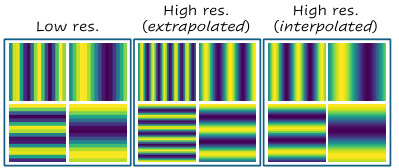
This figure compares three different methods for adapting positional embeddings to higher resolutions: (left) using the original low-resolution embeddings, (middle) extrapolating the low-resolution embeddings, and (right) interpolating the low-resolution embeddings. The figure shows that interpolation produces better results than extrapolation, because extrapolation leads to a mismatch between the positional embeddings and image features, whereas interpolation preserves a smooth transition between resolutions.
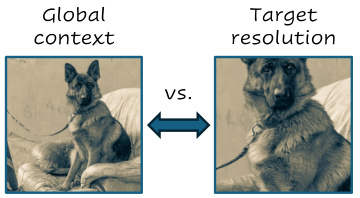
This figure illustrates the impact of different pre-training strategies on the model’s ability to finetune at higher resolutions. The left image shows a low-resolution crop used during pre-training, representing the ‘global context’ the model learns. The right image shows the higher-resolution image used during fine-tuning, representing the ’target resolution’. The arrow indicates that the model may struggle to adapt between these very different contexts during the finetuning phase. This highlights a potential issue in training: models that learn only from low-resolution, small crops may not generalize well to high-resolution, full images.
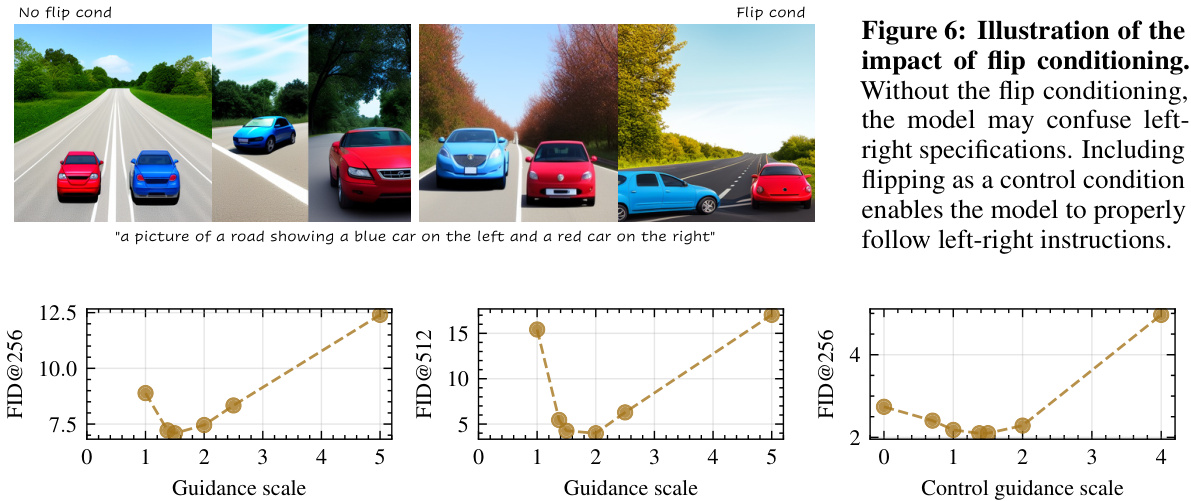
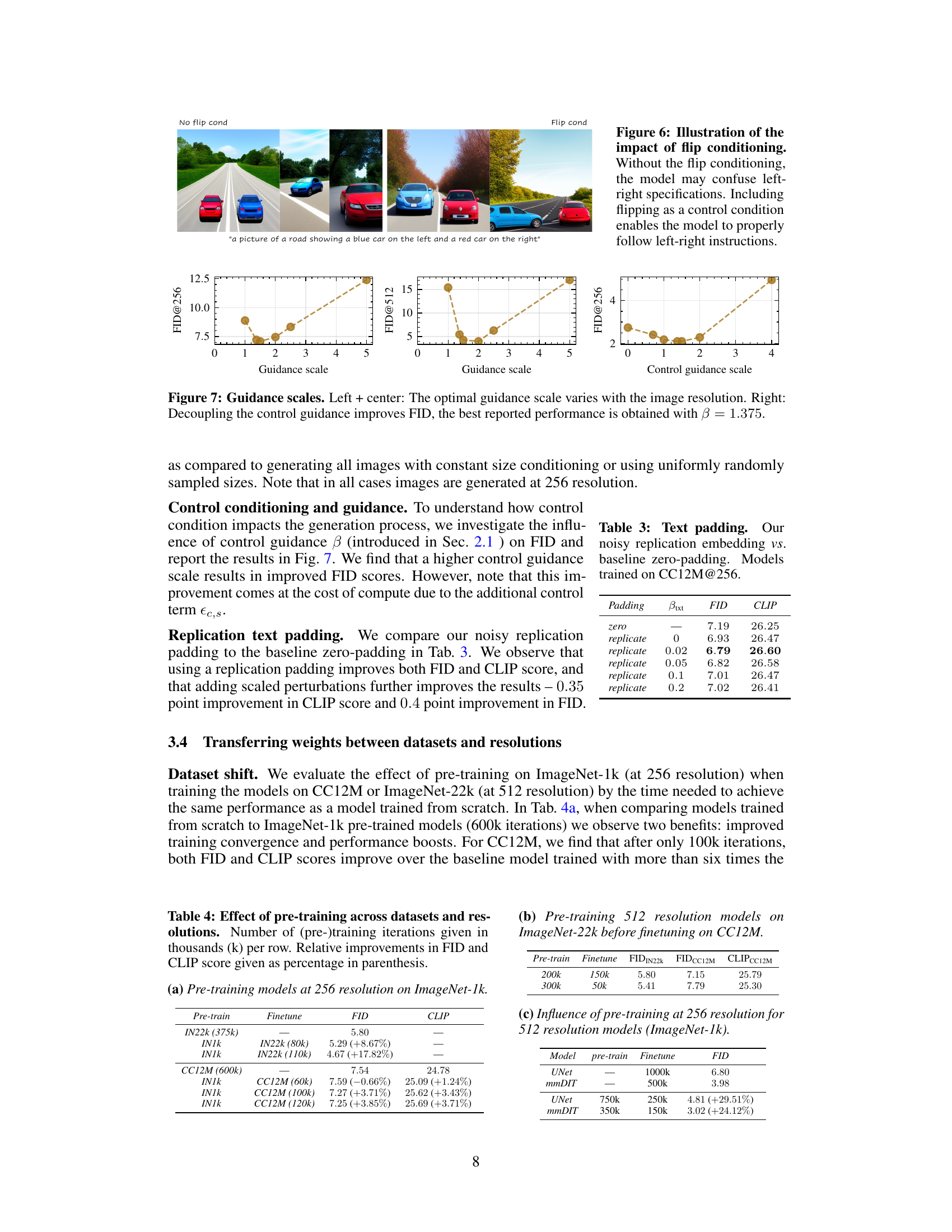
This figure demonstrates the effect of including ‘flip’ as a control condition during image generation using diffusion models. The top row shows images generated without flip conditioning, where the model struggles to consistently place objects correctly (a blue car on the left and a red car on the right). In contrast, the bottom row showcases images generated with flip conditioning enabled, demonstrating improved consistency in object placement and adherence to the prompt’s specifications.
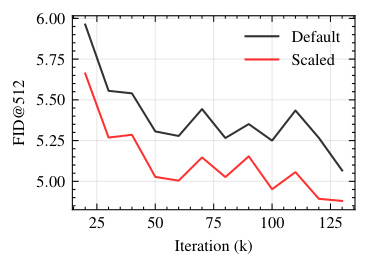
This figure shows the impact of different strategies for handling resolution changes during the training process of diffusion models. Specifically, it compares the training convergence and final FID score (Fréchet Inception Distance, a measure of image quality) for three different approaches: default (no special handling of resolution change), positional embeddings resampling, and noise schedule rescaling. The x-axis represents training iterations, and the y-axis shows the FID score. The results suggest that scaling the noise schedule and resampling positional embeddings can lead to better performance.

This figure presents the results of experiments conducted to analyze the impact of resolution changes on the performance of the model. Three subplots show how different approaches to handling the transition from lower to higher resolutions affect the model’s convergence. Specifically, it evaluates the impact of changes in the positional embedding resampling (left), noise schedule scaling (middle), and pre-training cropping strategies (right). The y-axis represents the FID score, and the x-axis represents the number of training iterations (k). The results demonstrate the significance of carefully managing the transition to higher resolutions to achieve optimal performance.
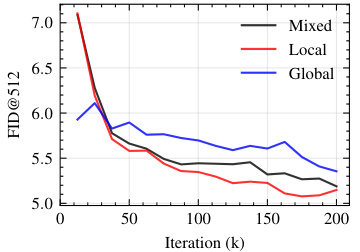
This figure demonstrates the impact of different pre-training strategies and resolution adaptations on model performance. It shows how various methods for handling positional embeddings, noise schedules, and cropping strategies affect convergence speed and the final FID (Fréchet Inception Distance) score on ImageNet-1k at 512x512 resolution. The results illustrate that careful consideration of these factors is crucial for efficient and effective training of high-resolution diffusion models.

This figure displays several example images generated by the model trained on the Conceptual Captions dataset at 512x512 resolution. It showcases the model’s ability to generate various images based on different prompts, highlighting the diversity and quality of the generated images. The images demonstrate the model’s capacity to produce realistic and varied outputs.
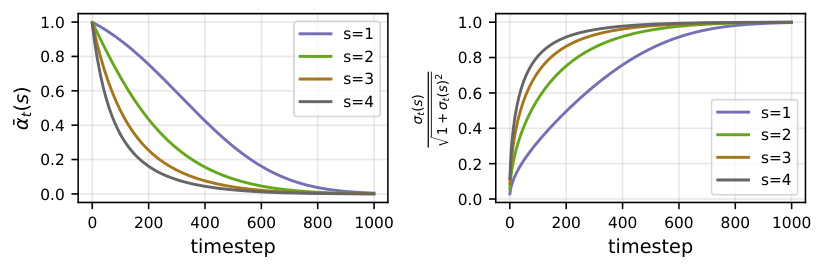
This figure illustrates how the noise schedule needs to be adjusted when scaling the resolution of diffusion models. At higher resolutions, with more observations of each image patch, the uncertainty is naturally reduced. To maintain the same level of uncertainty across resolutions, the noise schedule needs to be modified. The plot shows the noise schedule (σt(s)) for different scaling factors (s), demonstrating how the noise amplitude changes over time (timestep) to compensate for this resolution-dependent uncertainty.

This figure compares three different methods for adapting positional embeddings to higher resolutions: extrapolation, which simply replicates the original embeddings; bicubic interpolation; and the method proposed in the paper, which uses sinusoidal embeddings and adjusts the sampling grid.

This figure shows the results of a grid search over the momentum parameters (β1 and β2) of the Adam optimizer used in training a UNet model on ImageNet1k at 256x256 resolution. The FID (Fréchet Inception Distance) scores are shown as a heatmap, with lower FID values indicating better performance. The heatmap reveals the optimal momentum parameter settings, demonstrating their impact on the model’s training dynamics and FID score.

This figure shows the gradient magnitude of each token embedding in the text encoder. For short prompts (less than the maximum number of tokens the model accepts), padding tokens are added. Even though these tokens contain no semantic information, their embeddings still contribute to the attention mechanism in the transformer, as evidenced by non-zero gradients.

This figure illustrates how different padding mechanisms affect the attention matrix in a diffusion model. Zero padding wastes attention on irrelevant padding tokens, replicate padding leads to redundancy, while noisy replicate padding improves diversity and robustness by adding noise to the replicated tokens.

This figure shows several example images generated by the improved mmDiT-XL/2 model trained on ImageNet-1k at a resolution of 512x512 pixels. The images are generated using 50 DDIM sampling steps and a guidance scale of 5, highlighting the model’s ability to generate high-quality and diverse images of various classes from the ImageNet-1k dataset. The improved conditioning mechanisms and pre-training strategies lead to these superior results.
More on tables
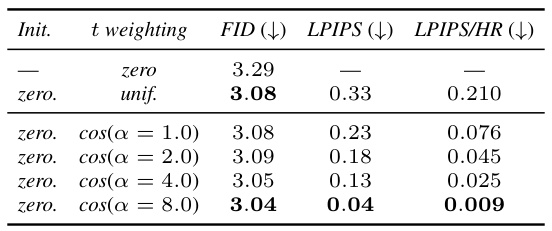
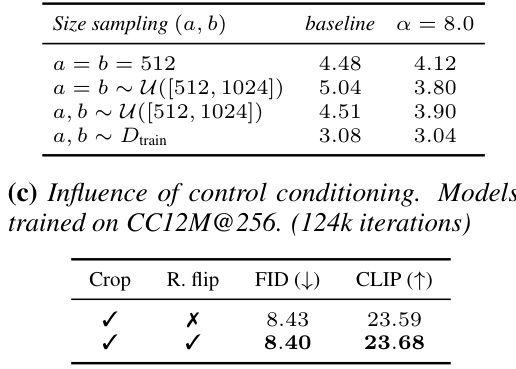
This table presents a study on control conditioning in diffusion models. It shows the impact of different control mechanisms (parametrization, size conditioning, crop, and random flip) on the model’s performance, measured by FID (Fréchet Inception Distance) and LPIPS (Learned Perceptual Image Patch Similarity). The experiments are conducted on ImageNet-1k and CC12M datasets at 256 resolution.
This table compares the performance of five different diffusion model architectures on ImageNet-1k and CC12M datasets at 256x256 and 512x512 resolutions. It shows a comparison between results reported in prior publications and the authors’ reimplementation of those models, as well as their improved models. The table highlights the FID (Fréchet Inception Distance) and CLIPscore metrics, showcasing improvements achieved through architectural refinements and advanced training strategies. The use of ‘-’ indicates missing data from original publications, while ‘X’ signifies training failures.
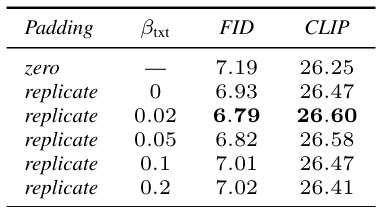
This table presents the results of an experiment comparing different text padding methods used in a diffusion model trained on the CC12M dataset at 256x256 resolution. The experiment assesses the impact of replacing padding tokens with noisy copies of existing tokens (‘replicate’ padding) versus the standard zero-padding method on FID (Fréchet Inception Distance) and CLIP scores. The results show that noisy replication padding improves both FID and CLIP scores compared to zero-padding, indicating that this technique enhances the model’s ability to condition on text prompts and improve its performance.
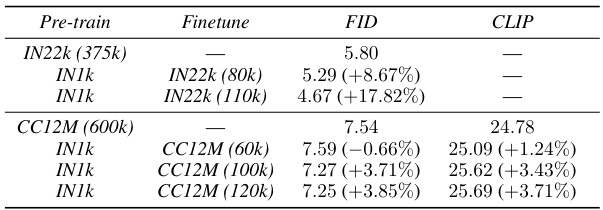
This table shows the results of pre-training models on different datasets (ImageNet-22k and CC12M) at different resolutions before fine-tuning on the target datasets. The table demonstrates the impact of pre-training on model performance (measured by FID and CLIP score) when transferring knowledge across datasets and resolutions. The relative improvements in FID and CLIP scores are shown in parentheses, indicating the performance gain achieved through pre-training.

This table shows the results of pre-training models at 256 resolution on ImageNet-1k before fine-tuning on ImageNet-22k and CC12M at 512 resolution. It compares the FID and CLIP scores achieved with different pre-training iteration counts and fine-tuning iteration counts on both datasets. The relative improvements in FID and CLIP scores compared to the baseline are also presented, highlighting the impact of pre-training on model performance.

This table presents the results of experiments evaluating the impact of pre-training on the performance of diffusion models. Two different model architectures (UNet and mmDiT) were evaluated. The table compares the FID scores obtained when training models from scratch versus when transferring weights from pre-trained models on ImageNet-1k (at 256 resolution) before fine-tuning on either CC12M or ImageNet-22k at 512 resolution. The results show significant improvements in FID and CLIP score when using transfer learning, demonstrating the effectiveness of this technique for improving training efficiency and model performance. The relative improvement is shown in parentheses.

This table compares the performance of five different diffusion model architectures across two datasets (ImageNet-1k and CC12M) at two resolutions (256x256 and 512x512). It contrasts results from the original papers describing the models with the authors’ own reimplementation of those models and finally their improved models. The table shows FID and CLIP scores, highlighting the best-performing architecture (mmDiT-XL/2) and the impact of improvements made by the authors.

This table compares the performance of five different diffusion model architectures (UNet, DiT-XL2, mDT-v2-XL/2, PixArt-a-XL/2, mmDiT-XL/2) across two datasets (ImageNet-1k and CC12M) at two resolutions (256x256 and 512x512). The table presents results from the original papers, the authors’ reimplementations, and their improved models, allowing for a comparison of the models’ performance and the impact of the authors’ training techniques.

This table compares the performance of five different diffusion model architectures across two datasets (ImageNet-1k and CC12M) at two resolutions (256x256 and 512x512 pixels). The comparison includes results from previously published papers, the authors’ re-implementations of those papers, and finally their own improved models using new conditioning mechanisms and pre-training strategies. FID (Fréchet Inception Distance) and CLIP-COCO scores are used to evaluate the image generation quality. The table highlights the best-performing architecture and demonstrates the improvements achieved by the authors’ methods.
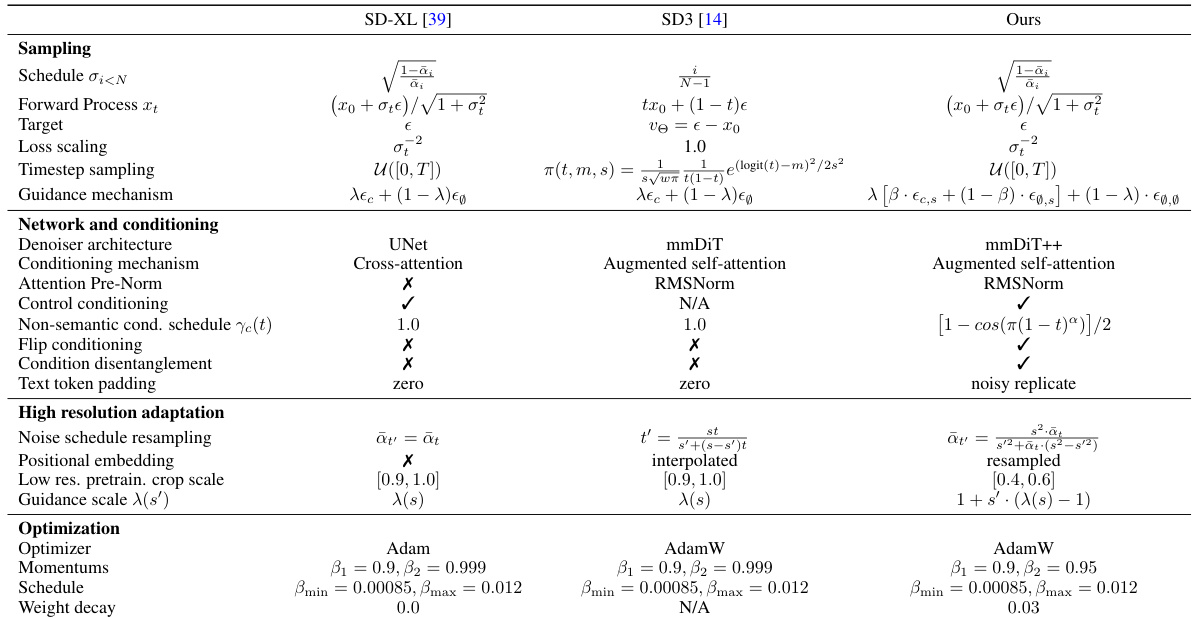
This table compares the performance of different diffusion model architectures on ImageNet-1k and CC12M datasets at 256x256 and 512x512 resolutions. It shows a comparison between results reported in previous publications, the authors’ re-implementations of those models, and finally, the authors’ improved models. The table highlights the impact of architectural choices and training strategies on model performance, using FID (Fréchet Inception Distance) and CLIPscore as evaluation metrics. The ‘-’ indicates missing data from original papers, ‘X’ indicates training failures, and ‘*’ signifies differences in FID calculation compared to another study.

This table compares the performance of five different diffusion model architectures on ImageNet-1k and CC12M datasets at 256x256 and 512x512 resolutions. It shows a comparison of results from previously published papers, the authors’ reimplementations of those models, and finally, the authors’ improved results using novel conditioning and training strategies. The table highlights improvements in FID (Fréchet Inception Distance) scores, demonstrating the effectiveness of the proposed methods. The ‘-’ indicates missing data from original papers, ‘X’ represents failed training runs, and ‘*’ notes discrepancies in evaluation details with a specific prior work.
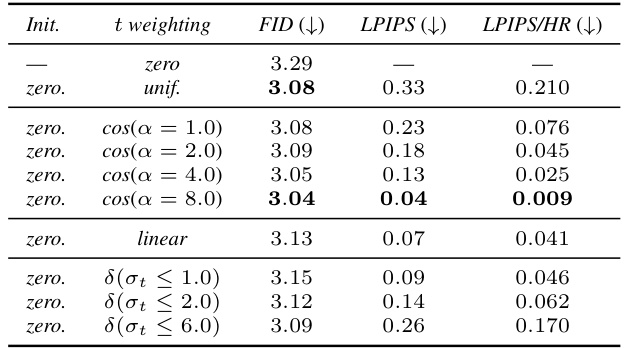
This table presents the results of experiments on control conditioning, exploring its various aspects and impact on model performance. It focuses on ImageNet-1k dataset with 256 resolution, using 250 sampling steps and 120k training iterations. The table is divided into subsections showing: (a) the influence of parametrization on FIDtrain and LPIPS (with and without higher resolutions), (b) size conditioning’s effect on FID at inference, and (c) control conditioning’s effect on FID and CLIP score on the CC12M dataset at 256 resolution with 124k iterations. The results show how different methods of control conditioning affect the final performance metrics.
Full paper#