↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Domain generalization in semantic segmentation struggles with cross-domain style variations, hindering the performance of vision foundation models (VFMs). Existing methods either focus on style decoupling or content representation, neglecting the importance of style invariance for robust scene understanding. This paper tackles this challenge by proposing a novel method.
The proposed Frequency-Adapted (FADA) learning scheme utilizes Haar wavelet transform to effectively decouple style and content information in the frequency domain. FADA leverages low-rank adaptation separately on low-frequency (content) and high-frequency (style) components. The low-frequency branch stabilizes scene content representation, while the high-frequency branch mitigates style variations through instance normalization. Experimental results demonstrate FADA’s superior performance, outperforming existing DGSS methods on various VFMs and datasets.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in semantic segmentation and domain generalization. It introduces a novel Frequency-Adapted (FADA) learning scheme that significantly improves the performance of domain generalized semantic segmentation by decoupling style and content information in the frequency domain using Haar wavelet transform. This offers a new paradigm for adapting vision foundation models (VFMs) to downstream tasks and opens up exciting avenues for future research in style-invariant learning and low-rank adaptation.
Visual Insights#
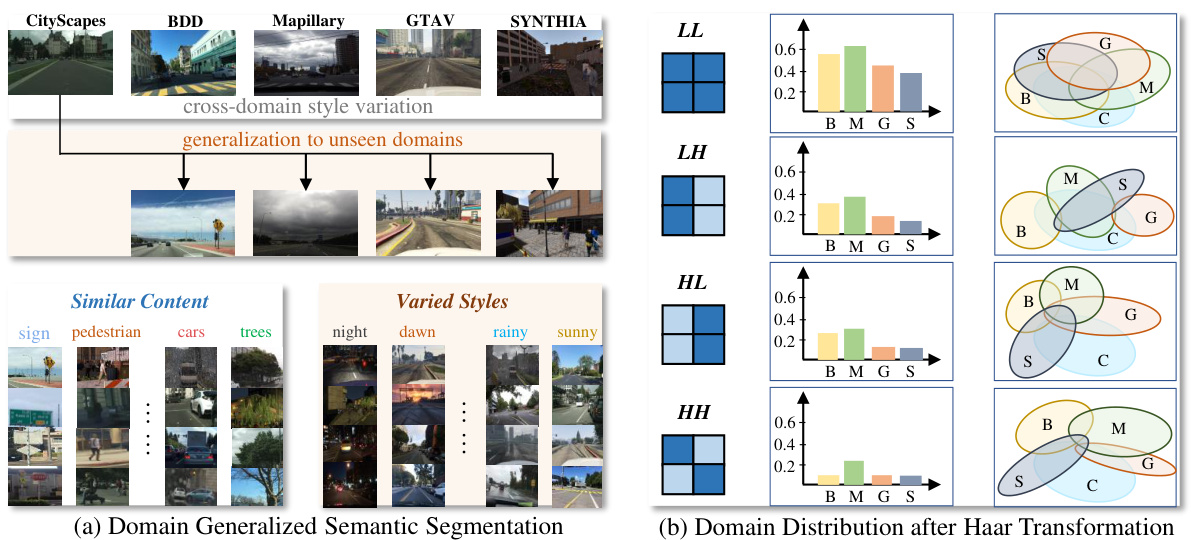
This figure shows the key challenge in domain generalized semantic segmentation (DGSS). The left side (a) illustrates how similar content can have varied styles across different domains. The right side (b) analyzes the impact of Haar wavelet transformation on the feature distribution. It demonstrates that low-frequency components maintain higher correlation across domains while high-frequency components show a larger domain gap, which is valuable for understanding the proposed method’s focus on separating style and content information.
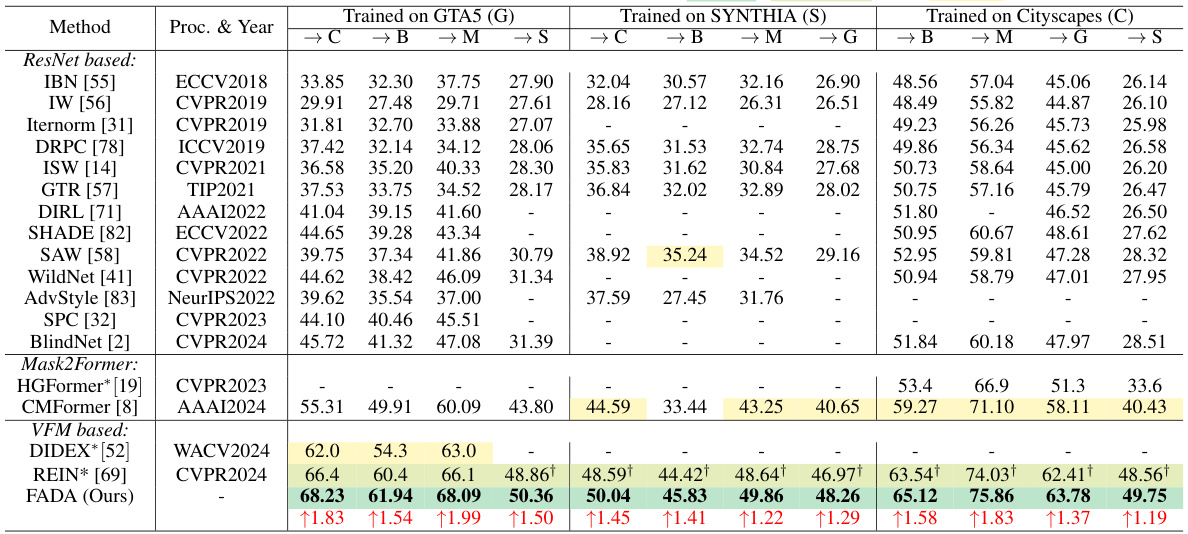
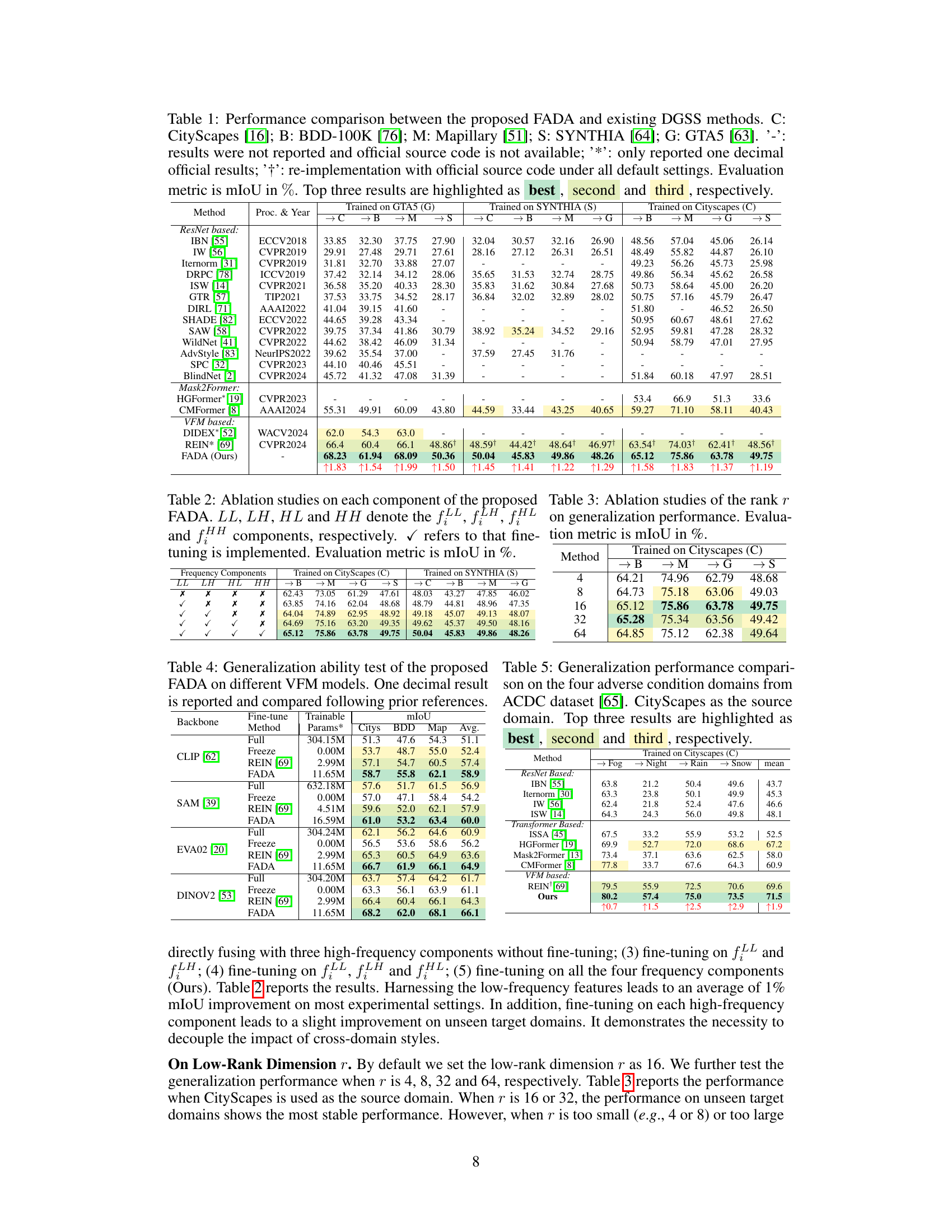
This table presents a comparison of the proposed Frequency-Adapted Domain Generalized Semantic Segmentation (FADA) method against several existing state-of-the-art Domain Generalized Semantic Segmentation (DGSS) methods across five benchmark datasets (Cityscapes, BDD100K, Mapillary, SYNTHIA, GTA5). The results are shown for three different experimental settings, indicating which dataset is used as the source domain for training and the remaining four as target domains. The mean Intersection over Union (mIoU) metric is used to evaluate the performance. The table highlights the top three performing methods for each setting, indicating the superiority of the proposed FADA method.
In-depth insights#
Freq-Adapt Learning#
Freq-Adapt Learning, as a concept, presents a powerful strategy for enhancing model robustness and generalization capabilities, particularly within the context of domain adaptation and generalization tasks. The core idea revolves around adapting a model’s learning process to the frequency characteristics of the input data. This can be achieved through various techniques that modify the weighting or filtering applied to different frequency bands. For instance, high-frequency components, often associated with style and noise, could be suppressed, whereas low-frequency components, which carry more semantic information, might be emphasized. The specific implementation depends heavily on the choice of frequency transform and the precise adaptation method, such as attention mechanisms or low-rank updates to specific frequency-sensitive layers. Benefits include improved resilience against noisy data and better transfer to unseen domains, making this approach particularly relevant for real-world applications with significant domain shifts. However, careful consideration should be paid to the choice of frequency decomposition method and adaptation strategy. Inappropriate choices can lead to loss of crucial information and reduced overall performance. The success of Freq-Adapt Learning hinges on effectively leveraging frequency information to guide the learning process, thereby enhancing both generalization and robustness.
VFM Style Decoupling#
The concept of “VFM Style Decoupling” presents a compelling approach to enhancing the robustness of Vision Foundation Models (VFMs) in domain generalization. The core idea revolves around separating style-specific information from content within VFM features. This disentanglement is crucial because style variations across domains (e.g., lighting, weather, viewpoint) often hinder the model’s ability to generalize to unseen data. Techniques like frequency analysis using wavelet transforms could be employed to achieve this decoupling, with low frequencies representing content and high frequencies capturing style. By isolating and potentially discarding or modifying style-specific information, VFMs can be made more robust to domain shifts. Effective decoupling strategies must be carefully chosen and evaluated to determine the optimal balance between preserving necessary visual details and mitigating the negative effects of style. Furthermore, the interaction between this decoupling and other VFM adaptation techniques needs further study to optimize performance.
Haar Wavelet DGSS#
Haar wavelet-based domain generalized semantic segmentation (DGSS) offers a compelling approach to address the challenge of visual domain shifts. By leveraging the Haar wavelet transform’s ability to decompose images into low- and high-frequency components, representing content and style respectively, this method aims to learn style-invariant features. The low-frequency information, rich in content, is used for robust semantic segmentation, while high-frequency components, reflecting style variations, are processed to mitigate their impact on cross-domain generalization. This frequency-based approach promises a more effective handling of domain adaptation by disentangling domain-invariant content from style-specific characteristics. However, it’s crucial to consider potential limitations such as the sensitivity of the Haar transform to noise and the effectiveness of this approach across diverse visual domains and foundation models. Further research should investigate optimal strategies for handling high-frequency information and the scalability of this method for large-scale datasets and complex scenes.
Low-Rank Adaptation#
Low-rank adaptation is a crucial technique in deep learning, particularly relevant when dealing with large models like Vision Foundation Models (VFMs). It addresses the challenge of parameter efficiency, allowing for fine-tuning of pre-trained models without drastically increasing the number of trainable parameters. This is achieved by decomposing the weight matrices into lower-rank matrices, effectively reducing the number of parameters that need to be updated. This approach is particularly beneficial in the context of domain generalized semantic segmentation (DGSS), where adapting VFMs to various unseen domains is essential. By applying low-rank adaptation, the model can maintain the knowledge learned from the large pre-trained dataset while adapting to the specific characteristics of the new domain. Reducing the number of trainable parameters helps in preventing overfitting and improving the generalization ability of the model. A key benefit is that this approach enables the fine-tuning process to be much faster, thereby making low-rank adaptation a very computationally practical method.
FADA Limitations#
The Frequency-Adapted learning scheme (FADA) for domain generalized semantic segmentation, while showing state-of-the-art results, has some limitations. Computational cost is a significant concern, as the method involves a Haar wavelet transform and two separate adaptation branches (low and high-frequency), increasing the number of parameters compared to simpler methods. The reliance on a frozen Vision Foundation Model (VFM) might hinder the flexibility in adapting to highly diverse and unseen domains, especially those exhibiting drastically different style characteristics. Although the method mitigates the effects of style variations, the effectiveness might be reduced when dealing with extreme style discrepancies. The generalizability to VFMs beyond DINO-V2 requires further investigation, although the authors demonstrate versatility. Finally, the impact of various Haar wavelet kernel parameters on performance could benefit from a more comprehensive study.
More visual insights#
More on figures
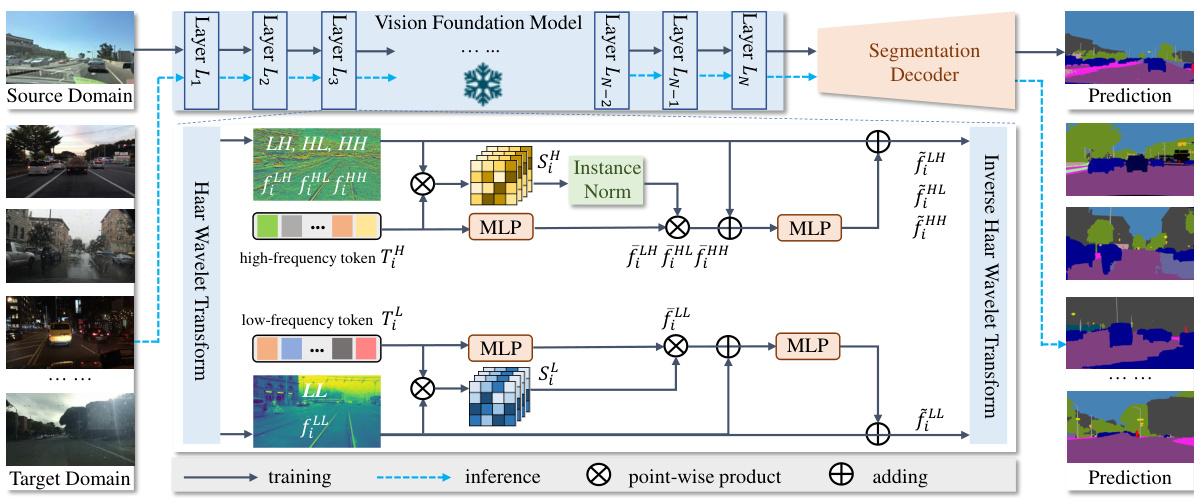
This figure illustrates the Frequency-adapted Vision Foundation Model (FADA) learning scheme proposed in the paper. FADA processes frozen Vision Foundation Model (VFM) features by first using a Haar wavelet transform to decompose them into low- and high-frequency components. The low-frequency components, representing scene content, are processed by a low-frequency adaptation branch, while the high-frequency components, representing style information, are handled by a high-frequency adaptation branch using instance normalization. The adapted low- and high-frequency components are then fused and undergo an inverse Haar wavelet transform to yield the final feature map, which is then fed into a segmentation decoder.
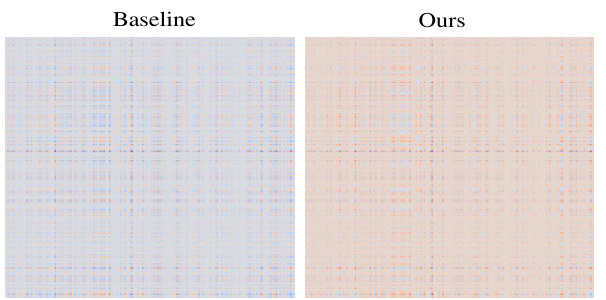
This figure shows a heatmap visualizing the correlation between the channel-wise features from the last layer of the Vision Foundation Model (VFM) in the source domain (Cityscapes) and a target domain (BDD100k). Brighter colors indicate higher correlation, suggesting that FADA helps align features across different domains, which should improve cross-domain generalization performance. The low and high-frequency decomposition is shown in figure 2.

This figure shows the t-SNE visualization of features extracted from the last VFM layer. The left panel displays the baseline results, while the right panel shows the results obtained using the proposed method. The visualization helps to understand the impact of the proposed method on the feature distribution. By comparing the two panels, we can observe how the proposed method improves the separation of features from different unseen target domains, leading to better generalization performance.

This figure shows t-SNE visualizations of high-frequency components (LH, HL, HH) from the last VFM layer, comparing the feature distributions with and without instance normalization. The visualizations demonstrate how instance normalization helps to mitigate domain-specific information present in the high-frequency components, leading to a more uniform distribution of samples from different unseen target domains, thus improving domain generalization.

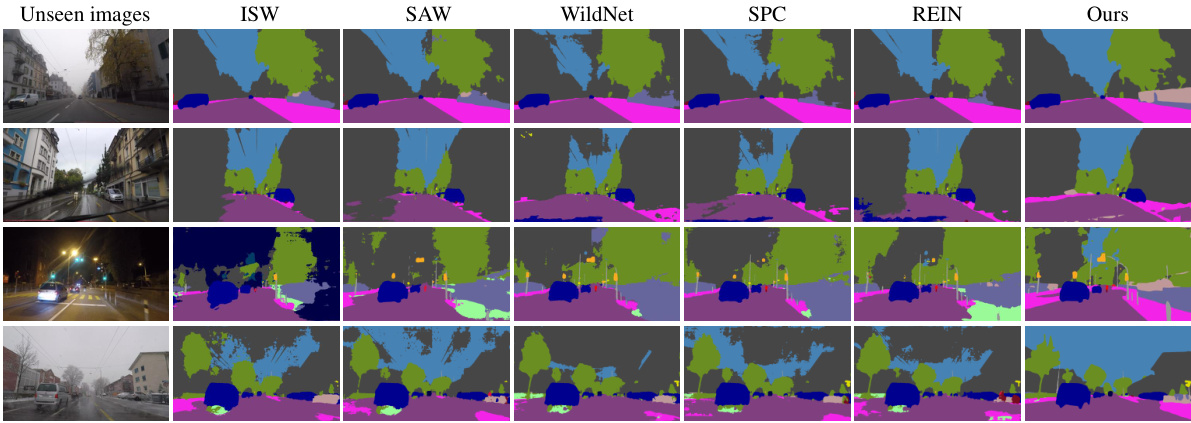
This figure shows a qualitative comparison of semantic segmentation results on unseen images from four different datasets (BDD, GTA5, Mapillary, SYNTHIA). The results are from several state-of-the-art Domain Generalized Semantic Segmentation (DGSS) methods and the proposed Frequency-Adapted (FADA) method. The goal is to visually demonstrate the superior performance of FADA in handling style variations across different domains, leading to more accurate and robust segmentations.
This figure shows two parts: (a) illustrates the core challenge of domain generalized semantic segmentation (DGSS), which is maintaining consistent scene content while handling variations in style across different domains. (b) analyzes the impact of Haar wavelet transformation on the features of a Vision Foundation Model (VFM). By calculating the correlation between a source domain and several target domains in both low and high-frequency components, it demonstrates that the low-frequency components are more consistent across domains, while the high-frequency components exhibit a larger domain gap.

This figure shows the ablation study on different token lengths (m) in the proposed FADA model. The impact of varying token lengths on the model’s performance is evaluated across four different unseen target domains (B, M, G, S) with CityScapes (C) as the source domain. The graphs illustrate how the mean Intersection over Union (mIoU) varies depending on the token length used for each target domain.

This figure shows a qualitative comparison of the proposed FADA method against several existing Domain Generalized Semantic Segmentation (DGSS) methods on unseen images from four different datasets (BDD, GTA5, Mapillary, SYNTHIA). The Cityscapes dataset is used as the source domain for training. The results show the segmentation output for each method alongside the ground truth for visual comparison, highlighting the performance differences. The images cover various driving scenarios, showcasing the challenges of DGSS.

This figure shows a qualitative comparison of segmentation results produced by several existing domain generalized semantic segmentation methods and the proposed Frequency-Adapted (FADA) method. The source domain is Cityscapes (C), and the target domains are BDD100k (B), GTA5 (G), Mapillary (M), and SYNTHIA (S). Each column shows the segmentation results of a different method: ISW, SAW, WildNet, SPC, REIN, and the proposed FADA. The rows represent different unseen images from the target domains. This comparison visually demonstrates the superior performance of FADA in terms of accuracy and detail preservation compared to existing methods.
More on tables

This table compares the performance of the proposed Frequency-Adapted Domain Generalization Semantic Segmentation model (FADA) against several state-of-the-art methods on five benchmark datasets. Different source domains are used with the remaining four serving as unseen target domains for evaluation. The results are presented in terms of mean Intersection over Union (mIoU), a common metric for evaluating semantic segmentation accuracy. The table also indicates which methods were re-implemented and which results were taken from the original papers.
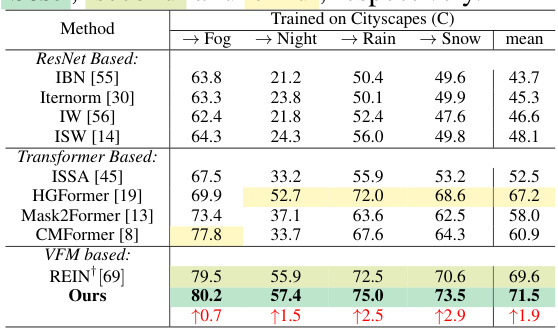
This table compares the performance of the proposed Frequency-Adapted Domain Generalized Semantic Segmentation model (FADA) against other state-of-the-art methods across various source and target domain settings. It shows the mean Intersection over Union (mIoU) for each setting, highlighting the top three performing methods. The table also notes which methods had incomplete results or were re-implemented by the authors.

This table compares the performance of the proposed Frequency-Adapted (FADA) learning scheme against several state-of-the-art Domain Generalized Semantic Segmentation (DGSS) methods across different source and target domains. The results are evaluated using the mean Intersection over Union (mIoU) metric, showing the superiority of FADA in various settings.

This table presents an ablation study to analyze the impact of the position of frequency adapters in the proposed FADA model. The experiment uses GTA5 as the source domain and CityScapes, BDD, and Mapillary as unseen target domains. The mean Intersection over Union (mIoU) metric is used to evaluate performance. The table compares the full model, the frozen VFM baseline, REIN [69], and three variants of FADA with the frequency adapter placed in different layer positions (shallow, deep, and all layers).
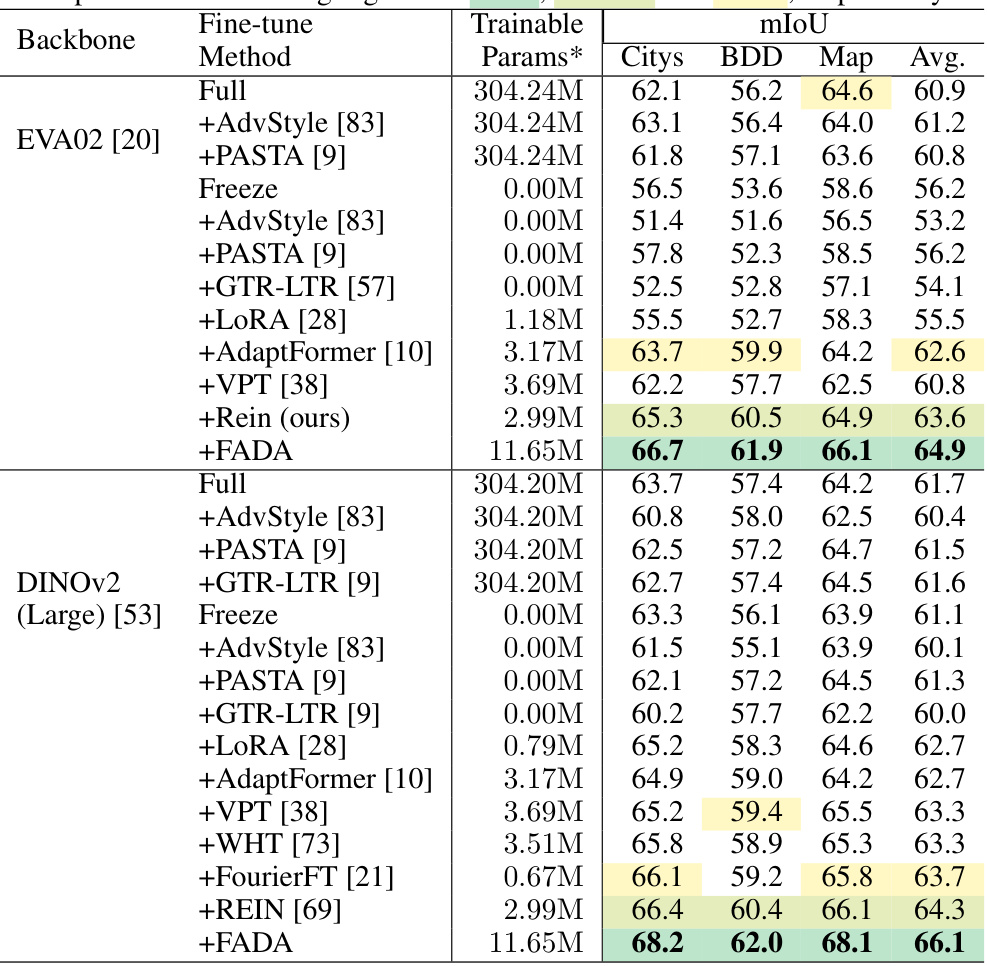
This table compares the performance of the proposed Frequency-Adapted (FADA) method against various state-of-the-art Domain Generalized Semantic Segmentation (DGSS) methods across five datasets (Cityscapes, BDD100k, Mapillary, SYNTHIA, GTA5). The comparison is done under different experimental settings, each using one dataset as the source domain and the remaining four as target domains. The table displays the mean Intersection over Union (mIoU) scores and highlights the best performing methods for each setting.
Full paper#